Python随机森林算法详解与案例实现
目录
- Python随机森林算法详解与案例实现
- 1、随机森林算法概述
- 2、随机森林的原理
- 3、实现步骤
- 4、分类案例:使用随机森林预测鸢尾花品种
- 4.1 数据集介绍
- 4.2 代码实现
- 4.3 代码解释
- 4.4 运行结果
- 5、回归案例:使用随机森林预测波士顿房价
- 5.1 数据集介绍
- 5.2 代码实现
- 5.3 代码解释
- 5.4 运行结果
- 6、随机森林的优缺点
- 7、改进方向
- 8、应用场景
- 9、总结
Python随机森林算法详解与案例实现
1、随机森林算法概述
随机森林(Random Forest) 是一种基于决策树的集成学习算法,由多个决策树组成的「森林」构成。它通过Bagging(自助法采样)和特征随机选择来提高模型的泛化能力,减少过拟合的可能性。该算法通常在分类问题和回归问题上都能取得良好效果。
2、随机森林的原理
-
Bagging(自助法采样):
在训练过程中,从数据集中有放回地抽取若干样本构建不同的决策树。每棵树只对一部分数据进行训练,使得模型更加稳健。 -
特征随机选择:
在每棵树的构建过程中,不是使用全部特征,而是随机选择一部分特征用于分裂节点,这进一步增强了模型的多样性。 -
多数投票和平均:
- 对于分类问题:多个树的预测结果通过投票决定最终类别。
- 对于回归问题:将所有树的输出值取平均,作为最终预测值。
3、实现步骤
我们将用Python实现一个随机森林算法解决两个典型问题:分类和回归。代码将采用面向对象的编程思想(OOP),通过类封装模型逻辑。
4、分类案例:使用随机森林预测鸢尾花品种
4.1 数据集介绍
使用Iris数据集(鸢尾花数据集),其中包含150条记录,每条记录有4个特征,目标是根据花萼和花瓣的尺寸预测其品种(Setosa, Versicolor, Virginica)。
4.2 代码实现
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifierclass IrisRandomForest:def __init__(self, n_estimators=100, max_depth=None, random_state=42):"""初始化随机森林分类器"""self.n_estimators = n_estimatorsself.max_depth = max_depthself.random_state = random_stateself.model = RandomForestClassifier(n_estimators=self.n_estimators, max_depth=self.max_depth, random_state=self.random_state)def load_data(self):"""加载Iris数据集并拆分为训练集和测试集"""iris = load_iris()X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=self.random_state)return X_train, X_test, y_train, y_testdef train(self, X_train, y_train):"""训练模型"""self.model.fit(X_train, y_train)def evaluate(self, X_test, y_test):"""评估模型性能"""predictions = self.model.predict(X_test)accuracy = accuracy_score(y_test, predictions)return accuracyif __name__ == "__main__":rf_classifier = IrisRandomForest(n_estimators=100, max_depth=5)X_train, X_test, y_train, y_test = rf_classifier.load_data()rf_classifier.train(X_train, y_train)accuracy = rf_classifier.evaluate(X_test, y_test)print(f"分类模型的准确率: {accuracy:.2f}")
4.3 代码解释
IrisRandomForest类 封装了模型的初始化、数据加载、模型训练和评估流程。- 使用Scikit-learn库中的
RandomForestClassifier来构建模型。 - 数据集通过
train_test_split拆分为训练集和测试集,测试集占30%。 - 模型最终打印出分类准确率。
4.4 运行结果
分类模型的准确率通常在95%以上,证明随机森林对鸢尾花数据的分类性能非常优秀。
5、回归案例:使用随机森林预测波士顿房价
5.1 数据集介绍
我们使用波士顿房价数据集,其中每条记录包含影响房价的多个特征。目标是根据这些特征预测房价。
5.2 代码实现
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_errorclass HousingPricePredictor:def __init__(self, n_estimators=100, max_depth=None, random_state=42):"""初始化随机森林回归模型"""self.n_estimators = n_estimatorsself.max_depth = max_depthself.random_state = random_stateself.model = RandomForestRegressor(n_estimators=self.n_estimators, max_depth=self.max_depth, random_state=self.random_state)def load_data(self):"""加载房价数据并拆分为训练集和测试集"""data = fetch_california_housing()X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=self.random_state)return X_train, X_test, y_train, y_testdef train(self, X_train, y_train):"""训练模型"""self.model.fit(X_train, y_train)def evaluate(self, X_test, y_test):"""评估模型性能"""predictions = self.model.predict(X_test)mse = mean_squared_error(y_test, predictions)return mseif __name__ == "__main__":predictor = HousingPricePredictor(n_estimators=100, max_depth=10)X_train, X_test, y_train, y_test = predictor.load_data()predictor.train(X_train, y_train)mse = predictor.evaluate(X_test, y_test)print(f"回归模型的均方误差: {mse:.2f}")
5.3 代码解释
HousingPricePredictor类 封装了回归模型的逻辑。- 使用
fetch_california_housing()加载房价数据集。 - 模型最终通过**均方误差(MSE)**来评估性能。
5.4 运行结果
均方误差的值通常在0.4-0.6之间,表示模型在回归任务中的预测能力良好。
6、随机森林的优缺点
优点:
- 能处理高维数据且不会轻易过拟合。
- 能有效应对缺失数据和非线性特征。
- 对于分类和回归任务都表现良好。
缺点:
- 训练速度较慢,计算资源消耗较大。
- 难以解释模型的具体决策路径。
7、改进方向
- 超参数调优: 使用网格搜索优化
n_estimators、max_depth等参数。 - 特征重要性分析: 使用模型中的
feature_importances_属性识别重要特征。 - 集成多种算法: 将随机森林与其他算法(如XGBoost)结合,构建更强大的混合模型。
8、应用场景
- 金融风控: 随机森林可用于信用评分、欺诈检测等任务。
- 医疗诊断: 用于预测疾病的发生和病人的治疗效果。
- 图像分类: 在人脸识别和物体检测任务中表现出色。
9、总结
通过本文的分类与回归案例,我们详细展示了如何使用Python实现随机森林算法,并使用面向对象的思想组织代码。随机森林在处理高维数据和复杂问题时具有优异的表现,是一种可靠且常用的机器学习模型。希望这篇文章能帮助你深入理解随机森林算法的工作原理及应用场景。
相关文章:

Python随机森林算法详解与案例实现
目录 Python随机森林算法详解与案例实现1、随机森林算法概述2、随机森林的原理3、实现步骤4、分类案例:使用随机森林预测鸢尾花品种4.1 数据集介绍4.2 代码实现4.3 代码解释4.4 运行结果 5、回归案例:使用随机森林预测波士顿房价5.1 数据集介绍5.2 代码实…...

提示词高级阶段学习day2.1-在提示词编写中对{}的使用教程
首先在 prompt engineering 中,使用 {} 通常是为了标识占位符或变量, 这些占位符可以在实际生成内容时被动态替换。 通过这种方式,prompt 可以更加通用和灵活,适用于不同的输入数据场景。 以下是一个体系化、结构化的教程&…...

2024年,每一个大模型都躲不过容嬷嬷和紫薇
2024年还不上视频生成的大模型公司,还能上桌吃饭吗? 连最积极搞AI的李彦宏,在这件事上也迟疑了。 “百度不碰Sora类的视频生成方向。”李彦宏在近期的2024年Q3总监会上说道。原因在于,10年、20年都可能难以商业化应用。 从Open…...

SpringBoot之RedisTemplate基本配置
公司要求redis配置密码使用密文,但是程序使用的是spring默认的redisTemplate,那么就需要修改配置实现密码加解密。 先搞个加密工具类: public class SM2Encryptor {// 加密,使用公钥public static String encryptText(String pub…...

SparseRCNN 模型,用于目标检测任务
SparseRCNN 模型,用于目标检测任务 import logging import math from typing import Listimport numpy as np import torch import torch.distributed as dist import torch.nn.functional as F from torch import nn #项目完整代码下载链接:https://download.csdn.net/downl…...

【AIGC】第一性原理下的ChatGPT提示词Prompt设计:系统信息与用户信息的深度融合
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯第一性原理与ChatGPT提示词Prompt设计应用第一性原理于ChatGPT提示词Prompt设计系统信息和用户信息的融合实际应用结论 💯系统信息与用户信息的定义和重要性系…...

DeepSpeed性能调优与常见问题解决方案
1. 引言 什么是DeepSpeed? DeepSpeed是由微软开源的深度学习训练优化库,旨在帮助研究人员和工程师高效地训练大规模深度学习模型。基于PyTorch框架,DeepSpeed提供了一系列先进的技术,如ZeRO(Zero Redundancy Optimiz…...
【GESP】C++一级练习BCQM3052,鸡兔同笼
GESP一级知识点:for循环和if的应用。 题目题解详见:https://www.coderli.com/gesp-1-bcqm3052/ 【GESP】C一级练习BCQM3052,鸡兔同笼 | OneCoderGESP一级知识点:for循环和if的应用。https://www.coderli.com/gesp-1-bcqm3052/ …...

Android面试之5个性能优化相关的深度面试题
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”,和我一起每天进步一点点 面试题目1:如何优化Android应用的启动速度? 解答: 优化Android应用的启动速度可以从以下几个方面入手: 1、 减少主线程工…...

R语言机器学习算法实战系列(六)K-邻近算法 (K-Nearest Neighbors)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍教程下载数据加载R包导入数据数据预处理数据描述数据切割调节参数构建模型预测测试数据评估模型模型准确性混淆矩阵模型评估指标ROC CurvePRC Curve保存模型总结系统信息介绍 K-邻…...

FPGA图像处理之构建3×3矩阵
免责声明:本文所提供的信息和内容仅供参考。作者对本文内容的准确性、完整性、及时性或适用性不作任何明示或暗示的保证。在任何情况下,作者不对因使用本文内容而导致的任何直接或间接损失承担责任,包括但不限于数据丢失、业务中断或其他经济…...

【Linux】进程间通信(匿名管道)
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12625432.html 目录 进程间通信目的 进程间通信发展 进程间通信分类 管道 System V IPC POSI…...

memset()函数的实现
memset()函数的实现 _CRTIMP void* __cdecl memset (void*, int, size_t); memset()函数的实现 文章目录 memset()函数的实现memset()函数 memset()函数 _CRTIMP void* __cdecl memset (void*, int, size_t);void* memset(void* src, int val, size_t count) {char *char_src…...

STM32CUBEIDE FreeRTOS操作教程(七):queue队列
STM32CUBEIDE FreeRTOS操作教程(七):queue队列 STM32CUBE开发环境集成了STM32 HAL库进行FreeRTOS配置和开发的组件,不需要用户自己进行FreeRTOS的移植。这里介绍最简化的用户操作类应用教程。以STM32F401RCT6开发板为例ÿ…...

类型转换与字符串操作:数据的灵活变形!
Java中的隐式与强制类型转换:让你轻松驾驭数据 在编程的世界中,数据的类型如同游戏中的角色,赋予它们不同的特性与能力。而在Java中,隐式类型转换与强制类型转换就像是两把利剑,帮助我们在这个复杂的世界中游刃有余。…...

动态规划18:188. 买卖股票的最佳时机 IV
动态规划解题步骤: 1.确定状态表示:dp[i]是什么 2.确定状态转移方程:dp[i]等于什么 3.初始化:确保状态转移方程不越界 4.确定填表顺序:根据状态转移方程即可确定填表顺序 5.确定返回值 题目链接:188.…...

YOLOv8改进 - 注意力篇 - 引入ShuffleAttention注意力机制
一、本文介绍 作为入门性篇章,这里介绍了ShuffleAttention注意力在YOLOv8中的使用。包含ShuffleAttention原理分析,ShuffleAttention的代码、ShuffleAttention的使用方法、以及添加以后的yaml文件及运行记录。 二、ShuffleAttention原理分析 ShuffleA…...
基于Multisim的8路彩灯循环控制电路设计与仿真
1)由八个彩灯LED的明暗构成各种彩灯图形; 2)彩灯依次显示的图形: 彩灯从左至右渐亮至全亮(8个CP) 彩灯从左至右渐灭至全灭(8个CP) 彩灯从右至左渐亮至全亮(8个CP) 彩灯从右至左渐灭至全灭(8个CP) 彩灯全亮(1个CP) 彩灯全灭(1个CP) 彩灯全亮(1个CP) 彩灯全灭(1个CP) 3)彩灯图形循…...

完整的模型训练套路 pytorch
**前置知识: 1、 (1).train():将模型设置为训练模式 (2).eval():将模型设置为评估模式 不写也可以(只对特定网络模型有作用,如含有Dropout的) 2、 with…...
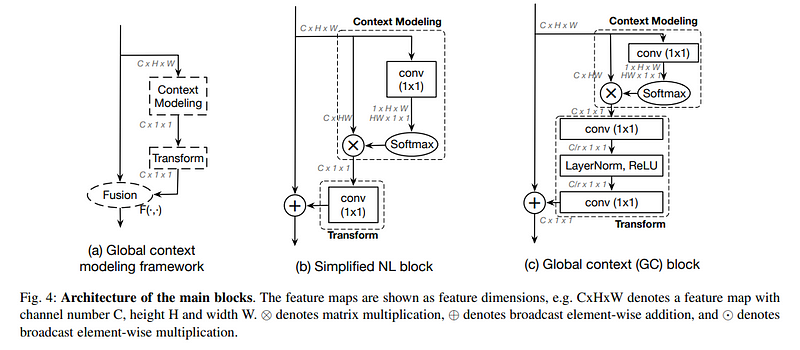
2024年十大前沿图像分割模型汇总:工作机制、优点和缺点介绍
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
)
你的电机为什么抖?排查STM32F4 PWM驱动TB6612的5个常见硬件坑(附示波器实测)
你的电机为什么抖?排查STM32F4 PWM驱动TB6612的5个常见硬件坑(附示波器实测) 电机控制系统中,PWM信号的质量直接影响着驱动芯片和电机的性能表现。许多工程师在使用STM32F4系列MCU配合TB6612驱动模块时,常常遇到电机抖…...

【笔记】旧AI,新人类
AI擅长"旧",人类擅长"新" 关于人机分工的一点思考 不久前,一场颇具戏剧性的"人机对决"在餐饮界引起了不小的波澜。"美膳狮"智能炒菜机器人与湘菜厨师杨孙同台竞技,共同炒制三道菜:XO酱笋…...

海底管道电伴热机理及系统建模与控制策略【附程序】
✨ 长期致力于电伴热、集肤效应、Hammerstein模型、参数辨识、约束广义预测控制算法、功率调节、场路耦合法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&#…...

FPGA系统时钟革新:纯硅可编程振荡器提升可靠性与设计灵活性
1. 项目概述:为什么FPGA需要一个更“稳”的时钟?在FPGA(现场可编程门阵列)的设计与应用中,时钟信号就像是整个数字系统的“心跳”。无论是高速数据采集、复杂算法处理,还是多协议通信,一个稳定、…...

3分钟掌握BilibiliDown:您的专业B站视频离线下载解决方案
3分钟掌握BilibiliDown:您的专业B站视频离线下载解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirror…...
)
RFSoC玩转跳频通信:从NCO配置到多片同步的实战指南(Zynq UltraScale+ RFSoC Gen 3)
RFSoC跳频通信实战:从NCO配置到多片同步的高级技巧 跳频通信技术在现代无线系统中扮演着关键角色,尤其在抗干扰和频谱感知应用中。Xilinx的Zynq UltraScale RFSoC Gen 3平台凭借其集成的RF数据转换器和灵活的数字信号处理能力,为跳频系统设计…...

从USB转TTL到RS485:手把手教你用一颗CH342F芯片玩转三种串口通信
CH342F芯片实战指南:一芯三用的串口通信解决方案 在物联网和工业控制领域,串口通信依然是设备间可靠数据传输的基石。面对多样化的接口标准(TTL、RS232、RS485),工程师常常需要准备多种转换模块。而CH342F芯片以其独特…...

告别RGB控制混乱:用ChromaControl打造统一灯光生态
告别RGB控制混乱:用ChromaControl打造统一灯光生态 【免费下载链接】ChromaControl 3rd party device lighting support for Razer Synapse. 项目地址: https://gitcode.com/gh_mirrors/ch/ChromaControl 你是否曾经面对桌上五颜六色的RGB设备感到困惑&#…...

初次使用Taotoken从注册获取Key到完成第一次API调用的全流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken从注册获取Key到完成第一次API调用的全流程指引 本文旨在为初次接触Taotoken平台的开发者提供一份清晰的入门指南…...

医疗设备晶振精度:从ppm偏差到诊断治疗安全的关键影响
1. 项目概述:从一颗“心跳”说起在医疗设备这个对可靠性要求近乎苛刻的领域,我们常常关注传感器精度、算法鲁棒性、材料生物相容性这些显性指标。然而,有一个看似不起眼、却如同设备“心跳”般至关重要的基础元件——晶体振荡器,也…...