ComfyUI_LayerStyle节点介绍
✨原作者地址
ComfyUI_LayerStyle是一个很强大的节点组,支持了大量图像处理的基础节点。这篇是简单搬运和翻译原作者的内容,方便大家更方便快速的了解这个节点的价值。
https://github.com/chflame163/ComfyUI_LayerStyle
✨节点描述
节点根据功能分为5组:LayerStyle,LayerColor,LayerMask,LayerUtility和LayerFilter。

节点组在dznodes节点组下。
- LayerStyle节点提供模仿 Adobe Photoshop 的图层样式。
- LayerColor节点组提供颜色调整功能。
- LayerMask节点提供遮罩辅助工具。
- LayerUtility节点提供与图层合成工具和工作流程相关的辅助节点。
- LayerFilter节点提供图片效果滤镜。
图层样式LayerStyle


包含图像叠加,投影,渐变叠加,内发光,内阴影,外发光,描边,作者还在持续更新。
图层颜色LayerColor
可以实现图像色调的调整,调整图像的亮度、对比度、曝光、色温、色阶、色彩平衡等,甚至支持按照上传图像的色调来调整目标图像;


图层工具LayerUtility

图层混合工具-高级:可以实现两张图像叠加混合,支持不同图层叠加模式,支持修改位置,旋转缩放等操作;

图像蒙版裁剪:根据遮罩范围裁剪图片,并设置保留的周围边框的大小。此节点可以与RestoreCropBox和ImageScaleRestore节点配合使用,裁剪并修改图片的放大部分,然后将其粘贴回原位。这个很适合将重绘区域放大重绘再贴回去的场景。

图像缩放。当此节点成对使用时,图像可以在第二个节点上自动恢复到原始大小。

- original_size:可选输入,用于将图像恢复到其原始大小。
- scale:缩放比例,当original_size有输入,或者scale_by_longest_side设置为True时,该设置将被忽略。
- scale_by_longest_side:允许按长边尺寸缩放。
- longest_side:当scale_by_longest_side设置为True时,将使用此值作为图像的长边。当original_size有输入时,此设置将被忽略。
图像蒙版比例
将图像或蒙版缩放到参考图像(或参考蒙版)的大小。

按纵横比缩放图像
按纵横比缩放图像或蒙版。缩放后的尺寸可以四舍五入为 8 或 16 的倍数,并且可以缩放为长边尺寸。

QWenImage2Prompt
根据图片推断提示。该节点为ComfyUI_VLM_nodes的重新打包UForm-Gen2 Qwen Node,感谢原作者。模型文件请从huggingface或者百度网盘下载到ComfyUI/models/LLavacheckpoints/files_for_uform_gen2_qwen文件夹中。

Llama Vision
使用Llama 3.2视觉模型进行局部推理。可用于生成提示词。本节点部分代码来自ComfyUI-PixtralLlamaMolmoVision,感谢原作者。使用此节点需要transformers升级到4.45.0或更高版本。从百度网盘或者huggingface/SeanScripts下载模型,并复制到ComfyUI/models/LLM。

JoyCaption2
使用JoyCaption-alpha-two模型进行局部推理。可以用来生成提示词。
this node is https://huggingface.co/John6666/joy-caption-alpha-two-cli-mod Implementation in ComfyUI, thank you to the original author. Download models form BaiduNetdisk and BaiduNetdisk , or huggingface/Orenguteng and huggingface/unsloth , then copy to ComfyUI/models/LLM, Download models from BaiduNetdisk or huggingface/google , and copy to ComfyUI/models/clip, Donwload the cgrkzexw-599808 folder from BaiduNetdisk or huggingface/John6666 , and copy to ComfyUI/models/Joy_caption。

JoyCaption2Split
JoyCaption2的节点将模型加载和推理分离,当使用多个JoyCaption2节点时,可以共享模型,提高效率。
加载JoyCaption2Model
JoyCaption2 的模型加载节点,与 JoyCaption2Split 配合使用。
其他多种视觉识别模型暂时不过多介绍,大家自行探索
用户提示生成器替换词
UserPrompt 预设用于将文本中的某个关键词替换为不同的内容,这不仅仅是简单的替换,还会根据提示词的上下文对文本进行逻辑排序,以达到输出内容的合理性。
节点选项:
- rig_prompt:原始提示词输入。
- template:提示词模板,目前仅支持“提示替换词”。
- exclude_word:需要排除的关键字。
- replace_with_word:该词将替换 exclude_word
图像移位
移动图像。该节点支持位移接缝蒙版的输出,方便创建连续纹理。

影像卷轴
在一个卷轴中显示多张图片。可以为卷轴中的每个图片添加文本注释。通过使用ImageReelComposite节点,可以将多个卷轴合并为一张图片。

颜色选择器
从mtb节点修改web扩展。在调色板上选择颜色并输出RGB值,感谢原作者。

RGB值
将颜色值输出为单个 R、G、B 三个十进制值。支持 ColorPicker 节点输出的 HEX 和 DEC 格式。

其他色值等节点不展开。
获取色调
从图像中获取主色或平均色并输出RGB值。

获取主颜色
获取图像的主颜色。可以获取 5 种颜色。


扩展画布
扩展画布

XY 到百分比
将绝对坐标转换为百分比坐标。

图层图像变换
该节点用于对layer_image进行单独变换,可以在不改变图片大小的情况下改变大小、旋转、长宽比、镜像翻转。

彩色图像
生成指定颜色和大小的图像。

渐变图像
生成具有指定大小和颜色渐变的图像。

图像奖励过滤器
对批量图片进行评分,并输出排名靠前的图片。使用 [ImageReward]( https://github.com/THUDM/ImageReward ) 进行图像评分,感谢原作者。

节点选项:
- prompt:可选输入。在这里输入 prompt 将作为判断与图片匹配程度的依据。
- output_nun:输出的图片数量,该值应小于图片批次。
输出:
- images:按评分从高到低的顺序批量输出图片。
- obsolete_images:淘汰赛图片。同样按照评分从高到低的顺序输出。
简单文本图像从文本生成简单的排版图片和蒙版。此节点引用了ZHO-ZHO-ZHO/ComfyUI-Text_Image-Composite的部分功能和代码,感谢原作者。

文字图像
从文本生成图像和蒙版。支持调整字距、行距、水平和垂直调整,可以设置每个字符的随机变化,包括大小和位置。

LaMa:
根据遮罩从图像中擦除物体。此节点是IOPaint的重新包装,由最先进的 AI 模型提供支持,感谢原作者。
它有LaMa、LDM、ZITS、MAT、 FcF、Manga模型和 SPREAD 擦除方法。请参阅原始链接以了解每个模型的介绍。请从lama models(BaiduNetdisk)或lama models(Google Drive)
下载模型文件到文件夹。ComfyUI/models/lama

图像通道分割
将图像通道分割成单独的图像。

图像通道合并
将各个通道图像合并为一幅图像。

图像移除Alpha
从图像中删除alpha通道并将其转换为RGB模式。您可以选择填充背景并设置背景颜色。

图像合并Alpha
将图像和蒙版合并为包含 alpha 通道的 RGBA 模式图像。

图像自动裁剪
自动根据mask对图片进行裁剪,可指定输出图片的背景颜色,长宽比,大小。该节点用于生成训练模型所需的图片素材。

HL频率细节恢复
利用低频滤波,保留高频,恢复图像细节。相比于kijai的DetailTransfer,该节点在保留细节的同时,与环境融合得更好。

- 图像:背景图像输入。
- detail_image:细节图像输入。
- mask:可选输入,如果有mask输入,则只恢复mask部分的细节。
- keep_high_freq:保留高频部分范围,值越大,保留的高频细节越丰富。
- erasure_low_freq:擦除的低频部分的范围。值越大,擦除的低频范围越多。
- mask_blur:蒙版边缘模糊。仅当有蒙版输入时才有效。
图片中心
在多幅输入图像和 mask 之间切换输出,支持 9 组输入,所有输入项都是可选的,如果一组输入中只有图像或 mask,则缺少的项将输出为 None。

批次选择器
从批量图像或蒙版中检索指定的图像或蒙版。

随机数生成器
用于生成指定范围内的随机值,输出类型为int、float、boolean。支持批量和列表生成,支持根据图片批次批量生成一组不同的随机数列表。

字符串条件
判断文本是否包含子字符串,并输出布尔值。

检查掩码V2
在CheckMask的基础上method增加了选项,可以选择不同的检测方式,area_percent将精度改为2位小数的浮点数,可以检测更小的有效区域。

- method:检测方法有两种,分别是
simple和detectability,simple方法只检测mask是否全黑,而detect_percent方法检测有效区域占比。
SwitchCase
根据匹配到的字符串切换输出,可用于任意类型的数据切换,包括但不限于数值、字符串、图片、mask、模型、latent、pipe管线等。支持最多3组case切换,比较case与switch_condition,若相同则输出对应输入,若有相同case则按优先顺序输出,若没有匹配到的case则输出默认输入。注意字符串区分大小写和中英文全角半角。

排队停止
停止当前队列。在此节点执行时,队列将停止。上面的工作流程图说明,如果图像大于 1Mega 像素,队列将停止执行。

清除VRAM
清理 GPU VRAM 和系统 RAM。任何类型的输入都可以访问,当执行到此节点时,RAM 中的 VRAM 和垃圾对象将被清理。通常放置在推理任务完成的节点之后,例如 VAE Decode 节点。
节点选项:
- purge_cache: 清理缓存。
- purge_models:卸载所有已加载的模型。

保存图像
增强保存图片节点,可以自定义图片保存目录、为文件名添加时间戳、选择保存格式、设置图片压缩率、设置是否保存工作流,可选为图片添加不可见水印(以肉眼不可见的方式添加信息,使用节点ShowBlindWaterMark解码水印)。可选输出工作流的json文件。

图片标记器保存
用于保存训练集图像及其文本标签的节点,其中图像文件和文本标签文件具有相同的文件名。可自定义目录,用于保存图像、在文件名中添加时间戳、选择保存格式和设置图像压缩率。*工作流程 image_tagger_stave.exe 位于工作流程目录中。

添加盲水印
给图片添加不可见的水印。以肉眼不可见的方式添加水印图片,并使用节点ShowBlindWaterMark解码水印。

创建QRCode
生成方形二维码图片。
节点选项:
- size:图像的边长。
- border:二维码周围边框的大小,值越大,边框越宽。
- text:此处输入二维码的文本内容,不支持多语言。

加载PSD
加载PSD格式文件,导出图层。注意此节点需要安装psd_tools依赖包,如果安装psd_tool时出现错误,如ModuleNotFoundError: No module named 'docopt',请下载docopt的whl并手动安装

SD3负面条件作用
将SD3中的Negative Condition的四个节点封装成一个单独的节点。

图层蒙版LayerMask

BlendIfMask
重现 Photoshop 的图层样式 - Blend If 功能。此节点输出用于 ImageBlend 或 ImageBlendAdvance 节点上的图层合成的蒙版。 mask是可选输入,如果您在此处输入蒙版,它将作用于输出。


- invert_mask:是否反转掩码。
- blend_if:混合通道选择。有四个选项:
gray、red、green和blue。 - black_point:黑点值,范围从0到255。
- black_range:暗部过渡范围,值越大,暗部mask的过渡层次越丰富。
- white_point:白点值,范围从0到255。
- white_range:亮度过渡范围,值越大,亮部mask的过渡层次越丰富。
遮罩盒检测
检测遮罩所在的区域,并输出其位置和大小。

- 检测:检测方法,
min_bounding_rect为块形状的最小外接矩形,max_inscribed_rect为块形状的最大内接矩形,mask-area为掩蔽像素的有效区域。 - x_adjust:检测后的水平偏差调整。
- y_adjust:检测后的垂直偏移调整。
- scale_adjust:调整检测后的缩放偏移。
输出:
- box_preview:检测结果预览图,红色代表检测结果,绿色代表调整输出结果。
- x_percent:以百分比形式输出水平位置。
- y_percent:垂直位置输出百分比。
- width:宽度。
- height:高度。
- x:左上角位置的 x 坐标。
- y:左上角位置的 y 坐标。
超级节点
使用超精细边缘遮罩处理方法的节点,最新版本的节点包括:SegmentAnythingUltraV2、RmBgUltraV2、BiRefNetUltra、PersonMaskUltraV2、SegformerB2ClothesUltra 和 MaskEdgeUltraDetailV2。这些节点的边缘处理方法有三种:
PyMatting通过使用与掩模三分图的封闭形式匹配来优化掩模的边缘。GuideFilter使用 opencvguidedfilter 根据颜色相似性对边缘进行羽化,在边缘颜色分离较强时效果最佳。
以上两种方法的代码来自spacepxl 的Alpha Matte 中的ComfyUI-Image-Filters,感谢原作者。VitMatte使用transformer vit模型进行高质量边缘处理,保留边缘细节甚至生成半透明遮罩。注意:首次运行时需要下载vitmate模型文件并等待自动下载完成,If the download cannot be completed, you can run the commandhuggingface-cli download hustvl/vitmatte-small-composition-1kto manually download. After successfully downloading the model, you can useVITMatte(local)without accessing the network.- VitMatte 的选项:
device设置是否使用 CUDA 进行 vitimate 操作,比 CPU 快 5 倍左右。max_megapixels设置 vitmate 操作的最大图像尺寸,过大的图像会缩小尺寸。对于 16G VRAM,建议设置为 3。
*从百度网盘或者Huggingface下载所有模型文件到ComfyUI/models/vitmatte文件夹。
下图是三种方法输出差异的示例。

SegmentAnythingUltra
ComfyUI Segment Anything的改进,感谢原作者。
*请参考ComfyUI Segment Anything的安装来安装模型,如果ComfyUI Segment Anything已经正确安装,可以跳过此步骤。
- 从这里下载config.json,model.safetensors,tokenizer_config.json,tokenizer.json和vocab.txt 5个文件到
ComfyUI/models/bert-base-uncased文件夹。 - 将GroundingDINO_SwinT_OGC 配置文件、GroundingDINO_SwinT_OGC 模型、 GroundingDINO_SwinB 配置文件、GroundingDINO_SwinB 模型下载到
ComfyUI/models/grounding-dino文件夹。 - 将sam_vit_h,sam_vit_l, sam_vit_b,sam_hq_vit_h, sam_hq_vit_l,sam_hq_vit_b, mobile_sam下载到
ComfyUI/models/sams文件夹。 *或者从百度网盘的 GroundingDino 模型和 百度网盘的 SAM 模型下载。


SegmentAnythingUltraV2
SegmentAnythingUltra V2升级版新增VITMatte边缘处理方法。(注:大于2K的图片使用此方法会消耗大量内存)

- detail_method:边缘处理方法。提供VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果在第一次使用VITMatte后已经下载了模型,则可以随后使用VITMatte (local)。
- detail_erode:从边缘向内掩盖侵蚀范围。值越大,向内修复的范围越大。
- detail_dilate:mask边缘向外扩展,值越大,向外修复的范围越广。
- 设备:设置VitMatte是否使用cuda。
- max_megapixels:设置 VitMate 操作的最大尺寸。
SAM2Ultra
此节点修改自kijai/ComfyUI-segment-anything-2,感谢kijai对 Comfyui 社区做出的重大贡献。SAM2
Ultra 节点仅支持单张图片,如果需要处理多张图片,请先将图片批次转换为图片列表。 *从BaiduNetdisk或huggingface.co/Kijai/sam2-safetensors
下载模型并复制到文件夹。ComfyUI/models/sam2

SAM2VideoUltra
SAM2 Video Ultra 节点支持处理多帧图像或视频序列。请在序列的第一帧中定义识别框数据以确保正确识别。

绘制BBoxMask
将 Object Detector 节点输出的识别 BBoxes 数据绘制为 mask。

Florence2Ultra
利用Florence2模型的分割功能,同时还拥有超高的边缘细节。本节点部分代码来自spacepxl/ComfyUI-Florence-2,感谢原作者。 *从百度网盘下载模型文件至ComfyUI/models/florence2文件夹。

移除背景
去除背景。与类似的背景去除节点相比,该节点具有超高的边缘细节。
此节点结合了Spacepxl的ComfyUI-Image-Filters的Alpha Matte节点和ZHO-ZHO-ZHO的ComfyUI-BRIA_AI-RMBG的功能,感谢原作者。
*从BRIA Background Removal v1.4或百度网盘下载模型文件到ComfyUI/models/rmbg/RMBG-1.4文件夹,此模型可用于非商业用途。

RmBgUltraV2
RemBgUltra V2升级版新增VITMatte边缘处理方法。(注:大于2K的图片使用此方法会消耗大量内存)
在RemBgUltra的基础上做了如下修改:

- detail_method:边缘处理方法。提供VITMatte、VITMatte(local)、PyMatting、GuidedFilter。如果在第一次使用VITMatte后已经下载了模型,则可以随后使用VITMatte (local)。
- detail_erode:从边缘向内掩盖侵蚀范围。值越大,向内修复的范围越大。
- detail_dilate:mask边缘向外扩展,值越大,向外修复的范围越广。
- 设备:设置VitMatte是否使用cuda。
- max_megapixels:设置 VitMate 操作的最大尺寸。
BiRefNetUltra
使用BiRefNet模型去除背景具有更好的识别能力和超高的边缘细节。该节点模型部分的代码来自Viper的ComfyUI-BiRefNet,感谢原作者。
*从https://huggingface.co/ViperYX/BiRefNet或BaiduNetdisk下载BiRefNet-ep480.pth、pvt_v2_b2.pth、pvt_v2_b5.pth、 5swin_base_patch4_window12_384_22kto1k.pth个swin_large_patch4_window12_384_22kto1k.pth文件到ComfyUI/models/BiRefNet文件夹。

BiRefNetUltraV2
本节点支持使用最新的BiRefNet模型。 *从百度网盘或GoogleDrive下载模型文件并命名BiRefNet-general-epoch_244.pth为ComfyUI/Models/BiRefNet/pth文件夹。 您也可以下载更多的BiRefNet模型并放在这里。

透明背景Ultra
使用透明背景模型去除背景具有更好的识别能力和速度,同时还具有超高的边缘细节。
*从googledrive或者 百度网盘 下载所有文件到ComfyUI/models/transparent-background文件夹。

PersonalMaskUltra
为人像的脸部、头发、身体皮肤、衣服或配饰生成蒙版。相比之前的 A Person Mask Generator 节点,此节点具有超高的边缘细节。此节点的模型代码来自 a-person-mask-generator ,边缘处理代码来自 ComfyUI-Image-Filters ,感谢原作者。 *从 百度网盘 下载模型文件至ComfyUI/models/mediapipe 文件夹。

SegformerB2ClothesUltra

生成人物脸部、头发、手臂、腿部、衣服的遮罩,主要用于衣服的分割。模型分割代码来自StartHua,感谢原作者。相比 comfyui_segformer_b2_clothes,此节点边缘细节超高。(注:使用 VITMatte 方法生成边缘超过 2K 的图片会消耗大量内存)
*从huggingface或者百度网盘下载所有模型文件 到 ComfyUI/models/segformer_b2_clothes文件夹。
HumanPartsUltra
用于生成人体部位蒙版,基于metal3d/ComfyUI_Human_Parts的 Warrper制作,感谢原作者。本节点在原作基础上增加了超精细边缘处理。从百度网盘或者huggingface下载模型文件并复制到ComfyUI\models\onnx\human-parts文件夹内。

遮罩边缘超细节
将粗糙的蒙版处理成极精细的边缘。此节点结合了 Spacepxl 的ComfyUI-Image-Filters的 Alpha Matte 和 Guided Filter Alpha 节点功能,感谢原作者。

YoloV8Detect
使用YoloV8模型检测人脸、手框区域或人物分割。支持选定通道数的输出。从GoogleDrive或百度网盘下载模型文件到ComfyUI/models/yolo文件夹。

媒体管道面部段
使用Mediapipe模型检测人脸特征,分割左右眉毛、眼睛、嘴唇、牙齿。 *从百度网盘下载模型文件到ComfyUI/models/mediapipe文件夹。

按颜色遮罩
根据选定的颜色生成蒙版。

图像转蒙版
将图片转换为mask,支持LAB、RGBA、YUV、HSV模式任意通道转换为mask,同时提供色阶调节,支持mask可选输入,获取仅包含有效部分的mask。

阴影和高光蒙版
为图像的暗部和亮部生成蒙版。

找出两幅图像的不同并生成蒙版
计算两幅图像之间的差异并将其输出为掩码。

MaskGrow
增大和缩小边缘并模糊蒙版

遮罩边缘收缩
平滑过渡并缩小蒙版边缘,同时保留边缘细节。

MaskGrow 与 MaskEdgeShrink 的比较

创建蒙版、渐变蒙版等系列节点,跳过。
图层过滤器LayerFilter
锋利与柔软
增强或平滑图像的细节。

皮肤美容
使皮肤看上去更加光滑。

水彩
水彩画效果

柔光
柔光效果,屏幕上的明亮高光显得模糊。

摇动通道
渠道错位。类似抖音logo的效果。

HDR效果
增强输入图像的动态范围和视觉吸引力。此节点是 HDR 效果 (SuperBeasts.AI)的重新组织和封装,感谢原作者。

电影
模拟胶片的颗粒感、暗边、模糊边,支持输入深度图模拟散焦。本节点为digitaljohn/comfyui-propost
的重新整理封装,感谢原作者。

漏光
模拟薄膜漏光效果,请从百度网盘或者[Google Drive]([light_leak.pkl(Google Drive)( https://drive.google.com/file/d/1DcH2Zkyj7W3OiAeeGpJk1eaZpdJwdCL-/view?usp=sharing ))下载模型文件并复制到ComfyUI/models/layerstyle文件夹。

颜色图
伪彩色热力图效果。


运动模糊
使图像运动模糊

高斯模糊
使图像高斯模糊

添加噪点
给图片添加噪点。

以上~
✨写在最后
去年的时候写了两门比较基础的Stable Diffuison WebUI的基础文字课程,大家如果喜欢的话,可以按需购买,在这里首先感谢各位老板的支持和厚爱~
✨StableDiffusion系统基础课(适合啥也不会的朋友,但是得有块Nvidia显卡):
https://blog.csdn.net/jumengxiaoketang/category_12477471.html
 🎆综合案例课程(适合有一点基础的朋友):
🎆综合案例课程(适合有一点基础的朋友):
https://blog.csdn.net/jumengxiaoketang/category_12526584.html

面向ComfyUI的新手,还有一门系统性入门图文课程内容主要包括如何下载软件、如何搭建自己的工作流、关键基础节点讲解、遇到报错怎么解决等等,如果大家在学习过程中遇到什么问题,也可以直接对应的文章下留言,会持续更新相关答疑内容哈。欢迎订阅哦~
https://blog.csdn.net/jumengxiaoketang/category_12683612.html

感谢大家的支持~
相关文章:
ComfyUI_LayerStyle节点介绍
✨原作者地址 ComfyUI_LayerStyle是一个很强大的节点组,支持了大量图像处理的基础节点。这篇是简单搬运和翻译原作者的内容,方便大家更方便快速的了解这个节点的价值。 https://github.com/chflame163/ComfyUI_LayerStyle ✨节点描述 节点根据功能分…...

SQL Injection | SQL 注入 —— 时间盲注
关注这个漏洞的其他相关笔记:SQL 注入漏洞 - 学习手册-CSDN博客 0x01:时间盲注 —— 理论篇 时间盲注(Time-Based Blind SQL Injection)是一种常见的 SQL 注入技术,适用于那些页面不会返回错误信息,只会回…...

最新开发项目H5商城小程序源码系统 带源代码安装包以及搭建部署教程
系统概述 在当今数字化迅猛发展的时代,电子商务已成为企业拓展市场、提升品牌影响力的重要手段。H5商城小程序作为一种跨平台、轻量级的应用形式,凭借其无需下载安装、即用即走的特性,迅速赢得了广大用户的青睐。为了满足企业对高质量H5商城…...
5大绝招揭秘:Cursor如何让RESTful API开发效率提升300%?
5大绝招揭秘:Cursor如何让RESTful API开发效率提升300%? 在当今快速迭代的软件开发世界中,高效构建RESTful API已成为开发者的必备技能。今天,我们将为大家介绍一款强大的AI辅助工具——Cursor,它能让您的API开发事半功倍。 Cursor Compos…...

鸿蒙开发,在 ArkTS 中,如何使用 Column 实现垂直居中对齐
面向万物互联时代,华为提出了“一次开发多端部署、可分可合自由流转、统一生态原生智能”三大应用与服务开发理念。针对多设备、多入口、服务可分可合等特性,华为提供了多种能力协助开发者降低开发门槛。HarmonyOS基于JS/TS语言体系,构建了全…...

红日安全vulnstack (一)
目录 环境搭建 本机双网卡 Kali IP 靶机IP Web GetShell 前期信息收集 Yxcms后台模板 Getshell PHPMyAdmin日志 Getshell into outfile写入一句话 X phpmyadmin 日志写入一句话 后渗透 MSF 生成木马上线 提取用户hash值 **hash**加密方式 MSF权限Shell至CS CS …...

为什么SSH协议是安全的?
SSH的传输层协议(Transport Layer Protocol)和用户鉴权协议(Authentication Protocol)确保数据的传输安全,这里只介绍传输层协议,是SSH协议的基础。 本文针对SSH2协议。 1、客户端连接服务器 服务器默认…...

主键 外键
主键 外键 在关系型数据库中,主键(Primary Key)和外键(Foreign Key)是用于维护数据完整性和建立表之间关系的重要概念。 主键(Primary Key) 定义: 主键是一个或多个列的组合,其值能…...

G - Road Blocked 2
G - Road Blocked 2 思路 只有当一条边是从 1 1 1到 n n n的所有最短路构成的图的桥时,去掉这条边,最短路才会变大 所以就可以用最短路加tarjan解决这道题了 怎么判断一条边是否可以构成最短路呢,比如求 1 1 1到 n n n的最短路࿰…...

R语言绘制Venn图(文氏图、温氏图、维恩图、范氏图、韦恩图)
Venn图,又称文氏图,标题中其他名字也是它的别称,由封闭圆形组成,代表不同集合。圆形重叠部分表示集合交集,非重叠处为独有元素。在生物学、统计学等领域广泛应用,可展示不同数据集相似性与差异,…...

【Vue.js】vue2 项目在 Vscode 中使用 Ctrl + 鼠标左键跳转 @ 别名导入的 js 文件和 .vue 文件
js 文件跳转 需要安装插件 Vetur 然后需要我们在项目根目录下添加 jsconfig.json 配置,至于配置的作用,可以参考我的另外一篇博客: 【React 】react 创建项目配置 jsconfig.json 的作用 它主要用于配置 JavaScript 或 TypeScript 项目的根…...
NVM配置与Vue3+Vite项目快速搭建指南
本文目录 1、配置环境1.1 NVM1、nvm常用命令 1.2 Mac配置环境1、安装nvm 1.3 Window配置环境1、安装nvm 2、 项目搭建2.1 项目依赖2.2 安装依赖2.3 配置1、别名配置2、创建样式及图片文件夹3、路由 2.4 项目搭建效果2.5 项目结构 在当今快速发展的前端技术领域中,掌…...

面试“利器“——微学时光
大家好,我是程序员阿药。微学时光是一款专为计算机专业学生和IT行业求职者设计的面试刷题小程序,它汇集了丰富的计算机面试题和知识点,旨在帮助用户随时随地学习和复习,提高自身的技术能力和面试技巧。 主题 随时随地学习&#x…...

【Unity】【游戏开发】游戏引擎是如何模拟世界的
【核心感悟】 游戏引擎通过两个维度的合并来模拟这个时间。 一个维度叫物理模型。 一个维度叫视觉模型。 对于物理模型,我们需要用物理引擎给予行为。 对于视觉模型,我们需要用动画去给予行为。 物理模型是真实机制,视觉模型是艺术表现&…...
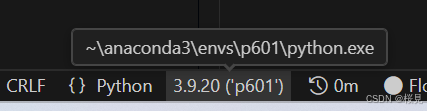
vscode配置conda虚拟环境【windows系统】
安装好anacondavscode里安装python插件 3.点击左侧插件 如图1,再2,再点击3小星星激活conda环境 最后下方栏就出现conda环境了。就可以用啦...
libgpiod在imx8平台交叉编译说明
如下记录是在 imx8上测试使用 参考博主的文章 iMX6ULL 库移植 | Libgpiod 库的交叉编译及使用指南(linux) 编译说明 1: build.sh代码如下所示,先执行 source build.sh,注意修改交叉编译工具链为自己本地的地址; 2:执行 ./autogen…...

无人机之自主飞行关键技术篇
无人机自主飞行指的是无人机利用先进的算法和传感器,实现自我导航、路径规划、环境感知和自动避障等能力。这种飞行模式大大提升了无人机的智能化水平和操作的自动化程度。 一、传感器技术 传感器是无人机实现自主飞行和数据采集的关键组件,主要包括&a…...

performance.timing
performance.timing 是 Web 性能 API 的一部分,用于获取页面加载过程中的各个时间戳。这些时间戳可以帮助开发者分析页面加载性能,找出潜在的瓶颈。performance.timing 返回一个 PerformanceTiming 对象,该对象包含了多个属性,每个…...
教你不用下载 maven,不用配置环境变量,在 idea 上创建 maven 项目
我的主页:2的n次方_ 1. Maven Maven是⼀个项⽬管理⼯具, 通过 pom.xml ⽂件的配置获取 jar 包,⽽不⽤⼿动去添加 jar 包,这样就大大的提高了开发效率 2. Maven 的核心功能 2.1. 项目构建 创建第一个 Maven 项目 Maven 提供了标准的…...

linux 设置tomcat开机启动
在Linux系统中,要配置Tomcat开机自启动,可以创建一个名为 tomcat.service 的 systemd 服务文件,并将其放置在 /etc/systemd/system/ 目录下。以下是一个基本的服务文件示例,假设Tomcat安装在 /usr/local/tomcat 路径下:…...

干货 | 细胞功能学实验合集
细胞增殖实验细胞增殖、凋亡及细胞周期调控,是肿瘤学研究中的核心表型指标,同时也是分子生物学与药理学领域的重点研究方向。在实验研究中,研究者通常通过在细胞内实现特定基因的过表达或干扰,来探究该基因对细胞增殖的调控作用&a…...

量子架构搜索:结合张量网络与强化学习的创新方法
1. 量子架构搜索的现状与挑战量子计算正经历从理论走向实践的关键转型期,但当前NISQ(噪声中等规模量子)设备的局限性给算法实现带来了严峻挑战。这些设备通常只有50-100个量子比特,且存在显著的噪声和有限的量子比特连通性。在这样…...
)
告别手动更新!用Python脚本+Excel表格批量修改UG零件参数(NX2007实战)
告别手动更新!用Python脚本Excel表格批量修改UG零件参数(NX2007实战) 在工业设计领域,UG NX作为主流的三维建模软件,其参数化设计能力直接影响产品迭代效率。传统手动修改模型参数的方式不仅耗时费力,还容易…...

深入解析Arm Cortex-A53 Cache架构:从原理到多核一致性与性能优化实践
1. 项目概述:为什么我们需要深入理解A53的Cache?在嵌入式系统和移动计算领域,Arm Cortex-A53处理器是一个绕不开的名字。作为Armv8-A架构下的“小核”常青树,它以其出色的能效比,广泛存在于从智能手表到智能电视&#…...

串口屏三大主流方案的多维度比较
全球串口屏市场正处于稳步增长通道。据行业研究机构数据,2025年全球串口屏市场规模约6.0亿美元,预计到2030年将增长至6.9亿美元,年复合增长率约5.6%。越来越多的中小设备制造商面临同一个问题:如何在预算和开发周期内,…...

初创团队如何利用 Taotoken 的 Token Plan 有效控制 AI 开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 的 Token Plan 有效控制 AI 开发成本 对于资源有限的初创团队而言,在产品原型开发或内部工…...

告别DLL缺失!用VS2019的Setup Project打包C++程序,保姆级配置指南
告别DLL缺失!用VS2019的Setup Project打包C程序,保姆级配置指南 在C开发中,最令人头疼的问题之一莫过于程序在其他电脑上运行时出现"DLL缺失"的错误。这种问题不仅影响用户体验,也让开发者陷入反复调试的困境。本文将带…...

从“寄生二极管”入手:用万用表二极管档快速判别NMOS/PMOS管脚与好坏
从“寄生二极管”入手:用万用表二极管档快速判别NMOS/PMOS管脚与好坏 当你面对一个没有任何标识的MOS管,或者怀疑电路板上的MOS管损坏时,如何快速准确地判断它是NMOS还是PMOS,并识别出D、S、G三个引脚?本文将详细介绍一…...

RTOS任务通知:轻量级通信机制的原理、应用与性能优化
1. 项目概述:为什么RTOS应用需要“任务通知”在嵌入式实时操作系统(RTOS)的世界里,任务间的通信与同步是决定系统效率、响应速度和稳定性的基石。传统的通信机制,如信号量、消息队列、事件标志组,我们早已驾…...

C++11多线程与线程管理
一、线程基础 1.1 thread默认构造函数 std::thread::thread() _NOEXCEPT {_Thr_set_null(_Thr); }默认构造函数创建一个空线程对象,不关联任何执行线程。 1.2 thread带参数构造函数 explicit thread(Fn &&, Args &&...);可变参数模板,可…...