数据库常见面试
8道面试题
目录
目录
7道面试题
1.怎样进行sql优化
4、group by优化
5、limit优化
6、count优化
7、update优化
2.。怎样查看sql执行情况呢(哪个关键字),说说你对这个关键字的认识
4) possible_key:
5) key
3.说说你对innodb和 myisam的理解
4.char 和varchar的区别
5.innodb引擎底层结构是什么,为什么不用B树呢
B+树
6.事物你了解吗,详细说说
事物四大特性
并发事物问题
事物隔离级别
演示问题:
读未提交-脏读问题
读已提交-不可重复读
可重复读-幻读
7.主键使用自增ID好还是uuid(比较大的随机数)好呢
自增ID (Auto-Incrementing ID)
UUID (通用唯一识别码)
总结
8、什么情况下索引会失效
1.怎样进行sql优化
1、怎样进行sql优化
1)查询对where条件后的字段加索引,用于提升查询效率
2)explain查看执行情况,需要插入数据时批量插入
3)sql语句上,查询数量时尽可能用count(*)而不用count(字段)
4)在查询时,尽量不要进行回表查询,这就要求满足需求的情况下,不要使用select *
5)多条件时,考虑是不是可以使用最左前缀原则针对条件列进行索引
6)插入数据时,如果有主键,那么主键最好是顺序插入的且尽量不要太长,可以避免页分裂
7)模糊查询时,尽量不要开头加%
8)尽量不要使用or/in/not in,因为可能会造成索引失效
9)where条件后的字段(加索引)如果是varchar类型,那么一定要加’’
10)尽量不要将索引列进行运算
- 插入数据
- 批量插入:因为一条条插入时,每一条数据的插入都要与数据库建立连接,并且关闭连接
![]()
- 手动提交事物:
默认是自动提交,每提交一次insert语句就会提交一次事物,造成事物的频繁提交和关闭

- 主键顺序插入

顺序插入的性能要高于乱序插入,主键优化中讲解
- 大批量数据插入
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。操作如下·

- 客户端连接服务端时,加上参数 --local-infile
mysql --local-infile -u root -p
- 设置全局参数 local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
- 执行local指令,将准备好的数据加载到表结构中
local data local infile ‘/xx/yy/sql.log’ into table 表名 fields terminated by ‘,’ lines terminated by ‘\n’;

- 主键优化

页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据多大,会行溢出),根据主键排列。
主键顺序插入时,当第一个page写满后,再去申请第二个page

页和页之间需要维护一个双向指针

乱序插入时:可能发生页分裂

最后变成:

页合并:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间允许被其他记录声明使用,当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。

合并后:

主键设计原则:
- 满足业务需求的情况下,尽量降低主键的长度
二级索引下,二级索引的叶子节点中挂的是主键,如果主键较长,二级索引比较多,
将会占用大量的磁盘空间,在搜索时将会耗费大量的磁盘IO
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
顺序插入时,当一个page写完后才会写另一个page,而乱序插入可能会引起页分裂现象
- 尽量不要使用UUID作为做主键或者其他自然主键,如身份证号
主键较长,二级索引比较多,将会占用大量的磁盘空间,在搜索时将会耗费大量的 磁盘IO
- 业务操作时,避免对主键的修改
- order by优化
- Using filesort;通过表的索引或全表扫猫,读取满足条件的教据行,然后在排序缓冲区sort bufter中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort排序。
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高
排序字段加上索引

两个排序字段,一正一倒呢?


所以我们优化 时就是尽可能将using filesort给优化点
可以通过创建索引来解决

优化后的结果为:

排序字段不加索引:

总结:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则 (ASC/DESC)
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小,sort buffer_size(默认256k)。

4、group by优化
主要是针对索引进行优化。验证下加索引与不加索引时 分组的效率

加上索引后,效率会得到提升

关于索引的使用

5、limit优化
需要时间较久,如果有1000万条数据,时间大概会在10s级别

可以通过覆盖索引+子查询的方式优化

6、count优化

count的用法:

用法截图如下:

效率:

7、update优化
行锁还是表锁
两个事物,当都修改id(有索引)对应的信息时
update course set name = ‘kafka’ where id=4
update course set name = ‘java’ where id=1
两个事物的修改操作都能成功,因为此时锁的是行级锁
两个事物,当都修改name(无索引)对应的信息时
update course set name = ‘kafka’ where name=’java’
update course set name = ‘java’ where name=’mysql’
第一个事物会马上修改成功,但是第二个事物的修改会等第一个事物提交后才能修改成功,因为name没有索引,此时锁的是表级锁
为name加上索引后,两个事物都修改name对应的信息时
两个事物的修改操作都能成功,因为此时锁的是行级锁
2.。怎样查看sql执行情况呢(哪个关键字),说说你对这个关键字的认识
explain执行计划 通过explain我们可以模拟一个优化器对sql语句进行优化,进而提升查询效率,以下是explain查询结果中的几个重要字段
- id:
select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下,ID不同,值越大,越先执行)
多表查询展示id值相同:

多表查询展示id值不同:此时先执行id大的

- select_type
表示select的类型,常见的取值有simple(简单表、即不使用表链接或子查询)、primary(主查询,即外层的查询)、union(union中的第二个或者后面查询语句)、subquery(包含了子查询)等
- type
表示连接类型,性能由好到差的连接类型为null、system、const、eq_ref、ref、range、index、all
null:一般的业务开发不会优化到null,因为不访问任何表的时候才是null

system:一般是访问系统表时才可能会是system
const:根据主键或者唯一性索引进行访问一般会是const

ref:如果我们使用非唯一性索引查询时会出现

range: 对普通索引字段范围查找

index:
当查询能够仅通过扫描索引来满足而无需访问实际的数据行时,连接类型可能会是index

all:性能最低,需要全表扫描,查询的字段一般是非索引字段

4) possible_key:
在这张表中可能用到的索引,一个或多个
5) key
实际使用的索引,没有则为null
- key_len
表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
- rows
MySOL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。
- filtered
表示返回结果的行数占需读取行数的百分比,filtered 的值越大越好
- extra
额外信息展示
3.说说你对innodb和 myisam的理解
介绍
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在MYSOL 5.5之后,lnnoDB是默认的 MySOL存储引擎。
特点:
DML操作遵循ACID模型,支持事务,
行级锁,提高并发访问性能;
支持外键 FOREIGN KEY约束,保证数据的完整性和正确性
myisam是mysql早期默认的存储引擎
特点:
不支持事物、不支持外键
支持表锁,不支持行锁
访问速度快、
1)innodb支持事物,myisam不支持
2)inndb存储引擎对应的表会有一个ibd文件,用于存储索引、数据、结构,而myisam对用三个文件,分别存储索引、数据、结构
3)innodb支持行级锁,而myisam支持表级锁,所以innodb存储引擎在高并发下冲突小
4)myisam是在mysql5.5版本前的默认存储引擎,之后变成了innodb
5)innodb支持外键约束,myisam不支持
4.char 和varchar的区别
1、char性能高,varchar性能较低,原因是需要计算数据的长度进而确定需要使用的空间
2、char是定长的,varchar是变长的,更节省空间,使空间得倒充分利用
5.innodb引擎底层结构是什么,为什么不用B树呢
B+树
B+树

和B树相似,但是所有的数据都会出现在叶子节点,而不是每个节点都会挂载真实数据,且最后的叶子节点形成了一个单向链表,方便范围查找,叶子节点是用来存放数据的,非也字节点起到索引的作用
为什么不采用B树?(面试题)
数据保存:对于B tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
查询效率稳定:B+树每次查询数据都是遍历到叶子节点,很稳定,而B树则不一定遍历到哪一层
范围查找上:B+树找到最小值后,根据叶子节点形成的链表结构就可以找到最大值,B树还得需要二分查找才可以找到最大值
6.事物你了解吗,详细说说
事物四大特性
原子性:事物是不可分割的最小操作单元,要么全部成功,要么全部失败
一致性:事物完成时,必须使所有的数据都保持一致状态
隔离性:数据库系统提供的隔离机制,保证事物在不受外部并发操作影响的独立环境下运行
持久性:事物一旦提交或回滚,他对数据库中数据的改变就是永久的
并发事物问题
| 问题 | 描述 |
| 脏读 | 一个事物读到了另一个事物还没提交的数据 |
| 不可重复读 | 一个事物先后读取同一条记录,但是读到的数据不同,称之为不可重复读 |
| 幻读 | 一个事物按照条件读取数据,并没有对应的数据,但是在插入时又发现了对应的数据,就像出现了幻影一样 |
事物隔离级别

查看事物的隔离级别
select @@transaction_isolation;

设置事物的隔离级别
set [global | session] transaction isolation level 级别
演示问题:
读未提交-脏读问题
首先将隔离级别定为 读未提交
一个事物:
set session transaction isolation level read UNCOMMITTED;
start TRANSACTION;
select *
from account
另一个事物
start TRANSACTION;
update account set money = money-1000 where name = '张三';
//未提交但是上一个事物已经读到数据了
读已提交-不可重复读
set session transaction isolation level read COMMITTED;
解决脏读问题,会有不可重复读问题
事物1

事物2

事物1先开始查询一遍数据,
事物2插入了一条数据并提交
事物1在查询一边数据,发现此时读的数据和之前读的不一样了,就验证了不可重复读问题
可重复读-幻读
解决了不可重复读的问题,但是解决不了幻读问题
一个事物A里面读到的东西是一样的,不管中间其他事物有没有修改数据并提交,当事物A提交后在查询才能查到最新的数据
幻读-演示:
事物1;

查询时没有某条数据,但是插入时就报错,说主键冲突,像tm幻觉一样
事物二:插入一条数据

不可重复读侧重于修改
幻读侧重于插入
串行化解决幻读的问题,因为串行化同一时间只支持一个事物在操作,其他事物处于阻塞状态, 最安全,但是效率最低
7.主键使用自增ID好还是uuid(比较大的随机数)好呢
自增ID (Auto-Incrementing ID)
优点:
- 简单易用,不需要额外的存储或计算资源来生成。
- 插入性能好,因为只需要简单地递增一个计数器。
- 顺序的,这可以使得范围查询更快。
- 占用空间小,通常是整型数据。
缺点:
- 如果表有多个并发写入者,则需要锁定机制来确保唯一性。
- 可能会暴露一些关于数据库内部结构的信息,比如插入顺序等。
- 在分布式系统中实现起来可能更复杂,因为需要跨多个节点协调ID的生成。
UUID (通用唯一识别码)
优点:
- 全局唯一性,理论上不会重复。
- 不连续的值,可以增加数据的安全性,因为它们不透露插入顺序。
- 在分布式环境中更容易管理,因为每个节点都可以独立生成UUID。
- 支持多种生成方式,包括基于时间、随机数以及名字空间等方式。
缺点:
- 占用更多存储空间,通常是16字节。
- 随机生成的UUID可能会导致B树索引中的页面分裂,影响写入性能。
- 查询性能可能受到影响,尤其是当涉及到范围查询时。
总结
选择哪种方案取决于具体的应用场景:
uuid不是顺序插入的,会导致页分裂,效率底下
uuid比较大,在大数据两下占用空间比较多,造成索引扫描时消耗大
- 如果你的应用程序对插入顺序不敏感,并且对读取性能要求较高,或者是在一个高度分布式的环境中运行,那么UUID可能是更好的选择。
- 如果你的应用需要快速的插入性能,并且对数据的物理存储顺序有一定的需求,或者是在一个不太关心全局唯一性的单一服务器上运行,那么自增ID可能更适合。
8、什么情况下索引会失效
1)模糊查询时,开头加%会导致索引失效
2)使用or/in/not in,会导致索引失效
3) 一个联合索引,如果使用过程中跳过了联合列中的某一列,那么该列后面的列索引失效
4)索引列通过表达式运算会导致索引失效
5)某个varchar类型的字段使用时不加引号导致索引失效
相关文章:
数据库常见面试
8道面试题 目录 目录 7道面试题 1.怎样进行sql优化 4、group by优化 5、limit优化 6、count优化 7、update优化 2.。怎样查看sql执行情况呢(哪个关键字),说说你对这个关键字的认识 4) possible_key: 5) key 3.说说你对innodb和 myisam的理解 …...
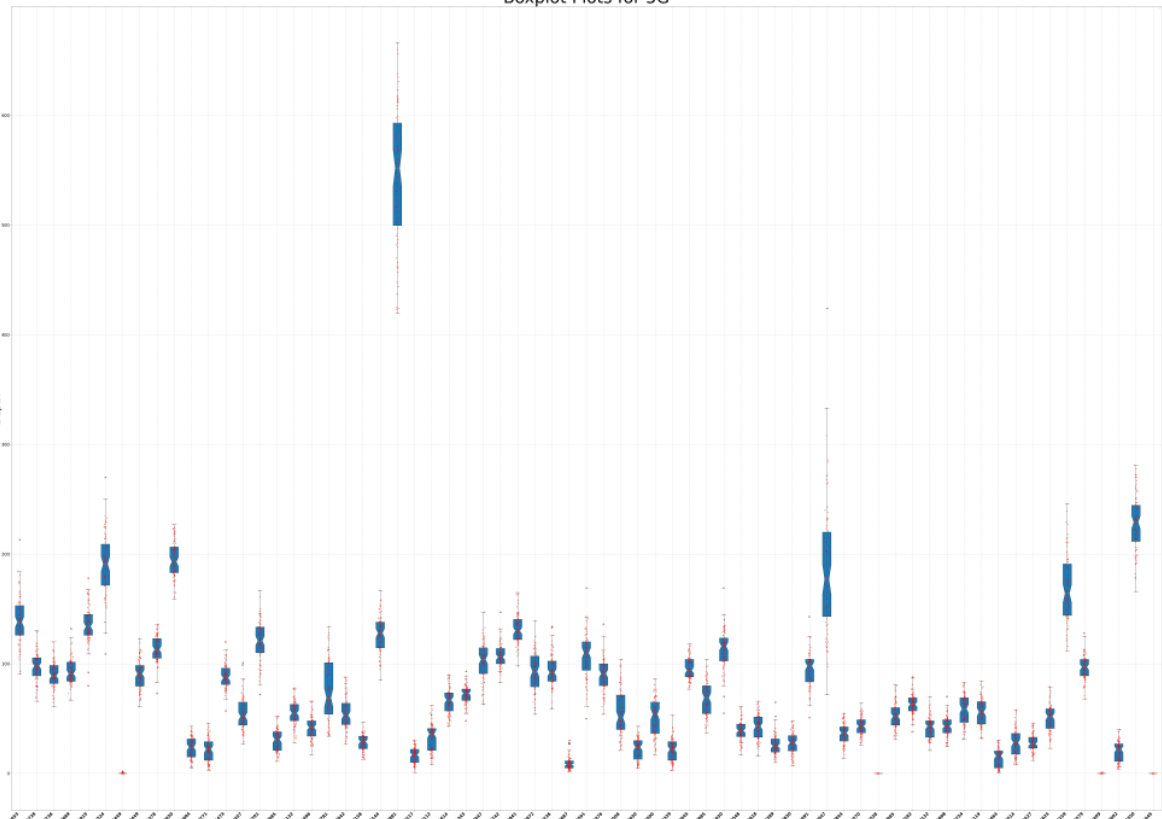
boxplot 绘制箱线图,添加数据点
先看效果图 import matplotlib.pyplot as plt #! 解决不显示的问题:中文设置为宋体格式 plt.rcParams[font.family] ["Times New Roman", SimSun]def plot_boxplot(data_list, out_file, x_custom_labels):# 画图fig, ax plt.subplots(figsize(90, 6…...

用sdkman管理多个jdk切换
前言 最近项目前后端进行升级,需要在jdk8和jdk17两个版本切换。最简单的是通过手动切换,但切换过程太繁琐,修改环境变量,达到切换目的。于是尝试其它解决方案,最终确实使用sdkman工具。 sdkman 是一款面向Java开发者的…...

【AIGC】ChatGPT提示词Prompt高效编写模式:结构化Prompt、提示词生成器与单样本/少样本提示
💯前言 在如今AI技术迅猛发展的背景下,尽管像ChatGPT这样的大型语言模型具备强大的生成能力,但它们的输出质量有时仍难以完全满足我们的预期。为了让ChatGPT生成更加准确、可靠的内容,掌握高效的Prompt编写技巧变得尤为重要。本文…...
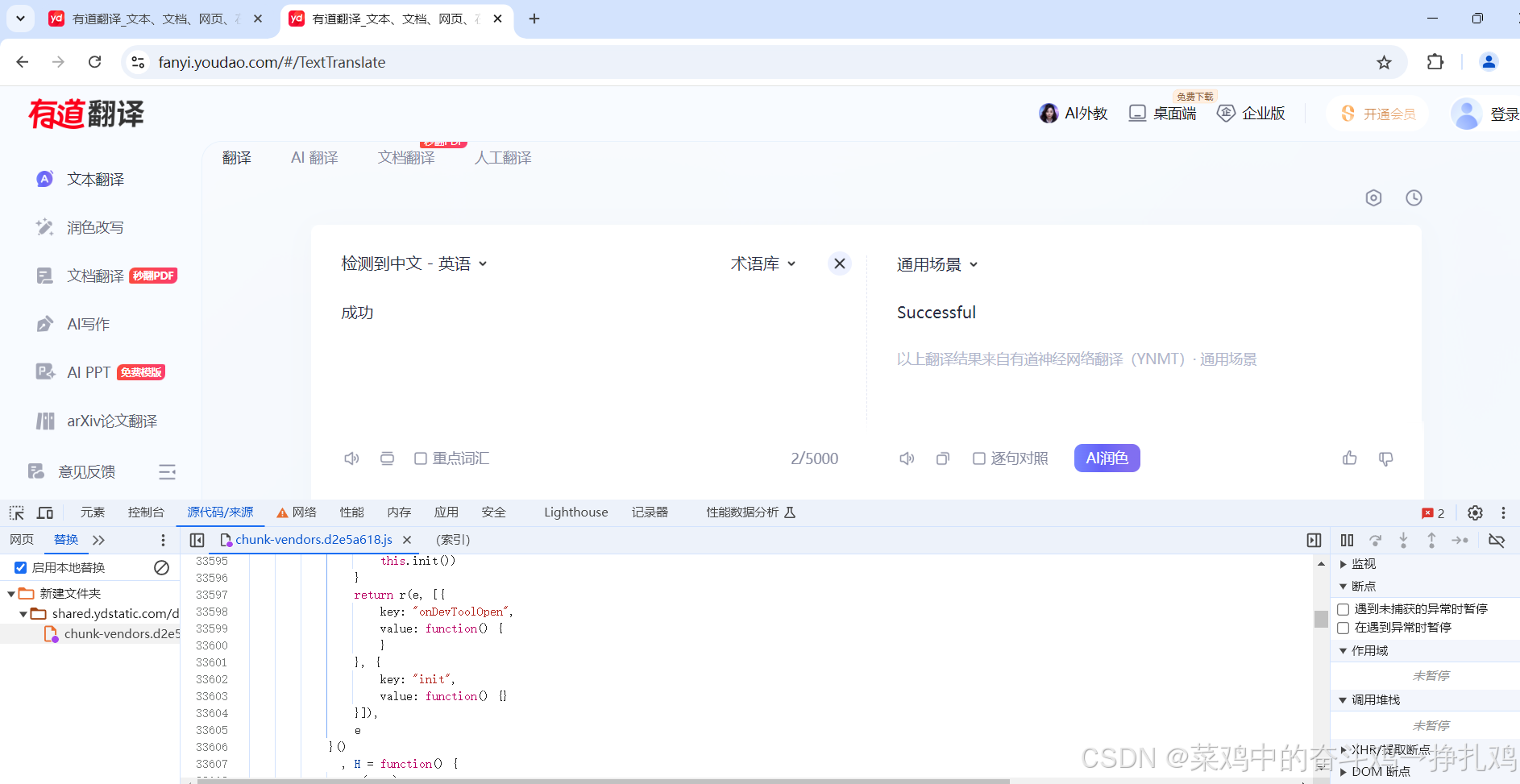
反调式实战(有道翻译窗口弹出)
1.添加脚本断点实现源码获取 2.Function构造器构造debugger 因为是窗口被弹出的情况,所以window.closefunction()构造debugger。 3.定位到影响弹出的JavaScript代码片段 反调试思想:置空和替换,所以将其JavaScript进行注释或者删除。 这里主…...

verilog端口使用注意事项
下图存在组合逻辑反馈环,即组合逻辑的输出反馈到输入(赋值的左右2边存在相同的信号),此种情况会造成系统不稳定。比如在data_in20的情况下,在data_out0 时候,输出的数据会反馈到输入,输入再输出,从而造成不…...

Docker常用命令大全汇总
Docker是一种流行的容器化平台,可以在一个独立的、隔离的环境中构建、部署和运行应用程序。了解Docker常用命令可以帮助我们更高效地管理容器,快速开发和部署应用。本文将整理一系列Docker的常用命令,便于日常使用和学习。 1 Docker基础命令 1.1 启动/停止/重启docker # …...

LVS-DR+Keepalived 高可用群集部署
LVS-DRKeepalived 高可用群集部署 Keepalived 的工作原理LVSKeepalived 高可用群集部署配置负载调度器(主、备相同)关闭防火墙和核心防护及准备IPVS模块配置keeplived(主、备DR 服务器上都要设置)启动 ipvsadm 服务调整 proc 响应…...

【elasticsearch】安装和启动
启动 Elasticsearch 并验证其是否成功运行通常涉及以下步骤: 下载和安装 Elasticsearch: 访问 Elasticsearch 官方网站下载页面:https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html根据你的操作系…...
理解与实践篇)
Golang 逃逸分析(Escape Analysis)理解与实践篇
Golang 逃逸分析(Escape Analysis)理解与实践篇 文章目录 1.逃逸分析2.相关知识(栈、堆、GC分析)3.逃逸分析综合-实践 demo 逃逸分析(Escape Analysis)是编译器在编译期进行的一项优化技术,是Gl…...

React入门 9:React Router
1. 什么是路由 路由(routing)就是通过互联的网络把信息从源地址传输到目的地址的活动。 以上是中文维基百科对路由的解释。通俗的来讲,把一个地方的信息传输到他想去的目的地的过程,就叫路由。 2. 用代码解释路由 需求:…...
)
MATLAB基础应用精讲-【数模应用】Bland-Altman图(附python和R语言代码实现)
目录 前言 几个高频面试题目 Bland-altman图:如何改变y轴 算法原理 Bland-Altman一致性分析 一致性界限 1. 背景介绍 2. Bland-Altman 法 3. batplot 命令介绍 4. 应用实例 Prism GraphPad实现Bland-Altman图 1.输入数据 2.从数据表中选择Bland-Altman分析 3.检…...
:中兴面经)
ARM/Linux嵌入式面经(四一):中兴面经
1. 请介绍一下您在嵌入式系统开发中的项目经验。 在嵌入式系统开发领域,我积累了丰富的项目经验,这些经验不仅锻炼了我的技术能力,也让我对嵌入式系统的设计和实现有了更深入的理解。以下是我参与的一个具有代表性的嵌入式系统开发项目的详细介绍: 项目背景 该项目是为一…...
鸿蒙虚拟运行环境
加一个环境变量:%SystemRoot%\System32\Wbem pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt for /f %%i in (findstr /i . hyper-v.txt 2^>nul) do dism /online /norestart /add-package:"%SystemRoot%…...
SpringCloud-Consul
为什么引入 Consul 简介以及安装 控制台 localhost:8500 服务注册与发现 服务端 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-discovery</artifactId><exclusions><exclusio…...

nginx搭建负载均衡
准备工作 两台虚拟机,或者本地启动两个相同应用,在不同的端口上安装好的nginx,在linux上两个版本的hexo,或者其他应用,方便观察是否进行了负载均衡 启动服务 在两台虚拟机上启动项目,这里以hexo为例 服务器…...

灵当CRM data/pdf.php 任意文件读取漏洞复现
0x01 产品简介 灵当CRM是一款专为中小企业打造的智能客户关系管理工具,由上海灵当信息科技有限公司开发并运营。广泛应用于金融、教育、医疗、IT服务、房地产等多个行业领域,帮助企业实现客户个性化管理需求,提升企业竞争力。无论是新客户开拓、老客户维护,还是销售过程管…...

Python 批量转换 Shapefile 为 GeoJSON
批量转换 Shapefile (.shp) 为 GeoJSON 文件的脚本详解 🗺️🔄 在地理信息系统(GIS)和遥感领域,Shapefile(.shp)格式与GeoJSON格式是两种常用的数据格式。Shapefile 作为矢量数据的标准格式之一…...

软考《信息系统运行管理员》- 4.1信息系统软件运维概述
4.1信息系统软件运维概述 文章目录 4.1信息系统软件运维概述信息系统软件运维的概念信息系统软件的可维护性及维护类型对软件可维护性的度量可以从以下几个方面进行:软件维护分类: 信息系统软件运维的体系1.**需求驱动**2.**运维流程**3.**运维过程**4.*…...

Leetcode 3319. K-th Largest Perfect Subtree Size in Binary Tree
Leetcode 3319. K-th Largest Perfect Subtree Size in Binary Tree 1. 解题思路2. 代码实现 题目链接:3319. K-th Largest Perfect Subtree Size in Binary Tree 1. 解题思路 这一题其实就是一个很常见的树的遍历,我们自底向上遍历每一个子树&#x…...

诺和诺德牵手OpenAI,能否夺回“药王”之位?
01 诺和诺德牵手OpenAI就在最近,诺和诺德(Novo Nordisk)宣布与OpenAI合作,消息发布后,诺和诺德股价短线上涨近4%。很多人或许不知道“诺和诺德”,但“司美格鲁肽”却广为人知,诺和诺德正是研发出…...

别再只盯着CVE-2017-7529复现了,聊聊Nginx缓存机制下的那些‘信息泄露’风险
深入解析Nginx缓存机制与敏感信息防护实践 Nginx作为现代Web架构的核心组件,其高效的缓存机制在提升性能的同时也隐藏着不容忽视的安全隐患。当开发者们热衷于讨论CVE-2017-7529这类高危漏洞的复现时,我们更需要将目光投向日常配置中那些容易被忽视的信息…...

物联网平台资本逻辑与开发实战:从涂鸦融资看行业价值回归
1. 从资本视角看物联网平台:一场关于“入口”与“生态”的持久战最近和几个做硬件的朋友聊天,大家不约而同地提到了一个词:“上云”。这个“云”,指的就是物联网开发平台。从智能家居的插座、灯泡,到工业产线上的传感器…...

UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法
UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法 如果你正在开发UEFI驱动或应用,事件机制(Event)一定是绕不开的核心功能。但看似简单的WaitForEvent和CreateEvent,在实际编码中却暗藏玄机。本文将…...

东南亚1.5亿数字钱包用户如何覆盖?Antom收单解决方案拆解
在东南亚,很多用户第一次完成线上付款可能不是通过信用卡,而是通过自己熟悉的本地电子钱包。从印尼的GoPay、DANA,到菲律宾的GCash,再到泰国的TrueMoney、马来西亚的Touch ‘n Go,电子钱包已经深度融入当地人的日常消费…...

私有化多用户AI代码助手:基于开源LLM的部署与协作实践
1. 项目概述:一个面向多用户的代码助手开源项目最近在逛GitHub的时候,发现了一个挺有意思的项目,叫openclaw-multiuser。光看名字,你可能会有点懵,“openclaw”是啥?“多用户”又是指什么?简单来…...

自动驾驶系统商业化策略:硬件与软件协同设计解析
1. 自动驾驶系统的商业策略框架解析自动驾驶系统(Autonomous Driving System, ADS)作为智能交通领域的核心技术,其商业化落地需要硬件(SSH)与软件策略的协同设计。从技术架构来看,ADS由感知层、决策层和执行…...

Beyond Compare 5 开源密钥生成器:逆向工程与授权机制的深度解析
Beyond Compare 5 开源密钥生成器:逆向工程与授权机制的深度解析 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件安全与逆向工程领域,授权验证机制始终是开发者与安…...

非线性系统安全控制:双相对度CBF框架与应用
1. 非线性系统安全控制基础在机器人控制和自动化系统领域,确保系统在复杂环境中的安全性是首要任务。控制屏障函数(Control Barrier Functions, CBFs)作为一种强大的数学工具,近年来已成为安全关键控制系统设计的核心方法。与传统…...

ThinkPad风扇控制终极指南:5分钟告别噪音与过热烦恼
ThinkPad风扇控制终极指南:5分钟告别噪音与过热烦恼 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾因ThinkPad风扇的"直升机起飞"声而烦…...