爬虫post收尾以及cookie加代理
爬虫post收尾以及cookie加代理
目录
1.post请求收尾
2.cookie加代理
post收尾
post请求传参有两种格式,载荷中有请求载荷和表单参数,我们需要做不同的处理。
1.表单数据:data=字典传参
content-type:
application/x-www-form-urlencoded; charset=UTF-8(这种方法是上一篇文章讲到的)
查询字符串参数:跟在url后面的参数
2.请求载荷:json=字典
content-type 告知服务端传入的参数类型是什么类型
application/json;charset=UTF-8 传入的参数是个json格式数据
两种处理办法:
一:
1- 伪装指定content-type
2- 传参还是使用data参数,参数值是一个json字符串
二:
直接使用json参数=字典
第一种方法:
import requests
url = 'https://join.qq.com/api/v1/position/searchPosition?timestamp=1727440821893'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/129.0.0.0 Safari/537.36','content-type':'application/json;charset=UTF-8'
}
data = '{"projectIdList":[1],"keyword":"","bgList":[],"workCountryType":0,"workCityList":
[],"recruitCityList":[],"positionFidList":[],"pageIndex":3,"pageSize":10}'
res = requests.post(url,data=data,headers=headers)
print(res.text)
第二种方法:
import requests
url = 'https://join.qq.com/api/v1/position/searchPosition?timestamp=1727440821893'
data = {"projectIdList":[1],"keyword":"","bgList":[],"workCountryType":0,"workCityList":
[],"recruitCityList":[],"positionFidList":[],"pageIndex":3,"pageSize":10}
res = requests.post(url,json=data)
print(res.text)
cookie
cookie是存储在浏览器中的一组键值对,用来保存当前用户身份
存在时效性的,会过期,过期的时间一般都是服务端指定
如果访问的目标网站需要cookie, 处理的办法:
1.直接复制浏览器中登录之后的cookie, 伪装(请求头)中有一个cookie
存储在客户端(浏览器)中的一组键值对, 能够用于保存一些状态, 但有个要求:必须要先登录。
import requests
url = 'https://my.4399.com/forums/index-getMtags?type=game&page=1'
headers = {'cookie':'UM_distinctid=18f5d84be7ab12-0d4fcf3a09be2e-26001d51-1fa400-18f5d84be7bf28;_4399tongji_vid=171526094309656; _4399stats_vid=17152609431943750; _gprp_c="";smidV2=202405111957567078c442e11c09b2676e719231c52c1f00ffe8aacc95bce90; home4399=yes;Puser=3073859018; Pnick=%E4%B8%AD%E9%87%8E%E5%B7%A7%E5%AE%89%E6%9B%BC%E5%A6%AE; Qnick=;Sauth=4078826105%7C3073859018%7C1724907026%7C1725771373%7Cad31369854452fbfe2af%7C%E4%B8%AD%E9%87%8E%E5%B7%A7%E5%AE%89%E6%9B%BC%E5%A6%AE%7C%E4%B8%AD%E9%87%8E%E5%B7%A7%E5%AE%89%E6%9B%BC%E5%A6%AE%7C47e7e4cfced0bcb5a19d88b03d094613;Hm_lvt_334aca66d28b3b338a76075366b2b9e8=1724391240,1724906618,1724932650;ptusertype=my.4399_login; zone_guide_date=1724947200; zone_guide_time=2;_4399tongji_st=1724933289; USESSIONID=e61b6eb4-3e07-48dd-b354-c9fe6ef545d2;Hm_lvt_5c9e5e1fa99c3821422bf61e662d4ea5=1724906645,1724932678,1724933289;HMACCOUNT=13108745FF137EDD;Hm_lvt_e5a07b5994f78634294b9c347a5be7d2=1724906645,1724932678,1724933289; phlogact=l1493;Uauth=4399|1|2024829|my.|1724933589815|d59a0688a9891db73745cf920f83aa63;Pauth=4078826105|3073859018|t3ce7n2813b76b1e854c4b9428c211e1|1724933589|10002|690950f30d878aa6ed7e245af0c9fb18|2; ck_accname=3073859018; Xauth=6b199edef659802ab9fac4d9eea16604;Hm_lpvt_e5a07b5994f78634294b9c347a5be7d2=1724933589;Hm_lpvt_5c9e5e1fa99c3821422bf61e662d4ea5=1724933589;Pmtime=85fe178bc1e94ed171d3%7C1724933590; ol=1'
}res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
print(res.text)
爬虫获取群组数据:
1- 找数据所在的url
https://my.4399.com/forums/index-getMtags?type=game&page=1
2- 请求成功之后,得到的反馈信息是要先登录(明明浏览器已经登录了,为什么还要登录,因为浏览器和代码没有关系)
3- 如何解决登录问题:
1- 带上登录之后的cookie:当你登录完成之后,会保存一些用户信息在里面,cookie中保存的内容不会永久有效,时间期
限(服务端决定)
优点:简单直接,缺点:会过期
2.通过模拟登录,登录成功之后获取cookie(大部分网站实现登录,密码都进行了加密,所以这种方式不适用所有
网站,但是4399可以直接传入明文,服务端没做密码是否为密文的检测,只做了密码是否正确的检测)
# 1- 登录请求
# 2- 获取数据请求
# 模拟登录
login_url = 'https://ptlogin.4399.com/ptlogin/login.do?v=1'
# post请求传入参数
import requests
data = {'loginFrom':'uframe','postLoginHandler':'refreshParent','layoutSelfAdapting':'false','externalLogin':'qq','displayMode':'embed','layout':'vertical','appId':'u4399','css':'https://uc.img4399.com/root/css/ptlogin.css?a3993b7','mainDivId':'embed_login_div','includeFcmInfo':'false','level':'0','regLevel':'4','userNameLabel':'4399用户名','userNameTip':'请输入4399用户名','welcomeTip':'欢迎回到4399','sec':'1','password':'hkyx8888', # 4399服务端支持密码传入明文,但是其它网站的登录不一定支持'username':'3073859018',
}
# 登录之后的响应对象 如果登录成功,服务端返回cookie,保存在响应对象中
login_res = requests.post(login_url,data=data)
# 目标url
url = 'https://my.4399.com/forums/index-getMtags?type=game&page=2'
res = requests.get(url,cookies=login_res.cookies)
res.encoding = 'utf-8'
print(res.text)
因为访问群组页面,需要先登录账号
爬虫也可以先登录,服务端会返回cookie(包含了用户信息)
再获取目标url的时候带上登录后的cookie
小tips:
我们可以看到data里面的数据, 有这么多的键值对, 都从网上赋值过来的文本数据, 那怎么一键变为键值对数据呢?
这个其实很简单, 我们在pycharm里面打开替换文本的工具(Ctrl+r快捷键打开)。
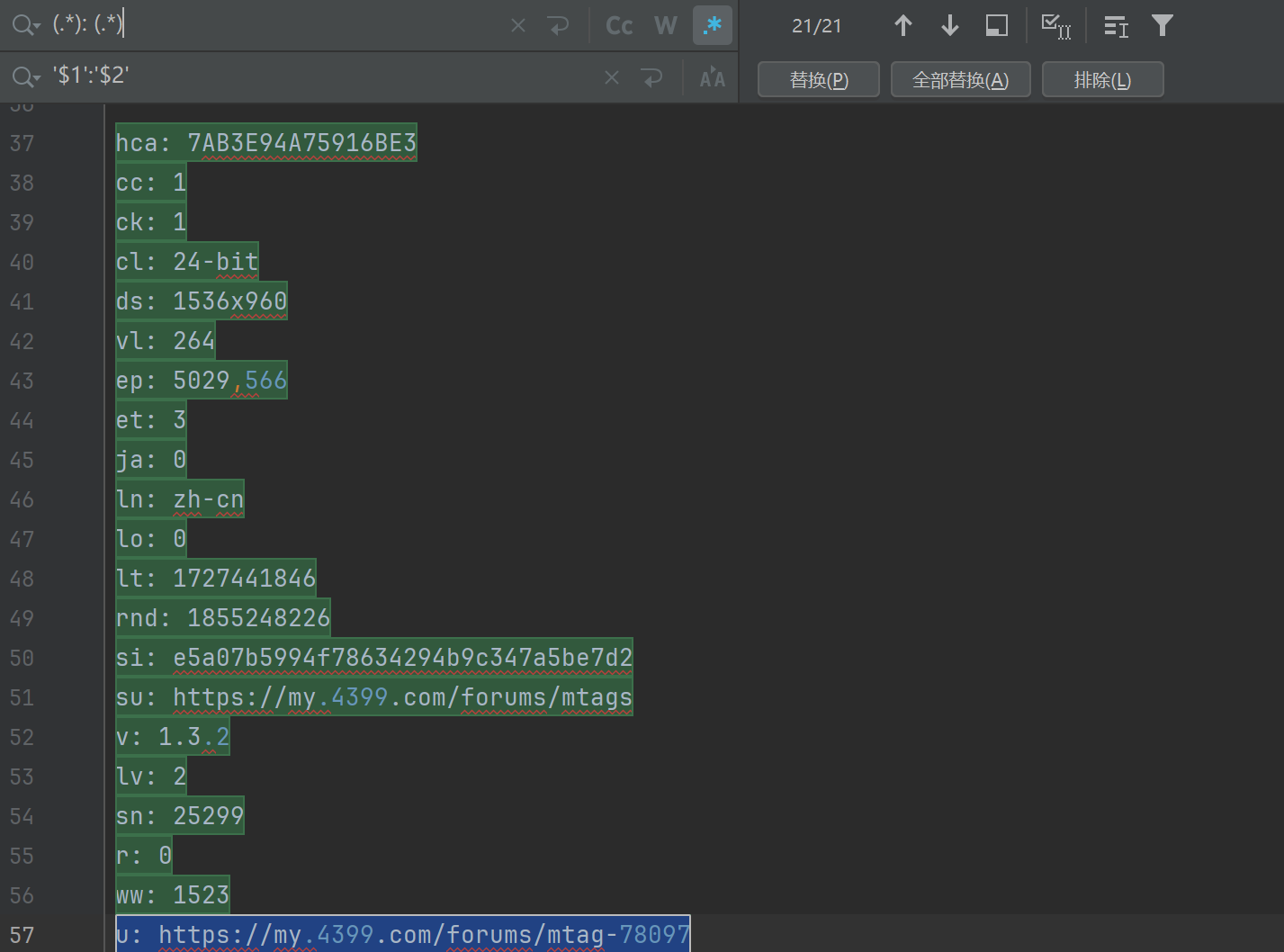
注意: 需要点亮星星哦, 就是最上面中间的地方, .*那个符号。
代码区自动会帮我们选中需要替换的区域
我们点击全部替换, 然后再给它放到一个字典里面去。
d = {'hca': '7AB3E94A75916BE3','cc': '1','ck': '1','cl': '24-bit','ds': '1536x960','vl': '264','ep': '5029,566','et': '3','ja': '0','ln': 'zh-cn','lo': '0','lt': '1727441846','rnd': '1855248226','si': 'e5a07b5994f78634294b9c347a5be7d2','su': 'https://my.4399.com/forums/mtags','v': '1.3.2','lv': '2','sn': '25299','r': '0','ww': '1523','u': 'https://my.4399.com/forums/mtag-78097'
}
以后大家可以多使用这种方法哦, 既方便又快捷, 但是需要注意的是在我们把修改好的数据全部放到新的字典里面去的时候, 每一句话的最后一行都要加分号。
实战:
获取腾讯招聘的招聘项目每一个框里面的数据(应届生的岗位投递信息, 就最下方最大的红色框里面的信息)。
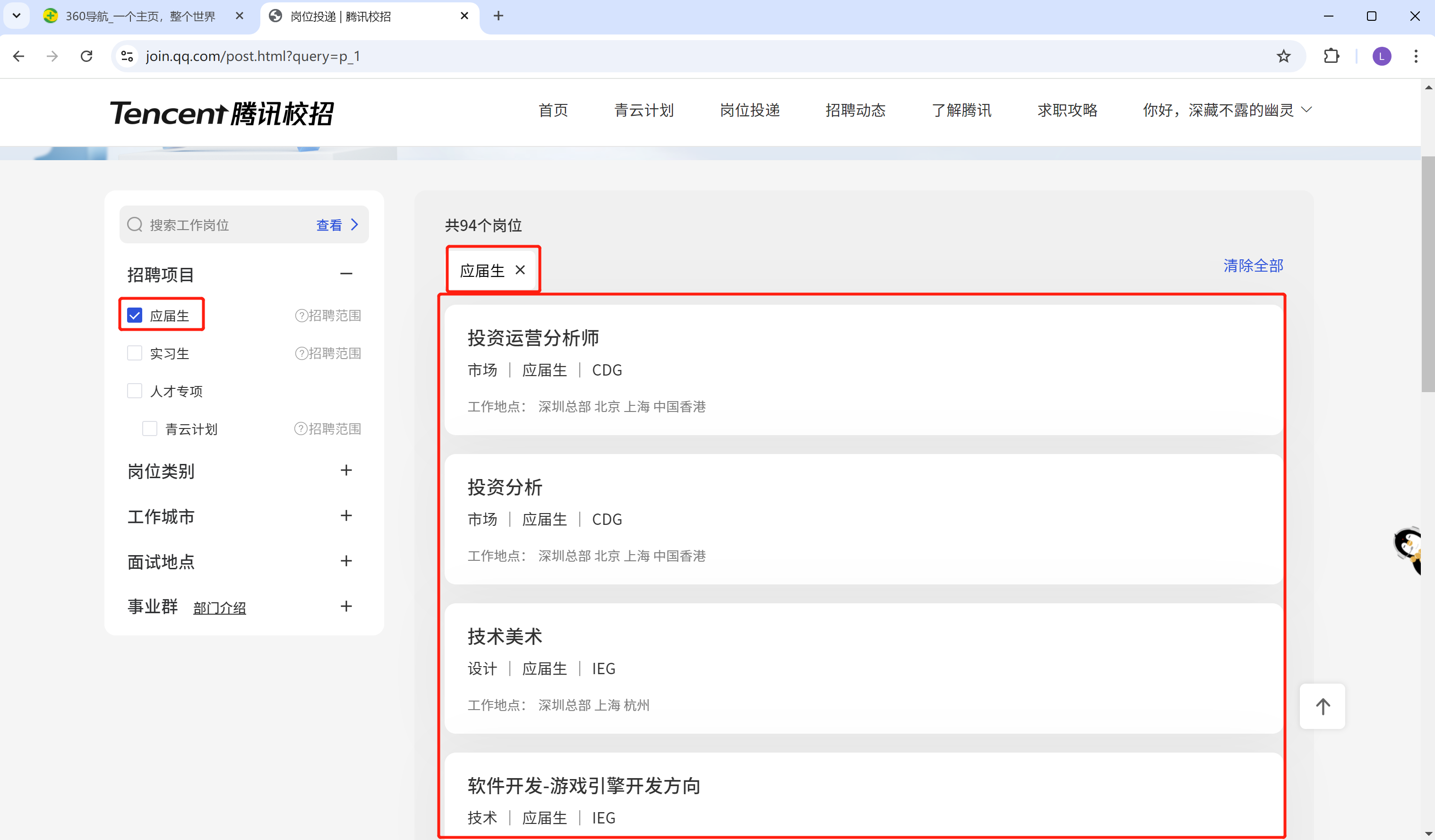
自己先尝试的去做一做, 不要马上看答案哦。
参考答案:
import requestspageIndex = 1
count = 1
# 分页获取数据
while True:url = 'https://join.qq.com/api/v1/position/searchPosition?timestamp=1727532633390'headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36","cookie": "UserInfo=1kij6FX225E8Xm5SldigGuGG8cYEEgz+nyKdgtlbiSLV5y/bsU4j/m2d1S8+dYWCQx0yLKUpGj4XJ3ZRiN5VrTuBbk3TnGGbSg7faVuROyuNOoS5p+gSyNqCS6nc51VLWrECSpiILWyPk2xP32aoS1cWGP37hTHHQzLZeJYd/QsSTJ/sSuDenS9g26yEgmphPnHE0Bfq/EDG1XZUS41Pni2nwHYHeEgEfhNspL25x67XXcVhZg+b7NYaSnklM/I2GLEH8c3gXpVU6/4jC4i6kg==; loginMark=02"}data = {'bgList': [],'pageIndex': pageIndex,'pageSize': 10,'positionFidList': [],'projectIdList': [1, 2, 12, 14],'recruitCityList': [],'workCityList': [],'workCountryType': 0}response = requests.post(url, headers=headers, json=data)data = response.json()if data['data']['positionList'] is not None:for i in data['data']['positionList']:# 工作岗位work_title = i['positionTitle']# 应届生的背景bgs = i['bgs']# 工作地点workCities = i['workCities']print(count)print("工作岗位:", work_title)print("应届生的背景:", bgs)print("工作地点:", workCities)count += 1else:breakpageIndex += 1
这个实战题你写出来了吗?如果写出来的话, 给自己一个掌声哦。👏
以上就是爬虫post收尾以及cookie的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!
相关文章:
爬虫post收尾以及cookie加代理
爬虫post收尾以及cookie加代理 目录 1.post请求收尾 2.cookie加代理 post收尾 post请求传参有两种格式,载荷中有请求载荷和表单参数,我们需要做不同的处理。 1.表单数据:data字典传参 content-type: application/x-www-form-urlencoded; …...

c++STL——map与set的使用及介绍
目录 前言: 1. 关联式容器 2. 键值对 3. 树形结构的关联式容器 3.1 set 3.1.1 set的介绍 3.1.2 set的使用 1. set的模板参数列表 2. set的构造 3. set的迭代器 4. set的容量 5. set修改操作 6. set的使用举例 3.2 map 3.2.1 map的介绍 3.2.2 map的…...

Vxe UI vue vxe-table select 下拉框选项列表数据量超大过大时卡顿解决方法
Vxe UI vue vxe-table vxe-grid select 下拉框选项列表数据量超大过大时卡顿解决方法 查看 github vxe-table 官网 vxe-table 本身支持虚拟滚动,数据量大也是支持的,但是如果在可编辑表格中使用下拉框,下拉框的数据量超大时,可能…...

python 基础笔记(其实有点内容的)
print(math.gamma(n)) # 求 (n-1) 的阶乘 数值, 数值计算 format(50, “b”) bin(50)[2:], 这个“b” 就代表的是 binary format(14, ‘b’) ------> ‘1110’ 去除 0b 去掉前导零 str(000001) # 只适合python2.x ‘1’ “00000001”.lstrip(“0”) # python3…...

(39)MATLAB生成高斯脉冲及其频谱
文章目录 前言一、MATLAB仿真代码二、仿真结果画图 前言 高斯脉冲在通信中是很重要的调制符号波形,本文使用MATLAB生成高斯脉冲,并使用FFT变换给出其频谱。 一、MATLAB仿真代码 代码如下: % 信号参数 fs 100; % 采样…...

35岁前端开发者:转型还是坚守?
在互联网行业,35岁似乎成了一个敏感的年龄分水岭。很多前端开发者开始思考:到了35岁,是不是都要转型?本文将探讨这个话题,希望能为面临这一困惑的前端开发者提供一些参考。 一、35岁焦虑:现实还是误解&…...

对MVC详细解读
一、MVC模式的详细组成部分 1. 模型(Model) 数据结构: 模型通常使用类或结构来定义应用程序的数据结构。例如,在Ruby on Rails中,模型通常与数据库表相对应,使用Active Record模式。 数据访问层࿱…...
centos系列图形化 VNC server配置,及VNC viewer连接,2024年亲测有效
centos系列图形化 VNC server配置,及VNC viewer连接 0.VNC服务介绍 VNC英文全称为Virtual Network Computing,可以位操作系统提供图形接口连接方式,简单的来说就是一款桌面共享应用,类似于qq的远程连接。该服务是基于C/S模型的。…...

STL序列式容器之string的基本用法及实现
1.string类 在使用string类时,必须包含<string>头文件以及using namespace std; 接下来我们看看string类是如何被声明的: typedef basic_string<char> string; 可以看到:string类是被类模板basic_string用数据类型…...

lua脚本使用cjson转换json时,空数组[]变成了空对象{}
一、前言 项目lua使用工具:cjson 问题:reids中部分数据的json key存在为[]的值,使用cjson进行解析的时候将原本空数组[]解析成了空对象{} 目标:原本[] 转 [] 二、解决方案 在使用cjson类库时,先配置json转换要求 -…...

ImportError: /../lib/libstdc++.so.6: version `GLIBCXX_3.4.29解决方案
今天跑实验遇到了一个头疼的报错,完全看不懂,上网查了一下成功解决,但是网上的指令没法直接拿来用,所以在这里记录一下自己的解决方案。 报错信息: Traceback (most recent call last):File "/home/shizhiyuan/c…...

java-实现一个简单的httpserver-0.6.0
2024年10月14日14:17:07—0.6.0 java-实现一个简单的httpserver-0.6.0 背景功能具体代码打印 背景 通常写了一些接口,需要通过临时的http访问,又不需要spring这么厚重的框架 功能 设置并发监控并发两个get请求一个是根路径,一个是other增加…...

【论文#码率控制】ADAPTIVE RATE CONTROL FOR H.264
目录 摘要1.前言2.基本知识2.1 蛋鸡悖论2.2 基本单元的定义2.3 线性MAD预测模型 3.GOP级码率控制3.1 总比特数3.2 初始化量化参数 4.帧级码率控制4.1 非存储图像的量化参数4.2 存储图像的目标比特 5.基本单元级码率控制6.实验结果7.结论 《ADAPTIVE RATE CONTROL FOR H.264》 A…...

2024-10-16 学习人工智能的Day8
函数 定义(创建) 函数的创建def开始,后接函数名,在给参数表最后冒号表示函数基础信息给定 换行书写函数内部定义,在函数内部定义操作,最后函数自带返回,无定义返回值返回为None&…...

Python Django 数据库优化与性能调优
Python Django 数据库优化与性能调优 Django 是一个非常流行的 Python Web 框架,它的 ORM(对象关系映射)允许开发者以简单且直观的方式操作数据库。然而,随着数据量的增长,数据库操作的效率可能会成为瓶颈,…...
基于SpringBoot+微信小程序的农产品销售平台
基于SpringBoot微信小程序的农产品销售平台 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目…...

微前端学习以及分享
微前端学习以及分享 注:本次分享demo的源码github地址:https://github.com/rondout/micro-frontend 什么是微前端 微前端的概念是由ThoughtWorks在2016年提出的,它借鉴了微服务的架构理念,核心在于将一个庞大的前端应用拆分成多…...

【Linux-进程间通信】vscode使用通信引入匿名管道引入
一、新系统,新软件 1.新系统 哈喽宝子们,从今以后我们不再使用风靡一时的CentOS系统了,因为CentOS已经不在维护了,各大公司几乎也都从CentOS转入其他操作系统了;我们现在由原来的CentOS系统切换到最新的Ubuntu系统&a…...

nerd bug:VPG多次计算vnetloss的计算图报错的解决
待更 Reference https://www.cnblogs.com/StarZhai/p/15495292.htmlhttps://github.com/huggingface/transformers/issues/12613https://discuss.pytorch.org/t/inplace-operation-errors-when-implementing-a2c-algorithm/145406/6...
BigDecimal类Date类JDK8日期
一、BigDecimal类是什么?它有什么用?先看一段代码,看这个代码有什么问题再说BigDeimal这个类是干什么用的,这样会好理解一些。 public class Test {public static void main(String[] args) {System.out.println(0.1 0.2);Syste…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...