Java通过RAG构建专属知识问答机器人_超详细
RAG:融合检索与生成的文本精准生成技术
检索增强生成(RAG)是一种技术,它通过结合检索模型和生成模型来提高文本生成的准确性。具体来说,RAG首先利用检索模型从私有或专有的数据源中搜索相关信息,然后将这些信息提供给生成模型,如大型语言模型(LLM),以生成更加准确、基于上下文的回复。这种方法有助于减少大模型在生成过程中可能出现的“幻觉”现象,并且能够使模型的回答更贴合企业的特定数据,从而提高了回答的精确度与相关性。这样,在使用大模型时,即使面对企业特有的知识或数据,也能获得更为精准的答案。
Spring AI:提升Java AI开发效率与灵活性的解决方案
我们使用了Spring AI来做这个检索增强。
之所以选择Spring AI,是因为在过去用Java编写AI应用时面临的一个主要困境是没有非常标准的Java封装。
现在,Spring项目推出了一套可以兼容市面上主要各类生成任务的接口——Spring AI,极大地解决了这一问题。
Spring AI通过标准化不同AI提供者的接口实现,使得开发者能够一次编写代码,仅通过修改配置即可轻松切换不同的AI实现。
同时,它直接兼容Flux流输出,简化了与基于流的机器人模型的集成。通过良好的抽象设计,Spring AI显著减少了程序员在对接不同类型接口时查阅文档和迁移实现的工作量,为基于Java的AI开发带来了极大的便利性和效率提升。因此,采用Spring AI不仅提高了开发效率,还增强了项目的可维护性与灵活性。
Spring生态AI框架:Spring AI Alibaba,赋能Java开发者高效对接多AI服务商
Spring AI Alibaba 是基于 Spring 生态系统设计的用于AI工程的应用框架,特别适合 Java 和 Spring Boot 开发者。它通过提供一套统一的抽象接口,标准化了不同AI服务提供商(如阿里云、OpenAI等)的接入方式,使得开发者能够轻松切换AI服务而无需大幅改动代码。此外,Spring AI Alibaba 集成了阿里云百炼系列的多个模型,支持对话、文本生成图像等功能,并提供了诸如Prompt Template等实用工具来简化开发过程。其核心优势在于极大提高了AI应用开发的效率与灵活性,同时保持了与现有Java Spring Boot项目的良好兼容性。
增强检索:打造PDF财务报表查询后端代码
为了通过检索增强的方式读取一个阿里巴巴的财务报表PDF并提供对外服务,我们需要按照以下步骤进行:
1. 确保前置条件
- JDK版本:确保你的JDK版本在17及以上。
- Spring Boot版本:确认使用的Spring Boot版本为3.3.x或更高。
- API Key申请:访问阿里云百炼页面,登录账号后开通“百炼大模型推理”服务,并创建一个新的API Key。将此Key配置到环境变量中:
export AI_DASHSCOPE_API_KEY=YOUR_VALID_API_KEY并且,在application.properties文件里添加:
spring.ai.dashscope.api-key: ${AI_DASHSCOPE_API_KEY}2. 添加仓库与依赖
由于spring-ai-alibaba-starter尚未发布到Maven中央仓库,因此需要在项目的pom.xml文件中添加如下仓库设置来支持获取最新快照版本及里程碑版本:
<repositories><repository><id>sonatype-snapshots</id><url>https://oss.sonatype.org/content/repositories/snapshots</url><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository></repositories>
然后添加必要的依赖项:
<dependencies><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>1.0.0-M2</version></dependency><!-- 其他依赖 -->
</dependencies>
3. 编写RAG服务相关代码
首先定义RagService类用于处理索引构建和查询逻辑。这包括向量存储、文档检索器以及如何使用这些组件来处理来自客户端的请求。
public class RagService {private final ChatClient chatClient;private final VectorStore vectorStore;private final DashScopeApi dashscopeApi = new DashScopeApi("您的API密钥");DocumentRetriever retriever;public RagService(ChatClient chatClient, EmbeddingModel embeddingModel) {this.chatClient = chatClient;vectorStore = new DashScopeCloudStore(dashscopeApi,new DashScopeStoreOptions("阿里巴巴财报知识库"));retriever = new DashScopeDocumentRetriever(dashscopeApi,DashScopeDocumentRetrieverOptions.builder().withIndexName("阿里巴巴财报知识库").build());}// 构建索引public String buildIndex() {String filePath = "/path/to/your/financial_report.pdf";DocumentReader reader = new DashScopeDocumentCloudReader(filePath, dashscopeApi, null);List<Document> documentList = reader.get();vectorStore.add(documentList);return "SUCCESS";}// 查询方法public StreamResponseSpec queryWithDocumentRetrieval(String message) {StreamResponseSpec response = chatClient.prompt().user(message).advisors(new DocumentRetrievalAdvisor(retriever, DEFAULT_USER_TEXT_ADVISE)).stream();return response;}
}4. 创建Controller以暴露REST API
最后,我们需要创建一个控制器类来接收HTTP请求,并调用之前定义的服务方法。
@RestController
@RequestMapping("/ai")
public class RagController {private final RagService ragService;public RagController(RagService ragService) {this.ragService = ragService;}@GetMapping("/steamChat")public Flux<String> generate(@RequestParam(value = "input", defaultValue = "2024年6月止,云智能集团的营收是多少?") String input, HttpServletResponse httpResponse) {StreamResponseSpec chatResponse = ragService.queryWithDocumentRetrieval(input);httpResponse.setCharacterEncoding("UTF-8");return chatResponse.content();}@GetMapping("/buildIndex")public String buildIndex() {return ragService.buildIndex();}
}通过上述步骤,我们实现了基于Spring Cloud Alibaba框架下的检索增强功能,能够从指定的PDF文件中提取信息并通过HTTP接口返回给用户。需要注意的是,在实际部署前,请确保已经完成了所有必要的环境配置,特别是关于API密钥的安全管理和正确配置。
构建React流式聊天应用:从零开始的实现攻略
基于提供的知识,我们可以分析出构建一个支持流式输出的前端项目需要遵循一定的步骤。这里的项目将使用React框架来创建,并与后端服务进行交互以处理用户输入并显示响应。后端接口返回的是flux<String>数据类型,这意味着客户端能够以渐进的方式接收和展示信息,而非等待全部数据加载完毕后再一次性展示。
分析
从给出的知识来看,我们已经有了关于如何设置基础React环境、以及如何处理流式数据请求的具体示例。这些例子非常适合用来作为本问题解决方案的基础。接下来将详细介绍如何根据要求实现这样一个前端应用。
实现步骤
首先,确保你已经安装了Node.js和npm(或yarn),然后按照以下步骤操作:
- 初始化一个新的React应用
npx create-react-app rag-chat-frontend
cd rag-chat-frontend
npm install- 修改
public/index.html文件(如果需要自定义HTML头部等信息):不过在这个案例中,我们可以直接使用默认生成的内容。
- 更新
src/index.js以引入应用程序入口点:
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';ReactDOM.render(<React.StrictMode><App /></React.StrictMode>,document.getElementById('root')
);- 编写主组件
src/App.js:
import React from 'react';
import ChatComponent from './components/ChatComponent';function App() {return (<div className="App"><ChatComponent /></div>);
}export default App;- 创建聊天组件
src/components/ChatComponent.js来处理用户输入及流式数据接收:
import React, { useState } from 'react';function ChatComponent() {const [input, setInput] = useState('');const [messages, setMessages] = useState('');const handleInputChange = (event) => {setInput(event.target.value);};const handleSendMessage = async () => {try {const response = await fetch(`http://localhost:8080/ai/steamChat?input=${input}`);if (!response.ok) throw new Error('Network response was not ok');const reader = response.body.getReader();const decoder = new TextDecoder('utf-8');let done = false;while (!done) {const { value, done: readerDone } = await reader.read();done = readerDone;const chunk = decoder.decode(value, { stream: true });setMessages((prevMessages) => prevMessages + chunk);}setMessages((prevMessages) => prevMessages + '\n\n=============================\n\n');} catch (error) {console.error('Failed to fetch', error);}};return (<div><inputtype="text"value={input}onChange={handleInputChange}placeholder="Enter your message"/><button onClick={handleSendMessage}>Send</button><div><h3>Messages:</h3><pre>{messages}</pre></div></div>);
}export default ChatComponent;- 启动你的React应用:
npm start这将打开浏览器并自动导航到 http://localhost:3000/ ,你可以在这里测试你的聊天界面。
小结
通过上述步骤,我们建立了一个基本的聊天应用程序界面,它可以通过发送GET请求至指定URL (http://localhost:8080/ai/steamChat) 来与后端通信。该请求会携带用户的输入文本参数。当后端开始流式地返回数据时,前端应用程序会逐步解析这些数据片段,并即时更新显示给用户。这种方式非常适合于实时性较强的场景,如在线聊天或实时问答系统。
相关文章:

Java通过RAG构建专属知识问答机器人_超详细
RAG:融合检索与生成的文本精准生成技术 检索增强生成(RAG)是一种技术,它通过结合检索模型和生成模型来提高文本生成的准确性。具体来说,RAG首先利用检索模型从私有或专有的数据源中搜索相关信息,然后将这些…...

2.1 使用点对点信道的数据链路层
欢迎大家订阅【计算机网络】学习专栏,开启你的计算机网络学习之旅! 文章目录 前言1 通信信道类型2 数据链路3 帧4 透明传输5 差错检测 前言 在计算机网络通信中,数据链路层起着关键作用。它为直接相连的网络设备之间提供可靠的数据传输服务。…...

台式机来电自启动设置
在前司时,由于有些工作需要用到台式机,且一到节假日或者突然停电等情况,电脑每次都需要自己手动开机,后来研究了一下,发现可以在BIOS里面更改设置,从而变成关机的情况下,只要来电就能自动开机&a…...

【最新华为OD机试E卷-支持在线评测】考勤信息(100分)多语言题解-(Python/C/JavaScript/Java/Cpp)
🍭 大家好这里是春秋招笔试突围 ,一枚热爱算法的程序员 💻 ACM金牌🏅️团队 | 大厂实习经历 | 多年算法竞赛经历 ✨ 本系列打算持续跟新华为OD-E/D卷的多语言AC题解 🧩 大部分包含 Python / C / Javascript / Java / Cpp 多语言代码 👏 感谢大家的订阅➕ 和 喜欢�…...

netdata保姆级面板介绍
netdata保姆级面板介绍 基本介绍部署流程下载安装指令选择设置KSM为什么要启用 KSM?如何启用 KSM?验证 KSM 是否启用注意事项 检查端口启动状态 netdata和grafana的区别NetdataGrafananetdata各指标介绍总览system overview栏仪表盘1. CPU2. Load3. Disk…...

苹果最新论文:LLM只是复杂的模式匹配 而不是真正的逻辑推理
大语言模型真的可以推理吗?LLM 都是“参数匹配大师”?苹果研究员质疑 LLM 推理能力,称其“不堪一击”!苹果的研究员 Mehrdad Farajtabar 等人最近发表了一篇论文,对大型语言模型 (LLM) 的推理能…...

Python知识点:基于Python工具,如何使用Scikit-Image进行图像处理与分析
开篇,先说一个好消息,截止到2025年1月1日前,翻到文末找到我,赠送定制版的开题报告和任务书,先到先得!过期不候! 基于Python的Scikit-Image图像处理与分析指南 在Python的科学计算生态系统中&am…...

MongoDB初学者入门教学:与MySQL的对比理解
🏝️ 博主介绍 大家好,我是一个搬砖的农民工,很高兴认识大家 😊 ~ 👨🎓 个人介绍:本人是一名后端Java开发工程师,坐标北京 ~ 🎉 感谢关注 📖 一起学习 &…...

Oracle AI Vector Search
Oracle AI Vector Search 是 Oracle Database 23ai 中引入的一项新技术,它允许用户在数据库中直接存储和高效查询向量数据。这项技术旨在简化应用程序的开发,并且支持不同维度和格式的向量。以下是 Oracle AI Vector Search 的一些关键特性和优势&#x…...

基于SpringBoot的健身会员管理系统实战分享
在这个充满活力的时代,我们自豪地呈现一款专为健身爱好者和专业人士设计的会员管理系统——一个集创新、效率与便捷于一体的解决方案。我们的系统基于强大的RuoYi-Vue框架构建,采用最新的Spring Boot和Vue3技术,确保了系统的高性能和用户友好…...

Elasticsearch高级搜索技术-结构化数据搜索
目录 结构化数据的存储 示例映射 使用range查询 查询示例 运算符 更多示例 日期查询 示例 结构化数据搜索是Elasticsearch另一个强大的功能,允许用户对具有明确类型的数据(如数字、日期和布尔值)进行精确的过滤和查询。这种类型的搜索通常涉及…...

ffmpeg面向对象——类所属的方法探索
ffmpeg是面向对象的思想写的代码,自然符合oopc的实现套路。这个也是oopc的通用法则。 1.类所属方法oopc的实现形式 ffmpeg抽象出某一类,然后某一类的方法如何调用?你说这还不简单: 对象.对象方法() 或者 对象指针-&g…...

TensorRT-LLM七日谈 Day3
今天主要是结合理论进一步熟悉TensorRT-LLM的内容 从下面的分享可以看出,TensorRT-LLM是在TensorRT的基础上进行了进一步封装,提供拼batch,量化等推理加速实现方式。 下面的图片更好的展示了TensorRT-LLM的流程,包含权重转换&…...

如何使用Pandas库处理大型数据集?
如何使用Pandas库处理大型数据集? 处理大型数据集是数据分析中的一个挑战,尤其是在资源有限的情况下。Pandas是Python中非常流行的数据处理库,但它在处理非常大的数据集时可能会遇到内存限制的问题。因此,我们需要一些策略来提高Pandas处理大型数据集的效率。以下是使用Pa…...

XHR 创建对象
XHR 创建对象 XMLHttpRequest(XHR)是现代Web开发中不可或缺的技术之一。它允许Web开发者通过JavaScript发送网络请求,以在不重新加载整个页面的情况下更新网页的某部分。XHR为开发者提供了一种在客户端和服务器之间传输数据的有效方式,是AJAX(Asynchronous JavaScript an…...

# 在执行 rpm 卸载软件使用 nodeps 参数时,报错 error: package nodeps is not installed 分析
在执行 rpm 卸载软件使用 nodeps 参数时,报错 error: package nodeps is not installed 分析 一、问题描述: 在执行 rpm 卸载软件使用 nodeps 参数时,报错 error: package nodeps is not installed 如下图: 二、报错分析&…...

C++的类和动态内存分配(深拷贝与浅拷贝)并实现自己的string类
首先,我们先写一个并不完美的类: #include<iostream> #include<cstring> using namespace std;class Mystring{private:char *p;int len;static int num;friend ostream& operator<<(ostream& os, const Mystring& c);pu…...
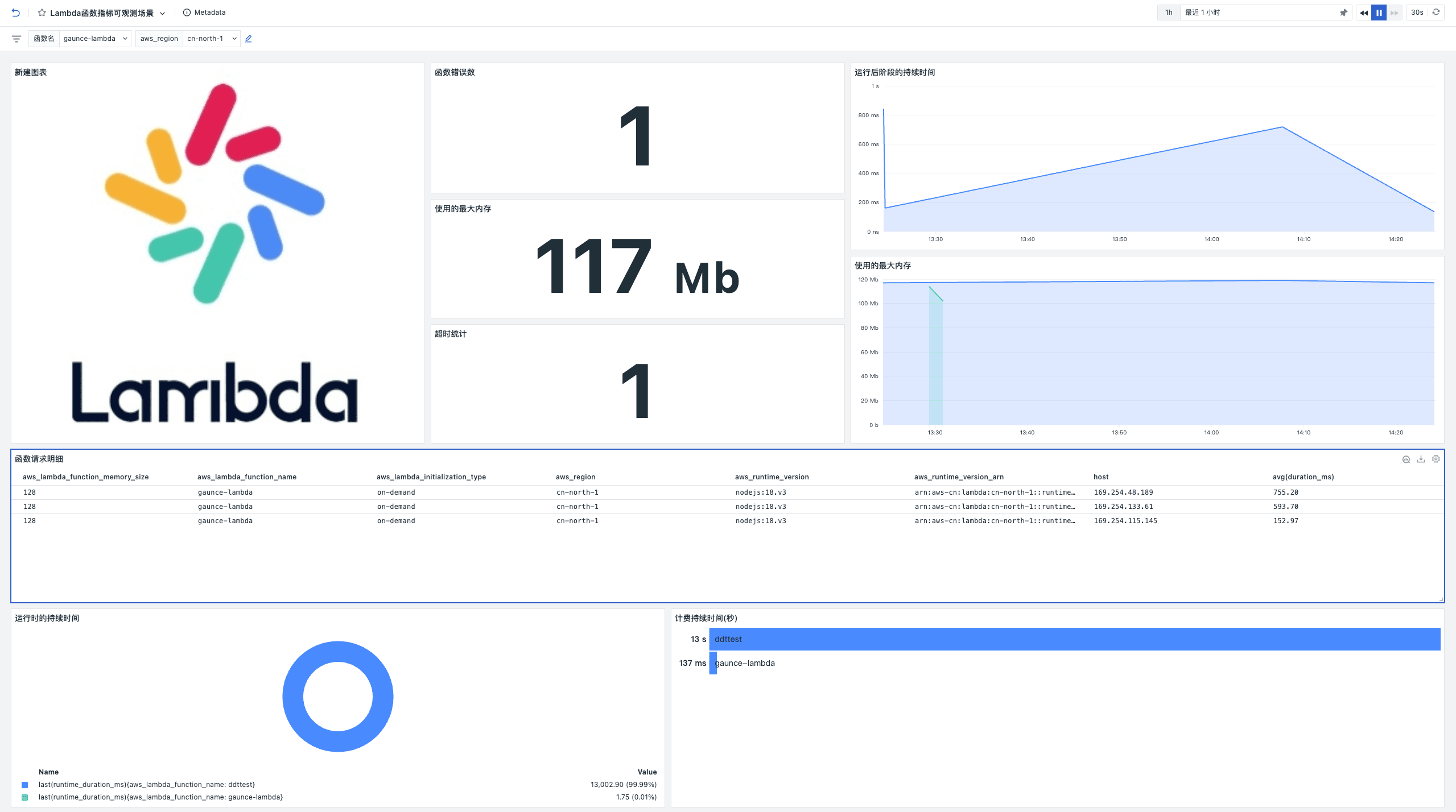
通过观测云 DataKit Extension 接入 AWS Lambda 最佳实践
前言 AWS Lambda 是一项计算服务,使用时无需预配置或管理服务器即可运行代码。AWS Lambda 只在需要时执行代码并自动缩放。借助 AWS Lambda,几乎可以为任何类型的应用程序或后端服务运行代码,而且无需执行任何管理。 Lambda Layer 是一个包…...

MySQL-三范式 视图
文章目录 三范式三范式简介第一范式第二范式第三范式 表设计一对一一对多多对多最终的设计 视图 三范式 三范式简介 所谓三范式, 其实是表设计的三大原则, 目的都是为了节省空间, 但是三范式是必须要遵守的吗? 答案是否定的(但是第一范式必须遵守) 因为有时候严格遵守三范式…...

多线程(三):线程等待获取线程引用线程休眠线程状态
目录 1、等待一个线程:join 1.1 join() 1.2 join(long millis)——"超时时间" 1.3 join(long millis,int nanos) 2、获取当前线程的引用:currentThread 3、休眠当前进程:sleep 3.1 实际休眠时间 3.2 sleep的特殊…...

ReID跨镜还在“找相似”,镜像视界无感定位已实现“定位置”
ReID跨镜还在“找相似”,镜像视界无感定位已实现“定位置”纵观当下视频跨镜追踪行业,技术路线早已形成鲜明代际差距。传统ReID行人重识别依旧固守视觉特征比对逻辑,全程停留在画面里反复“找相似”的浅层识别阶段;而依托国家十四…...

普通人如何构建AI智能体?一篇文章搞定——快速搭建属于自己的智能体
构建一个属于自己的智能体,其核心流程围绕一个通用架构展开,该架构定义了智能体如何感知、决策和行动。 对于普通人(非专业开发者)而言,关键在于利用现有的、低代码或无代码的框架和平台,将复杂的架构组件…...

基于SSE的轻量级实时通信库Hermes:Web应用实时消息推送实践
1. 项目概述:一个为Web应用量身打造的“信使”最近在折腾一个前后端分离的项目,后端服务部署在云端,前端应用则直接跑在用户的浏览器里。一个老生常谈的问题又摆在了面前:如何让前端能实时、可靠地获取后端的数据变更通知…...

初创团队如何利用Taotoken低成本启动AI功能并灵活扩展
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken低成本启动AI功能并灵活扩展 对于初创团队而言,在产品中引入人工智能能力是提升竞争力的关键…...

山东反向旅游推荐“小众秘境古村落”
假期不想挤热门景区,只想寻一处安静古村放空散心?给大家整理山东4 个小众秘境古村落,全程 1-2.5 小时车程,适合近郊自驾、短途出游,原生态氛围拉满,人少景美超适合避峰出行。一、济南长清|方峪古…...

这个内核 bug 潜伏了 9 年。
TL;DR — Linux 内核加密子系统的一行 sg_chain() 调用,让 page cache 页被放进了可写的 scatterlist。任何普通用户通过 splice() AF_ALG 就能精准覆盖 setuid 二进制的内存映像,5 秒 root。潜伏 9 年,影响 2017 年以来几乎所有主流发行版。…...

WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题
WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经在关键时刻被…...

【DeepSeek Chat功能测试全链路指南】:20年AI工程师亲测的7大核心场景验证法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试的底层逻辑与验证哲学 DeepSeek Chat 的功能测试并非仅面向接口响应的“黑盒点击”,而是建立在模型行为可解释性、推理路径可追溯性与系统边界可控性三重基石之上的验…...

职得Offer校园求职助手Pro深度评测:一个AI Agent陪你跑完求职全流程
一、 职得Offer是什么?—— 不止是工具,更是全程陪伴的AI求职伙伴 在AI应用爆发的今天,面对市面上众多的简历模板、面经题库和招聘平台,求职者尤其是学生群体,依然会陷入“信息过载却无从下手”的困境。“职得Offer校…...

AppleRa1n终极指南:5步免费绕过iOS 15-16 iCloud激活锁
AppleRa1n终极指南:5步免费绕过iOS 15-16 iCloud激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否遇到过这样的情况:忘记了自己iPhone的Apple ID密码,或…...