多线程——线程池
目录
·前言
一、什么是线程池
1.引入线程池的原因
2.线程池的介绍
二、标准库中的线程池
1.构造方法
2.方法参数
(1)corePoolSize 与 maximumPoolSize
(2)keepAliveTime 与 unit
(3)workQueue(任务队列)
(4)threadFactory(线程工厂)
(5) handler(拒绝策略)
3.使用标准库中线程池
三、实现线程池
·结尾
·前言
在我们学习编程知识过程中一定听说过很多池,比如常量池,还有在我前面 MySql 专栏中 JDBC 编程里提到的数据库连接池,以及本篇文章要为大家介绍的线程池,所谓的这些池作用其实都差不多,都是提前把要用的对象创建好,然后把用完的对象不立即释放留着以备下次使用,这样就可以起到提高效率的作用,本篇文章就会为大家介绍一下什么是线程池,在我们 Java 标准库中的线程池是什么样的,以及使用 Java 代码来实现一个简单的线程池让大家能更清晰的认识线程池,那么就开始本篇文章的介绍内容吧。
一、什么是线程池
1.引入线程池的原因
在我们最开始,引入进程的概念就能够解决并发编程的问题,后来由于频繁创建销毁进程带来的开销太大,从而引入了线程(轻量级进程)这样的概念,使用复用资源的方式来提高创建销毁的效率,但是如果创建和销毁线程的频率也进一步提高呢?此时,线程的创建和开销也就不能无视了。
为了优化线程的创建与销毁的效率,有下面两种解决方案:
- 引入轻量级线程,也称为“协程”;
- 使用线程池。
为什么协程可以优化线程的开销与销毁,这是因为协程的本质是我们在用户态代码中进行调度,不是靠内核的调度器调度的,这样就可以节省很多调度上的开销,此时,我们代码中创建上千个线程会卡死,但是创建上千个协程就没什么事了。
虽然协程有很多的好处,但是在 Java 中不是很推荐用上述做法来优化线程的创建与销毁,这是因为引入协程会引入额外的复杂性,使用协程可能不是很稳定,协程的调试比较困难……所以相比于协程,使用线程池对于优化线程的创建与销毁会更好一些,那么下面就进一步介绍一下线程池是什么吧。
2.线程池的介绍
线程池就是要把使用的线程提前创建好,用完了一个线程也不要直接释放,而是放到线程池中以备下次的使用,这样就节省了线程创建与销毁的开销,因为在这使用线程的过程中,并没有真的频繁创建和销毁线程,只是从线程池中取线程使用,用完还会放回去。
那么为什么从线程池中取线程就比从系统中申请更高效呢?这就好比你让室友帮你取快递,室友答应帮你取,但是什么时候给你取回来,他在帮你取快递的途中会不会做一些什么事情都是不确定的,相比之下,你自己去取快递,就会更高效,通过上面的例子,我们可以得到以下结论:
- 从线程池中取线程是纯用户态代码,是可控的;
- 通过系统申请创建线程,需要系统内核来完成,这是不可控的。
二、标准库中的线程池
1.构造方法
在 Java 标准库中 ThreadPoolExecutor 这个类就是用来创建线程池的,关于这个类,它的构造方法有很多的参数,由我来给大家介绍一下,下面是这个类的几个构造方法,如下图所示:
如上图,ThreadPoolExecutor 一共涉及到四个构造方法,这里我只对第四个构造方法的每个参数进行一个介绍,这是因为,最后一个构造方法的参数是最全的,可以这么理解,介绍完第四个构造方法的各个参数,其余三个构造方法也就都包含了。
2.方法参数
(1)corePoolSize 与 maximumPoolSize
在标准库提供的线程池中,持有的线程个数并不是一成不变的,它会根据当前的任务量来自适应当前线程的个数(任务数量很多,就会多创建几个线程,任务量比较少,就会少创建几个线程),在构造方法中的前两个参数 int corePoolSize 代表线程池中核心线程数有多少也就是一个线程池中最少得有多少个线程,int maximumPoolSize 代表了线程池中最大线程数是多少也就是一个线程池中最多能有多少个线程。
(2)keepAliveTime 与 unit
第三个参数:long keepAliveTime 代表的意思就是线程池中除了核心线程外的线程的保持存活时间,在上面介绍了标准库中的线程池是根据当前的任务量来自适应当前线程的个数,这个参数就是自适应实现的一个重要标准,keepAliveTime 可以记录除了核心线程外的线程空闲的时间,如果这些线程的空闲时间超过了 keepAliveTime 的值就会自动销毁这些线程,来达到一个自适应的效果,这里的第四个参数:TimeUnit unit 就是搭配 keepAliveTime 这个参数的,unit 代表的是时间单位,它可以是 s、min、ms、hour……也就代表了空闲时间 keepAliveTime 的时间单位。
(3)workQueue(任务队列)
第五个参数:BlockingQueue了<Runnable> workQueue 代表线程池中可以有很多个任务,这里使用 Runnable 来作为描述任务的主体,线程池中线程不断从这个阻塞队列中取任务来执行。
(4)threadFactory(线程工厂)
第六个参数:ThreadFactory threadFactory 意思是线程工厂,通过这个工厂类就可以来创建线程对象(Thread 对象),这个类里提供了方法,方法中封装了 new Thread 这样的操作,并且同时给 Thread 设置了一些属性,由此就构成了 ThreadFactory 线程工厂。
这里的线程工厂也用到了一种设计模式:工厂模式,它是通过专门的“工厂类”/“工厂对象”来创建指定对象,那么为什么使用工厂模式呢?我们来看下面的一个代码示例:
// 表示平面上的一个点
class Point {// 笛卡尔坐标系 x 与 yprivate double x;private double y;// 极坐标系 r 与 aprivate double r;private double a;// 通过笛卡尔坐标系来构造这个点public Point(double x, double y) {setX(x);setY(y);}// 通过极坐标系来构造这个点public Point(double r, double a) {setR(r);setA(a);}public double x() {return x;}public void setX(double x) {this.x = x;}public double y() {return y;}public void setY(double y) {this.y = y;}public double r() {return r;}public void setR(double r) {this.r = r;}public double a() {return a;}public void setA(double a) {this.a = a;}
} 不知道大家看完上面的代码有没有发现什么问题,这里的问题就在于 Point 这个类的两个构造方法不构成重载,它们的参数列表是一样的,如下图所示:
想必我们都知道,使用笛卡尔坐标和使用极坐标都可以表示一个点,并且这两个表示方法并不相同,想通过同一个类的构造方法来用这两种不同的方式表示不同的点就违背了 Java 的语法规则,为了解决上述的问题,就引入了“工厂模式”。
工厂模式的基本逻辑就是使用普通方法来创建对象,在普通方法中把构造方法进行封装,利用工厂模式修改后的代码及运行结果如下所示:
// 表示平面上的一个点
class Point {// 笛卡尔坐标系 x 与 yprivate double x;private double y;// 极坐标系 r 与 aprivate double r;private double a;// 通过笛卡尔坐标系来构造这个点public static Point makePointByXY(double x, double y) {Point point = new Point();point.setX(x);point.setY(y);return point;}// 通过极坐标系来构造这个点public static Point makePointByRA(double r, double a) {Point point = new Point();point.setR(r);point.setA(a);return point;}public double x() {return x;}public void setX(double x) {this.x = x;}public double y() {return y;}public void setY(double y) {this.y = y;}public double r() {return r;}public void setR(double r) {this.r = r;}public double a() {return a;}public void setA(double a) {this.a = a;}
}
public class PointFactory {public static void main(String[] args) {Point point1 = Point.makePointByXY(3,4);Point point2 = Point.makePointByRA(3,30);System.out.println("point1 的笛卡尔坐标:->(" + point1.x() + "," + point1.y() + ")");System.out.println("point2 的极坐标:->(" + point2.r() + "," + point2.a() + ")");}
} 
此时,利用工厂模式就可以创建出两个方式表示的点,代码中的 makePointByXY 方法与 makePointByRA 方法也称为工厂方法,如果把工厂方法放到一个其他的类中,这个类就叫做“工厂类”,总的来说,通过静态方法封装 new 操作,在方法内部设定不同的属性来完成对象的初始化,构造对象的过程,就是工厂模式。
(5) handler(拒绝策略)
第七个参数:RejectedExecutionHandler handler 这个参数可以算是最重要的一个参数,在前面介绍的第五个参数:BlockingQueue了<Runnable> workQueue 这是线程池中的一个阻塞队列,用来存储当前线程池要执行的任务都有哪些,它能够容纳的元素是有上限的,此时当这个阻塞队列中的任务已经排满了,还有新的任务要往这个阻塞队列中添加,线程池该怎么办?这就需要我们的第七个参数:RejectedExecutionHandler handler 来指明一个拒绝策略,如下图所示:
上图中的这四个类也就代表了四种拒绝策略,它们所对应的拒绝策略如下表所示:
| ThreadPoolExecutor.AbortPolicy | 继续添加任务,直接抛出异常。 |
| ThreadPoolExecutor.CallerRunsPolicy | 新的任务由添加任务的线程负责执行。 |
| ThreadPoolExecutor.DiscardOldestPolicy | 丢弃最老的任务,添加新的任务。 |
| ThreadPoolExecutor.DiscardPolicy | 丢弃最新的任务。 |
3.使用标准库中线程池
上面介绍了 ThreadPoolExecutor 类的构造方法及构造方法中的参数,可以看出来 ThreadPoolExecutor 类本身用起来比较复杂,因此在标准库中还提供了另一个版本的线程池,也就是把 ThreadPoolExecutor 类给封装了一下,这个线程池就是 Executors 工厂类,通过这个类来创建出的不同线程池对象,Executors 类在内部把 ThreadPoolExecutor 创建好了,并且设置了不同的参数,下面就使用 Executors 演示一下标准库中线程池的效果吧。
如下图所示,在 Executors 中内置了很多版本的线程池,这里我们使用固定数目的线程池来简单演示一下线程池的效果即可。

下面使用线程池的具体代码及运行结果如下所示:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class TestDemo7 {public static void main(String[] args) {// ExecutorService 提供了一种管理和控制异步任务执行的方式ExecutorService service = Executors.newFixedThreadPool(4);// 使用 submit 方法把任务添加到线程池中service.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello");}});}
} 介绍完这两个标准库中的线程池,可以明确一点,当我们只是想简单用一下线程池,就可以使用 Executors ,当我们希望高度定制化一个线程池,就可以使用 ThreadPoolExecutor。
介绍完这两个标准库中的线程池,可以明确一点,当我们只是想简单用一下线程池,就可以使用 Executors ,当我们希望高度定制化一个线程池,就可以使用 ThreadPoolExecutor。
三、实现线程池
在前面介绍了标准库中的线程池及演示了使用的效果,下面我就来写代码实现一个简单的线程池,这里我就直接写一个固定线程数目的线程池,下面是这个简单线程池中包含的内容:
- 提供构造方法,指定创建多少个线程;
- 在构造方法中,把这些线程都创建好;
- 创建一个阻塞队列,能够持有要执行的任务;
- 提供 submit 方法,可以添加新的任务。
那么下面我就直接上代码了,关于这个简单线程池实现的细节我会在代码中以注释的方式进行介绍,线程池实现的代码及运行结果如下所示:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;class MyThreadPoolExecutor {// 创建阻塞队列,用来接收任务,这里设置最多容纳任务量为 100private BlockingQueue<Runnable> blockingQueue = new ArrayBlockingQueue<>(100);// 创建线程链表,把创建的每个线程都用线程链表组织起来private List<Thread> threadList = new ArrayList<>();// 构造方法,指定线程池中固定的线程数,并且将线程都创建好public MyThreadPoolExecutor(int num) {for (int i = 0; i < num; i++) {Thread t = new Thread(()->{while (true) {// 利用 runnable 来接收阻塞队列中的任务Runnable runnable = null;try {// 获取任务runnable = blockingQueue.take();} catch (InterruptedException e) {throw new RuntimeException(e);}// 执行任务runnable.run();}});// 启动线程t.start();// 将线程加入到线程链表中threadList.add(t);}}// 方法 sumbit 用来向阻塞队列中添加新的任务public void sumbit(Runnable runnable) throws InterruptedException {blockingQueue.put(runnable);}
}public class ThreadDemo8 {public static void main(String[] args) throws InterruptedException {// 创建线程池,指定线程数目为 4MyThreadPoolExecutor executor = new MyThreadPoolExecutor(4);// 循环 100 次,向线程池中添加 100 个任务for (int i = 0; i < 100; i++) {int n = i;executor.sumbit(new Runnable() {@Overridepublic void run() {// 任务的内容System.out.println("执行任务:->" + n + ",执行的线程是:->" + Thread.currentThread().getName());}});}}
} 如上图的运行结果可以看出,多个线程之间的执行顺序是不确定的,某个线程获取到了某个任务,但并非是立即执行,在这个过程中很有可能另一个线程就插到前面了,这里的这些线程彼此之间都是等价的。
如上图的运行结果可以看出,多个线程之间的执行顺序是不确定的,某个线程获取到了某个任务,但并非是立即执行,在这个过程中很有可能另一个线程就插到前面了,这里的这些线程彼此之间都是等价的。
·结尾
文章到这里就要结束了,回顾本篇文章,我介绍了什么是线程池,标准库中线程池还有实现了一个简单的线程池,其中还是要多理解一下标准库中线程池构造方法每个参数的意思,及理解拒绝策略的含义,这可以让我们对 ThreadPoolExecutor 类的使用更加清晰,后面实现的线程池也就可以看出线程池基本的工作原理,那就是不断利用这 4 个线程来执行任务,这样就省去创建和销毁线程的开销,那么如果你感觉本篇文章对你有所帮助,还是希望能收到你的三连鼓励,如果对文章的内容有所疑问欢迎在评论区进行讨论,我们下一篇文章再见吧~~~
相关文章:
多线程——线程池
目录 前言 一、什么是线程池 1.引入线程池的原因 2.线程池的介绍 二、标准库中的线程池 1.构造方法 2.方法参数 (1)corePoolSize 与 maximumPoolSize (2)keepAliveTime 与 unit (3)workQueue&am…...

VScode插件:前端每日一题
大文件上传如何做断点续传? 在前端实现大文件上传的断点续传,通常会将文件切片并分块上传,记录每块的上传状态,以便在中断或失败时只上传未完成的部分。以下是实现断点续传的主要步骤和思路: 1. 文件切片 (File Slici…...

Android跨进程通信
1、跨进程通信的几种方式 在 Android 中,跨进程通信 (IPC, Inter-Process Communication) 方式有多种,主要用于在不同的应用或进程之间传递数据。常见的跨进程通信方式包括: AIDL (Android Interface Definition Language) • 描述ÿ…...

【初阶数据结构】计数排序 :感受非比较排序的魅力
文章目录 前言1. 什么是计数排序?2. 计数排序的算法思路2.1 绝对位置和相对位置2.2 根据计数数组的信息来确认 3. 计数排序的代码4. 算法分析5. 计数排序的优缺点6.计数排序的应用场景 前言 如果大家仔细思考的话,可能会发现这么一个问题。我们学的七大…...

前后双差速轮之LQR控制
在之前的代码中,我们实现了前后两对双差速轮AGV的运动学正解和逆解。但为了实现对AGV的精确路径跟踪和姿态控制,我们需要引入控制算法。线性二次型调节器(LQR)是一种常用的最优控制方法,可以有效地将系统的状态误差最小化。本文将详细说明如何在之前的C++代码中加入LQR控制…...

Linux之远程连接服务器
1、远程连接服务器简介 (1)什么是远程连接服务器 远程连接服务器通过文字或图形接口方式来远程登录系统,让你在远程终端前登录linux主机以取得可操作主机接口(shell),而登录后的操作感觉就像是坐在系统前面…...

k8s 部署 nexus3 详解
创建命名空间 nexus3-namespace.yaml apiVersion: v1 kind: Namespace metadata:name: nexus-ns创建pv&pvc nexus3-pv-pvc.yaml apiVersion: v1 kind: PersistentVolume metadata:name: nfs-pvnamespace: nexus-ns spec:capacity:storage: 3GiaccessModes:- ReadWriteM…...

从“摸黑”到“透视”:AORO A23热成像防爆手机如何改变工业检测?
在工业检测领域,传统的检测手段常因效率低下、精度不足和潜在的安全风险而受到诟病。随着科技的不断进步,一种新兴的检测技术——红外热成像技术,正逐渐在该领域崭露头角。近期,小编对一款集成红外热成像技术的AORO A23防爆手机进…...
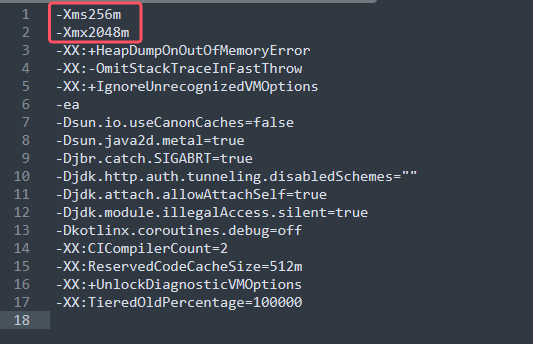
让你的 IDEA 使用更流畅 | IDEA内存修改
随着idea使用越来越频繁,笔者最近发现使用过程中有时候会出现卡顿现象,例如,启动软件变慢,打开项目的速度变慢等: 因此如果各位朋友觉得最近也遇到了同样的困惑,不妨跟着笔者一起来设置IDEA的内存大小吧~ …...

docker run 命令解析
docker run 命令解析 docker run 命令用于从给定的镜像启动一个新的容器。这个命令可以包含许多选项,下面是一些常用的选项: -d:后台运行容器,并返回容器ID;-i:以交互模式运行容器,通常与 -t …...

[Unity Demo]从零开始制作空洞骑士Hollow Knight第十七集:制作第一个BOSS苍蝇之母
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、战斗场景Battle Scene相关逻辑处理 1.防止玩家走出战斗场景的门2.制作一个简单的战斗场景二、制作游戏第一个BOSS苍蝇之母 1.导入素材和制作相关动画2.制作…...

【Nginx系列】499错误
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

Springboot项目控制层注释
Springboot主流的 ----------------------- 简略写法 package com.dx.wlmq.controller;import com.dx.wlmq.domain.Address; import com.dx.wlmq.service.AddresssService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.b…...

从Docker容器中备份整个PostgreSQL
问题 现在需要从Docker容器中备份整个PostgreSQL后,然后,使用备份文件在另外一个pg的docker容器中恢复过来。 步骤 备份旧容器中的PG # 登录到旧的PG容器中 docker exec -it postgres bash # 备份数据库 pg_dumpall -c -U postgres > dump_date %…...

从小需求看大格局:如何用技术智慧赢得客户信任
时间:2024年 10月 26日 作者:小蒋聊技术 邮箱:wei_wei10163.com 微信:wei_wei10 音频:从小需求看大格局:如何用技术智慧赢得客户信任 欢迎大家回到“小蒋聊技术”,这是一个不只是教你如何写…...

模型 支付矩阵
系列文章 分享 模型,了解更多👉 模型_思维模型目录。策略选择的收益分析工具。 1 支付矩阵的应用 1.1 支付矩阵在市场竞争策略分析中的应用 支付矩阵是一种强大的决策工具,它在多个领域的应用中都发挥着重要作用。以下是一个具体的应用案例…...

擎创科技声明
近日,我司陆续接到求职者反映,有自称是擎创科技招聘人员,冒用“上海擎创信息技术有限公司”名义,用“126.com”的邮箱向求职者发布招聘信息,要求用户下载注册APP,进行在线测评。 对此,我司郑重…...

二叉树习题其六【力扣】【算法学习day.13】
前言 书接上篇文章二叉树习题其四,这篇文章我们将基础拓展 ###我做这类文档一个重要的目的还是给正在学习的大家提供方向(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一…...

互联网的无形眼睛:浏览器指纹与隐私保护攻略
你是否曾有过这样的经历:在某个电商网站上搜索了某件商品,随后无论你打开哪个网页,都能看到与之相关的广告?或者当你再次访问某个网站时,它居然记得你之前的浏览记录?这一切,背后都有一只“看不…...

后端技术:有哪些常见的应用场景?
篇一、 原文链接:https://www.zhihu.com/question/642709585/answer/3388752666 1、数据处理和存储 后端技术可用于处理和存储大量数据,例如构建数据库系统、设计高效的数据结构、实现算法等。常见的数据库技术有关系型数据库(如MySQL、O…...

开源项目本地化实战:从Presentify翻译项目看国际化协作
1. 项目概述:一个被忽视的开源宝藏如果你是一个经常需要做演示、录屏或者线上教学的开发者、讲师或者知识分享者,那你一定遇到过这个痛点:如何在屏幕上清晰地标注你的鼠标点击、按键操作,让观众能毫不费力地跟上你的思路ÿ…...
:从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级)
Midjourney版本战争白皮书(V7终结篇 vs V8统治纪元):从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级
更多请点击: https://intelliparadigm.com 第一章:V7终结篇与V8统治纪元的战略分水岭 V7 版本的正式 EOL(End-of-Life)标志着一个技术周期的谢幕,而 V8 的全面 GA(General Availability)则开启…...

LangChain+FAISS 向量数据库搭建轻量化 RAG 应用
📝 本章学习目标:本章聚焦企业轻量化落地,帮助读者快速掌握基于 LangChainFAISS 的私有化 RAG 开发流程。通过本章学习,你将从零搭建一套无需 GPU、无外网依赖、纯本地运行、代码极简、可直接上线的轻量化 RAG 应用。 一、引言&a…...
)
Codex入门10-Goal自主任务(进阶必学:设定目标就不管了,AI自己干活到完成)
🎯 本文目标 掌握 /goal 持久化任务系统,让 Codex 自主完成复杂的大型工作。 🤔 /goal 和普通对话有什么区别? 对比 普通对话 /goal 任务 交互方式 一问一答 设定目标后AI自主工作 持久性 关终端就中断 关终端也能继续 适合任务 小任务、即时反馈 大任务、长期执行 计划…...

开源高级提示词数据库:一键部署,解锁AI生产力
1. 项目概述:一个开箱即用的高级提示词数据库如果你和我一样,经常在ChatGPT、Claude或者Midjourney这类AI工具里折腾,那你肯定明白一个道理:好的提示词(Prompt)就是生产力。但问题来了,那些真正…...

ctf show web 入门46
这道题目是上一题的升级版,过滤条件变得更加苛刻了。我们来分析一下新增的限制以及应对方案。 代码审计与变化 相比之前,正则过滤 preg_match 新增了以下内容: [0-9]:禁止使用任何数字。这意味着 $IFS$9 这种绕过方式失效了。 \$&…...

通过 curl 命令在 Ubuntu 终端快速测试 Taotoken 的 API 连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令在 Ubuntu 终端快速测试 Taotoken 的 API 连通性 在服务器或容器环境中进行开发或部署时,直接使用 curl…...

UniversalUnityDemosaics:Unity游戏马赛克去除全攻略
UniversalUnityDemosaics:Unity游戏马赛克去除全攻略 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics …...

Tailark部署指南:从开发到生产环境的完整流程
Tailark部署指南:从开发到生产环境的完整流程 【免费下载链接】cnblocks Shadcn marketing blocks 项目地址: https://gitcode.com/gh_mirrors/cn/cnblocks Tailark是一个专为现代营销网站打造的响应式组件库,基于shadcn/ui、Tailwind CSS和Next.…...

Azure OpenAI代理:无缝迁移OpenAI应用到Azure云服务
1. 项目概述如果你正在使用或开发基于OpenAI官方API的应用,比如各种ChatGPT Web UI、LangChain应用,但同时又想利用微软Azure OpenAI Service在合规性、稳定性、网络延迟或成本控制上的优势,那么你大概率会遇到一个头疼的问题:这两…...