基于 Prometheus+Grafana+Alertmanager 搭建 K8S 云监控告警平台(附配置告警至QQ、钉钉)
文章目录
- 一、机器规划
- 二、部署安装 node-exporter、prometheus、Grafana、kube-state-metrics
- 1、创建 monitor-sa 命名空间
- 2、安装node-exporter组件
- 2.1、说明
- 2.2、应用资源清单
- 2.3、通过node-exporter采集数据
- 3、k8s 集群中部署 prometheus
- 3.1、创建一个 sa 账号
- 3.2、将 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
- 3.3、创建数据目录
- 3.4、安装prometheus
- 3.4.1、将 `prometheus.yml` 文件以 ConfigMap 的形式进行管理
- 3.4.2、应用 cm 资源清单
- 3.4.3、通过 Deployment 部署 prometheus
- 3.4.4、应用 prometheus 资源清单
- 3.4.5、给 prometheus 的 pod 创建一个 svc
- 3.4.6、应用 svc 资源清单
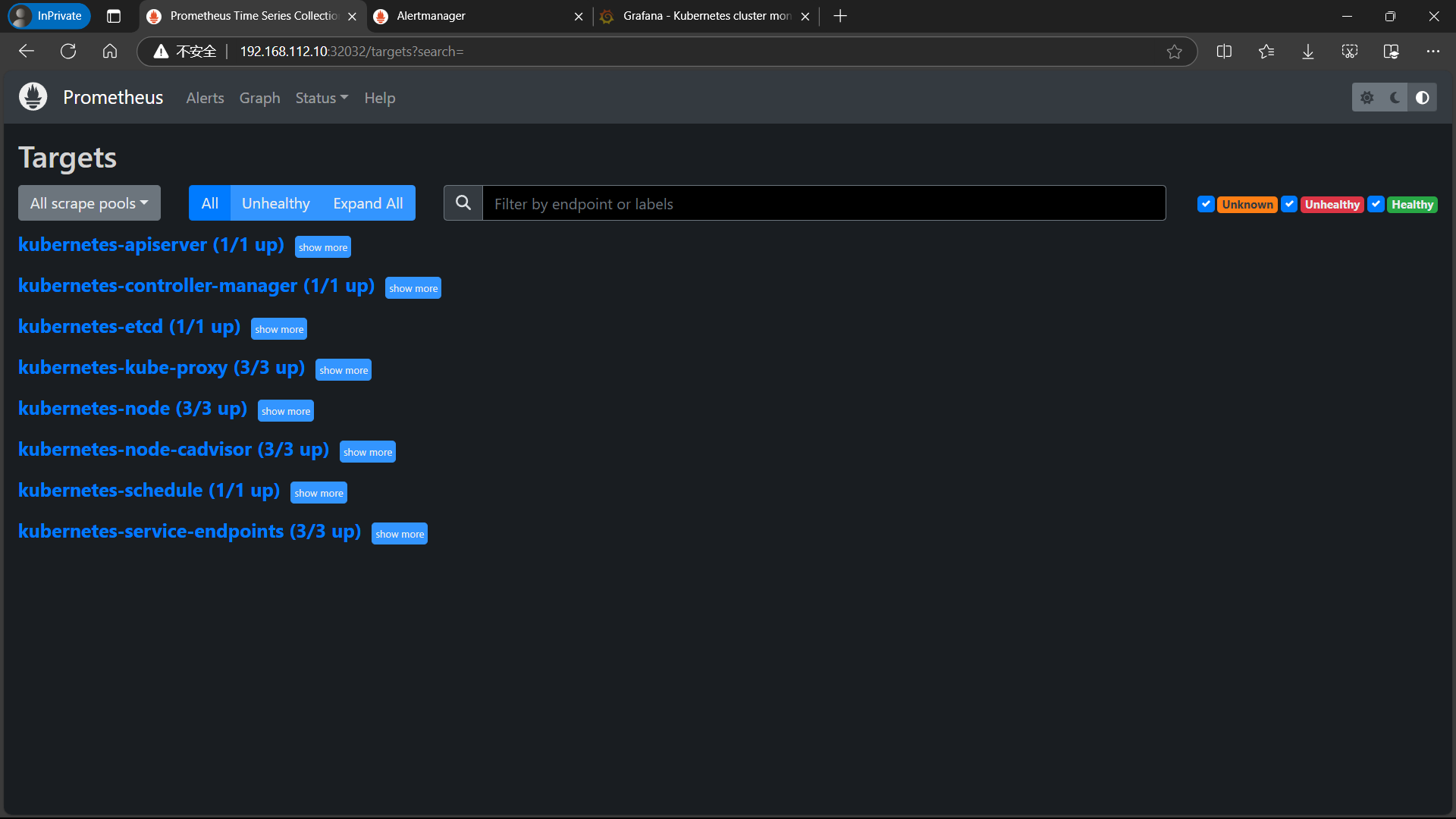
- 3.5、访问prometheus UI界面
- 3.6、查看配置的服务发现
- 4、prometheus热更新
- 4.1、热加载 prometheus
- 4.2、暴力重启 prometheus
- 5、Grafana安装和配置
- 5.1、下载 Grafana 需要的镜像
- 5.2、在 k8s 集群各个节点导入 Grafana 镜像
- 5.3、master 节点创建 grafana.yaml
- 5.4、查看 Grafana 的 pod 和 svc
- 5.5、查看 Grafana UI 界面
- 5.6、给 Grafana 接入 Prometheus 数据源
- 5.7、获取监控模板
- 5.8、导入监控模板
- 6、安装配置 kube-state-metrics 组件
- 6.1、什么是 kube-state-metrics
- 6.2、创建 sa ,并进行授权
- 6.3、创建并应用 kube-state-metrics-deploy.yaml 文件
- 6.4、创建并应用 kube-state-metrics-svc.yaml 文件
- 6.5、获取 kube-state-metrics json 文件
- 6.6、向 Grafana 导入 kube-state-metrics json 文件
- 三、安装和配置 Alertmanager -- 发送告警到 QQ 邮箱
- 1、将 alertmanager-cm.yaml 文件以 cm 形式进行管理
- 1.1、alertmanager配置文件说明
- 2、重新生成并应用 prometheus-cfg.yaml 文件
- 3、重新生成 prometheus-deploy.yaml 文件
- 3.1、创建一个名为 etcd-certs 的 Secret
- 3.2、应用 prometheus-deploy.yaml 文件
- 4、重新生成并创建 alertmanager-svc.yaml 文件
- 5、访问 prometheus UI 界面
- 5.1、【error】kube-controller-manager、etcd、kube-proxy、kube-scheduler 组件 connection refused
- 5.1.1、kube-proxy
- 5.1.2、kube-controller-manager
- 5.1.3、kube-schedule
- 5.1.4、etcd
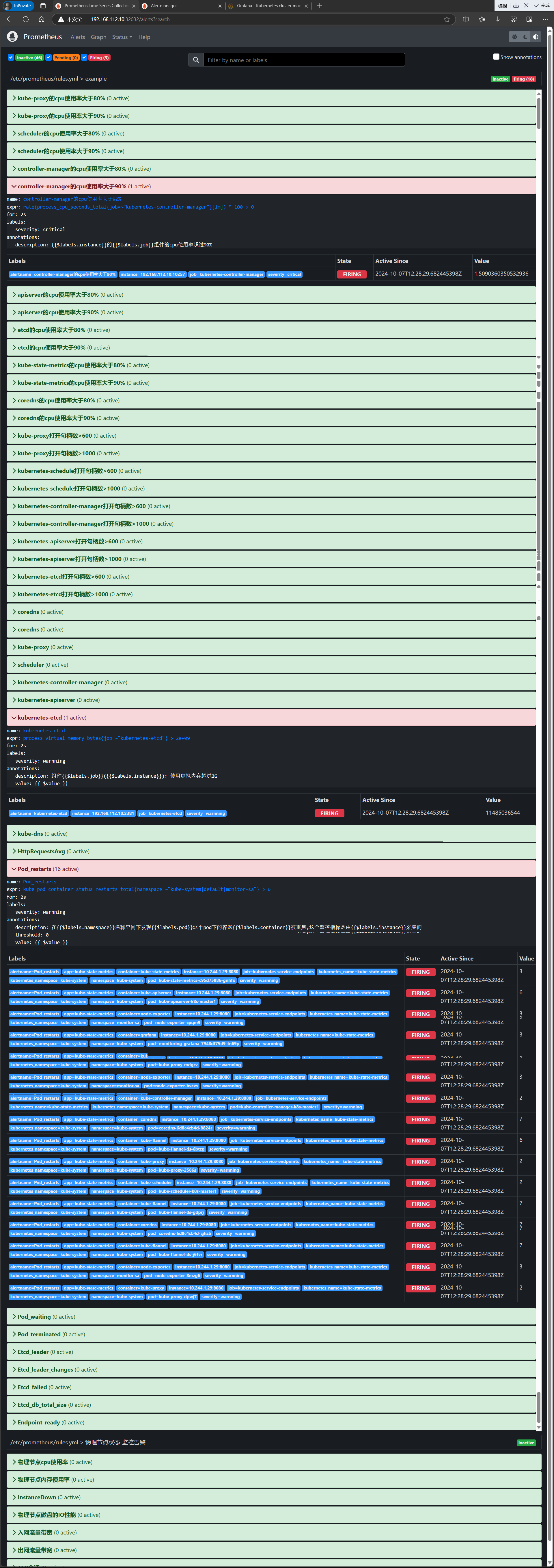
- 6、点击Alerts,查看
- 7、把controller-manager的cpu使用率大于90%展开
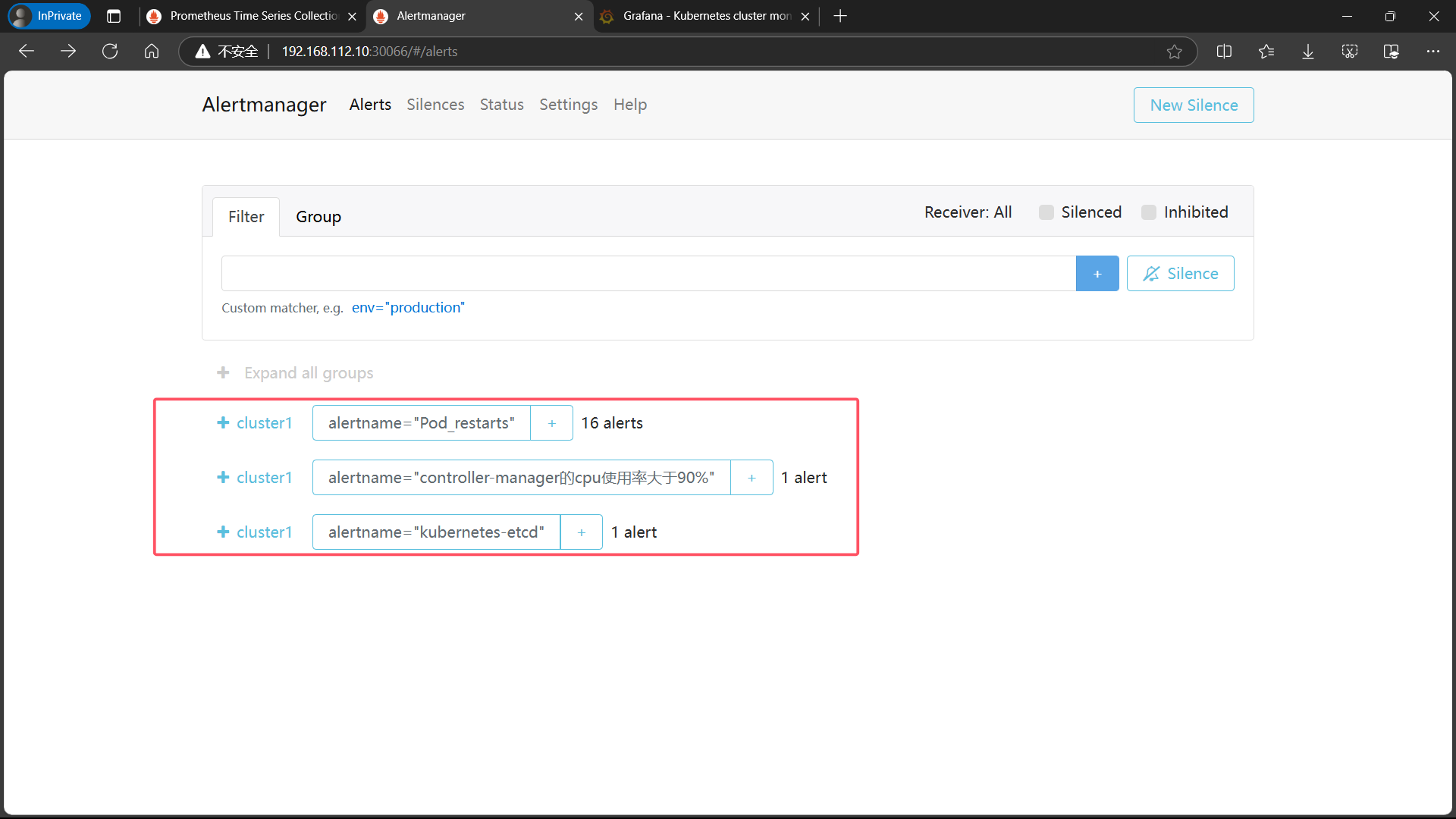
- 8、登录 alertmanager UI
- 9、登录 QQ 邮箱查看告警信息
- 四、配置 Alertmanager 报警 -- 发送告警到钉钉
- 1、手机端拉群
- 2、创建自定义机器人
- 3、获取钉钉的 Webhook 插件
- 4、启动钉钉告警插件
- 5、对 alertmanager-cm.yaml 文件做备份
- 6、重新生成新的 alertmanager-cm.yaml 文件
- 7、重建资源以生效
- 8、效果
一、机器规划
| 角色 | 主机名 | ip 地址 |
|---|---|---|
| master | k8s-master1 | 192.168.112.10 |
| node | k8s-node1 | 192.168.112.20 |
| node | k8s-node2 | 192.168.112.30 |
| 平台 | VMware Workstation |
|---|---|
| 操作系统 | CentOS Linux release 7.9.2009 (Core) |
| 内存、CPU | 4C4G |
| 磁盘大小 | 20G SCSI |
二、部署安装 node-exporter、prometheus、Grafana、kube-state-metrics
1、创建 monitor-sa 命名空间
master 节点操作
kubectl create ns monitor-sa
2、安装node-exporter组件
master 节点操作
cat >> node-export.yaml <<EOF
apiVersion: apps/v1
kind: DaemonSet
metadata:name: node-exporternamespace: monitor-salabels:name: node-exporter
spec:selector:matchLabels:name: node-exportertemplate:metadata:labels:name: node-exporterspec:hostPID: truehostIPC: truehostNetwork: truecontainers:- name: node-exporterimage: prom/node-exporter:v0.16.0ports:- containerPort: 9100resources:requests:cpu: 0.15securityContext:privileged: trueargs:- --path.procfs- /host/proc- --path.sysfs- /host/sys- --collector.filesystem.ignored-mount-points- '"^/(sys|proc|dev|host|etc)($|/)"'volumeMounts:- name: devmountPath: /host/dev- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootfsmountPath: /rootfstolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"volumes:- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: rootfshostPath:path: /
EOF
2.1、说明
- 主机命名空间共享 (
hostPID,hostIPC,hostNetwork)hostPID: true: 允许 Pod 使用主机的 PID 命名空间。Pod 可以看到主机上的所有进程hostIPC: true: 允许 Pod 使用主机的 IPC 命名空间。Pod 可以与其他在主机上运行的进程共享 IPC 资源(如信号量、消息队列等)。hostNetwork: true: 允许 Pod 使用主机的网络命名空间。Pod 将使用主机的网络接口
- 命令行参数 (
args) --path.procfs /host/proc: 指定node-exporter应该从/host/proc路径读取进程文件系统的数据。这使得node-exporter可以访问宿主机的进程信息。--path.sysfs /host/sys: 指定node-exporter应该从/host/sys路径读取系统文件系统的数据。这使得node-exporter可以访问宿主机的系统信息。--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)": 指定哪些文件系统的挂载点应该被忽略,不被node-exporter收集。这里忽略了/sys,/proc,/dev,/host, 和/etc这些挂载点,避免收集不必要的数据。- 挂载点 (
volumeMounts和volumes)/proc挂载- 宿主机路径:
/proc - 容器内路径:
/host/proc - 作用: 让
node-exporter访问宿主机的进程文件系统。
- 宿主机路径:
/dev挂载- 宿主机路径:
/dev - 容器内路径:
/host/dev - 作用: 让
node-exporter访问宿主机的设备文件。
- 宿主机路径:
/sys挂载- 宿主机路径:
/sys - 容器内路径:
/host/sys - 作用: 让
node-exporter访问宿主机的系统文件系统。
- 宿主机路径:
/挂载- 宿主机路径:
/ - 容器内路径:
/rootfs - 作用: 让
node-exporter访问宿主机的根文件系统。
- 宿主机路径:
- 容忍度 (
tolerations)key: "node-role.kubernetes.io/master": 指定容忍的污点键。operator: "Exists": 表示只要存在该污点键,无论值是什么,都予以容忍。effect: "NoSchedule": 表示即使节点上有这种污点,也不会阻止 Pod 被调度到该节点上。
2.2、应用资源清单
kubectl apply -f node-export.yamlkubectl get pods -n monitor-sa -l name=node-exporter

2.3、通过node-exporter采集数据
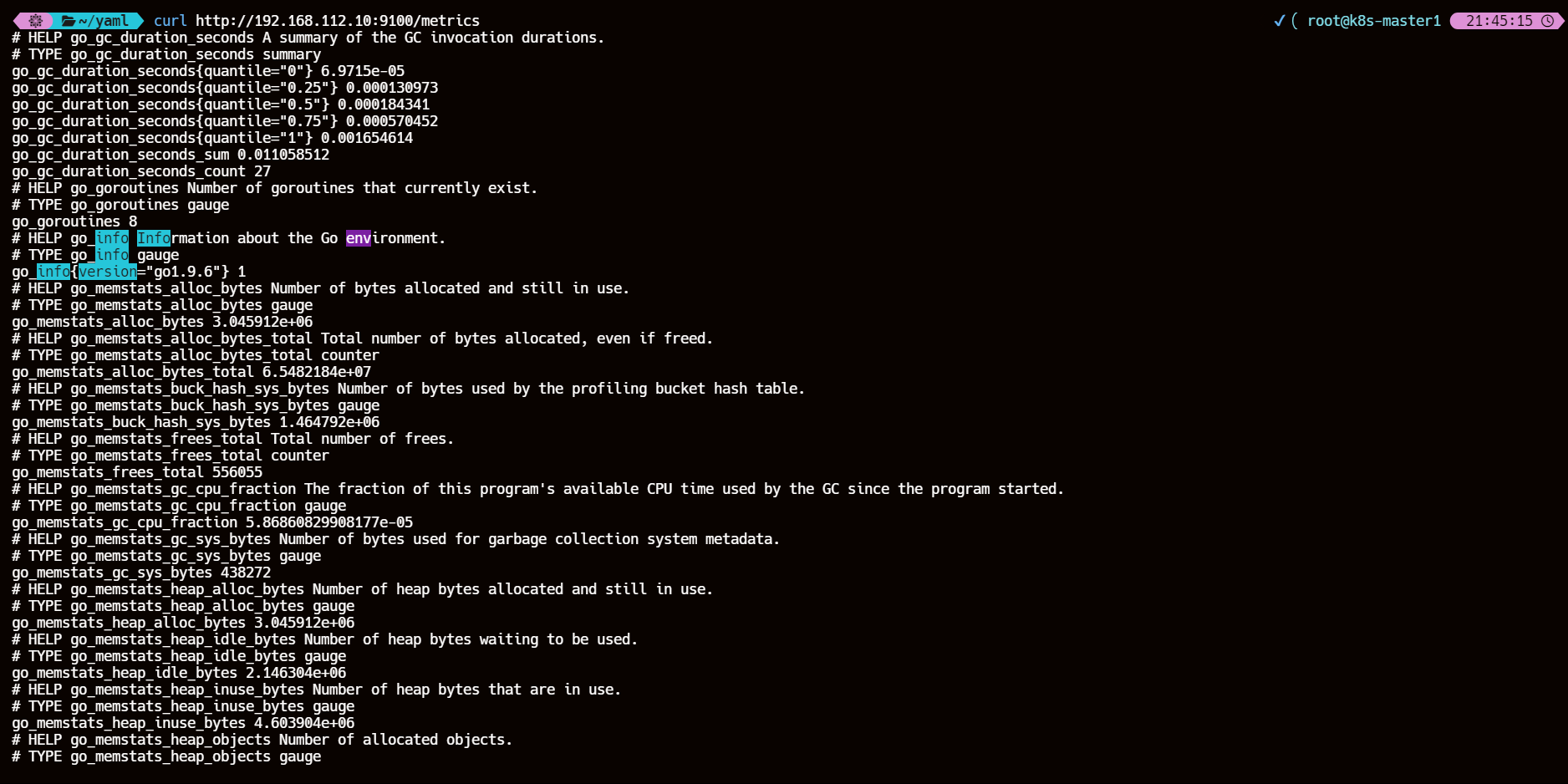
node-export默认的监听端口是9100,可以看到当前主机获取到的所有监控数据
# curl http://<master-ip>:9100/metricscurl http://192.168.112.10:9100/metrics
3、k8s 集群中部署 prometheus
3.1、创建一个 sa 账号
kubectl create serviceaccount monitor -n monitor-sa
3.2、将 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
3.3、创建数据目录
所有 node 节点
mkdir /data && chmod 777 /data/
3.4、安装prometheus
master 节点操作
3.4.1、将 prometheus.yml 文件以 ConfigMap 的形式进行管理
cat >> prometheus-cfg.yaml << 'EOF'
---
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |global:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: '/api/v1/nodes/${1}/proxy/metrics/cadvisor'- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: '$1:$2'- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name
EOF
3.4.2、应用 cm 资源清单
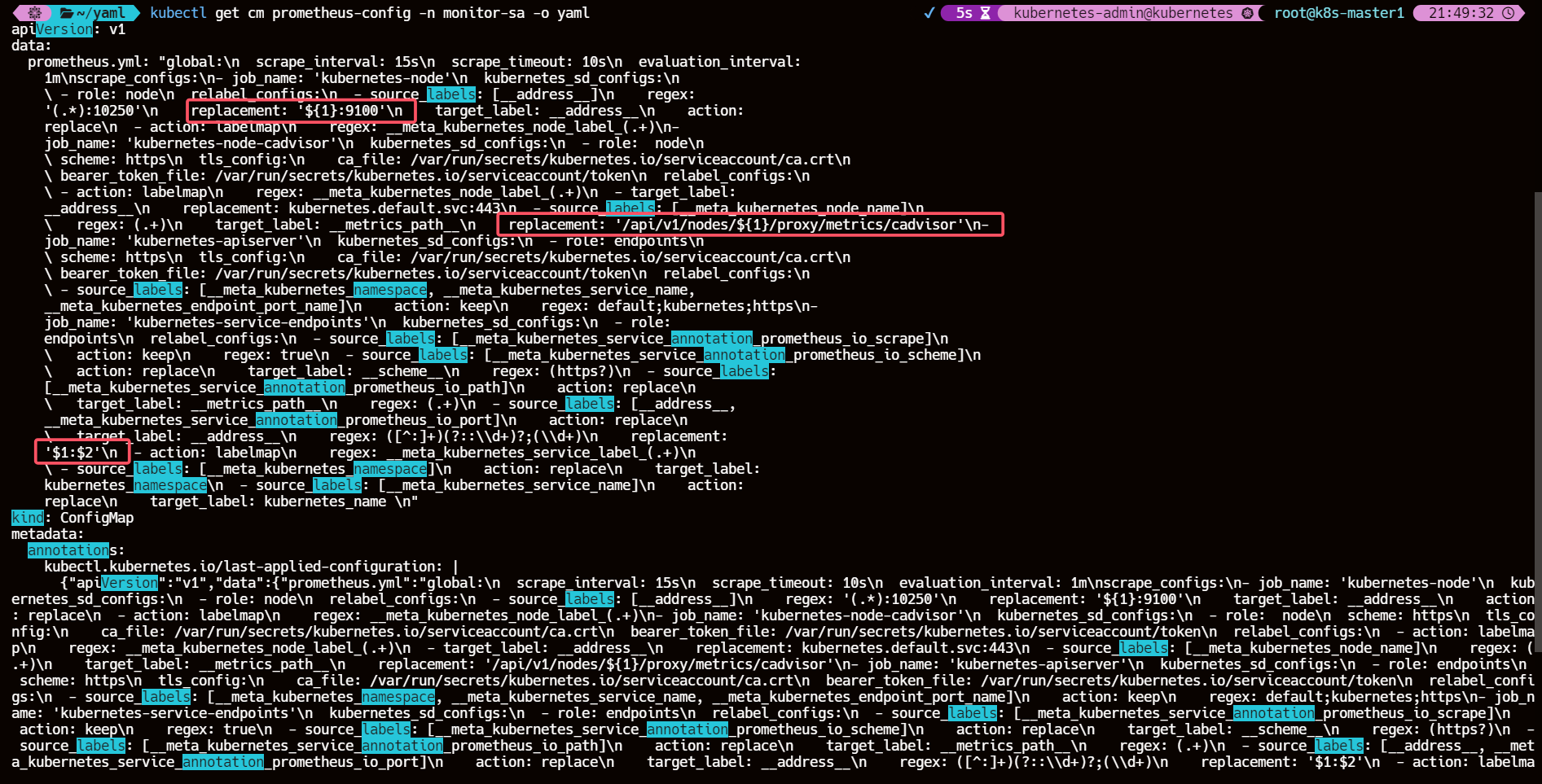
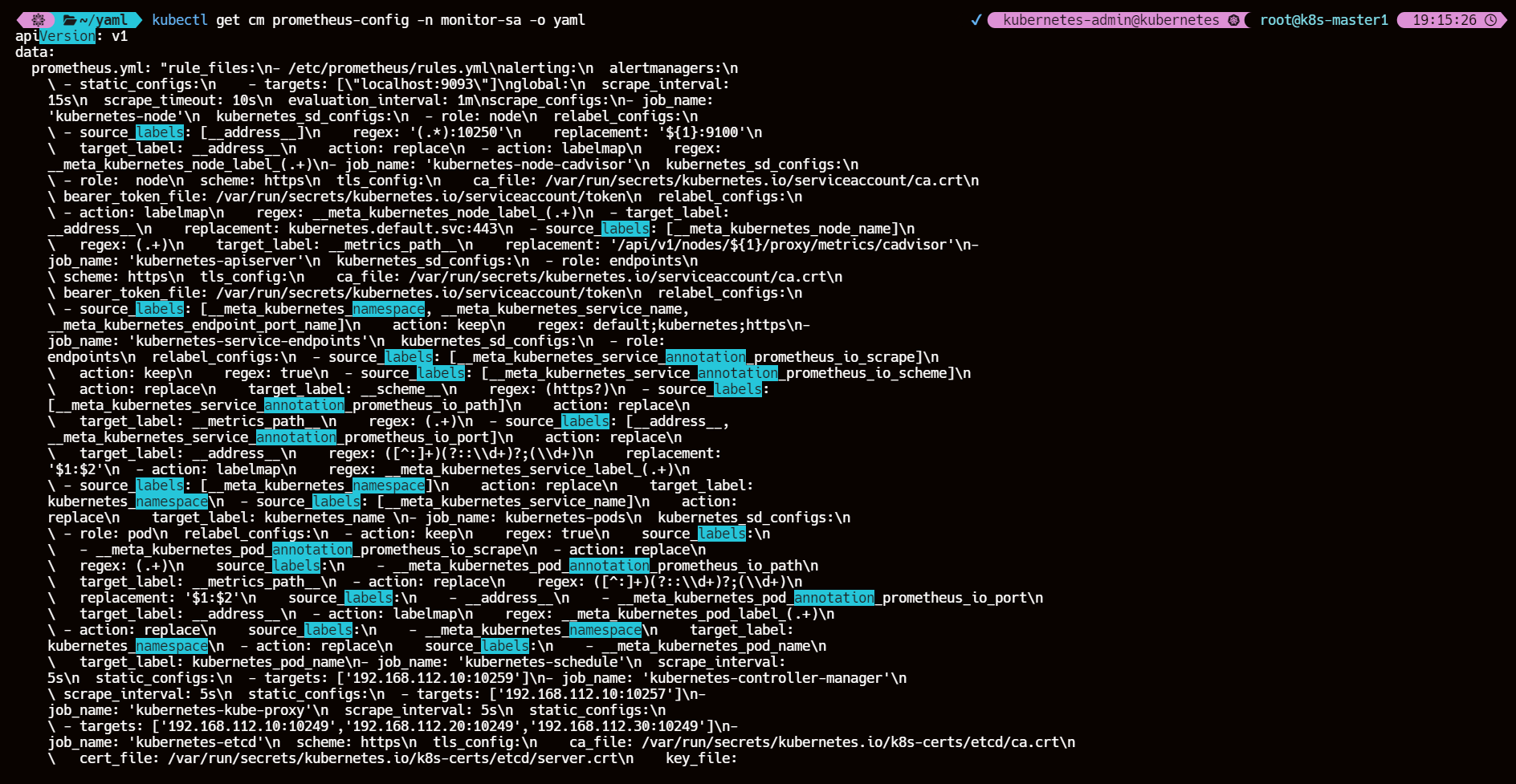
kubectl apply -f prometheus-cfg.yamlkubectl get cm prometheus-config -n monitor-sa -o yaml
需要确保 cm 正确解析了变量 $1、$2
不然 prometheus 获取不到对应的 IP 地址会无法正常监控
3.4.3、通过 Deployment 部署 prometheus
cat >> prometheus-deploy.yaml << EOF
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 2selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- prometheus- key: componentoperator: Invalues:- servertopologyKey: kubernetes.io/hostnameserviceAccountName: monitorcontainers:- name: prometheusimage: quay.io/prometheus/prometheus:latestimagePullPolicy: IfNotPresentcommand:- prometheus- --config.file=/etc/prometheus/prometheus.yml- --storage.tsdb.path=/prometheus- --storage.tsdb.retention=720hports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheus/prometheus.ymlname: prometheus-configsubPath: prometheus.yml- mountPath: /prometheus/name: prometheus-storage-volumevolumes:- name: prometheus-configconfigMap:name: prometheus-configitems:- key: prometheus.ymlpath: prometheus.ymlmode: 0644- name: prometheus-storage-volumehostPath:path: /datatype: Directory
EOF
3.4.4、应用 prometheus 资源清单
kubectl apply -f prometheus-deploy.yaml

3.4.5、给 prometheus 的 pod 创建一个 svc
cat > prometheus-svc.yaml << EOF
---
apiVersion: v1
kind: Service
metadata:name: prometheusnamespace: monitor-salabels:app: prometheus
spec:type: NodePortports:- port: 9090targetPort: 9090protocol: TCPselector:app: prometheuscomponent: server
EOF
3.4.6、应用 svc 资源清单
kubectl get svc -n monitor-sa -o wide

通过上面可以看到service在宿主机上映射的端口是30172,这样我们访问k8s集群的k8s-master1节点的ip:30172,就可以访问到prometheus的web ui界面了
3.5、访问prometheus UI界面
# <k8s-master1 IP>:32032
192.168.112.10:32032
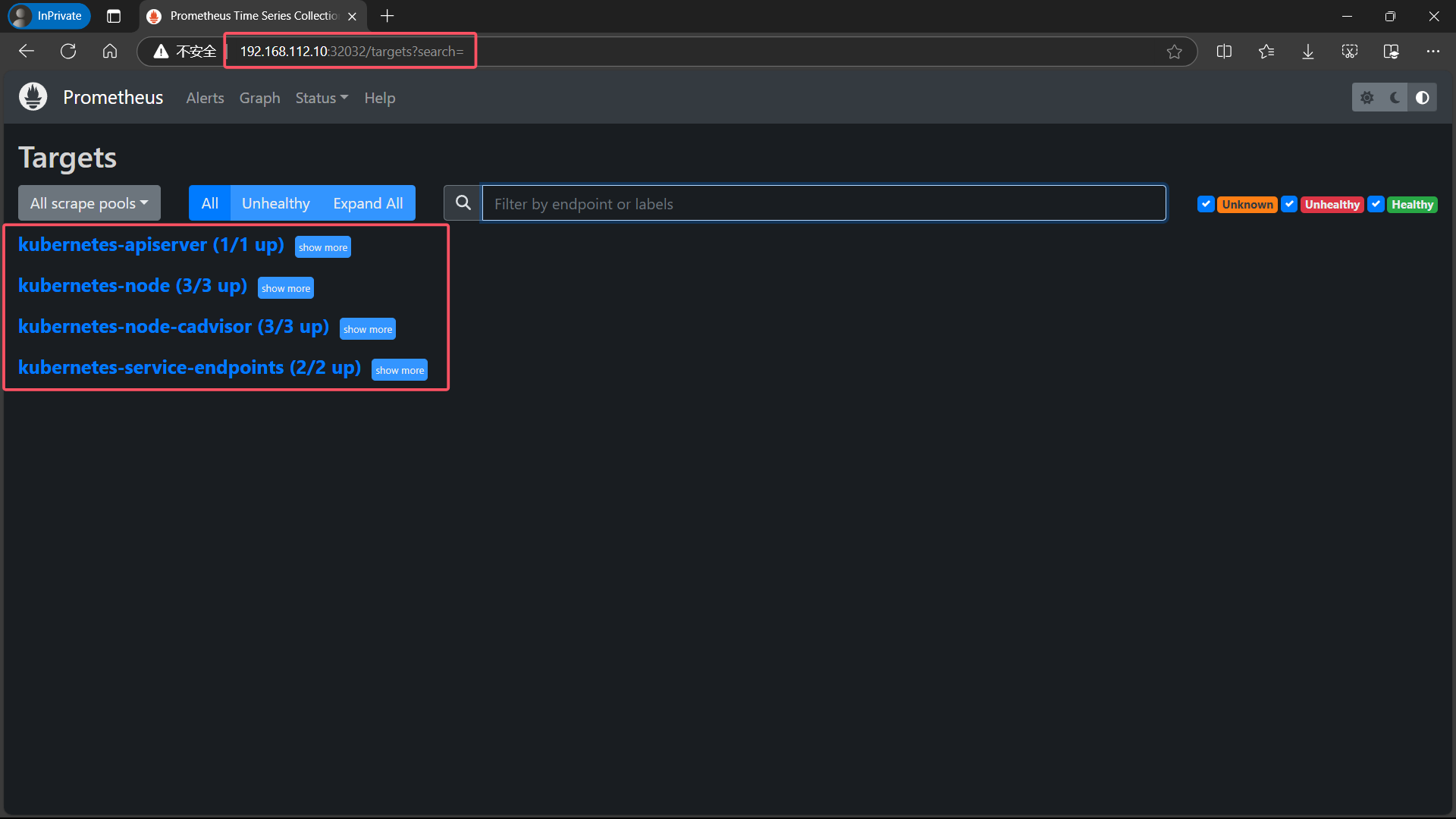
3.6、查看配置的服务发现
点击页面的Status->Targets,可看到如下,说明我们配置的服务发现可以正常采集数据
4、prometheus热更新
4.1、热加载 prometheus
#为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效,如修改prometheus-cfg.yaml,想要使配置生效可用如下热加载命令:
curl -X POST http://<prometheus-pod-ip>:9090/-/reload
kubectl get pods -n monitor-sa -l app=prometheus -o wide

4.2、暴力重启 prometheus
热加载速度比较慢,可以暴力重启prometheus
如修改上面的prometheus-cfg.yaml文件之后,可执行如下强制删除
kubectl delete -f prometheus-cfg.yamlkubectl delete -f prometheus-deploy.yaml# 然后再通过apply更新kubectl apply -f prometheus-cfg.yamlkubectl apply -f prometheus-deploy.yaml
线上最好热加载,暴力删除可能造成监控数据的丢失
5、Grafana安装和配置
5.1、下载 Grafana 需要的镜像
链接:https://pan.baidu.com/s/1TmVGKxde_cEYrbjiETboEA
提取码:052u
5.2、在 k8s 集群各个节点导入 Grafana 镜像
docker load -i heapster-grafana-amd64_v5_0_4.tar.gzdocker images | grep grafana



5.3、master 节点创建 grafana.yaml
cat >> grafana.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: monitoring-grafananamespace: kube-system
spec:replicas: 1selector:matchLabels:task: monitoringk8s-app: grafanatemplate:metadata:labels:task: monitoringk8s-app: grafanaspec:containers:- name: grafanaimage: k8s.gcr.io/heapster-grafana-amd64:v5.0.4ports:- containerPort: 3000protocol: TCPvolumeMounts:- mountPath: /etc/ssl/certsname: ca-certificatesreadOnly: true- mountPath: /varname: grafana-storageenv:- name: INFLUXDB_HOSTvalue: monitoring-influxdb- name: GF_SERVER_HTTP_PORTvalue: "3000"# The following env variables are required to make Grafana accessible via# the kubernetes api-server proxy. On production clusters, we recommend# removing these env variables, setup auth for grafana, and expose the grafana# service using a LoadBalancer or a public IP.- name: GF_AUTH_BASIC_ENABLEDvalue: "false"- name: GF_AUTH_ANONYMOUS_ENABLEDvalue: "true"- name: GF_AUTH_ANONYMOUS_ORG_ROLEvalue: Admin- name: GF_SERVER_ROOT_URL# If you're only using the API Server proxy, set this value instead:# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxyvalue: /volumes:- name: ca-certificateshostPath:path: /etc/ssl/certs- name: grafana-storageemptyDir: {}
---
apiVersion: v1
kind: Service
metadata:labels:# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)# If you are NOT using this as an addon, you should comment out this line.kubernetes.io/cluster-service: 'true'kubernetes.io/name: monitoring-grafananame: monitoring-grafananamespace: kube-system
spec:# In a production setup, we recommend accessing Grafana through an external Loadbalancer# or through a public IP.# type: LoadBalancer# You could also use NodePort to expose the service at a randomly-generated port# type: NodePortports:- port: 80targetPort: 3000selector:k8s-app: grafanatype: NodePort
EOF
5.4、查看 Grafana 的 pod 和 svc

5.5、查看 Grafana UI 界面
# <master-ip>:<grafana-svc-port>192.168.112.10:31455
5.6、给 Grafana 接入 Prometheus 数据源
| 选择 Create your first data source |
|---|
 |
 |
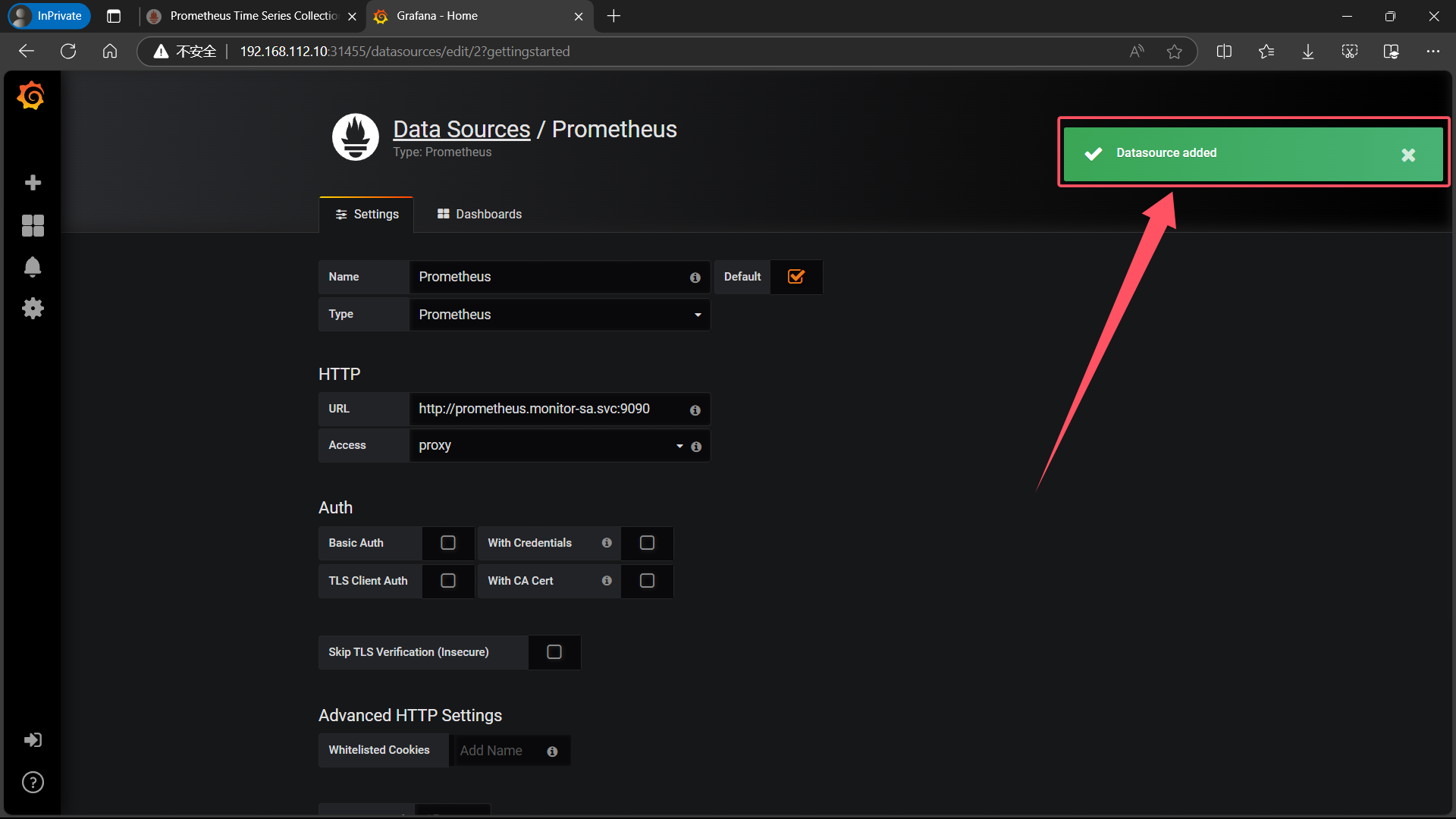
| Name: Prometheus |Type: Prometheus|HTTP 处的URL写 如下:http://prometheus.monitor-sa.svc:9090 |
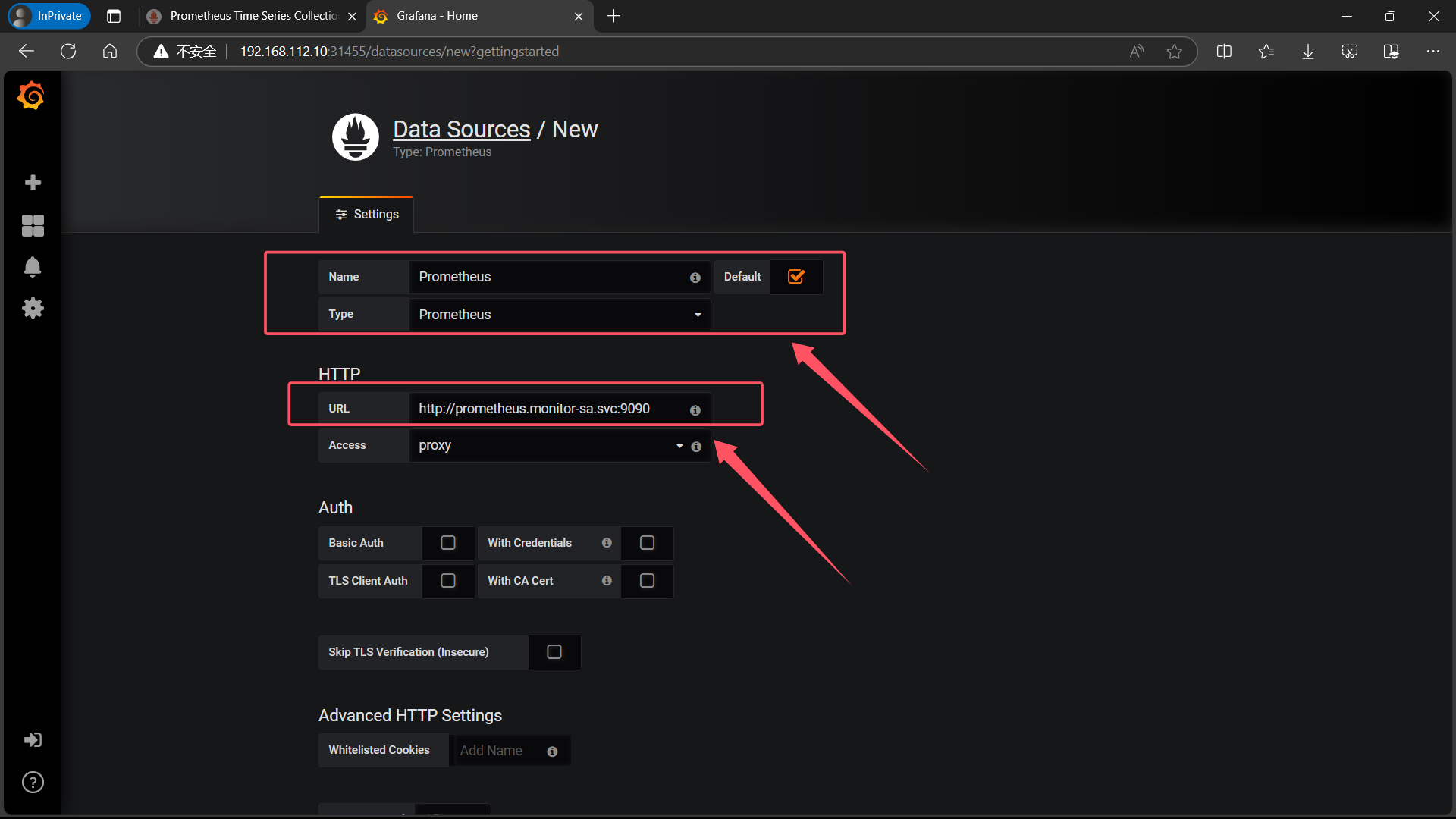 |
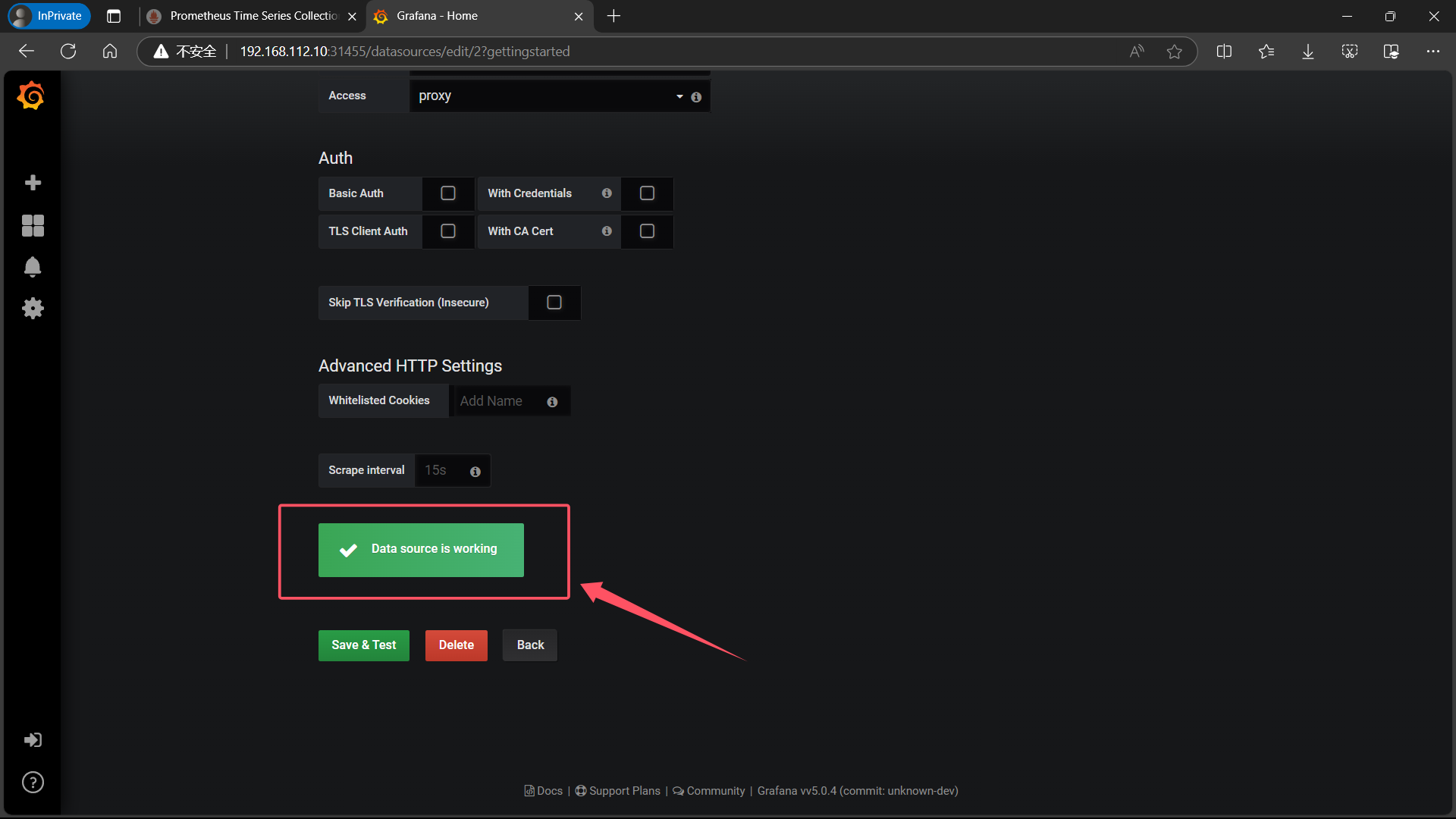
| 点击左下角 Save & Test,出现如下 Data source is working,说明 prometheus 数据源成功的被 grafana 接入了 |
 |
 |
5.7、获取监控模板
- 可以在 Grafana Dashboard 官网搜索需要的
Grafana dashboards | Grafana Labs
- 也可以直接克隆 Github 仓库,获取 node_exporter.json 、 docker_rev1.json 监控模板
git clone git@github.com:misakivv/Grafana-Dashboard.git
5.8、导入监控模板
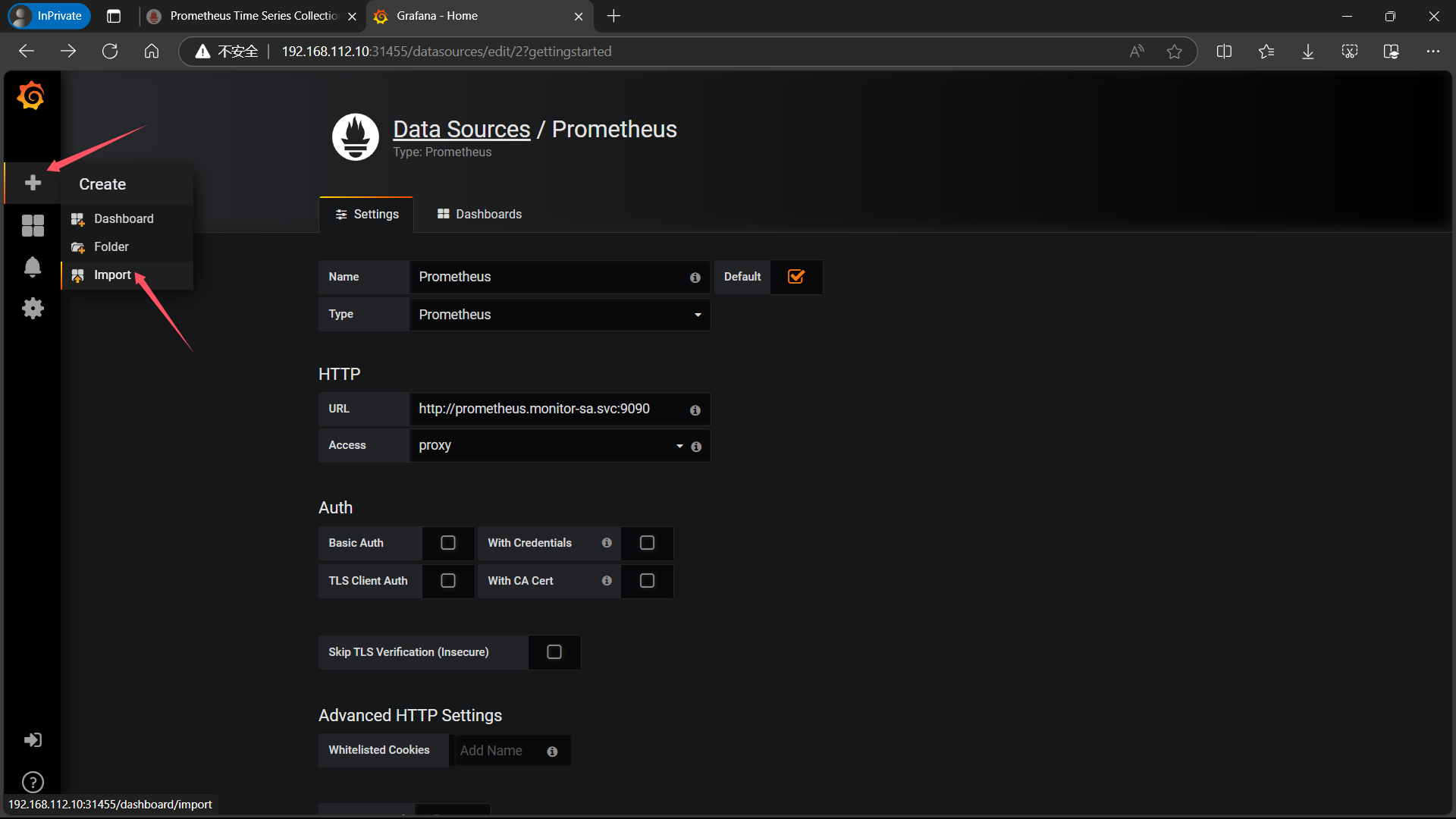
| 依次点击左侧栏的 + 号下方的 Import |
|---|
 |
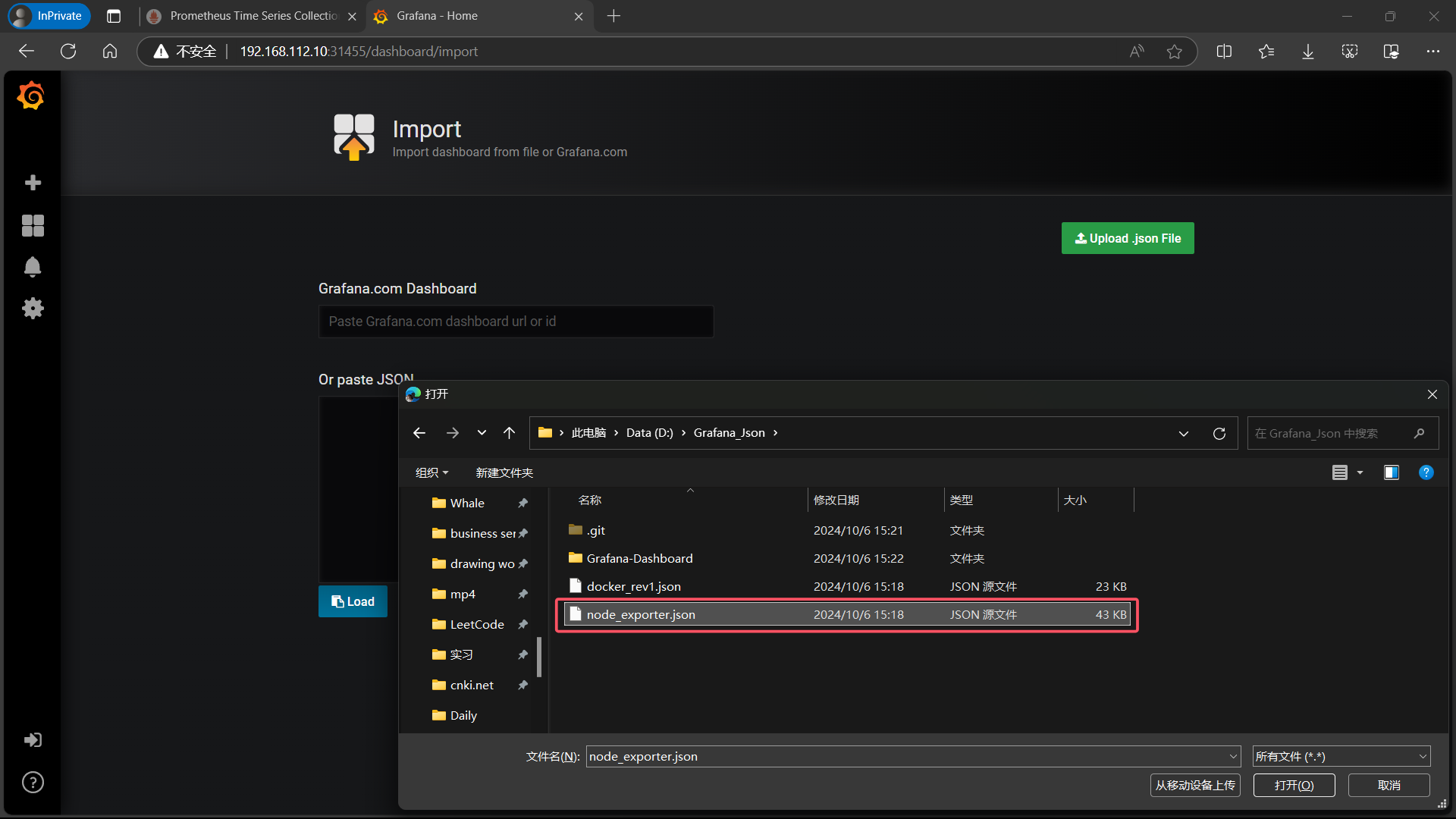
| 选择 Upload json file,选择一个本地的node_exporter.json 文件 |
 |
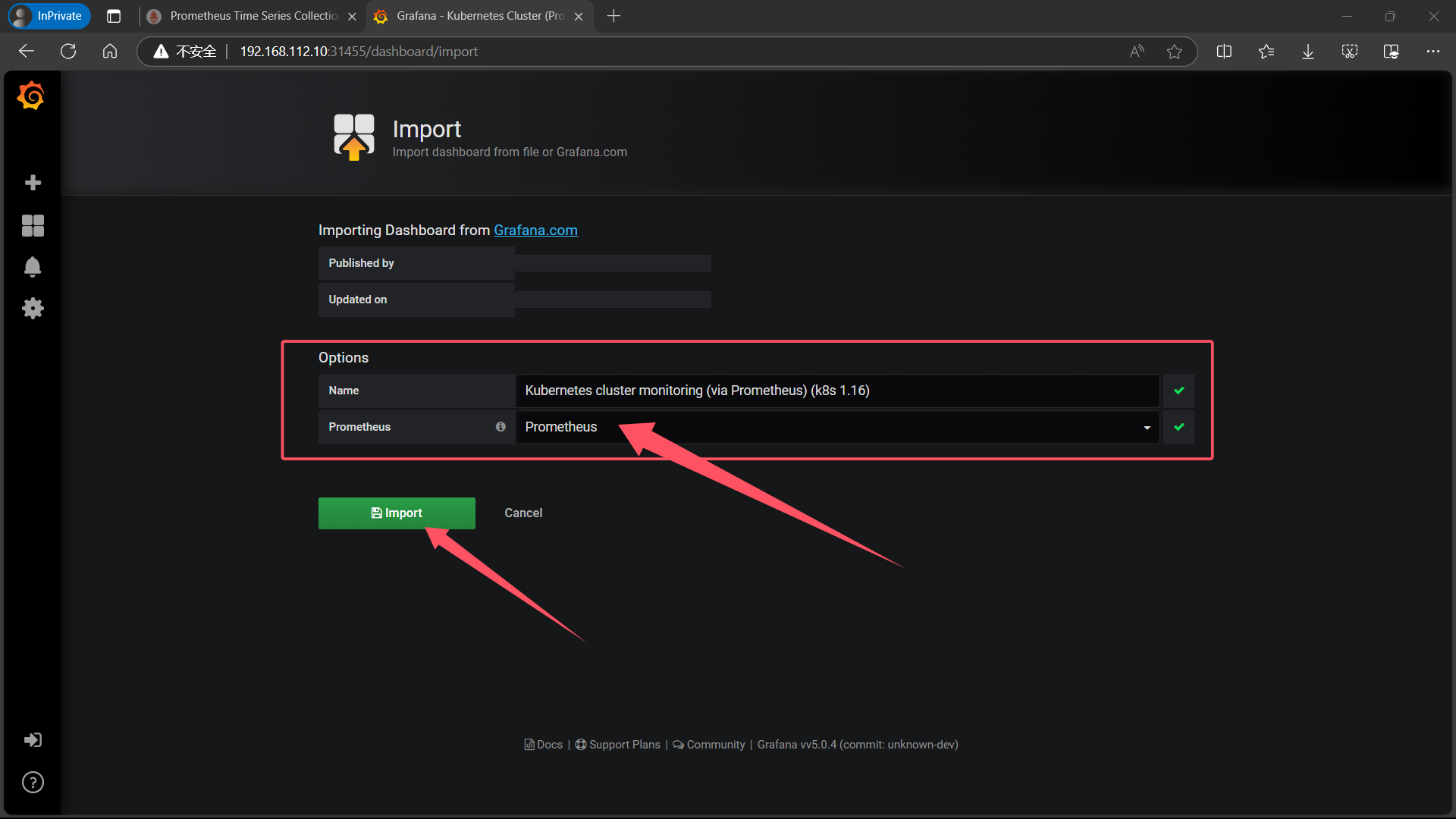
| 导入后 Options 选项中会出现 Name 是自动生成的,Prometheus 是需要我们选择 Prometheus的 |
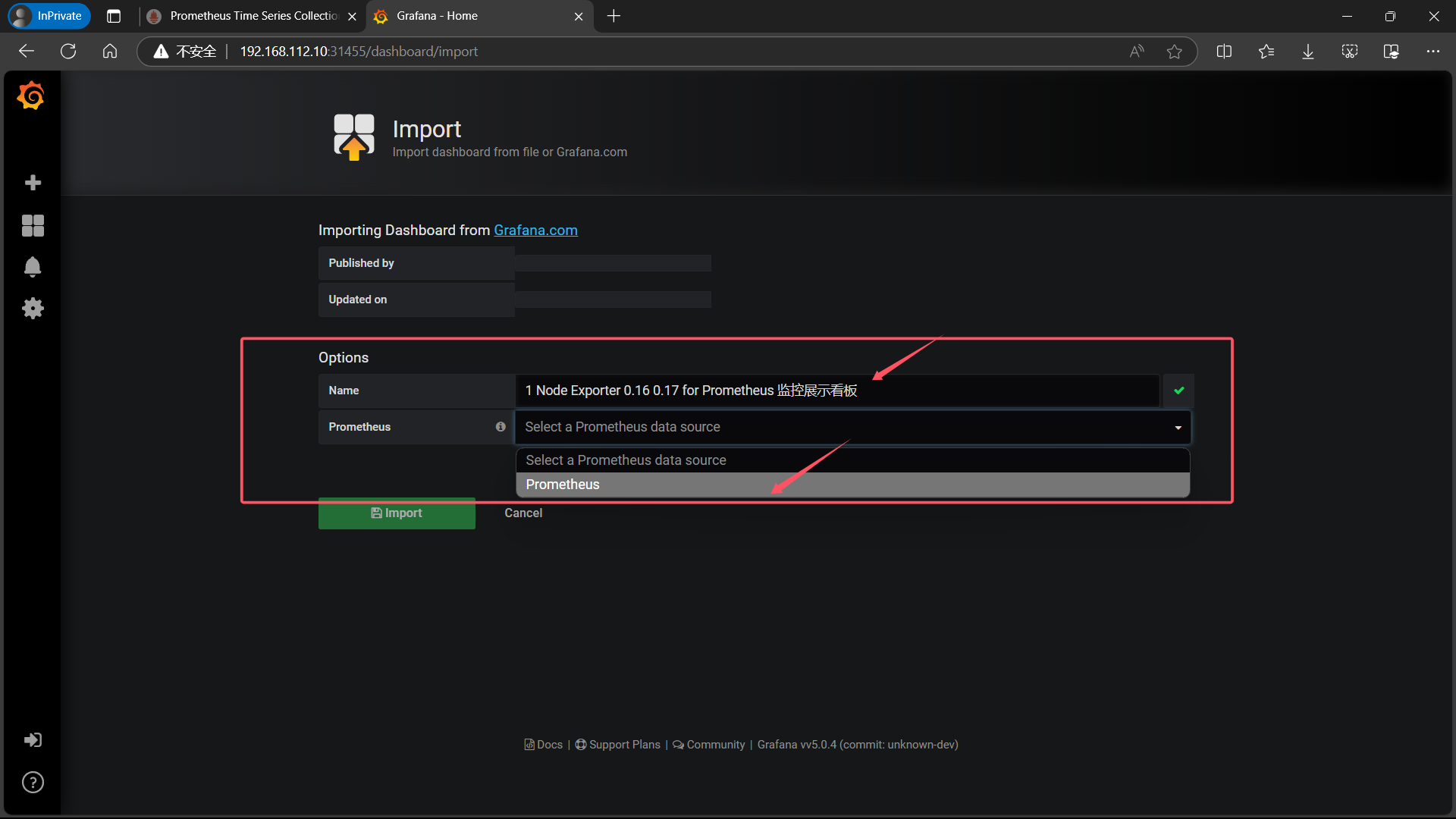 |
| 点击 Import 即可出现如下界面 |
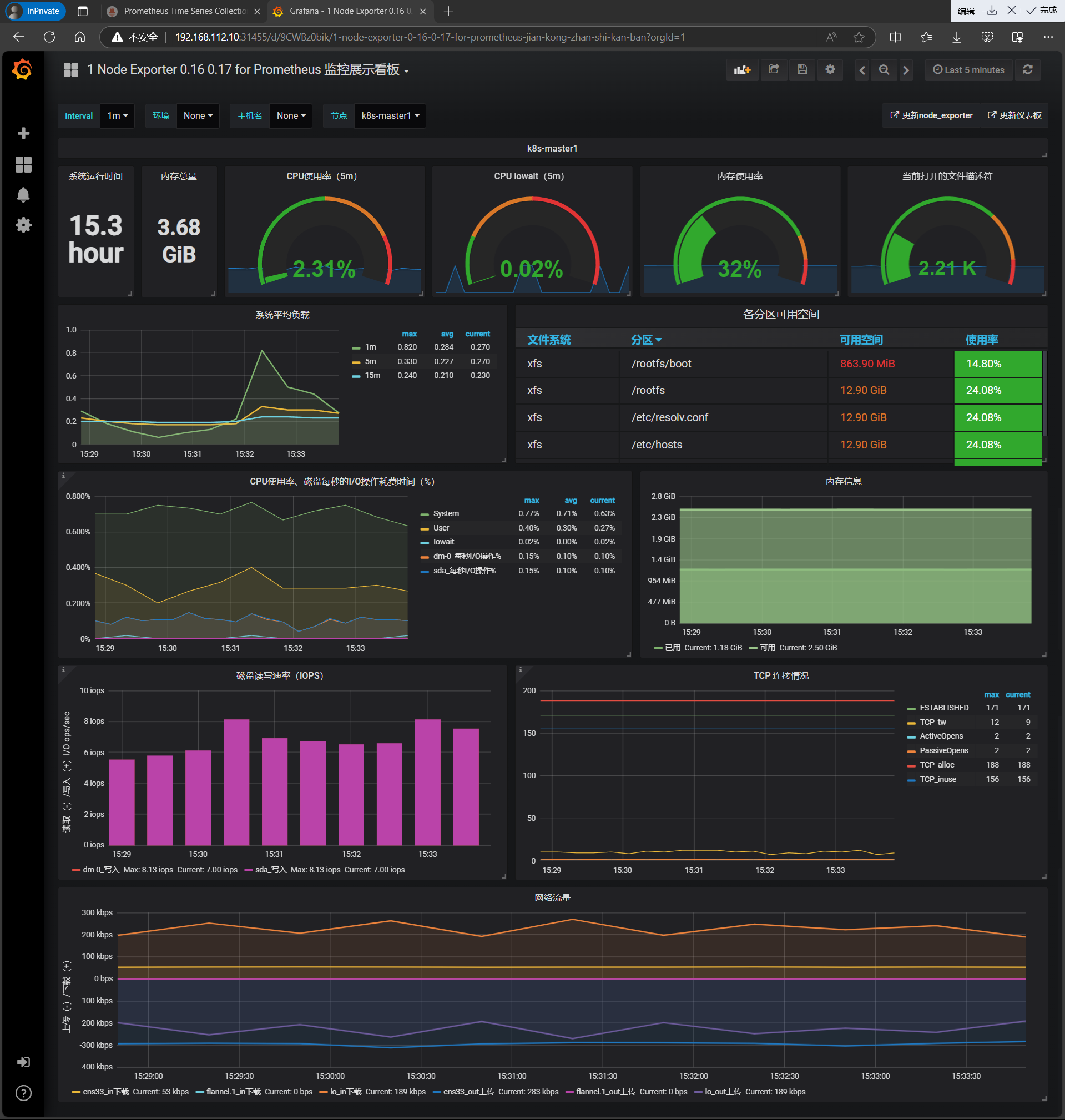 |
| 按照如上操作,导入docker_rev1.json监控模板 |
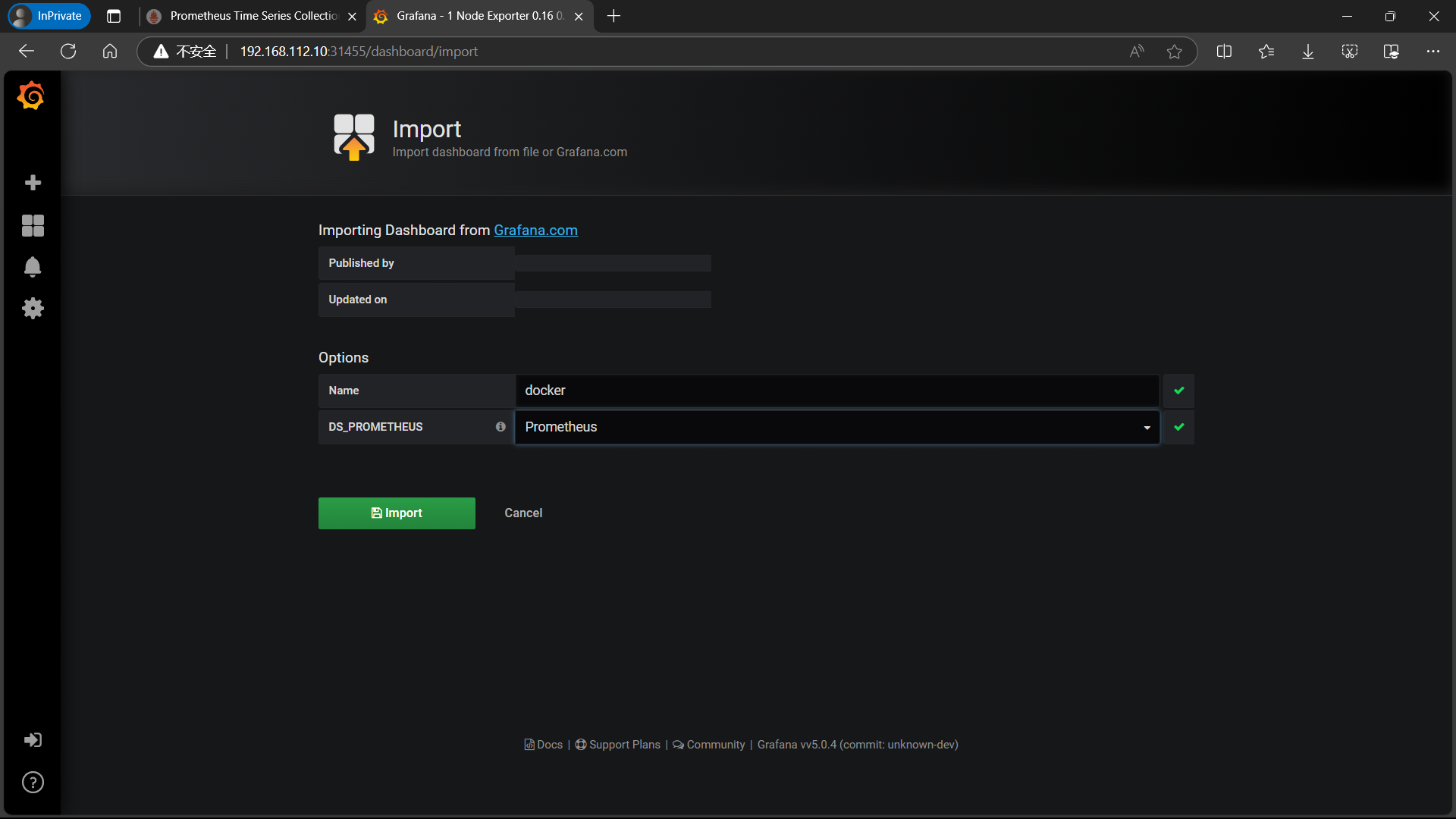 |
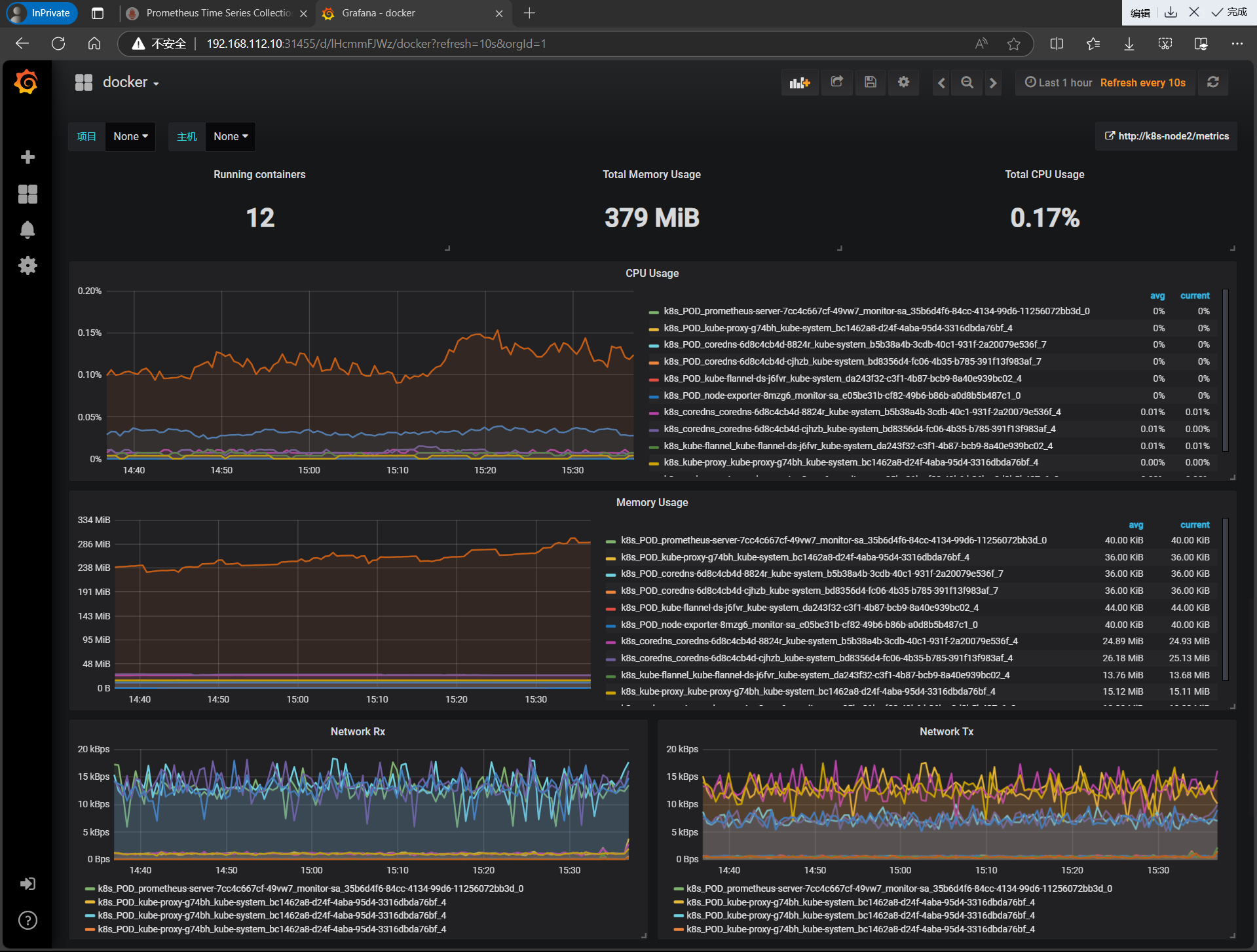 |
6、安装配置 kube-state-metrics 组件
6.1、什么是 kube-state-metrics
kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;调度了多少个replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?有多少job在运行中。
6.2、创建 sa ,并进行授权
k8s-master1 节点编写一个 kube-state-metrics-rbac.yaml 文件
cat >> kube-state-metrics-rbac.yaml << EOF
---
apiVersion: v1
kind: ServiceAccount
metadata:name: kube-state-metricsnamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: kube-state-metrics
rules:
- apiGroups: [""]resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]verbs: ["list", "watch"]
- apiGroups: ["extensions"]resources: ["daemonsets", "deployments", "replicasets"]verbs: ["list", "watch"]
- apiGroups: ["apps"]resources: ["statefulsets"]verbs: ["list", "watch"]
- apiGroups: ["batch"]resources: ["cronjobs", "jobs"]verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]resources: ["horizontalpodautoscalers"]verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: kube-state-metrics
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metrics
subjects:
- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
EOF
kubectl get sa,clusterrole,clusterrolebinding -n kube-system | grep kube-state-metrics

6.3、创建并应用 kube-state-metrics-deploy.yaml 文件
k8s-master1 节点操作
cat > kube-state-metrics-deploy.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: kube-state-metricsnamespace: kube-system
spec:replicas: 1selector:matchLabels:app: kube-state-metricstemplate:metadata:labels:app: kube-state-metricsspec:serviceAccountName: kube-state-metricscontainers:- name: kube-state-metrics
# image: gcr.io/google_containers/kube-state-metrics-amd64:v1.3.1image: quay.io/coreos/kube-state-metrics:latestports:- containerPort: 8080
EOF
kubectl apply -f kube-state-metrics-deploy.yamlkubectl get pods -n kube-system -l app=kube-state-metrics -w
拉取 kube-state-metrics 指定镜像版本失败时可以选择在集群各个节点上
docker pull quay.io/coreos/kube-state-metrics:latest
拉取最新 tag 版本

6.4、创建并应用 kube-state-metrics-svc.yaml 文件
k8s-master1 节点操作
cat >> kube-state-metrics-svc.yaml <<EOF
apiVersion: v1
kind: Service
metadata:annotations:prometheus.io/scrape: 'true'name: kube-state-metricsnamespace: kube-systemlabels:app: kube-state-metrics
spec:ports:- name: kube-state-metricsport: 8080protocol: TCPselector:app: kube-state-metrics
EOF
kubectl apply -f kube-state-metrics-svc.yamlkubectl get svc -n kube-system -l app=kube-state-metrics
6.5、获取 kube-state-metrics json 文件
git clone git@github.com:misakivv/Grafana-Dashboard.git
6.6、向 Grafana 导入 kube-state-metrics json 文件
| 点击左侧栏 + 号的 Import |
|---|
 |
| 点击 Upload .json File,上传 Kubernetes Cluster (Prometheus)-1577674936972.json |
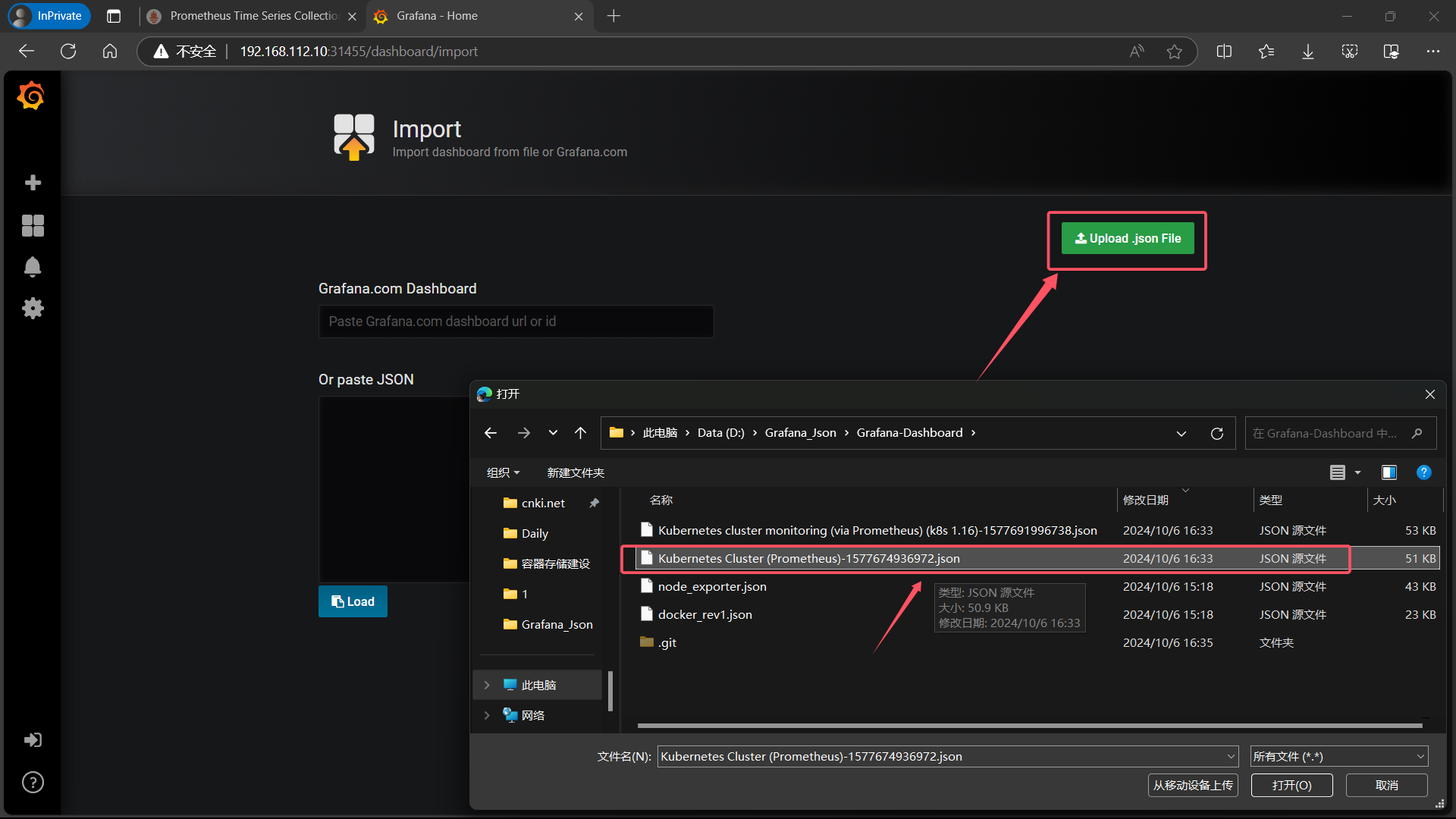 |
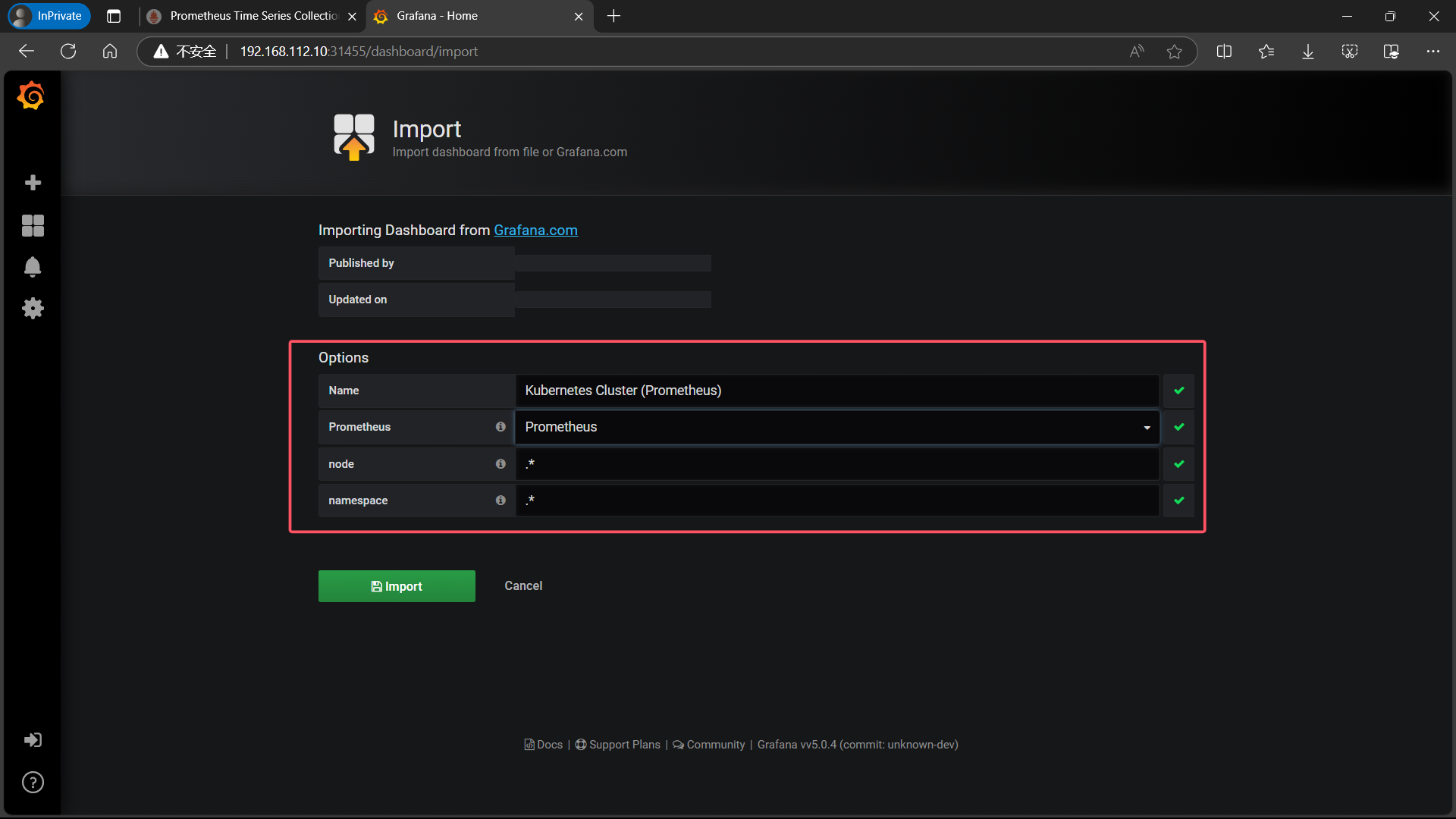 |
| 查看 |
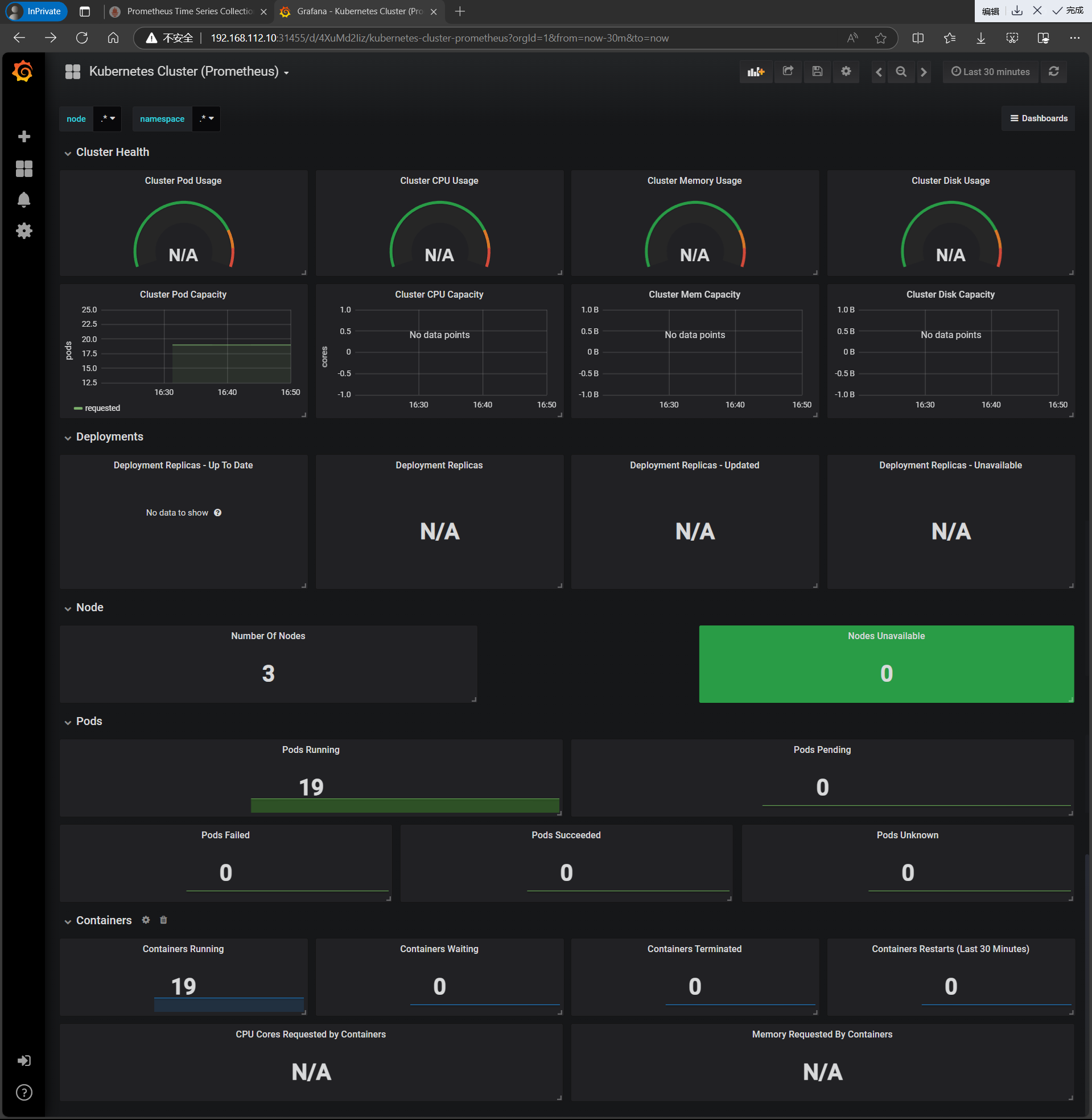 |
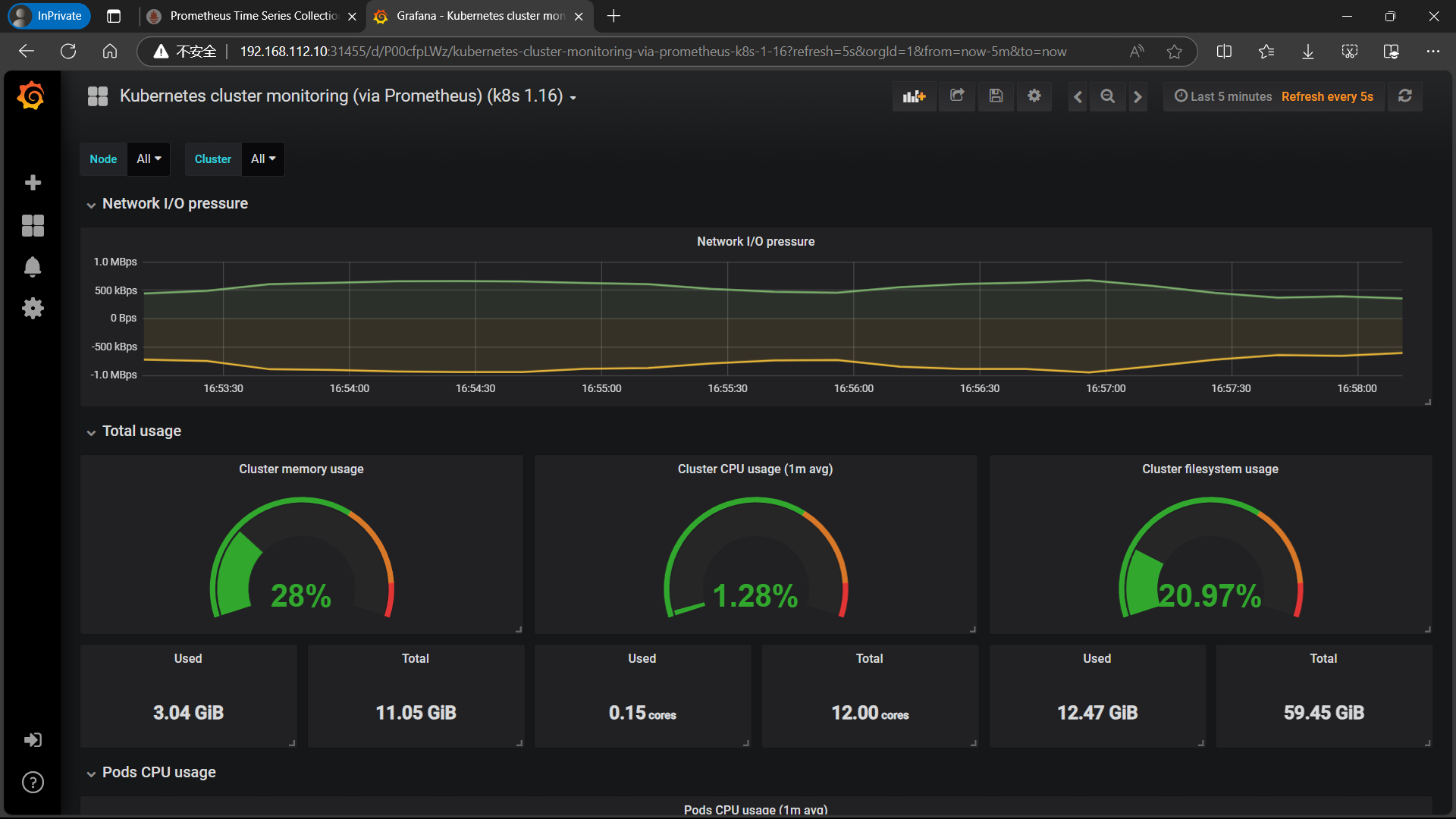
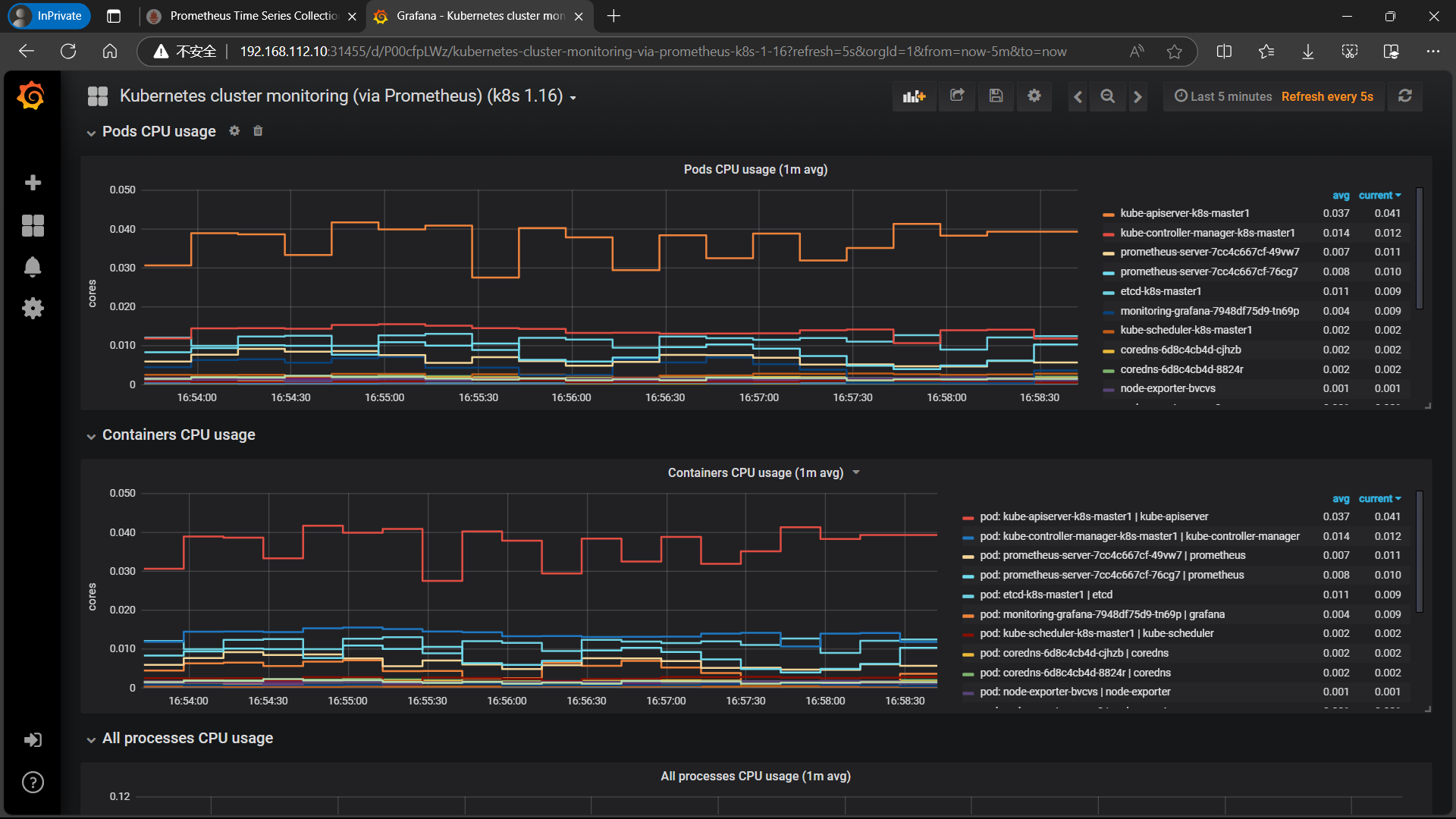
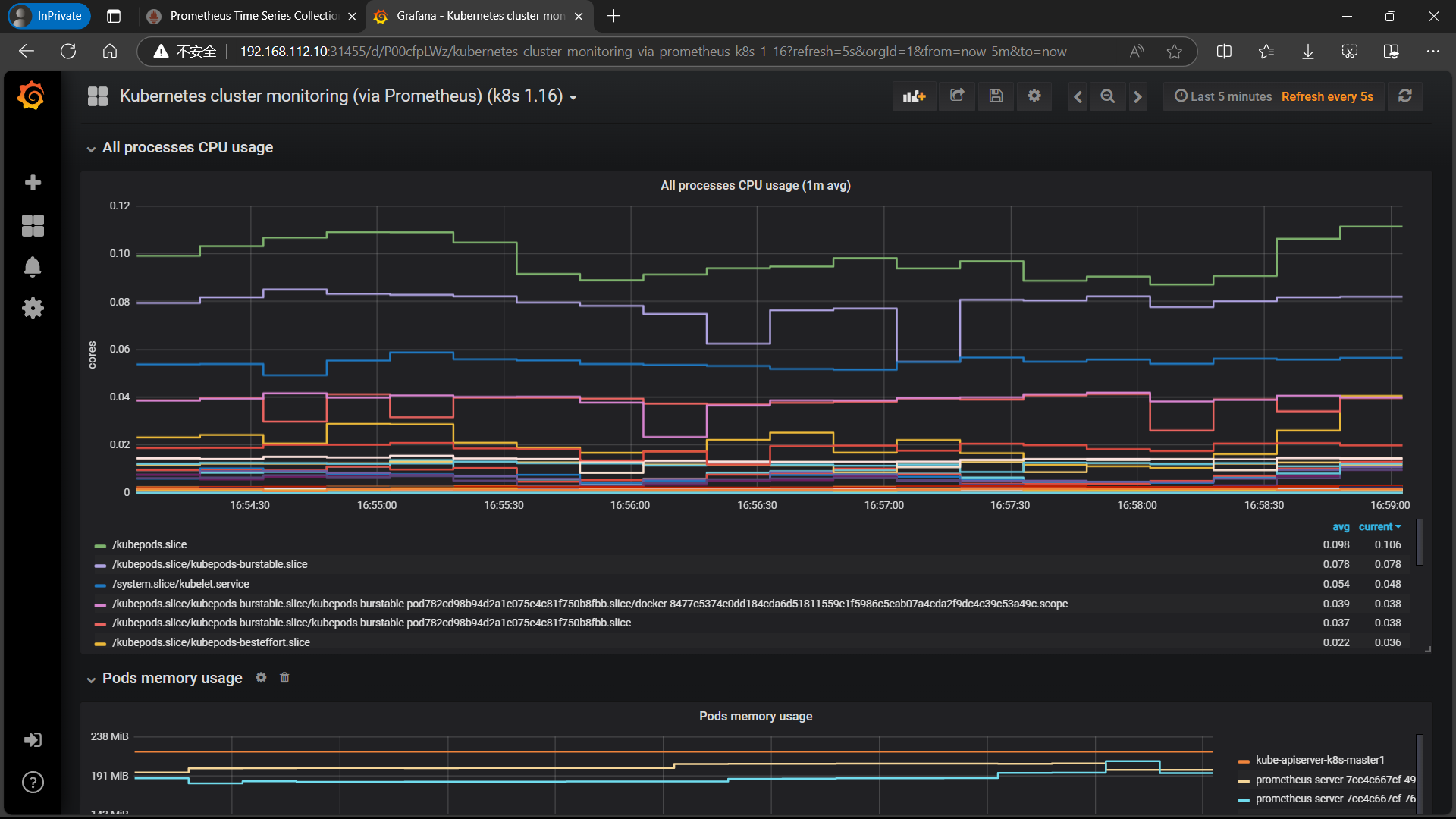
| **同样的导入 Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json ** |
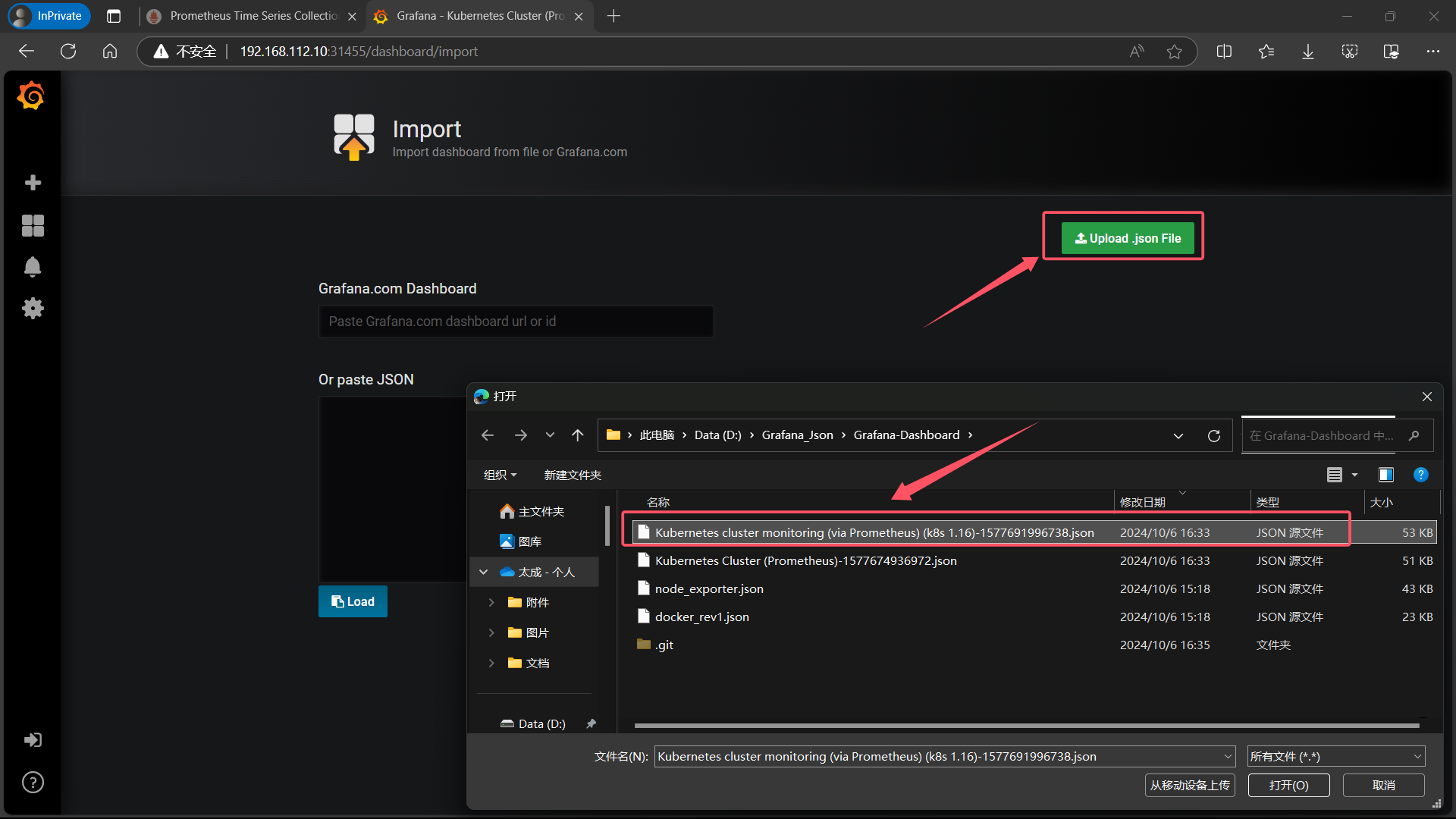 |
 |
 |
 |
 |
 |
 |
 |
 |
三、安装和配置 Alertmanager – 发送告警到 QQ 邮箱
1、将 alertmanager-cm.yaml 文件以 cm 形式进行管理
k8s-master1 节点操作
cat >> alertmanager-cm.yaml << EOF
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |-global:resolve_timeout: 1msmtp_smarthost: 'smtp.qq.com:465'smtp_from: '2830909671@qq.com'smtp_auth_username: '2830909671@qq.com'smtp_auth_password: 'ajjgpgwwfkpcdgih'smtp_require_tls: falseroute:group_by: [alertname]group_wait: 5sgroup_interval: 5srepeat_interval: 5mreceiver: default-receiverreceivers:- name: 'default-receiver'email_configs:- to: 'misakikk@qq.com'send_resolved: true
EOF
kubectl apply -f alertmanager-cm.yamlkubectl get cm alertmanager -n monitor-sa

1.1、alertmanager配置文件说明
smtp_smarthost: 'smtp.qq.com:465'
#用于发送邮件的邮箱的SMTP服务器地址+端口。QQ 邮箱 SMTP 服务地址,官方地址为 smtp.qq.com 端口为 465 或 587,同时要设置开启 POP3/SMTP 服务。
smtp_from: '2830909671@qq.com'
#这是指定从哪个邮箱发送报警
smtp_auth_password: 'ajjgpgwwfkpcdgih'
#这是发送邮箱的授权码而不是登录密码
email_configs:- to: 'misakikk@qq.com'
#to后面指定发送到哪个邮箱
2、重新生成并应用 prometheus-cfg.yaml 文件
k8s-master1 节点操作
cat > prometheus-cfg.yaml << 'EOF'
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |rule_files:- /etc/prometheus/rules.ymlalerting:alertmanagers:- static_configs:- targets: ["localhost:9093"]global:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: '/api/v1/nodes/${1}/proxy/metrics/cadvisor'- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: '$1:$2'- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: '$1:$2'source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-schedule'scrape_interval: 5sstatic_configs:- targets: ['192.168.112.10:10259']- job_name: 'kubernetes-controller-manager'scrape_interval: 5sstatic_configs:- targets: ['192.168.112.10:10257']- job_name: 'kubernetes-kube-proxy'scrape_interval: 5sstatic_configs:- targets: ['192.168.112.10:10249','192.168.112.20:10249','192.168.112.30:10249']- job_name: 'kubernetes-etcd'scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['192.168.112.10:2381']rules.yml: |groups:- name: examplerules:- alert: kube-proxy的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: kube-proxy的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: scheduler的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: scheduler的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: controller-manager的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: controller-manager的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
EOF
注意:
除了
kube-proxy默认在每个节点的10249端口上暴露其指标其余的
kubernetes-schedule、kubernetes-controller-manager、kubernetes-etcd这些组件Pod 的容器需要根据自己的 k8s 集群情况进行修改
kubectl apply -f prometheus-cfg.yamlkubectl get cm prometheus-config -n monitor-sa -o yaml
同样的还是需要检查 cm 文件中是否正确解析了 $1 $2
3、重新生成 prometheus-deploy.yaml 文件
k8s-master1 节点操作
cat > prometheus-deploy.yaml << EOF
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 2selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- prometheus- key: componentoperator: Invalues:- servertopologyKey: kubernetes.io/hostnameserviceAccountName: monitorcontainers:- name: prometheusimage: quay.io/prometheus/prometheus:latestimagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: alertmanagerimage: prom/alertmanager:latestimagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai
EOF
3.1、创建一个名为 etcd-certs 的 Secret
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt

3.2、应用 prometheus-deploy.yaml 文件
kubectl apply -f prometheus-deploy.yamlkubectl get pods -n monitor-sa

4、重新生成并创建 alertmanager-svc.yaml 文件
cat >alertmanager-svc.yaml <<EOF
---
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: monitor-sa
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
EOF
kubectl apply -f alertmanager-svc.yamlkubectl get svc alertmanager -n monitor-sa

5、访问 prometheus UI 界面
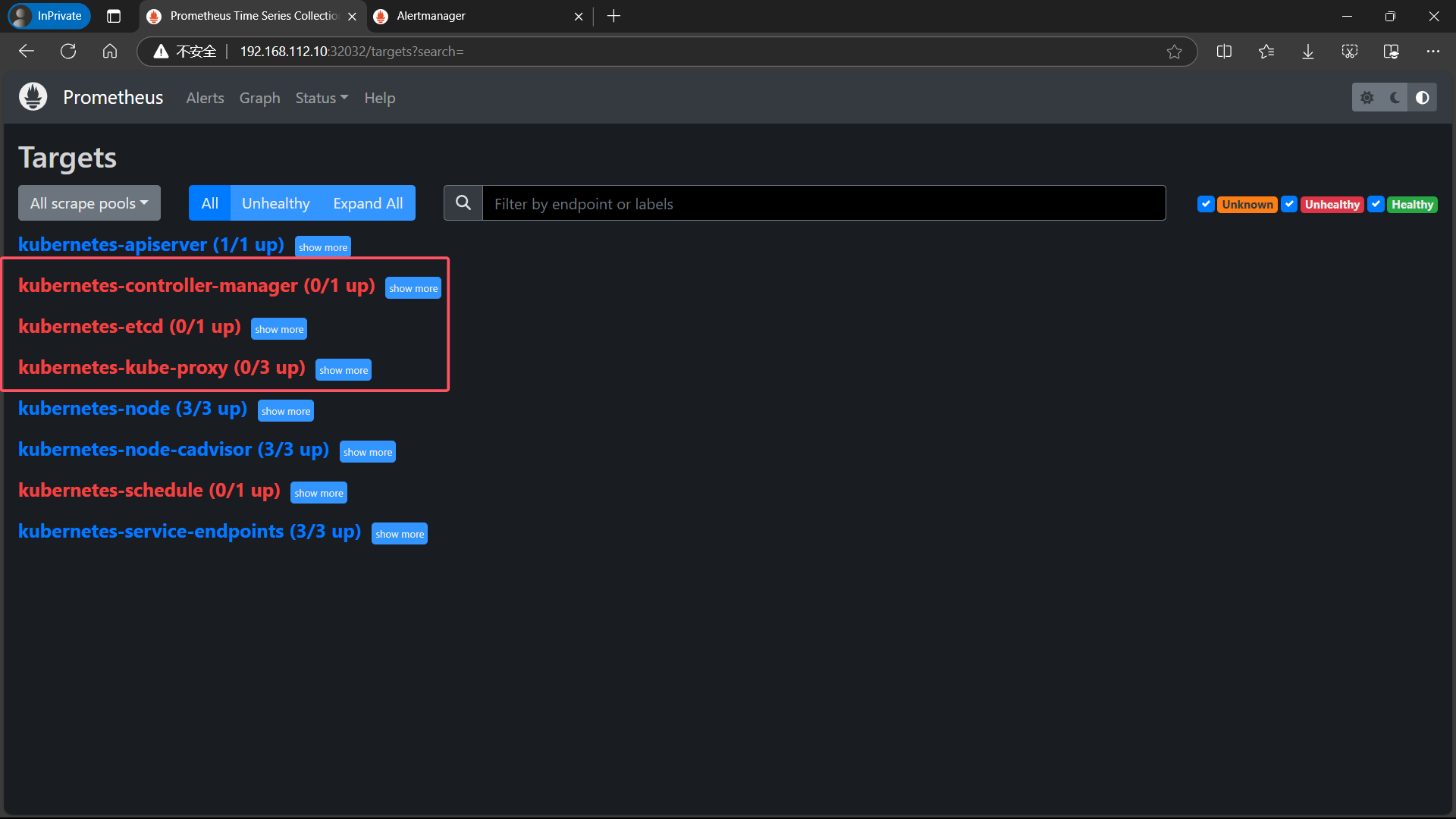
5.1、【error】kube-controller-manager、etcd、kube-proxy、kube-scheduler 组件 connection refused
5.1.1、kube-proxy
默认情况下,该服务监听端口只提供给127.0.0.1,需修改为0.0.0.0
kubectl edit cm/kube-proxy -n kube-system
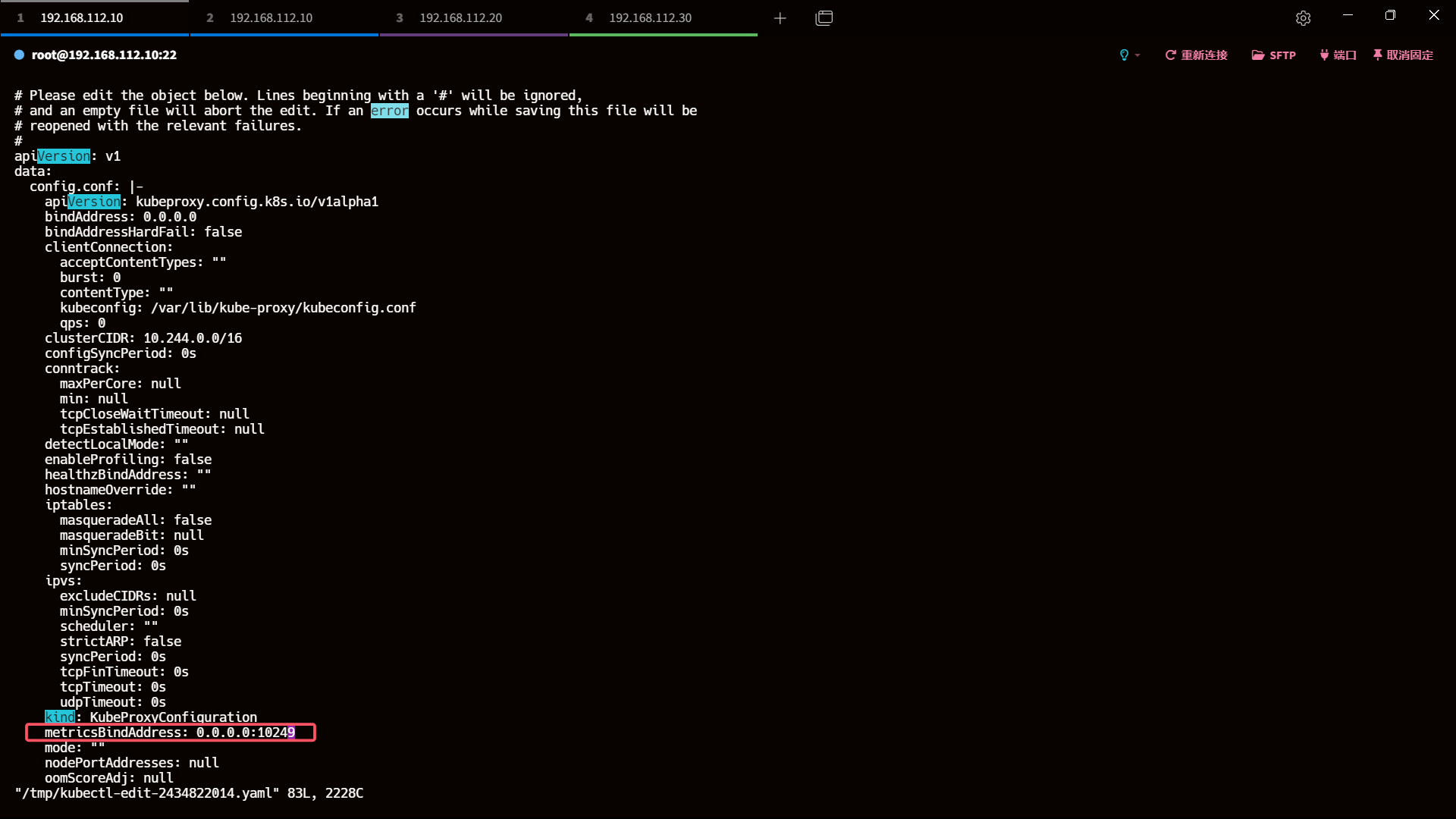
- 编辑文件,将文件修改允许0.0.0.0即可,保存
metricsBindAddress: 0.0.0.0:10249
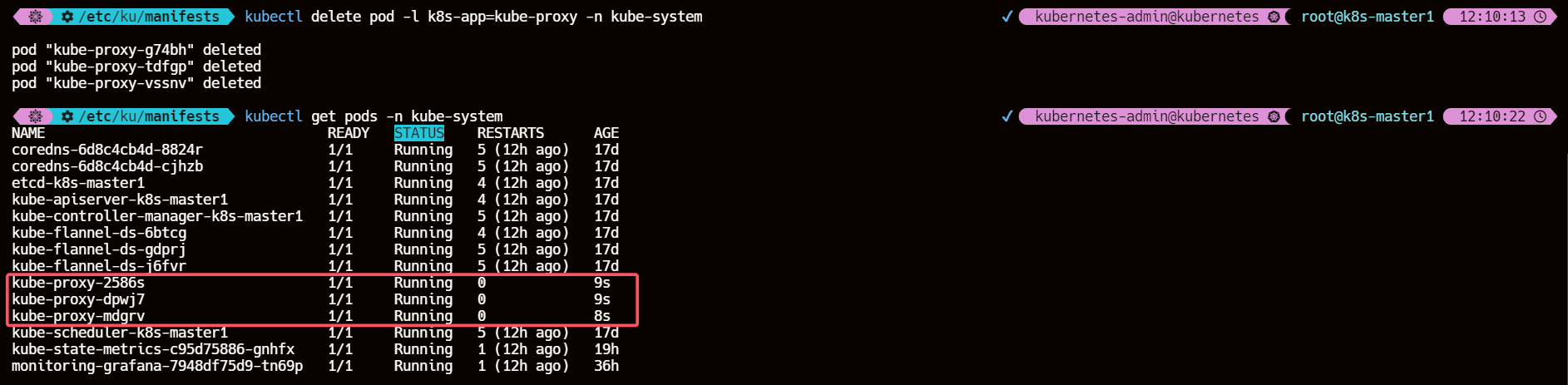
- 删除重建 kube-proxy 的 pod
kubectl delete pod -l k8s-app=kube-proxy -n kube-system
- 效果

5.1.2、kube-controller-manager
事先说明:到这一步我试过网上很多方法都没有成功获取到数据,所以我重新创建了 sa 慎用,仅供参考
- 修改 kube-controller-manager 的 yaml 文件
默认监听本地修改为 0.0.0.0
- --bind-address=127.0.0.1
# 修改为
- --bind-address=0.0.0.0
- 创建ServiceAccount
创建一个新的ServiceAccount,用于Prometheus访问 kube-controller-manager。
cat > prom-sa << EOF
apiVersion: v1
kind: ServiceAccount
metadata:name: prometheus-sanamespace: monitor-sa
EOF
- 创建ClusterRole
创建一个ClusterRole,定义Prometheus所需的权限。
cat > porm-role << EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: prometheus-role
rules:
- nonResourceURLs:- "/metrics"verbs:- get
EOF
- 创建ClusterRoleBinding
将ServiceAccount绑定到ClusterRole。
cat > prom-bind.yaml << EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: prometheus-binding
subjects:
- kind: ServiceAccountname: prometheus-sanamespace: monitor-sa
roleRef:kind: ClusterRolename: prometheus-roleapiGroup: rbac.authorization.k8s.io
EOF
- 获取ServiceAccount的Token
获取ServiceAccount的Token,以便在Prometheus配置中使用。
TOKEN=$(kubectl get secret $(kubectl get sa prometheus-sa -n monitor-sa -o json | jq -r '.secrets[].name') -n monitor-sa -o json | jq -r '.data.token' | base64 --decode)
- 修改Prometheus配置文件(cm)
- job_name: 'kubernetes-controller-manager'scheme: httpstls_config:insecure_skip_verify: true # 禁用证书验证authorization:credentials: eyJhbGciOiJSUzI1NiIsImtpZCI6IkFEWVNqaWlueWVDMzBUcTZvQk9MRkpxQ0diLWRGWkNoaWlpZkgwR21NcEkifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtb25pdG9yLXNhIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtc2EtdG9rZW4tbnQ5bm4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cy1zYSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjQ4YTA5NDExLTAwMmYtNDE0Ni05YzY4LTBiNmVjOWYzYWZlZCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDptb25pdG9yLXNhOnByb21ldGhldXMtc2EifQ.DNgCjTVxsrGDltvQZG-x7qPQrh369SO_e0faGrrhjgkBLS4q2sh85wkaBNNZcIjxZcVk7ZU9gQmQkM3AIgGIcIURpQGDMgVVI_xF1JV8iQWe-nL1yHnQAXDjyMAd1826wVvMH8LSKqdKfPVaMHN8t0LScX5yHonSJUqoevxi7Mm7tiUd33IlMQ6xH6M8Tu8bsg-fOVmL6nnGpC1tPgaZy8M_GA_Kh9j8SwHXi4Yd9r75eOSa3J6N4KF6n-EPKxnGmXDooA60G94YptsDFCQMi1t4TLAFR1FKraycWHwPbIwviUZTvA1WXbkiHnh0R6q-y0hHJVbAi_ZXagVXKZFBaw # 替换为实际的Token值scrape_interval: 5sstatic_configs:- targets: ['192.168.112.10:10257']
- 重启Prometheus
更新配置后,重启Prometheus以应用新的配置。
kubectl rollout restart deployment/prometheus-server -n monitor-sa
- 效果
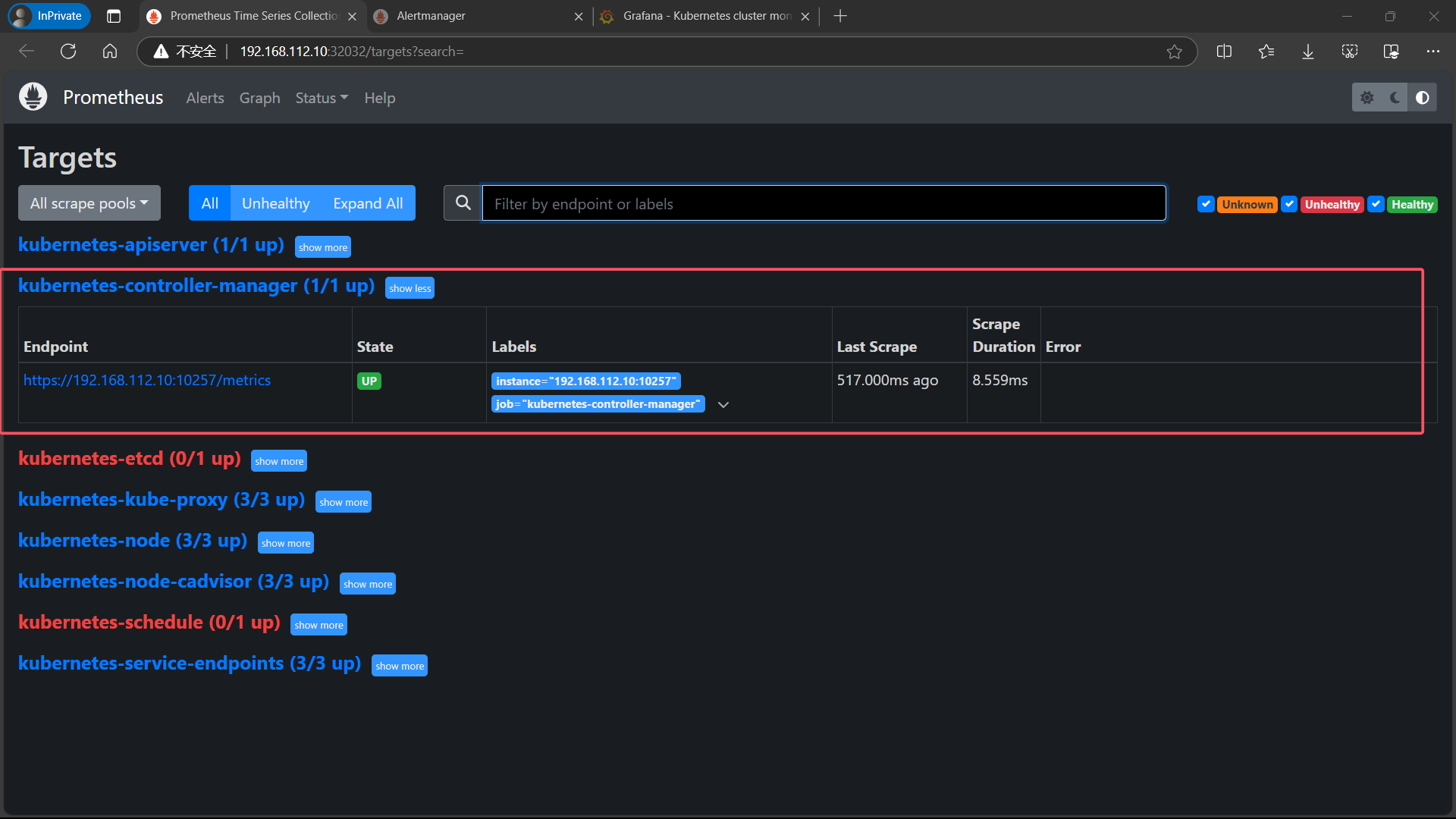
5.1.3、kube-schedule
和 kube-controller-manager 操作一致
- 效果
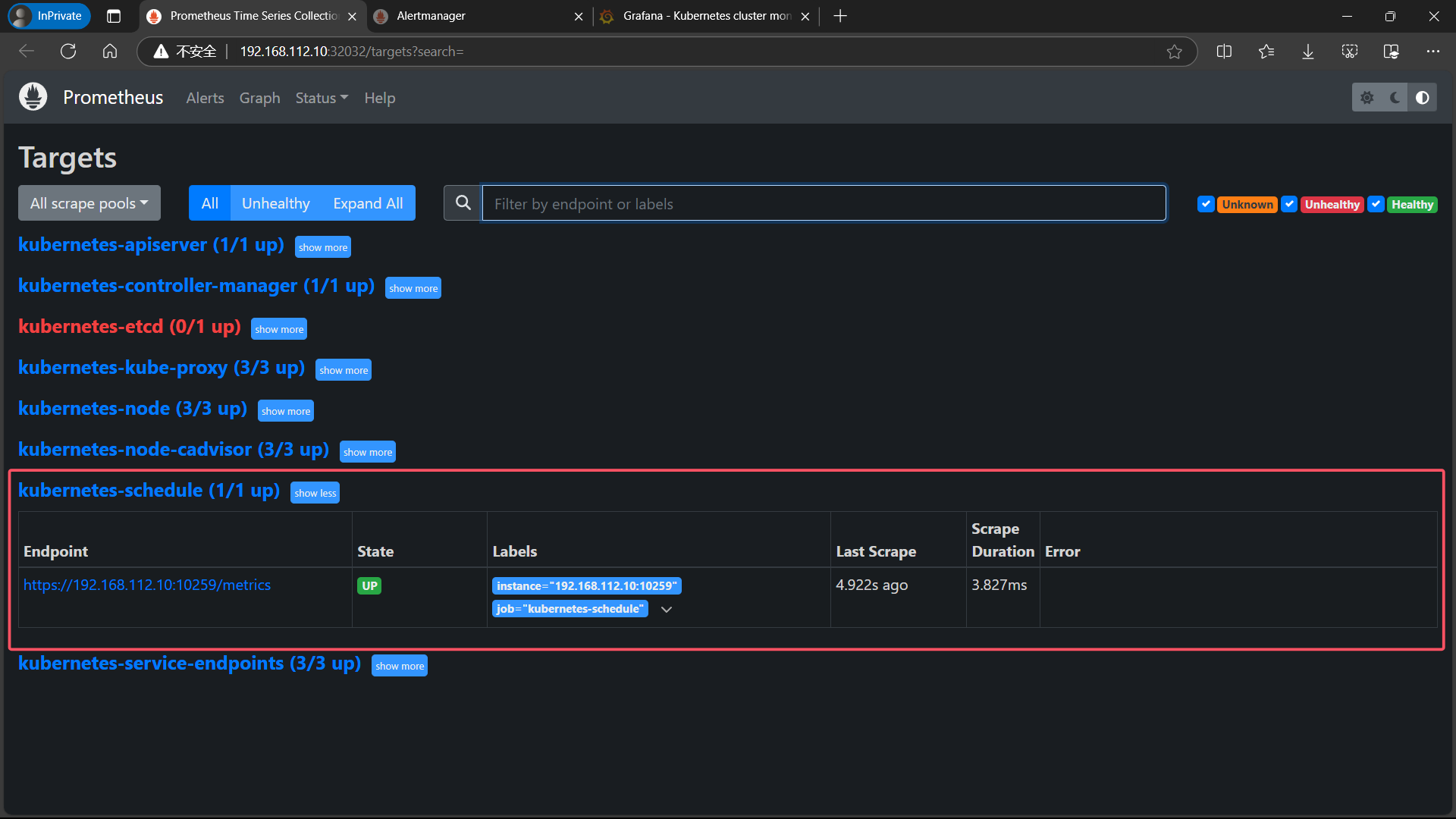
5.1.4、etcd
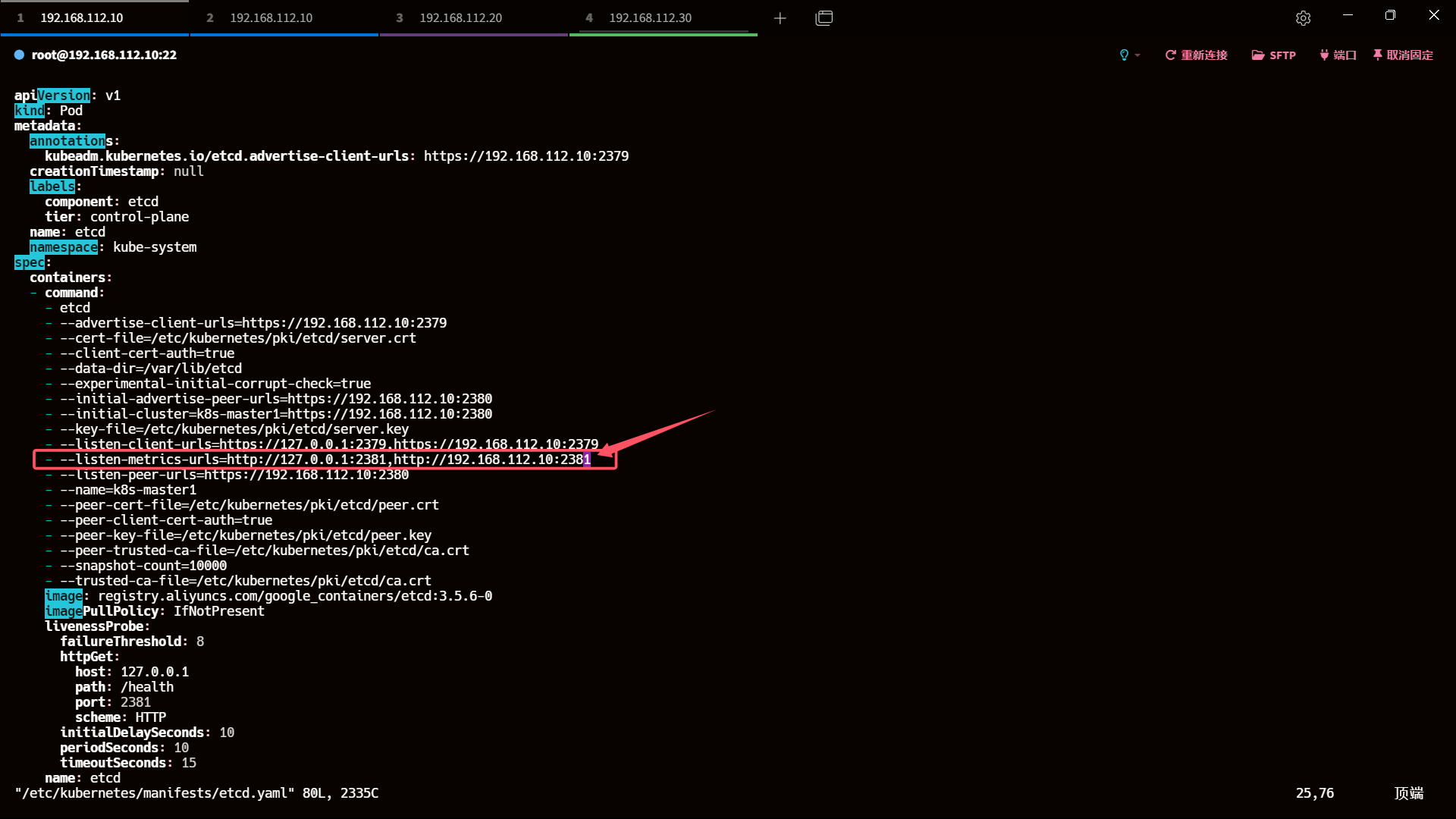
- 修改创建 etcd 的 yaml 文件
添加 master 节点 ip + etcd port
vim /etc/kubernetes/manifests/etcd.yaml- --listen-metrics-urls=http://127.0.0.1:2381,http://192.168.112.10:2381
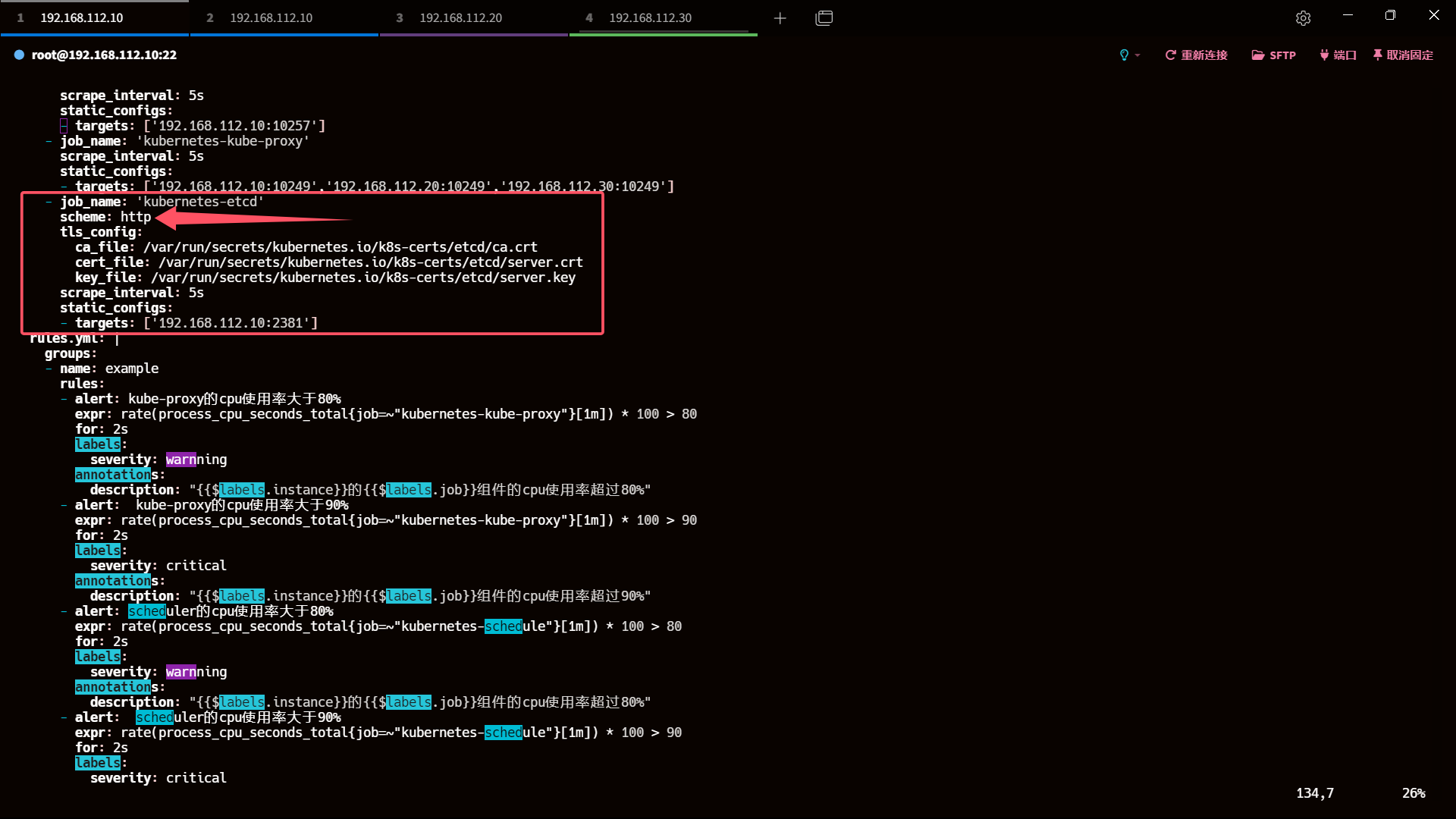
- 修改 prometheus.yaml 文件
改为 http
- 效果
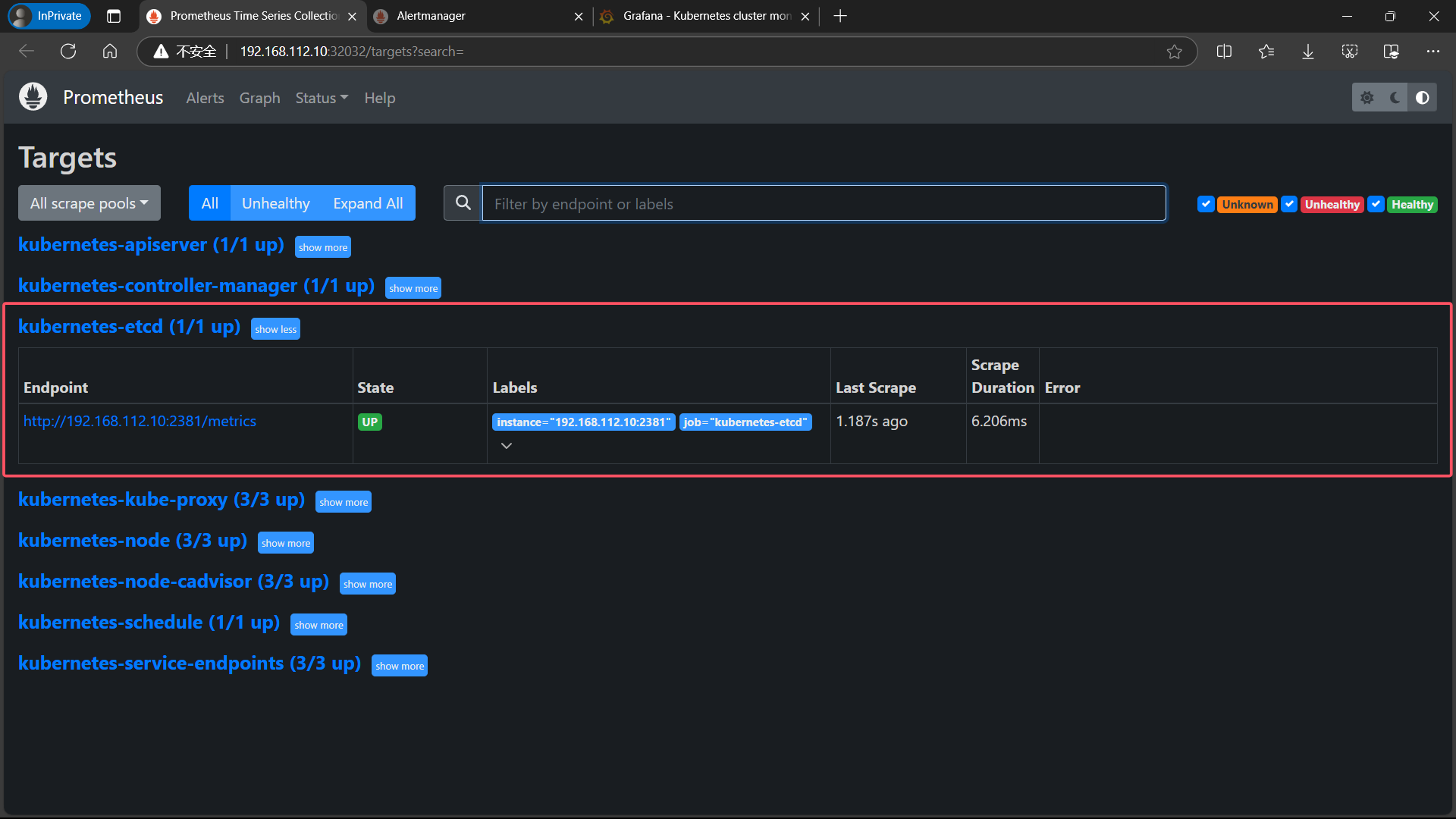
6、点击Alerts,查看

7、把controller-manager的cpu使用率大于90%展开
FIRING表示prometheus已经将告警发给alertmanager
在Alertmanager 中可以看到有 alert。
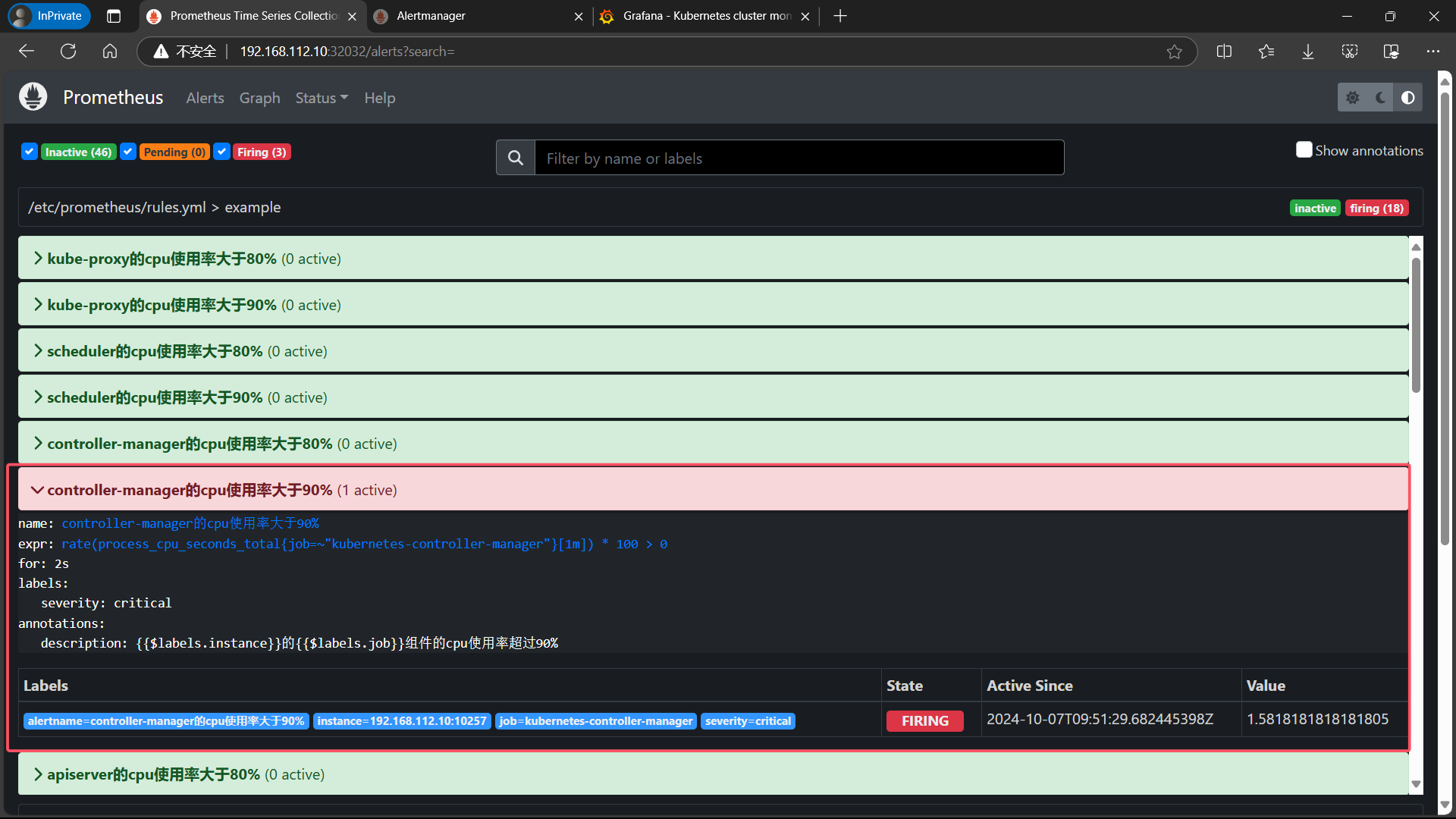
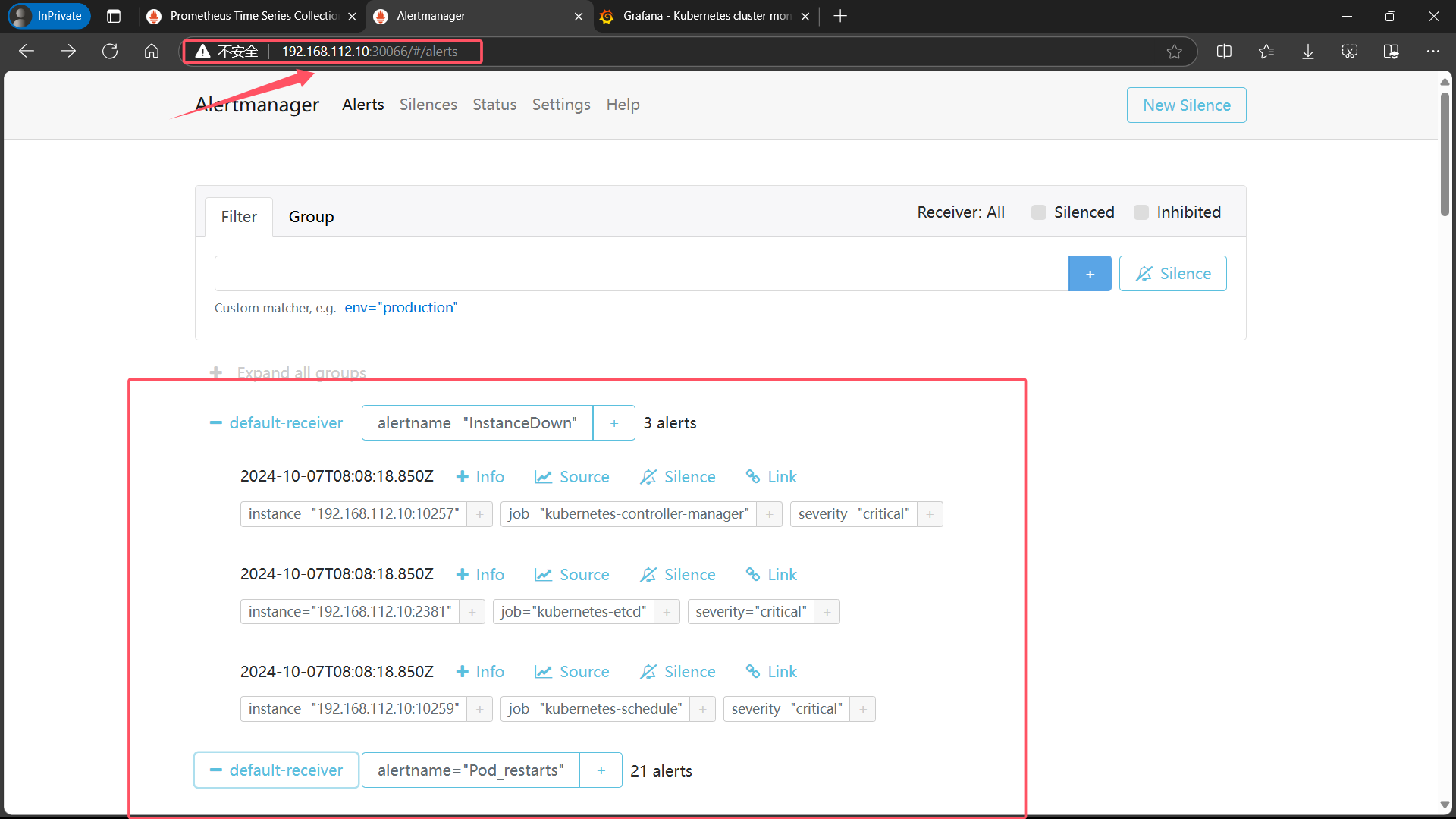
8、登录 alertmanager UI
<master-ip>:svc-alertmanager-port192.168.112.10:30066

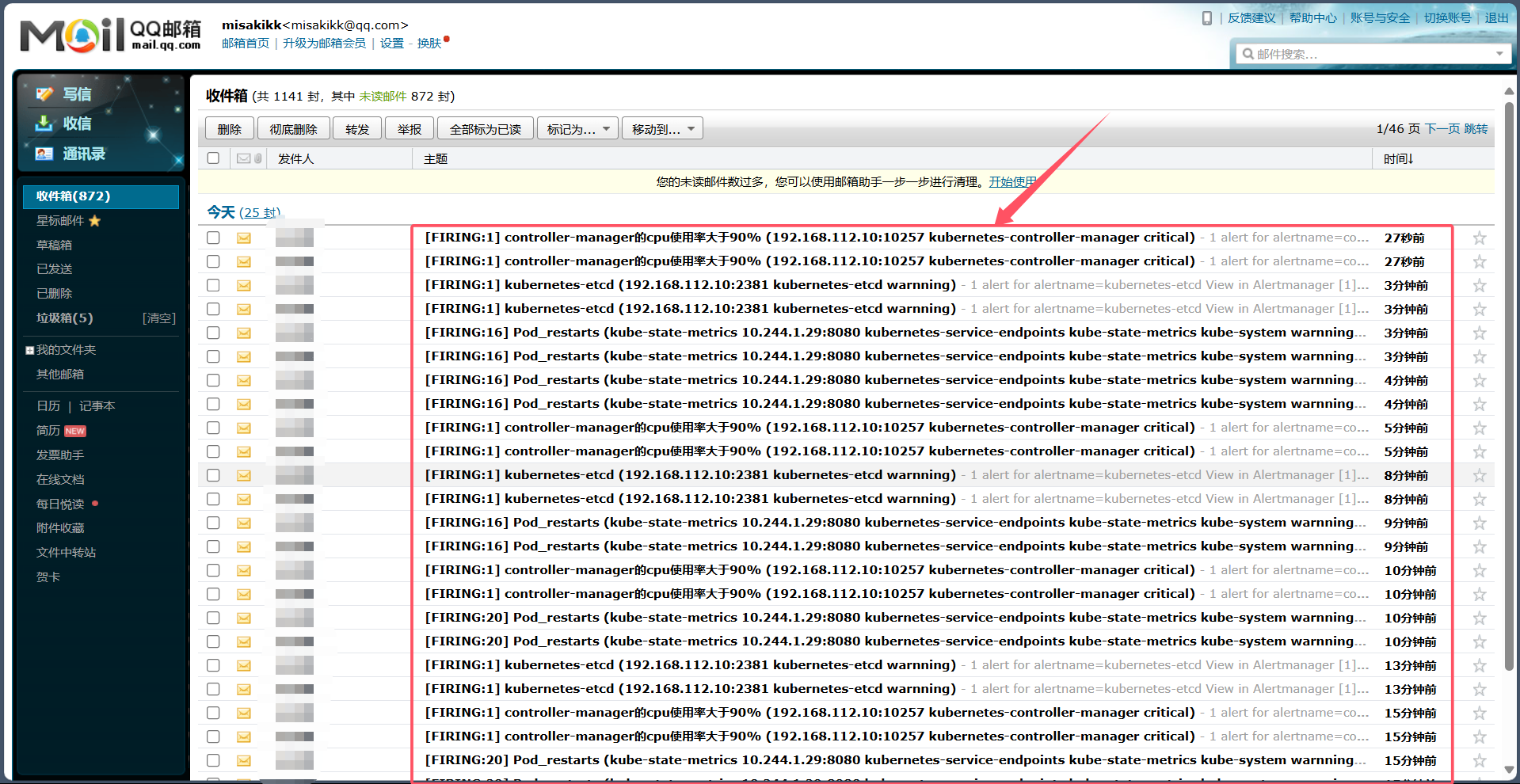
9、登录 QQ 邮箱查看告警信息
四、配置 Alertmanager 报警 – 发送告警到钉钉
1、手机端拉群
因为 PC 端不好操作
2、创建自定义机器人
自定义机器人安全设置 - 钉钉开放平台 (dingtalk.com)
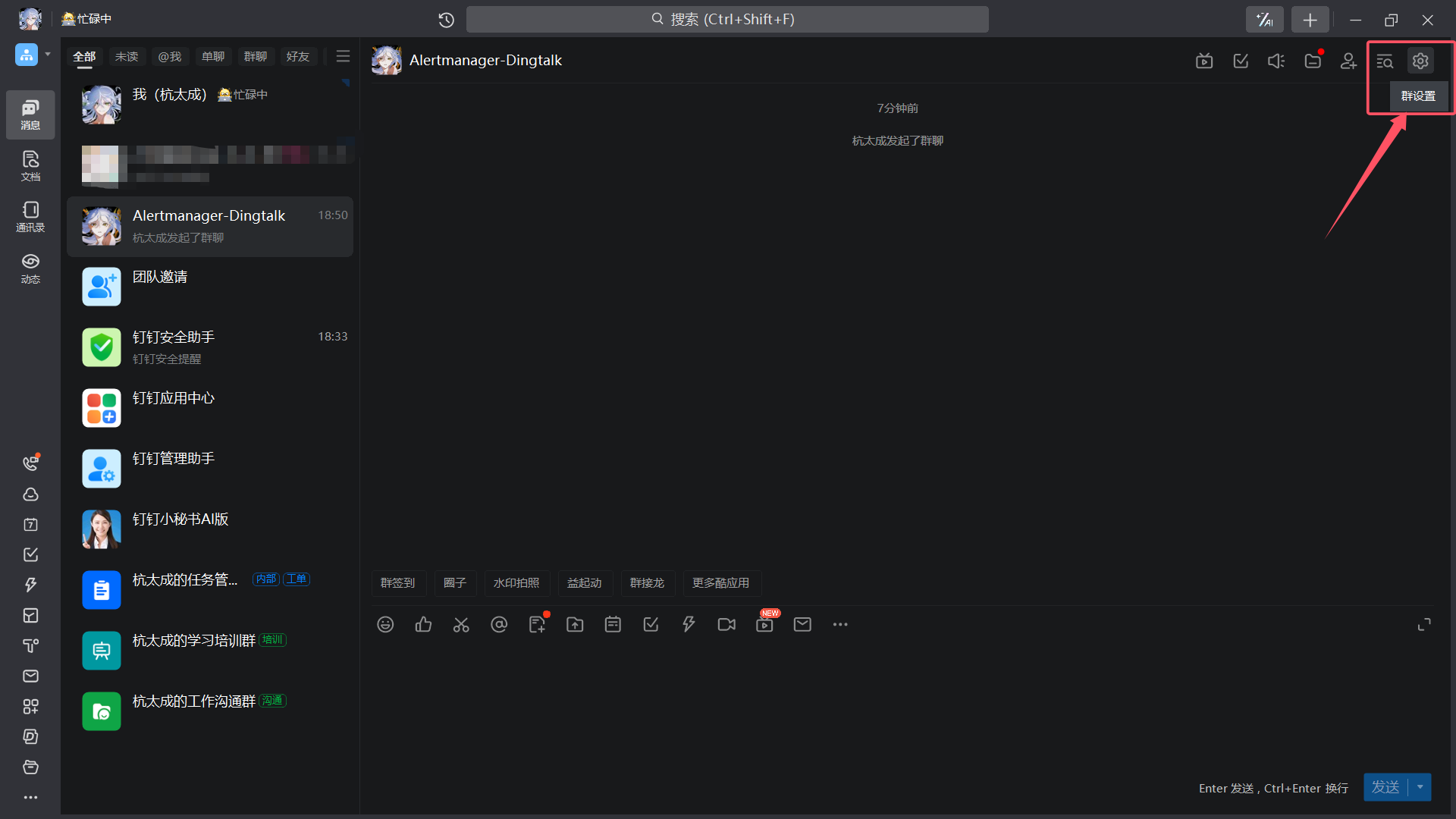
| 群设置 |
|---|
 |
| 机器人 |
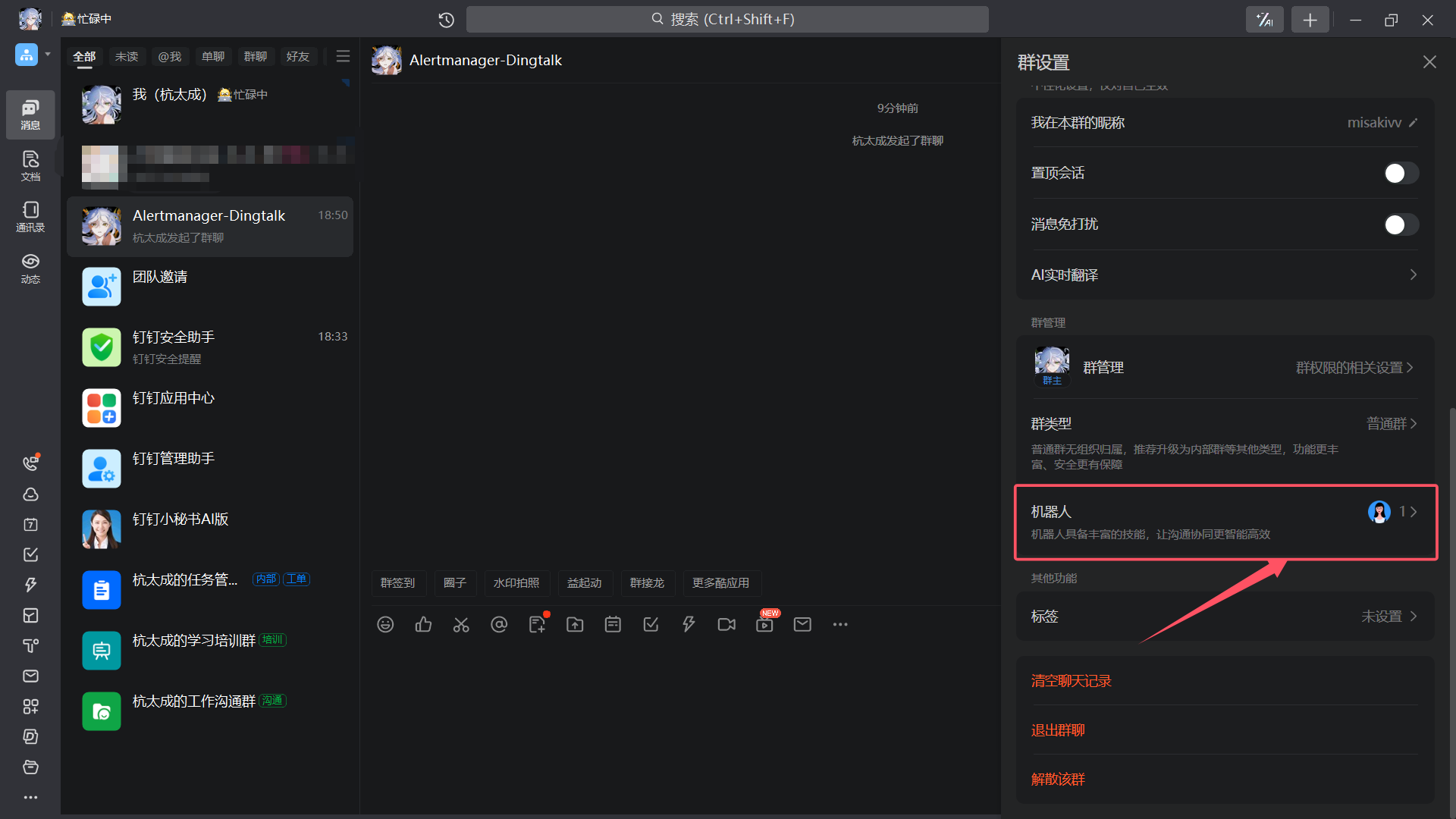 |
| 添加机器人 |
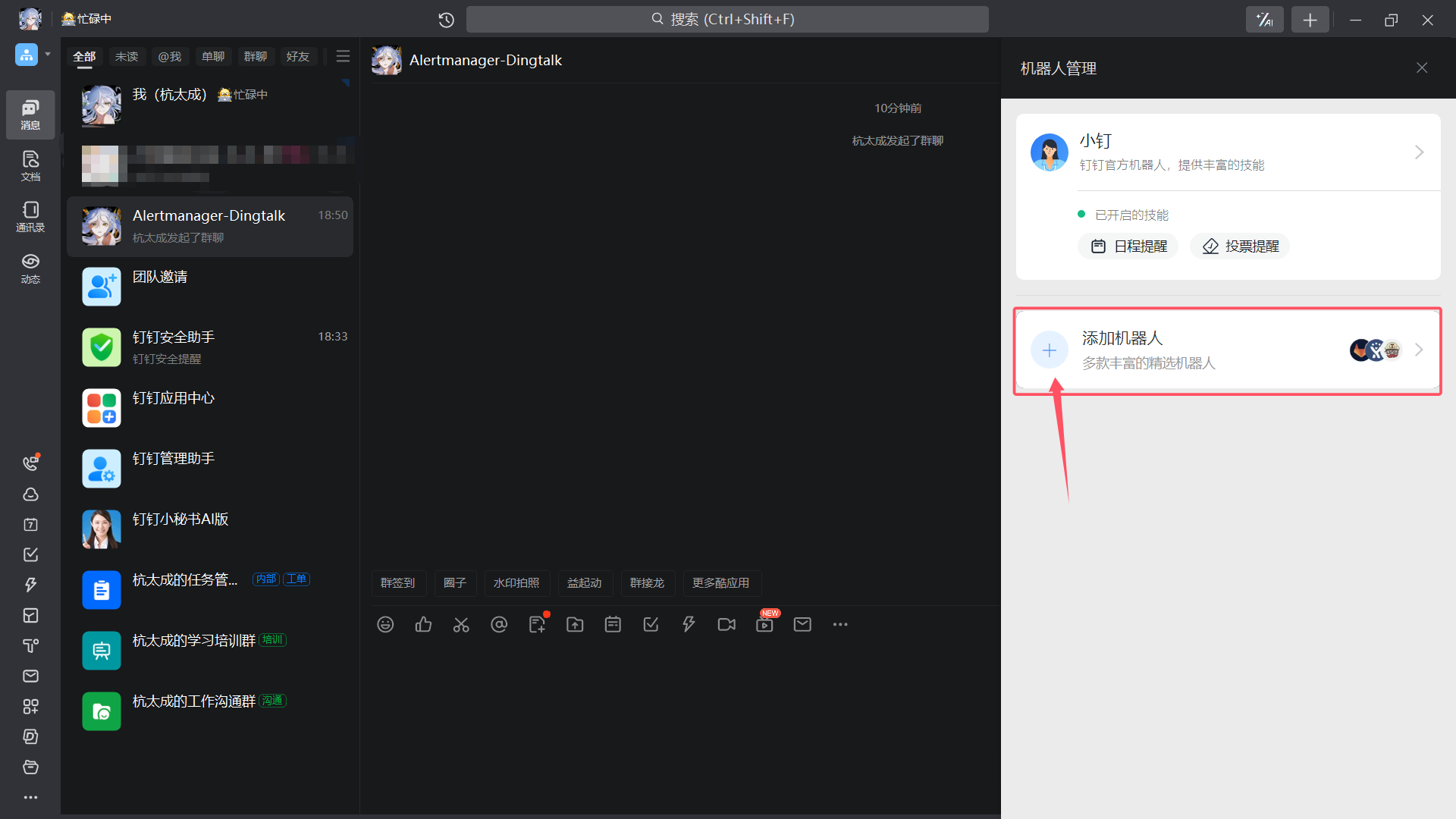 |
| 自定义 |
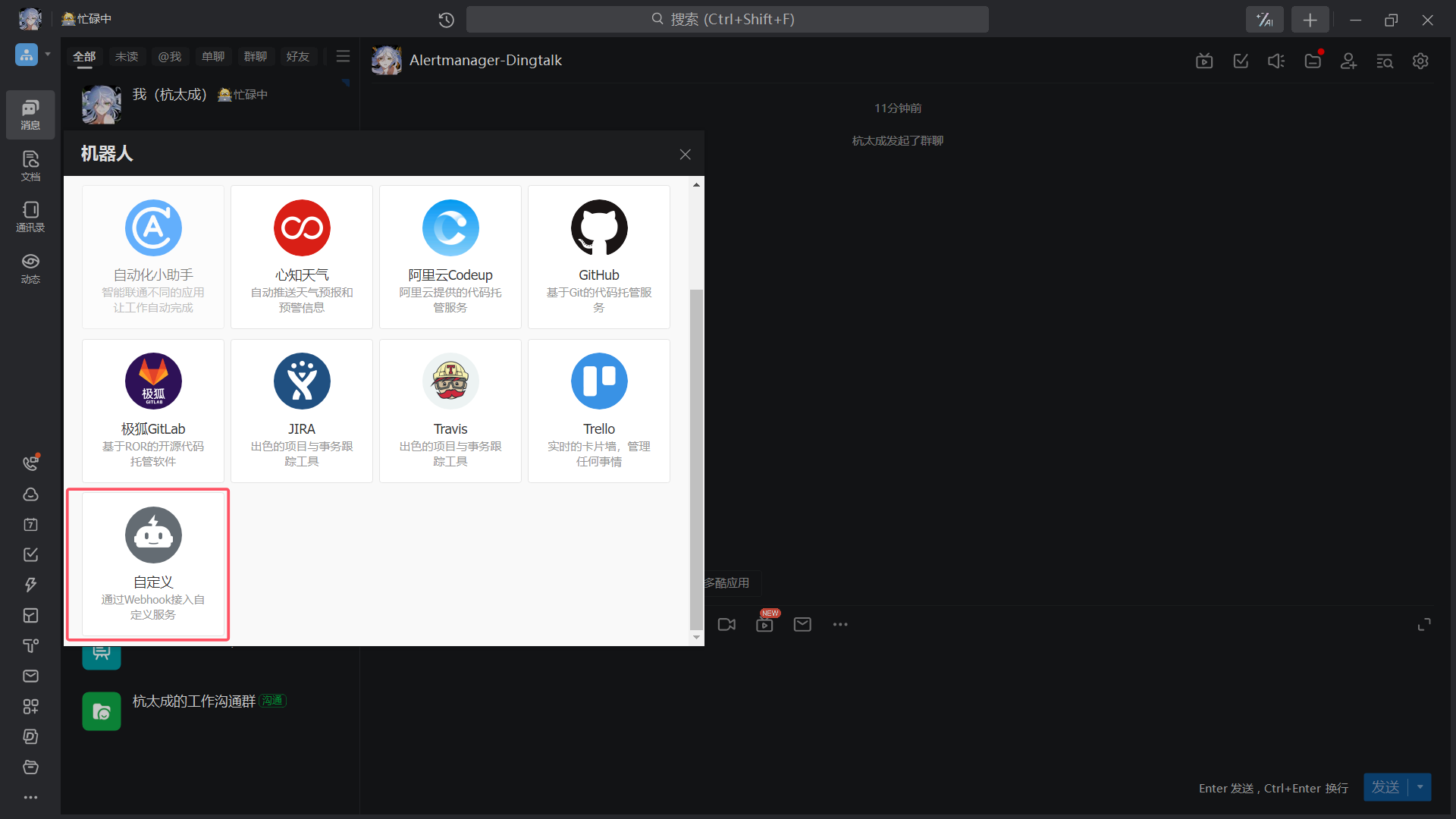 |
| 添加 |
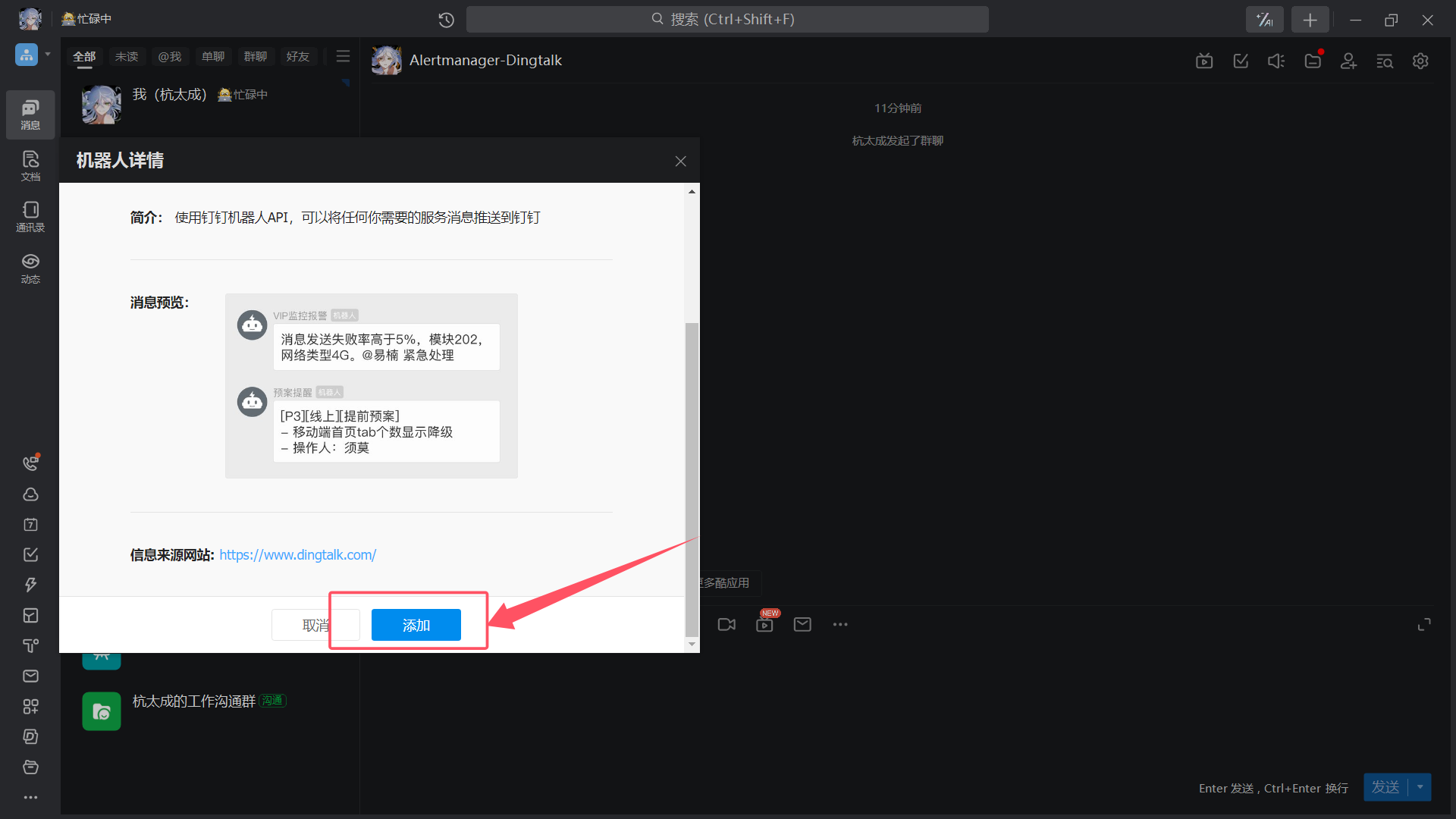 |
| 机器人名字、安全设置 |
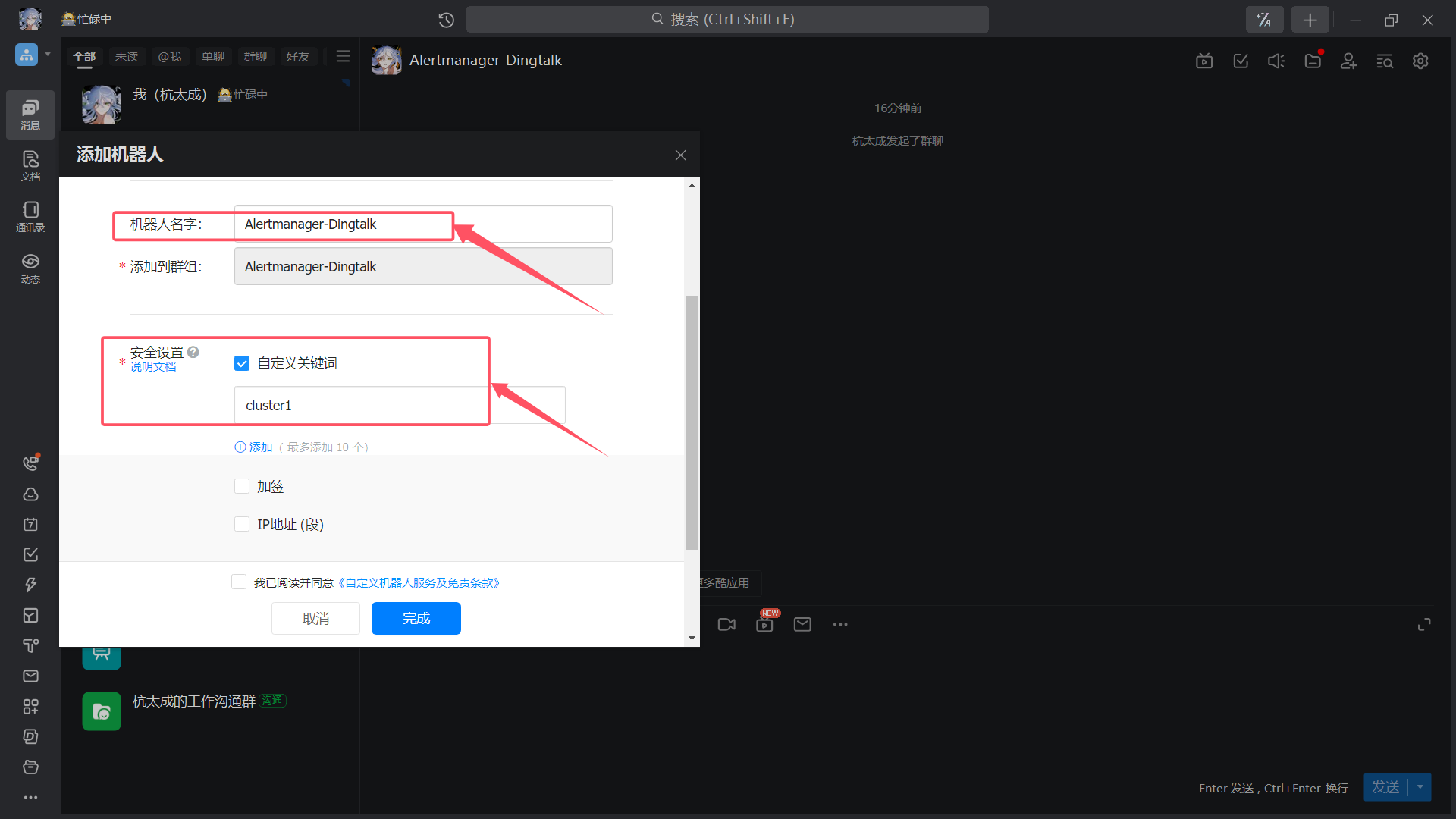 |
| 保管好 Webhook |
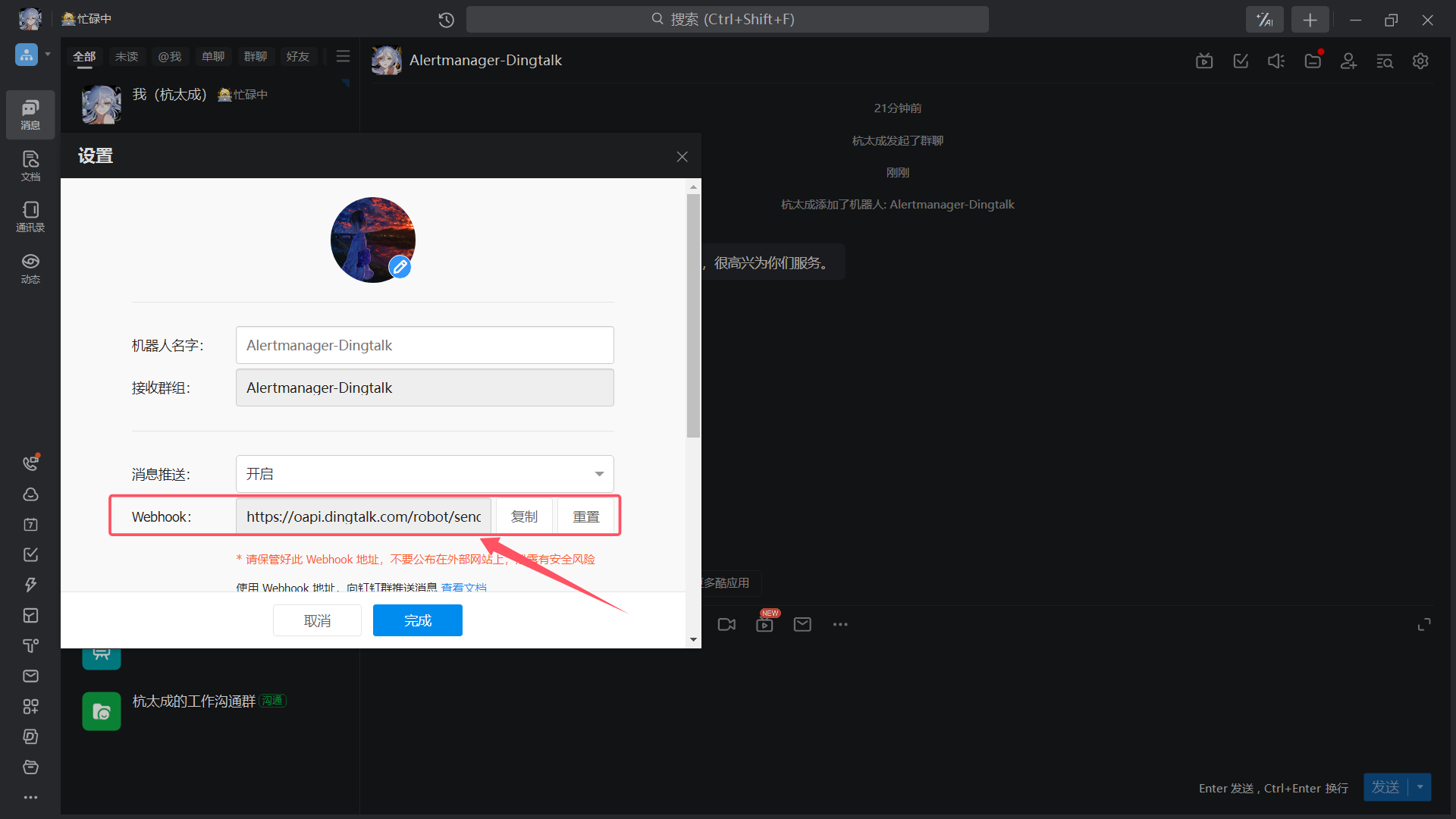 |
3、获取钉钉的 Webhook 插件
master 节点操作
git clone git@github.com:misakivv/prometheus-webhook-dingtalk.gitcd prometheus-webhook-dingtalktar zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gzcd prometheus-webhook-dingtalk-0.3.0.linux-amd64
4、启动钉钉告警插件
nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --ding.profile="cluster1=https://oapi.dingtalk.com/robot/send?access_token=feb3df2c6a987c8c1466c16eb90f4c2d3817c481aacf15cecc46f588f2716f25" &

5、对 alertmanager-cm.yaml 文件做备份
cp alertmanager-cm.yaml alertmanager-cm.yaml.bak
6、重新生成新的 alertmanager-cm.yaml 文件
cat >alertmanager-cm.yaml <<EOF
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |-global:resolve_timeout: 1msmtp_smarthost: 'smtp.qq.com:465'smtp_from: '2830909671@qq.com'smtp_auth_username: '2830909671@qq.com'smtp_auth_password: 'ajjgpgwwfkpcdgih'smtp_require_tls: falseroute:group_by: [alertname]group_wait: 10sgroup_interval: 10srepeat_interval: 10mreceiver: cluster1receivers:- name: cluster1webhook_configs:- url: 'http://192.168.112.10:8060/dingtalk/cluster1/send'send_resolved: true
EOF
7、重建资源以生效
kubectl delete cm alertmanager -n monitor-sakubectl apply -f alertmanager-cm.yamlkubectl delete -f prometheus-cfg.yamlkubectl apply -f prometheus-cfg.yamlkubectl delete -f prometheus-deploy.yamlkubectl apply -f prometheus-deploy.yaml

8、效果
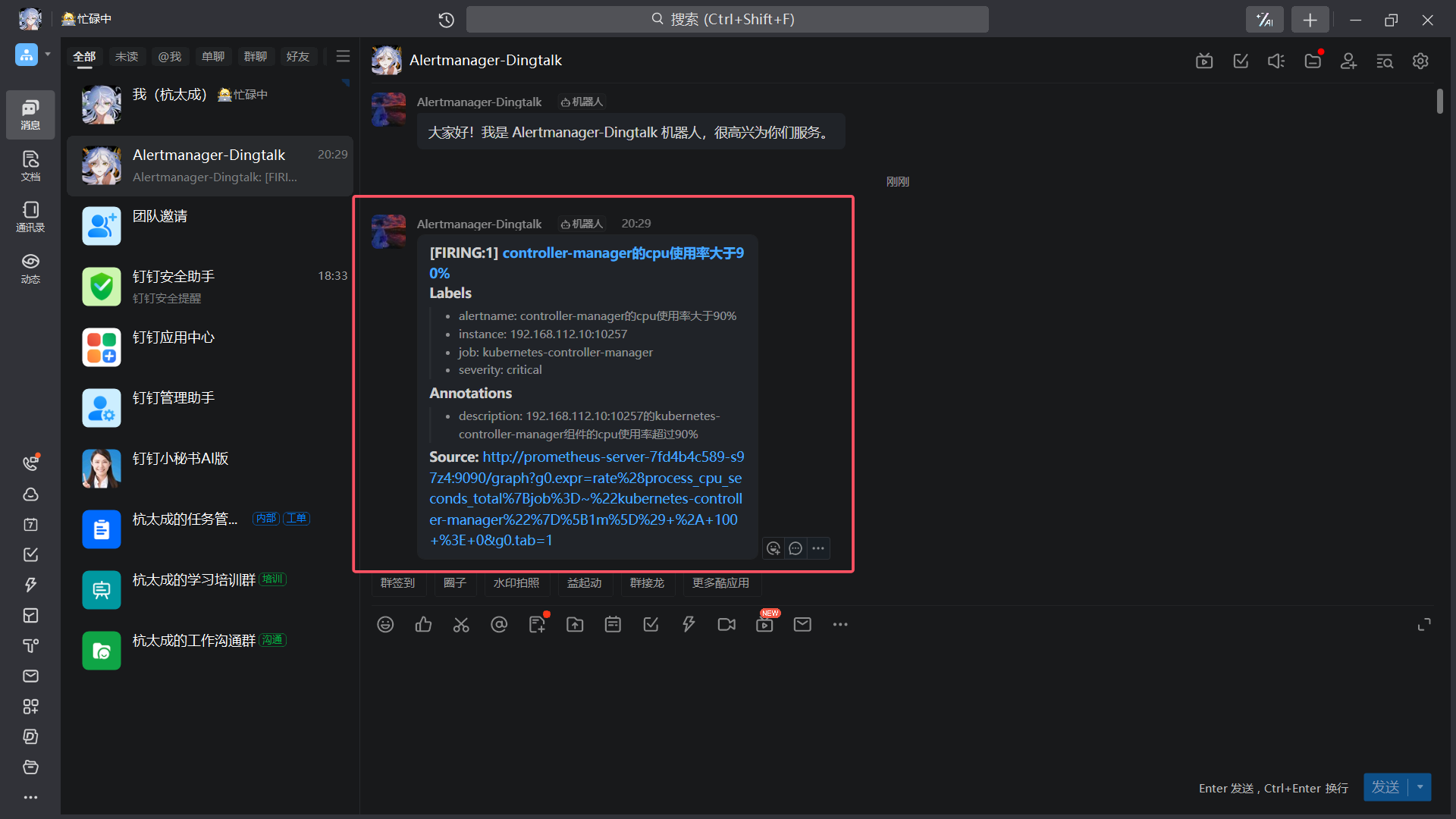 |
|---|
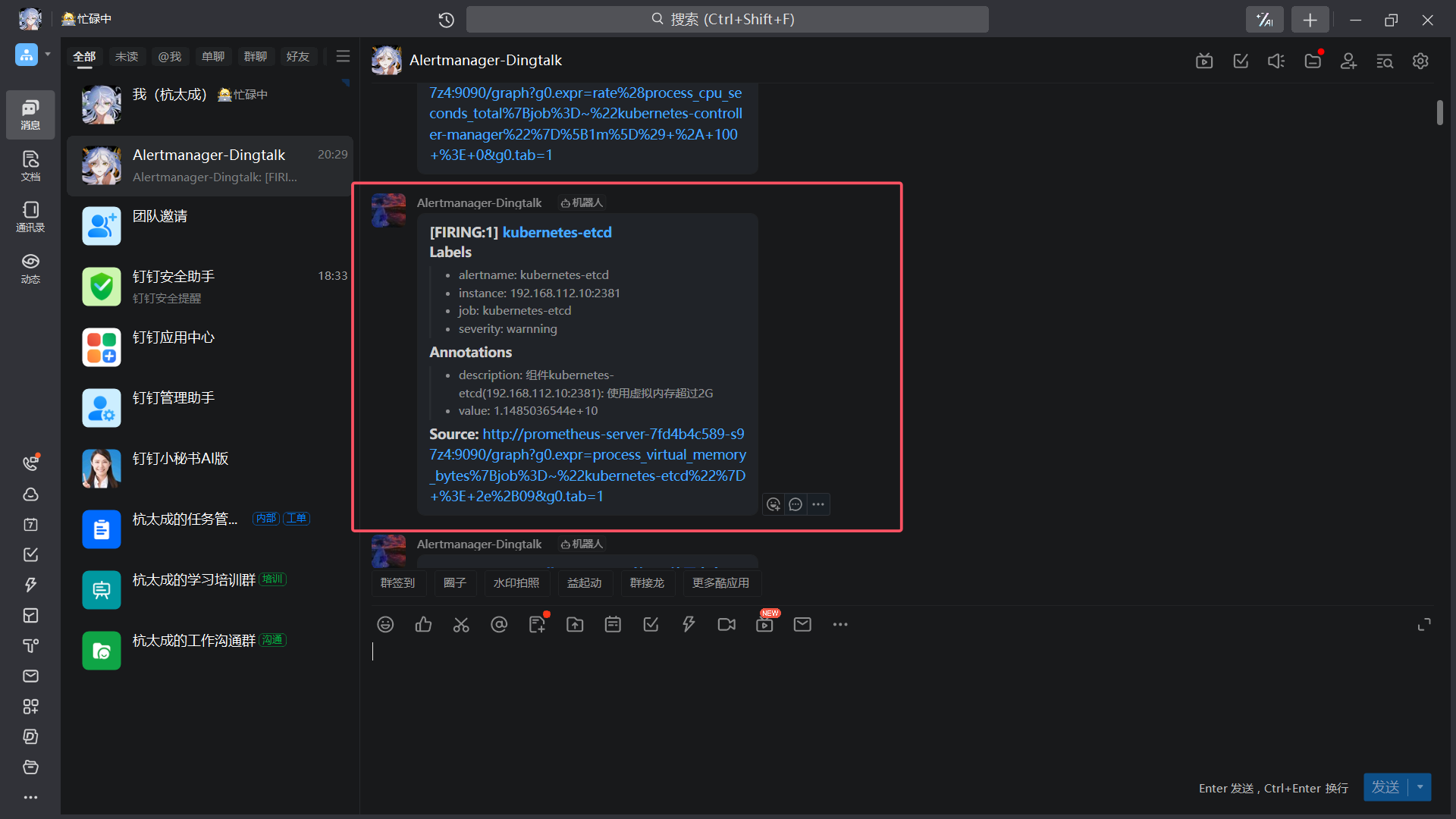 |
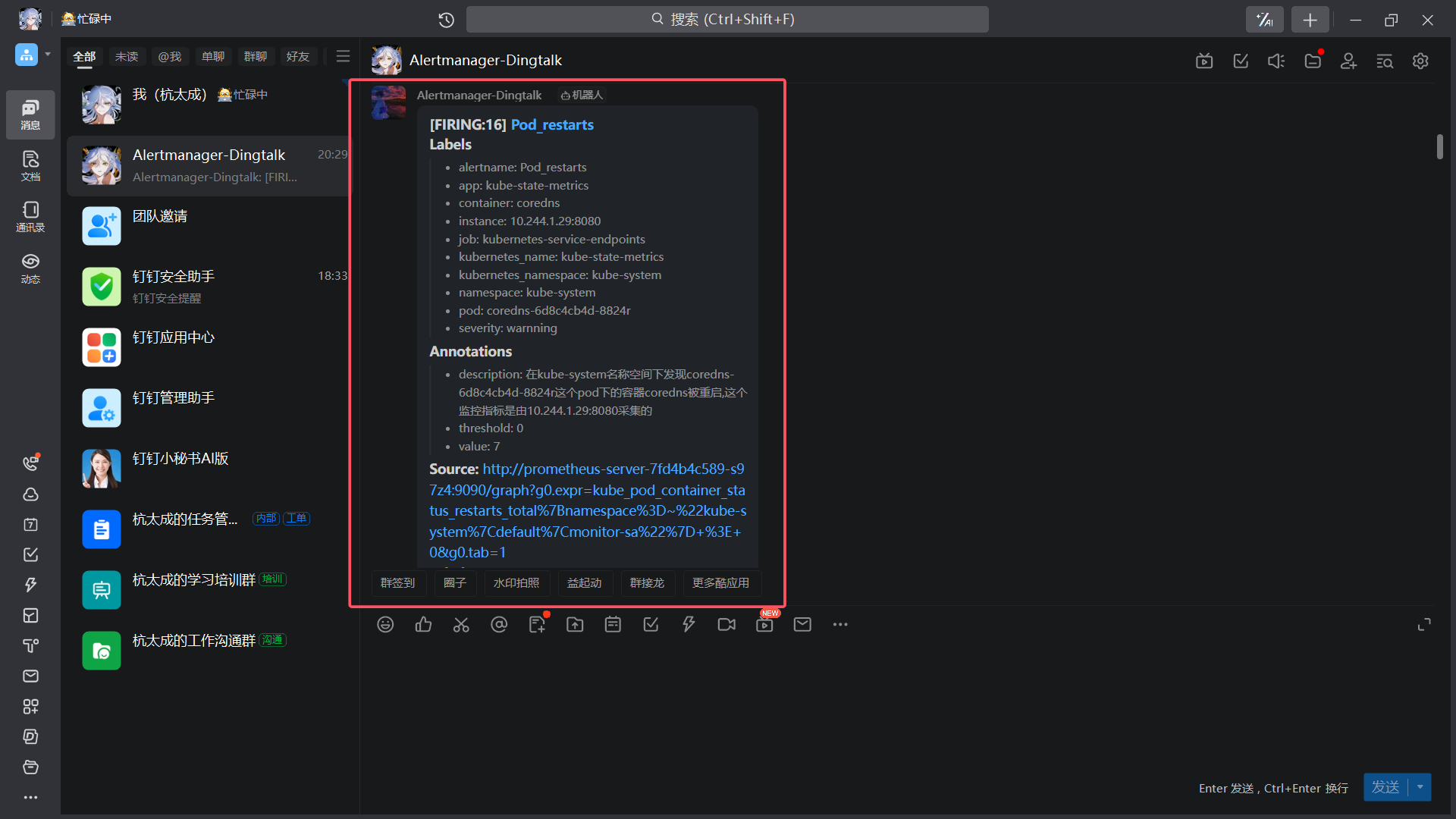 |
 |
 |
 |
暂时先写到这里,其实 alertmanager 还有静默、去重、抑制等功能,告警也可以模板化,下一篇再共同学习
相关文章:
基于 Prometheus+Grafana+Alertmanager 搭建 K8S 云监控告警平台(附配置告警至QQ、钉钉)
文章目录 一、机器规划二、部署安装 node-exporter、prometheus、Grafana、kube-state-metrics1、创建 monitor-sa 命名空间2、安装node-exporter组件2.1、说明2.2、应用资源清单2.3、通过node-exporter采集数据 3、k8s 集群中部署 prometheus3.1、创建一个 sa 账号3.2、将 sa …...

C++ | Leetcode C++题解之第461题汉明距离
题目: 题解: class Solution { public:int hammingDistance(int x, int y) {int s x ^ y, ret 0;while (s) {s & s - 1;ret;}return ret;} };...

ElasticSearch备考 -- Update by query Reindex
一、题目 有个索引task,里面的文档长这样 现在需要添加一个字段all,这个字段的值是以下 a、b、c、d字段的值连在一起 二、思考 需要把四个字段拼接到一起,组成一个新的字段,这个就需要脚本, 这里有两种方案ÿ…...

从认识String类,到走进String类的世界
作为一个常用的数据类型,跟随小编一同进入String的学习吧,领略String的一些用法。 1. 认识 String 类 2. 了解 String 类的基本用法 3. 熟练掌握 String 类的常见操作 4. 认识字符串常量池 5. 认识 StringBuffer 和 StringBuilder 一:…...

Vue入门-指令修饰符-@keyup.enter
指令修饰符: 通过"."指明一些指令后缀,不同后缀封装了不同的处理操作 ->简化代码 ①按键修饰符 keyup.enter ->键盘回车监听 ".enter"if(e.keyenter){} //".enter"用来简化代码 demo: <!DOCTYPE…...

【Kubernetes】常见面试题汇总(五十九)
目录 129.问题:pod 使用 PV 后,无法访问其内容? 130.查看节点状态失败? 特别说明: 题目 1-68 属于【Kubernetes】的常规概念题,即 “ 汇总(一)~(二十二…...

【ARM Linux驱动开发】嵌入式ARM Linux驱动开发基本步骤
【ARM Linux驱动开发】嵌入式ARM Linux驱动开发基本步骤 文章目录 开发环境驱动开发(以字符设备为例)安装驱动应用程序开发附录:压缩字符串、大小端格式转换压缩字符串浮点数压缩Packed-ASCII字符串 开发环境 首先需要交叉编译器和Linux环境…...
(一))
SpinalHDL之设计错误(Design Errors)(一)
本文作为SpinalHDL学习笔记第七十四篇,介绍SpinalHDL的设计错误。 目录: 1.赋值覆盖(Assignment Overlap) 2.跨时钟域违例(Clock crossing violation) 3.组合环(Combinatorial loop) 4.层次违例(Hierarchy violation) 5.IO包 ⼀、赋值覆盖(Assignment Overlap) ⼀、简介…...

QT + opengl 让2d贴图动起来
1 qtopengl 实现纹理贴图,平移旋转,绘制三角形,方形-CSDN博客 在上篇文章里面我已经学会了给贴图,并且旋转,那我们如何动态的显示2D的图片呢,那我们在qt里面是如何实现呢,定时器连续更新。 上…...

【selenium】webdriver测试脚本
【背景】 不同电脑上运行selenium时总是因为环境问题出幺蛾子,所以需要一个最简单的脚本每次先验证一下能不能正常启用selenium。 【脚本】 这个脚本做的事情就是试着用selenium启动网页,默认用了百度首页,也可以根据情况自己修改。 from…...

工业自动化中的关键信号:开关量、模拟量与脉冲量
工业自动化和控制系统中,信号的类型对于数据处理和决策至关重要。主要的信号类型包括开关量、模拟量和脉冲量。每种信号类型都有其独特的特点和应用场景,它们共同构成了自动化系统的基础。这三种信号的特点、应用及其在现代工业自动化中的重要性。 开关…...
VMware vCenter Server 8.0U3c 发布下载,修复 U3b 更新停止响应的问题
VMware vCenter Server 8.0U3c 发布下载 - 集中式管理 vSphere 环境 Server Management Software | vCenter 请访问原文链接:https://sysin.org/blog/vmware-vcenter-8-u3/ 查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org VMw…...

Java面试宝典-Java集合02
目录 Java面试宝典-Java集合02 21、TreeMap 和 TreeSet 在排序时如何比较元素? 22、ArrayList 和 LinkedList 的区别是什么? 23、ArrayList 和 Vector 的区别? 24、队列和栈是什么?有什么区别? 25、Queue和Deque的区别…...

HJ212-2017协议详解:工业物联网环境监测标准简单了解
在工业物联网(IIoT)领域,环境数据的采集、传输和分析对于环境监控和治理至关重要。中国环境监测系统中,HJ212-2017协议是针对污染源在线监控(监测)系统的通信协议标准。该协议规定了污染源自动监控设备与数…...

【Golang】Go语言Seeker接口与文件断点续传实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

【MySQL】基本查询(下):更新、删除
3.Update 语法: UPDATE table_name SET column expr [, column expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]举几个例子: 将孙悟空同学的数学成绩变更为 80 分: 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 …...

django urlconf路由分发
在Django中,URLconf(URL configuration)是用来定义应用程序的URL路由规则的,主要用于将特定的URL请求映射到相应的视图函数。以下是关于Django中URL分发的详细介绍和代码示例。 URLconf的基本结构 URL配置文件(urls.p…...

The 2024 ICPC Kunming Invitational Contest K. Permutation(交互 期望)
在知乎内查看 题目 思路来源 题解 首先特判n1的情况,其实也不用问 分治,假设当前解决到[l,r],要递归的vector是x, 维护两个vector L、R,代表下一步要在[l,mid]和[mid1,r]分治的vector 每次将x random_shuffle后&a…...

TensorFlow与Pytorch的转换——1简单线性回归
import numpy as np# 生成随机数据 # 生成随机数据 x_train np.random.rand(100000).astype(np.float32) y_train 0.5 * x_train 2 import tensorflow as tf# 定义模型 W tf.Variable(tf.random.normal([1])) b tf.Variable(tf.zeros([1])) y W * x_train b # 定义损失函…...

短剧小程序短剧APP在线追剧APP网剧推广分销微短剧小剧场小程序集师知识付费集师短剧小程序集师小剧场小程序集师在线追剧小程序源码
一、产品简介功能介绍 集师专属搭建您的独有短剧/追剧/小剧场小程序或APP平台 二、短剧软件私域运营解决方案 针对短剧类小程序的运营,以下提出10条具体的方案: 明确定位与目标用户: 对短剧类小程序进行明确定位,了解目标用户群体…...

终极指南:如何免费搭建专业的电子实验室笔记本系统
终极指南:如何免费搭建专业的电子实验室笔记本系统 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw eLabFTW是一款功能强大…...

在RK3568 Android 11上搞定移远EC20 4G模块:从驱动到RIL的完整移植避坑记录
RK3568 Android 11平台EC20 4G模块全流程移植指南:从硬件连接到网络配置 在嵌入式Android开发中,4G模块的集成一直是项目落地的关键环节。本文将基于RK3568平台和Android 11系统,详细解析移远EC20模块从硬件连接到上层应用的全链路移植过程。…...

一封好JD,唤醒应届生的投递欲
你的实习岗位描述为何石沉大海? 在校招实习生招募的初期,JD(职位描述)就是企业的门面。然而,很多HR直接套用社招模版,导致文案枯燥乏味,完全无法触动应届生的痛点。在信息爆炸的春招季…...

谷歌搜索重大更新:更智能个性化,多项新功能即将上线!
谷歌搜索迈向更智能、更个性化时代曾几何时,谷歌搜索简洁易用,只需在搜索框输入关键词,浏览蓝色链接列表即可。然而,如今人工智能已层层覆盖搜索模式。2026 年谷歌 I/O 大会上,谷歌宣布一系列搜索更新,使搜…...

在Blender中创建逼真流体模拟:FLIP Fluids插件完全指南
在Blender中创建逼真流体模拟:FLIP Fluids插件完全指南 【免费下载链接】Blender-FLIP-Fluids The FLIP Fluids addon is a tool that helps you set up, run, and render high quality liquid fluid effects all within Blender, the free and open source 3D crea…...

无王无帝定乾坤,来自田间第一人:大道同源归本心
无王无帝定乾坤,来自田间第一人。 世间千般法理,万般修行,流派纷杂,说辞各异; 世人终日寻道问路,遍历山河苦思真谛, 却往往舍近求远,向外求索不休, 反倒遗忘最本真的根源…...
)
保姆级教程:用YOLOv8和Pyside6从零搭建一个火焰烟雾检测桌面应用(附完整源码和数据集)
从零构建火焰烟雾检测桌面应用:YOLOv8与Pyside6实战指南 在工业安全、家庭监控和实验室防护场景中,火焰与烟雾的早期检测至关重要。传统监控系统依赖人工值守或简单传感器,难以实现精准的实时预警。本文将带你用Python生态中最前沿的YOLOv8目…...

ThinkPad双风扇终极控制指南:TPFanControl2完全使用教程
ThinkPad双风扇终极控制指南:TPFanControl2完全使用教程 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否为ThinkPad笔记本的风扇噪音而烦恼ÿ…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

法律文书分析系统接入 A-MEM 长程记忆
项目实训 | Vue3 FastAPI | NeurIPS 2025 A-MEM 复现与工程落地一、背景与动机 在法律文书智能分析系统的开发过程中,我们发现了一个核心痛点:AI助手没有"记忆"。 用户在第一轮对话里详细描述了案件事实——“我是原告张三,2024年…...