超全!一文详解大型语言模型的11种微调方法
导读:大型预训练模型是一种在大规模语料库上预先训练的深度学习模型,它们可以通过在大量无标注数据上进行训练来学习通用语言表示,并在各种下游任务中进行微调和迁移。随着模型参数规模的扩大,微调和推理阶段的资源消耗也在增加。针对这一挑战,可以通过优化模型结构和训练策略来降低资源消耗。
一般来说,研究者的优化方向从两个方面共同推进:
-
一方面,针对训练参数过多导致资源消耗巨大的情况,可以考虑通过固定基础大型语言模型的参数,引入部分特定参数进行模型训练,大大减少了算力资源的消耗,也加速了模型的训练速度。比较常用的方法包括前缀调优、提示调优等。
-
另一方面,还可以通过固定基础大型语言模型的架构,通过增加一个“新的旁路”来针对特定任务或特定数据进行微调,当前非常热门的LoRA就是通过增加一个旁路来提升模型在多任务中的表现。
接下来,我们将详细介绍11种高效的大型语言模型参数调优的方法。
文章目录
- 1. 前缀调优
- 2. 提示调优
- 3. P-Tuning v2
- 4. LoRA
- 5. DyLoRA
- 6. AdaLoRA
- 7. QLoRA
- 8. QA-LoRA
- 9. LongLoRA
- 10. VeRA
- 11. S-LoRA
- 12. 总结
- 13. 购买链接
1. 前缀调优
前缀调优(Prefix Tuning)是一种轻量级的微调替代方法,专门用于自然语言生成任务。前缀调优的灵感来自于语言模型提示,前缀就好像是“虚拟标记”一样,这种方法可在特定任务的上下文中引导模型生成文本。
前缀调优的独特之处在于它不改变语言模型的参数,而是通过冻结LM参数,仅优化一系列连续的任务特定向量(即前缀)来实现优化任务。前缀调优的架构如图1所示。

由于在训练中只需要为每个任务存储前缀,前缀调优的轻量级设计避免了存储和计算资源的浪费,同时保持了模型的性能,具有模块化和高效利用空间的特点,有望在NLP任务中提供高效的解决方案。
2. 提示调优
提示调优(Prompt Tuning)方法是由Brian Lester在论文“The Power of Scale for Parameter-Efficient Prompt Tuning”中提出的。
提示调优采用“软提示”(Soft Prompt)的方式,通过冻结整个预训练模型,只允许每个下游任务在输入文本前面添加k个可调的标记(Token)来优化模型参数,赋予语言模型能够执行特定的下游任务的能力。提示调优的架构如图2所示。

在论文的实验对比中,对于T5-XXL模型,每个经过调整的模型副本需要110亿个参数,相较于为每个下游任务制作特定的预训练模型副本,提示调优需要的参数规模仅为20480个参数。该方法在少样本提示方面表现出色。
3. P-Tuning v2
尽管提示调优在相应任务上取得了一定的效果,但当底座模型规模较小,特别是小于1000亿个参数时,效果表现不佳。为了解决这个问题,清华大学的团队提出了针对深度提示调优的优化和适应性实现——P-Tuning v2方法。
该方法最显著的改进是对预训练模型的每一层应用连续提示,而不仅仅是输入层。这实际上是一种针对大型语言模型的软提示方法,主要是将大型语言模型的词嵌入层和每个Transformer网络层前都加上新的参数。深度提示调优增加了连续提示的功能,并缩小了在各种设置之间进行微调的差距,特别是对于小型模型和困难的任务。
实验表明,P-Tuning v2在30亿到100亿个参数的不同模型规模下,以及在提取性问题回答和命名实体识别等NLP任务上,都能与传统微调的性能相匹敌,且训练成本大大降低。
4. LoRA
LoRA的核心思想是通过冻结预训练模型的权重,并将可训练的秩分解矩阵注入Transformer架构的每一层,从而显著减少下游任务中可训练参数的数量。在训练过程中,只需要固定原始模型的参数,然后训练降维矩阵A和升维矩阵B。LoRA的架构如图3所示。

具体来看,假设预训练的矩阵为
,它的更新可表示为:
,其中:
。
与使用Adam微调的GPT-3 175B相比,LoRA可以将可训练参数的数量减少10000倍,并将GPU内存需求减少3倍。尽管LoRA的可训练参数较少,训练吞吐量较高,但与RoBERTa、DeBERTa、GPT-2和GPT-3等模型相比,LoRA在模型质量性能方面与微调相当,甚至更好。
5. DyLoRA
但随着研究的深入,LoRA块存在两大核心问题:
-
一旦训练完成后,LoRA块的大小便无法更改,若要调整LoRA块的秩,则需重新训练整个模型,这无疑增加了大量时间和计算成本;
-
LoRA块的大小是在训练前设计的固定超参,优化秩的过程需要精细的搜索与调优操作,仅设计单一的超参可能无法有效提升模型效果。
为解决上述问题,研究者引入了一种全新的方法—DyLoRA(动态低秩适应)。
研究者参考LoRA的基本架构,针对每个LoRA块设计了上投影(Wup)和下投影(Wdw)矩阵及当前LoRA块的规模范围R。为确保增加或减少秩不会明显阻碍模型的表现,在训练过程中通过对LoRA块对不同秩的信息内容进行排序,再结合预定义的随机分布中进行抽样,来对LoRA块镜像上投影矩阵和下投影矩阵截断,最终确认单个LoRA块的大小。DyLoRA的架构如图4所示。

研究结果表明,与LoRA相比,使用DyLoRA训练出的模型速度可提升4~7倍,且性能几乎没有下降。此外,与LoRA相比,该模型在更广泛的秩范围内展现出了卓越的性能。
6. AdaLoRA
正如DyLoRA优化方法一样,提出AdaLoRA的研究者也发现,当前LoRA存在的改进方向:
-
由于权重矩阵在不同LoRA块和模型层中的重要性存在差异,因此不能提前制定一个统一规模的秩来约束相关权重信息,需要设计可以支持动态更新的参数矩阵;
-
需要设计有效的方法来评估当前参数矩阵的重要性,并根据重要性程度,为重要性高的矩阵分配更多参数量,以提升模型效果,对重要性低的矩阵进行裁剪,进一步降低计算量。
根据上述思想,研究者提出了AdaLoRA方法,可以根据权重矩阵的重要性得分,在权重矩阵之间自适应地分配参数规模。在实际操作中,AdaLoRA采用奇异值分解(SVD)的方法来进行参数训练,根据重要性指标剪裁掉不重要的奇异值来提高计算效率,从而进一步提升模型在微调阶段的效果。
7. QLoRA
Tim Dettmers等研究者在论文“QLoRA: Efficient Finetuning of Quantized LLMs”中提出了一种高效的模型微调方法——QLoRA。
QLoRA的架构如图5所示。

QLoRA的创新内容主要如下:
-
4bit NormalFloat(NF4)。NF4是一种新型数据类型,它对正态分布的权重来说是信息理论上的最优选择。
-
双重量化技术。双重量化技术减少了平均内存的使用,它通过对已量化的常量进行再量化来实现。
-
分页优化器。分页优化器有助于管理内存峰值,防止梯度检查点时出现内存不足的错误。
实验表明,QLoRA技术使得研究者能够在单个48GB GPU上微调650亿个参数规模的模型,同时维持16bit精度任务的完整性能。例如,在训练Guanaco模型时,仅需在单个GPU上微调24h,即可达到与ChatGPT相当的99.3%性能水平。通过QLoRA微调技术,可以有效降低模型微调时的显存消耗。
8. QA-LoRA
大型语言模型取得了迅猛发展,尽管在许多语言理解任务中表现强大,但由于巨大的计算负担,尤其是在需要将它们部署到边缘设备时,应用受到了限制。具体而言,预训练权重矩阵的每一列只伴随一个缩放和零参数对,但有很多LoRA参数。这种不平衡不仅导致了大量的量化误差(对LLM的准确性造成损害),而且使得将辅助权重整合到主模型中变得困难。
在论文“QA-LoRA: Quantization-aware Low-rank Adaptation of large language models”中,研究者提出了一种量化感知的低秩适应(QA-LoRA)算法。该方法来源于量化和适应的自由度不平衡的思想。
研究者提出采用分组运算符的方式,旨在增加量化自由度的同时减少适应自由度。
QA-LoRA的实现简便,仅需几行代码,同时赋予原始的LoRA两倍的能力:
-
在微调过程中,LLM的权重被量化(如INT4),以降低时间和内存的使用;
-
微调后,LLM和辅助权重能够自然地集成到一个量化模型中,而不损失准确性。
通过在LLaMA和LLaMA2模型系列的实验中证明,QA-LoRA在不同的微调数据集和下游场景中验证了其有效性。
如图6所示,与之前的适应方法LoRA和QLoRA相比,QA-LoRA在微调和推理阶段都具有更高的计算效率。更重要的是,由于不需要进行训练后量化,因此它不会导致准确性损失。在图6中展示了INT4的量化,但QA-LoRA可以推广到INT3和INT2。

9. LongLoRA
通常情况下,用较长的上下文长度训练大型语言模型的计算成本较高,需要大量的训练时间和GPU资源。
为了在有限的计算成本下扩展预训练大型语言模型的上下文大小,研究者在论文“LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models”中提出了LongLoRA的方法,整体架构如图7所示。

LongLoRA在两个方面进行了改进:
-
虽然在推理过程中需要密集的全局注意力,但通过采用稀疏的局部注意力,可以有效地进行模型微调。在LongLoRA中,引入的转移短暂的注意力机制能够有效地实现上下文扩展,从而在性能上与使用香草注意力(Vanilla Attention)进行微调的效果相似;
-
通过重新审视上下文扩展的参数高效微调机制,研究者发现在可训练嵌入和规范化的前提下,用于上下文扩展的LoRA表现良好。
LongLoRA在从70亿、130亿到700亿个参数的LLaMA2模型的各种任务上都取得了良好的结果。具体而言,LongLoRA采用LLaMA2-7B模型,将上下文长度从4000个Token扩展到10万个Token,展现了其在增加上下文长度的同时保持了高效计算的能力。这为大型语言模型的进一步优化和应用提供了有益的思路。
10. VeRA
LoRA是一种常用的大型语言模型微调方法,它在微调大型语言模型时能够减少可训练参数的数量。然而,随着模型规模的进一步扩大或者需要部署大量适应于每个用户或任务的模型时,存储问题仍然是一个挑战。
研究者提出了一种基于向量的随机矩阵适应(Vector-based Random matrix Adaptation,VeRA)的方法,VeRA的实现方法是通过使用一对低秩矩阵在所有层之间共享,并学习小的缩放向量来实现这一目标。
与LoRA相比,VeRA成功将可训练参数的数量减少了10倍,同时保持了相同的性能水平。VeRA与LoRA的架构对比如图8所示,LoRA通过训练低秩矩阵和来更新权重矩阵,中间秩为。在VeRA中,这些矩阵被冻结,在所有层之间共享,并通过可训练向量和进行适应,从而显著减少可训练参数的数量。在这种情况下,低秩矩阵和向量可以合并到原始权重矩阵中,不引入额外的延迟。这种新颖的结构设计使得VeRA在减少存储开销的同时,还能够保持和LoRA相媲美的性能,为大型语言模型的优化和应用提供了更加灵活的解决方案。

实验证明,VeRA在GLUE和E2E基准测试中展现了其有效性,并在使用LLaMA2 7B模型时仅使用140万个参数的指令就取得了一定的效果。这一方法为在大型语言模型微调中降低存储开销提供了一种新的思路,有望在实际应用中取得更为显著的效益。
11. S-LoRA
LoRA作为一种参数高效的大型语言模型微调方法,通常用于将基础模型适应到多种任务中,从而形成了大量派生自基础模型的LoRA模型。由于多个采用LoRA形式训练的模型的底座模型都为同一个,因此可以参考批处理模式进行推理。
据此,研究者提出了一种S-LoRA(Serving thousands of con current LoRA adapters)方法,S-LoRA是一种专为可伸缩地服务多个LoRA适配器而设计的方法。
S-LoRA的设计理念是将所有适配器存储在主内存中,并在GPU内存中动态获取当前运行查询所需的适配器。为了高效使用GPU内存并减少碎片,S-LoRA引入了统一分页。统一分页采用统一的内存池来管理具有不同秩的动态适配器权重以及具有不同序列长度的KV缓存张量。此外,S-LoRA还采用了一种新颖的张量并行策略和高度优化的自定义CUDA核心,用于异构批处理LoRA计算。这些特性使得S-LoRA能够在单个GPU或跨多个GPU上提供数千个LoRA适配器,而开销相对较小。
通过实验发现,S-LoRA的吞吐量提高了4倍多,并且提供的适配器数量增加了数个数量级。因此,S-LoRA在实现对许多任务特定微调模型的可伸缩服务方面取得了显著进展,并为大规模定制微调服务提供了潜在的可能性。
12. 总结
本文从背景、来源、技术路线及性能等方面综述了11种在模型参数调优阶段进行的方法,其中前缀调优、提示调优和P-Tuning v2属于引入特定参数来减少算力消耗、提升训练速度;基于LoRA的各种方法的基本思想是添加新的旁路,对特定任务或特定数据进行微调。
开源社区Hugging Face将这11种方法归纳为高效参数调优方法(Parameter-Efficient Fine-Tuning,PEFT)。PEFT方法能够在不微调所有模型参数的情况下,有效地让预训练语言模型适应各种下游应用。PEFT方法只微调了少量额外的模型参数,从而大幅降低了大模型训练和微调的计算与存储成本。通过合理使用PEFT方法,不但能提高模型的训练效率,还能在特定任务上达到大型语言模型的效果。有关基于PEFT的微调实战案例,推荐您阅读刘聪、沈盛宇、李特丽和杜振东的新书《大型语言模型实战指南:应用实践与场景落地》。
文章来源:IT阅读排行榜
本文摘编自《大型语言模型实战指南:应用实践与场景落地》,刘聪 沈盛宇 李特丽 杜振东 著,机械工业出版社出版,经出版方授权发布,转载请标明文章来源。
▼
延伸阅读

《大型语言模型实战指南:应用实践与场景落地》
刘聪 沈盛宇 李特丽 杜振东 著
资深大模型技术专家撰写
零一万物、通义千问、面壁智能等
多个主流大模型的负责人力荐
内容简介:
这是一本系统梳理并深入解析大模型的基础理论、算法实现、数据构造流程、模型微调方法、偏好对齐方法的著作,也是一本能手把手教你构建角色扮演、信息抽取、知识问答、AI Agent等各种强大的应用程序的著作。本书得到了零一万物、面壁智能、通义千问、百姓AI、澜舟科技等国内主流大模型团队的负责人的高度评价和鼎力推荐。
13直播预告
10月18日周五晚19:30 南京云问科技首席算法架构师刘聪、资深算法工程师沈盛宇、资深NLP技术专家和AI技术专家汪鹏、某头部大厂算法工程师谷清水四位嘉宾与您分享“如何让大模型应用真正落地:场景+解决方案+案例”
点击预约观看!直播间好礼不停

13. 购买链接
本书的京东购买链接为:大型语言模型实战指南:应用实践与场景落地。
相关文章:
超全!一文详解大型语言模型的11种微调方法
导读:大型预训练模型是一种在大规模语料库上预先训练的深度学习模型,它们可以通过在大量无标注数据上进行训练来学习通用语言表示,并在各种下游任务中进行微调和迁移。随着模型参数规模的扩大,微调和推理阶段的资源消耗也在增加。…...

C 主要函数解析
1、fseek 函数 int fseek(FILE *stream, long offset, int fromwhere); 第一个参数stream为文件指针 第二个参数offset为偏移量,正数表示正向偏移,负数表示负向偏移 第三个参数origin设定从文件的哪里开始偏移,可能取值为:SEEK_CUR、 SEE…...

vue3学习:数字时钟遇到的两个问题
在前端开发学习中,用JavaScript脚本写个数字时钟是很常见的案例,也没什么难度。今天有时间,于是就用Vue的方式来实现这个功能。原本以为是件非常容易的事,没想到却卡在两个问题上,一个问题通过别人的博文已经找到答案&…...

吴恩达深度学习笔记:卷积神经网络(Foundations of Convolutional Neural Networks)3.7-3.8
目录 第四门课 卷积神经网络(Convolutional Neural Networks)第三周 目标检测(Object detection)3.7 非极大值抑制(Non-max suppression)3.8 Anchor Boxes 第四门课 卷积神经网络(Convolutional…...

【Linux】最基本的字符设备驱动
前面我们介绍到怎么编译出内核模块.ko文件,然后还加载了这个驱动模块。但是,那个驱动代码还不完善,驱动写好后怎么在应用层使用也没有介绍。 字符设备抽象 Linux内核中将字符设备抽象成一个具体的数据结构(struct cdevÿ…...
利用 Llama 3.1模型 + Dify开源LLM应用开发平台,在你的Windows环境中搭建一套AI工作流
文章目录 1. 什么是Ollama?2. 什么是Dify?3. 下载Ollama4. 安装Ollama5. Ollama Model library模型库6. 本地部署Llama 3.1模型7. 安装Docker Desktop8. 使用Docker-Compose部署Dify9. 注册Dify账号10. 集成本地部署的 Llama 3.1模型11. 集成智谱AI大模型…...

Docker常用命令分享二
docker的用户组管理过程: 1、sudo : 可以让普通用户临时获得root用户的权限,来新建docker用户组 2、普通用户并没有使用sudo的权限 3、先要让root用户把testing用户加入到sudoers的授权文件中 4、sudoers的文件居然是只读的,先解决这个问…...

【一步步开发AI运动小程序】二十、AI运动小程序如何适配相机全屏模式?
引言 受小程序camera组件预览和抽帧图像不一致的特性影响,一直未全功能支持全屏模式,详见本系列文件第四节小程序如何抽帧;随着插件在云上赛事、健身锻炼、AI体测、AR互动场景的深入应用,各开发者迫切的希望能在全屏模式下应用&am…...

[Java基础] 运算符
[Java基础] 基本数据类型 [Java基础] Java HashMap 的数据结构和底层原理 目录 算术运算符 比较运算符 逻辑运算符 位运算符 赋值运算符 其他运算符 常见面试题 Java语言支持哪些类型的运算符? 请解释逻辑运算符&&和&的区别? 请解释条件运…...

[001-02-018].第05节:数据类型及类型转换
我的后端学习大纲 我的Java学习大纲 1、数据类型介绍: 1.0.计算机存储单位: 1.1.基本数据类型介绍: a.整型:byte、short、int、long 1.整型包括:byte、short、int、long,可如下图方式类比记忆࿱…...

Netty基础
Netty基础 一级目录I/O请求基础知识Netty如何实现自己的I/O模型 网络框架的选型 Netty整体架构Netty逻辑处理架构网络通信层事件调度层服务编排层 组件关系梳理Netty源码结构 netty是目前最流行的一款高性能java网络编程框架,广泛使用于中间件、直播、社交、游戏等领…...

602,好友申请二:谁有最多的好友
好友申请二:谁有最多的好友 实现 with tmp as (selectrequester_id idfrom RequestAcceptedunion allselectaccepter_id idfrom RequestAccepted )selectid,count(*) num from tmp group by id order by num desc limit 1;...
)
【Matlab算法MATLAB实现的音频信号时频分析与可视化(附MATLAB完整代码)
MATLAB实现的音频信号时频分析与可视化 前言正文:时频分析实现原理代码实现代码运行结果图及说明结果图:结果说明:总结前言 音频信号的时频分析是信号处理领域中的一个重要研究方向。它允许我们同时观察信号在时间和频率域的特性,为音频处理、语音识别、音乐分析等应用提供…...

界面耻辱纪念堂--可视元素03
更多的迹象表明,关于在程序里使用新的动态界面元素,微软的态度是不确定的,其中一个是仅仅需要对比一下Office97 里的“Coolbars”和“标准工具条”。Coolbar 按钮直到用户指针通过的时候才成为按钮(否则是平的)。 工具…...

国产龙芯处理器选择迅为2K1000开发板有资料
硬件配置国产龙芯处理器,双核64位系统,板载2G DDR3内存,流畅运行Busybox、Buildroot、Loognix、QT5.12 系统!接口全板载4路USB HOST、2路千兆以太网、2路UART、2路CAN总线、Mini PCIE、SATA固态盘接口、4G接口、GPS接口WIF1、蓝牙、Mini HDMI…...
)
MySQL 命令(持续更新)
将 MySQL 命令结果输出到文件中 通过 k8s MySQL pod 里的客户端连接到 MySQL 服务器 kubectl exec mysql-pod -- mysql -hx.x.x.x -uroot -proot -e SELECT * FROM db.table; > result.txt通过 k8s MySQL pod 的客户端连接 MySQL 服务器,直接进入到 MySQL 客户端…...

Linux下Docker方式Jenkins安装和配置
一、下载&安装 Jenkins官方Docker仓库地址:https://hub.docker.com/r/jenkins/jenkins 从官网上可以看到,当前最新的稳定版本是 jenkins/jenkins:lts-jdk17。建议下在新的,后面依赖下不来 所以,我们这里,执行doc…...

低代码框架参考
企业管理信息系统作为一类重要的应用软件系统,具有自己的特点,主要有两个方面: 1. 系统规模大,目前市场上常见的ERP系统一般都有几千个页面。 2. 页面逻辑相似性强。经过比较可以发现,大部分页面具有类似的功能&…...
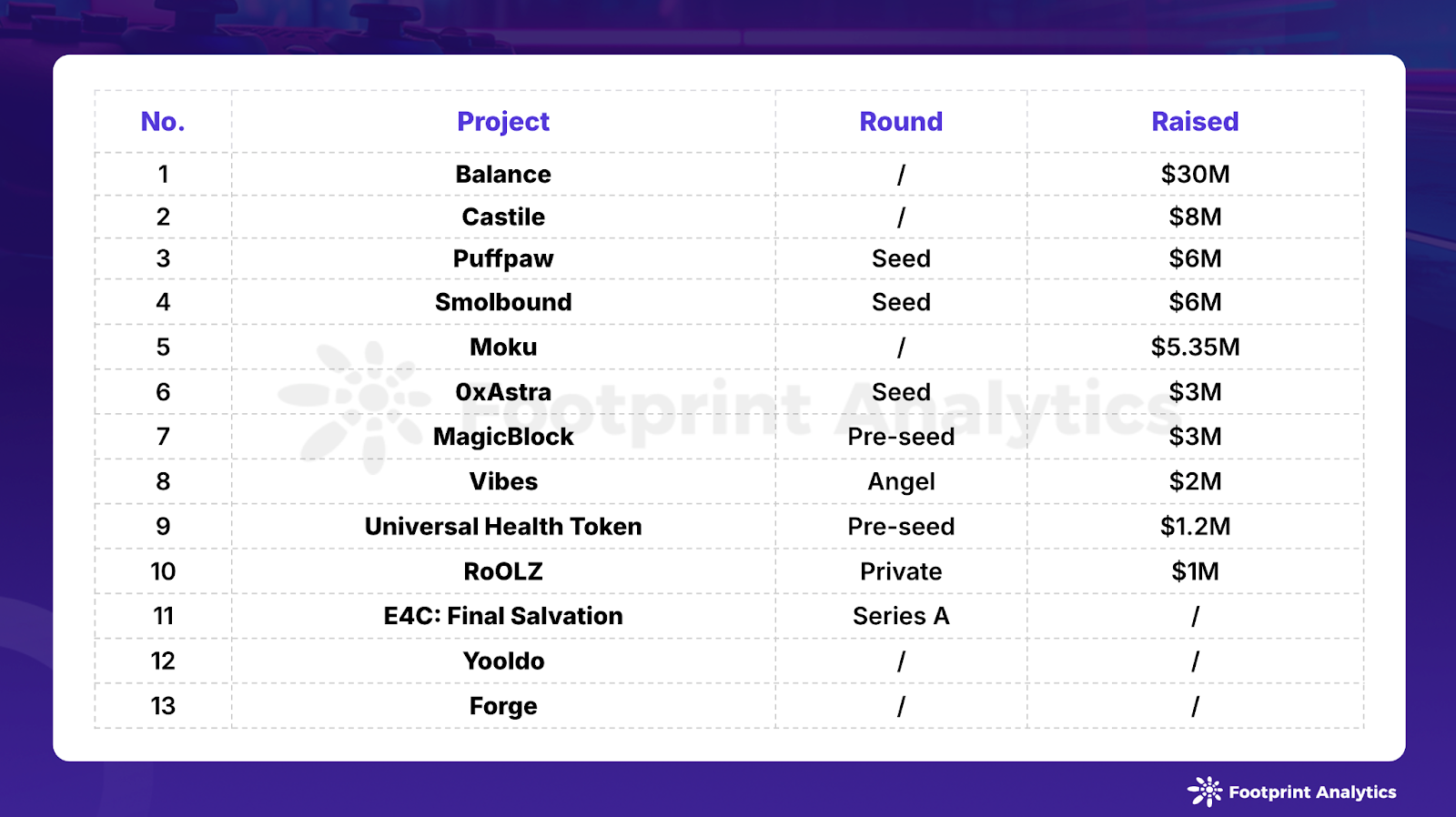
2024 年 9 月区块链游戏研报:行业回暖,Telegram 游戏引发热潮
作者:Stella L (stellafootprint.network) 数据来源:Footprint Analytics Games Research Page 9 月份,区块链游戏代币的市场总值增长了 29.2%,达到 232 亿美元,日活跃用户(DAU)数量上升了 1…...
)
python爬虫登录校验之滑块验证、图形验证码(OCR)
在爬虫过程中,验证码和滑块验证是常见的反爬措施。针对这些挑战,通常采用OCR识别图形验证码和模拟滑块拖动来处理滑块验证。以下是如何处理这两种类型验证的详细方法。 1. 图形验证码(OCR) a. 使用 tesserocr 和 Pillow 处理图形…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

13456
12356...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...