FLINK SQL 元数据持久化扩展
Flink SQL元数据持久化扩展是一个复杂但重要的过程,它允许Flink作业在重启或失败后能够恢复状态,从而确保数据处理的连续性和准确性。以下是对Flink SQL元数据持久化扩展的详细分析:
一、元数据持久化的重要性
在Flink中,元数据包括作业的拓扑结构、状态、检查点等关键信息。这些信息对于作业的恢复和容错至关重要。元数据持久化可以确保这些信息在作业失败或重启时不会丢失,从而允许作业从上一个成功的状态点恢复执行。
二、Flink SQL元数据持久化的实现方式
Flink SQL元数据持久化通常通过以下方式实现:
- Catalog和Table API:
- Flink提供了Catalog和Table API,允许用户定义和管理元数据。
- 通过Catalog,用户可以创建、修改和删除数据库、表和视图等元数据对象。
- Table API则提供了丰富的SQL查询功能,允许用户对表进行各种操作。
- 状态后端(State Backend):
- Flink支持多种状态后端,如RocksDB、Heap State Backend等。
- 状态后端用于存储和管理作业的状态信息,包括键值对状态、列表状态等。
- 当作业失败或重启时,状态后端可以恢复这些状态信息,从而确保作业的连续性。
- 检查点(Checkpointing):
- Flink提供了检查点机制,允许用户在作业执行过程中定期保存状态。
- 检查点包含作业的完整状态信息,包括数据源、操作符状态、输出等。
- 当作业失败时,Flink可以从上一个成功的检查点恢复执行。
三、Flink SQL元数据持久化扩展的实践
- 配置Catalog和Table API:
- 用户需要在Flink作业中配置Catalog,以便管理和访问元数据。
- 可以通过Flink的配置文件或代码方式创建和配置Catalog。
- 使用Table API定义和管理表结构,包括字段类型、分区信息等。
- 选择合适的状态后端:
- 根据作业的需求和性能要求,选择合适的状态后端。
- 对于需要持久化大量状态信息的作业,推荐使用RocksDB状态后端。
- 对于需要快速访问和修改状态信息的作业,可以选择Heap State Backend。
- 启用检查点机制:
- 在Flink作业中启用检查点机制,并配置检查点的间隔时间。
- 确保检查点存储位置是可靠的,以便在作业失败时能够恢复状态。
- 可以根据需要配置异步检查点、增量检查点等高级特性。
- 监控和管理元数据:
- 使用Flink的Web UI或其他监控工具监控作业的元数据状态。
- 定期检查作业的状态信息,确保元数据的一致性和完整性。
- 在作业失败或异常时,及时查看和分析元数据日志,以便快速定位问题并恢复作业。
四、案例分享
假设有一个实时数据处理作业,需要处理来自Kafka的数据流,并将处理结果写入HDFS。为了确保作业的连续性和容错性,可以采取以下元数据持久化扩展措施:
- 配置Hive Catalog:
- 在Flink作业中配置Hive Catalog,以便管理和访问Hive中的元数据。
- 使用Hive Catalog定义和管理作业所需的数据库和表结构。
- 选择RocksDB状态后端:
- 由于作业需要持久化大量状态信息,选择RocksDB状态后端进行存储。
- 配置RocksDB的相关参数,如存储路径、压缩算法等。
- 启用检查点机制:
- 在Flink作业中启用检查点机制,并配置检查点的间隔时间为5分钟。
- 将检查点存储到HDFS上,以确保在作业失败时能够恢复状态。
- 监控和管理元数据:
- 使用Flink的Web UI监控作业的元数据状态。
- 定期检查作业的状态信息,确保元数据的一致性和完整性。
- 在作业失败时,及时查看和分析元数据日志,以便快速定位问题并恢复作业。
GenericMemoryCatalog
Flink SQL中的GenericMemoryCatalog是一种基于内存实现的元数据管理机制,它为Flink作业提供了一个轻量级的元数据存储解决方案。以下是对GenericMemoryCatalog的详细解析:
1、GenericMemoryCatalog概述
GenericMemoryCatalog是Flink SQL内置的一种Catalog实现,它完全在内存中存储元数据,因此具有访问速度快、配置简单等优点。然而,由于数据存储在内存中,GenericMemoryCatalog的元数据在Flink会话(session)结束后会丢失,因此它通常用于测试环境或临时数据处理任务中。
1、GenericMemoryCatalog的特点
- 内存存储:
- GenericMemoryCatalog的元数据完全存储在内存中,因此不需要额外的存储资源。
- 由于内存访问速度快,GenericMemoryCatalog能够提供高效的元数据查询和更新操作。
- 会话级生命周期:
- GenericMemoryCatalog的元数据只在当前Flink会话的生命周期内有效。
- 当会话结束时,存储在GenericMemoryCatalog中的元数据会丢失,无法持久化。
- 默认Catalog:
- 在Flink SQL CLI或Table API中,如果没有指定其他Catalog,Flink会默认使用GenericMemoryCatalog。
- 默认情况下,GenericMemoryCatalog包含一个名为“default_database”的数据库。
3、GenericMemoryCatalog的使用场景
- 测试环境:
- 在测试Flink SQL查询或作业时,可以使用GenericMemoryCatalog来模拟元数据环境。
- 由于数据存储在内存中,测试过程可以更加快速和高效。
- 临时数据处理:
- 对于一些临时数据处理任务,如数据清洗、转换等,可以使用GenericMemoryCatalog来存储和管理元数据。
- 这些任务通常不需要持久化元数据,因此使用GenericMemoryCatalog是一个合适的选择。
4、使用GenericMemoryCatalog的注意事项
- 数据持久化需求:
- 如果需要持久化元数据,以便在Flink会话结束后仍能访问,应使用其他类型的Catalog,如HiveCatalog或JdbcCatalog。
- 并发访问:
- 由于GenericMemoryCatalog是基于内存的,因此在高并发访问场景下可能需要考虑性能问题。
- 在实际应用中,应根据具体需求和场景选择合适的Catalog实现。
- 大小写敏感:
- 与HiveCatalog不同,GenericMemoryCatalog是区分大小写的。
- 在创建数据库、表等元数据对象时,需要注意名称的大小写。
JdbcCatalog
link SQL中的JdbcCatalog是一种允许Flink通过JDBC协议连接到关系型数据库,并将数据库的元数据作为Catalog使用的机制。以下是对JdbcCatalog的详细解析:
一、JdbcCatalog概述
JdbcCatalog是Flink SQL提供的一种External Catalog,它使得Flink能够直接查询和操作关系型数据库(如MySQL、PostgreSQL等)中的元数据。通过JdbcCatalog,Flink可以无缝地集成到现有的数据库环境中,利用数据库的元数据管理能力来优化数据处理流程。
二、JdbcCatalog的特点
- JDBC协议支持:
- JdbcCatalog基于JDBC协议与关系型数据库进行通信,因此支持所有遵循JDBC标准的数据库。
- 元数据管理:
- JdbcCatalog允许Flink访问和操作数据库的元数据,包括数据库、表、视图、列等。
- 这使得Flink能够利用数据库的元数据来优化查询计划、提高数据处理效率。
- 数据转换和导入:
- 通过JdbcCatalog,Flink可以实现对JDBC数据源的数据转换和导入操作。
- 这使得Flink能够轻松地与现有的数据库系统集成,实现数据的无缝流动。
- 可扩展性:
- JdbcCatalog是可扩展的,用户可以根据需要自定义JDBC驱动和连接属性。
- 这使得JdbcCatalog能够支持更多种类的关系型数据库,满足不同的数据处理需求。
三、JdbcCatalog的配置和使用
- 配置JdbcCatalog:
- 在Flink的配置文件(如flink-conf.yaml)中,需要指定JdbcCatalog的类型、数据库连接信息(如URL、用户名、密码等)以及JDBC驱动的相关信息。
- 配置完成后,Flink将能够识别并使用JdbcCatalog来访问和操作数据库的元数据。
- 使用JdbcCatalog:
- 在Flink SQL客户端或Table API中,用户可以通过指定JdbcCatalog的名称来访问和操作数据库的元数据。
- 例如,可以使用SHOW DATABASES FROM <catalog_name>来列出JdbcCatalog中所有的数据库,使用USE <catalog_name>.<database_name>来切换到指定的数据库,以及使用SELECT * FROM <catalog_name>.<database_name>.<table_name>来查询数据库中的表数据。
四、JdbcCatalog的应用场景
JdbcCatalog适用于以下场景:
- 数据集成:
- 当需要将Flink与现有的关系型数据库系统集成时,可以使用JdbcCatalog来实现数据的无缝流动和集成。
- 数据迁移:
- 在数据迁移过程中,可以使用JdbcCatalog将源数据库中的元数据迁移到目标数据库中,确保数据的一致性和完整性。
- 数据查询和分析:
- 通过JdbcCatalog,Flink可以实现对关系型数据库中数据的查询和分析操作,满足不同的数据处理需求。
HiveCatalog
Flink SQL中的HiveCatalog是Flink与Hive集成的重要组件,它使得Flink能够利用Hive的元数据管理能力来优化数据处理流程。以下是对HiveCatalog的详细解析:
一、概述
HiveCatalog是Flink提供的一种External Catalog,它基于Hive的元数据管理机制,使得Flink能够直接查询和操作Hive中的元数据。HiveCatalog不仅支持Hive的DDL(数据定义语言)操作,如创建表、删除表、修改表结构等,还提供了对Hive中数据的访问接口,使得Flink能够轻松地与Hive集成,实现数据的无缝流动和查询分析操作。
二、特点
- 元数据管理:
- HiveCatalog能够存储和管理Hive的元数据,包括数据库、表结构、分区、列信息等。
- 通过HiveCatalog,Flink可以访问和操作Hive中的元数据,实现跨系统的数据集成和查询分析。
- Hive兼容性:
- HiveCatalog完全兼容Hive的元数据管理机制,支持Hive的DDL操作和查询语法。
- 这使得Flink能够无缝地集成到Hive环境中,实现与Hive的互操作性。
- 数据持久化:
- 与GenericMemoryCatalog不同,HiveCatalog将元数据存储在Hive Metastore中,实现了数据的持久化。
- 这意味着即使Flink会话结束,存储在HiveCatalog中的元数据也不会丢失。
- 高性能:
- HiveCatalog利用了Hive的元数据管理机制和查询优化技术,提高了数据处理的性能和效率。
- 通过HiveCatalog,Flink可以更快地访问和操作Hive中的数据,实现实时数据处理和分析。
三、配置和使用
- 配置HiveCatalog:
- 在配置HiveCatalog时,需要指定Hive Metastore的连接信息(如Hive Metastore的URI、用户名、密码等)以及Hive的配置文件路径(如hive-site.xml)。
- 配置完成后,Flink将能够识别并使用HiveCatalog来访问和操作Hive的元数据。
- 使用HiveCatalog:
- 在Flink SQL客户端或Table API中,用户可以通过指定HiveCatalog的名称来访问和操作Hive的元数据。
- 例如,可以使用SHOW DATABASES FROM <catalog_name>来列出HiveCatalog中所有的数据库,使用USE <catalog_name>.<database_name>来切换到指定的数据库,以及使用SELECT * FROM <catalog_name>.<database_name>.<table_name>来查询Hive中的表数据。
四、应用场景
HiveCatalog适用于以下场景:
- 数据集成:
- 当需要将Flink与Hive集成时,可以使用HiveCatalog来实现数据的无缝流动和集成。
- 通过HiveCatalog,Flink可以访问和操作Hive中的数据,实现跨系统的数据分析和查询。
- 数据迁移:
- 在数据迁移过程中,可以使用HiveCatalog将源Hive中的元数据迁移到目标Hive中,确保数据的一致性和完整性。
- 实时数据处理:
- 利用HiveCatalog的高性能和实时数据处理能力,Flink可以实现对Hive中数据的实时查询和分析操作。
- 这使得Flink能够更快地响应业务需求,提高数据处理和决策的效率。
用户自定义Catalog
在Flink SQL中,自定义Catalog是一种强大的功能,它允许用户根据自己的需求实现特定的元数据管理机制。以下是对Flink SQL自定义Catalog的详细解析:
一、自定义Catalog的概述
自定义Catalog是Flink提供的一种扩展机制,允许用户根据自己的业务需求和数据特点,实现特定的元数据管理方式。通过自定义Catalog,用户可以灵活地定义和管理数据库、表、视图、列等元数据,以及这些元数据与底层存储系统之间的映射关系。
二、自定义Catalog的实现步骤
- 定义Catalog接口的实现类:
- 用户需要实现Flink提供的Catalog接口或其子类(如AbstractJdbcCatalog等),以定义自定义Catalog的具体行为。
- 在实现类中,用户需要重写Catalog接口中的方法,如getDatabase、listDatabases、createTable、getTable等,以实现元数据的获取、管理和操作。
- 配置自定义Catalog:
- 在Flink的配置文件(如flink-conf.yaml)或代码中,用户需要指定自定义Catalog的类型和配置信息。
- 这通常包括自定义Catalog的实现类名、连接信息(如数据库URL、用户名、密码等)以及其他必要的配置参数。
- 注册自定义Catalog:
- 在Flink SQL客户端或Table API中,用户需要将自定义Catalog注册到Flink环境中。
- 这通常通过调用TableEnvironment的registerCatalog方法来实现,该方法需要传入自定义Catalog的名称和实现类实例。
三、自定义Catalog的应用场景
自定义Catalog适用于以下场景:
- 特定存储系统的集成:
- 当需要将Flink与特定的存储系统集成时(如NoSQL数据库、数据湖等),可以使用自定义Catalog来实现元数据的映射和管理。
- 这使得Flink能够无缝地访问和操作这些存储系统中的数据,实现跨系统的数据集成和查询分析。
- 元数据管理的优化:
- 对于某些特定的应用场景,用户可能需要优化元数据的管理方式以提高数据处理性能。
- 通过自定义Catalog,用户可以实现更高效的元数据获取、更新和删除操作,以满足业务需求。
- 数据安全和隐私保护:
- 在某些情况下,用户需要对数据进行安全和隐私保护。
- 通过自定义Catalog,用户可以实现更细粒度的访问控制和数据加密措施,以确保数据的安全性和隐私性。
相关文章:

FLINK SQL 元数据持久化扩展
Flink SQL元数据持久化扩展是一个复杂但重要的过程,它允许Flink作业在重启或失败后能够恢复状态,从而确保数据处理的连续性和准确性。以下是对Flink SQL元数据持久化扩展的详细分析: 一、元数据持久化的重要性 在Flink中,元数据…...

MySQL【知识改变命运】04
复习: 1:CURD 1.1Create (创建) 语法: insert [into] 表名 [column[,column]] valuse(value_list)[,vaule_list]... value_list:value,[value]...创建一个实例表: 1.1.1单⾏数据全列插⼊ values_l…...

AD9680(adc直采芯片)使用说明
写这篇文章之前我是没有使用过AD9680的芯片,但是使用过GMS011芯片(是国内24S)下的公司出来的芯片,寄存器和管脚全对标。 在这里我就大概说一下芯片的说用方法 一、硬件设计 该芯片支持双通道射频直采 支持协议JESD204B 14位 采样…...

无人机之位置信息计算篇
一、主要导航技术 卫星导航 全球定位系统(GPS):无人机上装有专门的接收器,用于捕获GPS系统发射的无线电信号。当无人机接收到来自至少四颗卫星的信号时,通过计算信号抵达时间的微小差异,即可运用三角定位…...

安卓cpu知识
背景 目前的cpu都是多核的,为了有更好的能效,每个核的频率从低往高不等。市面上,大家根据频率不同,都叫大小核。既然分了大小核,那么多核心,就要有不同的cpu调度策略。所以cpu上的所有核,又会根…...

图书管理新纪元:Spring Boot进销存系统
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理图书进销存管理系统的相关信息成为必然。开…...

Application protocol
5 应用协议 在 TS 31.101 [11] 的对应条款中所述的要求适用于 USIM 应用。 在执行后续章节“USIM 安全相关程序”和“订阅相关程序”中的程序之前,必须执行“USIM 管理程序”中列出的程序。“USIM 安全相关程序”中列出的程序是强制性的。“订阅相关程序”中列出的程…...
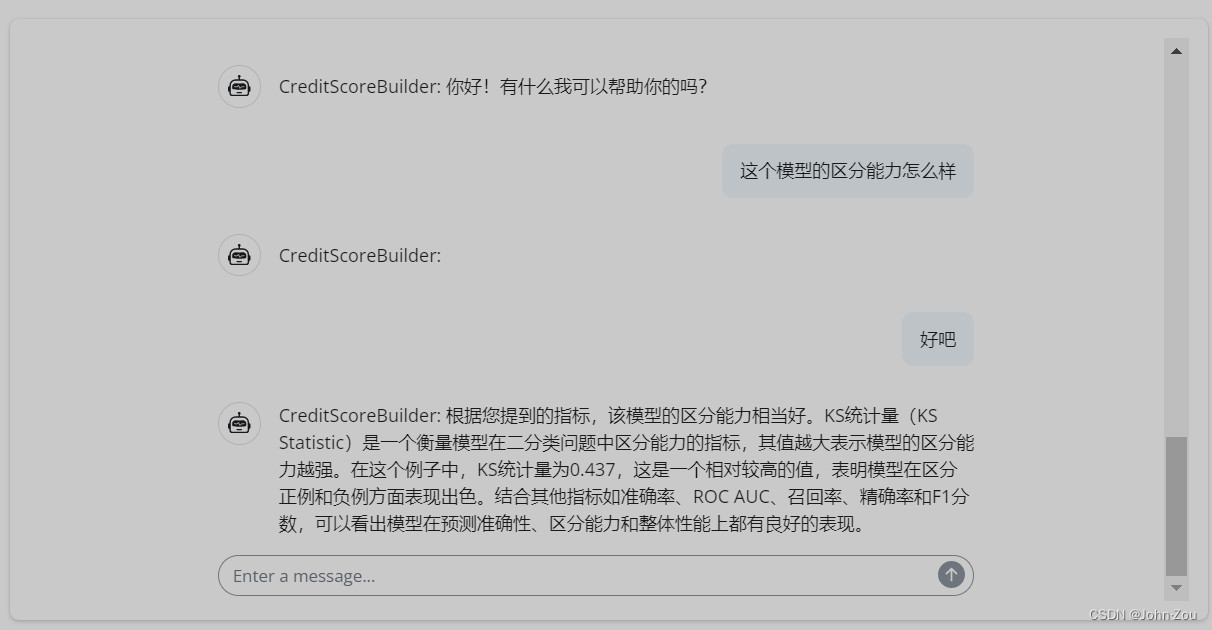
金融信用评分卡建模项目:AI辅助
最近我一直忙着开发一个信用评分卡建模工具,所以没有时间更新示例或动态。今天,我很高兴地跟大家分享,这个工具的基本框架已经完成了,并且探索性的将大语言模型(AI)整合了进去。目前ai在工具中扮演智能助手…...

java对接GPT 快速入门
统一对接GPT服务的Java说明 当前,OpenAI等GPT服务厂商主要提供HTTP接口,这使得大部分Java开发者在接入GPT时缺乏标准化的方法。 为解决这一问题,Spring团队推出了Spring AI ,它提供了统一且标准化的接口来对接不同的AI服务提供商…...
微信小程序引入组件教程
1、安装 node.js 下载网址:https://nodejs.org 2.通过 npm 安装 npm init -y npm i vant/weapp -S --production 3、修改 app.json 将 app.json 中的 “style”: “v2” 去除 4、修改 project.config.json 关于修改 project.config.json 的详细内容&#x…...

STM32—SPI通信外设
1.SPI外设简介 STM32内部集成了硬件SPI收发电路,可以由硬件自动执行时钟生成、数据收发等功能,减轻CPU的负担可配置8位/16位数据帧、高位先行/低位先行时钟频率:fpclk/(2,4,8,16,32,64,128,256)支持多主机模型、主或从操作可精简为半双工/单…...

Ubuntu:用户不在sudoers文件中
1、问题 执行sudo xxx命令时,显示: user 不在sudoers文件中 需要查看系统版本进入恢复模式修复。 2、重启进入恢复模式 查看系统命令:uname -r 可能显示为:6.8.0-45-generic 重启Ubuntu系统,在开机时按ESC进入模…...
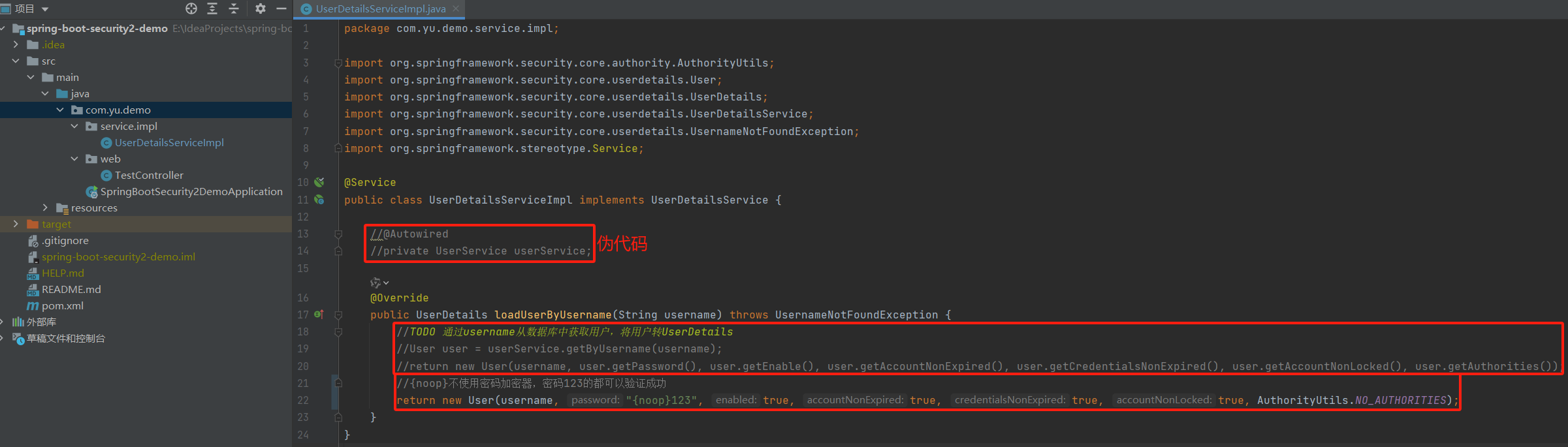
五、Spring Boot集成Spring Security之认证流程2
一、Spring Boot集成Spring Security专栏 一、Spring Boot集成Spring Security之自动装配 二、Spring Boot集成Spring Security之实现原理 三、Spring Boot集成Spring Security之过滤器链详解 四、Spring Boot集成Spring Security之认证流程 五、Spring Boot集成Spring Se…...

接口测试(全)
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1、什么是接口测试 顾名思义,接口测试是对系统或组件之间的接口进行测试,主要是校验数据的交换,传递和控制管理过程࿰…...

【学习】word保存图片
word中有想保存的照片 直接右键另存为的话,文件总是不清晰,截屏的话,好像也欠妥。 怎么办? 可以另存为 网页 .html 可以得到: 原图就放到了文件夹里面...

【实战篇】用SkyWalking排查线上[xxl-job xxl-rpc remoting error]问题
一、组件简介和问题描述 SkyWalking 简介 Apache SkyWalking 是一个开源的 APM(应用性能管理)工具,专注于微服务、云原生和容器化环境。它提供了分布式追踪、性能监控和依赖分析等功能,帮助开发者快速定位和解决性能瓶颈和故障。…...
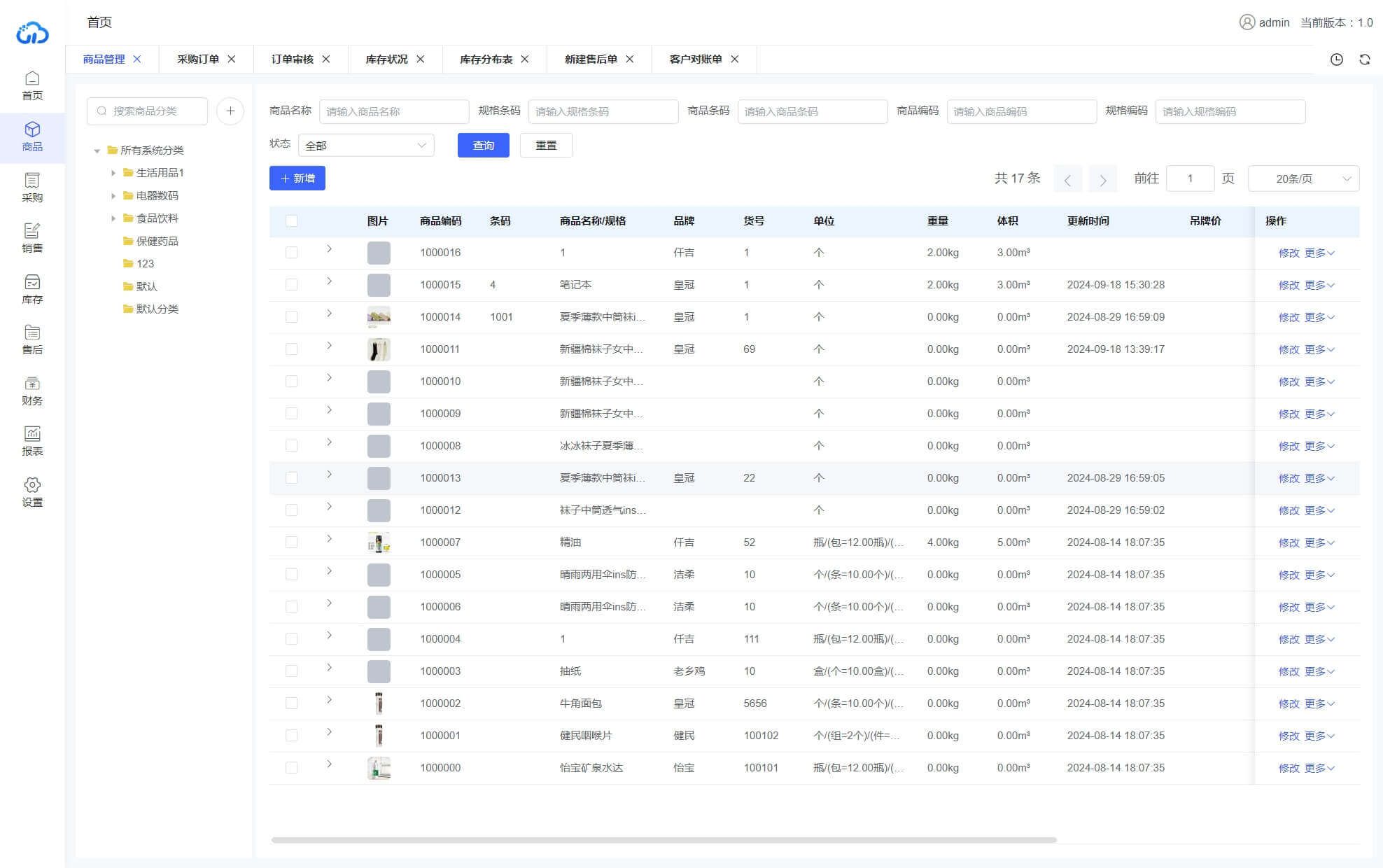
三勾软件/ java+springboot+vue3玖玖云电商ERP多平台源码
玖玖云ERP系统、支持多平台订单同步,仓库发货,波次拣货,售后服务,电商ERP一站式解决方案 项目介绍 玖玖云ERP系统基于javaspringbootelement-plusuniapp打造的面向开发的电商管理ERP系统,方便二次开发或直接使用。主…...

020 elasticsearch7.10.2 elasticsearch-head kibana安装
文章目录 全文检索流程ElasticSearch介绍ElasticSearch应用场景elasticsearch安装允许远程访问设置vm.max_map_count 的值 elasticsearch-head允许跨域 kibana 商品数量超千万,数据库无法使用索引 如何使用全文检索: 使用lucene,在java中唯一…...

基于SpringBoot+Vue的蜗牛兼职网的设计与实现(带文档)
基于SpringBootVue的蜗牛兼职网的设计与实现(带文档) 开发语言:Java数据库:MySQL技术:SpringBootMyBatisVue等工具:IDEA/Ecilpse、Navicat、Maven 该系统主要分为三个角色:管理员、用户和企业,每个角色都有其独特的功能模块,以满…...

Linux 命令 chown 和 chmod 的区别
Linux 命令 chown 和 chmod 的区别 chown的作用:更改文件或目录的所有者和所属用户组chmod的作用:更改文件或目录的访问权限 chown的作用:更改文件或目录的所有者和所属用户组 $ chown [options] user:group file_pathuser:新文件…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

模式分层预测驱动推断:处理复杂缺失数据的统计新框架
1. 项目概述:当数据“缺胳膊少腿”时,如何做出靠谱的推断?在数据科学和统计建模的日常工作中,我们最怕遇到什么?不是复杂的算法,也不是海量的数据,而是数据本身“缺胳膊少腿”——也就是缺失值。…...

地理空间机器学习库全解析:从TorchGeo到Raster Vision的实战指南
1. 项目概述:为什么我们需要专门的地理空间机器学习库?如果你尝试过用标准的PyTorch或TensorFlow去处理一张卫星影像,大概率会在第一步就卡住。不是模型写不出来,而是数据根本读不进去,或者读进去了却对不上位置。一张…...

如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南
如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南 【免费下载链接】genshin-impact-script 原神脚本,包含自动钓鱼、自动拾取、自动跳过对话等多项实用功能。A Genshin Impact script includes many useful features such as automatic fishing…...

PrediPrune:机器学习驱动的编译器超级优化候选剪枝策略
1. 项目概述与核心挑战在编译器优化的世界里,我们总在追求极致的性能。传统的编译器优化器,比如LLVM的Pass,依赖于一系列预定义的、经过验证的转换规则。它们很高效,但想象力也受限于这些规则。超级优化器(Superoptimi…...