训练VLM(视觉语言模型)的经验
知乎:lym
链接:https://zhuanlan.zhihu.com/p/890327005

如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包括时间成本。
基于prompt确实不行(情况包括格式输出不稳定、格式输出基本不对、任务不完全会、任务完全不会等情况,难度逐渐加大),选择上SFT微调。
业务场景基本用不到强化学习,强化解决的是最后一公里的问题,可以理解为有两种非常接近的输出(这两种输出都非常接近目标输出,此时已经解决了90%的问题),强化学习会对相同的输入,打压其中一种不希望的输出,同时增强另一种更接近目标的希望的输出(从DPO loss就可以看出)。强化是用来应对细微输出差异的,并且业务场景优先用DPO,DPO只需要pair对数据,更好构造。PPO的reward model几乎没有开源的,需要的数据更多,超参也更多,除非是逻辑或代码场景,在文本场景中,DPO效果是足够的。
业务数据质量最重要,数据量也不能少,越难的任务数据量越多
数据内容:要尽量和期望输出一致,这个一致既包括内容,也包括格式。不要期望垃圾数据能训练出好的VLM模型,不要寄希望于dalle3那种recaptioning,依靠泛化能力变换格式的玩法太高级了,我还把我不住。可以用 手工标注数据+GPT改写(甚至可以是Vision版本) 生成质量尽可能高的业务数据。改写用的GPT原本没有解决对应任务的能力也不要怕,在改写的prompt模板让它参考人工标注就行。
数据量:如果模型会该类任务,但仅是输出格式不稳定(比如json少个括号,文本输出少个\n什么的),几十到上百条业务数据就够了,不用考虑通用数据;一般普通业务需要千条业务数据(类似数据在VLM模型预训练的训练集出现过,但模型对于该任务处于会与不会区间),需要少量通用数据(10:1,1份通用)。如果特别难的task,VLM模型根本没见过(比如文生图生成数据,输出的文本也和输入图之间的关系需要重学),那需要1-2w条业务数据,通用数据5:1。
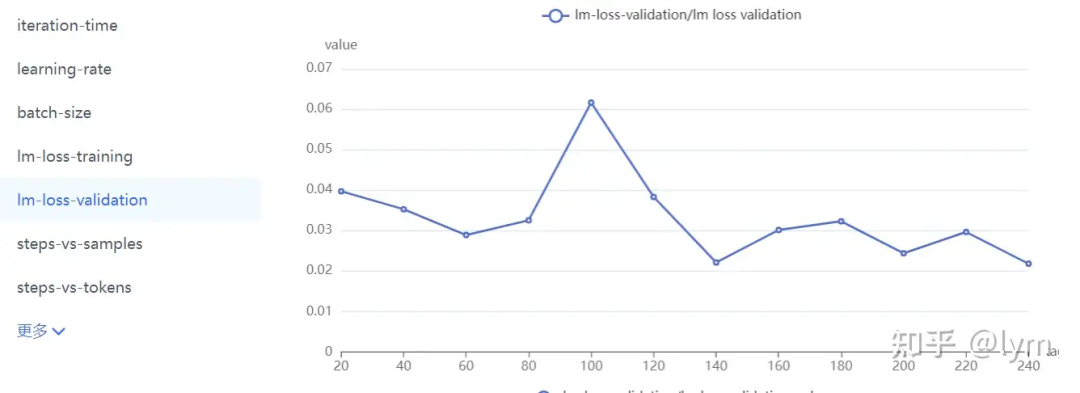
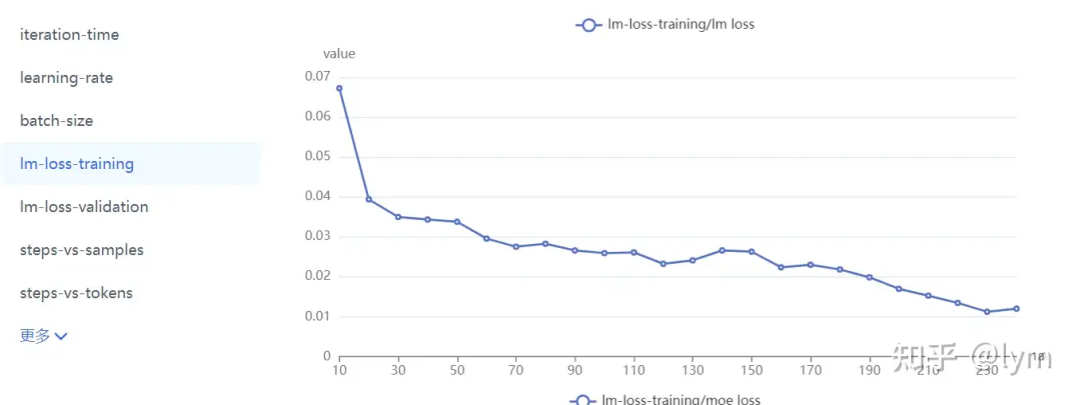
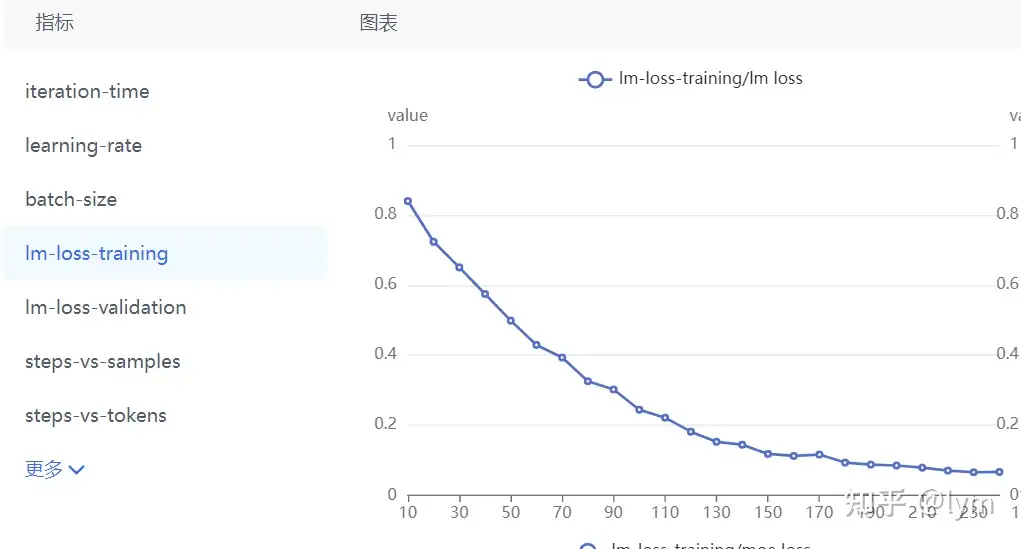
训练轮次:我训练的task就特别难,4B左右的模型甚至训练10个epoch测试集的loss还在下降。但是一般7B模型训5个epoch,70B模型训练2个epoch,就会开始过拟合了。下面是比较正常的收敛曲线。


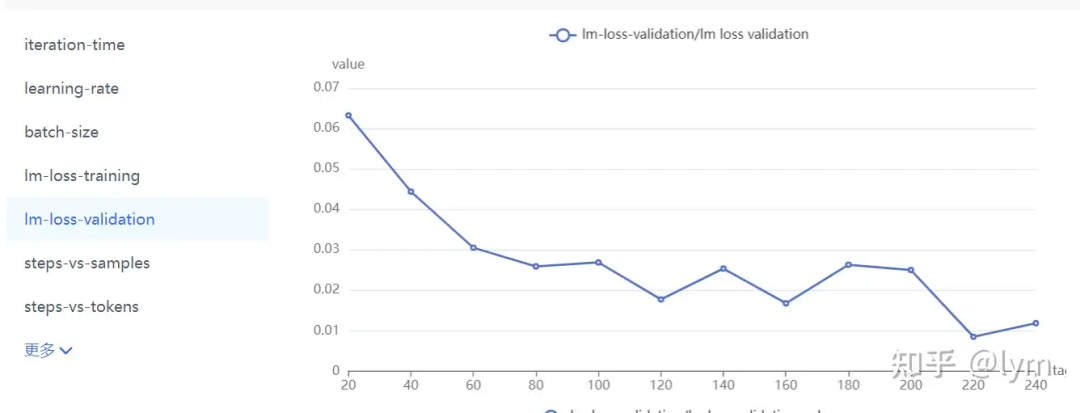
当然还有些肯定不正确的曲线:


数据难度:可以用PPL衡量,也可以看训练集上测试的效果。
多个类型数据:先各自训练看效果,确保各自没有问题,再去混合。
训练流程
-
收集清洗改写增强广业务数据,同一个问题可以除了文本对话,还可以改写成选择判断,有帮助,而且这些形式更容易做评测,方便确认效果。
-
磨刀不误砍柴工:找一个小的VLM模型(2B~7B),按照默认微调参数对纯业务数据集上进行训练,设置较高的lr(1e-5)和较长的epoch(10轮)。训练好的模型在训练集上先测试(对,用什么训练用什么测!)。在训练集上进行测试是非常重要的,它可以一定程度排除数据集质量的问题,也不用担心过拟合的问题,同时也能确保框架底层没什么问题。别管数据质量多垃圾,别管在测试集泛化性有多差,在训练集上都应该有较好的学习效果。如果你的业务数据有多种形式,也可以在这个阶段进行配比的消融。
-
确保在训练集上没问题,再结合validation集上的曲线,应该可以大致确认:训练轮次(epoch)、业务数据配比、学习率、batch_size、文本长度、moe专家数量、并行配置(tp pp dp)等绝大部分超参。
PS:在VLM训练中,无论是预训练、对齐还是精调,用的都是SFT loss,没有Pretrain loss。学界可能比较喜欢用lora,但工业届全量调的更多,这俩区别不是很大,lora dim设置成128/256,scaling设置成64(dim的05倍),也能学很多东西。
如果只是输出格式不满意、不稳定,那么调LLM就够。如果全新的知识,那么vit和LLM以及二者间的中间层都放开比较好。参数量的大头在LLM中,但如果图片业务数据和预训练数据差异较大,vit放开也很重要。(上vit冻住,下vit放开,vit解冻后明显收敛更稳定)。我的任务比较难,肯定就是全放开训练了。

往里面加入通用数据,来维护原有通用能力(在业务垂域没搞明白前,一般先别考虑通用数据,否则变量太多,把握不住)。配比从10:1开始,不行可以试试5:1。通用数据包括两种,一种是caption,一种是instruct数据。caption数据的question基本都是”详细描述图中有什么?“,它在VLM预训练中是用来做一阶段的。Instruct数据的question就比较多样了,比如”图中叉子右边的茶杯是什么颜色的?“它一般对应预训练的二阶段微调。VLM这两个阶段虽然一阶段叫训练,二阶段叫对齐,但是loss形式是一样的,超参可能也只有学习率的差异,越往后学习率越小。全用instruct数据问题也不大,但instruct数据可能信息量可能不如caption对图片描述那么丰富,也更难收集一些。
caption的数据我翻译了些sharegpt4o的,整理好了:
https://huggingface.co/datasets/LYM2024/share_gpt4o_zh?row=0
instruct数据用的ALLAVA-4V的,量太大了翻译的还没整理好。
https://huggingface.co/datasets/FreedomIntelligence/ALLaVA-4V
这俩我是1:1用的,没做严格消融。英文数据去llamafactory找就行,中文大部分得自己动手翻译。通用 数据也可以大量用英文,融合一点自己翻译的中文,效果也不会太差的。
然后我发现个特别有意思的现象,我的业务数据是diffusion生成的图片,上面这些数据是自然图片,业务数据的通用能力几乎没有被维护。解决方案:
-
用现有VLM对业务数据作captioning,因为caption的question与图无关,直接取sharegpt40的就行。直接生成大量业务图片的通用数据。
-
用LCM的SSD或SDXL模型做Img2Img,把正prompt置空,guidance_scale置0(最好negative输出的embedding取torch.zeros),strength强度设置0.025。用无引导生成生成有diffusion特征的图片。
-
训练可以分多个阶段,前面用质量差一点的大量数据,后面用质量高的小批量数据,提升最终效果。两阶段question的词汇可以作下隔离,即这两批数据的question最好有点小差异,后续推理测试只用高质量数据的question。实测高质量数据的需求大会大大降低。
-
我个人觉得,精调这种任务,如果数据量大,在7B小模型和72B大模型上,在业务(垂域)上效果差异并不大,因为我们一般更关心业务和垂域的性能,而非要成为全面的通才。
-
数据质量高可以训练久一些,数据质量差训练短一些,可以保留更好的泛化性。我们的数据比较短,训练10epoch的话,输出就非常短,往往不带主语。训练6epoch就会带一些,所以不是validation loss下降就是好事,它可能同时对应着通用loss的上升,稍微遇到些长尾问题,性能就会崩溃式下降。训练太短也不行,容易学不会,至少要保证训练5epoch,看看整体的结果。
知乎:lym
链接:https://zhuanlan.zhihu.com/p/890327005
如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包括时间成本。
基于prompt确实不行(情况包括格式输出不稳定、格式输出基本不对、任务不完全会、任务完全不会等情况,难度逐渐加大),选择上SFT微调。
业务场景基本用不到强化学习,强化解决的是最后一公里的问题,可以理解为有两种非常接近的输出(这两种输出都非常接近目标输出,此时已经解决了90%的问题),强化学习会对相同的输入,打压其中一种不希望的输出,同时增强另一种更接近目标的希望的输出(从DPO loss就可以看出)。强化是用来应对细微输出差异的,并且业务场景优先用DPO,DPO只需要pair对数据,更好构造。PPO的reward model几乎没有开源的,需要的数据更多,超参也更多,除非是逻辑或代码场景,在文本场景中,DPO效果是足够的。
业务数据质量最重要,数据量也不能少,越难的任务数据量越多
数据内容:要尽量和期望输出一致,这个一致既包括内容,也包括格式。不要期望垃圾数据能训练出好的VLM模型,不要寄希望于dalle3那种recaptioning,依靠泛化能力变换格式的玩法太高级了,我还把我不住。可以用 手工标注数据+GPT改写(甚至可以是Vision版本) 生成质量尽可能高的业务数据。改写用的GPT原本没有解决对应任务的能力也不要怕,在改写的prompt模板让它参考人工标注就行。
数据量:如果模型会该类任务,但仅是输出格式不稳定(比如json少个括号,文本输出少个\n什么的),几十到上百条业务数据就够了,不用考虑通用数据;一般普通业务需要千条业务数据(类似数据在VLM模型预训练的训练集出现过,但模型对于该任务处于会与不会区间),需要少量通用数据(10:1,1份通用)。如果特别难的task,VLM模型根本没见过(比如文生图生成数据,输出的文本也和输入图之间的关系需要重学),那需要1-2w条业务数据,通用数据5:1。
训练轮次:我训练的task就特别难,4B左右的模型甚至训练10个epoch测试集的loss还在下降。但是一般7B模型训5个epoch,70B模型训练2个epoch,就会开始过拟合了。下面是比较正常的收敛曲线。
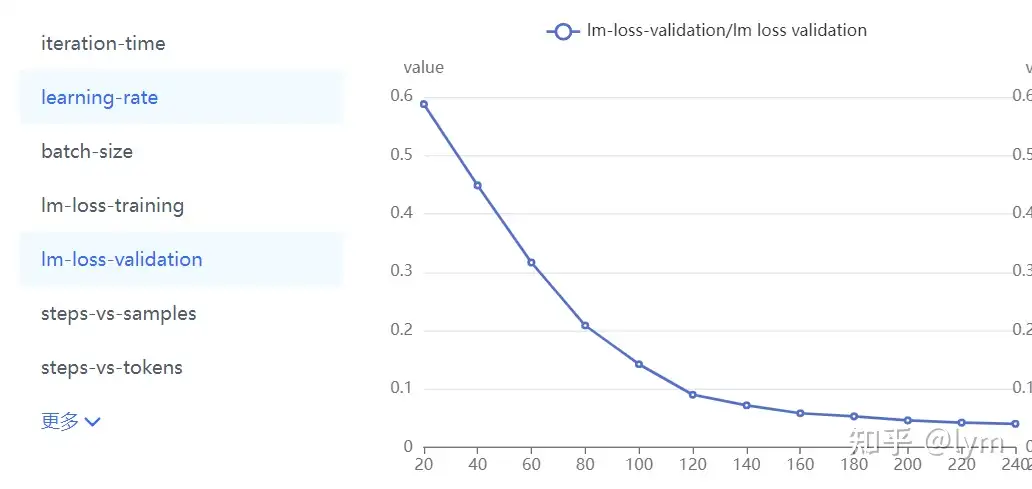
当然还有些肯定不正确的曲线:
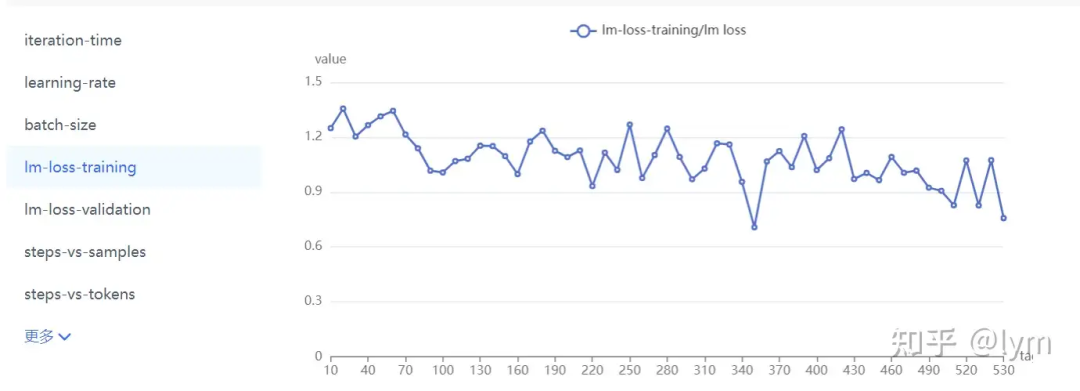
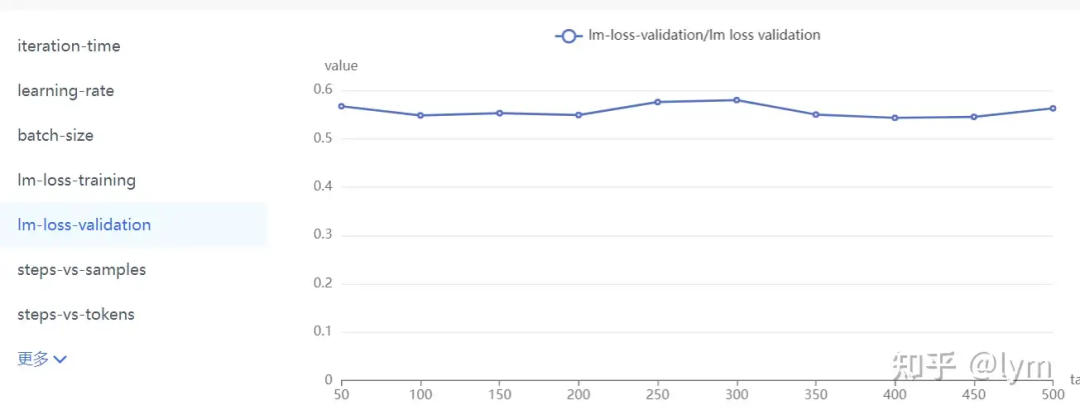
数据难度:可以用PPL衡量,也可以看训练集上测试的效果。
多个类型数据:先各自训练看效果,确保各自没有问题,再去混合。
训练流程
-
收集清洗改写增强广业务数据,同一个问题可以除了文本对话,还可以改写成选择判断,有帮助,而且这些形式更容易做评测,方便确认效果。
-
磨刀不误砍柴工:找一个小的VLM模型(2B~7B),按照默认微调参数对纯业务数据集上进行训练,设置较高的lr(1e-5)和较长的epoch(10轮)。训练好的模型在训练集上先测试(对,用什么训练用什么测!)。在训练集上进行测试是非常重要的,它可以一定程度排除数据集质量的问题,也不用担心过拟合的问题,同时也能确保框架底层没什么问题。别管数据质量多垃圾,别管在测试集泛化性有多差,在训练集上都应该有较好的学习效果。如果你的业务数据有多种形式,也可以在这个阶段进行配比的消融。
-
确保在训练集上没问题,再结合validation集上的曲线,应该可以大致确认:训练轮次(epoch)、业务数据配比、学习率、batch_size、文本长度、moe专家数量、并行配置(tp pp dp)等绝大部分超参。
PS:在VLM训练中,无论是预训练、对齐还是精调,用的都是SFT loss,没有Pretrain loss。学界可能比较喜欢用lora,但工业届全量调的更多,这俩区别不是很大,lora dim设置成128/256,scaling设置成64(dim的05倍),也能学很多东西。
如果只是输出格式不满意、不稳定,那么调LLM就够。如果全新的知识,那么vit和LLM以及二者间的中间层都放开比较好。参数量的大头在LLM中,但如果图片业务数据和预训练数据差异较大,vit放开也很重要。(上vit冻住,下vit放开,vit解冻后明显收敛更稳定)。我的任务比较难,肯定就是全放开训练了。
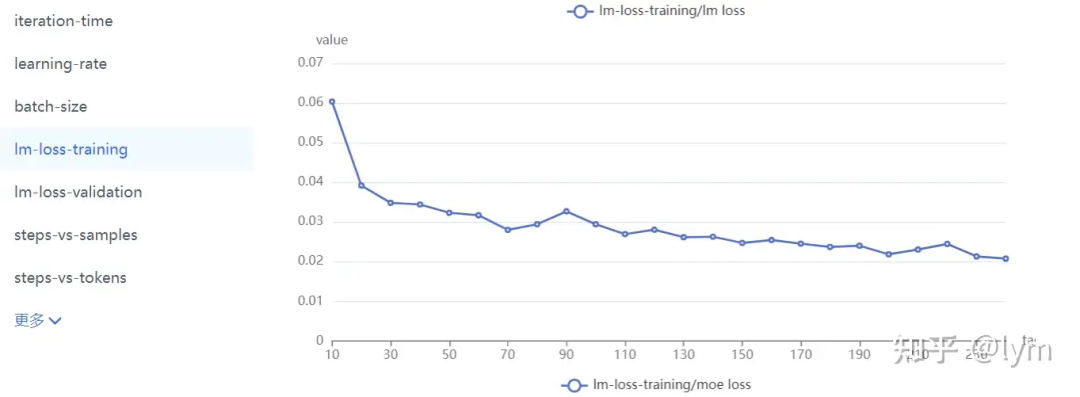
往里面加入通用数据,来维护原有通用能力(在业务垂域没搞明白前,一般先别考虑通用数据,否则变量太多,把握不住)。配比从10:1开始,不行可以试试5:1。通用数据包括两种,一种是caption,一种是instruct数据。caption数据的question基本都是”详细描述图中有什么?“,它在VLM预训练中是用来做一阶段的。Instruct数据的question就比较多样了,比如”图中叉子右边的茶杯是什么颜色的?“它一般对应预训练的二阶段微调。VLM这两个阶段虽然一阶段叫训练,二阶段叫对齐,但是loss形式是一样的,超参可能也只有学习率的差异,越往后学习率越小。全用instruct数据问题也不大,但instruct数据可能信息量可能不如caption对图片描述那么丰富,也更难收集一些。
caption的数据我翻译了些sharegpt4o的,整理好了:
https://huggingface.co/datasets/LYM2024/share_gpt4o_zh?row=0
instruct数据用的ALLAVA-4V的,量太大了翻译的还没整理好。
https://huggingface.co/datasets/FreedomIntelligence/ALLaVA-4V
这俩我是1:1用的,没做严格消融。英文数据去llamafactory找就行,中文大部分得自己动手翻译。通用 数据也可以大量用英文,融合一点自己翻译的中文,效果也不会太差的。
然后我发现个特别有意思的现象,我的业务数据是diffusion生成的图片,上面这些数据是自然图片,业务数据的通用能力几乎没有被维护。解决方案:
-
用现有VLM对业务数据作captioning,因为caption的question与图无关,直接取sharegpt40的就行。直接生成大量业务图片的通用数据。
-
用LCM的SSD或SDXL模型做Img2Img,把正prompt置空,guidance_scale置0(最好negative输出的embedding取torch.zeros),strength强度设置0.025。用无引导生成生成有diffusion特征的图片。
-
训练可以分多个阶段,前面用质量差一点的大量数据,后面用质量高的小批量数据,提升最终效果。两阶段question的词汇可以作下隔离,即这两批数据的question最好有点小差异,后续推理测试只用高质量数据的question。实测高质量数据的需求大会大大降低。
-
我个人觉得,精调这种任务,如果数据量大,在7B小模型和72B大模型上,在业务(垂域)上效果差异并不大,因为我们一般更关心业务和垂域的性能,而非要成为全面的通才。
-
数据质量高可以训练久一些,数据质量差训练短一些,可以保留更好的泛化性。我们的数据比较短,训练10epoch的话,输出就非常短,往往不带主语。训练6epoch就会带一些,所以不是validation loss下降就是好事,它可能同时对应着通用loss的上升,稍微遇到些长尾问题,性能就会崩溃式下降。训练太短也不行,容易学不会,至少要保证训练5epoch,看看整体的结果。
相关文章:
训练VLM(视觉语言模型)的经验
知乎:lym 链接:https://zhuanlan.zhihu.com/p/890327005 如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包…...

犬儒乐队热歌《阶梯》主观
犬儒乐队一直以来是中国独立音乐界的一支重要力量。他们的音乐作品总是充满创意与实验,擅长将不同的音乐元素融合在一起,给人带来耳目一新的感受。最近,犬儒乐队发布了一首新歌《阶梯》,让我们一起来评价一下这首作品。 首先&…...

多模态大语言模型(MLLM)-Blip3/xGen-MM
论文链接:https://www.arxiv.org/abs/2408.08872 代码链接:https://github.com/salesforce/LAVIS/tree/xgen-mm 本次解读xGen-MM (BLIP-3): A Family of Open Large Multimodal Models 可以看作是 [1] Blip: Bootstrapping language-image pre-training…...

flutter TabBar自定义指示器(带文字的指示器、上弦弧形指示器、条形背景指示器、渐变色的指示器)
带文字的TabBar指示器 1.绘制自定义TabBar的绿色带白色文字的指示器 2.将底部灰色文字与TabrBar层叠,并调整高度位置与胶囊指示器重叠 自定义的带文字的TabBar指示器 import package:atui/jade/utils/JadeColors.dart; import package:flutter/material.dart; im…...

【Fargo】9:模拟图片采集的内存泄漏std::bad_alloc
std::bad_alloc 崩溃。这样的内存分配会导致内存耗尽 is simulating an image of size 640x480 with 3 bytes per pixel, resulting in an allocation of approximately 921,600 bytes (or around 900 KB) for each image. The error you’re encountering (std::bad_alloc) ty…...

c# 前端无插件打印导出实现方式
打印 打印导出分布页 model List<界面的数据模型类> using WingSoft; using Newtonsoft.Json; <style type"text/css">.modal-content {width: 800px;}.modal-body {height: 400px;} </style> <script type"text/javascript">$(…...

数组的初始化,参数传递,和求和
在自己做的这个C语言解释器中,数组的使用非常简便。下面小程序是一个例子。演示了数组的初始化,参数传递, 和求和。 all[] { WA12,OR8,CA54, ID4, MT4, WY3, NV6, UT6, AZ11, CO10, NM5, ND3,SD3,NE4, KS6, OK7,TX40, MN10, WI10,IA6, MO10,…...

初始JavaEE篇——多线程(1):Thread类的介绍与使用
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏:JavaEE 目录 创建线程 1、继承 Thread类 2、实现Runnable接口 3、使用匿名内部类 1)继承Thread类的匿名内部类 2)…...
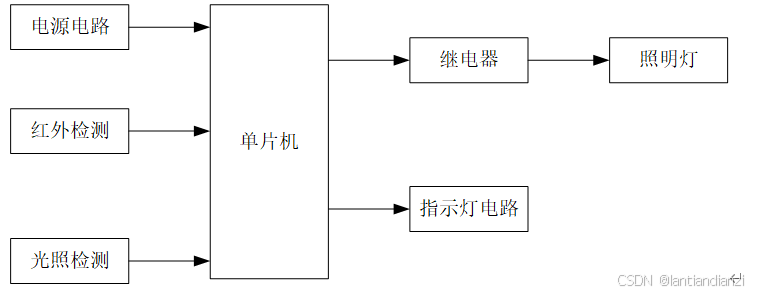
基于单片机的LED照明自动控制系统的设计
本设计主控核心芯片选用了AT89C51单片机,接入了光照采集模块、红外感应模块、继电器控制模块,通过控制发光二极管模拟教室智能灯组的控制。首先通过光敏感应的方式感应当前光照环境为白天还是夜晚,同时,红外感应模块感应是否有人。…...

C语言——头文件的使用
目录 前言头文件怎么包含 前言 这个专栏会专门讲一些C语言的知识,后续会慢慢更新,欢迎关注 C语言专栏 头文件怎么包含 在使用头文件的过程中,我们经常会遇到重定义、重复包含等问题,那么怎么编写头文件和使用头文件才能解决这些…...

LeetCode 精选 75 回顾
目录 一、数组 / 字符串 1.交替合并字符串 (简单) 2.字符串的最大公因子 (简单) 3.拥有最多糖果的孩子(简单) 4.种花问题(简单) 5.反转字符串中的元音字母(简单&a…...

【Unity - 屏幕截图】技术要点
在Unity中想要实现全屏截图或者截取某个对象区域的图片都是可以通过下面的函数进行截取 Texture2D/// <summary>/// <para>Reads the pixels from the current render target (the screen, or a RenderTexture), and writes them to the texture.</para>/…...

句句深刻,字字经典,创客匠人老蒋金句出炉,哪一句让你醍醐灌顶?
注意力经济时代、流量经济时代、短视频经济时代,创始人到底应该如何做,才能抓住风口,链接未来? 「创始人IP创新增长班」线下大课现场,老蒋作为主讲导师,再一次用他丰富的行业经验与深刻的时代洞察ÿ…...

柯尼卡美能达CA-310 FPD色彩分析仪
柯尼卡美能达CA-310 FPD色彩分析仪 型 号:CA-310 名 称:FPD色彩分析仪 品 牌:柯尼卡美能达(KONICA MINOLTA) 分 类:光学和色彩测试 > 光学、显示与色彩测量 > 色彩分析仪 产品属性:主机 简 述&…...

二维EKF的MATLAB代码
EKF二维滤波 MATLAB 实现 提升您的数据处理能力!本MATLAB程序实现了扩展卡尔曼滤波(EKF)在二维状态估计中的应用,专为需要高精度定位和动态系统分析的用户设计。通过精确的滤波技术,有效减少噪声影响,确保…...

大数据治理:数据时代的挑战与应对
目录 大数据治理:数据时代的挑战与应对 一、大数据治理的概念与内涵 二、大数据治理的重要性 1. 提高数据质量与可用性 2. 确保数据安全与合规 3. 支持数据驱动的决策 4. 提高业务效率与竞争力 三、大数据治理的实施策略 1. 建立健全的数据治理框架 2. 数…...

绿联NAS免驱安装MacOS
前段时间UGOS Pro迎来了一次大更新,Docker新增了Docker Compose堆栈项目,于是便在Docker Hub找了个支持Docker Compose部署的MacOS开源项目来验证一下,顺便体验一下用N100运行是什么感觉。 开始折腾 先说说,在没用Docker Compos…...

聊聊ASSERT处理在某些场景下的合理用法
先看看ASSERT的介绍: 编写代码时,我们总是会做出一些假设,ASSERT断言就是用于在代码中捕捉这些假设,可以将断言看作是异常处理的一种高级形式。断言表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真…...

SAP Odata 服务
参考过程 SAP创建ODATA服务-Structure_sap odata-CSDN博客 案例...

【java数据结构】栈
【java数据结构】栈 一、栈的概念二、 栈的使用三、 栈的模拟实现(数组)构造方法size()empty()push()pop()peek() 四、 栈的模拟实现(链表)构造方法size()empty()push()pop()peek() 五、 栈的例题 此篇博客希望对你有所帮助(帮助你了解栈),不…...

零基础学AI,从入门到上手,看这一篇就够了
零基础学习AI的路径规划学习AI需要从基础数学、编程语言开始,逐步深入机器学习和深度学习。以下路径适合完全零基础的学习者。数学基础 线性代数、概率统计和微积分是AI的核心数学工具。线性代数涉及矩阵运算,概率统计帮助理解数据分布,微积分…...

3个步骤掌握RPGMakerDecrypter:高效解密RPG Maker游戏资源
3个步骤掌握RPGMakerDecrypter:高效解密RPG Maker游戏资源 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/…...

跨搜索引擎图像批量采集工具的技术实现与应用实践
跨搜索引擎图像批量采集工具的技术实现与应用实践 【免费下载链接】Image-Downloader Download images from Google, Bing, Baidu. 谷歌、百度、必应图片下载. 项目地址: https://gitcode.com/gh_mirrors/im/Image-Downloader 在数据驱动的研究与开发中,高质…...

春联生成模型-中文-base入门必看:Python3.10+Gradio6环境部署详解
春联生成模型-中文-base入门必看:Python3.10Gradio6环境部署详解 想用AI写一副独一无二的春联,却不知道从何下手?今天,我就带你从零开始,手把手部署一个能自动生成春联的AI模型。这个模型叫“春联生成模型-中文-base”…...

如何用5分钟将模糊图片变成高清矢量图:Vectorizer完全指南
如何用5分钟将模糊图片变成高清矢量图:Vectorizer完全指南 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer 你是否曾遇到过这样的烦…...

NCM格式转换全攻略:3步解锁网易云音乐文件自由播放
NCM格式转换全攻略:3步解锁网易云音乐文件自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否遇到过下载的网易云音乐NCM文件无法在车载音响、MP3播放器等设备播放的问题?ncmdump作为一款高效的NC…...

无需代码!李慕婉-仙逆-造相Z-Turbo快速上手:输入文字秒出动漫图
无需代码!李慕婉-仙逆-造相Z-Turbo快速上手:输入文字秒出动漫图 1. 什么是李慕婉-仙逆-造相Z-Turbo 如果你是一位《仙逆》小说迷,或者喜欢动漫风格的人物创作,那么这个工具可能会让你眼前一亮。李慕婉-仙逆-造相Z-Turbo是一个专…...
)
科研协作新姿势:团队共用Word写论文,如何用Bibtex4Word插件统一参考文献库?(附Texlive2024配置)
科研团队高效协作:基于Bibtex4Word的参考文献统一管理方案 引言:团队协作中的文献管理痛点 在科研团队撰写论文或项目报告时,参考文献管理往往成为效率黑洞。想象这样的场景:三位合作者分别负责不同章节,A使用EndNote插…...

OpenClaw+百川2-13B-4bits量化模型:个人知识管理自动化方案
OpenClaw百川2-13B-4bits量化模型:个人知识管理自动化方案 1. 为什么需要自动化知识管理 作为一个长期与技术文档打交道的开发者,我的知识库在过去三年膨胀到了2000篇杂乱无章的Markdown文件。每次查找资料时,要么记不清文件名,…...

SecGPT-14B长文本处理:OpenClaw自动分割大型日志文件
SecGPT-14B长文本处理:OpenClaw自动分割大型日志文件 1. 问题背景与挑战 上周排查服务器问题时,我遇到了一个典型的技术困境:需要分析一个12GB的Nginx访问日志文件,但SecGPT-14B模型的上下文窗口仅有32K tokens。这种"大象…...