利用可解释性技术增强制造质量预测模型
概述
论文地址:https://arxiv.org/abs/2403.18731
本研究提出了一种利用可解释性技术提高机器学习(ML)模型性能的方法。该方法已用于铣削质量预测,这一过程首先训练 ML 模型,然后使用可解释性技术识别不需要的特征并去除它们,以提高准确性。这种方法有望降低制造成本,提高对 ML 模型的理解。这项研究表明,可解释性技术可用于优化和解释制造业的预测模型。
介绍
铣削是一种加工工艺,通过去除材料来加工出所需的形状或表面光洁度。在这一过程中,被称为铣刀的切削工具高速旋转,在移动工件的同时去除材料。工件固定在一个可以多轴移动的工作台上,可以进行各种方向和角度的加工(Fertig 等人,2022 年)。铣削过程中的能耗会因设置和材料的不同而有很大差异,但通常被认为是一种能源密集型工艺。如果能预测和预防质量问题,就能降低能耗,减少因生产缺陷零件而造成的浪费(Pawar 等人,2021 年)。
机器学习(ML)模型可以识别数据中的模式和结构,并在不受程序直接指导的情况下进行预测。这些模型是预测铣削操作最终质量的有用工具,可以提高制造过程的效率和可靠性(Mundada 和 Narala,2018 年)。然而,铣削操作的实验数据非常昂贵,因此可用数据往往很少,难以训练 ML 模型来预测工件质量(Postel 等人,2020 年)。
此外,在使用复杂的 ML 模型(尤其是深度神经网络模型)时,其内部运作是不透明的,其 "黑箱 "性质可能会造成问题。出现这一问题的原因是这些模型的预测结果难以理解,因此无法被制粉质量预测领域的从业人员和利益相关者完全理解(Kwon 等人,2023 年)。
本研究提出了一种利用可解释性方法来阐明和优化 ML 模型预测机制,从而提高 ML 模型性能的方法。通过使用可解释性方法,可以识别 ML 模型预测中的重要特征并消除不必要的特征,从而有效推进优化工作(Bento 等人,2021 年;Sun 等人,2022 年)。
相关研究
将机器学习(ML)应用于制造和加工任务至少已有十年之久(Kummar,2017)。例如,ML 最初用于优化车削操作(Mokhtari Homami 等人,2014 年)、预测铣削操作的稳定条件(Postel 等人,2020 年)、估算内孔质量(Schorr 等人,2020 年)以及使用 ML 驱动的表面质量控制对缺陷进行分类(Chouhad 等人,2021 年)。Chouhad 等人,2021 年)等。
然而,可解释人工智能(XAI)方法在制造过程中的应用最近才开始受到关注(Yoo 和 Kang,2021 年;Senoner 等人,2022 年)。正在进行的欧洲 XMANAI 项目(Lampathaki 等人,2021 年)旨在评估 XAI 在不同制造领域的能力。特别是,XAI 在故障诊断领域的成功应用潜力已经显现(Brusa 等人,2023 年)。
还有一些研究侧重于数据集的特征选择,而不直接考虑 ML 模型(Bins 和 Draper,2001 年;Oreski 等人,2017 年;Venkatesh 和 Anuradha,2019 年)。本研究探讨了使用 XAI 通过消除不必要的传感器来提高预测模型质量的可能性,尽管通过可解释性方法来提高 ML 模型性能的方法在可解释性 ML 的背景下是众所周知的(Bento 等人,2021 年;Sun 等人,2022 年;Nguy 等人,2022 年)。等人,2022 年;Nguyen 和 Sakama,2021 年;Sofianidis 等人,2021 年),但这是 XAI 首次用于铣削操作的质量预测模型。特别是,通过使用 XAI 方法识别和消除不需要的特征来改进铣削过程质量预测模型的方法非常新颖。
方法论
本研究提出了一种利用可解释性技术提高机器学习(ML)模型性能的方法,具体步骤如下。
1. 训练 ML 模型
首先,使用给定的数据集训练 ML 模型。本研究使用了三种模型:决策树回归、梯度提升回归和随机森林回归。与神经网络相比,这些模型需要的数据更少,也更容易解释。
2. 可解释性方法的应用
将可解释性方法应用于训练好的 ML 模型和数据集,以确定对预测准确性至关重要的特征。这一步骤包括对特征的重要性进行排序,并使用越来越多的重要特征来训练新模型。
3. 特征选择
根据特征的重要性,只使用最重要的特征来训练新模型。这一过程可提高 ML 模型的性能。
机器学习模型
- 决策树回归模型
决策树回归模型将输入空间划分为不同的区域,并对每个区域内的训练样本拟合一个简单的模型(通常为常数)。  对新输入𝑥 x 的预测 𝑦^表示如下。
对新输入𝑥 x 的预测 𝑦^表示如下。

其中,𝑐𝑚cm 是拟合区域 𝑅𝑚R m的常数,𝑀 M 是区域数量,𝐼 ⋅I⋅ 是指标函数。
- 梯度提升回归模型
 梯度提升回归模型结合了多个弱模型来优化损失函数。从初始近似值F0(x)开始,通过添加弱模型hmx(x)对其进行如下更新。
梯度提升回归模型结合了多个弱模型来优化损失函数。从初始近似值F0(x)开始,通过添加弱模型hmx(x)对其进行如下更新。

其中,𝛼 α 是学习率,hm(x) 是弱学习器,用于纠正前一个模型中的错误。
𝐹𝑚(𝑥)=𝐹𝑚-1(𝑥)+𝛼⋅타𝑚(𝑥)
- 随机森林回归模型
随机森林回归模型通过训练多棵决策树并取其平均值来做出最终预测。 
新输入数据𝑥x � �最终预测结果表达如下

其中,𝑇 T 是树的总数,yt(x)𝑦𝑡(𝑥) 是第 t 棵树的预测值。
𝑦^(𝑥)=1𝑇∑𝑡=1𝑇𝑦𝑡(𝑥)
可解释性技术
- 特征的排列重要性
特征置换重要性是一种评估模型重要特征的问责方法。它通过随机替换某些特征并监测模型性能的变化来衡量每个特征的重要性。
- 夏普利值
夏普利值源于合作博弈论,根据每个参与者的边际贡献分配公平值。在机器学习模型中,它量化了每个特征对预测的贡献。
案例研究
本研究使用 ENSAM 生成的数据集来应用所提出的方法。详情如下。
目标
本案例研究的目的是为每个质量指标开发一个预测模型。这不仅包括训练模型,还包括明确预测结果的原因,以及识别和删除不需要的特征。这一步骤旨在通过减少冗余传感器、优化资源和降低成本,最大限度地降低安装和维护成本。

| 图 1:用于加工工件的铣床 |
数据预处理
由于本研究处理的是时间序列长度不固定的数据,因此对每个时间序列都计算了方框图值。此外,数据集中的元数据包含各种实验参数。
训练机器学习模型
在本研究中,对决策树回归、梯度提升回归和随机森林模型进行了训练,以预测每个质量指标。模型输入和输出的整体视图如图 2 所示。每个模型的训练都采用了五部分交叉验证法。这种方法将数据分成五个相等的部分,其中四个部分(80%)用于训练,其余一个部分(20%)用于每次迭代测试。这一过程重复五次,五部分中的每一部分都作为测试集。对模型的性能取五次迭代的平均值,以得出更可靠的评估结果。

| 图 2:ML 预测模型接收箱形图(时域和频域)和机器配置参数,并输出质量指标。 |
分析
对所提出的方法进行了分析。首先评估了 ML 模型的性能,然后分析了 ML 模型的预测机制,最后评估了去除特征对 ML 模型性能的影响。
评估模型的预测质量
本研究旨在评估梯度提升回归、决策树和随机森林这三种 ML 模型的预测准确性。评估预测质量的主要指标是平均绝对误差率(MAPE)。如果 MAPE 小于 5%,则认为预测质量较高。
-
设置:使用 100 个样本的预处理数据集。
-
运行:在预处理数据集上训练了梯度提升回归、决策树和随机森林三种不同的机器学习模型,并使用 k 分割交叉验证法测量了 MAPE。
-
研究结果:利用这些 ML 技术,我们能够利用一套完整的质量特征对 Rdq 进行预测,误差率低于 5%。具体来说,梯度提升回归模型的误差率为 4.58%,随机森林模型的误差率为 4.88%。
了解 ML 模型的预测机制
研究评估了每个属性在预测质量指标方面的重要性。
- 设置:侧重于梯度提升回归模型,这些模型在训练后表现出最佳性能。
- 运行:应用特征的排列重要性和 Shapley 值。
- 发现:我们发现不同的解释方法显示出不同的原因。例如,与夏普利值相比,排列特征重要性突出显示 fa_ts_max 是更重要的特征(见图 3)。

| 图 3:使用 FPI(特征排列重要性排列)和 SHAP(夏普利值)方法对 Rdqmaxmean 预测的特征重要性等级进行可视化展示。 |
提高性能
本实验探索了将可解释性方法整合到 ML 模型开发过程中以提高模型性能的可能性。
-
设置:ML 模型中的变量根据特征的重要性从高到低进行分类,每次试验都要训练一个新的模型,并改变顶级特征的比例(p)。
-
运行:尝试只使用重要特征来提高模型的性能。
-
研究结果:通过将最重要的特征整合到训练数据集中,ML 模型的性能得到了提高。例如,只选择排列重要性最高的 20% 的最重要特征,MAPE 就从约 4.58 提高到了 4.4。

| 图 4:在 Rdq 预测中根据不同方法使用不同比例的最重要特征。 |
讨论
本案例研究展示了可解释机器学习(ML)方法对制造质量预测模型的益处。可解释性分数(如特征重要性)用于解释每个特征与模型预测能力的相关性。人类专家可以利用这种解释来分析训练有素的模型,并验证重要性高的特征是否对预测任务有意义。
ML 模型可以揭示输入特征与预测目标之间的新关系,但在质量预测环境中,由于缺乏数据,过度依赖某些特征可能会成为学习错误相关性的指标。可解释性方法可以作为模型验证和人工检查的工具。
此外,研究还表明,可以通过去除低级特征来改进模型。具体来说,如图 4 所示,只保留最重要的特征就能提高模型的准确性。这种方法不仅提高了预测的准确性,还减少了预测所需的传感器数量,从而降低了预测的计算成本。在生产过程中进行实时质量预测以检测潜在缺陷和偏离计划的情况时,重要的是要尽量减少预测所需的时间并提高预测频率。
在设计生产原型机时,同样重要的是在早期阶段对预测模型进行评估,以确定机器的最终传感器组。虽然原型机配备了许多传感器,但只有在对预测模型进行评估后,才会选择相关的传感器。
此外,使用简单且可解释的模型(Breiman,2001 年;Rudin 等人,2022 年)可能有利于制造业质量预测模型的开发。然而,简单性和准确性之间存在权衡(奥卡姆困境):模型越简单,准确性就越低。在案例研究中,简单决策树与更复杂的梯度提升树和随机森林之间的误差差异也体现了这种权衡。使用可解释性技术减少特征数量再次降低了模型的复杂性,并使最终模型更具可解释性。
总结
本研究展示了结合机器学习(ML)和可解释性技术来提高制造业表面质量预测模型性能的潜力。尽管可用数据有限,但基于可解释性技术的特征选择能够利用少量数据提高 ML 模型的有效性。
未来研究的目标是将可解释性方法扩展到铣削以外的制造工艺,并建立一个更全面的预测系统。此外,这些 ML 模型将被用作物理机器的数字孪生模型,并将应用参数优化方法来开发新的开发成果。这种整合不仅能提高模型的准确性,还能对机器操作进行实时微调,从而提高效率并降低成本。
相关文章:
利用可解释性技术增强制造质量预测模型
概述 论文地址:https://arxiv.org/abs/2403.18731 本研究提出了一种利用可解释性技术提高机器学习(ML)模型性能的方法。该方法已用于铣削质量预测,这一过程首先训练 ML 模型,然后使用可解释性技术识别不需要的特征并去…...

FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling
FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling 摘要:引言:背景3 flexMatch3.1 Curriculum Pseudo Labeling3.2 阈值预热3.3非线性映射函数实验4.1 主要结果4.2 ImageNet上的结果4.3收敛速度加速4.4 消融研究5 相关工作摘要: 最近提出的Fi…...
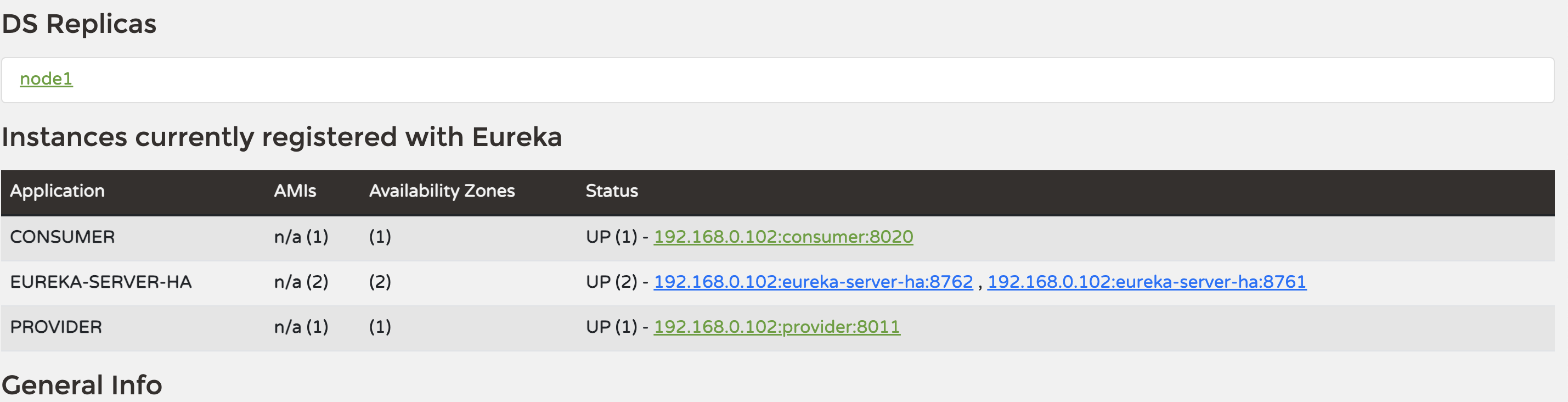
Spring Cloud 3.x 集成eureka快速入门Demo
1.什么是eureka? Eureka 由 Netflix 开发,是一种基于REST(Representational State Transfer)的服务,用于定位服务(服务注册与发现),以实现中间层服务的负载均衡和故障转移ÿ…...
线性代数 矩阵
一、矩阵基础 1、定义 一组数按照矩形排列而成的数表;形似行列式,区别点是 矩阵行列式符号()或[]| |形状方阵或非方阵方阵本质数表数属性A|A|是A诸多属性中的一种维度m *n (m 与n可以相等也可以不相等)n*n 同型矩阵 若A、B两个矩阵都是mn 矩阵&#x…...

【C语言】使用结构体实现位段
文章目录 一、什么是位段二、位段的内存分配1.位段内存分配规则练习1练习2 三、位段的跨平台问题四、位段的应用五、位段使用的注意事项 一、什么是位段 在上一节中我们讲解了结构体,而位段的声明和结构是类似的,它们有两个不同之处,如下&…...

univer实现excel协同
快速入门 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title><script src&q…...

JavaScript进阶笔记--深入对象-内置构造函数及案例
深入对象 创建对象三种方式 利用对象字面量new Object({…})利用构造函数 // 1. 字面量创建对象const obj1 {name: pig,age: 18};console.log(obj1); // {name: "pig", age: 18}// 2. 构造函数创建对象function Pig(name, age) {this.name…...

网络爬虫自动化Selenium模拟用户操作
自动化测试和网络爬虫在现代软件开发中占据着重要的位置。它们通过自动化用户操作,减少了人工重复操作的时间成本。Selenium作为一个功能强大且应用广泛的自动化工具,不仅能在不同的浏览器中运行自动化测试,还能进行跨平台测试,并允许与多种编程语言集成。本教程将介绍如何…...

尚硅谷rabbitmq 2024 流式队列2024指定偏移量 第55节答疑
rabbitmq的stream: 4、对比 autoTrackingstrategy方式:始终监听Stream中的新消息(狗狗看家,忠于职守)指定偏移量方式:针对指定偏移量的消息消费之后就停止(狗狗叼飞盘,回来就完) 这两种分别怎么写?java 在 RabbitMQ 中,…...

NSSCTF-WEB-pklovecloud
目录 前言 正文 思路 尝试 结尾 前言 许久未见,甚是想念. 今天来解一道有意思的序列化题 正文 思路 <?php include flag.php; class pkshow {function echo_name(){return "Pk very safe^.^";} }class acp {protected $cinder;public $neutron;public $…...
深入Postman- 自动化篇
前言 在前两篇博文《Postman使用 - 基础篇》《玩转Postman:进阶篇》中,我们介绍了 Postman 作为一款专业接口测试工具在接口测试中的主要用法以及它强大的变量、脚本功能,给测试工作人员完成接口的手工测试带来了极大的便利。其实在自动化测试上,Postman 也能进行良好的支…...

react-JSX
JSX理念 jsx在编译的时候会被babel编译为react.createELement方法 在使用jsx的文件中,需要引入react。import React from "react" jsx会被编译为React.createElement,所有jsx的运行结果都是react element React Component 在react中,常使用…...

深度对比:IPguard与Ping32在企业网络管理中的应用
随着网络安全形势日益严峻,企业在选择网络管理工具时需慎之又慎。IPguard与Ping32是目前市场上两款颇具代表性的产品,它们在功能、性能以及应用场景上各有优势。本文将对这两款产品进行深度对比,以帮助企业找到最合适的解决方案。 IPguard以其…...
AI测试之 TestGPT
如今最火热的技术莫非OpenAI的ChatGPT莫属,AI技术也在很多方面得到广泛应用。今天我们要介绍的TestGPT就是一个软件测试领域中当红的应用。 TestGPT是什么? TestGPT是一家总部位于以色列特拉维夫的初创公司 CodiumAI Ltd.,发布的一款用于测…...

JavaEE-进程与线程
1.进程 1.1什么是进程 每个应⽤程序运⾏于现代操作系统之上时,操作系统会提供⼀种抽象,好像系统上只有这个程序在运 ⾏,所有的硬件资源都被这个程序在使⽤。这种假象是通过抽象了⼀个进程的概念来完成的,进程可 以说是计算机科学…...
-equals与hashcode方法)
JAVA软开-面试经典问题(6)-equals与hashcode方法
1.equals方法 1.Object类中的equals方法比较的是两个对象的地址(底层原理是 比较的,即比较的是对象的地址) return (this obj);2.基本数据类型的包装类和String类都重写了equals方法。 基本数据类型:比较的是数值的是否相等 …...

计算机网络(以Linux讲解)
计算机网络 网络协议初识协议分层OSI七层模型TCP/IP五层模型--初识 网络中的地址管理IP地址MAC地址 网络传输基本流程网络编程套接字预备知识网络字节序socket编程UDP socketTCP socket地址转换函数Jsoncpp 进程间关系与守护进程进程组会话控制终端作业控制守护进程 网络命令TC…...

计算机网络基本架构知识点
1. 网络体系结构模型: - OSI 七层模型: - 物理层:是网络通信的基础层,负责在物理介质上传输比特流。该层定义了物理连接的标准,如电缆的类型、接口的形状、插头的规格等,以及信号的传输方式,包括…...
GES DISC 的 ATMOS L2 潜在温度网格上的痕量气体,固定场格式 V3 (ATMOSL2TF)
ATMOS L2 Trace Gases on Potential Temperature Grid, Fixed Field Format V3 (ATMOSL2TF) at GES DISC 简介 GES DISC 的 ATMOS L2 潜在温度网格上的痕量气体,固定场格式 V3 (ATMOSL2TF) 这是版本3的气溶胶痕量分子光谱(ATMOS)第二级产品…...

MLCC贴片电容不同材质区别:【及电容工作原理】
贴片电容的材质常规有:NPO(COG),X7R,X5R,Y5V 等,主要区别是它们的填充介质不同。在相同的体积下由于填充介质不同所组成的电容器的容量就不同,随之带来的电容器的介质损耗、容量稳定…...
)
手把手教你给STM32MP157开发板接上HDMI显示器(基于Sii9022A芯片与设备树配置)
STM32MP157开发板HDMI显示实战:从硬件连接到设备树配置全解析 引言 当你第一次拿到STM32MP157开发板时,最令人兴奋的莫过于看到图形界面在屏幕上亮起的那一刻。但现实往往很骨感——手头可能没有配套的LCD屏幕,而HDMI显示器却是大多数开发者桌…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...

Otter多模态大模型实战:从架构解析到部署应用的完整指南
1. 项目概述:当多模态大模型学会“看”与“说”最近在开源社区里,一个名为Otter的多模态大模型项目引起了我的注意。它来自EvolvingLMMs-Lab,这个实验室的名字就很有意思,“Evolving LMMs”—— 进化中的大型多模态模型。Otter 这…...

ARM Debug Interface v5.1架构解析与调试实践
1. ARM Debug Interface v5.1架构深度解析1.1 调试接口技术演进与核心价值ARM调试接口(ADI)技术历经多次迭代,v5.1版本作为当前主流标准,在嵌入式系统调试领域确立了关键地位。调试接口本质上是处理器核与外部调试工具之间的标准化通信桥梁,其…...