分布式ID多种生成方式
分布式ID
雪花算法(时间戳41+机器编号10+自增序列号10)
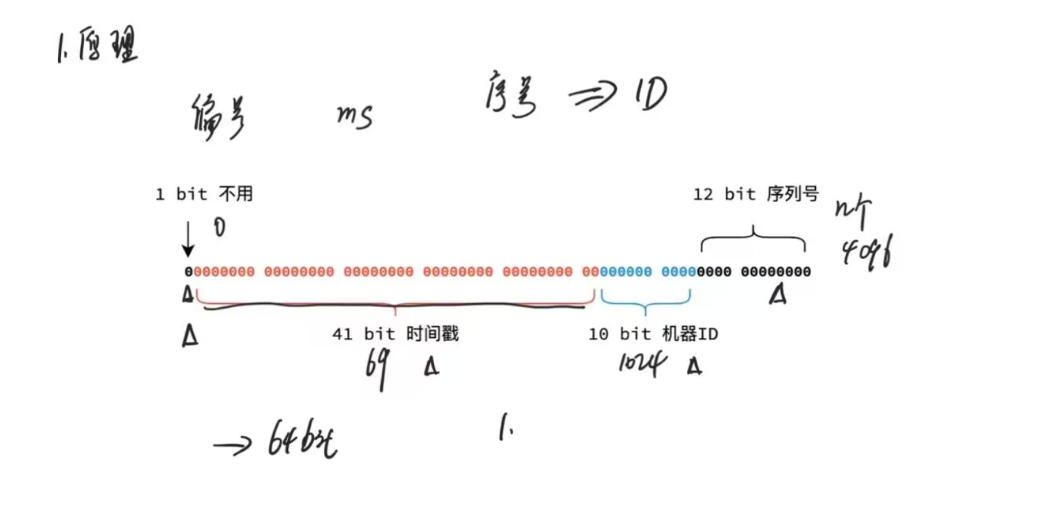
作用:希望ID按照时间进行有序生成
原理:
即一台带有编号的服务器在毫秒级时间戳内生成带有自增序号的ID,这个ID保证了自增性和唯一性
雪花算法根据结构的生成ID个数的上线时,每毫秒最多能生成2^12次方个ID即4096个
总共64个Bit位,第一个位置不用,使用41个比特位作为时间戳(可以使用69年,单位时毫秒级别)、使用10个bit为作为机器ID(机器编号),最后使用12个比特位作为自增ID
特点:
1、按照时间递增
2、因为分布式ID采用了机器编号组成,因此,就算进行分布式部署,由于机器编号不同,最后生成的ID也不同,做到了不重复
3、1毫秒产生4096个id,那么1秒内就能产生400万左右个的ID
实现方式:
now:生成id的时间戳
workId:机器编号id
n:序列号
大概生成伪代码
now=System.now();//获取当前时间戳
if(now==last){last //为前一个生成id的时间戳n++;if(n>4069){//判断序列号是否超过每毫秒内的最大值 now=nextTime();n=0;;}
}else{n=0;
}long id=(now<<22)|(workId<<12)|n; //去或运算实现方式:可以使用Redis来完成
@Component
public class RedisIdWorker {/*** 开始时间戳*/private static final long BEGIN_TIMESTAMP = 1640995200L;/*** 序列号的位数*/private static final int COUNT_BITS = 22;private static final int work_id = 452;//机器idprivate StringRedisTemplate stringRedisTemplate;public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}public long nextId(String keyPrefix) {// 1.生成时间戳LocalDateTime now = LocalDateTime.now();//需要获得毫秒级的时间戳long nowSecond = now.toEpochSecond(ZoneOffset.UTC);long timestamp = nowSecond - BEGIN_TIMESTAMP;//得到毫秒// 2.生成序列号// 2.1.获取当前日期,精确到天String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));// 2.2.自增长long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);// 3.拼接并返回return timestamp << COUNT_BITS | work_id<<12|count;//时间戳左移22位,机器id左移12位,序列号}
}Redis实现全局唯一Id(时间戳+自增序号)
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:


时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
将时间戳转化为日期格式,然后作为key好处
- 1、首先就是通过redis的key不能重复来进行计算,每秒内进行自增
- 2、便于统计每天、每月的一个id生成量
分布式ID生成方式
- 1、UUID
- 2、数据库自增ID
- 3、Redis
- 4、雪花算法
UUID:
缺点:
- 生成不是自增的,会导致插入数据库的效率较慢
- 2、生成所需要的空间较大
数据库自增
数据库自增ID:分库分表情况下会重复
解决方式:单独使用一张表(主要字段,id,其他字段)来生成分布式ID
表结构如下:
create table order_id(id bigint(20) unsigned not null auto_increment,stub char(1) not null default '',primary key (id),unique key sub(stub))begin;
replace into order_id stub values('b');//如果数据库中有字段b的值那么会先将原来字段删除,再进行插入,否则直接插入
select Last_insert_id();//通过这个查询拿到最后一个ID
commit;缺点:
在高并发、数据量大的情况下性能比较差
对于高并发方面:比如每秒几十万的生成,那么需要同时去数据库执行这个生成ID,数据库扛不住
第二个就是,每次生成ID都需要去访问数据库,性能肯定不会太好,就算id表的数据很少基本就是用1条,但需要和数据库交互性能本就会受影响
当然解决上面方法痛点可以采用集群模式
比如可以将请求负载均衡到多个数据库,数据库A自增比如只生成奇数1,3,5,数据库只生成偶数比如2,4,6
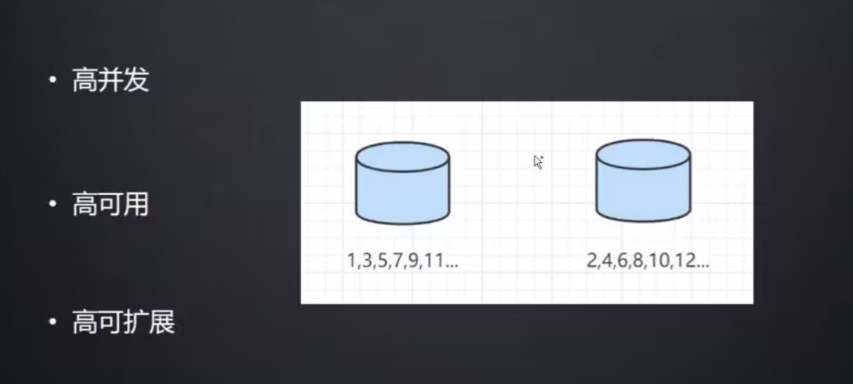

这种方式的问题:
- 1、不是绝对的ID递增
- 2、对于高并发情况:如果要使用数据库方式,那么就只有一直加机器,让其负载均衡
-
- 如果一开始并发量不大,我们就使用两台机器来做分布式自增id,但是后面并发量变大了,两台并发量扛不住,那只有加机器,那么我们可以先拿到此时库中最大的id(比如10000),然后将所有数据库的自增起始值设置为大于这个值比如(10w)的,然后再设置对应的步长,但是这个方式设置,需要对数据库进行重启(所以说这种方式在高并发情况下并不合适)
雪花算法
public class SnowflakeIdWorker{/** 开始时间截 (2015-01-01) */private final long twepoch = 1288834974657L;/** 机器id所占的位数 */private final long workerIdBits = 5L;/** 数据标识id所占的位数 */private final long datacenterIdBits = 5L;/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */private final long maxWorkerId = -1L ^ (-1L << workerIdBits);/** 支持的最大数据标识id,结果是31 */private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);/** 序列在id中占的位数 */private final long sequenceBits = 12L;/** 机器ID向左移12位 */private final long workerIdShift = sequenceBits;/** 数据标识id向左移17位(12+5) */private final long datacenterIdShift = sequenceBits + workerIdBits;/** 时间截向左移22位(5+5+12) */private final long timestampLeftShift = sequenceBits + workerIdBits+ datacenterIdBits;/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */private final long sequenceMask = -1L ^ (-1L << sequenceBits);/** 工作机器ID(0~31) */private long workerId;/** 数据中心ID(0~31) */private long datacenterId;/** 毫秒内序列(0~4095) */private long sequence = 0L;/** 上次生成ID的时间截 */private long lastTimestamp = -1L;/*** 构造函数** @param workerId* 工作ID (0~31)* @param datacenterId* 数据中心ID (0~31)*/public SnowflakeIdWorker(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}/*** 获得下一个ID (该方法是线程安全的)** @return SnowflakeId*/public synchronized long nextId() {long timestamp = timeGen();// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常//这里是处理时间回波的方案:为什么会有:因为我们的ID是对当前时间具有比较高的依赖性//所以一半会采取将生成分布式ID的服务器的时间和时间服务器的时间进行同步,//如果发现本地生成ID的这台服务器的时间走快了,那么再去时间的时候就会有时间回退到之前//比如现在系统是12:30:05,然后准确时间是20:30:00// 那么时间就会回退到30:00那么如果不额外处理就会造成ID重复的问题if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",(lastTimestamp - timestamp)));}// 如果是同一时间生成的,则进行毫秒内序列if (lastTimestamp == timestamp) {//mask:4095即二进制12个1(即如果序列号小于4095时候就是本身,//如果超过了4096了比如4096那么后面12位就是0,那么做与运算之后序列号就变为0sequence = (sequence + 1) & sequenceMask;// 毫秒内序列溢出if (sequence == 0) {//超过了4096,那么就等下一秒// 阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}// 时间戳改变,毫秒内序列重置else {sequence = 0L;}// 上次生成ID的时间截lastTimestamp = timestamp;// 移位并通过或运算拼到一起组成64位的ID//timestamp - twepoch(twepoch一般设置为服务启动的一个初始时间,因为雪花算法最多69年//减去之后时间就可以长一点,比如初始时间2024年的,那么就可以用用到2024+69return ((timestamp - twepoch) << timestampLeftShift) //| (datacenterId << datacenterIdShift) //| (workerId << workerIdShift) //| sequence;}/*** 阻塞到下一个毫秒,直到获得新的时间戳** @param lastTimestamp* 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以毫秒为单位的当前时间** @return 当前时间(毫秒)*/protected long timeGen() {return System.currentTimeMillis();}//测试方法public static void main(String[] args) {// 假设我们有一个工作机器ID为1,数据中心ID为1的环境long workerId = 1L;long datacenterId = 1L;// 创建一个SnowflakeIdWorker实例SnowflakeIdWorker idWorker = new SnowflakeIdWorker(workerId, datacenterId);// 生成并打印10个ID作为示例for (int i = 0; i < 10; i++) {long id = idWorker.nextId();System.out.println(id);}}}时间回拨:
- 如果回波时间很短比如(<=100ms)
-
- 比较短可以考虑直接sleep一段时间(等时间大于原来的时间后继续生成ID)
- 如果回拨时间适中比如(100ms<s<=1s)
-
- 我们可以采用缓存机制,即缓存下每一毫秒生成的最大id,可以使用hashmap等结构
- 然后出现时间回波后就只需要拿到最后那一毫秒的最大ID,然后再此基础上进行自增
- 时间太长不太适合:比较占内存
- 如果时间比较长,比如(1s<s<=5s)
-
- 这台机器上出现时间回波,那我就让客户端进行重试策略,去另一个分布式ID服务上去拿ID
- 当时间回拨非常长比如(5<s):
-
- 就可以考虑将这个服务进行下线,然后将这台机器时间不同好之后又重新上线
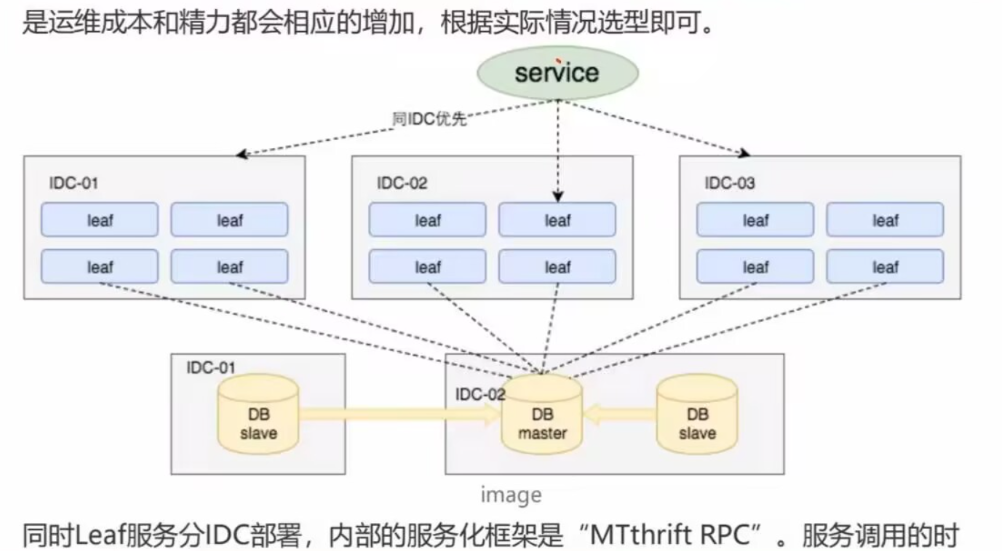
美团Leaf分布式ID生成方案(号段模式)
提供了两种方式:
Leaf 提供了 号段模式 和 Snowflake(雪花算法) 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:《Leaf——美团点评分布式 ID 生成系统》)。
号段模式
核心:数据库中一次自增一段的ID,然后本地程序拿到这一段ID之后,使用程序进行自己维护自增ID,比如一次访问数据库拿到数据范围是1000~2000,那么我们程序就在这个范围进行自增
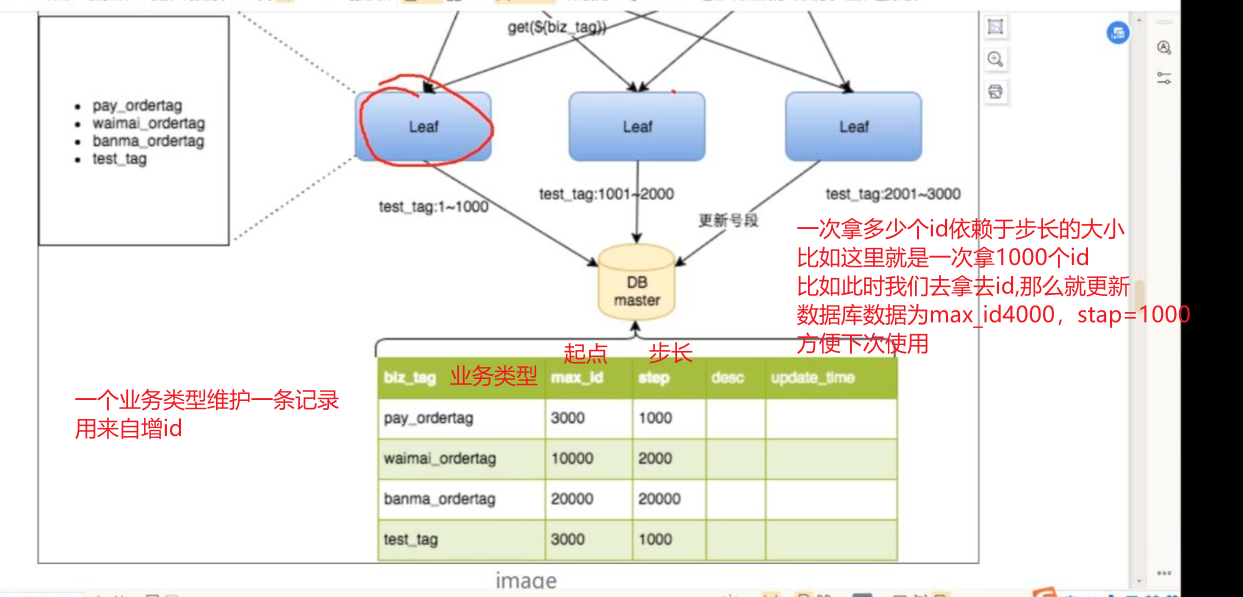
优点:
- 支撑高并发:
- leaf服务可以很方便的进行线性扩展,性能完全能支撑大多数业务场景
- ID号码是趋势递增的8byte的64位数字。满足上述数据库存储的主键要求
- 3、容灾性高:Leaf服务内部有号段缓存,几十DB宕机了,短时间内Leaf服务任然能正常对外提供服务(因为每次leaf服务从DB中拿的是一段ID)
- 4:灵活性强,比如这里max_id,步长step等可以自定义,直接修改
- 5、如果后面并发量非常大,那么我们就直接分表就完事了,让每个业务类型使用一张表,一个服务器,即一个表一个业务
缺点:
- 1、id是有规律的,别人可以根据id可以分析出每天的订单量大概在多少,可能会造成数据泄露
- 2、数据波动比较大(即在去和数据库进行交互去获取一段的ID的那个时刻,由于各个服务都去拿取这个数据,由于每次获取id后需要进行一个数据的更行操作,所以数据库会有一个行锁,虽然也比较快,但是在高并发情况下,就会导致在取id这一时刻,用户的响应时间会增加)
- 3、DB宕机,还是
优化段号模式(双段号模式):
上面这个方案的优化:美团Leaf方式---缓存双Buffer
- 当leaf服务器原来的ID用了10%的时候那就取访问数据库取下一段,重复这个操作,这样处理就比较好的处理

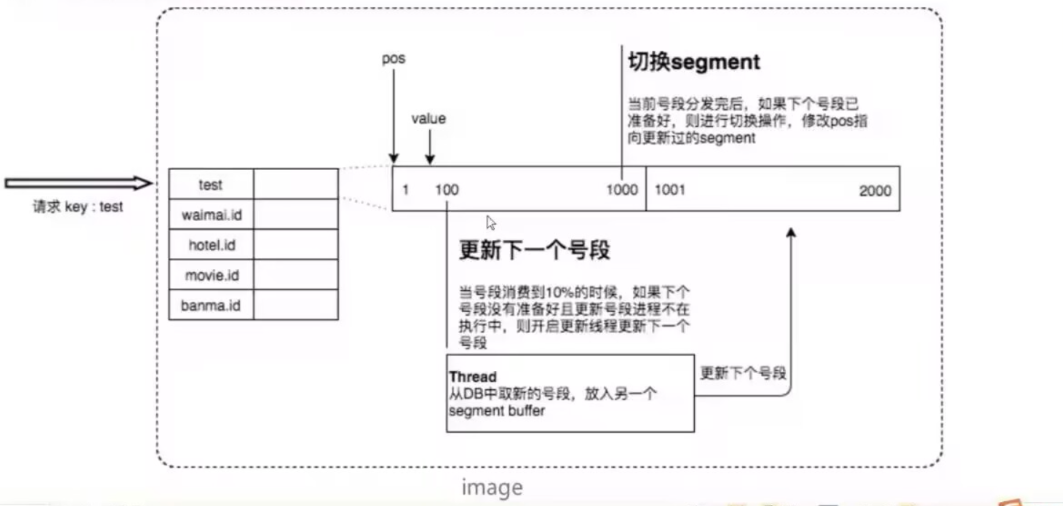


当让也可以使用Redis来完成自增设计,和上面这个设计方式其实也类似
这两种方式都有一个共同的问题:就是自增ID需要依赖于第三方库,比如Mysql,Redis等
大厂基本就是基于雪花算法来进行封装对应的方法的

时钟回波的解决方案:默认的雪花算法时钟回波问题时就抛一个异常,但是对于每个公司来说处理方式是不同的,大多数公司是另外的处理方式,
雪花算法模式
还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
相关文章:
分布式ID多种生成方式
分布式ID 雪花算法(时间戳41机器编号10自增序列号10) 作用:希望ID按照时间进行有序生成 原理: 即一台带有编号的服务器在毫秒级时间戳内生成带有自增序号的ID,这个ID保证了自增性和唯一性 雪花算法根据结构的生成ID个数的上线时…...

时间序列预测(六)——循环神经网络(RNN)
目录 一、RNN的基本原理 1、正向传播(Forward Pass): 2、计算损失(Loss Calculation) 3、反向传播——反向传播通过时间(Backpropagation Through Time,BPTT) 4、梯度更新&…...

Day2算法
Day2算法 1.算法的基本概念 算法: 对特定问题求解步骤的一种描述,他叔指令的有限序列,其中的每条指令表示一个或多个操作。 算法的特性: 1.有穷性: 一个算法必须总在执行有穷步之后结束,且每一步都可…...

智洋创新嵌入式面试题汇总及参考答案
堆和栈有什么区别 内存分配方式 栈由编译器自动分配和释放,函数执行时,函数内局部变量等会在栈上分配空间,函数执行结束后自动回收。例如在一个简单的函数int add(int a, int b)中,参数a和b以及函数内部的一些临时变量都会在栈上分配空间,函数调用结束后这些空间就会被释放…...
)
无线网卡知识的学习-- wireless基础知识(nl80211)
1. 基本概念 mac80211 :这是最底层的模块,与hardware offloading 关联最多。 mac80211 的工作是给出硬件的所有功能与硬件进行交互。(Kernel态) cfg80211:是设备和用户之间的桥梁,cfg80211的工作则是观察跟踪wlan设备的实际状态. (Kernel态) nl80211: 介于用户空间与内核…...

除了 Python,还有哪些语言适合做爬虫?
以下几种语言也适合做爬虫: 一、Java* 优势: 强大的性能和稳定性:Java 运行在 Java 虚拟机(JVM)上,具有良好的跨平台性和出色的内存管理机制,能够处理大规模的并发请求和数据抓取任务&#x…...

JS | JS中类的 prototype 属性和__proto__属性
大多数浏览器的 ES5 实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class 作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。 构造函数的子类有prototype属性。 …...

15分钟学Go 第3天:编写第一个Go程序
第3天:编写第一个Go程序 1. 引言 在学习Go语言的过程中,第一个程序通常是“Hello, World!”。这个经典的程序不仅教会你如何编写代码,还引导你理解Go语言的基本语法和结构。本节将详细介绍如何编写、运行并理解第一个Go程序,通过…...

简单的常见 http 响应状态码
简单的常见 http 响应状态码 HTTP状态码(HTTP Status Code)是用以表示网页服务器超文本传输协议响应状态的3位数字代码。它由 RFC 2616 规范定义,所有状态码的第一个数字代表了响应的五种状态之一。 1. 大体分类 状态码类别解释1xx信息性响…...

2024年【安全员-C证】复审考试及安全员-C证模拟考试题
安全员-C证考试是针对生产经营单位的安全生产管理人员进行的职业资格认证考试。考试内容涵盖安全生产法律法规、安全管理知识、安全技术措施等多个方面。通过考试,可以检验考生对安全生产知识的掌握程度,提高安全管理水平,确保生产安全。 二…...

RT-Thread之STM32使用定时器实现输入捕获
前言 基于RT-Thread的STM32开发,配置使用定时器实现输入捕获。 比如配置特定通道捕获上升沿,该通道对应的引脚有上升沿信号输入,则触发捕获中断。 一、新建工程 二、工程配置 1、打开CubeMX 进行工程配置 2、时钟使用外部高速晶振 3、配置…...

数字图像处理:图像分割应用
数字图像处理:图像分割应用 图像分割是图像处理中的一个关键步骤,其目的是将图像分成具有不同特征的区域,以便进一步的分析和处理。 1.1 阈值分割法 阈值分割法(Thresholding)是一种基于图像灰度级或颜色的分割方法&…...

Java面试宝典-并发编程学习02
目录 21、并行与并发有什么区别? 22、多线程中的上下文切换指的是什么? 23、Java 中用到的线程调度算法是什么? 24、Java中线程调度器和时间分片指的是什么? 25、什么是原子操作?Java中有哪些原子类? 26、w…...

【每日一题】洛谷 - 快速排序模板
今天的每日一题来自洛谷,题目要求对给定的 N N N 个正整数进行从小到大的排序,并输出结果。我们将使用经典的**快速排序算法(QuickSort)**来解决这一问题。下面我将从问题分析、代码实现、及快速排序的核心思想进行详细说明。 题…...

Django模型优化
1、创建一个Django项目 可参考之前的带你快速体验Django web应用 我使用的是mysql数据库。按照上述教程完成准备工作。 2、创建一个app并完成注册 demo主要来完成创建用户、修改用户、查询用户、删除用户的操作。 python manage.py startapp test0023、app的目录 新建templ…...

Python实现火柴人的设计与实现
1.引言 火柴人(Stick Figure)是一种极简风格的图形,通常由简单的线段和圆圈组成,却能生动地表达人物的姿态和动作。火柴人不仅广泛应用于动画、漫画和涂鸦中,还可以作为图形学、人工智能等领域的教学和研究工具。本文…...
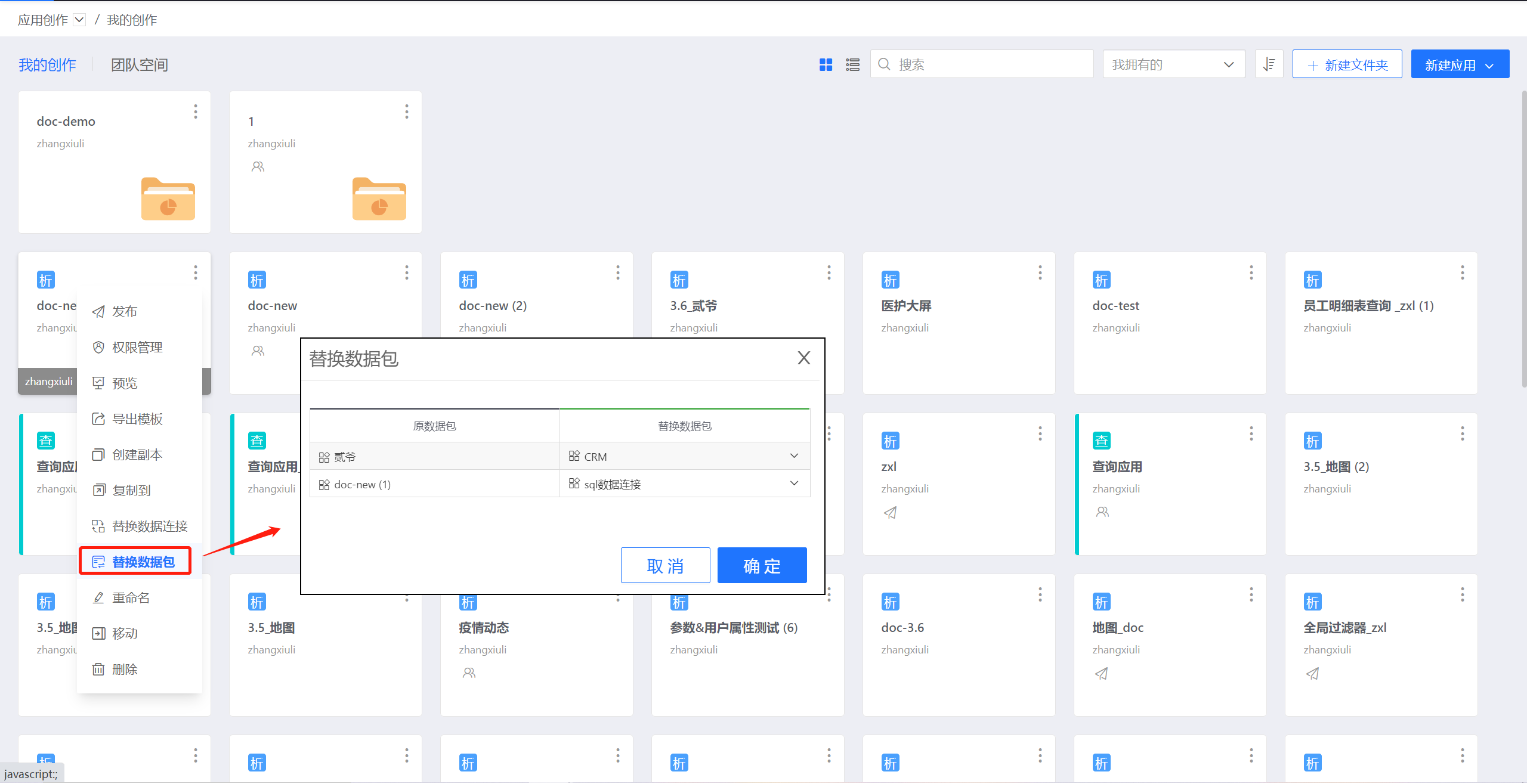
衡石分析平台系统分析人员手册-应用模版
应用模板 应用模板使分析成果能被快速复用,节省应用创作成本,提升应用创作效率。此外应用模板实现了应用在不同环境上快速迁移。 支持应用复制功能 用户可以从现有的分析成果关联到新的分析需求并快速完成修改。 支持应用导出为模板功能 实现多个用户…...

Git和SVN
一. Git和SVN的区别 1.1 Git是分布式的,SVN是集中式的 1.2 Git复杂概念多,SVN简单易上手 Git 的命令实在太多了,日常工作需要掌握 add, commit, status, fetch, push, rebase等,若要熟练掌握,还必须掌握 rebase和 m…...
宏与预处理 - <stddef.h> 和 <stdbool.h>)
【C语言教程】【常用类库】(十八)宏与预处理 - <stddef.h> 和 <stdbool.h>
18. 宏与预处理 - <stddef.h> 和 <stdbool.h> C语言的宏和预处理指令在程序编译之前就被执行,用于文件包含、符号定义、条件编译等操作。理解和运用宏和预处理可以提高代码的灵活性和可移植性。 18.1 宏定义与条件编译 18.1.1 #define 与参数化宏 #…...

订单超时过期的实现方案的探讨
在我们的业务开发中,会遇到这样一个场景,用户下了一个单,如果超过20分钟不进行支付,订单就要变成已取消状态。 字段设定 订单中需要设定了三个字段:订单是否取消、是否支付、支付超时时间。 订单是否取消会存在&…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

Hyper-V离散设备分配图形化解决方案:企业级虚拟化性能优化实践
Hyper-V离散设备分配图形化解决方案:企业级虚拟化性能优化实践 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 在数字化转…...

Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化
Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

DamaiHelper:大麦网演唱会抢票脚本终极指南
DamaiHelper:大麦网演唱会抢票脚本终极指南 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪演唱会门票而烦恼吗?面对秒光的票源和黄牛的高价,…...

Lilishop:基于Spring Boot3的B2B2C开源商城系统全解析
引言在数字化转型浪潮席卷各行各业的今天,电商系统已成为企业拓展线上业务的核心基础设施。然而,从零构建一套功能完备、性能卓越、可扩展的商城系统,不仅需要投入大量研发资源,还面临技术选型、架构设计、安全合规等诸多挑战。开…...

使用taotoken cli工具,一键为团队开发环境配置多模型api密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken cli工具,一键为团队开发环境配置多模型api密钥 在团队协作开发中,统一管理多个大模型API的密…...