django celery 定时任务 Crontab 计划格式
Celery 定时任务教程
Celery 是一个强大的异步任务队列/作业队列基于分布式消息传递的开源项目。它广泛用于处理各种类型的后台任务,例如发送电子邮件、处理图像、数据分析和视频转换等。
本文将介绍如何使用 Celery 实现定时任务,包括:
- 安装 Celery
- 配置 Celery
- 定义定时任务
- 启动 Celery worker 和 beat
1. 安装 Celery
首先,您需要安装 Celery。可以通过以下命令进行安装:
pip install celery
2. 配置 Celery
在django项目主文件夹下(即settings.py同目录)创建一个名为 celery.py 的文件,并添加以下代码:
import osfrom django.conf import settingsfrom celery import Celery
from celery.schedules import crontab# Set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MainConfig.settings')app = Celery('MainConfig')# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')# Load task modules from all registered Django apps.
app.autodiscover_tasks()# 定时任务配置
app.conf.beat_schedule = {'schedule_task': {'task': 'myapp.tasks.add', # 任务代码所在文件'schedule': crontab(hour='*/3'), # 每3小时执行一次},
}@app.task(bind=True, ignore_result=True)
def debug_task(self):print(f'Request: {self.request!r}')
这里,我们使用 redis作为消息代理。
crontab示例
| 例子 | 意义 |
|---|---|
crontab() | 每分钟执行一次。 |
crontab(minute=0, hour=0) | 每天午夜执行。 |
crontab(minute=0, hour='*/3') | 每三小时执行一次:午夜、凌晨 3 点、早上 6 点、早上 9 点、中午、下午 3 点、下午 6 点、晚上 9 点。 |
crontab(minute=0, hour='0,3,6,9,12,15,18,21') | 与以前相同。 |
crontab(minute='*/15') | 每15分钟执行一次。 |
crontab(day_of_week='sunday') | 每周日每分钟执行一次(!)。 |
crontab(minute='*', hour='*', day_of_week='sun') | 与以前相同。 |
crontab(minute='*/10', hour='3,17,22', day_of_week='thu,fri') | 每十分钟执行一次,但仅限于周四或周五凌晨 3 点至 4 点、下午 5 点至 6 点和晚上 10 点至 11 点之间。 |
crontab(minute=0, hour='*/2,*/3') | 每双数小时和每个能被三整除的小时执行。这意味着:除以下时间外的每个小时:凌晨 1 点、凌晨 5 点、早上 7 点、上午 11 点、下午 1 点、下午 5 点、晚上 7 点、晚上 11 点 |
crontab(minute=0, hour='*/5') | 执行可被 5 整除的小时。这意味着它是在下午 3 点触发,而不是下午 5 点(因为下午 3 点等于 24 小时制时钟值“15”,可以被 5 整除)。 |
crontab(minute=0, hour='*/3,8-17') | 每个能被 3 整除的小时执行一次,办公时间(上午 8 点至下午 5 点)每小时执行一次。 |
crontab(0, 0, day_of_month='2') | 每月第二天执行。 |
crontab(0, 0, day_of_month='2-30/2') | 在每个双数日执行。 |
crontab(0, 0, day_of_month='1-7,15-21') | 在每月的第一周和第三周执行。 |
crontab(0, 0, day_of_month='11', month_of_year='5') | 每年五月十一日执行。 |
crontab(0, 0, month_of_year='*/3') | 每季度第一个月每天执行。 |
settings.py相关配置
#从环境变量中读取服务网络
REDIS_SERVER_URL = os.environ.get('REDIS_SERVER_URL',"127.0.0.1")
# redis 配置
CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": f"redis://{REDIS_SERVER_URL}:6379/1","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient",}}
}# celery
CELERY_BROKER_URL = f"redis://{REDIS_SERVER_URL}:6379/0"
CELERY_RESULT_BACKEND = f"redis://{REDIS_SERVER_URL}:6379/0"
CELERY_BROKER_CONNECTION_RETRY_ON_STARTUP = True
CELERY_TASK_SERIALIZER = "json"
CELERY_RESULT_SERIALIZER = "json"
CELERY_ACCEPT_CONTENT = ["json"]
CELERY_TIMEZONE = "Asia/Shanghai"
CELERY_ENABLE_UTC = True
在django主项目目录的__init__文件下加入以下代码
from .celery import app as celery_app__all__ = ('celery_app',)
3. 定义定时任务
在您的项目中创建一个名为 tasks.py 的文件,并添加以下代码:
from celery import shared_task@shared_task
def add(x, y):return x + y
这里,我们定义了一个名为 add 的任务,它接受两个参数 x 和 y 并返回它们的和。
5. 启动 Celery worker 和 beat
使用以下命令启动 Celery worker 和 beat:
celery -A MainConfig worker -l info -P threads
celery -A main beat --loglevel=info
这里,-A 指定当前目录作为工作目录,--loglevel=info 设置日志级别为 info。
总结
使用 Celery 实现定时任务非常简单。只需按照上述步骤进行配置,即可轻松实现各种复杂的定时任务。
相关文章:

django celery 定时任务 Crontab 计划格式
Celery 定时任务教程 Celery 是一个强大的异步任务队列/作业队列基于分布式消息传递的开源项目。它广泛用于处理各种类型的后台任务,例如发送电子邮件、处理图像、数据分析和视频转换等。 本文将介绍如何使用 Celery 实现定时任务,包括: 安…...
 工具 Fortify WebInspect)
动态应用程序安全测试 (DAST) 工具 Fortify WebInspect
Fortify WebInspect 是一种动态应用程序安全测试 (DAST) 工具,可识别所部署的Web 应用程序和服务中的应用程序漏洞。 OpenText™ 推出的 Fortify WebInspect 是一种自动化DAST 解决方案,可提供全面的漏洞检测能力并有助于安全专业人士和 QA 测试人员识别安全漏洞和…...

深入解析东芝TB62261FTG,步进电机驱动方案
TB62261FTG是一款由东芝推出的两相双极步进电机驱动器,采用了BiCD工艺,能够提供高效的电机控制。这款芯片具有多种优秀的功能,包括PWM斩波、内置电流调节、低导通电阻的MOSFET以及多种步进操作模式,使其非常适合用于需要精确运动控…...

Vue 常用的狗钩子函数
beforeCreate(){ console.log(刚刚创建实例); },created(){console.log(实例创建完成);},beforeMount(){console.log(模板编译之前 ); },mounted(){/* 请求数据,操作Dom时常用 */console.log(实力挂载完成);},beforeUpdate(){console.log(更新前)},update…...

【机器学习基础】激活函数
激活函数 1. Sigmoid函数2. Tanh(双曲正切)函数3. ReLU函数4. Leaky ReLU函数 1. Sigmoid函数 观察导数图像在我们深度学习里面,导数是为了求参数W和B,W和B是在我们模型model确定之后,找出一组最优的W和B,使…...
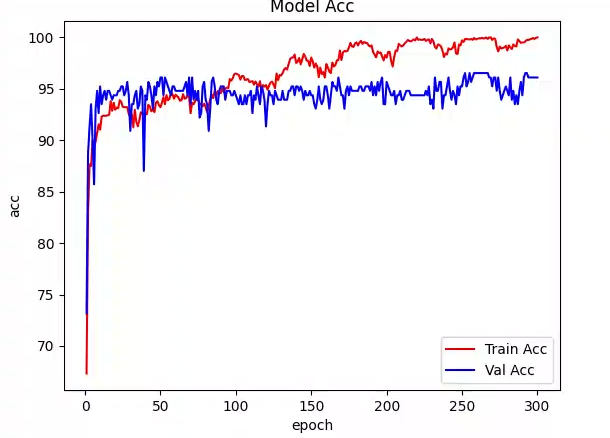
nnMamba用于糖尿病视网膜病变检测测试
1.代码修改 源码是针对3D单通道图像的,只需要简单改写为2D就行,修改nnMamba4cls.py代码如下: # -*- coding: utf-8 -*- # 作者: Mr Cun # 文件名: nnMamba4cls.py # 创建时间: 2024-10-25 # 文件描述:修改nnmamba,使…...

【Spring MVC】创建项目和建立请求连接
我的主页:2的n次方_ 1. MVC MVC 是 Model View Controller 的缩写,它是软件⼯程中的⼀种软件架构设计模式,它把软件系统分为模型、视图和控制器三个基本部分。 View (视图): 指在应⽤程序中专⻔⽤来与浏览器进⾏交互&…...

台达A2伺服
驱动器: L 外接脉冲 U 在L的基础上增加DI E ethercat总线 F 台达 M CANopen总线 电机: ECMA-C A 0604 SS...

ReactOS系统中搜索给定长度的空间地址区间中的二叉树
搜索给定长度的空间地址区间 //搜索给定长度的空间地址区间 MmFindGap MmFindGapTopDown PVOID NTAPI MmFindGap(PMADDRESS_SPACE AddressSpace,ULONG_PTR Length,ULONG_PTR Granularity,BOOLEAN TopDown );PMADDRESS_SPACE AddressSpace,//该进程用户空间 ULONG_PTR Length,…...

Postgresql中和时间相关的字段类型及其适用场景
PostgreSQL 提供了多种数据类型来表示时间和日期,适用于不同的场景和需求。以下是常用的时间类型及其适用场景: 1. TIMESTAMP WITH TIME ZONE (TIMESTAMPTZ) 用途: 表示一个包含时区信息的日期和时间。 使用场景: 适合存储需要考虑时区变化的全球化应用…...

储能蓝海:技术革新与成本骤降引爆市场
在当今全球能源转型的大背景下,储能项目的前景无疑呈现出前所未有的乐观态势。其快速增长的装机规模、持续的技术创新与成本降低、政策的强力支持以及市场的迫切需求,共同绘制了一幅充满机遇与挑战的壮丽画卷。 快速增长的装机规模:储能市场的…...

java抽象类和接口
前言: 在 Java 编程中,抽象类和接口是面向对象编程(OOP)中的重要概念。它们都是用来定义抽象类型的机制,来帮助程序员构建更加灵活、可维护和可扩展的软件系统。 但是随着软件系统规模的不断扩大和复杂度的增加&…...

法治在沃刷积分-刷文章浏览数
最近有一个任务,需要通过浏览文章来获取积分,一个个手点文章太麻烦,专业的事情还得专业的来。 法1:模拟发包 抓包发现,是通过接口来使积分增长,那直接模拟发包即可。 至于info_id的获取,可以通…...

【深度学习实验七】 自动梯度计算
目录 一、利用预定义算子重新实现前馈神经网络 (1)使用pytorch的预定义算子来重新实现二分类任务 (2)完善Runner类 (3) 模型训练 (4)性能评价 二、增加一个3个神经元的隐藏层,再次实现二分类,并与1做对比 三、自定义隐藏层层数和每个隐藏层中的神经元个数,尝…...

JAVA毕业设计192—基于Java+Springboot+vue的个人博客管理系统(源代码+数据库+万字论文+开题+任务书)
毕设所有选题: https://blog.csdn.net/2303_76227485/article/details/131104075 基于JavaSpringbootvue的个人博客管理系统(源代码数据库万字论文开题任务书)192 一、系统介绍 本项目前后端分离,分为用户、管理员两种角色,角色菜单可自行…...

must be ‘pom‘ but is ‘jar‘解决思路
这个错误信息表明在 Maven 的 pom.xml 文件中,定义的父 POM 的 packaging 类型设置不正确。具体来说,它应该是 pom 类型,但当前设置为 jar。这个问题通常会导致构建失败。以下是解决这个问题的步骤。 解决步骤 检查父 POM 的 packaging 类型…...

STM32启动文件浅析
目录 STM32启动文件简介启动文件中的一些指令 启动文件代码详解栈空间的开辟堆空间的开辟中断向量表定义(简称:向量表)复位程序对于weak的理解对于_main函数的分析 中断服务程序用户堆栈初始化 系统启动流程 STM32启动文件简介 STM32启动文件…...

h5页面与小程序页面互相跳转
小程序跳转h5页面 一个home页 /pages/home/home 一个含有点击事件的元素:<button type"primary" bind:tap"toWebView">点击跳转h5页面</button>toWebView(){ wx.navigateTo({ url: /pages/webview/webview }) } 一个webView页 /pa…...
:React 合成事件系统)
探索 JavaScript 事件机制(四):React 合成事件系统
前言 在前端开发中,事件处理是不可或缺的一部分。在众多的前端框架中,React 凭借其高效和灵活性受到众多开发者的喜爱。React 的事件处理系统,即“合成事件系统”,是其性能优化的一大亮点。 本文将带你深入浅出地探索 React 的合…...

openlayers 封装加载本地geojson数据 - vue3
Geojson数据是矢量数据,主要是点、线、面数据集合 Geojson数据获取:DataV.GeoAtlas地理小工具系列 实现代码如下: import {ref,toRaw} from vue; import { Vector as VectorLayer } from ol/layer.js; import { Vector as VectorSource } fr…...
:核心抽象层 —— 块 、分区 、inode 从原理到实操)
【Linux 指南】文件系统系列(二):核心抽象层 —— 块 、分区 、inode 从原理到实操
上一篇我们吃透了磁盘的底层原理,搞懂了磁盘通过 CHS/LBA 寻址定位扇区,也知道扇区是磁盘硬件的最小读写单位(512 字节)。但随之而来的两个核心问题摆在眼前:一是逐个扇区读写磁盘效率极低,磁头的寻道和旋转…...

Argo CD 集成 Helmfile 插件:实现 GitOps 下复杂应用声明式部署
1. 项目概述与核心价值如果你正在使用 Argo CD 管理 Kubernetes 集群,并且你的应用清单是由 Helmfile 来编排的,那么travisghansen/argo-cd-helmfile这个项目很可能就是你一直在寻找的“粘合剂”。简单来说,它是一个专门为 Argo CD 设计的 He…...

Android本地AI智能家居框架:ZeroClaw架构设计与工程实践
1. 项目缘起与核心愿景几年前,我还在为一个智能家居项目焦头烂额,试图让家里的灯光、空调和音箱能听懂人话,而不是只会执行预设的“回家模式”或“睡眠模式”。当时市面上主流的方案,要么是依赖某个封闭的云平台,所有指…...

技术决策的后悔药:选型错误后的补救策略
在软件测试的全生命周期中,技术选型是影响测试效率、质量与项目成败的关键环节。小到一款测试工具的挑选,大到整个测试框架的搭建,每一次决策都如同在迷雾中航行,稍有不慎便可能驶入“选型错误”的漩涡。当测试环境兼容性问题频发…...

阴阳师御魂自动刷脚本:5分钟快速上手的智能挂机指南
阴阳师御魂自动刷脚本:5分钟快速上手的智能挂机指南 【免费下载链接】yysScript 阴阳师脚本 支持御魂副本 双开 项目地址: https://gitcode.com/gh_mirrors/yy/yysScript 还在为重复刷御魂副本而感到疲惫吗?yysScript智能挂机脚本是专为《阴阳师》…...

3分钟掌握B站缓存视频转换:m4s-converter终极使用指南
3分钟掌握B站缓存视频转换:m4s-converter终极使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的困扰&a…...

从“鸡尾酒会”到手机通话:用生活场景图解CDMA码分多址到底是怎么“听清”你的
鸡尾酒会里的通信密码:用生活场景拆解CDMA如何从噪音中识别你的声音 1. 当鸡尾酒会遇见通信技术 想象你站在一个嘈杂的鸡尾酒会现场,四周充斥着数十人同时进行的对话。神奇的是,尽管声波在空气中混杂叠加,你的大脑却能自动过滤无关…...

深入STM32F429 LTDC双图层与DMA2D:打造流畅UI界面的性能优化指南
STM32F429 LTDC与DMA2D深度优化:构建60FPS工业级UI的实战指南 在工业HMI和医疗设备等对显示性能要求严苛的场景中,流畅的UI动画和实时数据可视化往往成为系统瓶颈。STM32F429的LTDC控制器配合DMA2D加速器,通过合理的架构设计可实现媲美专业GP…...

别再只调参了!搞懂MaxPool2D的padding=‘same‘和‘valid‘,让你的CNN模型效果立竿见影
别再只调参了!搞懂MaxPool2D的paddingsame和valid,让你的CNN模型效果立竿见影 在构建卷积神经网络(CNN)时,许多开发者习惯性地将注意力集中在卷积核大小、激活函数选择等显性参数上,却常常忽略池化层中padd…...

Hive内部表 vs 外部表:选错一次,数据全丢?结合HDFS路径详解核心区别与选型指南
Hive内部表与外部表:数据安全与架构设计的深度抉择 在数据仓库与大数据分析领域,Hive作为构建在Hadoop之上的数据仓库工具,其表类型的选择往往被初学者视为简单的语法差异。然而,当生产环境中TB级的数据因为一个DROP TABLE命令而永…...