机器学习——解释性AI与可解释性机器学习
解释性AI与可解释性机器学习: 理解机器学习模型背后的逻辑
随着人工智能技术的广泛应用,机器学习模型越来越多地被用于决策过程。然而,这些模型,尤其是深度学习模型,通常被视为“黑箱”,难以理解其背后的决策逻辑。解释性AI(Explainable AI, XAI)和可解释性机器学习(Interpretable Machine Learning, IML)旨在解决这个问题,使模型的决策过程透明、可信。本文将深入探讨解释性AI与可解释性机器学习的概念、方法和代码实现,帮助读者全面理解这一重要主题。
1. 为什么需要解释性AI?
1.1 黑箱问题
现代的深度学习模型,特别是神经网络模型,通常具有数十亿个参数,这使得它们的预测难以解释。即便这些模型在许多任务中表现出色,如图像识别、自然语言处理等,但其复杂的内部结构和特征提取过程使得人类难以理解其逻辑,这种现象被称为“黑箱问题”。
黑箱模型的不可解释性在一些敏感领域如医疗、金融和司法系统中特别令人担忧。在这些领域中,用户希望了解模型为何做出某种决策,以确保模型的决策公正、合理并能够识别潜在的偏差。
1.2 法规合规与伦理问题
近年来,越来越多的法律和伦理准则要求人工智能模型的决策过程是透明的。例如,欧盟的《通用数据保护条例》(GDPR)中明确指出,用户有权要求解释有关自动化决策的逻辑。这意味着需要开发能够解释其决策的模型或方法,解释性AI因此成为一个重要研究方向。
2. 解释性AI的分类
可解释性可以从多个维度来考虑:
- 可解释性 vs 可理解性:可解释性通常指通过后处理方法使复杂模型变得可解释,而可理解性更侧重于构建本身就易于解释的模型。
- 内生解释 vs 后处理解释:内生解释指的是模型本身就具有解释性,如决策树、线性回归等;后处理解释则是对训练好的模型进行分析和解释。
2.1 本地解释 vs 全局解释
- 本地解释:关注单个预测结果的解释,目的是理解模型如何对某个具体的输入进行决策。
- 全局解释:关注整个模型的工作机制,解释模型在整个数据集上的行为。
3. 可解释性机器学习的方法
3.1 模型本身具有可解释性
一些简单的模型具有天然的可解释性,例如:
- 线性回归:通过模型系数可以直接理解特征对预测的影响。
- 决策树:决策过程可以通过树结构可视化,便于理解模型如何进行决策。
3.2 黑箱模型的解释方法
对于那些复杂的黑箱模型,如深度神经网络,我们需要一些技术来解释它们的预测:
- SHAP (Shapley Additive Explanations)
- LIME (Local Interpretable Model-agnostic Explanations)
- Saliency Maps (梯度方法)
3.2.1 LIME 示例代码
LIME 是一种用于解释黑箱模型的本地方法。下面是一个使用 LIME 解释分类器决策的示例:
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.ensemble
from lime import lime_tabular# 加载数据
iris = sklearn.datasets.load_iris()
X, y = iris.data, iris.target# 训练随机森林模型
rf = sklearn.ensemble.RandomForestClassifier(n_estimators=100)
rf.fit(X, y)# 使用LIME进行解释
explainer = lime_tabular.LimeTabularExplainer(X, feature_names=iris.feature_names, class_names=iris.target_names, discretize_continuous=True)# 选择一个样本进行解释
sample = X[25]
explanation = explainer.explain_instance(sample, rf.predict_proba, num_features=2)
explanation.show_in_notebook()
在这个示例中,我们使用了 lime 库对 Iris 数据集进行解释。LIME 通过扰动输入特征并观察模型输出的变化,来评估每个特征对决策的影响,从而解释模型对某个输入的预测。
3.3 SHAP 示例代码
SHAP 是基于合作博弈论的解释方法,通过计算 Shapley 值来衡量每个特征对预测的贡献。以下是使用 SHAP 解释随机森林模型的示例:
import shap
import xgboost
import sklearn.datasets# 加载数据并训练模型
X, y = sklearn.datasets.load_boston(return_X_y=True)
model = xgboost.XGBRegressor().fit(X, y)# 使用SHAP解释模型
explainer = shap.Explainer(model, X)
shap_values = explainer(X)# 可视化第一个样本的解释
shap.plots.waterfall(shap_values[0])
SHAP 提供了多种可视化方法,如 waterfall 图可以直观地展示特征对某个样本预测值的贡献。
4. 可解释性机器学习的具体应用
4.1 医疗应用
在医疗领域中,模型的解释性至关重要,因为它关系到患者的生命安全。例如,在预测疾病的模型中,医生需要知道哪些特征(如血压、年龄等)对预测结果有重要影响,这样才能在决策中更好地结合医疗知识。
以下代码展示了如何使用 LIME 解释医疗数据中的一个分类模型:
import pandas as pd
import sklearn.model_selection
import sklearn.linear_model
from lime import lime_tabular# 加载糖尿病数据集
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
df = pd.read_csv(url, names=columns)
X = df.iloc[:, :-1]
y = df['Outcome']# 训练逻辑回归模型
model = sklearn.linear_model.LogisticRegression(max_iter=1000)
model.fit(X, y)# 使用LIME解释模型
explainer = lime_tabular.LimeTabularExplainer(X.values, feature_names=columns[:-1], class_names=['No Diabetes', 'Diabetes'], discretize_continuous=True)
explanation = explainer.explain_instance(X.values[5], model.predict_proba, num_features=3)
explanation.show_in_notebook()
4.2 金融风控
在金融行业中,模型的预测结果会影响贷款申请的批准或拒绝。为了保证客户的信任并满足监管需求,金融机构需要解释模型的决策过程,例如贷款被拒绝的原因是什么。
import shap
import lightgbm as lgb# 加载数据并训练LightGBM模型
data = sklearn.datasets.load_breast_cancer()
X, y = data.data, data.target
model = lgb.LGBMClassifier()
model.fit(X, y)# 使用SHAP解释模型
explainer = shap.Explainer(model, X)
shap_values = explainer(X)# 可视化全局特征重要性
shap.summary_plot(shap_values, X, feature_names=data.feature_names)
在上面的代码中,我们使用了 LightGBM 模型来预测乳腺癌数据,并用 SHAP 来解释模型的全局特征重要性,帮助理解哪些特征对整个模型的预测贡献最大。
5. 构建具有可解释性的模型
并不是所有机器学习任务都需要深度模型,对于一些需要高可解释性的任务,我们可以选择一些本身就具有良好可解释性的模型。
5.1 线性模型
线性回归和逻辑回归模型具有天然的可解释性,特别适用于数据和输出之间存在简单线性关系的场景。模型的每个系数直接反映了特征对目标变量的影响方向和大小。
5.2 决策树和规则模型
决策树通过其分支结构展示了模型的决策过程,能够很清楚地表明每个决策节点的条件。以下是一个决策树的示例代码:
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt# 加载数据并训练决策树模型
X, y = sklearn.datasets.load_iris(return_X_y=True)
model = DecisionTreeClassifier(max_depth=3)
model.fit(X, y)# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
在上面的代码中,我们使用了 DecisionTreeClassifier 并通过 plot_tree 函数对决策树进行了可视化,能够直观地看到模型的决策逻辑。
6. 解释性AI的挑战和未来
6.1 挑战
- 复杂度:随着模型复杂度的增加,可解释性方法也会变得越来越复杂,这可能导致解释本身也难以理解。
- 解释的可信度:解释方法本身可能带有偏差,并不总是能完全准确地代表模型的行为。
- 计算开销:对于某些大型模型(如深度学习模型),解释的计算成本非常高。
6.2 未来趋势
- 可解释性与准确性的平衡:未来的研究将更多地关注如何在保持高模型性能的同时增强其可解释性。
- 自动化解释工具:随着解释性需求的增加,更多的自动化工具将被开发出来,用于帮助研究人员和从业者更高效地解释复杂模型。
- 面向领域的解释方法:针对特定领域(如医疗、法律)的定制化解释方法将被更多地开发,以满足领域专家的需求。
7. 结论
解释性AI与可解释性机器学习在当今社会中扮演着越来越重要的角色,使得机器学习模型不再只是一个“黑箱”,而是一个可以被人类理解和信任的工具。通过 LIME、SHAP 等工具,我们可以更好地解释复杂模型的行为,增强用户对模型的信任感。在未来,随着算法的不断优化和法规的日益严格,解释性AI必将在更多领域中得到广泛应用。
8.总结
本文探讨了解释性AI和可解释性机器学习的必要性及其方法,重点介绍了黑箱问题、法规要求、模型可解释性的多种方法(如LIME和SHAP)以及它们在医疗和金融中的应用。本文还讨论了具有可解释性的模型(如线性回归、决策树)及其优缺点,并展望了未来解释性AI的发展趋势,如自动化工具和面向特定领域的解释方法。
参考资料
- Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?” Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Lundberg, S. M., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems.
相关文章:

机器学习——解释性AI与可解释性机器学习
解释性AI与可解释性机器学习: 理解机器学习模型背后的逻辑 随着人工智能技术的广泛应用,机器学习模型越来越多地被用于决策过程。然而,这些模型,尤其是深度学习模型,通常被视为“黑箱”,难以理解其背后的决策逻辑。解…...

中国全国省市区县汇总全国省市区json省市区数据2024最新
简介 包含全国省市区县数据,共3465个。 全国总共有23个省、5个自治区、4个直辖市、2个特别行政区。 ——更新于2024年10月16日,从2017年开始,已经更新坚持7年 从刚开始1000个左右的城市json,到现在全国省市区县3465个。 本人感觉应该是目前最完善的~ 每年都在更新中,…...
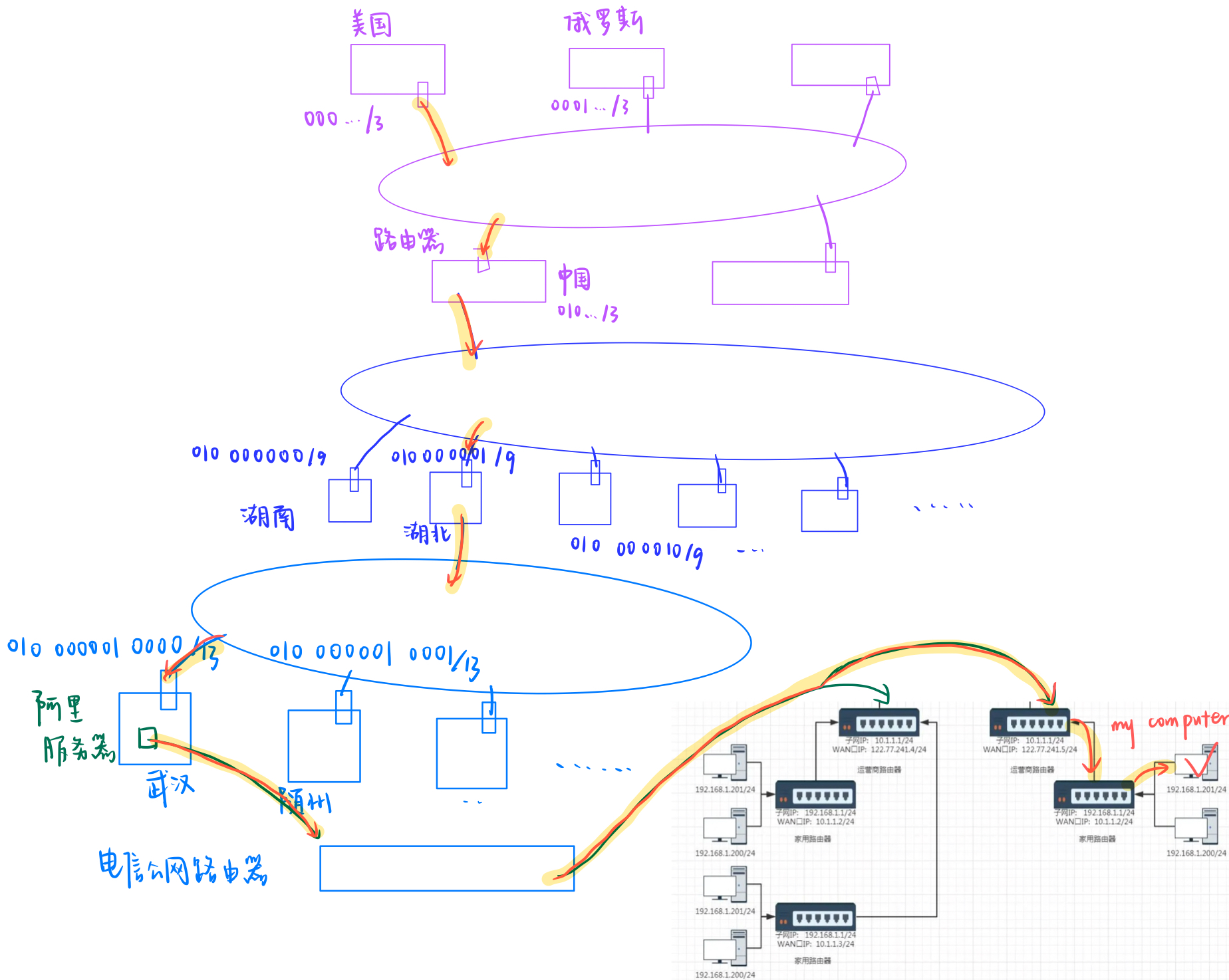
[Linux#67][IP] 报头详解 | 网络划分 | CIDR无类别 | DHCP动态分配 | NAT转发 | 路由器
目录 一. IP协议头格式 学习任何协议前的两个关键问题 IP 报头与有效载荷分离 分离方法 为什么需要16位总长度 如何交付 二. 网络通信 1.IP地址的划分理念 2. 子网管理 3.网络划分 CIDR(无类别域间路由) 目的IP & 当前路由器的子网掩码 …...

路由器原理和静态路由配置
一、路由器的工作原理 根据路由表转发数据 接收数据包→查看目的地址→与路由表进行匹配找到转发端口→转发到该端口 二、路由表的形成 它是路由器中维护的路由条目的集合,路由器根据路由表做路径选择,里面记录了网段ip地址和对应下一跳接口的接口号。…...

UE5 使用Animation Budget Allocator优化角色动画性能
Animation Budget Allocator是UE内置插件,通过锁定动画系统所占CPU的预算,在到达预算计算量时对动画进行限制与优化。 开启Animation Budget Allocator需要让蒙皮Mesh使用特定的组件,并进行一些编辑器设置即可开启。 1.开启Animation Budget…...

Element UI 组件库详解:从入门到精通
在追求统一且流畅的用户体验时,开发者们常常选择使用 UI 组件库来加快开发速度。Element UI,这个基于 Vue.js 的组件库,提供了大量界面组件,极大地提升了前端开发的效率。本文将指导您如何开始使用 Element UI 组件库,…...
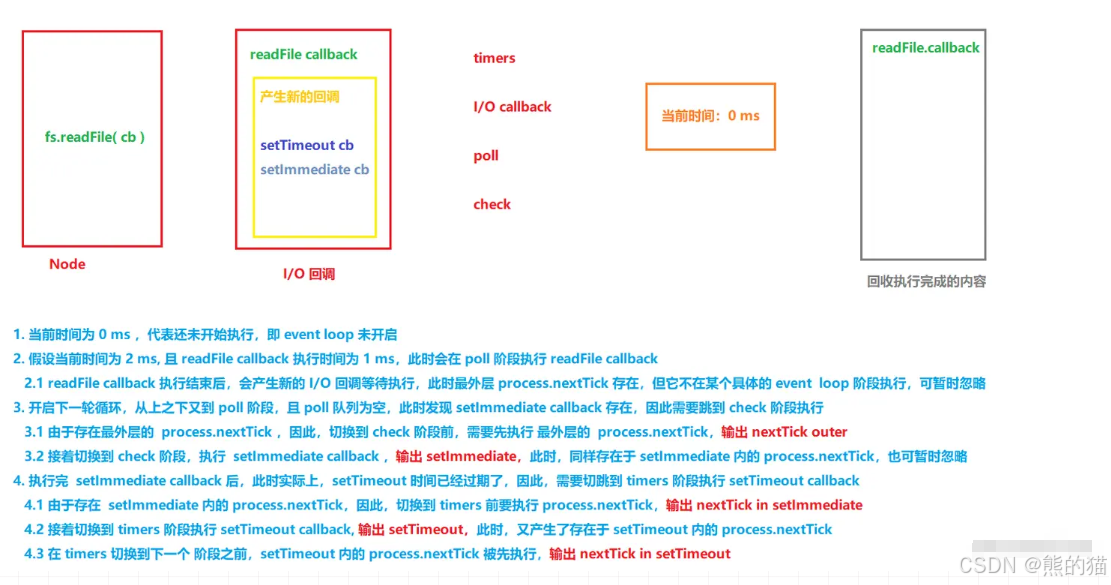
JavaScript 事件循环(EventLoop) —— 浏览器 Node
一、事件循环的本质 本质:运行时对 JS 脚本的调度方式就叫做事件循环. 对于 浏览器 而言,需要考虑用户交互、UI渲染、脚本运行、网络请求等操作,这些操作必然都依赖于事件去执行,因此,为了协调事件必须要使用事件循环…...

【ROS2】订阅手柄数据,发布运动命令
1、相关消息 sensor_msgs::msg::Joy:用来描述手柄控制器数据 geometry_msgs::msg::Twist :用来描述物体运动时的线速度和角速度 参见博客: 【ROS2】geometry_msgs::msg::Twist和sensor_msgs::msg::Joy 2、订阅和发布 2.1 定义、创建订阅者和发布者 订阅手柄的按键、摇杆…...
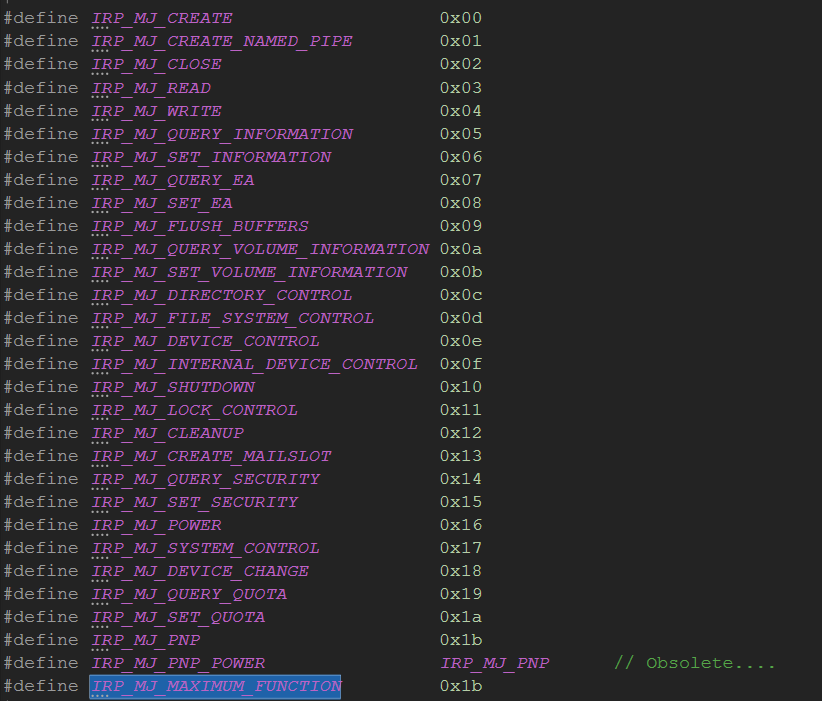
WinX86内核02-驱动程序
把昨天的程序改用 c++ 编译,改成 .cpp ,发现编译报错 原因是名称粉碎,因此可以直接 extern “C”声明一下这个函数 或者用 头文件(推荐) 因为 在头文件中 可以把 头文件一起包含进去 #pragma once extern "C" { #include <Ntddk.h> /*驱动入口函…...

基于SpringBoot+Vue的体育馆场地预约系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

【WebGIS】Cesium:天地图加载
天地图是中国国家基础地理信息系统,由中国测绘地理信息局和国家地理信息公共服务平台共同开发和运营。它提供多项地理信息服务,包括地图数据、地理编码、路径规划以及地理搜索等。天地图的目标是为各行业提供高质量、全面的地理信息数据和解决方案。 天…...

[产品管理-46]:产品组合管理中的项目平衡与管道平衡的区别
目录 一、项目平衡 1.1 概述 1.2 项目的类型 1、根据创新程度和开发方式分类 2、根据产品开发和市场周期分类 3、根据风险程度分类 4、根据市场特征分类 5、根据产品生命周期分类 1.3 产品类型的其他分类 1、按物理形态分类 2、按功能或用途分类 3、按技术或创新程…...

【MySQL】MySQL的简单了解详解SQL分类数据库的操纵方法
一、mysql定义 mysql是数据库服务的客户端,mysqld是数据库服务的服务器端。mysql的本质就是基于CS模式下的一种网络服务。数据库一般指的是在磁盘中或内存中存储的特定结构组织的数据,将来就是在磁盘上存储的一套数据库方案。 创建数据库,本质…...

【Python爬虫实战】正则:从基础字符匹配到复杂文本处理的全面指南
🌈个人主页:https://blog.csdn.net/2401_86688088?typeblog 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、正则表达式 (一)正则表达式的基本作用 …...

10.18Python基础迭代器生成器_函数式编程
Python迭代器与生成器 1. 迭代器 Iterator 什么是迭代器 迭代器是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器可以重复使用,而不会像列表那样在迭代时被修改。 迭代器函数iter和next 函数说明iter(iterable)从可迭代对象中返回一个迭…...
)
HttpPost 类(构建 HTTP POST 请求)
HttpPost 类是 Apache HttpClient 库中的一个类,用于构建 HTTP POST 请求。以下是 HttpPost 类的一些常用方法和代码案例: 常用方法 构造方法: HttpPost(String uri):创建一个 HttpPost 对象,并将请求的 URI 作为参数…...

xtu oj 原根
文章目录 回顾杂思路c 语言代码 回顾 AB III问题 H: 三角数问题 G: 3个数等式 数组下标查询,降低时间复杂度1405 问题 E: 世界杯xtu 数码串xtu oj 神经网络xtu oj 1167 逆序数(大数据) 杂 有一些题可能是往年的程设的题,现在搬到…...

Java Spring 中常用的 @PostConstruct 注解使用总结
引言 在最近的学习中,我发现了一个非常实用的注解 —— PostConstruct。通过深入学习,逐步发现这个注解在实际开发中可以帮助我们更轻松地解决不少原本复杂的问题,特别是在项目启动时自动执行一些必要的初始化操作。相比于手动调用ÿ…...

Visual Studio--VS安装配置使用教程
Visual Studio Visual Studio 是一款功能强大的开发人员工具,可用于在一个位置完成整个开发周期。 它是一种全面的集成开发环境 (IDE)。对新手特别友好,使用方便,不需要复杂的去配置环境。用它学习很方便。 Studio安装教程 Visual Studio官…...

什么叫CMS?如何使用CMS来制作网站?
CMS是什么? 内容管理系统(Content Management System,CMS),是一种位于WEB前端(Web 服务器)和后端办公系统或流程(内容创作、编辑)之间的软件系统。内容的创作人员、编辑人…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...