CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
全是干货 | 数据集、学习资料、建模资源分享!
EMD、EEMD、FEEMD、CEEMD、CEEMDAN的区别、原理和Python实现(一)EMD-CSDN博客
EMD、EEMD、FEEMD、CEEMD、CEEMDAN的区别、原理和Python实现(二)EEMD
EMD、EEMD、FEEMD、CEEMD、CEEMDAN的区别、原理和Python实现(三)FEEMD-CSDN博客
EMD、EEMD、FEEMD、CEEMD、CEEMDAN的区别、原理和Python实现(四)CEEMD-CSDN博客
EMD变体分解效果最好算法——CEEMDAN(五)-CSDN博客
拒绝信息泄露!VMD滚动分解 + Informer-BiLSTM并行预测模型-CSDN博客
风速预测(一)数据集介绍和预处理_风速数据在哪里下载-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
前言
本文基于前期介绍的风速数据(文末附数据集),介绍一种综合应用完备集合经验模态分解CEEMDAN与混合预测模型(BiLSTM-Attention + ARIMA)的方法,以提高时间序列数据的预测性能。该方法的核心是使用CEEMDAN算法对时间序列进行分解,接着利用BiLSTM-Attention模型和ARIMA模型对分解后的数据进行建模,最终通过集成方法结合两者的预测结果。
风速数据集的详细介绍可以参考下文:
风速预测(一)数据集介绍和预处理_weather in szeged 2006-2016-CSDN博客
1 风速数据CEEMDAN分解与可视化
1.1 导入数据

1.2 CEEMDAN分解

根据分解结果看,CEEMDAN一共分解出11个分量,我们大致把前7个高频分量作为BiLSTM-Attention模型的输入进行预测,后4个低频分量作为ARIMA模型的输入进行预测
2 数据集制作与预处理
2.1 划分数据集
按照8:2划分训练集和测试集, 然后再按照前7后4划分分量数据

2.2 设置滑动窗口大小为7,制作数据集
# 定义滑动窗口大小
window_size = 7
# 分量划分分界
imf_no = 7 # 第一步,划分数据集
dataset1, dataset2 = make_wind_dataset(wind_emd_imfs, imf_no)
# 第二步,制作数据集标签 滑动窗口
# BiLSTM-Attention 模型数据
train_set1, train_label1 = data_window_maker(dataset1[0], window_size)
test_set1, test_label1 = data_window_maker(dataset1[1], window_size)# ARIMA 模型数据
train_data_arima = dataset2[0]
test_data_arima = dataset2[1]# 保存数据
dump(train_set1, 'train_set1')
dump(train_label1, 'train_label1')
dump(test_set1, 'test_set1')
dump(test_label1, 'test_label1')dump(train_data_arima, 'train_data_arima')
dump(test_data_arima, 'test_data_arima')
分批保存数据,用于不同模型的预测
3 基于CEEMADN的BiLSTM-Attention模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载数据集
def dataloader(batch_size, workers=2):# 训练集train_set = load('train_set1')train_label = load('train_label1')# 测试集test_set = load('test_set1')test_label = load('test_label1')# 加载数据train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_set, train_label),batch_size=batch_size, num_workers=workers, drop_last=True)test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_set, test_label),batch_size=batch_size, num_workers=workers, drop_last=True)return train_loader, test_loaderbatch_size = 64
# 加载数据
train_loader, test_loader = dataloader(batch_size)3.2 定义CEEMDAN-BiLSTM-Attention预测模型

注意:输入风速数据形状为 [64, 7, 7], batch_size=64, 维度7维代表7个分量,7代表序列长度(滑动窗口取值)。
3.3 定义模型参数
# 定义模型参数
batch_size = 64
input_len = 48 # 输入序列长度为96 (窗口值)
input_dim = 7 # 输入维度为7个分量
hidden_layer_sizes = [32, 64] # LSTM 层 结构 隐藏层神经元个数
attention_dim = hidden_layer_sizes[-1] # 注意力层维度 默认为 LSTM输出层维度
output_size = 1 # 单步输出model = BiLSTMAttentionModel(batch_size, input_len, input_dim, attention_dim, hidden_layer_sizes, output_size=1) # 定义损失函数和优化函数
model = model.to(device)
loss_function = nn.MSELoss() # loss
learn_rate = 0.003
optimizer = torch.optim.Adam(model.parameters(), learn_rate) # 优化器3.4 模型训练

训练结果

100个epoch,MSE 为0.00559,BiLSTM-Attention预测效果良好,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加BiLSTM层数和隐藏层的维度,微调学习率;
-
调整注意力维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
保存训练结果和预测数据,以便和后面ARIMA模型的结果相组合。
4 基于ARIMA的模型预测
传统时序模型(ARIMA等模型)教程如下:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
4.1 数据加载
训练数据、测试数据分组,四个分量,划分四个数据集
# 加载数据
from joblib import dump, load
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')# 训练集
train_set = load('train_data_arima')
# 测试集
test_set = load('test_data_arima')# IMF1-Model1
model1_train = train_set[0, :]
model1_test = test_set[0, :]
# IMF2-Model2
model2_train = train_set[1, :]
model2_test = test_set[1, :]
# IMF3-Model3
model3_train = train_set[2, :]
model3_test = test_set[2, :]
# IMF4-Model4
model4_train = train_set[3, :]
model4_test = test_set[3, :]4.2 介绍一个分量预测过程(其他分量类似)
第一步,单位根检验和差分处理

ADF检验P值远小于0.05,故拒绝原假设,即数据是平稳的时间序列数据,也确定了d=0
第二步,模型识别,采用AIC指标进行参数选择

采用AIC指标进行参数选择,得到最小的AIC值的组合为p=2,q=0,选择其作为模型进行拟合,因此针对原数据可知最终确定模型为ARIMA(2,0,0)(结合代码指标结果来看)
第三步,模型预测

第四步,模型评估

保存预测的数据,其他分量预测与上述过程一致,保留最后模型结果即可。
5 结果可视化和模型评估
5.1 组合预测,加载各模型的预测结果
# 训练集
arima_train_set = load('train_data_arima')
# 测试集
arima_test_set = load('test_data_arima')# IMF1-Model1
model1_imf_arima_pre = load('model1_imf_arima_pre')
# IMF2-Model2
model2_imf_arima_pre = load('model2_imf_arima_pre')
# IMF3-Model3
model3_imf_arima_pre = load('model3_imf_arima_pre')
# IMF4-Model4
model4_imf_arima_pre = load('model4_imf_arima_pre')# BiLSTM-Attention
original_label_bilstmatt = load('original_label_bilstmatt')
pre_data_bilstmatt = load('pre_data_bilstmatt')5.2 结果可视化


5.3 模型评估
由分量预测结果可见,前7个分量在BiLSTM-Attention预测模型下拟合效果良好,分量9在ARIMA模型的预测下,拟合程度比较好,其他低频分量拟合效果弱一点,调整参数可增强拟合效果。

6 代码、数据整理如下:

相关文章:
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)
往期精彩内容: 时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较 全是干货 | 数据集、学习资料、建模资源分享! EMD、EEMD、FEEMD、CEEMD、CEEMDAN的区别、原理和Python实现(一)EMD-CSDN博客 EMD、EEM…...

2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体
2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体 2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体 文章目录 2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体KIDTENTRY KIDTENTRY 数据结构KIDTENTRY定义了CPU对中断描述符的格式 // // …...

三、ElementPlus下拉搜索加弹窗组件的封装
近期产品提出了一个需求,要求一个form的表单里面的一个组件既可以下拉模糊搜索,又可以弹窗搜索,我就为这个封装了一个组件,下面看效果图。 效果大家看到了,下面就看组件封装和实现方法 第一步,组件封装&…...

androidStudio编译导致的同名.so文件冲突问题解决
files found with path lib/arm64-v8a/libserial_port.so from inputs: ...\build\intermediates\library_jni\debug\jni\arm64-v8a\libserial_port.so C:\Users\...\.gradle\caches\transforms-3\...\jni\arm64-v8a\XXX.so 解决方式如下: 1.将gradle缓存文件删…...

大学新生编程入门指南:如何选择编程语言与制定学习计划
大学新生编程入门指南:如何选择编程语言与制定学习计划 编程已成为当代大学生的必备技能,尤其是在信息技术高速发展的今天,编程能力不仅能帮助你在课堂学习中脱颖而出,更能为未来职业生涯打下坚实的基础。然而,面对如…...

SpringAI快速上手
一、导入依赖 镜像(导入maven依赖) <repositories><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>…...

07 django管理系统 - 部门管理 - 搜索部门
在dept_list.html中,添加搜索框 <div class"container-fluid"><div style"margin-bottom: 10px" class"clearfix"><div class"panel panel-default"><!-- Default panel contents --><div clas…...

数据操作学习
1.导入torch。虽然被称为PyTorch,但应导入torch而不是pytorch import torch 2.张量表示一个数值组成的数组,这个数组可能有多个维度 xtorch.arange(12)x 3.通过张量的shape属性来访问张量的形状和张量中元素的总数 x.shape x.numel() 4.要改变张量的形…...

什么是网络代理
了解网络代理 网络代理是一种特殊的网络服务,它允许一个网络终端(通常指客户端)通过这个服务与另一个网络终端(通常指服务器)进行非直接的连接。网络代理服务器位于发送主机和接收主机之间,接收网络请求&a…...

安防监控摄像头图传模组,1公里WiFi无线传输方案,监控新科技
在数字化浪潮汹涌的今天,安防监控领域也迎来了技术革新的春风。今天,我们就来聊聊这一领域的产品——摄像头图传模组,以及它如何借助飞睿智能1公里WiFi无线传输技术,为安防监控带来未有的便利与高效。 一、安防监控的新篇章 随着…...

问:JVM中GC类型有哪些?触发条件有哪些?区别是啥?
在Java虚拟机(JVM)中,垃圾收集(GC)是自动管理内存的关键机制。GC负责识别并回收那些不再被程序使用的对象,以释放内存空间。根据回收的区域和策略的不同,JVM中的GC可以分为多种类型。 一、GC的…...

【操作系统的使用】Linux 输入输出重定向:掌握控制台的高级用法
文章目录 Linux 输入输出重定向:掌握控制台的高级用法输出重定向将命令输出保存到文件将命令输出追加到文件 输入重定向从文件读取输入 管道操作将多个命令的输出链接起来 错误重定向将错误信息保存到文件同时重定向输出和错误信息 Linux 输入输出重定向:…...

无线通信中的四个关键概念:OFDM、多径效应、CSI和信道均衡
无线通信中的四个关键概念:OFDM、多径效应、CSI和信道均衡 无线通信技术在现代通信系统中发挥着至关重要的作用。无论是日常的手机通信,还是复杂的物联网应用,理解无线信道的特性和优化信号传输的技术是关键。在本文中,我们将介绍…...
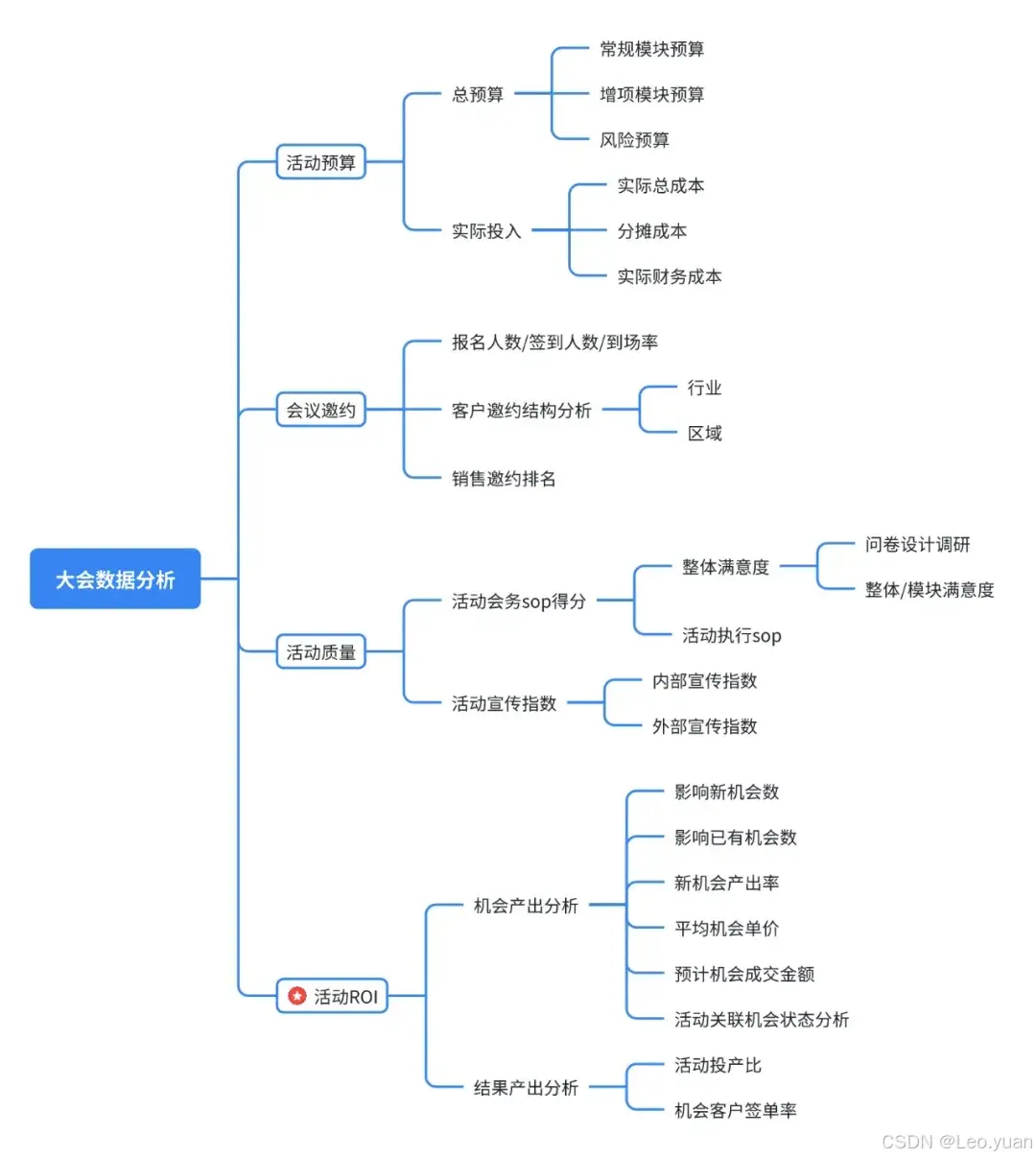
如何高效规划千人大会?数字化会议管理的实战经验分享!建议收藏!
在当今快节奏的商业环境中,大型会议不仅是企业展示自身实力、促进交流合作的重要平台,更是推动行业发展、分享创新思维的关键活动。然而,随着参会人数的增加,如何高效规划并管理一场千人大会,成为了组织者面临的巨大挑…...
)
mysql指令笔记(基本)
一、数据库操作 创建数据库:CREATE DATABASE database_name;选择数据库:USE database_name;删除数据库:DROP DATABASE database_name; 二、表操作 创建表:CREATE TABLE table_name (column1 datatype constraint, column2 datat…...

web前端-----html5----用户注册
以改图为例 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <title>用户注册</title> </hea…...

bug的定义和测试
一、软件测试的生命周期 软件测试的⽣命周期是指测试流程,这个流程是按照⼀定顺序执⾏的⼀系列特定的步骤,去保证产品 质量符合需求。在软件测试⽣命周期流程中,每个活动都按照计划的系统的执⾏。每个阶段有不同的 ⽬标和交付产物 需求分析…...

Kamailio-Sngrep 短小精悍的利器
一个sip的抓包小工具,在GitHub上竟然能够积累1K的star,看来还是有点东西,当然官方的友链也是发挥了重要作用 首先送上项目地址,有能力的宝子可以自行查看 经典的网络抓包工具有很多,比如: Wireshark&…...

9.6 Linux_I/O_IO模型
基本概念 I/O执行过程与分类: 用户进程中的一个完整I/O分为 "用户进程空间->内核空间->设备空间(磁盘、网卡)" 这两个阶段。 I/O可以分为内存I/O、网络I/O、磁盘I/O 同步和异步是什么: 1、对于线程的请求调用,同步与异步…...
:fiber 架构)
React 探秘(一):fiber 架构
文章目录 背景React 采用 fiber 主要为了解决哪些问题?性能问题:用户体验问题: 为什么在 React 15 版本中性能会差:浏览器绘制原理:react 15 架构和问题 那么 fiber 怎么解决了这个问题?任务“大”的问题递…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...