强化学习之DDPG算法
前言:
在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。
一、算法介绍
深度确定性策略梯度 (Deep Deterministic Policy Gradient,简称DDPG) 算法是一种基于策略梯度的方法,结合了深度神经网络和确定性策略的优势。它特别适用于具有连续动作空间的控制任务,如机械臂控制、自动驾驶等。DDPG算法通过同时训练一个演员网络(Actor)和一个评论家网络(Critic),实现对策略的优化。
主要特点包括:
- 确定性策略:与随机策略不同,DDPG使用确定性策略,直接输出给定状态下的最优动作。
- 经验回放(Replay Buffer):通过存储经验样本,打破样本间的相关性,提升训练稳定性。
- 目标网络(Target Networks):使用延迟更新的目标网络,减少训练过程中的震荡和不稳定。
二、算法原理
2.1 网络结构
DDPG算法由两个主要网络组成:
-
演员网络(Actor):参数为 θ μ \theta^\mu θμ,用于确定性地选择动作。
a = μ ( s ∣ θ μ ) a = \mu(s|\theta^\mu) a=μ(s∣θμ)
-
评论家网络(Critic):参数为 θ Q \theta^Q θQ,用于估计给定状态-动作对的Q值。
Q ( s , a ∣ θ Q ) Q(s,a|\theta^Q) Q(s,a∣θQ)
此外,还存在两个目标网络,分别对应演员和评论家网络,参数为 θ μ ′ \theta^{\mu'} θμ′和 θ Q ′ \theta^{Q'} θQ′,用于计算目标Q值。
2.2 经验回放
经验回放池 D \mathcal{D} D用于存储经验元组 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1)。在每次训练迭代中,算法从 D \mathcal{D} D中随机采样一个小批量样本,打破数据间的相关性,提高训练效率和稳定性。
2.3 目标网络的更新
目标网络的参数通过软更新方式更新:
θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ \theta^{\mu'} \leftarrow \tau \theta^\mu + (1 - \tau) \theta^{\mu'} θμ′←τθμ+(1−τ)θμ′
θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ \theta^{Q'} \leftarrow \tau \theta^Q + (1 - \tau) \theta^{Q'} θQ′←τθQ+(1−τ)θQ′
其中, τ \tau τ是软更新的步长,通常取值较小,如 0.001 0.001 0.001。
2.4 损失函数与优化
-
评论家网络的损失函数采用均方误差(MSE):
L = 1 N ∑ i = 1 N ( y i − Q ( s i , a i ∣ θ Q ) ) 2 L = \frac{1}{N} \sum_{i=1}^N \left( y_i - Q(s_i, a_i|\theta^Q) \right)^2 L=N1i=1∑N(yi−Q(si,ai∣θQ))2
其中,
y i = r i + γ Q ′ ( s i + 1 , μ ′ ( s i + 1 ∣ θ μ ′ ) ∣ θ Q ′ ) y_i = r_i + \gamma Q'(s_{i+1}, \mu'(s_{i+1}|\theta^{\mu'})|\theta^{Q'}) yi=ri+γQ′(si+1,μ′(si+1∣θμ′)∣θQ′)
-
演员网络的损失函数通过最大化Q值来优化策略:
J = − 1 N ∑ i = 1 N Q ( s i , μ ( s i ∣ θ μ ) ∣ θ Q ) J = -\frac{1}{N} \sum_{i=1}^N Q(s_i, \mu(s_i|\theta^\mu)|\theta^Q) J=−N1i=1∑NQ(si,μ(si∣θμ)∣θQ)
2.5 算法流程
- 初始化演员网络 μ ( s ∣ θ μ ) \mu(s|\theta^\mu) μ(s∣θμ)和评论家网络 Q ( s , a ∣ θ Q ) Q(s,a|\theta^Q) Q(s,a∣θQ),以及对应的目标网络 μ ′ \mu' μ′和 Q ′ Q' Q′。
- 初始化经验回放池 D \mathcal{D} D。
- 对于每个回合:
- 在环境中选择动作 a t = μ ( s t ∣ θ μ ) + N t a_t = \mu(s_t|\theta^\mu) + \mathcal{N}_t at=μ(st∣θμ)+Nt,其中 N t \mathcal{N}_t Nt为噪声,用于探索。
- 执行动作 a t a_t at,观察奖励 r t r_t rt和下一个状态 s t + 1 s_{t+1} st+1。
- 存储经验 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1)到 D \mathcal{D} D。
- 从 D \mathcal{D} D中随机采样一个小批量样本。
- 计算目标Q值 y i y_i yi。
- 更新评论家网络参数 θ Q \theta^Q θQ,最小化损失 L L L。
- 更新演员网络参数 θ μ \theta^\mu θμ,最大化 J J J。
- 软更新目标网络参数 θ μ ′ \theta^{\mu'} θμ′和 θ Q ′ \theta^{Q'} θQ′。
- 重复以上步骤,直至收敛。
三、案例分析
在本节中,我们将通过在Pendulum-v0环境中应用DDPG算法,展示其具体实现过程。该环境的目标是让倒立摆尽可能长时间地保持直立状态,涉及连续动作空间。
3.1 环境简介
- 状态空间:摆锤的角度、角速度,共3个维度。
- 动作空间:施加的力矩,范围为 [ − 2 , 2 ] [-2, 2] [−2,2]。

3.2 实现代码
以下是使用PyTorch实现的DDPG算法在Pendulum-v0环境中的部分代码。
# 经验回放池
class ReplayBuffer:def __init__(self, buffer_size, batch_size, seed):self.memory = deque(maxlen=buffer_size)self.batch_size = batch_sizeself.seed = random.seed(seed)def add(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def sample(self):experiences = random.sample(self.memory, k=self.batch_size)states = torch.FloatTensor([e[0] for e in experiences]).to(device)actions = torch.FloatTensor([e[1] for e in experiences]).to(device)rewards = torch.FloatTensor([e[2] for e in experiences]).unsqueeze(1).to(device)next_states = torch.FloatTensor([e[3] for e in experiences]).to(device)dones = torch.FloatTensor([float(e[4]) for e in experiences]).unsqueeze(1).to(device)return states, actions, rewards, next_states, donesdef __len__(self):return len(self.memory)# 神经网络定义
def hidden_init(layer):fan_in = layer.weight.data.size()[0]lim = 1. / np.sqrt(fan_in)return (-lim, lim)class PolicyNet(nn.Module):def __init__(self, state_dim, hidden_dim, action_dim, action_bound):super(PolicyNet, self).__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, action_dim)self.action_bound = action_bound # 动作最大值# 初始化权重self.fc1.weight.data.uniform_(*hidden_init(self.fc1))self.fc2.weight.data.uniform_(-3e-3, 3e-3)def forward(self, x):x = F.relu(self.fc1(x))return torch.tanh(self.fc2(x)) * self.action_boundclass QValueNet(nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(QValueNet, self).__init__()self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, hidden_dim)self.fc_out = nn.Linear(hidden_dim, 1)# 初始化权重self.fc1.weight.data.uniform_(*hidden_init(self.fc1))self.fc2.weight.data.uniform_(*hidden_init(self.fc2))self.fc_out.weight.data.uniform_(-3e-3, 3e-3)def forward(self, x, a):cat = torch.cat([x, a], dim=1) # 拼接状态和动作x = F.relu(self.fc1(cat))x = F.relu(self.fc2(x))return self.fc_out(x)# DDPG智能体
class DDPGAgent:''' DDPG算法 '''def __init__(self, state_dim, hidden_dim, action_dim, action_bound, sigma, actor_lr, critic_lr, tau, gamma, device):self.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)# 初始化目标网络并设置和主网络相同的参数self.target_critic.load_state_dict(self.critic.state_dict())self.target_actor.load_state_dict(self.actor.state_dict())self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=critic_lr, weight_decay=WEIGHT_DECAY)self.gamma = gammaself.sigma = sigma # 高斯噪声的标准差self.tau = tau # 目标网络软更新参数self.action_dim = action_dimself.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)self.actor.eval()with torch.no_grad():action = self.actor(state).cpu().data.numpy().flatten()self.actor.train()# 给动作添加噪声,增加探索action += self.sigma * np.random.randn(self.action_dim)return np.clip(action, -self.actor.action_bound, self.actor.action_bound)def soft_update(self, net, target_net):for target_param, param in zip(target_net.parameters(), net.parameters()):target_param.data.copy_(param.data * self.tau + target_param.data * (1.0 - self.tau))def update(self, replay_buffer):if len(replay_buffer) < BATCH_SIZE:returnstates, actions, rewards, next_states, dones = replay_buffer.sample()# 更新Critic网络with torch.no_grad():next_actions = self.target_actor(next_states)Q_targets_next = self.target_critic(next_states, next_actions)Q_targets = rewards + (self.gamma * Q_targets_next * (1 - dones))Q_expected = self.critic(states, actions)critic_loss = F.mse_loss(Q_expected, Q_targets)self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()# 更新Actor网络actor_loss = -torch.mean(self.critic(states, self.actor(states)))self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()# 软更新目标网络self.soft_update(self.critic, self.target_critic)self.soft_update(self.actor, self.target_actor)3.3 运行结果
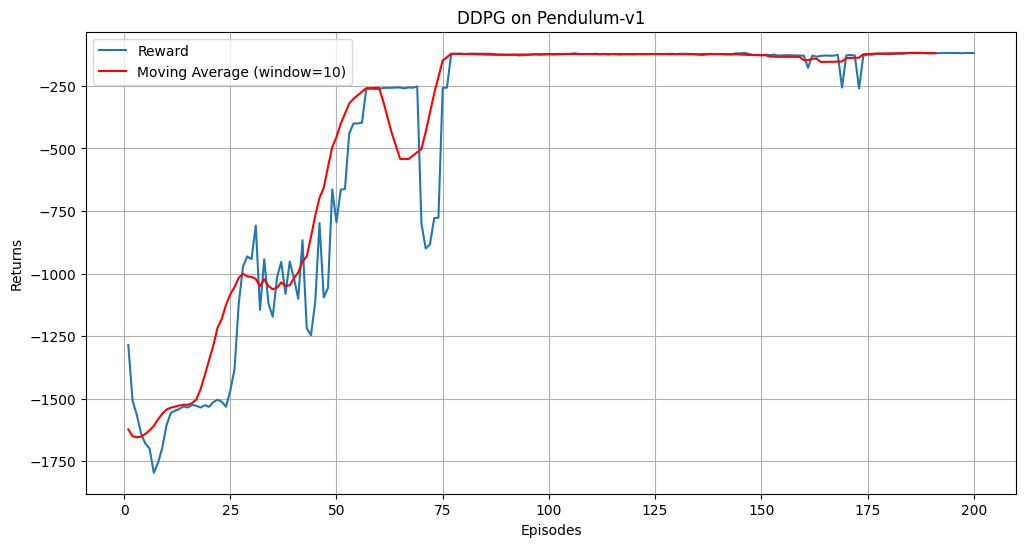
Episode 10 Average Score: -1623.12
Episode 20 Average Score: -1536.40
Episode 30 Average Score: -1287.98
Episode 40 Average Score: -1021.30
Episode 50 Average Score: -995.55
Episode 60 Average Score: -401.11
Episode 70 Average Score: -311.09
Episode 80 Average Score: -433.98
Episode 90 Average Score: -122.43
Episode 100 Average Score: -125.27
Episode 110 Average Score: -122.54
Episode 120 Average Score: -122.86
Episode 130 Average Score: -122.51
Episode 140 Average Score: -123.11
Episode 150 Average Score: -122.93
Episode 160 Average Score: -127.22
Episode 170 Average Score: -146.53
Episode 180 Average Score: -138.31
Episode 190 Average Score: -119.34
Episode 200 Average Score: -118.65
在Pendulum-v0环境中,DDPG智能体经过200个回合的训练后,奖励曲线应逐渐上升,表明智能体的策略在不断优化。滑动平均曲线更平滑,能够更清晰地反映训练趋势。
四、总结
DDPG算法通过结合演员-评论家架构、经验回放和目标网络等技术,有效地解决了连续动作空间中的强化学习问题。在Pendulum-v0环境中的应用展示了其强大的学习能力和策略优化效果。随着研究的深入,DDPG及其衍生算法在更多复杂任务中的应用前景广阔。
相关文章:
强化学习之DDPG算法
前言: 在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。 一、算法介绍 深度确定性策略梯度 ࿰…...

【进阶OpenCV】 (16)-- 人脸识别 -- FisherFaces算法
文章目录 FisherFaces算法一、算法原理二、算法优势与局限三、算法实现1. 图像预处理2. 创建FisherFace人脸特征识别器3. 训练模型4. 测试图像 总结 FisherFaces算法 PCA方法是EigenFaces人脸识别的核心,但是其具有明显的缺点,在操作过程中会损失许多人…...

电脑主机配置
显卡: 查看显卡:设备管理器--显示适配器 RTX4060 RTX和GTX区别: GTX是NVIDIA公司旧款显卡,RTX比GTX好但是贵 处理器CPU: Intel(R) Core(TM) i5-10400F CPU 2.90GHz 2.90 GHz 10400F:10指的是第几代…...
图书借阅小程序开源独立版
图书借阅微信小程序,多书馆切换模式,书馆一键同步图书信息,开通会员即可在线借书,一书一码书馆员工手机扫码出入库从会员到书馆每一步信息把控图书借阅小程序,让阅读触手可及在这个快节奏的时代,你是否渴望…...

flutter TextField限制中文,ios自带中文输入法变英文输入问题解决
由于业务需求,要限制TextField只能输入中文,但是测试在iOS测试机发现自带中文输入法会变英文输入问题,安卓没有问题,并且只有iOS自带输入法有问题,搜狗等输入法没问题。我们目前使用flutter2.5.3版本,高版本…...

ThreadLocal的应用场景
ThreadLocal介绍 ThreadLocal为每个线程都提供了变量的副本,使得每个线程访问各自独立的对象,这样就隔离了多个线程对数据的共享,使得线程安全。ThreadLocal有如下方法: 方法声明 描述public void set(T value)设置当前线程绑定的…...

Python--plt.errorbar学习笔记
plt.errorbar 是 Matplotlib 库中的一个函数,用于绘制带有误差条的图形。下面给出的代码行的详细解释: import numpy as np from scipy.special import kv, erfc from scipy.integrate import dblquad import matplotlib.pyplot as plt import scipy.in…...

文件信息类QFileInfo
常用方法: 构造函数 //参数:文件的绝对路径或相对路径 [explicit] QFileInfo::QFileInfo(const QString &path) 设置文件路径 可构造一个空的QFileInfo的对象,然后设置路径 //参数:文件的绝对路径或相对路径 void QFileI…...

堆排序(C++实现)
参考: 面试官:请写一个堆排序_哔哩哔哩_bilibiliC实现排序算法_c从小到大排序-CSDN博客 堆的基本概念 堆排实际上是利用堆的性质来进行排序。堆可以看做一颗完全二叉树。 堆分为两类: 最大堆(大顶堆):除根…...

Qt中加入UI文件
将 UI 文件整合到 Qt 项目 使用 Qt Designer 创建 UI 文件: 在 Qt Creator 中使用 Qt Designer 创建 UI 文件,设计所需的界面。确保在设计中包含所需的控件(如按钮、文本框等),并为每个控件设置明确的对象名称…...

Redisson使用全解
redisson使用全解——redisson官方文档注释(上篇)_redisson官网中文-CSDN博客 redisson使用全解——redisson官方文档注释(中篇)-CSDN博客 redisson使用全解——redisson官方文档注释(下篇)_redisson官网…...

Go4 和对 Go 的贡献
本篇内容是根据2017年4月份Go4 and Contributing to Go音频录制内容的整理与翻译, Brad Fitzpatrick 加入节目谈论成为开源 Go 的代言人、让社区参与 bug 分类、Go 的潜在未来以及其他有趣的 Go 项目和新闻。 过程中为符合中文惯用表达有适当删改, 版权归原作者所有. Erik St…...

区间动态规划
区间动态规划(Interval DP)是动态规划的一种重要变种,特别适用于解决一类具有区间性质的问题。典型的应用场景是给定一个区间,要求我们在满足某些条件下进行最优划分或合并。本文将从区间DP的基本思想、常见问题模型以及算法实现几…...

什么情况下需要使用电压探头
高压探头是一种专门设计用于测量高压电路或设备的探头,其作用是在电路测试和测量中提供安全、准确的信号捕获,并确保操作人员的安全。这些探头通常用于测量高压电源、变压器、电力系统、医疗设备以及其他需要处理高电压的设备或系统。 而高压差分探头差分…...
)
数据结构——八大排序(下)
数据结构中的八大排序算法是计算机科学领域经典的排序方法,它们各自具有不同的特点和适用场景。以下是这八大排序算法的详细介绍: 五、选择排序(Selection Sort) 核心思想:每一轮从未排序的元素中选择最小࿰…...

Linux系统:Ubuntu上安装Chrome浏览器
Ubuntu系统版本:23.04 在Ubuntu系统上安装Google Chrome浏览器,可以通过以下步骤进行: 终端输入以下命令,先更新软件源: sudo apt update 或 sudo apt upgrade终端输入以下命令,下载最新的Google Chrome .…...

Redis位图BitMap
一、为什么使用位图? 使用位图能有效实现 用户签到 等行为,用数据库表记录签到,将占用很多存储;但使用 位图BitMap,就能 大大减少存储占用 二、关于位图 本质上是String类型,最小长度8位(一个字…...

YOLOv11改进策略【卷积层】| ParNet 即插即用模块 二次创新C3k2
一、本文介绍 本文记录的是利用ParNet中的基础模块优化YOLOv11的目标检测网络模型。 ParNet block是一个即插即用模块,能够在不增加深度的情况下增加感受野,更好地处理图像中的不同尺度特征,有助于网络对输入数据更全面地理解和学习,从而提升网络的特征提取能力和分类性能…...

学习threejs,网格深度材质MeshDepthMaterial
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️网格深度材质MeshDepthMate…...

算法时间、空间复杂度(二)
目录 大O渐进表示法 一、时间复杂度量级的判断 定义: 例一:执行2*N+1次 例二:执行MN次 例三:执行已知次数 例四:存在最好情况和最坏情况 顺序查找 冒泡排序 二分查找 例五:阶乘递归 编辑 例…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...