大数据-204 数据挖掘 机器学习理论 - 混淆矩阵 sklearn 决策树算法评价
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(正在更新…)
章节内容
上节我们完成了如下的内容:
- 决策树 sklearn 剪枝参数
- 决策树 样本不均匀问题

混淆矩阵
从上一节的例子中可以看出,如果我们的目标是希望尽量捕获少数类,那准确率这个模型评估逐渐失效,所以我们需要新的模型评估指标来帮助我们。如果简单来看,其实我们只需要查看模型在少数类上的准确率就好了,只要能够将少数类尽量捕捉出来,就能够达到我们的目的。
但此时,新问题又出现了,我们对多数类判断错误后,会需要人工甄别或者更多的业务上的措施来一一排除我们判断错误的多数类,这种行为往往伴随着很高的成本。
比如银行在判断一个申请信用卡的客户是否会违约行为的时候,如果一个客户被判断为会违约,这个客户的信用卡申请就会驳回,如果为了捕捉会违约的人,大量地将不会违约的客户判断为会违约的客户,就会有许多无辜的客户的申请被驳回。
也就是说,单纯的追求捕捉少数类,就会成本太高,而不顾及少数类,又会无法达成模型的效果。所以在现实中,我们往往在寻找捕获少数类的能力和将多数判错后需要付出的成本的平衡。如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数判断正确,则这个模型就非常优秀了。为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵可以帮助我们。
- 混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用
- 在混淆矩阵中,我们将少数类认为时正例,多数类认为时负例
- 在决策树,随机森林这些算法里,即是说少数类是1,多数类时 0
- 在 SVM 里,就是说少数类时 1,多数类时 -1
普通的混淆里,一般使用「0,1」来表示,混淆矩阵如其名,十分容易让人混淆,在需要教材中各种各样的名称和定义让大家难以理解和记忆。

其中:
- 行代表预测情况,列则表示实际情况
- 预测值是 1,记为 P(Positive)
- 预测值是 0,记为 N(Negative)
- 预测值与真实值相同,记为 T(True)
- 预测值与真实值相反,记为 F(False)
因此矩阵中四个元素分别表示:
- TP(True Positive)真实为 1,预测为 1
- FN(False Negative)真实为 1,预测为 0
- FP(False Positive)真实为 0,预测为 1
- TN(True Negative)真实为 0,预测为 0
基于混淆矩阵,我们有一系列不同的模型评估指标,这些评估指标范围都在【0,1】之间,所以有11 和 00为分子的指标都是越来越接近 1 越好,所以 01 和 10 为分子的指标都是越来越接近 0 越好。
对于所有指标,我们用橙色表示分母,用绿色表示分子,则我们有:
准确率 Accuracy

精确度 Precision

精确度 Precision,又叫查准率,表示在所有预测结果为 1 的样例数中,实际为 1 的样例数所占比重。精确度越低,意味着 01 比重很大,则代表你的模型对多数类 0 误判率越高,误伤了过多的多数类。为了避免对多数类的误伤,需要追求高精确度。
精确度是将多数类判错后所需要付出成本的衡量
召回率 Recall
召回率 Recall,又称为敏感度(sensitivity),真正率,查全率,表示所有真实为 1 的样本中,被我们预测正确的样本所占的比例。
召回率越高,代表我们尽量捕捉出了越多的少数类。召回率越低,代表我们捕捉出足够的少数类。

我们希望不计代价,找出少数类(比如潜逃的犯罪分子),那我们会追求高召回率,相反如果我们的目标不是尽量捕获少数类,那我们就不需要在意召回率。
注意召回率和精确度的分子是相同的(都是 11),只是分母不同。
而召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需要求的平衡。
究竟要偏向哪一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,还是无法捕捉少数类的代表更高。
F1 Measure
为了同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1 Measure。
两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的F1 Measure,能够保证我们精确度和召回率都比较高。
F1 Measure 在 [0,1]之间分布,越接近 1 越好。

假负率
从 Recall 延伸出来的另一个评估指标叫做假负率(False Negative Rate),它等于 1 - Recall,用于衡量。
所有真实为 1 的样本中,被我们错误判断为 0 的,通常用的不多。

ROC 曲线
ROC 的全称是:Receiver Operating characteristic Curve,其主要的分析方法就是画这条特征曲线。

该曲线的横坐标为假正率(False Positive Rate,FPR),N 是真实负样本的个数,FP 是N 个负样本中被分类器预测为正样本的个数。

纵坐标为召回率,真正率(True Positive Rate,TPR):

P 是真实正样本的个数,TP 是 P 个正样本被分类器预测为正样本的个数。
sklearn 中的混淆矩阵

决策树的算法评价
决策树优点
- 易于理解和解释,因为树木可以画出来被看见
- 需要很少的数据准备,其他很多算法通常都需要数据规范化,需要创建虚拟变量并删除空值等。但请注意,sklearn 中的决策树模块不支持对缺失值的处理。
- 使用树的成本(比如说,在预测数据的时候)是用于训练树的数据点的数量的对数,相比于其他算法,这是一个很低的成本。
- 能够同时处理数字和分类数据,既可以做回归又可以做分类。其他技术通常专门用于分析仅具有一种变量类型的数据集。
- 即使其假设在某种程度上违反了生成数据的真实模型,也能够表现良好。
决策树缺点
- 使用决策树可能创建过于复杂的树,这些树不能很好的推广数据。这称为过度拟合,修剪,设置,叶节点所需要的最小样本数或设置树的最大深度等机制是避免此问题所必须的,而这些参数的整合和调整对初学者来说会比较晦涩。
- 决策树可能不稳定,数据中微小的变化可能导致生成完全不同的树,这个问题需要通过集成算法来解决。
- 决策树的学习是基于贪婪算法,它靠优化局部最优(每个节点最优)来试图达到整体的最优,但这种做法不能保证返回全局的最优,这个问题也可以由集成算法来解决,在随机森林中,特征和样本会在分支过程中被随机采样。
- 如果标签中的某些类占主导地位,决策树学习会创建偏向主导类的树。因此,建议拟合决策树之前平衡数据集。
相关文章:
大数据-204 数据挖掘 机器学习理论 - 混淆矩阵 sklearn 决策树算法评价
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

Fsm1
为了处理有时间上先后的事件,在FPGA中采用状态机的形式完成事件处理。 Mealy 状态机:输出不仅取决于当前状态,还取决于输入状态。 Moore 状态机:组合逻辑的输出只取决于当前状态,而与输入状态无关。 二段式状态机&…...

C. Gorilla and Permutation
time limit per test 2 seconds memory limit per test 256 megabytes Gorilla and Noobish_Monk found three numbers nn, mm, and kk (m<km<k). They decided to construct a permutation†† of length nn. For the permutation, Noobish_Monk came up with the …...

从0开始学python-day17-数据结构2
2.3 队列 队列(Queue),它是一种运算受限的线性表,先进先出(FIFO First In First Out) 队列是一种受限的线性结构 受限之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作 P…...
—— 编程基础)
(蓝桥杯C/C++)—— 编程基础
文章目录 一、C基础格式 1.打印hello, world 2.基本数据类型 二、string 1.string简介 2.string的声明和初始化 3.string其他基本操作 (1)获取字符串长度 (2) 拼接字符串( 或 append) (3)字符串查找(find) (4)字符串替换 (5)提取子字符串…...
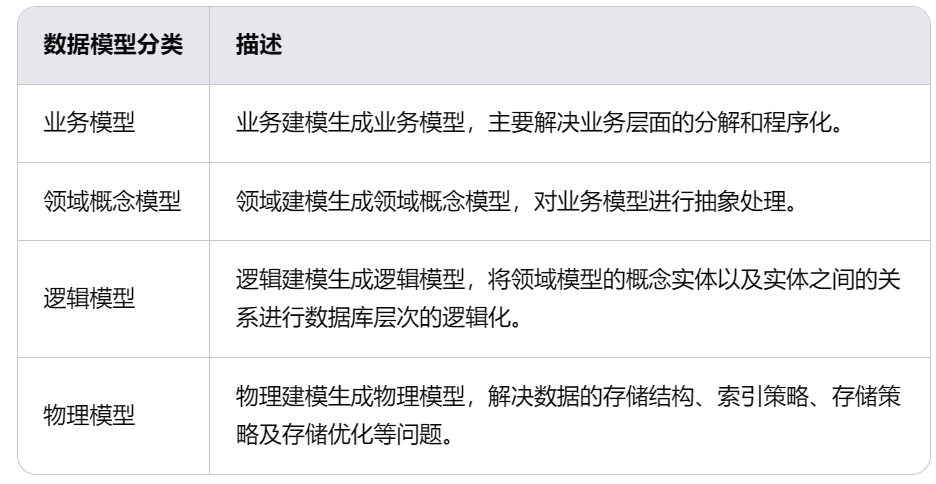
企业物流管理数据仓库建设的全面指南
文章目录 一、物流管理目标二、总体要求三、数据分层和数据构成(1)数据分层(2)数据构成 四、数据存储五、数据建模和数据模型(1)数据建模(2)数据模型 六、总结 在企业物流管理中&…...

数据采集-Kepware 安装证书异常处理
这里写目录标题 一、 问题描述二、原因分析三、处理方案3.1 1.执行根证书的更新3.2 安装KepServerEx 资源 一、 问题描述 在进行KepServerEx进行安装的情况下,出现了如下的报错: The installer was unable to find required root certificates ,please …...

ubuntu禁止自动更新设置
背景概述 从CentOS变更到uBuntu或多或少会遇到一些坑,今天分享一个。 在Ubuntu系统中,自动更新是一个既方便又引发争议的功能。它可以帮助用户保持系统的最新状态,但有时也会因为自动更新而导致系统不稳定或不兼容。 Ubuntu系统的自动更新主…...

Rust 力扣 - 1461. 检查一个字符串是否包含所有长度为 K 的二进制子串
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 长度为k的二进制子串所有取值的集合为[0, sum(k)],其中sum(k)为1 2 4 … 1 << (k - 1) 我们只需要创建一个长度为sum(k) 1的数组 f ,其中下标为 i 的元素用来标记字符串中子串…...
C#/.NET/.NET Core技术前沿周刊 | 第 11 期(2024年10.21-10.31)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。 欢迎投稿、推荐…...

unity 三维数学 ,角度 弧度计算
弧度 角度*π/180...
Java基础4-控制流程
控制流程 Java使用条件语句和循环结构确定控制流程。基本和C一样,但是没有goto语句,但break语句可以有标签,用于跳出内层循环。 块作用域(block) 块(即复合语句)是指由一堆花括号括起来的若干…...
面试题分享11月1日
1、过滤器和拦截器的区别 过滤器是基于spring的 拦截器是基于Java Web的 2、session 和 cookie 的区别、关系 cookie session 存储位置 保存在浏览器 (客户端) 保存在服务器 存储数据大小 限制大小,存储数据约为4KB 不限制大小&…...

【含文档】基于ssm+jsp的学科竞赛系统(含源码+数据库+lw)
1.开发环境 开发系统:Windows10/11 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql5.7或8.0 数据库可视化工具: navicat 服务器: apache tomcat 主要技术: Java,Spring,SpringMvc,mybatis,mysql,vue 2.视频演示地址 3.功能 系统定义了四个…...

Docker方式部署ClickHouse
Docker方式部署ClickHouse ClickHouse docker 版本镜像:https://docker.aityp.com/r/docker.io/clickhouse/clickhouse-server ClickHouse 21.8.13.6 docker 版本镜像:https://docker.aityp.com/image/docker.io/clickhouse/clickhouse-server:21.8.13.…...

车载通信架构 --- PNC、UB与信号的关系
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 所有人的看法和评价都是暂时的,只有自己的经历是伴随一生的,几乎所有的担忧和畏惧,都是来源于自己的想象,只有你真的去做了,才会发现有多快乐。…...

智慧农业云平台:大数据赋能现代农业的未来
近年来,随着科技的迅速发展,农业作为传统行业正面临着前所未有的变革。智慧农业,作为现代农业发展的重要方向,借助云计算、大数据、物联网等技术,正在为农业生产、管理和服务提供全新的解决方案。在这个背景下…...

【python】OpenCV—Tracking(10.4)—Centroid
文章目录 1、任务描述2、人脸检测模型3、完整代码4、结果展示5、涉及到的库函数6、参考 1、任务描述 基于质心实现多目标(以人脸为例)跟踪 人脸检测采用深度学习的方法 核心步骤: 步骤#1:接受边界框坐标并计算质心 步骤#2&…...
2倍MSL)
为什么TCP(TIME_WAIT)2倍MSL
为什么TCP(TIME_WAIT)2倍MSL 一、TCP关闭连接的四次挥手流程进入TIME_WAIT 二、TIME_WAIT状态的意义1. 确保ACK报文到达对方2. 防止旧报文干扰新连接 三、为什么是2倍MSL四、TIME_WAIT的图解五、TIME_WAIT在实际应用中的影响总结 在TCP连接的关闭过程中&…...

jieba-fenci 05 结巴分词之简单聊一聊
拓展阅读 DFA 算法详解 为了便于大家学习,项目开源地址如下,欢迎 forkstar 鼓励一下老马~ 敏感词 sensitive-word 分词 segment 分词系列专题 jieba-fenci 01 结巴分词原理讲解 segment jieba-fenci 02 结巴分词原理讲解之数据归一化 segment jieba…...

B站视频转换神器:5分钟掌握m4s到MP4的无损转换
B站视频转换神器:5分钟掌握m4s到MP4的无损转换 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站缓存视频无法在其他播放器播…...

助睿平台-零代码实现订单利润数据分流加工
一.实验背景 1.1 实验目的 本次实验旨在熟悉助睿零代码数据集成平台(ETL平台)的核心功能和操作方法,具体包括: 掌握新建转换、添加组件、执行转换等基本操作流程 熟悉表输入、记录集连接、字段选择、过滤记录、Excel输出等常用…...

从内存条到手机主板:盘点不同场景下过孔尺寸选择的实战经验与避坑指南
从内存条到手机主板:不同场景下过孔尺寸选择的实战经验与避坑指南 在高速PCB设计中,过孔的选择往往被工程师视为"细节问题",但正是这些看似微小的设计决策,决定了产品的信号完整性、电源完整性和最终可靠性。从内存条的…...
)
ESP32玩转1.8寸LCD屏:用TFT_eSPI库做个桌面小时钟(附完整代码)
ESP32打造高颜值桌面时钟:从TFT_eSPI库到完整项目实战 在创客的世界里,将硬件与代码结合创造出实用又有趣的项目总是令人兴奋。今天我们要用ESP32开发板和1.8寸ST7735驱动的LCD屏幕,打造一个功能完善、界面美观的桌面电子时钟。这个项目不仅适…...

如何快速掌握JASP统计分析软件:3个高效使用技巧完整指南
如何快速掌握JASP统计分析软件:3个高效使用技巧完整指南 【免费下载链接】jasp-desktop JASP aims to be a complete statistical package for both Bayesian and Frequentist statistical methods, that is easy to use and familiar to users of SPSS 项目地址:…...

用STM32F103和继电器DIY智能家居:低成本改造台灯/风扇的保姆级教程
用STM32F103和继电器DIY智能家居:低成本改造台灯/风扇的保姆级教程 智能家居的概念早已不再遥不可及,借助STM32F103这样的低成本微控制器和简单的继电器模块,任何人都能将普通家电升级为智能设备。本文将手把手教你如何将一个普通台灯或风扇改…...

Discovery与Kubernetes深度集成:实现容器化微服务注册发现的终极指南
Discovery与Kubernetes深度集成:实现容器化微服务注册发现的终极指南 【免费下载链接】discovery A registry for resilient mid-tier load balancing and failover. 项目地址: https://gitcode.com/gh_mirrors/discov/discovery 在当今云原生时代࿰…...
)
昇腾310开发板内存告急?手把手教你在Ubuntu虚拟机上离线转换YOLOv5模型(非root用户避坑指南)
昇腾310开发板内存告急?Ubuntu虚拟机离线转换YOLOv5模型全攻略 当开发者手头只有一块内存有限的昇腾310开发板时,模型转换工作往往会遇到硬件资源不足的困境。本文将详细介绍如何在普通x86架构的Ubuntu虚拟机上,完成YOLOv5模型的离线转换全流…...
)
终身机器学习的起源:为什么 LLML 是 AI 领域的下一个游戏改变者(第一部分)
原文:towardsdatascience.com/the-origins-of-lifelong-ml-part-1-of-why-llml-is-the-next-game-changer-of-ai-8dacf9897143?sourcecollection_archive---------12-----------------------#2024-01-17 通过 Q 学习和基于解释的神经网络理解终身机器学习的力量 h…...

VBS转VBE不只是加密:聊聊Scripting.Encoder的‘黑历史’与现代替代方案
VBS转VBE:从Scripting.Encoder的兴衰到现代脚本保护方案 在Windows脚本技术的发展长河中,VBScript(VBS)曾经是自动化任务和系统管理的重要工具。而与之相伴的VBE(VBScript Encoded)格式,则承载着…...