11.Three.js使用indexeddb前端缓存模型优化前端加载效率
11.Three.js使用indexeddb前端缓存模型优化前端加载效率
1.简述
在使用Three.js做数字孪生应用场景时,我们常常需要用到大量模型或数据。在访问我们的数字孪生应用时,每次刷新都需要从web端进行请求大量的模型数据或其他渲染数据等等,会极大的消耗时间,用户体验不好,因而我们可以通过indexeddb缓存我们的模型数据。
2.indexeddb简介
indexeddb 介绍和学习可以参考这里:https://zhuanlan.zhihu.com/p/429086021
IndexedDB主要用来客户端存储大量数据而生的,我们都知道cookie、localstorage等存储方式都有存储大小限制。如果数据量很大,且都需要客户端存储时,那么就可以使用IndexedDB数据库。它是一种前端的非关系型数据库,同样具有增删改查的功能。我下面封装了一个工具类dbUtils.js对模型数据进行缓存:
const DB_NAME = 'modeldb'; //数据库名称
const DB_VERSION = 1; //数据库版本号
const DB_STORE_NAME = 'model_glb_table'; //数据库仓库function DBUtil() {this.db = null;// 根据模型的url地址,请求模型// 如果没有数据库中没有模型,则请求模型并放入缓存中,返回promise,带有模型的blob文件对象// 如果如果缓存中有模型了,就直接从缓存中取出this.get = async (url, onProgress) => {this.db = await this.initDataBase();let getRequest = this.db.transaction([DB_STORE_NAME], "readwrite") // 事务对象 指定表格名称和操作模式("只读"或"读写").objectStore(DB_STORE_NAME) // 仓库对象.get(url); // 通过主键(url)获取数据let that = this;return new Promise((resolve, reject) => {getRequest.onsuccess = function (event) {let modelFile = event.target.result;// 假如已经有缓存了 直接用缓存if (modelFile) {if (onProgress) {onProgress(100);}console.log("使用缓存");resolve(modelFile.blob)} else {// 假如没有缓存 请求新的模型存入that.put(url, onProgress).then((blob) => {resolve(blob)}).catch(() => {reject()});}};getRequest.onerror = function (event) {// console.log('error', event)reject()}})}// 请求模型并放入缓存中this.put = async (url, onProgress) => {const response = await fetch(url);if (response.status !== 200) {throw new Error('Request failed');}const contentLength = response.headers.get('Content-Length');// console.log(contentLength)const totalBytes = parseInt(contentLength, 10);let downloadedBytes = 0;const readableStream = response.body;const { readable, writable } = new TransformStream();const writer = writable.getWriter();const reader = readableStream.getReader();const pump = async () => {const { done, value } = await reader.read();if (done) {writer.close();return;}writer.write(value);downloadedBytes += value.length;if (onProgress) {const progress = (downloadedBytes / totalBytes) * 100;console.log(progress.toFixed(2))onProgress(progress.toFixed(2));}return pump();};await pump();let blob = null;try {blob = await new Response(readable).arrayBuffer();} catch (e) {console.log('请求arrayBuffer失败,用blob方式')blob = await new Response(readable).blob();}let obj = {ssn: url}obj.blob = new Blob([blob])const inputRequest = this.db.transaction([DB_STORE_NAME], "readwrite").objectStore(DB_STORE_NAME).add(obj);return new Promise((resolve, reject) => {inputRequest.onsuccess = function () {console.log('glb数据添加成功');resolve(obj.blob);};inputRequest.onerror = function (evt) {console.log('glb数据添加失败', evt);reject();};});}// 打开数据库this.initDataBase = () => {if (!window.indexedDB) {console.log("浏览器不支持indexedDB缓存!!!")return;}let request = indexedDB.open(DB_NAME, DB_VERSION); //如果没有数据库,则创建,有数据库就链接return new Promise((resolve, reject) => {request.onerror = function () {// console.log("error: create db error");reject()};// 数据库创建或升级的时候会触发request.onupgradeneeded = function (evt) {evt.currentTarget.result.createObjectStore(DB_STORE_NAME, { keyPath: 'ssn' });};// 数据库打开成功回调request.onsuccess = function (evt) {// console.log("onsuccess: create db success ");resolve(evt.target.result)};})}
}
3.Three.js加载模型
原本的three.js加载模型如下,这是最基础的加载模型的方法:
function initObject() {//再加载模型const objLoader = new THREE.GLTFLoader();objLoader.load("./data/Soldier.glb",function (gltf) {let root = gltf.scene;root.position.set(0,0,0);root.scale.set(100,100,100);scene.add(root);},//加载回调function (xhr) {console.log((xhr.loaded / xhr.total) * 100 + "% loaded");},//加载失败回调function (error) {console.log("An error happened");});}
使用缓存后加载的方法:
function initObject() {new DBUtil().get("./data/Soldier.glb", (progress) => {console.log("progress", progress);}).then((blob) => {//再加载模型const objLoader = new THREE.GLTFLoader();let url = URL.createObjectURL(new Blob([blob]));objLoader.load(url, function (gltf) {let root = gltf.scene;root.position.set(0, 0, 0);root.scale.set(100, 100, 100);scene.add(root);},//加载回调function (xhr) {console.log((xhr.loaded / xhr.total) * 100 + "% loaded");},//加载失败回调function (error) {console.log("An error happened");});})}
4.验证检查
我们刷新网页后,查看应用程序中是否多了一个数据库,数据库中是否有数据

尝试删除该数据库后,再刷新页面。
对比数据库存在时,再次刷新页面。可以发现该数据库缓存存在时,模型渲染效率快了很多。特别时互联网访问时,还会有一个模型数据下载的过程,使用缓存可以直接省略下载的时间,效率上可以得到很大的提升。
视频地址:https://www.bilibili.com/video/BV1cQSzYLE9n/?vd_source=0f4eae2845bd3b24b877e4586ffda69a
相关文章:
11.Three.js使用indexeddb前端缓存模型优化前端加载效率
11.Three.js使用indexeddb前端缓存模型优化前端加载效率 1.简述 在使用Three.js做数字孪生应用场景时,我们常常需要用到大量模型或数据。在访问我们的数字孪生应用时,每次刷新都需要从web端进行请求大量的模型数据或其他渲染数据等等,会极大…...

功能测试:方法、流程与工具介绍
功能测试是对产品的各功能进行验证的一种测试方法,旨在确保软件以期望的方式运行并满足设计需求。以下是对功能测试的详细解释: 一、定义与目的 定义:功能测试(Functional Testing),也称为行为测试&#…...

【Orange Pi 5 Linux 5.x 内核编程】-设备驱动中的sysfs
设备驱动中的sysfs 文章目录 设备驱动中的sysfs1、sysfs介绍2、内核对象(kobject)介绍3、设备驱动中的SysFS31 在/sys中创建目录3.2 创建sysfs文件3.2.1 创建属性3.2.2 创建sysfs文件4、驱动程序实现5、驱动验证1、sysfs介绍 sysfs是内核导出的虚拟文件系统,类似于/proc。sys…...

微信小程序-全局数据共享/页面间通信
一.全局数据共享 声明全局的变量,在app.js文件里 App({//全局共享的数据globalData:{token:},//设置全局数据setToken(token){this.globalData.tokentoken}})使用 getApp() 获取全局App实例 //返回全局唯一的APP实例 const appInstancegetApp()Page({login(){con…...
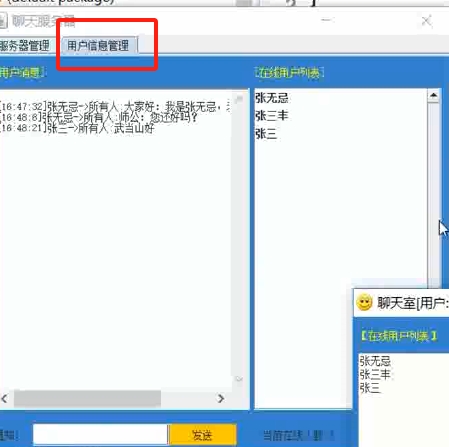
java计算机毕设课设—Java聊天室(附源码、文章、相关截图、部署视频)
这是什么系统? 资源获取方式再最下方 java计算机毕设课设—Java聊天室(附源码、文章、相关截图、部署视频) Java聊天室系统是一个基于Java语言开发的在线即时通讯平台,旨在为用户提供一个简单、易用的实时交流环境。该系统支持多用户同时在线交流&…...

图像识别基础认识
import numpy as np import pandas as pd import matplotlib.pyplot as plt import cv2 %matplotlib inline读取图像 img = cv2.imread(shuzi.png) # 显示图像 cv2.imshow(shuzi, img) # 设置窗口大小 #cv2.resizeWindow(shuzi, 800, 600) # 设置宽为800,高为600 cv2.waitKe…...

使用 OpenCV 读取和显示图像与视频
概述 OpenCV 是一个强大的计算机视觉库,广泛应用于图像处理和视频处理等领域。本文将详细介绍如何使用 OpenCV 在 Python 中读取和显示图像以及视频,并通过具体的代码示例来展示整个过程。 环境准备 在开始之前,请确保已经安装了 OpenCV 库…...

【1】Elasticsearch 30分钟快速入门
文章目录 一、Elasticsearch 基本概念及工作原理(一)基本概念(二)工作原理二、Elasticsearch 原生 RESTful 方式的增删改查(一)创建索引(二)插入文档(三)查询文档(四)更新文档(五)删除文档(六)删除索引三、Python SDK 实现增删改查(一)安装 Elasticsearch Py…...

教材管理系统设计与实现
教材管理系统设计与实现 1. 系统概述 教材管理系统是一个基于PHP和SQL的Web应用程序,旨在为学校提供一个高效的教材管理平台。该系统可以帮助管理员录入教材信息、教师查询和申请教材、学生查询教材信息,提高教材管理的效率和透明度。 2. 技术栈 前端…...

软考(中级-软件设计师)数据库篇(1101)
第6章 数据库系统基础知识 一、基本概念 1、数据库 数据库(Database ,DB)是指长期存储在计算机内的、有组织的、可共享的数据集合。数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和扩展…...
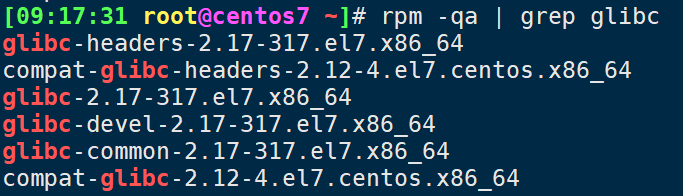
安装nscd及glibc包冲突降级【centos7】
安装nscd及glibc包冲突降级【centos7】 一、查看当前glibc版本二、查找可用的glibc版本三、备份系统和数据四、降级glibc五、验证降级是否成功六、解决其他依赖问题七、测试和验证八、考虑使用容器技术endl [08:41:07 rootcentos7 ~]# yum -y install nscd Loaded plugins: fas…...

Qt字符编码
目前字符编码有以下几种: 1、UTF-8 UTF-8编码是Unicode字符集的一种编码方式(CEF),其特点是使用变长字节数(即变长码元序列、变宽码元序列)来编码。一般是1到4个字节,当然,也可以更长。 2、UTF-16 UTF-16是Unicode字符编码五层次…...
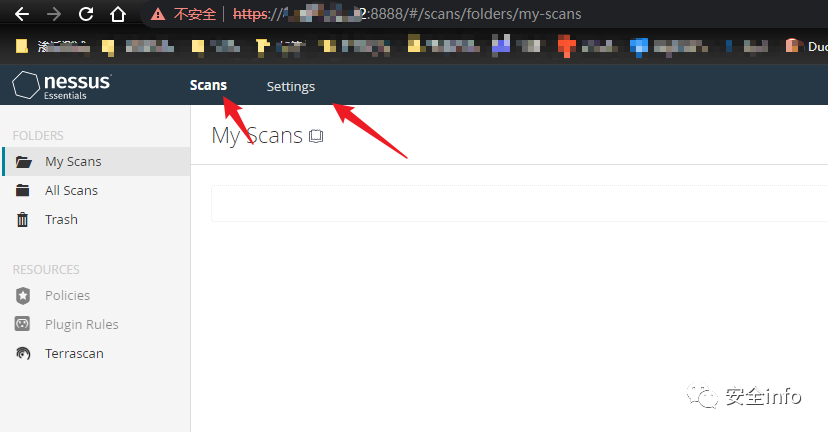
Ubuntu用docker安装AWVS和Nessus(含破解)
Ubuntu安装AWVS(更多搜索:超详细Ubuntu用docker安装AWVS和Nessus) 首先安装docker,通过dockers镜像安装很方便,且很快;Docker及Docker-Compose-安装教程。 1.通过docker search awvs命令查看镜像; docker search awvs…...

tauri开发中如果取消了默认的菜单项,复制黏贴撤销等功能也就没有了,解决办法
取消默认的菜单项:清除tauri默认的菜单项,让顶部的菜单menu不显示-CSDN博客 就是通过配置空菜单,让菜单不显示,但是这个引发的问题就是复制黏贴撤销等功能也就没有了,解决办法: 新增加编辑下的子菜单&…...

HNU-小学期-专业综合设计
写在前面 选题:大数据技术-智慧交通预测系统 项目github地址(如果有用麻烦点个star与follow):https://github.com/wolfvoid/HNU-ITPS (全部代码以及如何部署参见README) 项目报告:如下&…...

Linux安装es和kibana
安装Elasticsearch 参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/targz.html#targz-enable-indices 基本步骤下载包,解压,官网提示: wget https://artifacts.elastic.co/downloads/elasticsearc…...

第二十六章 Vue之在当前组件范围内获取dom元素和组件实例
目录 一、概述 二、获取dom 2.1. 具体步骤 2.2. 完整代码 2.2.1. main.js 2.2.2. App.vue 2.3. BaseChart.vue 三、获取组件实例 3.1. 具体步骤 3.2. 完整代码 3.2.1. main.js 3.2.2. App.vue 3.2.3. BaseForm.vue 3.3. 运行效果 一、概述 我们过去在想要获取一…...

Markdown 区块
再段落开头,使用>符号,在符号后面按空格,效果图是最左侧有一条灰色的粗线,这是一级区块 二级区块和三级区块只需要在一级的后面加>符号,就可以进入二级区块,效果如下图 还可以在区块内部签到无序列表…...

ctf文件上传题小总结与记录
解题思路:先看中间件,文件上传点(字典扫描,会员中心),绕过/验证(黑名单,白名单),解析漏洞,cms,编辑器,最新cve 文件上传漏…...

什么是QAM
什么是调制呢? 调制就是把信号形式转换成适合在信道中传输的一个过程。可分为基带调制和载波调制。我们这里所说的调制都是载波调制。 什么是载波调制呢? 就是把调制信号骑到载波上,方法就是用调制信号去控制载波的参数,使载波…...

微软DebugMCP:可视化调试MCP协议,解决AI与工具通信黑盒问题
1. 项目概述:当你的AI助手开始“自言自语”,你需要一个调试器 最近在折腾AI应用开发的朋友,估计没少跟各种“智能体”打交道。无论是基于OpenAI的GPTs,还是那些能联网、能调用工具的自定义助手,它们背后的核心通信协议…...

5秒无损转换B站缓存视频:m4s-converter完整使用指南
5秒无损转换B站缓存视频:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的学习…...

城通网盘解析工具终极指南:免费获取高速直连下载地址
城通网盘解析工具终极指南:免费获取高速直连下载地址 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的下载速度?每次下载文件都要面对漫长的等待…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

MySQL 视图使用场景与限制
视图是把查询封装成「虚拟表」的方式,用对了简化查询,用错了性能爆炸。这篇说说视图的用法和注意事项。 什么是视图? -- 视图:保存好的 SQL 查询,像表一样使用 CREATE VIEW view_name AS SELECT column1, column2 FROM…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...

数据中心碳减排:工作负载迁移与服务器调度优化
1. 数据中心碳减排技术概述 在数字经济时代,数据中心作为信息基础设施的核心载体,其能源消耗和碳排放问题日益凸显。据统计,全球数据中心电力消耗已占全球总用电量的1-2%,且随着AI、云计算等技术的快速发展,这一比例仍…...

开源提示词管理工具:本地化部署与AI工作流效率提升实践
1. 项目概述:一个为AI工作流设计的提示词管理利器如果你和我一样,每天都在和ChatGPT、Claude、Midjourney这些AI模型打交道,那你一定有过这样的烦恼:昨天精心调试好的、能稳定输出高质量代码的提示词,今天想用的时候&a…...

我给了智能体$100去赚钱,结果...
你看过那些演示。一个自主智能体启动,获得一个目标,然后——跳到两周后的 Twitter 帖子——它不知怎么地就在运营一个 Shopify 店铺、写通讯和炒币了。未来已来。AGI 即将降临。买课吧。 我想找出实际发生了什么。 所以我给了一个智能体 100 美元和一个…...