多模态大语言模型(MLLM)-Blip3/xGen-MM
论文链接:https://www.arxiv.org/abs/2408.08872
代码链接:https://github.com/salesforce/LAVIS/tree/xgen-mm
本次解读xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
可以看作是
[1] Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
[2] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
的后继版本
前言

没看到Blip和Blip2的一作Junnan Li,不知道为啥不参与Blip3
整体pipeline服从工业界的一贯做法,加数据,加显卡,模型、训练方式简单,疯狂scale up
创新点
- 开源模型在模型权重、训练数据、训练方法上做的不好
- Blip2用的数据不够多、质量不够高;Blip2用的Q-Former、训练Loss不方便scale up;Blip2仅支持单图输入,不支持多图输入
- Blip3收集超大规模数据集,并且用相对简单的训练方式,实现多图、文本的交互。
- 开放两个数据集:BLIP3-OCR-200M(大规模OCR标注数据集),BLIP3-GROUNDING-50M(大规模visual grounding数据集)
具体细节
模型结构
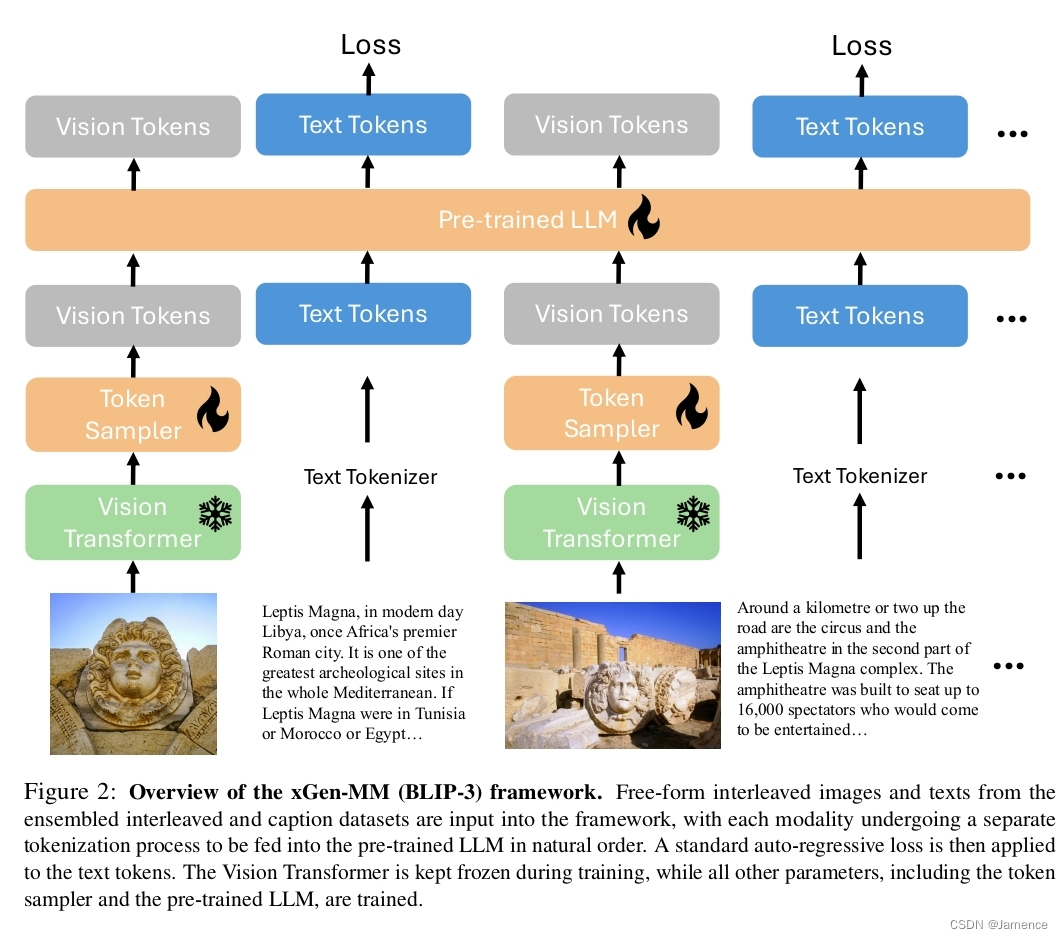
整体结构非常简单
- 图像经过ViT得到patch embedding,再经过token sampler得到vision token。(先经过Token Sampler,得到视觉embedding,而后经过VL connector,得到vision token)
- 文本通过tokenizer获得text token
- 文本、图像输入均送到LLM中,并且仅对本文加next prediction loss
- 注意:ViT参数冻结,其他参数可训练
- 注意:支持图像和文本交替输入,支持多图,任意分辨率图像
- ViT:所用模型有DFN、SigLIP,在不同任务上,效果不同,如下:

- LLM:所用模型为phi3-mini
- 模型结构代码见https://github.com/salesforce/LAVIS/blob/xgen-mm/open_flamingo/src/factory.py
- token Sampler代码见https://github.com/salesforce/LAVIS/blob/xgen-mm/open_flamingo/src/vlm.py
- VL connector代码见https://github.com/salesforce/LAVIS/blob/xgen-mm/open_flamingo/src/helpers.py
Token Sampler
详见博客https://blog.csdn.net/weixin_40779727/article/details/142019977,就不赘述了
VL Connector
整体结构如下:
class PerceiverAttention(nn.Module):def __init__(self, *, dim, dim_head=64, heads=8):super().__init__()self.scale = dim_head**-0.5self.heads = headsinner_dim = dim_head * headsself.norm_media = nn.LayerNorm(dim)self.norm_latents = nn.LayerNorm(dim)self.to_q = nn.Linear(dim, inner_dim, bias=False)self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)self.to_out = nn.Linear(inner_dim, dim, bias=False)def forward(self, x, latents, vision_attn_masks=None):"""Args:x (torch.Tensor): image featuresshape (b, T, n1, D)latent (torch.Tensor): latent featuresshape (b, T, n2, D)"""x = self.norm_media(x)latents = self.norm_latents(latents)h = self.headsq = self.to_q(latents)kv_input = torch.cat((x, latents), dim=-2) # TODO: Change the shape of vision attention mask according to this.if vision_attn_masks is not None:vision_attn_masks = torch.cat((vision_attn_masks, torch.ones((latents.shape[0], latents.shape[-2]), dtype=latents.dtype, device=latents.device)),dim=-1)k, v = self.to_kv(kv_input).chunk(2, dim=-1)q, k, v = rearrange_many((q, k, v), "b t n (h d) -> b h t n d", h=h)q = q * self.scale# attentionsim = einsum("... i d, ... j d -> ... i j", q, k)# Apply vision attention mask here.# Reference: https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html#torch.nn.functional.scaled_dot_product_attentionif vision_attn_masks is not None:attn_bias = torch.zeros((q.size(0), 1, 1, q.size(-2), k.size(-2)), dtype=q.dtype, device=q.device)vision_attn_masks = repeat(vision_attn_masks, 'b n -> b 1 1 l n', l=q.size(-2))attn_bias.masked_fill_(vision_attn_masks.logical_not(), float("-inf"))sim += attn_biassim = sim - sim.amax(dim=-1, keepdim=True).detach()attn = sim.softmax(dim=-1)out = einsum("... i j, ... j d -> ... i d", attn, v)out = rearrange(out, "b h t n d -> b t n (h d)", h=h)return self.to_out(out)class PerceiverResampler(VisionTokenizer):def __init__(self,*,dim,dim_inner=None,depth=6,dim_head=96,heads=16,num_latents=128,max_num_media=None,max_num_frames=None,ff_mult=4,):"""Perceiver module which takes in image features and outputs image tokens.Args:dim (int): dimension of the incoming image featuresdim_inner (int, optional): final dimension to project the incoming image features to;also the final dimension of the outputted features. If None, no projection is used, and dim_inner = dim.depth (int, optional): number of layers. Defaults to 6.dim_head (int, optional): dimension of each head. Defaults to 64.heads (int, optional): number of heads. Defaults to 8.num_latents (int, optional): number of latent tokens to use in the Perceiver;also corresponds to number of tokens per sequence to output. Defaults to 64.max_num_media (int, optional): maximum number of media per sequence to input into the Perceiverand keep positional embeddings for. If None, no positional embeddings are used.max_num_frames (int, optional): maximum number of frames to input into the Perceiverand keep positional embeddings for. If None, no positional embeddings are used.ff_mult (int, optional): dimension multiplier for the feedforward network. Defaults to 4."""if dim_inner is not None:projection = nn.Linear(dim, dim_inner)else:projection = Nonedim_inner = dimsuper().__init__(dim_media=dim, num_tokens_per_media=num_latents)self.projection = projectionself.latents = nn.Parameter(torch.randn(num_latents, dim))# positional embeddingsself.frame_embs = (nn.Parameter(torch.randn(max_num_frames, dim))if exists(max_num_frames)else None)self.media_time_embs = (nn.Parameter(torch.randn(max_num_media, 1, dim))if exists(max_num_media)else None)self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),FeedForward(dim=dim, mult=ff_mult),]))self.norm = nn.LayerNorm(dim)def forward(self, x, vision_attn_masks):"""Args:x (torch.Tensor): image featuresshape (b, T, F, v, D)vision_attn_masks (torch.Tensor): attention masks for padded visiont tokens (i.e., x)shape (b, v)Returns:shape (b, T, n, D) where n is self.num_latents"""b, T, F, v = x.shape[:4]# frame and media time embeddingsif exists(self.frame_embs):frame_embs = repeat(self.frame_embs[:F], "F d -> b T F v d", b=b, T=T, v=v)x = x + frame_embsx = rearrange(x, "b T F v d -> b T (F v) d") # flatten the frame and spatial dimensionsif exists(self.media_time_embs):x = x + self.media_time_embs[:T]# blockslatents = self.latentslatents = repeat(latents, "n d -> b T n d", b=b, T=T)for attn, ff in self.layers:latents = attn(x, latents, vision_attn_masks) + latentslatents = ff(latents) + latentsif exists(self.projection):return self.projection(self.norm(latents)) else:return self.norm(latents)
训练及数据
预训练
- 训练数据:
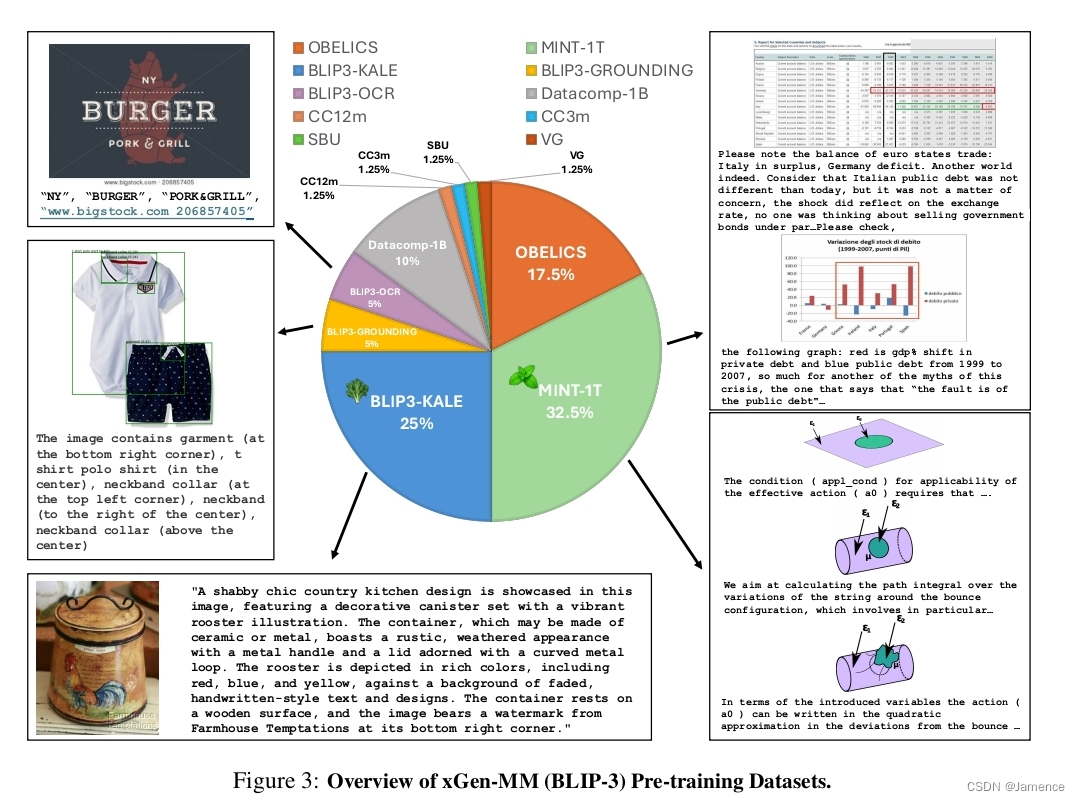
用了0.1T token的多模态数据训练,和一些知名的MLLM相比,例如Qwen2VL 0.6T,还是不太够 - 训练方式:针对文本的next token prediction方式训练,图像输入为384x384
有监督微调(SFT)
- 训练数据:从不同领域(multi-modal conversation、 image captioning、chart/document understanding、science、math),收集一堆开源数据。从中采样1百万,包括图文指令+文本指令数据。
训练1epoch - 训练方式:针对文本的next token prediction方式训练
交互式多图有监督微调(Interleaved Multi-Image Supervised Fine-tuning)
- 训练数据:首先,收集多图指令微调数据(MANTIS和Mmdu)。为避免模型过拟合到多图数据,选择上一阶段的单图指令微调数据子集,与收集的多图指令微调数据合并,构成新的训练集合。
- 训练方式:针对文本的next token prediction方式训练
后训练(Post-training)
DPO提升Truthfulness
part1
- 训练数据:利用开源的VLFeedback数据集。VLFeedback数据集构造方式:输入指令,让多个VLM模型做生成,随后GPT4-v从helpfulness, visual faithfulness, ethics三个维度对生成结果打分。分值高的输出作为preferred responses,分值低的输出作为dispreferred responses。BLIP3进一步过滤掉一部分样本,最终得到62.6K数据。
- 训练方式:DPO为训练目标,用LoRA微调LLM 2.5%参数,总共训练1 epoch
part2
- 训练数据:根据该工作,生成一组额外responses。该responses能够捕捉LLM的内在幻觉,作为额外dispreferred responses,采用DPO训练。
- 训练方式:同part1,再次训练1 epoch
Safety微调(Safety Fine-tuning)提升Harmlessness
- 训练数据:用2k的VLGua数据集+随机5K SFT数据集。VLGuard包括两个部分:
这段话可以翻译为:
(1) 恶心图配上安全指示及安全回应
(2) 安全图配上安全回应及不安全回应 - 训练方式:用上述7k数据,训练目标为next token prediction,用LoRA微调LLM 2.5%参数,总共训练1 epoch
实验效果
预训练
对比类似于预训练任务的VQA、Captioning任务,效果在使用小参数量LLM的MLLM里,效果不错。
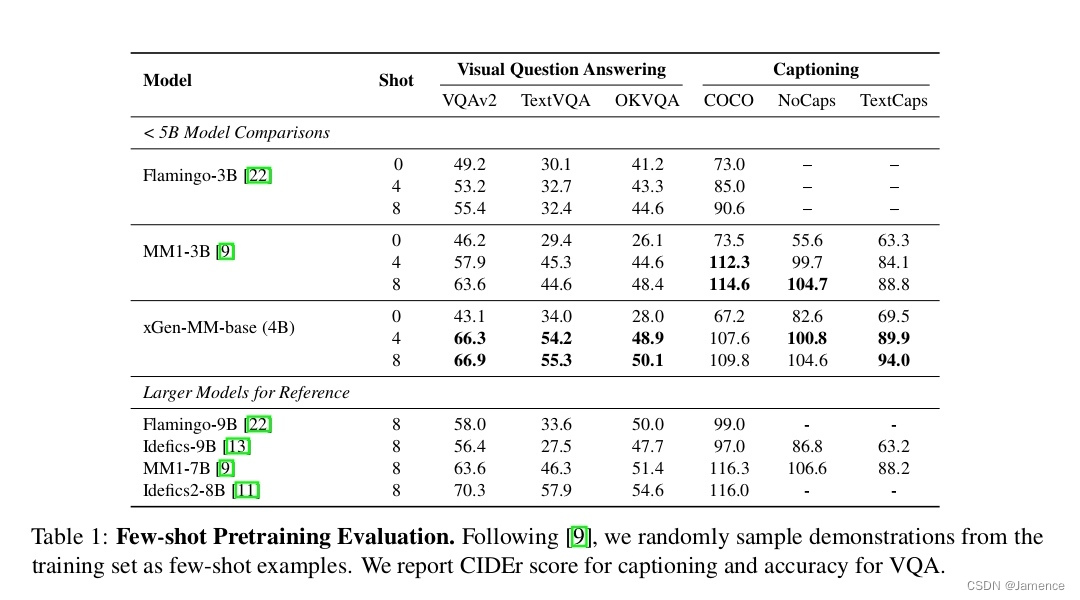
有监督微调(SFT)
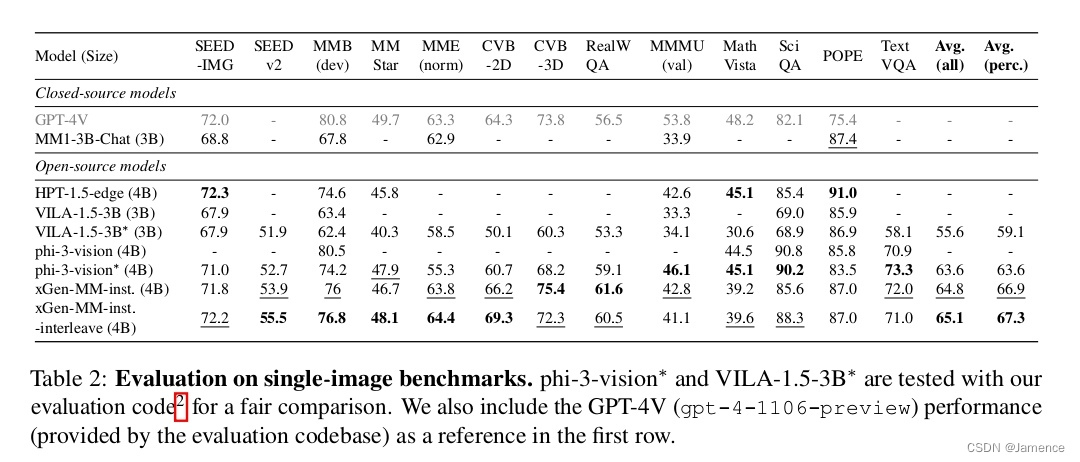
交互式多图有监督微调(Interleaved Multi-Image Supervised Fine-tuning)
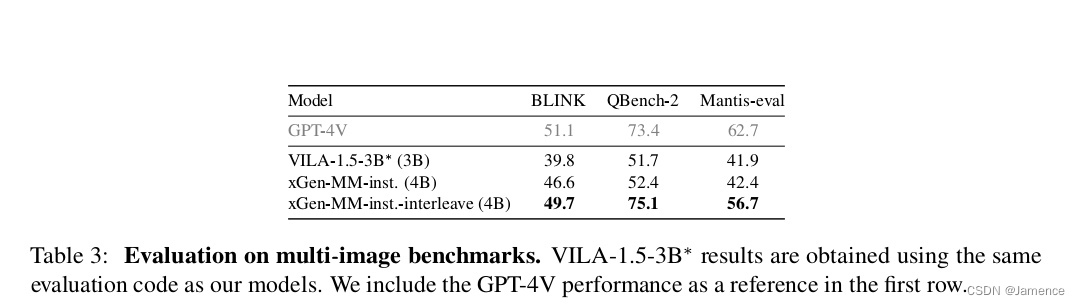
后训练(Post-training)
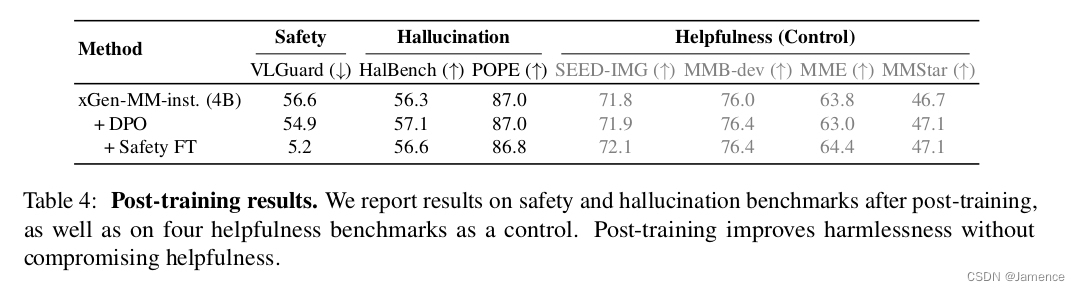
消融实验
预训练
预训练数据量
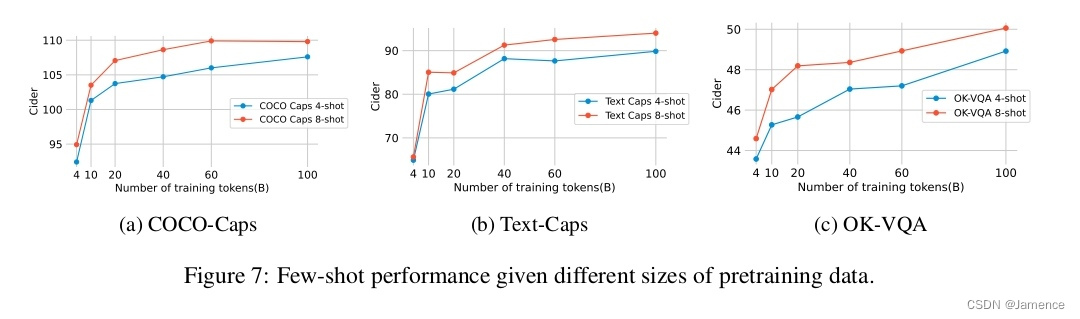
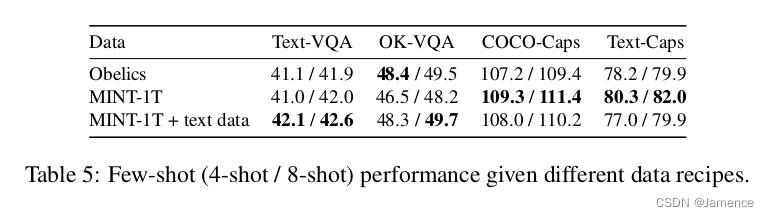
预训练数据配比
视觉backbone
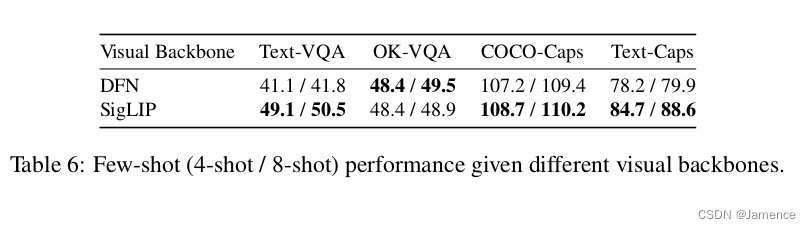
有监督微调(SFT)
视觉Token Sampler对比

base resolution:直接把图片resize到目标大小
anyres-fixed-sampling (ntok=128):把所有图像patch的表征concat起来,经过perceiver resampler,得到128个vision token
anyres-fixed-sampling (ntok=256):把所有图像patch的表征concat起来,经过perceiver resampler,得到256个vision token
anyres-patch-sampling:本文采用的方法
Instruction-Aware Vision Token Sampling.

XGen-MM:输入图像,获取vision token
XGen-MM(instruction-aware):同时输入图像+指令,获取vision token
Quality of the Text-only Instruction Data.
 仅利用文本指令数据,训练SFT模型,对比效果
仅利用文本指令数据,训练SFT模型,对比效果
https://blog.csdn.net/weixin_40779727/article/details/142019977
相关文章:
多模态大语言模型(MLLM)-Blip3/xGen-MM
论文链接:https://www.arxiv.org/abs/2408.08872 代码链接:https://github.com/salesforce/LAVIS/tree/xgen-mm 本次解读xGen-MM (BLIP-3): A Family of Open Large Multimodal Models 可以看作是 [1] Blip: Bootstrapping language-image pre-training…...

flutter TabBar自定义指示器(带文字的指示器、上弦弧形指示器、条形背景指示器、渐变色的指示器)
带文字的TabBar指示器 1.绘制自定义TabBar的绿色带白色文字的指示器 2.将底部灰色文字与TabrBar层叠,并调整高度位置与胶囊指示器重叠 自定义的带文字的TabBar指示器 import package:atui/jade/utils/JadeColors.dart; import package:flutter/material.dart; im…...

【Fargo】9:模拟图片采集的内存泄漏std::bad_alloc
std::bad_alloc 崩溃。这样的内存分配会导致内存耗尽 is simulating an image of size 640x480 with 3 bytes per pixel, resulting in an allocation of approximately 921,600 bytes (or around 900 KB) for each image. The error you’re encountering (std::bad_alloc) ty…...

c# 前端无插件打印导出实现方式
打印 打印导出分布页 model List<界面的数据模型类> using WingSoft; using Newtonsoft.Json; <style type"text/css">.modal-content {width: 800px;}.modal-body {height: 400px;} </style> <script type"text/javascript">$(…...

数组的初始化,参数传递,和求和
在自己做的这个C语言解释器中,数组的使用非常简便。下面小程序是一个例子。演示了数组的初始化,参数传递, 和求和。 all[] { WA12,OR8,CA54, ID4, MT4, WY3, NV6, UT6, AZ11, CO10, NM5, ND3,SD3,NE4, KS6, OK7,TX40, MN10, WI10,IA6, MO10,…...

初始JavaEE篇——多线程(1):Thread类的介绍与使用
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏:JavaEE 目录 创建线程 1、继承 Thread类 2、实现Runnable接口 3、使用匿名内部类 1)继承Thread类的匿名内部类 2)…...
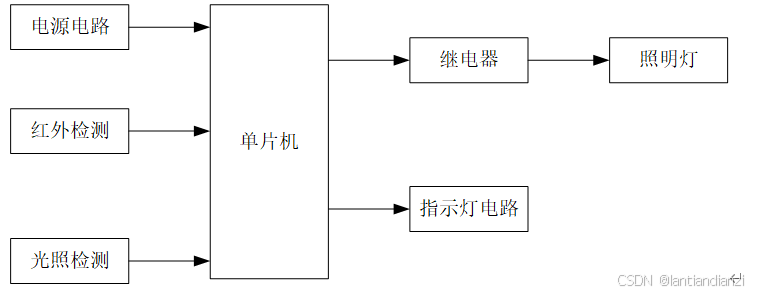
基于单片机的LED照明自动控制系统的设计
本设计主控核心芯片选用了AT89C51单片机,接入了光照采集模块、红外感应模块、继电器控制模块,通过控制发光二极管模拟教室智能灯组的控制。首先通过光敏感应的方式感应当前光照环境为白天还是夜晚,同时,红外感应模块感应是否有人。…...

C语言——头文件的使用
目录 前言头文件怎么包含 前言 这个专栏会专门讲一些C语言的知识,后续会慢慢更新,欢迎关注 C语言专栏 头文件怎么包含 在使用头文件的过程中,我们经常会遇到重定义、重复包含等问题,那么怎么编写头文件和使用头文件才能解决这些…...

LeetCode 精选 75 回顾
目录 一、数组 / 字符串 1.交替合并字符串 (简单) 2.字符串的最大公因子 (简单) 3.拥有最多糖果的孩子(简单) 4.种花问题(简单) 5.反转字符串中的元音字母(简单&a…...

【Unity - 屏幕截图】技术要点
在Unity中想要实现全屏截图或者截取某个对象区域的图片都是可以通过下面的函数进行截取 Texture2D/// <summary>/// <para>Reads the pixels from the current render target (the screen, or a RenderTexture), and writes them to the texture.</para>/…...

句句深刻,字字经典,创客匠人老蒋金句出炉,哪一句让你醍醐灌顶?
注意力经济时代、流量经济时代、短视频经济时代,创始人到底应该如何做,才能抓住风口,链接未来? 「创始人IP创新增长班」线下大课现场,老蒋作为主讲导师,再一次用他丰富的行业经验与深刻的时代洞察ÿ…...

柯尼卡美能达CA-310 FPD色彩分析仪
柯尼卡美能达CA-310 FPD色彩分析仪 型 号:CA-310 名 称:FPD色彩分析仪 品 牌:柯尼卡美能达(KONICA MINOLTA) 分 类:光学和色彩测试 > 光学、显示与色彩测量 > 色彩分析仪 产品属性:主机 简 述&…...

二维EKF的MATLAB代码
EKF二维滤波 MATLAB 实现 提升您的数据处理能力!本MATLAB程序实现了扩展卡尔曼滤波(EKF)在二维状态估计中的应用,专为需要高精度定位和动态系统分析的用户设计。通过精确的滤波技术,有效减少噪声影响,确保…...

大数据治理:数据时代的挑战与应对
目录 大数据治理:数据时代的挑战与应对 一、大数据治理的概念与内涵 二、大数据治理的重要性 1. 提高数据质量与可用性 2. 确保数据安全与合规 3. 支持数据驱动的决策 4. 提高业务效率与竞争力 三、大数据治理的实施策略 1. 建立健全的数据治理框架 2. 数…...

绿联NAS免驱安装MacOS
前段时间UGOS Pro迎来了一次大更新,Docker新增了Docker Compose堆栈项目,于是便在Docker Hub找了个支持Docker Compose部署的MacOS开源项目来验证一下,顺便体验一下用N100运行是什么感觉。 开始折腾 先说说,在没用Docker Compos…...

聊聊ASSERT处理在某些场景下的合理用法
先看看ASSERT的介绍: 编写代码时,我们总是会做出一些假设,ASSERT断言就是用于在代码中捕捉这些假设,可以将断言看作是异常处理的一种高级形式。断言表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真…...

SAP Odata 服务
参考过程 SAP创建ODATA服务-Structure_sap odata-CSDN博客 案例...

【java数据结构】栈
【java数据结构】栈 一、栈的概念二、 栈的使用三、 栈的模拟实现(数组)构造方法size()empty()push()pop()peek() 四、 栈的模拟实现(链表)构造方法size()empty()push()pop()peek() 五、 栈的例题 此篇博客希望对你有所帮助(帮助你了解栈),不…...

从头开始的可视化数据 matplotlib:初学者努力绘制数据图
从头开始学习使用 matplotlib 可视化数据,对于初学者来说,可能会有些挑战,但 matplotlib 的核心理念非常清晰:绘制图表需要了解如何设置图形、坐标轴以及如何用数据填充它们。我们可以通过一些简单的例子来逐步介绍基本步骤。 1. …...

vscode 远程linux服务器 连接git
vscode 远程linux服务器 连接git 1. git 下载2. git 配置1)github 设置2)与github建立连接linux端:创建密钥github端:创建ssh key 3. 使用1)初始化repository2)commit 输入本次提交信息,提交到本…...

OpCore-Simplify:黑苹果配置自动化的架构设计与技术实现
OpCore-Simplify:黑苹果配置自动化的架构设计与技术实现 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 传统黑苹果配置面临硬件兼容性判断…...

实战应用:基于快马ai快速开发集成多款iic传感器的物联网环境监测站
今天想和大家分享一个物联网环境监测站的实战项目开发经验。这个项目用到了ESP32开发板和几种常见的I2C传感器,通过快马平台快速实现了从硬件连接到数据上传的全流程开发。 项目背景与硬件选型 这个环境监测站的核心是ESP32开发板,它内置WiFi功能&…...

4步解决Windows系统苹果设备驱动适配问题
4步解决Windows系统苹果设备驱动适配问题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/ap/Apple-Mobile-Dr…...

基于RexUniNLU的SpringBoot智能客服系统开发全攻略
基于RexUniNLU的SpringBoot智能客服系统开发全攻略 智能客服系统已经成为现代企业提升服务效率、降低运营成本的关键工具。本文将手把手教你如何利用RexUniNLU零样本通用自然语言理解模型,快速构建一个功能完备的SpringBoot智能客服系统。 1. 智能客服系统核心价值 …...

OpenClaw异常处理:Kimi-VL-A3B-Thinking长任务断连恢复方案
OpenClaw异常处理:Kimi-VL-A3B-Thinking长任务断连恢复方案 1. 问题背景与挑战 上周我在用OpenClaw对接Kimi-VL-A3B-Thinking模型处理一批产品说明书的图文转换任务时,遇到了一个棘手的问题:当模型需要处理超过50页的PDF文档时,…...

Qwen3-ASR-1.7B保姆级教程:一键部署,轻松实现中英日韩语音转文字
Qwen3-ASR-1.7B保姆级教程:一键部署,轻松实现中英日韩语音转文字 1. 引言:为什么选择Qwen3-ASR-1.7B? 语音识别技术正在改变我们处理信息的方式,但大多数解决方案要么需要联网调用云端API,要么部署复杂难…...

OpenClaw硬件选型指南:Qwen2.5-VL-7B本地部署的配置建议
OpenClaw硬件选型指南:Qwen2.5-VL-7B本地部署的配置建议 1. 为什么需要硬件选型指南 当我第一次尝试在本地部署OpenClaw对接Qwen2.5-VL-7B模型时,遇到了一个典型问题:我的笔记本显卡只有6GB显存,结果模型加载到一半就崩溃了。这…...

突破语言壁垒:XUnity.AutoTranslator的游戏实时翻译解决方案
突破语言壁垒:XUnity.AutoTranslator的游戏实时翻译解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 当你面对心仪的日文视觉小说却因不懂日语而无法体验剧情,或是在游玩欧…...

通义千问1.5-1.8B-Chat-GPTQ-Int4 WebUI 集成Dify实战:构建可视化AI应用工作流
通义千问1.5-1.8B-Chat-GPTQ-Int4 WebUI 集成Dify实战:构建可视化AI应用工作流 你是不是也遇到过这样的场景:手头有一个不错的AI模型,比如部署好的通义千问,想把它变成一个能解决实际业务问题的应用,比如一个智能客服…...

海思SS524/SS522系列SDK编译实战:从零构建DVR开发环境
1. 海思SS524/SS522芯片与DVR开发入门 第一次接触海思SS524/SS522系列芯片时,我被它强大的视频处理能力震撼到了。这颗芯片简直就是为DVR产品量身定制的,特别是当你需要处理多路高清视频流时,它的优势就更加明显。SS524和SS522虽然型号不同&a…...