【设计模式】使用python 实践框架设计
-
单一职责原则(SRP):一个类应该只有一个职责,意味着该类只应该有一个引起变化的原因。这使得代码更易于维护和理解。
-
开放封闭原则(OCP):软件实体(类、模块、函数等)应该对扩展开放,对修改封闭。这意味着可以通过添加新代码来扩展功能,而不是修改现有代码。
-
里氏替换原则(LSP):子类对象应该能够替换父类对象而不影响程序的正确性。这要求子类必须完全实现父类的行为。
-
接口隔离原则(ISP):不应强迫一个类依赖于它不使用的接口。多个特定客户端接口要好于一个通用接口。
-
依赖反转原则(DIP):高层模块不应该依赖于低层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
-
合成复用原则(CRP):优先使用对象组合而不是继承来达到复用的目的。组合可以提供更灵活的解决方案,并且避免了继承带来的复杂性。
结合机器学习中大模型微调的数据处理场景,尝试梳理学习以下设计模式:
- 模板方法模式 (Template Method):在方法中定义算法框架。
- 策略模式 (Strategy):定义一系列算法,使算法可以互换,提高系统的灵活性。
- 组合模式 (Composite):部分-整体层次关系,简化对复杂树形结构的操作。
- 适配器模式 (Adapter):将一个接口转换为另一个接口,解决不兼容接口的问题,增加系统的可复用性。
- 建造者模式 (Builder):构建复杂对象的步骤,逐步配置对象,便于管理和扩展。
- 工厂方法模式 (Factory Method):需要创建对象时,子类决定具体类,增加新形状时,不需要修改现有代码,只需实现新类。
#coding:utf8
import pandas as pd
from abc import ABC, abstractmethod
import jsonclass Trainset:def __init__(self):self.raw_data_path = Noneself.feature_column_list = Noneself.label_strategy = Noneself.trainset_ratio = Noneself.train_data = Noneself.test_data = Noneself.oversample = Noneself.data_format = Nonedef __str__(self):return f"raw data path: {self.raw_data_path}\nfeature_column_list: {self.feature_column_list}\nlabel_strategy: {self.label_strategy}\n" \f"trainset_ratio: {self.trainset_ratio}\ntrain_df: {len(self.train_data)}\ntest_df: {len(self.test_data)}\nsample:\n{self.train_data.iloc[7]}"def save_train_data(self, path):with open(path, "w", encoding="utf8") as fout:for i in range(len(self.train_data)):fout.write(self.train_data.iloc[i]+"\n")def save_test_data(self, path):with open(path, "w", encoding="utf8") as fout:for i in range(len(self.test_data)):fout.write(self.test_data.iloc[i] + "\n")
class LabelStrategy(ABC):@staticmethod@abstractmethoddef gen_label(row):passclass ImportantType1(LabelStrategy):@staticmethoddef gen_label(row):if row['是否重要新闻标签'] == 1 and row['判断条件一'] == 'Y':return 1else:return 0class ImportantType2(LabelStrategy):@staticmethoddef gen_label(row):if row['是否重要新闻标签'] == 1 and row['判断条件二'] == 'Y':return 1else:return 0class ImportantType3(LabelStrategy):@staticmethoddef gen_label(row):if row['是否重要新闻标签'] == 1 and row['判断条件三'] == 'Y':return 1else:return 0class ImportantType4(LabelStrategy):@staticmethoddef gen_label(row):if row['是否重要新闻标签'] == 1 and row['判断条件四'] == 'Y':return 1else:return 0class DataFormat(ABC):@staticmethod@abstractmethoddef transform(row):passclass BertDataFormat(DataFormat):@staticmethoddef transform(row):return str(row['label']) + "\t" + row["feature"]class QwenDataFormat(DataFormat):prompt = "请判断以下新闻会不会对对应股票价格造成重大负面影响,造成股价异常下跌?会导致股价大幅下跌输出1,不会输出0。新闻为:"@classmethod# classmethod和staticmethod的共同的是可以不实例化类就调用类内方法,区别是classmethod可以通过cls使用类内变量,而staticmethod无法调用类内变量def transform(cls, row):return json.dumps({"type": "chatml", "message":[{"role": "user", "content": cls.prompt+row['feature']},{"role": "assistant", "content": str(row['label'])}],"source": "self-made"}, ensure_ascii=False)class TrainsetBuilder:def __init__(self):self.trainset = Trainset()self.train_df = Noneself.test_df = Noneself.data_format_dict = {'bert': BertDataFormat,'qwen': QwenDataFormat}def set_data_path(self, raw_data_path):self.trainset.raw_data_path = raw_data_pathreturn selfdef set_feature(self, feature_column_list):self.trainset.feature_column_list = feature_column_listreturn selfdef set_label_strategy(self, label_strategy):self.trainset.label_strategy = label_strategyreturn selfdef set_trainset_ratio(self, ratio):self.trainset.trainset_ratio = ratioreturn selfdef set_data_format(self, data_format):self.trainset.data_format = data_formatreturn selfdef set_oversample(self, oversample=True):self.trainset.oversample = oversamplereturn selfdef balance_label(self):pos_df = self.train_df[self.train_df['label'].isin([1])]neg_df = self.train_df[self.train_df['label'].isin([0])]if len(neg_df) > 1.5 * len(pos_df):oversampel_ratio = int(len(neg_df)/len(pos_df))print(f"pos:{len(pos_df)}, neg:{len(neg_df)}, oversampel_ratio:{oversampel_ratio}")pos_df = pd.concat([pos_df] * oversampel_ratio, ignore_index=True)elif len(pos_df) > 1.5 * len(neg_df):oversampel_ratio = int(len(pos_df) / len(neg_df))print(f"pos:{len(pos_df)}, neg:{len(neg_df)}, oversampel_ratio:{oversampel_ratio}")neg_df = pd.concat([neg_df] * oversampel_ratio, ignore_index=True)train_df = pd.concat([pos_df, neg_df])self.train_df = train_df.sample(frac=1, random_state=87).reset_index(drop=True)def build(self):data_df = pd.read_csv(self.trainset.raw_data_path, encoding="gbk")data_df['feature'] = data_df.apply(lambda row: ",".join([row[i] for i in self.trainset.feature_column_list]), axis=1)data_df['label'] = data_df.apply(lambda row: self.trainset.label_strategy.gen_label(row), axis=1)data_df = data_df[['feature', 'label']]data_df = data_df.sample(frac=1, random_state=42).reset_index(drop=True)self.train_df = data_df.head(int(len(data_df) * self.trainset.trainset_ratio))self.test_df = data_df.tail(len(data_df) - len(self.train_df))if self.trainset.oversample:self.balance_label()self.trainset.train_data = self.train_df.apply(lambda row: self.data_format_dict.get(self.trainset.data_format, BertDataFormat).transform(row), axis=1)print(type(self.trainset.train_data))print(self.trainset.train_data)self.trainset.test_data = self.test_df.apply(lambda row: self.data_format_dict.get(self.trainset.data_format, BertDataFormat).transform(row), axis=1)return self.trainsetif __name__ == "__main__":builder = TrainsetBuilder()trainset = (builder.set_data_path("./raw_data/outputresult.csv").set_feature(['新闻标题']).set_label_strategy(ImportantType4) #ImportantType1, ImportantType2, ImportantType3, ImportantType4.set_trainset_ratio(0.8).set_oversample(True).set_data_format('bert') #bert, qwen.build())print(trainset)output_dir = "./data/"trainset.save_train_data(output_dir + "bert_train.tsv")trainset.save_test_data(output_dir + "bert_test.tsv")相关文章:

【设计模式】使用python 实践框架设计
单一职责原则(SRP):一个类应该只有一个职责,意味着该类只应该有一个引起变化的原因。这使得代码更易于维护和理解。 开放封闭原则(OCP):软件实体(类、模块、函数等)应该…...

Apache paimon-CDC
CDC集成 paimon支持五种方式通过模式转化数据提取到paimon表中。添加的列会实时同步到Paimon表中 MySQL同步表:将MySQL中的一张或多张表同步到一张Paimon表中。MySQL同步数据库:将MySQL的整个数据库同步到一个Paimon数据库中。API同步表:将您的自定义DataStream输入同步到一…...

如何分析算法的执行效率和资源消耗
分析算法的执行效率和资源消耗可以从以下几个方面入手: 一、时间复杂度分析 定义和概念 时间复杂度是衡量算法执行时间随输入规模增长的速度的指标。它通常用大 O 符号表示,表示算法执行时间与输入规模之间的关系。例如,一个算法的时间复杂度为 O(n),表示该算法的执行时间…...

提示工程(Prompt Engineering)指南(进阶篇)
在 Prompt Engineering 的进阶阶段,我们着重关注提示的结构化、复杂任务的分解、反馈循环以及模型的高级特性利用。随着生成式 AI 技术的快速发展,Prompt Engineering 已经从基础的单一指令优化转向了更具系统性的设计思维,并应用于多轮对话、…...
——FFmpeg源码中,解码Audio Tag的AudioTagHeader,并提取AUDIODATA的实现)
音视频入门基础:FLV专题(19)——FFmpeg源码中,解码Audio Tag的AudioTagHeader,并提取AUDIODATA的实现
一、引言 从《音视频入门基础:FLV专题(18)——Audio Tag简介》可以知道,未加密的情况下,FLV文件中的一个Audio Tag Tag header AudioTagHeader AUDIODATA。本文讲述FFmpeg源码中是怎样解码Audio Tag的AudioTagHead…...

前端零基础入门到上班:【Day3】从零开始构建网页骨架HTML
HTML 基础入门:从零开始构建网页骨架 目录 1. 什么是 HTML?HTML 的核心作用 2. HTML 基本结构2.1 DOCTYPE 声明2.2 <html> 标签2.3 <head> 标签2.4 <body> 标签 3. HTML 常用标签详解3.1 标题标签3.2 段落和文本标签3.3 链接标签3.4 图…...

字符脱敏工具类
1、字符脱敏工具类 import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils;/*** 数据脱敏工具类** date 2024/10/30 13:44*/Slf4j public class DataDesensitizationUtils {public static final String STAR_1 "*";public static final …...

【jvm】jvm对象都分配在堆上吗
目录 1. 说明2. 堆上分配3. 栈上分配(逃逸分析和标量替换)4. 方法区分配5. 直接内存(非堆内存) 1. 说明 1.JVM的对象并不总是分配在堆上。2.堆是JVM用于存储对象实例的主要内存区域,存在一些特殊情况,对象…...

@AutoWired和 @Resource原理深度分析!
嗨,你好呀,我是猿java Autowired和Resource是 Java程序员经常用来实现依赖注入的两个注解,这篇文章,我们将详细分析这两个注解的工作原理、使用示例和它们之间的对比。 依赖注入概述 依赖注入是一种常见的设计模式,…...

C++设计模式创建型模式———原型模式
文章目录 一、引言二、原型模式三、总结 一、引言 与工厂模式相同,原型模式(Prototype)也是创建型模式。原型模式通过一个对象(原型对象)克隆出多个一模一样的对象。实际上,该模式与其说是一种设计模式&am…...
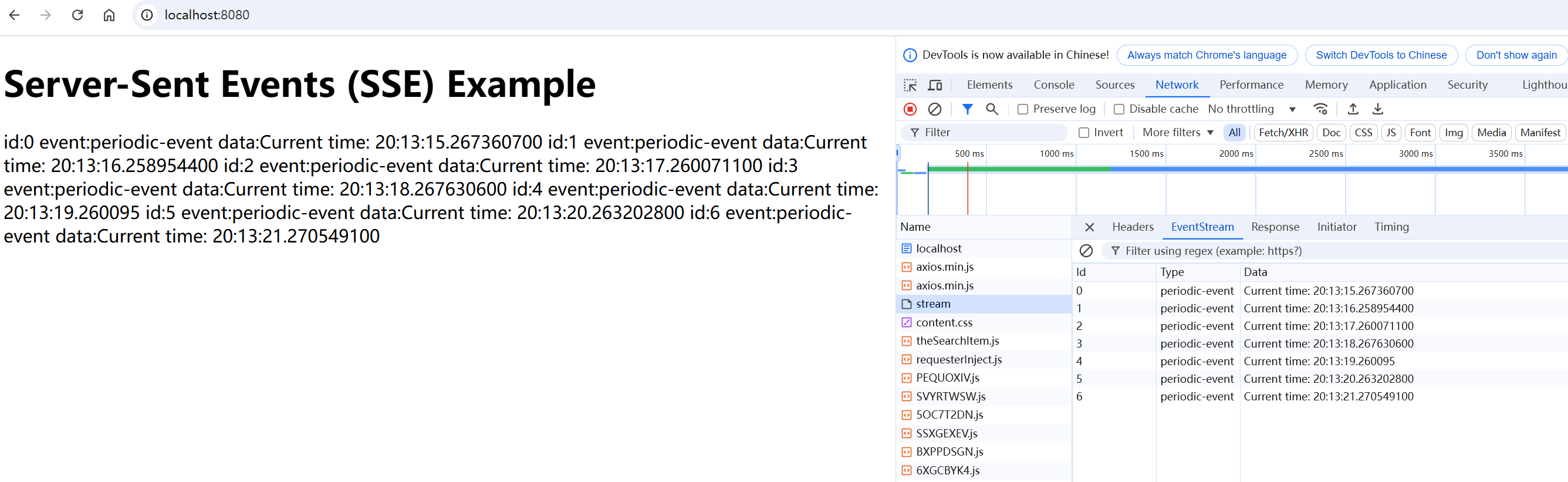
重学SpringBoot3-Spring WebFlux之SSE服务器发送事件
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ Spring WebFlux之SSE服务器发送事件 1. 什么是 SSE?2. Spring Boot 3 响应式编程与 SSE为什么选择响应式编程实现 SSE? 3. 实现 SSE 的基本步骤3.…...

YOLO即插即用模块---AgentAttention
Agent Attention: On the Integration of Softmax and Linear Attention 论文地址:https://arxiv.org/pdf/2312.08874 问题: 普遍使用的 Softmax 注意力机制在视觉 Transformer 模型中计算复杂度过高,限制了其在各种场景中的应用。 方法&a…...

探索开源语音识别的未来:高效利用先进的自动语音识别技术20241030
🚀 探索开源语音识别的未来:高效利用自动语音识别技术 🌟 引言 在数字化时代,语音识别技术正在引领人机交互的新潮流,为各行业带来了颠覆性的改变。开源的自动语音识别(ASR)系统,如…...

学习路之TP6--workman安装
一、安装 首先通过 composer 安装 composer require topthink/think-worker 报错: 分析:最新版本需要TP8,或装低版本的 composer require topthink/think-worker:^3.*安装后, 增加目录 vendor\workerman vendor\topthink\think-w…...

.NET内网实战:通过白名单文件反序列化漏洞绕过UAC
01阅读须知 此文所节选自小报童《.NET 内网实战攻防》专栏,主要内容有.NET在各个内网渗透阶段与Windows系统交互的方式和技巧,对内网和后渗透感兴趣的朋友们可以订阅该电子报刊,解锁更多的报刊内容。 02基本介绍 03原理分析 在渗透测试和红…...

AI Agents - 自动化项目:计划、评估和分配
Agents: Role 角色Goal 目标Backstory 背景故事 Tasks: Description 描述Expected Output 期望输出Agent 代理 Automated Project: Planning, Estimation, and Allocation Initial Imports 1.本地文件helper.py # Add your utilities or helper functions to…...

Git的.gitignore文件
一、各语言对应的.gitignore模板文件 项目地址:https://github.com/github/gitignore 二、.gitignore文件不生效 .gitignore文件只是ignore没有被追踪的文件,已被追踪的文件,要先删除缓存文件。 # 单个文件 git rm --cached file/path/to…...

网站安全,WAF网站保护暴力破解
雷池的核心功能 通过过滤和监控 Web 应用与互联网之间的 HTTP 流量,功能包括: SQL 注入保护:防止恶意 SQL 代码的注入,保护网站数据安全。跨站脚本攻击 (XSS):阻止攻击者在用户浏览器中执行恶意脚本。暴力破解防护&a…...

深度学习:梯度下降算法简介
梯度下降算法简介 梯度下降算法 我们思考这样一个问题,现在需要用一条直线来回归拟合这三个点,直线的方程是 y w ^ x b y \hat{w}x b yw^xb,我们假设斜率 w ^ \hat{w} w^是已知的,现在想要找到一个最好的截距 b b b。 一条…...

SparkSQL整合Hive后,如何启动hiveserver2服务
当spark sql与hive整合后,我们就无法启动hiveserver2的服务了,每次都要先启动hive的元数据服务(nohup hive --service metastore)才能启动hive,之前的beeline命令也用不了,hiveserver2的无法启动,这也导致我…...

为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升
为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升 【免费下载链接】shortkeys A browser extension for custom keyboard shortcuts 项目地址: https://gitcode.com/gh_mirrors/sh/shortkeys 每天在浏览器上,我们花费大量时间…...

GOAT-PEFT:模块化PEFT工具箱,让大模型微调像搭积木一样简单
1. 项目概述:当大模型遇上“轻量级”微调如果你最近在关注大语言模型(LLM)的应用落地,尤其是想在有限的算力资源下,让一个像Llama、ChatGLM这样的“庞然大物”学会你的专属知识或特定任务,那么“微调”这个…...

CxFlatUI——一款开源免费、现代化的 WinForm UI 控件库
文章目录一、前言二、项目概述三、应用场景四、功能模块五、功能特点六、功能演示七、源码地址一、前言 对于仍在使用 WinForms 技术栈构建企业内部系统、工具软件、桌面管理端、工业控制端或数据录入客户端的团队而言,传统 WinForms 默认控件在视觉表现、交互质感…...

2026年录音转换文字的软件推荐:从微信小程序到专业工具的实用对比
做视频或音频素材处理的时候,经常卡在这几个环节:转出来的文字有错别字需要反复核对、处理一个长视频得等半天、格式导出后没法直接用到其他软件。这些都是常见的痛点。本文会从实际应用出发,先重点讲一个相对高效的方案——微信小程序提词匠…...

十年后,编程还会是人类的工作吗?
一个正在被重写的职业剧本站在2026年的中点眺望2036年,没有人能准确预言未来。但作为软件测试从业者,我们或许是离“编程工作是否会被取代”这个答案最近的一群人。因为我们每天的工作,就是审视代码的边界、挖掘逻辑的漏洞、评估系统的风险。…...

Rails控制台集成AI助手:ask_chatgpt Gem的实践指南
1. 项目概述:在Rails控制台里装一个AI助手 如果你是一个Ruby on Rails开发者,并且每天都在跟Rails控制台( rails console )打交道,那你肯定有过这样的时刻:盯着一段复杂的ActiveRecord查询,或…...

淘金币自动化脚本:3分钟完成淘宝全任务,每天节省20分钟
淘金币自动化脚本:3分钟完成淘宝全任务,每天节省20分钟 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojin…...

如何在Windows上快速安装安卓应用:APK Installer终极指南
如何在Windows上快速安装安卓应用:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想要在Windows电脑上运行安卓应用&…...

602 游戏平台 — 做玩家喜爱、信任的游戏平台!
602 游戏是2013 年上线的老牌正规页游平台,十年稳定运营,始终以 “玩家喜爱、信任”为核心,主打传奇类精品页游 ,三端互通✅ 平台核心优势(为什么玩家信任)正规合规,账号安全:文网文…...

WPF中OxyPlot不同图表的使用
在 WPF 中使用 OxyPlot 实现不同图表,核心在于创建和配置PlotModel对象,并将其绑定到PlotView控件上进行显示。通过向PlotModel中添加不同类型的Series(数据系列),即可轻松实现折线图、柱状图、饼图、散点图等多种图表…...