leetcode-10/9【堆相关】
1.数组中的第K个最大元素【215】
思路:
1.1.要使得时间复杂度为O(n),自己实现大顶堆,通过K次调整,顶部元素就是想要的第K个最大元素
1.2.实现大顶堆的过程中,先建堆,建堆是利用递归,本质上是从下到上地进行大顶堆的调整,因为如果从上到下,只能实现局部的大顶堆,有可能会漏掉一些元素没调整
1.3.叶子节点本身就满足大顶堆的性质,所以不需要调整,只需要从倒数第2排进行调整即可,即heapSize / 2 - 1
1.4.对于某个堆进行调整的时候,判断左子树2 * i + 1,右子树 2 * i + 2,和根节点i,如果左右子树有比i的值大的,取更大的作为largest最大节点,与根节点进行交换,并且递归地调整largest位置的子树符合大顶堆的性质。注意!!交换的只是值,但是largest索引没变,其子树还是原来位置的子树
2. 前K个高频元素
思路:
2.1. 先用哈希表对元素以及元素出现的次数进行存储,之后对value即出现次数进行排序即可
2.2.要求算法时间复杂度优于O(nlogn),我采用堆排序,利用PriorityQueue优先队列,定义排序器规则,实现小顶堆。由此,最小的元素在队列首部
2.3.取前K个高频元素,因此优先队列实现的堆的大小为K即可
2.4.有新的元素来的时候,如果大小小于K,就直接进入队列;否则,如果小顶堆顶部元素小于新的元素,则将顶部元素弹出,新元素进入队列。且PriorityQueue会自动按照排序器规则调整小顶堆
相关文章:

leetcode-10/9【堆相关】
1.数组中的第K个最大元素【215】 思路: 1.1.要使得时间复杂度为O(n),自己实现大顶堆,通过K次调整,顶部元素就是想要的第K个最大元素 1.2.实现大顶堆的过程中,先建堆,建堆是利用递归,本…...

自然语言处理问答系统:技术进展、应用与挑战
自然语言处理问答系统:技术进展、应用与挑战 自然语言处理(NLP)作为人工智能领域的一个重要分支,旨在使计算机能够理解和生成人类语言。问答系统(Q&A System),作为NLP的一个重要应用&#…...

向量数据库!AI 时代的变革者还是泡沫?
向量数据库!AI 时代的变革者还是泡沫? 前言一、向量数据库的基本概念和原理二、向量数据库在AI中的应用场景三、向量数据库的优势和挑战四、向量数据库的发展现状和未来趋势五、向量数据库对AI发展的影响 前言 数据是 AI 的核心,而向量则是数…...

vue中css作用域及深度作用选择器的用法
Vue中有作用域的CSS 当< style>标签有scoped属性时,它的css只作用于当前组建中的元素。vue2和vue3均有此用法; 当使用scoped后,父组件的样式将不会渗透到子组件中。不过一个子组件的根节点会同时受父组件有作用域的css和子组件有作用…...

LLM - 使用 ModelScope SWIFT 测试 Qwen2-VL 的 LoRA 指令微调 教程(2)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142827217 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 SWIFT …...

2024 年热门前端框架对比及选择指南
在前端开发的世界里,框架的选择对于项目的成功至关重要。不同的框架有着不同的设计理念、生态系统和适用场景,因此,开发者在选框架时需要权衡多个因素。本文将对当前最流行的前端框架——React、Vue、Angular、Svelte 和 Solid——进行详细对…...

map_server
地图格式 此软件包中的工具处理的地图以两个文件的形式存储。YAML 文件描述地图的元数据,并命名图像文件。图像文件编码了占用数据。 图像格式 图像文件描述世界中每个单元格的占用状态,并使用相应像素的颜色表示。在标准配置中,较白的像素…...

无人机航拍视频帧处理与图像拼接算法
无人机航拍视频帧处理与图像拼接算法 1. 视频帧截取与缩放 在图像预处理阶段,算法首先逐帧地从视频中提取出各个帧。 对于每一帧图像,算法会执行缩放操作,以确保所有帧都具有一致的尺寸,便于后续处理。 2. 图像配准 在图像配准阶段,算法采用SIFT(尺度不变特征变换)算…...

搬砖11、Python 文件和异常
文件和异常 实际开发中常常会遇到对数据进行持久化操作的场景,而实现数据持久化最直接简单的方式就是将数据保存到文件中。说到“文件”这个词,可能需要先科普一下关于文件系统的知识,但是这里我们并不浪费笔墨介绍这个概念,请大…...
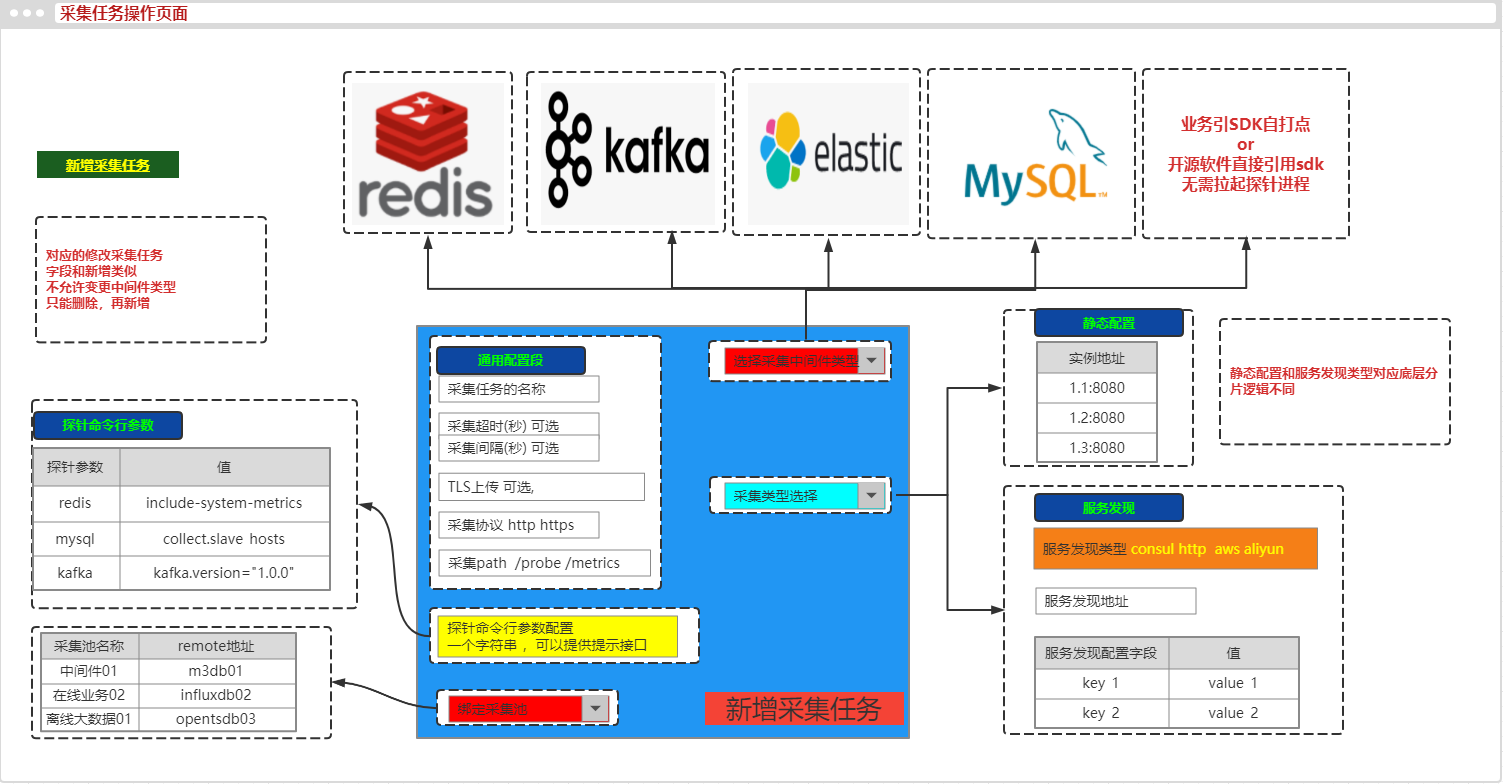
24.6 监控系统在采集侧对接运维平台
本节重点介绍 : 监控系统在采集侧对接运维平台 服务树充当监控系统的上游数据提供者在运维平台上 可以配置采集任务 exporter改造成探针型将给exporter传参和修改prometheus scrape配置等操作页面化 监控系统在采集侧对接运维平台 服务树充当监控系统的上游数据提供者在运…...

refresh-1
如果设置了刷新标志(refreshFlag): - 如果CAT(配置文件管理代理)未初始化,eUICC应返回一个错误代码commandError。 - 对于MEP-A2,eUICC可以返回一个错误代码commandError。 - 如果目标端口上正…...
如何写好一篇计算机应用的论文?
计算机应用是一个广泛的领域,涵盖了从软件开发到数据分析、人工智能、网络安全等多个方向。选择一个合适的毕业设计题目,不仅要考虑个人兴趣和专业技能,还要考虑项目的可行性、创新性以及对未来职业发展的帮助。以下是一些建议,帮…...

工业 5.0 时代的数字孪生:迈向高效和可持续的智能工厂
数字孪生(物理机器或流程的虚拟代表)正在彻底改变工业物联网和流程监控。这项新兴技术可实现实时模拟,提高效率、可持续性并降低成本。航空航天和汽车等行业已经从这些创新系统中获益匪浅 数字孪生是数字模拟器的演变,因此&#x…...

Python脚本之获取Splunk数据发送到第三方UDP端口
原文地址:https://www.program-park.top/2024/10/12/python_21/ 在 Linux 环境执行脚本,Python需要引入对应依赖: pip install splunk-sdk离线环境下,可手动执行python进入 Python 解释器的交互式界面,输入以下命令&a…...

Protobuf:复杂类型接口
Protobuf:复杂类型接口 package字段规则复杂类型enumAnyoneofmap 本博客基于proto3语法,讲解protobuf中的复杂类型。 package 在.proto文件中,支持导入其它.proto文件的内容,例如: test.proto: syntax …...

Git Push 深度解析:命令的区别与实践
目录 命令一:git push origin <branch-name>命令二:git push Factory_sound_detection_tool test工作流程:两者的主要区别实践中的应用总结 Git 是一种分布式版本控制系统,它允许用户对代码进行版本管理。在 Git 中…...
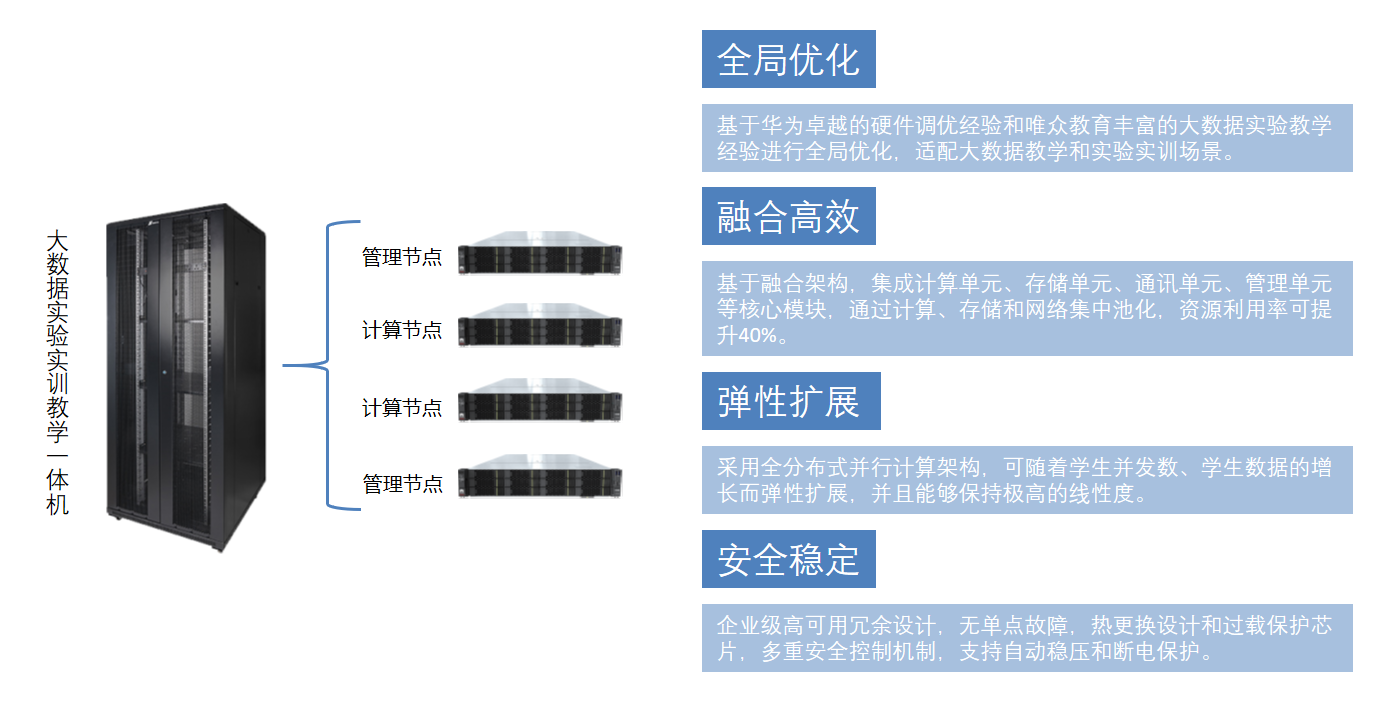
大数据开发基础实训室设备
大数据实验实训一体机 大数据实验教学一体机是一种专为大数据教育设计的软硬件融合产品,其基于华为机架服务器进行了调优设计,从而提供了卓越的性能和稳定性。这一产品将企业级虚拟化管理系统与实验实训教学信息化平台内置于一体,通过软硬件…...
)
【数据结构】string(C++模拟实现)
string构造 string::string(const char* str):_size(strlen(str)) {_str new char[_size 1];_capacity _size;strcpy(_str, str); }// s2(s1) string::string(const string& s) {_str new char[s._capacity 1];strcpy(_str, s._str);_size s._size;_capacity s._cap…...

【笔记】I/O总结王道强化视频笔记
文章目录 从中断控制器的角度来理解整个中断处理的过程复习 处理器的中断处理机制**中断驱动I/O方式** printf——从系统调用到I/O控制方式的具体实现1轮询方式下输出一个字符串(程序查询)中断驱动方式下输出一个字符串中断服务程序中断服务程序与设备驱动程序之间的关系 DMA方…...

XML XSLT:转换与呈现数据的力量
XML XSLT:转换与呈现数据的力量 XML(可扩展标记语言)和XSLT(XML样式表转换语言)是现代信息技术中不可或缺的工具,它们在数据交换、存储和呈现方面发挥着重要作用。本文将深入探讨XML和XSLT的概念、应用及其在信息技术领域的重要性。 XML:数据交换的标准 XML是一种用于…...

蓝桥杯备赛:那些教科书里没写的“潜规则”与实战优化
1. 那些容易被忽视的编译细节 参加过蓝桥杯的同学都知道,比赛中最让人崩溃的不是题目有多难,而是明明本地运行好好的代码,提交后却莫名其妙地编译失败。这些坑我在第一次参赛时几乎全踩过,现在回想起来都是血泪教训。 首先是main函…...
:一个骰子如何玩转优化问题?)
用Python从零复现混沌博弈算法(CGO):一个骰子如何玩转优化问题?
用Python从零复现混沌博弈算法(CGO):一个骰子如何玩转优化问题? 混沌博弈算法(Chaos Game Optimization, CGO)是近年来兴起的一种新型智能优化算法,它将混沌理论与博弈思想巧妙结合,…...

Python技能安装器设计:从虚拟环境到CLI的自动化部署实践
1. 项目概述:一个技能安装器的诞生在开源社区里,我们经常遇到一些“小而美”的工具或脚本,它们能解决特定场景下的痛点,但往往缺乏一个统一的、便捷的安装和管理入口。用户需要手动克隆仓库、检查依赖、配置环境变量,甚…...
)
别再手动敲空格了!用LaTeX的\parskip命令一键搞定论文段落间距(附局部调整技巧)
LaTeX段落间距精修指南:从全局配置到章节级微调 在学术写作的世界里,格式规范往往比内容本身更容易引发焦虑。当你在凌晨三点盯着屏幕,发现第17次调整的段落间距仍然不符合期刊要求时,那种绝望感足以让任何研究者崩溃。传统的手动…...

高性能WebGL地图引擎OME:海量地理空间数据可视化实战指南
1. 项目概述与核心价值 如果你在开源社区里混迹过一段时间,尤其是对数据可视化、地理信息系统或者大规模图数据渲染感兴趣,那么“sgl-project/ome”这个项目标题很可能已经引起了你的注意。OME,全称可能是“Open Map Engine”或类似的概念&am…...

AI工作流编排框架aiflows:构建模块化、可维护的多智能体系统
1. 项目概述:当AI工作流成为团队协作的“操作系统”如果你和我一样,在过去几年里尝试过将多个大语言模型(LLM)串联起来,构建一个能处理复杂任务的智能体(Agent)或工作流,那你一定经历…...

Next.js 14全栈样板工程解析:集成Prisma与NextAuth的现代Web开发实践
1. 项目概述:一个为现代Web应用量身定制的启动器如果你正在寻找一个能让你跳过繁琐的初始化配置,直接进入核心业务逻辑开发的Next.js项目起点,那么nemanjam/nextjs-prisma-boilerplate这个项目很可能就是你需要的。这不是一个简单的“Hello W…...

taotoken token plan套餐在ubuntu长期开发中的成本控制感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan 套餐在 Ubuntu 长期开发中的成本控制感受 在 Ubuntu 环境下进行 AI 应用的原型开发与长期迭代,模…...

SNMP 实战:从基础命令到高效监控场景应用
1. SNMP基础:从零开始理解网络监控的核心协议 第一次接触SNMP时,我也被那些数字串和术语搞得一头雾水。简单来说,SNMP就像是你给网络设备安装了一个"话筒",让它能主动汇报自己的状态。这个协议已经存在了30多年…...

为什么92%的团队在2026年前仓促重构AI栈?——主流框架弃用预警、许可证变更清单与平滑迁移路线图
更多请点击: https://intelliparadigm.com 第一章:2026年AI工具栈搭建完整指南 构建面向生产环境的AI工具栈,需兼顾前沿性、稳定性与可扩展性。2026年主流实践已从单点模型调用转向模块化、可观测、可编排的智能工作流基础设施。以下为推荐技…...