Python爬虫进阶(实战篇一)
接,基础篇,链接:python爬虫入门(所有演示代码,均有逐行分析!)-CSDN博客
目录
1.爬取博客网站全部文章列表
ps:补充(正则表达式)
爬虫实现
爬虫代码:
2.爬取豆瓣电影top250榜
爬虫代码:
3.爬取北京天气十年数据
爬虫代码:
1.爬取博客网站全部文章列表
ps:补充(正则表达式)

PS:这里涉及到python基础语法中正则表达式的内容
课:第三阶段-09-正则表达式-基础方法_哔哩哔哩_bilibili
实例代码:
import reurl1 = "http://www.crazyant.net/1234.html"
url2 = "http://www.crazyant.net/1234.html#comments"
url3 = "http://www.baidu.com"pattern = r'^http://www.crazyant.net/\d+.html$'
#r;使\d这类转义字符作为一个整体出现,而不是分开的\+d的意思;\d表示一个十进制的数字 [0-9],\d+代表十进制的数字有多个print(re.match(pattern,url1)) #ok
print(re.match(pattern,url2)) #none
print(re.match(pattern,url3)) #none运行结果图:

爬虫实现
创建Python Package,命名为blog_test
在package下创建url_manager.py文件,用于存放url管理器模块代码
url管理器代码:
class UrlManager():'''url管理器'''def __init__(self):#定义一个初始化函数self.new_urls = set()#新的待爬取url的集合self.old_urls = set()#已爬取url的集合def add_new_url(self, url):#定义新增单个url的方法一,传一个参数urlif url is None or len(url) == 0:#判断url是否为空或长度为0return#符合上述条件就停止增加if url in self.new_urls or url in self.old_urls:#判断url是否已经被记录在集合里return#已经载集合里的url不新增self.new_urls.add(url)#上述干扰条件排除后,url就可以加入待爬取的集合中def add_new_urls(self,urls):#定义新增url的方法二,传一个参数urlsif urls is None or len(urls) == 0:#判断参数urls是否为空returnfor url in urls:#不为空就将单个url循环传入单个判断url方法中经行判断存储self.add_new_url(url)def get_url(self):#定义获取新url的函数if self.has_new_url():#如果存在待爬取的urlurl = self.new_urls.pop()#就将待爬取的url从集合中移除并返回self.old_urls.add(url)#将移除的url加入已爬取的集合中return url#并将其返回else:return Nonedef has_new_url(self):#定义一个判断url是否存在等待爬取的urlreturn len(self.new_urls) > 0#如果待爬取集合中有元素就分返回这个集合'''测试代码'''
if __name__ == "__main__":
#文件内置变量,仅在执行当前文件时可用。当此文件被调用时,此出变量不会被执行。因此测试代码时一般加上这句话url_manger = UrlManager()#调用整个类url_manger.add_new_url("url1")url_manger.add_new_urls(["url1", "url2"])#故意增加一个重复的urlprint(url_manger.new_urls, url_manger.old_urls)print("#" * 30)new_url = url_manger.get_url()print(url_manger.new_urls, url_manger.old_urls)print("#" * 30)new_url = url_manger.get_url()print(url_manger.new_urls, url_manger.old_urls)print("#" * 30)print(url_manger.has_new_url())在package下创建craw_all_pages.py文件,用于存放爬虫代码
爬虫代码:
import url_manager
import requests
from bs4 import BeautifulSoup
import reroot_url = "http://www.crazyant.net"urls = url_manager.UrlManager()
#引入之前的url管理器模块
urls.add_new_url(root_url)
#初始化url管理器fout = open("craw_all_pages.txt", "w", encoding="utf-8")
#初始化文件,打开文件定义为可写入模式while urls.has_new_url():
#如果有新的uelcurr_url = urls.get_url()#循环获取urlr = requests.get(curr_url, timeout=3)#爬取获取到的url,同时定义timeout=3,防止页面卡死if r.status_code != 200:#如果状态码不是200,print("error,return status_code is not 200", curr_url)#输出上面的句子,和当前的urlcontinuesoup = BeautifulSoup(r.text, "html.parser")#获取url的所有内容title = soup.title.string#soup.tite快速获取title节点,.string得到title里面的文字fout.write("%s\t%s\n" % (curr_url, title))# %s将字符串按照指定格式输出;\t:空格;\n:换行;%(curr_url, title)将前面的内容传入后面fout.flush()# 内存中的数据刷到磁盘里print("success:%s, %s, %d" % (curr_url, title, len(urls.new_urls)))links = soup.find_all("a")# 找到所有的a节点for link in links:href = link.get("href")# 获取href标签中的所有内容if href is None:# 如果href中没有内容continue# 跳过并继续执行pattern = r"^http://www.crazyant.net/\d+.html$"if re.match(pattern, href):#字符串匹配查找,看看href格式是否与我们所需数据格式一致urls.add_new_url(href)#将找到的href添加到fout.close()运行结果:

2.爬取豆瓣电影top250榜
爬取内容:榜单数,标题,评分和评价人数。
查看豆瓣250的url,可以看到每一页都不一样,间隔25,最后一页start=225


查找需要爬取的信息 :电影排行、电影名称、电影评分和评价人数。

爬虫代码:
1.使用requests爬取网页
2.使用BeautifulSoup实现数据解析
3.借助pandas将数据写出到Excel
import requests
from bs4 import BeautifulSoup
import pandas as pd
import pprint#构造分页数字列表
page_indexs = range(0, 250, 25) #从0开始到250,取不到250,每个25个数字取一个,形成一个可迭代的对象而不是列表
list(page_indexs) #构造列表
#需要将User-agent修改成自己的
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:131.0) Gecko/20100101 Firefox/131.0'
}def downlode_all_htmls():'''下载所有列表页面的HTML,用于后续的分析'''htmls = []for idx in page_indexs:url = f"http://movie.douban.com/top250?start={idx}&filter="print("craw html:",url)r = requests.get(url,headers=headers)if r.status_code != 200:raise Exception("error")htmls.append(r.text)return htmls
#执行爬取
htmls = downlode_all_htmls()def parse_single_html(html):'''解析单个HTML,得到数据@return list({"link","title",[label]})'''soup = BeautifulSoup(html, 'html.parser')#获取每个电影的信息article_items = (soup.find("div",class_="article").find("ol",class_="grid_view").find_all("div",class_="item"))datas = []for article_item in article_items:#排序数字rank = article_item.find("div",class_="pic").find("em").get_text()#分步实现,首先获取文章的infoinfo = article_item.find("div",class_="info")#然后获取标题title = info.find("div",class_="hd").find("span",class_="title").get_text()#获取五星评级、评分、评价人数,span有4个,所以使用find_allstars = (info.find("div",class_="bd").find("div",class_="star").find_all("span"))#星级为第一个spanrating_star = stars[0]["class"][0]#评分为第二个spanrating_num = stars[1].get_text()#评分人数为最后一个spancomments = stars[3].get_text()datas.append({"rank":rank,"title":title,"rating_star":rating_star.replace("rating","").replace("-t",""), #去掉前缀和后缀"rating_num":rating_num,"comments":comments.replace("人评价","") #把人评价去掉})return datas#pprint可以漂亮的打印数据
pprint.pprint(parse_single_html(htmls[0]))#执行所有的HTML页面的解析
all_datas = []
for html in htmls:all_datas.extend(parse_single_html(html))
print(all_datas)
print(len(all_datas))df = pd.DataFrame(all_datas)
print(df)
#这里想直接输出excel需要安装openpyxl库
df.to_excel("豆瓣电影TOP250.xlsx")3.爬取北京天气十年数据
爬取目标:http://tianqi.2345.com/wea_history/54511.htm
涉及技术:
headers中设置user agent反爬机制
通过network抓包,分析ajax的请求和参数
通过for循环请求不同的参数的数据
利用pandas实现excel的合并与保存
首先进入网站,更换年份、月份,发现网站地址没有改变


可以判断出,网页存在隐藏的步奏,需要对网页进行抓包操作
右键检查,选择网络(network),不关闭页面的同时,点击更改年份,抓包获取数据

点击获取到的数据,在请求头中找到Uer_Agent,也可以看到请求方式为get

查看请求参数

查看响应内容
 爬取网址
爬取网址 
爬虫代码:
import time
import requests
import pandas as pd
from numpy.random import random
import random#设置随机休眠时间,防止ip被禁
time.sleep(random.random()*3)url = "http://tianqi.2345.com/Pc/GetHistory"
#请求头,防拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.97 Safari/537.36 Core/1.116.454.400 QQBrowser/13.2.6134.400","Cookie":"Hm_lvt_a3f2879f6b3620a363bec646b7a8bcdd=1729388880; HMACCOUNT=52D6CD0BBA8BE5AD; Hm_lpvt_a3f2879f6b3620a363bec646b7a8bcdd=1729388945","Referer":"http://tianqi.2345.com/wea_history/54511.htm"
}def craw_table(year, month):"""提供年费烦恼和月份爬取对应的表格数据"""#将参数传过来params = {"areaInfo[areaId]": 54511,"areaInfo[areaType]": 2,"date[year]": year,"date[month]": month}resp = requests.get(url, headers=headers, params=params)data = resp.json()["data"]#解析网页中所有的表格,取第一个元素df = pd.read_html(data)[0]return dfdf_list = []
for year in range(2014, 2024):for month in range(1,13):print("爬取:",year, month)df = craw_table(year,month)df_list.append(df)pd.concat(df_list).to_excel("北京10年天气数据.xlsx",index=False)相关文章:
Python爬虫进阶(实战篇一)
接,基础篇,链接:python爬虫入门(所有演示代码,均有逐行分析!)-CSDN博客 目录 1.爬取博客网站全部文章列表 ps:补充(正则表达式) 爬虫实现 爬虫代码: 2.爬…...
)
运维面试题(2)
ssh服务(重点)协议使用 端口 号:默认是 22, 可以是被修改的,如果需要修改,则需要修改 ssh 服务的配置文件:#/etc/ssh/ssh_config,可以通过这个配置文件来修改端口 端口号可以修改&am…...

Django CSRF Token缺失或不正确
在Django中,CSRF(跨站请求伪造)验证失败,提示“CSRF token missing or incorrect”的错误,通常是由以下几个原因造成的: 忘记在表单中添加 {% csrf_token %} 模板标签:这是最常见的原因之一。确…...
)
10.12Python数学基础-矩阵(下)
9.矩阵的转置 矩阵的转置(Transpose)是矩阵操作中的一种基本运算。它通过交换矩阵的行和列来生成一个新的矩阵。具体来说,如果 A 是一个 mn 的矩阵,那么它的转置矩阵 A^T 是一个 nm 的矩阵,其中 A^T 的第 i 行第 j 列…...

vue网络自学知识点汇总
初体验 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title><!--1.引入vue.j…...
)
Springboot项目Activemq延迟自定义消息完整代码案例(亲测可用)
1、porm.xml增加依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-activemq</artifactId> </dependency> 2、application.properties增加配置 # 连接地址 spring.activemq.broker-url=fa…...
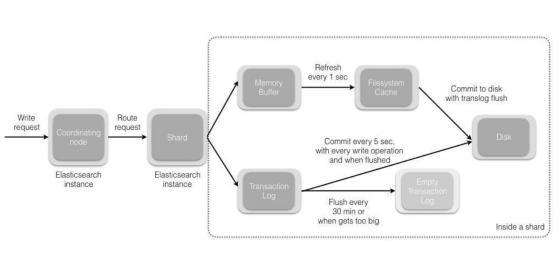
常见ElasticSearch 面试题解析(上)
前言 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch…...
训练VLM(视觉语言模型)的经验
知乎:lym 链接:https://zhuanlan.zhihu.com/p/890327005 如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包…...

犬儒乐队热歌《阶梯》主观
犬儒乐队一直以来是中国独立音乐界的一支重要力量。他们的音乐作品总是充满创意与实验,擅长将不同的音乐元素融合在一起,给人带来耳目一新的感受。最近,犬儒乐队发布了一首新歌《阶梯》,让我们一起来评价一下这首作品。 首先&…...

多模态大语言模型(MLLM)-Blip3/xGen-MM
论文链接:https://www.arxiv.org/abs/2408.08872 代码链接:https://github.com/salesforce/LAVIS/tree/xgen-mm 本次解读xGen-MM (BLIP-3): A Family of Open Large Multimodal Models 可以看作是 [1] Blip: Bootstrapping language-image pre-training…...

flutter TabBar自定义指示器(带文字的指示器、上弦弧形指示器、条形背景指示器、渐变色的指示器)
带文字的TabBar指示器 1.绘制自定义TabBar的绿色带白色文字的指示器 2.将底部灰色文字与TabrBar层叠,并调整高度位置与胶囊指示器重叠 自定义的带文字的TabBar指示器 import package:atui/jade/utils/JadeColors.dart; import package:flutter/material.dart; im…...

【Fargo】9:模拟图片采集的内存泄漏std::bad_alloc
std::bad_alloc 崩溃。这样的内存分配会导致内存耗尽 is simulating an image of size 640x480 with 3 bytes per pixel, resulting in an allocation of approximately 921,600 bytes (or around 900 KB) for each image. The error you’re encountering (std::bad_alloc) ty…...

c# 前端无插件打印导出实现方式
打印 打印导出分布页 model List<界面的数据模型类> using WingSoft; using Newtonsoft.Json; <style type"text/css">.modal-content {width: 800px;}.modal-body {height: 400px;} </style> <script type"text/javascript">$(…...

数组的初始化,参数传递,和求和
在自己做的这个C语言解释器中,数组的使用非常简便。下面小程序是一个例子。演示了数组的初始化,参数传递, 和求和。 all[] { WA12,OR8,CA54, ID4, MT4, WY3, NV6, UT6, AZ11, CO10, NM5, ND3,SD3,NE4, KS6, OK7,TX40, MN10, WI10,IA6, MO10,…...

初始JavaEE篇——多线程(1):Thread类的介绍与使用
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏:JavaEE 目录 创建线程 1、继承 Thread类 2、实现Runnable接口 3、使用匿名内部类 1)继承Thread类的匿名内部类 2)…...
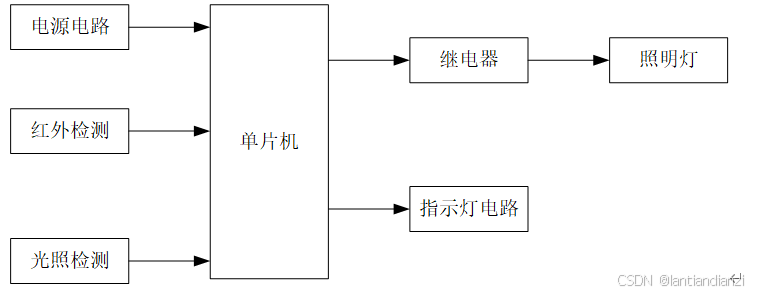
基于单片机的LED照明自动控制系统的设计
本设计主控核心芯片选用了AT89C51单片机,接入了光照采集模块、红外感应模块、继电器控制模块,通过控制发光二极管模拟教室智能灯组的控制。首先通过光敏感应的方式感应当前光照环境为白天还是夜晚,同时,红外感应模块感应是否有人。…...

C语言——头文件的使用
目录 前言头文件怎么包含 前言 这个专栏会专门讲一些C语言的知识,后续会慢慢更新,欢迎关注 C语言专栏 头文件怎么包含 在使用头文件的过程中,我们经常会遇到重定义、重复包含等问题,那么怎么编写头文件和使用头文件才能解决这些…...

LeetCode 精选 75 回顾
目录 一、数组 / 字符串 1.交替合并字符串 (简单) 2.字符串的最大公因子 (简单) 3.拥有最多糖果的孩子(简单) 4.种花问题(简单) 5.反转字符串中的元音字母(简单&a…...

【Unity - 屏幕截图】技术要点
在Unity中想要实现全屏截图或者截取某个对象区域的图片都是可以通过下面的函数进行截取 Texture2D/// <summary>/// <para>Reads the pixels from the current render target (the screen, or a RenderTexture), and writes them to the texture.</para>/…...

句句深刻,字字经典,创客匠人老蒋金句出炉,哪一句让你醍醐灌顶?
注意力经济时代、流量经济时代、短视频经济时代,创始人到底应该如何做,才能抓住风口,链接未来? 「创始人IP创新增长班」线下大课现场,老蒋作为主讲导师,再一次用他丰富的行业经验与深刻的时代洞察ÿ…...

5种方法提升研究效率:Zotero Reading List让文献管理不再繁琐
5种方法提升研究效率:Zotero Reading List让文献管理不再繁琐 【免费下载链接】zotero-reading-list Keep track of whether youve read items in Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-reading-list 在学术研究中,文献管理…...

ComfyUI-FramePackWrapper模型加载技术选型指南:提升效率的实战策略
ComfyUI-FramePackWrapper模型加载技术选型指南:提升效率的实战策略 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 在AI视频创作领域,模型加载是启动创作流程的关键环节&am…...

Winhance中文版:3大模块全面提升Windows使用体验
Winhance中文版:3大模块全面提升Windows使用体验 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_CN …...

胡桃工具箱:原神玩家的全能桌面助手与数据管理神器
胡桃工具箱:原神玩家的全能桌面助手与数据管理神器 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hutao …...

PlayStation手柄Windows兼容性解决方案:DS4Windows深度解析与实践指南
PlayStation手柄Windows兼容性解决方案:DS4Windows深度解析与实践指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 对于希望在Windows PC上使用PlayStation手柄的游戏玩家来…...

Kandinsky-5.0-I2V-Lite-5s多模型对比:与同类I2V模型的生成效果横向评测
Kandinsky-5.0-I2V-Lite-5s多模型对比:与同类I2V模型的生成效果横向评测 1. 开场白:为什么需要关注图像转视频技术 想象一下这样的场景:你手头有一张精美的产品静物照片,如果能让它动起来展示360度视角,转化率会不会…...
)
5分钟学会用PHPStudy搭建Pikachu靶场(含一句话木马实战)
5分钟实战:用PHPStudy快速搭建Pikachu靶场与一句话木马攻防演练 在网络安全领域,动手实践往往比理论阅读更能快速提升技能。本文将带您完成一次完整的本地环境搭建与基础渗透测试演练——从零开始配置PHPStudy环境、部署Pikachu靶场,到实战演…...

Superset报表与告警的深度配置与自适应截图二次开发
1. Superset报表与告警的核心配置解析 第一次接触Superset的报表和告警功能时,我被它的自动化能力惊艳到了。想象一下,每天早上咖啡还没喝完,关键业务指标的日报就已经整整齐齐地躺在邮箱里;当数据异常时,Slack消息比运…...

OpenClaw成本优化:Qwen3.5-9B-AWQ-4bit量化模型长期运行实测
OpenClaw成本优化:Qwen3.5-9B-AWQ-4bit量化模型长期运行实测 1. 为什么关注量化模型与OpenClaw的适配性 第一次用OpenClaw执行图片处理任务时,我的MacBook Pro风扇狂转的噪音让我意识到问题的严重性——原版Qwen3.5-9B模型在连续处理20张产品截图后&am…...

OpenClaw+Qwen2.5-VL-7B:低成本自动化学习助手
OpenClawQwen2.5-VL-7B:低成本自动化学习助手 1. 为什么需要自动化学习助手 作为一个经常需要处理大量学习资料的开发者,我一直在寻找能够提升学习效率的工具。传统的学习方式需要手动整理资料、做笔记、制作练习题,这些重复性工作不仅耗时…...