谷歌-BERT-第一步:模型下载
1 需求
需求1:基于transformers库实现自动从Hugging Face下载模型
需求2:基于huggingface-hub库实现自动从Hugging Face下载模型
需求3:手动从Hugging Face下载模型
2 接口
3.1 需求1
示例一:下载到默认目录
from transformers import BertModel, BertTokenizer# 初始化分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')# 现在您可以使用 tokenizer 和 model 进行推理或其他任务
示例二:下载到指定目录
from transformers import BertModel, BertTokenizer# 指定模型和分词器的名称
model_name = 'bert-base-uncased'# 指定下载路径
cache_dir = './test3'# 下载模型和分词器,并指定下载路径
model = BertModel.from_pretrained(model_name, cache_dir=cache_dir)
tokenizer = BertTokenizer.from_pretrained(model_name, cache_dir=cache_dir)# 现在你可以使用模型和分词器进行推理或其他任务了
print("123")3 .2 需求2
示例一:下载到默认目录
from huggingface_hub import snapshot_downloadsnapshot_download(repo_id="bert-base-uncased")示例二:下载到指定目录
from huggingface_hub import snapshot_downloadsnapshot_download(repo_id="bert-base-chinese", local_dir="./test2", local_dir_use_symlinks=False)3.3 需求3
手动导入模型和分词器
- 模型权重文件:pytorch_model.bin 或 tf_model.h5
- 模型配置文件:config.json
- 分词器的词汇表文件:vocab.txt
- 分词器配置文件:tokenizer.json、tokenizer_config.json
当手动下载 Hugging Face 模型时,通常需要以下类型的文件:
一、模型权重文件
- PyTorch 格式(.bin 或.pt)
- 如果模型是基于 PyTorch 开发的,其权重文件通常以
.bin或.pt格式存在。这些文件包含了模型的参数,例如神经网络的每层权重、偏置等信息。- 例如,对于一个预训练的 BERT 模型(PyTorch 版本),这些权重文件定义了模型如何将输入文本转换为有意义的表示。
- TensorFlow 格式(.h5 或.ckpt)
- 对于基于 TensorFlow 的模型,可能会有
.h5或者.ckpt格式的权重文件。.h5文件是一种常见的保存 Keras(TensorFlow 后端)模型的格式,它可以包含模型的结构和权重信息。.ckpt文件则是 TensorFlow 原生的检查点文件,主要用于保存模型在训练过程中的中间状态。二、模型配置文件
- JSON 或 YAML 格式
- 模型配置文件以 JSON 或 YAML 格式为主。这些文件描述了模型的架构,如模型的层数、每层的神经元数量、激活函数类型、输入输出形状等信息。
- 以 GPT - 2 模型为例,其配置文件会指定模型是由多少个 Transformer 块组成,每个块中的头数量、隐藏层大小等关键架构参数。
三、分词器(Tokenizer)相关文件
- 词汇表文件(.txt 或.pkl 等)
- 分词器用于将输入文本转换为模型能够处理的标记(tokens)。词汇表文件包含了模型所使用的所有词汇(对于基于单词的分词器)或者子词(对于基于子词的分词器,如 BPE、WordPiece 等)。
- 例如,对于一个基于 BPE 算法的分词器,词汇表文件定义了模型能够识别的所有子词单元。这个文件可能是一个简单的文本文件(
.txt),其中每行包含一个词汇或子词,也可能是经过序列化的 Python 对象(如.pkl文件,用于保存 Python 的字典等数据结构)。- 分词器配置文件(JSON 或 YAML 格式)
- 类似于模型配置文件,分词器配置文件描述了分词器的一些参数,如分词算法(BPE、WordPiece 等)、特殊标记(如开始标记、结束标记、填充标记等)的定义等。
具体需要下载哪些文件取决于模型的类型(如文本生成模型、图像分类模型等)、框架(PyTorch 或 TensorFlow 等)以及模型开发者所采用的存储和组织方式。
第一步
https://huggingface.co/
第二步
https://huggingface.co/models

第三步
https://huggingface.co/google-bert/bert-base-chinese

第四步
https://huggingface.co/google-bert/bert-base-chinese/tree/main


第五步 PyCharm手动添加模型和分词器

4 参考资料
huggingface下载模型文件(基础入门版)-CSDN博客
https://huggingface.co/docs/huggingface_hub/guides/download
相关文章:
谷歌-BERT-第一步:模型下载
1 需求 需求1:基于transformers库实现自动从Hugging Face下载模型 需求2:基于huggingface-hub库实现自动从Hugging Face下载模型 需求3:手动从Hugging Face下载模型 2 接口 3.1 需求1 示例一:下载到默认目录 from transform…...

FPGA实现PCIE采集电脑端视频缩放后转千兆UDP网络输出,基于XDMA+PHY芯片架构,提供3套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的PCIE方案我这里已有的以太网方案本博已有的FPGA图像缩放方案 3、PCIE基础知识扫描4、工程详细设计方案工程设计原理框图电脑端视频PCIE视频采集QT上位机XDMA配置及使用XDMA中断模块FDMA图像缓存纯Verilog图像缩放模块详解…...

Hi3061M开发板——系统时钟频率
这里写目录标题 前言MCU时钟介绍PLLCRG_ConfigPLL时钟配置另附完整系统时钟结构图 前言 Hi3061M使用过程中,AD和APT输出,都需要考虑到时钟频率,特别是APT,关系到PWM的输出频率。于是就研究了下相关的时钟。 MCU时钟介绍 MCU共有…...

C++入门基础知识110—【关于C++ if...else 语句】
成长路上不孤单😊😊😊😊😊😊 【14后😊///C爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于C if...else 语句的相关内容!…...

基于YOLO11深度学习的非机动车驾驶员头盔检测系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测、卷积神经网络
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

图像分类-demo(Lenet),tensorflow和Alexnet
目录 demo(Lenet) 代码实现基本步骤: TensorFlow 一、核心概念 二、主要特点 三、简单实现 参数: 模型编译 模型训练 模型评估 Alexnet model.py train.py predict.py demo(Lenet) PyTorch提供了一个名为“torchvision”的附加库,其中包含…...

excel 单元格嵌入图片
1.图片右键,设置图片格式 2.属性 随单元格改为位置和大小 这样的话,图片就会嵌入到单元格,也会跟着单元格的大小而改变...
GitHub简介与安装使用入门教程
1、Git与GitHub的简介 Git是目前世界上最先进的分布式控制系统,它允许开发者跟踪和管理源代码的改动历史记录等,可以将你的代码恢复到某一个版本,支持多人协作开发。它的核心功能包括版本控制、分支管理、合并和冲突解决等,其操作…...

HTML(五)列表详解
在HTML中,列表可以分为两种,一种为有序列表。另一种为无序列表 今天就来详细讲解一下这两种列表如何实现,效果如何 1.有序列表 有序列表的标准格式如下: <ol><li>列表项一</li><li>列表项二</li>…...

SparkSQL介绍及使用
SparkSQL介绍及使用 一、什么是SparkSQL(了解) spark开发时可以使用rdd进行开发,spark还提供saprksql工具,将数据转为结构化数据进行操作 1-1 介绍 官网:https://spark.apache.org/sql/ Spark SQL是 Apache Spark 用于…...

【聚星文社】3.2版一键推文工具更新啦
【聚星文社】3.2版一键推文工具更新啦。调试了好几个通宵就是为了效果和质量。 旧版尽早更新新版,从此告别手搓! 工具入口https://iimenvrieak.feishu.cn/docx/ZhRNdEWT6oGdCwxdhOPcdds7nof...

C++基础补充(03)C++20 的 std::format 函数
文章目录 1. 使用C20 std::format2. 基本用法3. 格式说明 1. 使用C20 std::format 需要将VisualStudio默认的标准修改为C20 菜单“项目”-“项目属性”,打开如下对话框 代码中加入头文件 2. 基本用法 通过占位符{}制定格式化的位置,后面传入变量 #…...

[论文笔记]DAPR: A Benchmark on Document-Aware Passage Retrieval
引言 今天带来论文DAPR: A Benchmark on Document-Aware Passage Retrieval的笔记。 本文提出了一个基准:文档感知段落检索(Document-Aware Passage Retrieval,DAPR)以及介绍了一些上下文段落表示的方法。 为了简单,下文中以翻译的口吻记录,…...

Spring Boot知识管理:智能搜索与分析
3系统分析 3.1可行性分析 通过对本知识管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本知识管理系统采用JAVA作为开发语言,Spring Boot框…...
 (进程调度/进程调度器类型/三种进程调度/调度算法))
操作系统(2) (进程调度/进程调度器类型/三种进程调度/调度算法)
目录 1. 介绍进程调度(Introduction to Process Scheduling) 2. 优先级调度(Priority Scheduling) 3. CPU 利用率(CPU Utilization) 4. 吞吐量(Throughput) 5. 周转时间…...
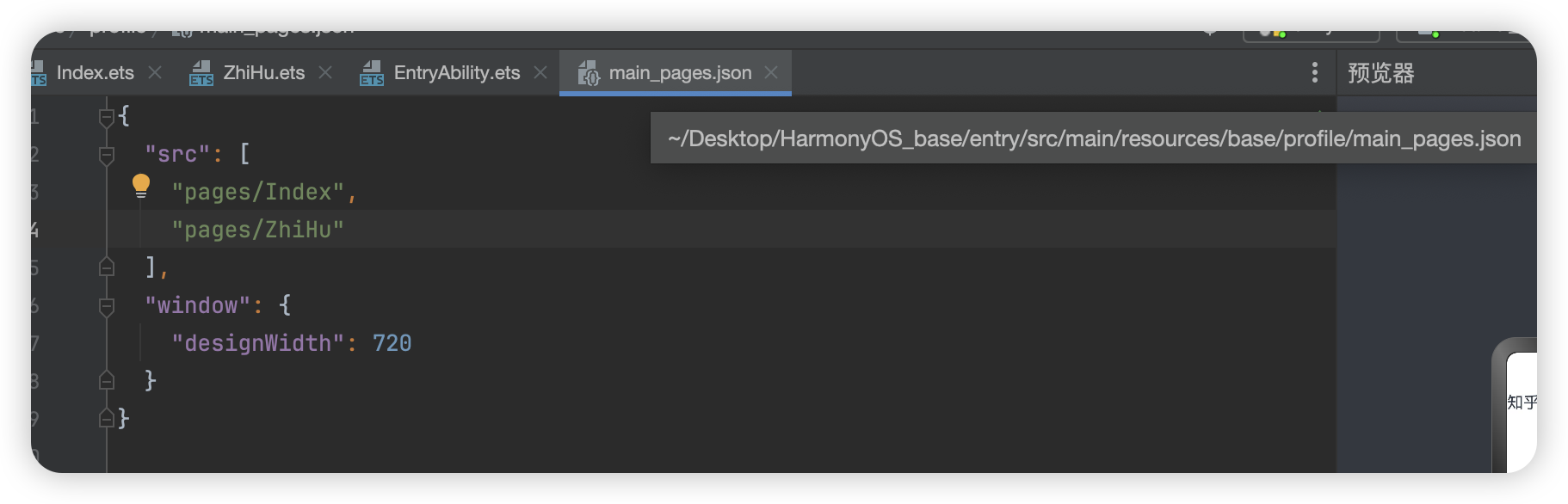
鸿蒙--知乎评论
这里我们将采用组件化的思想进行开发 在开发中默认展示的是首页也就是 pages/Index.ets页面 这里存放的是所有页面的配置文件,类似与uniapp中的pages.json 如果我们此时要更改默认显示Zh...
之间实现UDP通信(C语言版本))
2024 - 两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信(C语言版本)
两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信(C语言版本) 给女朋友对象写得,她不会,我就写了一个 为了帮助您在两台CentOS服务器上的1000个Docker容器(每台500个)之间实现UDP通信&…...

小程序该如何上架
小程序的上架流程通常包括准备工作、代码审核、人工审核以及上线发布等关键步骤。以下是一个详细的小程序上架指南: 一、准备工作 注册开发者账号: 在微信小程序平台或支付宝开放平台等相应的小程序发布平台上注册开发者账号。 开发小程序: …...

XMOJ3065 旅游线路
10分钟没啥思路就去看题解了,结果发现很蠢。 题目大意 有一条河,河的东侧和西侧分别有 n , m n,m n,m 个景点,每个景点有个权值。有 k k k 条船,每条船连接东侧和西侧的一个景点。定义一个旅游线路是通过船连接起来的景点序列…...

量化之一:均值回归策略
文章目录 均值回归策略理论基础数学公式 关键指标简单移动平均线(SMA)标准差Z-Score 交易信号实际应用优缺点分析优点缺点 结论 实践backtrader参数:正常情况:异常情况: 均值回归策略 均值回归(Mean Rever…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...

Go语言AI编程助手SDK:提升Cursor代码理解与生成精准度
1. 项目概述:一个为AI编程而生的Go语言SDK如果你是一名Go语言开发者,同时又在深度使用Cursor这样的AI辅助编程工具,那么你很可能已经感受到了一个痛点:如何让AI更精准、更高效地理解你的代码库,并在此基础上进行智能操…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

Vim-ai插件深度指南:在Vim中无缝集成AI提升开发效率
1. 项目概述:当Vim遇上AI,一场编辑器生产力的革命如果你和我一样,是个在终端里泡了十多年的老Vim用户,那你一定经历过这样的场景:面对一个复杂的函数重构,手指在键盘上飞舞,:s、%s、宏录制轮番上…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...