数据结构与算法 - 树 #数的概念 #二叉树 #堆 - 堆的实现/堆排序/TOP-K问题
文章目录
前言
一、树
(一)、概念
1、树的定义
(二)、树的定义
1、树为什么是递归定义的?
2、如何定义树(如何表达一棵树)
解决方案一:假设我们得知该树的度
解决方案二:顺序表
解决方案三:左孩子右兄弟表示法
二、二叉树
(一)、概念
(二)、特殊二叉树
1、斜树
2、满二叉树
3、完全二叉树
(三)、现实中的二叉树
(四)、二叉树的性质
(五)、二叉树的存储结构
1、顺序存储结构:
2、链式存储结构
三、堆
(一)、堆的概念
1、堆的定义:
2、堆的性质:
3、堆的特点:
(二)、堆类型的声明
(三)、堆的实现
1、Heap.h 的实现
2、Heap.c 的实现
1、初始化
2、销毁
3、交换
4、向上调整
5、push
6、向下调整
7、pop
8、获取堆顶数据
9、判空
(四)、堆排序
1、建堆算法
方法一:利用向上调整建堆
方法二:利用向下调整建堆
2、堆排序
(五)、TOP-K 问题
解决方案一:
解决方案二:
总结
前言
路漫漫其修远兮,吾将上下而求索;
一、树
(一)、概念
1、树的定义
在之前学习的顺序表、链表、栈、队列均是一对一的线性结构(此线性为逻辑上的”线性“),而非线性结构的特点是复杂;生活中当然不仅仅只是一对一的问题,面对一对多的问题,我们又该如何解决呢?利用一对多的数据结构,此处所要讲述的”树“便是一对多的数据结构;
树是一种非线性的数据结构,它是由 n (n>=0) 个有限结点组成的具有层次关系的集合,将此结构叫做树的原因是因为此结构像一棵倒挂的树,即其根在上,而叶朝下;
当n = 0 时,称此树为空树
在任意一棵非空树中(如下图所示):
- 1、有且只有一个特定的节点称为根(Root)结点,根节点没有前驱节点;
- 2、当n>1 时,其余节点可以分为m(m>0)个不相交的有限集T1、T2...Tm,其中一个集合本身又是一棵树,并且称为根节点的子树(SubTree),每棵树的根节点可以有0个或者多个后继;
- 3、树是递归定义的;

树为什么是递归定义的?
- 请继续往下看,下文中会有解释;

树的定义中运用到了树的概念;下图中的子树T1与子树T2 为上图根节点A的子树;当然,D、H组成的左子树与E组成的右子树又为根节点B的子树;F 组成的右子树与G、I组成的右子树又作为根节点C的子树;

注:树形结构中,子树之间不能有交集,否则就不叫作树形结构(子树之间有交集叫做”图“);如下图所示:

树形结构的特点:
- 1、子树不相交
- 2、除了根节点之外(根节点没有父节点)。每个结点有且有且只有一个父节点
- 3、一棵N个节点的树有N-1条边
2、树的相关概念

- 节点的度:一个节点含有的子树(孩子)个数称为该节点的度;如上图:节点A有三个子树,故而A的度为3;
- 叶节点(终端节点):度为0的节点称为叶节点(没有子节点的节点);如上图中,节点J、F、M、L、H、I为叶节点
- 分支节点(非终端节点):度不为0的节点;如上图:B、C、D、E、G、K 为非终端节点;
- 父节点(双亲节点):若一个节点中包含子节点,那么此节点便会被称为其子节点的父节点;如上图:节点A为节点B的父节点;
- 子节点(孩子节点):一个节点含有子树的根节点称为该节点的子节点;如上图:节点B是节点A的子节点;
- 兄弟节点: 具有相同父节点的节点称为兄弟节点;如上图,节点B、C、D称为兄弟节点
- 树的度:一棵树中,节点中最大的度为该树的度;如上图:因为在所有节点中最大的度为节点A的3 ,故而该树的度为3;
- 节点的层次:从根开始定义,根为第一层,根的子节点为第二层……以此类推下去;(有些地方从第0层开始计算树的层数)
- 树的高度或深度:树中节点的最大层次;如上图:树的高度为5;
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:节点E、J、H 互为堂兄弟节点;
- 节点的祖先: 从根节点到该节点所经历分支上的所有节点;如上图:A是所有节点的祖先,节点J的祖先有:A、B、E;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图,所有节点均为A的子孙、节点B的子孙有E、F、J;
- 森林:由m(m>0) 棵不相交的树的集合合称为森林;(即多棵树便称为森林);
注:
- 在树的这部分利用树的相关概念(树、叶、分支) 以及人类亲缘关系进行命名;
- 一棵树是由叶节点(终端节点) 与 分支节点(非终端节点) 构成的;
节点层次的概念如何区分?
- 看你如何分着走,可以从第0层开始,也可以从第一层开始;一般情况下从第1层开始,因为树还有空树的概念,这样的话,空树便为第0层;而若从第0层开始,那么空树只能当作 -1层,有点奇怪,但是这样的表达没有问题;
可能你会联想到数组的下标为什么是从0开始的,而不是从1开始?
- 数组的下标从0开始是被逼无奈的;众所周知,数组名表示首元素地址,倘若此处有一个数组a ,那么a[i] = *(a+i) ; 基于这个特点,只有数组的下标从0开始,才能满足此表达式;--> a[0] = *a ;
树的高度或深度--> 最大层次的概念
树的高度或者深度与其从第一层开始还是从第0层开始有关;如若一棵树有6层,并且其层次从第一层开始的,那么该树的高度(深度)便为6;而如若该树从第0层开始,那么该树的高度便为5;
此处并没有特别严格的概念来定义的高度(深度),由于一般情况下我们树的层次是从第一层开始的,所以可以将树的高度当作其层数;但是不要忘记树的高度的核心 —— 最大层次;
(二)、树的定义
1、树为什么是递归定义的?
任何一棵树均是由两部分组成的:根节点 与 子树(即任何一棵树均包含根和N棵子树,其中N大于等于0);
树是由根节点与子树构成,而子树又是由根节点与子树构成,子树又是由根节点与子树构成……故而说树是由递归构成的;
如何理解递归?
- 递归的 ”核心“ 思想:大事化小
- 递归:大问题可以拆分为小问题,小问题可以拆解称更小的问题……直到这个问题被拆成不可以再拆解的问题才会停止;而这些问题是相似的;
回顾之前在C语言阶段学习的递归,递归有两个条件

递归又称为”分治“,即分而治之(将大问题化为小问题);
用图像来理解:

由上图可知,A这棵树,由根节点A、子树B、子树C、子树D构成;而子树B又由根节点B、子树E与子树F构成,子树E由根节点E、子树J构成,子树F由根节点F构成…… 从上图中可以清楚地看见,一棵树由一个根节点与N个子树构成(N>=0) , 而一个子树又由一个根节点与N个子树构成(N>=0)……当这棵树只有一个根节点的时候便不再分下去。
2、如何定义树(如何表达一棵树)
在前面的学习,在定义单链表的结点时,由于单链表的结点需要一个数值域来存放数据,一个指针域来存放下一个结点的地址,所以在定义单链表结点类型的时候,定义一个数值域与指针域;在双链表中,需要一个数值域来存放数据,两个指针域分别指向前一个结点与后一个结点;故而在定义双链表结点类型的时候会定义一个数值域与两个指针域;
而树,是由根节点与子树(孩子)构成;一棵树只有一个根节点,这是显而易见的;但由于并不知道有多少子节点,定义树的时候究竟要定义多少个孩子就是一个问题;
解决方案一:假设我们得知该树的度
利用树的度建立一个指针数组,在将此指针数组与数据封装在一个结构体中,如下图所示:

注:如果此处的N很大,那么此结构是存在空间浪费的;
解决方案二:顺序表
(在未知数的度的情况下)使用顺序表来存放子节点的地址
方案一相当于使用的是静态的数组来存放子节点的地址,而方案二相当于是动态的数组来存放子节点的地址;
此处使用顺序表本质上也是在使用数组,只不过相较于方案一,此处的数组中存放子节点地址的空间是动态开辟的;这种方法不会浪费空间并且很直观,但是不好控制、访问;
解决方案三:左孩子右兄弟表示法
就定义两个指针(leftChild、rightBrother),不在乎有多少个孩子,定义如下:

左孩子右兄弟表示法究竟特点在何处?
- 让孩子去链接孩子,兄弟去链接兄弟
如下图所示:


如上图所示,无论一个结点会有多少个孩子,leftChild 均会指向其最左边的孩子,剩余的孩子右rightBrother (亲兄弟)解决;
二、二叉树
(一)、概念
二叉树(Binary Tree) 是n (n>=0) 个结点的有限集合,该集合或者为空集(即空二叉树),或者由一个根节点和两棵互不相交的、分别称为根节点的左子树和右子树的二叉树构成,如下图:

注:
1、二叉树中节点的子节点个数小于等于2,二叉树的度最大为2;
2、二叉树中的子树存在左右之分,次序不能颠倒,故而二叉树又称为有序树;
3、即使树中的节点只有一棵树,也是需要区分此数为左子树还是右子树;
二叉树的均为以下的二叉树复合而成:

即,二叉树的五种基本形态:
1、空二叉树
2、只有一个根节点
3、根节点只有左子树
4、根节点只有右子树
5、根节点既有左子树又有右子树
(二)、特殊二叉树
1、斜树
顾名思义,斜树就是斜着的树(二叉树只有左右之分,故而可向左斜也可向右斜)
- 左斜树:所有节点都只有左子树的二叉树
- 右斜树:所有节点均只有右子树的二叉树
斜树的特点:每一层均只有一个节点,节点的个数与其树的高度(深度)相同(从第一层开始算),如下图:

2、满二叉树
在一棵二叉树中,如果所有分支节点均存在左子树与右子树,并且所有的叶节点均在同一层,这样的二叉树便称为满二叉树;换句话说,此树的每一层均达到最大值,倘若此树的层次为 k ,那么该树的总节点个数为: 2^k-1 。如下图:

满二叉树的特点:
1、叶节点只能出现在最下面的一层;
2、非叶节点的度一定为2;
3、在同样高度(深度) 的二叉树中,满二叉树的节点个数最多,叶节点最多;

3、完全二叉树
对一棵有n个节点的二叉树按层序进行编号,如果编号为i (1 <= i <= n)的节点与同样深度的满二叉树中编号为 i 的节点在二叉树中的位置完全相同,那么此二叉树便称为完全二叉树;
换句话说,完全二叉树如果有k 层,其(k-1) 层均是满的,最后一层即第k层不是满的,但节点从左向右是连续的(中间没有空节点);
注:满二叉树是一种特殊的完全二叉树;

注:完全二叉树的所有节点与其同深度的满二叉树,他们按层序编号相同的节点,是一一对应的关系;
按层序编号,例如,上图中的左边的图中,其每一层的编号均是连续的,故而左图中的树为完全二叉树;而右图中最后一层的编号并不是连续的,编号10与11 空挡了,故而该树并不是完全二叉树;
完全二叉树的特点:(在头脑中过一遍完全二叉树的图形即可,无需记忆)
1、叶节点只能出现在最下面的两层
2、最后一层的叶节点一定会集中在左边连续位置上
3、倒数第二层,如果有叶节点,一定在右部连续的位置上
4、如果一个节点的度为1,那么该节点只有左孩子,即不会存在有右孩子的情况
5、同样节点数的二叉树中,完全二叉树的深度最小
(三)、现实中的二叉树

(四)、二叉树的性质
性质一:在二叉树的第 h 层,最多有 2^(h-1) 个节点,h>=1 即从第一层开始数;
性质二:深度为 h 的二叉树至多有 2^h -1 个节点 ,h>=1 即从第一层开始数;
注:最多就是参考的满二叉树;
(五)、二叉树的存储结构
二叉树的实现可以选择两种结构: 1、数组 2、链表
即顺序存储结构与链式存储结构;
1、顺序存储结构:
二叉树的顺序存储结构就是使用一维数组存储二叉树中的节点,并且数组的下标(节点的存储位置)要能够体现节点之间的存储逻辑;
一般数组只适合用来存储完全二叉树,因为完全二叉树中的节点均是连续存放的,不会浪费空间;在现实中只用使用堆才会用数组来存储节点,因为堆的逻辑结构为完全二叉树;二叉树的顺序存储在物理上是一个数组,在逻辑上是一棵二叉树;
注:
1、满二叉树是一种特殊的完全二叉树
2、逻辑结构是想象出来的;物理结构是真实存在的存储结构;

为什么完全二叉树适合用数组来存放?
1、存储简单,不会浪费空间(完全二叉树的节点均是连续的)
2、可以利用下标来计算父子节点

从上图中分析我们可以得知,假设父节点的下标为 i ,如果此父节点有两个孩子,那么其左孩子的下标为 2*i+1 ,右孩子的下标为 2*i+2 ;

同理,反过来,假设孩子的下标为 j ,如果此孩子为左孩子,那么其父节点的下标为:(j-1)/2 ; 而若此孩子为右孩子,那么其父节点的下标为 : (j-2)/2 ;

计算机中的 "/" 会去除除法中的余数而只保留整数;
假设父节点的下标为i ,那么左孩子的下标为 2*i+1 , 其中1小于2,那么当2*i-1 除以2 的时候结果就是 i ,当然,将这个1减去计算结果也为i,因为1小于2,不会对除2产生影响;同理,右孩子下标为 2*i+2 ,即 (1+i)*2 , 右孩子的的下标为2的倍数,只要将2破坏成1或者0,右孩子/2 的结果便就是父节点的下标 i, 故而假设右孩子的节点为j ,那么其父节点的下标为 (j-1)/2 (当然,也可以用(j-2)/2 来计算);
综上:
- 1、假设父节点的下标为 i ,(此父节点有两个孩子的情况下)其左孩子的下标为: 2*i+1 , 右孩子的下标为:2*i+2 ;
- 2、假设孩子的节点为 j (无论是左孩子还是右孩子),其父节点的下标为 :(j-1)/2 ;
2、链式存储结构
二叉树的链式存储结构,即用链表的形式来存储二叉树的节点,用指针来指示节点之间的逻辑关系;在链表的结点中通常是由三个域组成:数值域和左右指针域,左指针域用来指向左节点,右指针域用来指向右节点;
而链式结构又可以分为二叉链与三叉链;(此处使用的是二叉链,后面会学习红黑树的时候会使用到三叉链);

注:
1、三叉链就是在二叉链记录左右孩子结点的基础上再多增加一个指针域来记录其父节点的地址;
2、非完全二叉树中的节点就适合使用链式结构来存储;
三、堆
(一)、堆的概念
1、堆的定义:

堆的物理结构本质上是顺序存储的,是线性的。但在逻辑上不是线性的,是的这种逻辑储存结构。 堆的这个数据结构,里面的成员包括一维数组,数组的容量,数组元素的个数,有两个直接后继。
将根节点最大的堆叫做大根堆(大堆):大堆中的任何一个父节点总是大于等于其子节点,根节点为此树中最大的节点;
根结点最小的堆叫做小根堆(小堆):小堆中任何一个父节点总是小于等于其子节点,根节点为此树中最小的节点;
注:左右孩子之间并无大小关系,故而大堆与小堆存储在数组中的数据不一定有序;
常见的堆有二叉堆、斐波那契堆等。
2、堆的性质:
- 1、堆中某个节点的值总是不大于或不小于其父节点中的值;(堆分为大根堆、小根堆)
- 2、堆总是一棵完全二叉树;
注:满二叉树是一种特殊的完全二叉树
数据结构中堆和栈的概念是完全不同于C语言中堆和栈的概念;
- 数据结构中堆指的是用数组存储的完全二叉树,而栈是可以用数组实现具有后进先出特点的数据结构;另外,数据结构中给的堆还可以用来做堆排序、解决TOP-K问题;
- 而C语言中的堆和栈是操作系统中存有的概念,堆和栈属于内存区域的划分;(利用库函数malloc、calloc、realloc 动态开辟的空间来自于堆;函数调用会创建函数栈帧,局部变量便是存放在栈中给的);
3、堆的特点:
- 小根堆(小堆)中的根节点是整个二叉树中最小的节点;
- 大根堆(大堆)中的根节点是整个二叉树中最大的节点;
注:可以利用堆的这个特点找极值做排序,并且效率高;
注:如果给了一个算法,让我们判断它是否为堆,首先是要将数组中的数据还原为堆(建堆算法),然后再进行判断;
(二)、堆类型的声明
堆的本质是一个完全二叉树(底层是数组实现的,动态开辟的数组需要变量size 与变量capacity),并在此基础上增加了一些要求:父子节点之间的大小关系;
注:
- 1、大堆的父子节点大小关系:父节点 >= 子节点
- 2、小堆的父子节点大小关系: 父节点 <= 子节点
- 3、并没有约定兄弟之间的大小关系
类型声明如下:

注:
- 1、堆底层利用数组来存放数据
- 2、利用数组下标可以找到父子节点(因为堆一定是一个完全二叉树);如果父节点的下标为i,那么其左孩子的节点下标为2*i+1 ,其右孩子的节点下标为 2*2+2;如果孩子的的下标为j ,那么父节点的下标为 (j-1)/2;
(三)、堆的实现
1、Heap.h 的实现
#pragma once#include<stdio.h>
#include<stdbool.h>
#include<stdlib.h>
#include<assert.h>//堆的类型的定义
typedef int HPDataType;
typedef struct Heap
{HPDataType* a;int size;int capacity;
}HP;//初始化
void HPInit(HP* php);//销毁
void HPDestroy(HP* php);//交换
void Swap(HPDataType* p1, HPDataType* p2);//向上调整
void AdjustUp(HPDataType* a, int child);//push
void HPPush(HP* php, HPDataType x);//向下调整
void AdjustDown(HPDataType* a, int n, int parent);//pop
void HPPop(HP* php);//获取堆顶的数据
HPDataType HPTop(HP* php);//判空
bool HPEmpty(HP* php);
注:
为什么会有向上调整?
- 堆的规则:大堆,其父节点>=子节点 ; 小堆,父节点 <= 子节点 ;当你将数据放在数组的结尾的时候(size 指向的空间),要将该数据与其父节点进行比较,当不符合该堆的特点的时候就进行交换,以满足堆的结构规则;将数据一个一个地向上调整,便可以维护该堆地结构;
2、Heap.c 的实现
1、初始化
//初始化
void HPInit(HP* php)
{assert(php);php->a = NULL;php->size = php->capacity = 0;
}2、销毁
//销毁
void HPDestroy(HP* php)
{//释放所有动态开辟的空间assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}
3、交换
//交换
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}4、向上调整
大堆:
//向上调整 - 大堆 父节点>= 子节点
void AdjustUp(HPDataType* a, int child)
{//利用孩子的下标可以找到父节点的下标int parent = (child - 1) / 2;//让子节点与父节点进行比较,不符合大堆要求的就交换位置//当与根节点比较交换了之后便停止循环(最差的情况 - 比较交换到根节点)while (child>0){if (a[parent] < a[child])//不符合大堆 父节点>=子节点便交换{Swap(&a[parent], &a[child]);//调整child = parent;parent = (child - 1) / 2;}else{break;}}}小堆:
//向上调整 - 小堆 父节点<= 子节点
void AdjustUp(HPDataType* a, int child)
{//利用孩子的下标可以找到父节点的下标int parent = (child - 1) / 2;//让子节点与父节点进行比较,不符合小堆要求的就交换位置//当与根节点比较交换了之后便停止循环(最差的情况 - 比较交换到根节点)while (child>0){if (a[parent] > a[child])//不符合小堆 父节点<=子节点便交换{Swap(&a[parent], &a[child]);//调整child = parent;parent = (child - 1) / 2;}else{break;}}}5、push
//push
void HPPush(HP* php, HPDataType x)
{assert(php);//避空//空间--初次使用空间还是扩容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* tmp = (HPDataType*)realloc(php->a, newcapacity*sizeof(HPDataType));if (tmp == NULL){perror("HPPush realloc");exit(-1);}php->a = tmp;php->capacity = newcapacity;}php->a[php->size] = x;php->size++;//向上调整AdjustUp(php->a, php->size -1);}
6、向下调整
逻辑分析:
- 利用父节点的下标计算子节点的下标;
- 该父节点可能没有子节点,可能只有一个子节点(即左子节点),或者有两个子节点,分情况讨论;
- 假设法-先假设左孩子为两孩子中较大的节点,如若只有一个孩子,那么需要比较的也为左孩子;
- 让父节点与其子节点中较大或者较小(取决于堆) 来进行比较 --> 与其所有的子孙节点进行比较;
- 向下调整到右节点便停止,即没有孩子的节点 —— 循环限制的条件;
大堆:
//向下调整 - 大堆- 让父节点与较大的那个子节点进行比较
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n)//左孩子的下标要在数组合法的范围内{//假设法if (child + 1 < n && a[child + 1] > a[child])//保证有两个孩子的情况下{child++;}//与子祖孙节点进行比较if (a[parent] < a[child]){Swap(&a[parent], &a[child]);//调整parent = child;child = parent * 2 + 1;}else{break;}}
}
小堆:
//向下调整 - 小堆- 让父节点与较小的那个子节点进行比较
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n)//左孩子的下标要在数组合法的范围内{//假设法if (child + 1 < n && a[child + 1] < a[child])//保证有两个孩子的情况下{child++;}//与子祖孙节点进行比较if (a[parent] > a[child])//小堆 父节点 <= 子节点{Swap(&a[parent], &a[child]);//调整parent = child;child = parent * 2 + 1;}else{break;}}
}
注:大堆与小堆的向下调整的算法区别在于:
- 1、假设法中,取左右孩子中较大者还是较小者(取决于该堆是大堆还是小堆)
- 2、父节点与其子节点的大小关系(取决于该堆是大堆还是小堆)
7、pop
//pop - 堆根的数据
void HPPop(HP* php)
{//为了不破坏堆的结构,删除堆根的数据,首先让堆根的数据与最后一个数据进行交换//然后再使用向下调整assert(php);Swap(&php->a[0], &php->a[php->size]);//下标本身就比实际个数少一AdjustDown(php->a, php->size, 0);//让堆根的数据进行向下调整php->size--;
}
删除的逻辑?(删除的是堆根中的数据)
如果像顺序表中删除下标为0空间中的数据逻辑来实现堆中的删除 --> 将下标为0后面空间中的数据向前挪动1,以覆盖下标为0空间中的数据;由于堆仅仅只是规定了父子节点之间的大小关系,即其兄弟之间并没有规定大小关系;所以当数据向前挪动的时候父子节点关系会被改变,即父子变兄弟,倘若其父子节点之间的大小关系不符合堆的规定,那么其结构就不能再为堆;也可以重新建堆,但如果每删除一个数据均要重建堆,这样的消耗是非常大的;
故而此处采用了另外一个逻辑,将堆根中的数据与数组中最后一个数据进行交换,size--,然后再将堆根上的数据进行向下调整(让根节点与其子孙进行比较,让根节点中的数据要符合该堆的特点);
8、获取堆顶数据
//获取堆顶的数据
HPDataType HPTop(HP* php)
{assert(php);assert(php->size);//确保堆中有数据可以获得return php->a[0];
}9、判空
//判空
bool HPEmpty(HP* php)
{assert(php);//空为真return php->size == 0;
}(四)、堆排序
1、建堆算法
在讲述堆排序之前我们先来了解一下两种建堆算法;
在上述堆的实现中,我们利用向上调整与向下调整来处理堆中的数据,同理我们也可以利用向上调整或者向下调整来对数组中的数据进行调整,让其成为堆(大堆或者小堆);
方法一:利用向上调整建堆
其实就是模拟上述“堆实现”中插入push的过程,只不过此处是在原数组的基础上进行建堆,并没有另外创建空间来建堆;
代码如下:
int arr[] = { 2,10,29,38,42,53,31,4,21 };int sz = sizeof(arr) / sizeof(arr[0]);//建堆 - 向上调整建堆for (int i = 0; i < sz; i++){AdjustUp(arr, i);}注:向上调整算法的复杂度为O(N^logN);
方法二:利用向下调整建堆
向上调整建堆的前提:所调整的节点的子树为堆;
故而想要在数组中进行调整就不能像上述“堆的实现”中向上调整那样从下标为0的数据开始调整;而由于叶节点没有孩子,那么可以将叶节点本身就看做一个堆,故而向下调整应该从最后一个非叶节点开始;
最后一个非叶节点如何计算得到?
- 最后一个叶结点的父节点便是最后一个非叶结点;(可利用数组下标进行计算)
代码如下:
int arr[] = { 2,10,29,38,42,53,31,4,21 };
int sz = sizeof(arr) / sizeof(arr[0]);
//建堆 - 向下调整建堆
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
{AdjustDown(arr, sz, i);
}注:大堆与小堆中的向上、向下调整算法有一点差异,具体可以见上面的代码(堆的实现中的向上调整与向下调整);
向下调整算法的时间复杂度为:O(N);
2、堆排序
首先我们先来思考一下倘若我们想要数组中的数据降序,是需要建大堆还是小堆呢?
答案是小堆;因为堆中的数据并不是有序的(堆只是规定了父子节点的大小关系,并没有规定兄弟节点之间的大小关系),但是堆有个特点是:大堆中堆根上的数据是整个二叉树中最大的一个;小堆中的堆根上的数据是整个二叉树中最小的一个;
降序:大数据在前面,小数据在后面;降序可以有两种处理方式:
- 一是先确定大数据的位置,然后依次确定次大,次次大……的数据的位置
- 二是逆向思维,先确定好小数据的位置,然后依次确定好次小、次次小……的数据的位置;显然此处最好采用方式二的逆向思维;
我们先来思考一下方式一的问题,倘若排降序而你先确定好大数据的位置(大数据的对应的空间便不会再动了),就会选择建大堆, 那么抽象地理解上相当于头删,再将这个空间后面的数据当作堆的话又需要重新建堆,因为此时父子关系会变成兄弟关系,不符合堆的大小要求,如若每确定一个数据的位置都需要重新建堆的话,这样的消耗是非常大;此法的时间复杂度为:O(N^2 ) (假设此处建堆采用的是向下调整建堆,向下调整建堆的时间复杂度为O(N),而有N个数据,所以此算法的时间复杂度为:O(N^2);但是如果建堆采用向上调整算法的话,那么此法的时间复杂度便会为:O(N^2*logN));
我们再来思考一下方式二的逆向思维,排降序先确定小值的位置,当然是建小堆;建小堆,将堆根中的数据与数组中最后一个数据进行交换,并且不动这个位置的数据(相当于尾删);交换数据并没有破坏堆根子树堆的特点,于是可以对堆根进行向下调整处理,然后重复上述操作,一个一个地确定数据地位置让其变成降序;此法操作的时间复杂度为:O(N*logN);
故而排降序需要建小堆;同理,排升序就需要建大堆;
堆排降序的思路:借助于“堆的实现”中删除的操作,将堆根中的数据与最后一个数据进行交换,此时便会将该堆中最小的数据放在后面,然后进行伪删的操作(“伪删除,相当于不会将其交换到后面的数据当作堆中的数据”),然后再进行向下调整;重复上述操作,最后在数组中的数据便是降序;
代码如下:
int arr[] = { 2,10,29,38,42,53,31,4,21 };
int sz = sizeof(arr) / sizeof(arr[0]);
//建堆算法两种均可
//建堆 - 向下调整建堆 - 排降序 - 建小堆
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
{AdjustDown(arr, sz, i);
}建堆 - 向上调整建堆
//for (int i = 0; i < sz; i++)
//{
// AdjustUp(arr, i);
//}//排降序
int n = sz - 1;//最后数据的下标
while (n)//sz 个数据只需要处理 sz-1 次
{//交换Swap(&arr[0], &arr[n]);//伪删sz--;//向下调整AdjustDown(arr, sz, 0);n--;
}注:排升序同理;
(五)、TOP-K 问题
TOP-K问题:求数据结合中前K个最大的元素的或者最小的元素,一般情况下数据量都比较大(千万、上亿级别);
例如:世界500强、富豪榜、游戏中的战力排名等;
我们之前解决最大或者最小的前k个数据的时候,通常采用排序的方法;但是如果数据量非常大(例如 14亿),这时候如果还使用排序的话,消耗的是非常大的(将数据加载到内存中的时间、空间消耗以及排序操作的时间消耗),故而此时会利用堆来解决数据量非常大的TOP-K问题;
假设此处需要找出14亿 人中最有钱的前10个人;
如果利用上述“堆的实现”中的思路来解决这个问题:先建存放了14亿个数据的一个大堆,然后再利用HPTop 与 HPPop 来不断获得堆顶的数据;此操作的时间复杂度为O(N),空间复杂度为O(N);
假设一个数据的大小为4byte ,那么存放14亿个数据就需要 大约4GB的内存空间(小于4GB);在内存中开辟4GB的连续空间来存放数据显然是不太可能的;
解决方案一:
将总数据划分成若干份(适中),多次TOP-K即可;
简单来说,如果此次所要TOP-K的数据有4GB 这么多,那么便先1GB地将数据放入内存中然后获取前10个最大的数据……一路下来会得到40个最大的数据,最后在这40个数据中找到最大的前10个即可;
当然,如果你觉得花1GB的内存空间来存放数据还是太大了,可以将每一次所要比较的数再减少一些,这样每次比较的数据便少了,占用的内存也小了,但是处理次数变多了,势必会导致效率下降;(空间换时间)
解决方案二:
注:假设此处有100万个数据存放在文件 "data.txt" 中
先读取文件中k个数据以建K个数据的小堆,将文件中的数据每次读一个放在内存中,然后与堆根中的数据比较,比堆根的数据大便将堆根中的数据替换,然后再进行向下调整;
代码如下:
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<time.h>//堆的类型声明
typedef int HPDataType;
typedef struct Heap
{HPDataType* a;int size;int capacity;
}HP;void CreateData()
{//打开文件 FILE* fin = fopen( "data.txt", "w");if (fin == NULL){perror("fopen");exit(-1);}//产生100万个随机数并写入文件中int n = 1000000;//产生的数据个数srand((unsigned int)time(NULL));//利用时间戳产生随机的种子for (int i = 0; i < n; i++)//写入的次数{fprintf(fin, "%d\n", (rand() + i) % 100000000);//产生的数字范围0~亿}//关闭文件fclose(fin);fin = NULL;
}void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}//向下调整算法 - 建小堆
void AdjustDown(HPDataType* a, int n, int parent)
{//利用父节点的下标计算子节点的下标//假设法 - 假设左节点为较小的结点int child = parent * 2 + 1;while (child < n)//存在子节点{if (child + 1 < n && a[child + 1] < a[child])//有两个孩子的情况下{child++;}//小堆的特征: 父节点 <= 子节点if (a[parent] > a[child]){Swap(&a[parent], &a[child]);//调整parent = child;child = parent * 2 + 1;}else{break;}}}void TOP_KHeap()
{int k = 0;printf("请输入k:>");scanf("%d", &k);//动态开辟一个数组的空间 - 建小堆的准备工作HPDataType* KminHeap = (HPDataType*)malloc(k*sizeof(HPDataType));if (KminHeap == NULL){perror("TOP_KHeap malloc");exit(-1);}//打开文件FILE * fout = fopen("data.txt", "r");if (fout == NULL){perror("fopen");exit(-1);}//操作//先从文件中读取k个数据 - 放入创建的数组中for (int i = 0; i < k; i++){fscanf(fout, "%d", &KminHeap[i]);}//建小堆 - 向下调整与向上调整均可for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(KminHeap, k , i);}//读取文件中剩余的数据int x = 0;//一个一个地读,存放在变量x 中while (fscanf(fout, "%d", &x) != EOF){if (x > KminHeap[0]){//直接覆盖,再向下调整KminHeap[0] = x;AdjustDown(KminHeap, k, 0);}}//此时,数组KminHeap 中的k个数据为文件data.txt 中最大的前k 个数据;printf("最大的前%d个数据:", k);for (int i = 0; i < k; i++){printf("%d ", KminHeap[i]);}printf("\n");//换行//关闭文件fclose(fout);fout = NULL;
}
分析:
1、造100万个随机数部分:
srand 与 rand 常一起使用,srand 可以利用时间戳而产生不同的"种子"(伪随机数)而 让rand 每次产生的随机数都不太一样;int 可存放的数据范围为 0~ 2147483647; 故而在生成随机数最好控制在0~亿之内,即(rand() + i)%100000000 , 因为rand() 产生的数据额范围为0~32767 , +i 是为了避免产生许多重复的数,,%100000000 是为了控制产生的随机数的范围避免溢出,减少重复值;
打开文件 - 操作文件(将产生的随机值放到文件中) - 关闭文件
2、TOP-K问题的解决
主逻辑:建小堆,让数据与堆根中的数据进行比较(小堆中堆根的数据为此堆中最小的数据),如果文件有数据比堆根中的数据大,便让此数据替换堆根中的数据再进行向下调整,如此重复下去,直到文件中的数据读取结束;
整体逻辑梳理:
- 1、变量的准备:k、存放k 个数据的数组(所要进行建小堆的数据)
此处建立存放k个数据的数组的空间是使用malloc 动态开辟的;原因:k 为变量,在VS编译器中不支持变长数组;
- 2、打开文件 - 读取100万个数据
- 3、操作文件
先将文件中的前k个数据读取放入数组KminHeap 中,然后以向下调整的方式建小堆(当然,也可以使用向上调整算法,推荐使用向下调整算法,因为向下调整建堆算法的时间复杂度更优),然后再将剩余的数据一个一个地读取放在变量x 中,再与堆根中 的数据进行比较,大于堆根中 的数据便将此数替换堆根中的数据;如此往复,直至文件中的数据读取完了;
此处利用fscanf 来读取文件中 的数据,当fscanf 读取失败即返回EOF,此时便代表着文件中的数据均读取完了;
当文件中的数据均读完的时候,此时KminHeap 中k 个数据,便是这个文件中100万个数据中最大的前K个;
- 4、关闭文件
注:细节:由于我们在写入随机数到文件中的时候,数据本身是用'\n' 来分割的;而fscanf 在读取数据的时候遇到空格或者换行本身就会终止(scanf 遇到空格或者换行(空白字符) 便会以为是数据个数的分割),故而在读取数据的时候直接写作:fscanf(fout, "%d", &x) 即可,不用在%d 后面再增加'\n' ;
总结
1、树是一种非线性的数据结构,它是由 n (n>=0) 个有限结点组成的具有层次关系的集合,将此结构叫做树的原因是因为此结构像一棵倒挂的树,即其根在上,而叶朝下;
2、二叉树(Binary Tree) 是n (n>=0) 个结点的有限集合,该集合或者为空集(即空二叉树),或者由一个根节点和两棵互不相交的、分别称为根节点的左子树和右子树的二叉树构成,
3、堆是一种数据结构,可以在其中插入、删除数据,让其结构仍为堆;利用堆来进行选数是非常方便的,不用我们自己去建堆、调整。(注:以后在c++中还有一种数据结构叫做 优先级队列)
4、堆可以用来进行排序;堆排序是在堆这个数据结构的基础上利用向上调整或者向下调整来建堆的(直接对数组进行建堆操作)
5、TOP-K问题;
解决TOP-K问题有两种方式:
- 1、数据量不大,直接建大堆、pop数据便可;此法的时间复杂度为O(N),空间复杂度为O(N)
- 2、数据量很大的时候,需要建立一个K个数的小堆,让(文件中)的数据与堆根中 的数据进行比较,比堆根大便进行交换(实际上是直接将堆根中的数据进行覆盖),然后再向下调整;此法的时间复杂度为O(N),空间复杂度为O(1);
注:方法二与方法一在效率上是差不多的,但是方法二更节约空间;
6、我们之前学习的时间复杂度就是纯粹地将数据存放起来。只不过在存储地时候,例如数组、链表这样的结构,它们各有优势;而堆这种数据结构并不是单纯地用来存放数据,更重要的是利用堆存放数据可以帮助我们更加高效地进行排序、解决TOP-K问题等,即堆这种数据结构带有一定的功能性;
堆借助于完全二叉树的特性(高度低而可以存放大量的数据),那么向上调整、向下调整的次数就比较少,效率也就高(可以高效地帮助我们去选数来解决生活中地问题);
相关文章:
数据结构与算法 - 树 #数的概念 #二叉树 #堆 - 堆的实现/堆排序/TOP-K问题
文章目录 前言 一、树 (一)、概念 1、树的定义 (二)、树的定义 1、树为什么是递归定义的? 2、如何定义树(如何表达一棵树) 解决方案一:假设我们得知该树的度 解决方案二:顺序表 解决方案三:左孩子右兄弟表示法 二、二叉…...

Git推送被拒
今天开发完成一个新的需求,将自己的分支合并到test分支后,推送到远程仓库,结果显示推送被拒: 原因是因为有人更新了test分支的代码,我在合并之前没有拉取最新的test分支代码,所以他提示我“推送前需要合并…...
Jmeter进行http接口测试
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 本文主要针对http接口进行测试,使用jmeter工具实现。 Jmeter工具设计之初是用于做性能测试的,它在实现对各种接口的调用方面已经做的比较…...

工业相机详解及选型
工业相机相对于传统的民用相机而言,具有搞图像稳定性,传输能力和高抗干扰能力等,目前市面上的工业相机大多数是基于CCD(Charge Coupled Device)或CMOS(Complementary Metal Oxide Semiconductor)芯片的相机。 一,工业相机的分类 …...

RAID 矩阵
在架构设计中,RAID矩阵(RAID Log)是一个用于项目管理和风险管理的工具,帮助团队有效管理和跟踪项目中可能影响成功交付的关键因素。与存储技术中的 RAID 不同,这里的 RAID 是一个缩写,代表: R:…...

详细分析Redisson分布式锁中的renewExpiration()方法
目录 一、Redisson分布式锁的续期 整体分析 具体步骤和逻辑分析 为什么需要递归调用? 定时任务的生命周期? 一、Redisson分布式锁的续期 Redisson是一个基于Redis的Java分布式锁实现。它允许多个进程或线程之间安全地共享资源。为了实现这一点&…...

实验3,网络地址转换
实验3:网络地址转换 实验目的及要求: 通过实验,掌握NAT技术的工作原理,了解三种不同类型NAT技术的主要作用以及各自的主要应用环境。能够完成静态NAT和复用NAT技术的应用,并熟练掌握NAT技术相关的配置命令。 实验设…...

Java 中的 String 字符串是不可变的
文章目录 什么是不可变字符串?举个例子直观理解 不可变的原理1. 内部实现2. 字符串常量池3. 线程安全 为什么要设计成不可变?什么时候用可变字符串?示例 总结推荐阅读文章 在 Java 编程中,字符串(String)是…...

计算机网络架构实例
小型企业网络 1. 终端设备: - 员工的台式电脑和笔记本电脑,用于日常办公,如文档处理、邮件收发、业务软件使用等。 - 智能手机和平板电脑,方便员工在外出或移动办公时也能接入公司网络,查看邮件和处理紧急事务。 2.…...

Chrome与Firefox浏览器HTTP自动跳转HTTPS的解决方案
一、背景介绍 随着网络安全意识的不断提高,越来越多的网站开始采用HTTPS协议,以确保数据传输的安全性。然而,有时用户在浏览网页时,可能会遇到HTTP请求被自动跳转至HTTPS的情况导致网站打不开,提示安全问题࿰…...

众数信科荣登“2024 CHINA AIGC 100”榜单
2024年10月17日,由非凡产研推出的「2024 CHINA AIGC 100」榜单隆重发布,众数信科凭借领先的企业AI智能体解决方案能力荣登榜单。 非凡产研AIGC 100 评选旨在挖掘国内具有高潜力的AI应用,为AI产业的高质量发展注入新动力。榜单覆盖了教育、医疗…...

【AI知识】距离度量和相似性度量的常见算法
本文介绍一些AI中常见的距离度量和相似性度量算法: 1. 欧几里得距离(Euclidean Distance) 欧几里得距离是最常见的距离度量方法,用来计算两个向量之间的“直线距离”,也被成为L2范数。 公式如下,其中 x…...

LeetCode1004.最大连续1的个数
题目链接:1004. 最大连续1的个数 III - 力扣(LeetCode) 1.常规解法(会超时) 遍历数组,当元素是1时个数加一,当元素是0时且已有的0的个数不超过题目限制时,个数加一,若上…...
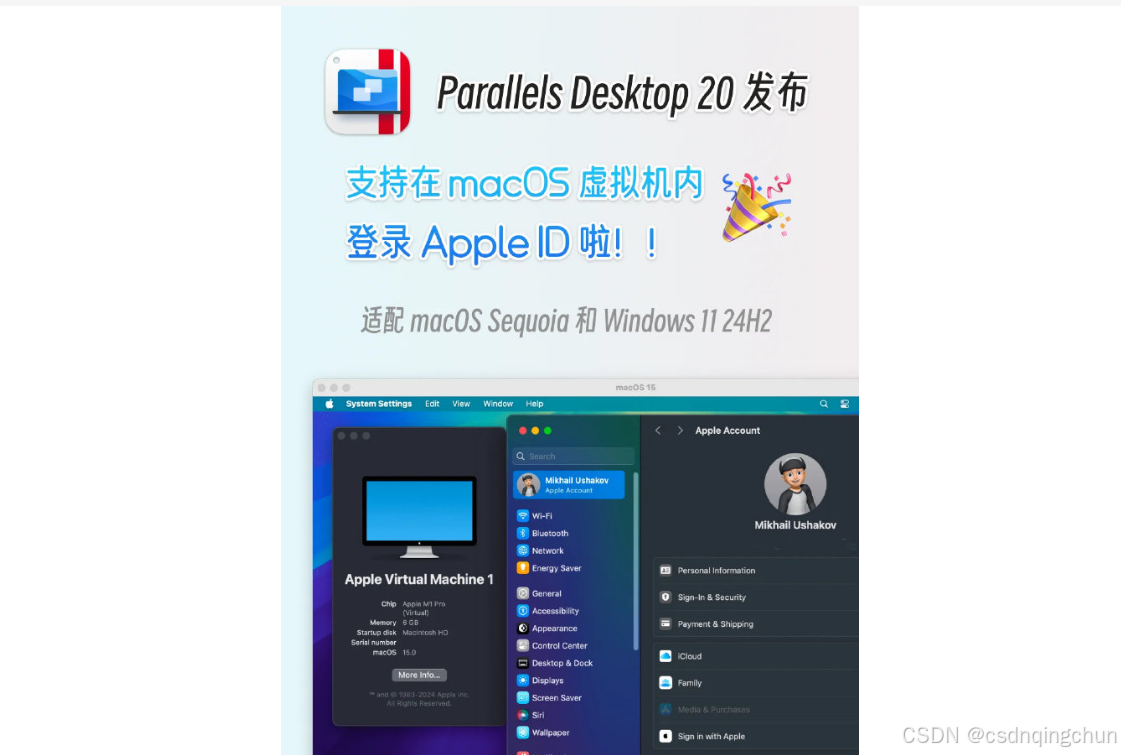
Parallels Desktop20虚拟机软件能让你在Mac上无缝运行Windows
Code 生成器:Parallels Desktop 20最新版本虚拟机的奇妙世界 🌟【轻松跨越操作系统界限】🌟 你是否常常感到在Mac和Windows之间切换太麻烦?Parallels Desktop 20最新版,让你不再为跨系统操作而烦恼。这款虚拟机软件能让…...

Golang | Leetcode Golang题解之第476题数字的补数
题目: 题解: func findComplement(num int) int {highBit : 0for i : 1; i < 30; i {if num < 1<<i {break}highBit i}mask : 1<<(highBit1) - 1return num ^ mask }...

Spring 实现 3 种异步流式接口,干掉接口超时烦恼
大家好,我是小富~ 如何处理比较耗时的接口? 这题我熟,直接上异步接口,使用 Callable、WebAsyncTask 和 DeferredResult、CompletableFuture等均可实现。 但这些方法有局限性,处理结果仅返回单个值。在某…...

字节 HLLM 论文阅读
github连接:https://github.com/bytedance/HLLM 探讨问题: 推荐LLM的三个关键问题: LLM预训练权重通常被认为是对世界知识的概括,其对于推荐系统的价值?对推荐任务进行微调的必要性?LLM是否可以在推荐系统…...

Chromium html<iframe>对应c++接口定义
HTML <iframe> 标签 使用 <iframe> 标签 在当前 HTML 文档中嵌入另一个文档: <!DOCTYPE html> <html> <body><h1>iframe 元素</h1><iframe src"https://www.w3school.com.cn" title"W3School 在线教…...

Vue详细入门(语法【三】)
今天滴的学习目标!!! Vue组件是什么?组件的特性和优势Vue3计算属性Vue3监听属性 在前面Vue详细入门(语法【一】——【二】)当中我们学习了Vue有哪些指令,它的核心语法有哪些?今天我们…...

快速构建SpringBoot项目
快速构建SpringBoot项目 下文将简述如何快速构建一个SpringBoot项目,使用SpringData JPA实现持久层访问,集成lombok、swagger2及集成thymeleaf进行页面展示。 准备环境: JDK版本:jdk17 IntelliJ IDEA版本: 2023.2.7…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...