Qt字符编码
目前字符编码有以下几种:
1、UTF-8
UTF-8编码是Unicode字符集的一种编码方式(CEF),其特点是使用变长字节数(即变长码元序列、变宽码元序列)来编码。一般是1到4个字节,当然,也可以更长。
2、UTF-16
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元, 长度为2 Byte)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。UTF-16是2字节或4字节存储,英文也是2字节。详细请参考文章
UTF-8 与 UTF-16编码详解-CSDN博客
3、GBK,GB2312
何为GBK,何为GB2312,与区位码有何渊源?
区位码是早些年(1980)中国制定的一个编码标准,如果有玩过小霸王学习机的话,应该会记得有个叫做“区位”的输入法(没记错的话是按F4选择)。就是打四个数字然后就出来汉字了,什么原理呢。请看下面的区位码表,每一个字符都有对应一个编号。其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。前面的区号有一些符号、数字、字母、注音符号(台)、制表符、日文等等。
而GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。一般编码方式是:0xA0+区号,0xA0+位号。如下表中的 “安”,区位号是1618(十进制),那么“安”字的GB2312编码就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE
区位码表节选


可能大家注意到了,区位码里有英文和数字,按道理说是不是也应该是双字节的呢。而一般情况下,我们见到的英文和数字是单字节的,以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。比如一个数字2,对应的二进制是0x32,而不是 0xA3 0xB2。那么问题来了,0xA3 0xB2 又对应到什么呢?还是2(笑)。注意看了,这里的2跟2是不是有点不太一样?!确实是不一样的。这里的双字节2是全角的二,ASCII的2是半角的二,一般输入法里的切换全角半角就是这里不同。
如果留意过早些年的手机(功能机),会发现人名中常见的“燊”字是打不出来的。为什么呢?因为早期的区位码表里面并没有这些字,也就是说早期的GB2312也是没有这些字的。到后来的GBK(1995)才补充了大量的汉字进去,当然现在的安卓苹果应该都是GBK字库了。再看看这些补充的汉字的字节码 燊 0x9F 0xF6 。和前面说到的GB2312不同,有的字的编码比 0xA0 0xA0 还小,难道新补充的区位号还能是负的??其实不然,这次的补充只补充了计算机编码表,并没有补充区位码表。也就是说区位码表并没有更新,用区位码打字法还是打不出这些字,而网上的反向区位码表查询也只是按照GBK的编码计算,并不代表字与区位号完全对应。时代的发展,区位码表早已经是进入博物馆的东西了。
Big5是与GB2312同时期的一种台湾地区繁体字的编码格式。后来GBK编码的制定,把Big5用的繁体字也包含进来(但编码不兼容),还增加了一些其它的中文字符。细心的朋友可能还会发现,台湾香港用的繁体字(如KTV里的字幕)跟大陆用的繁体字还有点笔画上的不一样,其实这跟编码无关,是字体的不同,大陆一般用的是宋体楷体黑体,港澳台常用的是明体(鸟哥Linux私房菜用的是新細明體)。GBK总体编码范围为0x8140~0xFEFE,首字节在 0x81~0xFE 之间,尾字节在 0x40~0xFE 之间,剔除 xx7F 一条线。详细编码表可以参考这个列表。微软Windows安排给GBK的code page(代码页)是CP936,所以有时候看到编码格式是CP936,其实就是GBK的意思。2000年和2005年,国家又先后两次发布了GB18030编码标准,兼容GBK,新增四字节的编码,但比较少见。
GBK编码字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
4、ANSI
用Notepad++创建一个文本文件text.txt,其默认编码格式为ANSI(乍看之下,还以为是ASCII呢),输入汉字居然不是乱码:
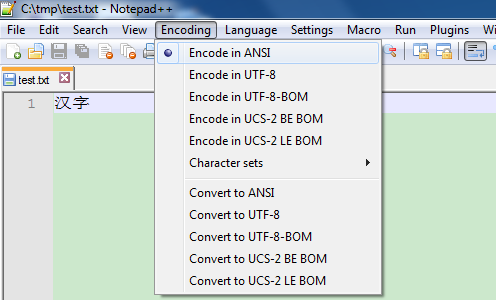
保存为test.txt,发送给你美国的同事Bob。他也用Notepad++,不幸的是,却发现你的文件内容是这样的:
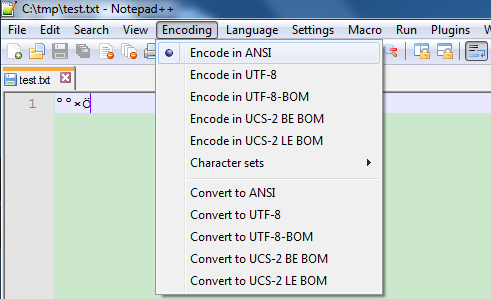
也许你会认为:你用的是中文系统,能正常显示中文;他用的是英文系统,不能显示中文!
这么想,好像很有道理呢!
但是再细想一下:一个系统显示乱码,说明它不支持这种编码格式(或者解码方式不对)。难道英文系统不支持ANSI?难道ANSI是一种中文编码?
如果你身边有一个韩文系统,也装一个Notepad++,默认还是ANSI编码,你可以输入“한국어”,发现也能正常显示:
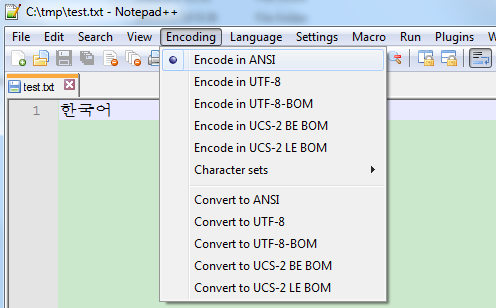
但是你要输入“汉字”可能就会发现是乱码了...
通过这个反例,就可以说明ANSI不是一种中文编码。那么,ANSI到底是什么编码?
用十六进制编辑器打开内容为“汉字”的test.txt文件:

你会发现:其中baba和d7d6正好是“汉”和“字”两个字的GBK编码值。
同样,用十六进制编辑器打开内容为“한국어”的test.txt文件:

你会发现:其中c7d1、b1b9和beee正好是“한”、“국”和“어”三个字符的EUC-KR编码值。
由此可以看出:其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。你的美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。
5、QString中的编码
QString中只存放unicode的utf16编码的字符串,内部用QChar(short)类型的指针进行保存。如果非要使用utf-8或ansi编码的字符串操作类,可以使用QLatin1String类。也可以考虑使用QByteArray类甚至std::string。
char*变量在内存中存放的字符串默认编码,与编译器参数 execution-charset有关,而vs2015及以下编译器默认为 "/execution-charset=GB2312",也就是char*变量内存中保存时使用ansi(具体为GB2312)编码,vs2022默认为 "/execution-charset=UTF-8",gcc或类gcc编译器默认为 "-fexec-charset=UTF-8",特就是char*使用unicode的utf8编码。可以通过在字符串前加u8强制编译器对某个char*变量在内存中保存时采用unicode的utf8编码。
char*转换成QString,一定会做一次字符编码的转码!!!通过QString(const char*)构造的QString对象,char*字符串会被QString强制当成unicode的 utf8编码,这是QString代码不可更改的,并隐式的将这个强制当做unicode 的utf8编码的字符串转换成unicode的utf16编码的字符串。vs编译器 的 execution-charset 默认 为ansi编码,存放的编码为ansi编码,如果你qt工程采用vs2015编译器或以下编译器,这时候强制当做unicode的utf8转换成QString,就一定会乱码,(所以这个时候最好设置"/execution-charset=UTF-8"的编译器参数)。QString 官方不建议使用从char*转QString的构造函数。所以在这个构造函数前加了QT_ASCII_CAST_WARN 宏开关和宏提示。QString中所有的从char*转换到QString的构造函数 或者 由char*隐式转换到QString的函数 或者 参数中含有char*的非static函数 都是隐式调用QString::fromUtf8(char*) 这个静态函数 进行字符编码的转换的。从QByteArray转QString 与 char*转QString 是一样,也会出现同样的问题。
从char*转到QString ,QString有提供很多的static类型的转码函数,qt建议通过调用这些函数进行显示的编码转换。
D:\Qt\Qt5.12.0\5.12.0\mingw73_64\include\QtCore\qstring.h
static inline QString fromLatin1(const QByteArray &str)//从ascii编码转unicode的utf16编码
{ return str.isNull() ? QString() : fromLatin1(str.data(), qstrnlen(str.constData(), str.size())); }
static inline QString fromUtf8(const QByteArray &str) //从unicode8的编码转换成unicode的utf16编码
{ return str.isNull() ? QString() : fromUtf8(str.data(), qstrnlen(str.constData(), str.size())); }
static inline QString fromLocal8Bit(const QByteArray &str) //从local编码转换虫unicode的utf16编码
{ return str.isNull() ? QString() : fromLocal8Bit(str.data(), qstrnlen(str.constData(), str.size())); }
static QString fromUtf16(const ushort *, int size = -1); //从unicode的utf16编码转unicode的utf16编码,可以在字符串前存放BOM来指定输入的字符串字节序,否则采用系统默认字节序
static QString fromUcs4(const uint *, int size = -1); //从unicode的utf32编码转unicode的utf16编码,可以在字符串前存放BOM来指定输入的字符串字节序,否则采用系统默认字节序
#if defined(Q_COMPILER_UNICODE_STRINGS)
static QString fromUtf16(const char16_t *str, int size = -1)
{ return fromUtf16(reinterpret_cast<const ushort *>(str), size); }
static QString fromUcs4(const char32_t *str, int size = -1)
{ return fromUcs4(reinterpret_cast<const uint *>(str), size); }
#endif
QString::fromUtf8(char*) 转码失败是不会给提示的,但是会将不认识的字节 转成 0xfffd。
如果你将ansi编码的字符串传入, 比如ansi编码的 "你好" 传入,其ansi(GB2312)编码为0xC4E3 0xBAC3 ,会得到由四个0xfffd的QChar组成的QString。
下面的案例中,使用windows下qt5.12+vs2015编译器的场景,采用默认的excution-charset(默认值为GB2312)和source-charset(默认值为GB2312)编译器参数,源文件编码为带BOM的utf8(vs编译器能通过BOM识别到文件为utf8编码,并自动将source-charset设置为utf8编码),QTextCodec为 system编码(在我电脑上也就是ansi(GB2312)),excution-charset为默认的ansi(GB2312)编码。
代码中QString类型的str1和str2都存在隐式地将ansi编码的字符串通过fromutf8() 转变成utf16编码的字符串,utf8并不识别ansi编码的字符串,存在转码错误,且刚好"你好"中的每个字节在utf8中都是非法的,导致char数组变量中的每个字节都变成值为0xfffd的占两个字节的QChar类型数据。 当然,主要问题还是qt中可能存在大量隐式的将char*赋予QString的地方。比如我们常用的qDebug中就有。各种使用char*的地方都可能存在隐式的将chai*转QString而存在字符编码转码的隐患!

测试代码
int main(int argc, char *argv[])
{
char cstr1[]="你好c1";
char cstr2[]=u8"你好c2";
wchar_t cstr3[]=L"你好c3";
QString str1("你好1"); //存在隐式地将gb2312转换成unicode的utf16
QString str2;
str2+="你好2"; //存在隐式地将gb2312转换成unicode的utf16
qDebug()<<"你好"<<endl; //qDebug内部存在隐式的将gb2312转换成unicode的utf16
//显示将gb2312转QString所需的utf16。qt推荐的用法。
QString str3=QString::fromLocal8Bit("你好3");
//显示将Utf8转QString所需的utf16。qt推荐的用法。
QString str4=QString::fromUtf8(u8"你好4");
QString str5=QString::fromLocal8Bit(cstr1);
QString str6=QString::fromUtf8(cstr2);
ushort buffer1[6]={};
ushort buffer2[6]={};
ushort buffer3[6]={};
ushort buffer4[6]={};
memcpy(buffer1,str1.data(),str1.length()*2);
memcpy(buffer2,str2.data(),str2.length()*2);
memcpy(buffer3,str3.data(),str3.length()*2);
memcpy(buffer4,str4.data(),str4.length()*2);
//设置控制台接收ansi(gb2312)编码的字符串。936是windows中GB2312字符编码的代码。
system("chcp 936");
cout<<cstr1<<endl;
qDebug().noquote()<<str1;
qDebug().noquote()<<str2;
qDebug().noquote()<<str3;
qDebug().noquote()<<str4;
qDebug().noquote()<<str5;
qDebug().noquote()<<str6;
return 0;
}
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qiushangren/article/details/136617718
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-NC-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/jackgo73/article/details/130225319
同一个编码文件里,怎么区分ASCII和中文编码呢?从ASCII表我们知道标准ASCII只有128个字符,0~127即0x00~0x7F(0111 1111)。所以区分的方法就是,高字节的最高位为0则为ASCII,为1则为中文。
笔者之前写过utf-8的博客【点击】
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/hherima/article/details/50801360
相关文章:
Qt字符编码
目前字符编码有以下几种: 1、UTF-8 UTF-8编码是Unicode字符集的一种编码方式(CEF),其特点是使用变长字节数(即变长码元序列、变宽码元序列)来编码。一般是1到4个字节,当然,也可以更长。 2、UTF-16 UTF-16是Unicode字符编码五层次…...
Ubuntu用docker安装AWVS和Nessus(含破解)
Ubuntu安装AWVS(更多搜索:超详细Ubuntu用docker安装AWVS和Nessus) 首先安装docker,通过dockers镜像安装很方便,且很快;Docker及Docker-Compose-安装教程。 1.通过docker search awvs命令查看镜像; docker search awvs…...

tauri开发中如果取消了默认的菜单项,复制黏贴撤销等功能也就没有了,解决办法
取消默认的菜单项:清除tauri默认的菜单项,让顶部的菜单menu不显示-CSDN博客 就是通过配置空菜单,让菜单不显示,但是这个引发的问题就是复制黏贴撤销等功能也就没有了,解决办法: 新增加编辑下的子菜单&…...

HNU-小学期-专业综合设计
写在前面 选题:大数据技术-智慧交通预测系统 项目github地址(如果有用麻烦点个star与follow):https://github.com/wolfvoid/HNU-ITPS (全部代码以及如何部署参见README) 项目报告:如下&…...

Linux安装es和kibana
安装Elasticsearch 参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/targz.html#targz-enable-indices 基本步骤下载包,解压,官网提示: wget https://artifacts.elastic.co/downloads/elasticsearc…...

第二十六章 Vue之在当前组件范围内获取dom元素和组件实例
目录 一、概述 二、获取dom 2.1. 具体步骤 2.2. 完整代码 2.2.1. main.js 2.2.2. App.vue 2.3. BaseChart.vue 三、获取组件实例 3.1. 具体步骤 3.2. 完整代码 3.2.1. main.js 3.2.2. App.vue 3.2.3. BaseForm.vue 3.3. 运行效果 一、概述 我们过去在想要获取一…...

Markdown 区块
再段落开头,使用>符号,在符号后面按空格,效果图是最左侧有一条灰色的粗线,这是一级区块 二级区块和三级区块只需要在一级的后面加>符号,就可以进入二级区块,效果如下图 还可以在区块内部签到无序列表…...

ctf文件上传题小总结与记录
解题思路:先看中间件,文件上传点(字典扫描,会员中心),绕过/验证(黑名单,白名单),解析漏洞,cms,编辑器,最新cve 文件上传漏…...

什么是QAM
什么是调制呢? 调制就是把信号形式转换成适合在信道中传输的一个过程。可分为基带调制和载波调制。我们这里所说的调制都是载波调制。 什么是载波调制呢? 就是把调制信号骑到载波上,方法就是用调制信号去控制载波的参数,使载波…...

GraphQL 与 Elasticsearch 相遇:使用 Hasura DDN 构建可扩展、支持 AI 的应用程序
作者:来自 Elastic Praveen Durairaju GraphQL 提供了一种高效且灵活的数据查询方式。本博客将解释 Hasura DDN 如何与 Elasticsearch 配合使用,以实现高性能和元数据驱动的数据访问。 此示例的代码和设置可在此 GitHub 存储库 - elasticsearch-subgraph…...

面试题整理 3
总结了某公司面试遇到的值得整理记录的面试题,比较侧重于Redis方面。 目录 Redis持久化配置 RDB AOF Redis rdb日志文件路径编辑 命令行参数设置 Redis事务 Redis事务介绍 Redis事务阶段 watch监听 Mysql隔离级别 1.READ UNCOMMITTED 2.READ COMMITTED …...

数据结构(Java)—— 认识泛型
1. 包装类 在学习泛型前我们需要先了解一下包装类 在 Java 中,由于基本类型不是继承自 Object ,为了在泛型代码中可以支持基本类型, Java 给每个基本类型都对应了一个包装类型。 1.1 基本数据类型和对应的包装类 基本数据类型包装类byteByt…...

处理后的视频如何加上音频信息?
总方案:原来模型对图像进行每帧处理,保留后的视频自然失去了audio信息,因此先用ffmpeg处理得到audio,原输出video加上audio即可,也采用ffmpeg处理。 imageio库用于读取和写入视频文件,并且你正在使用img_cartoon模型处理每一帧图像。然而,这段代码只处理了视频的图像部…...

02LangChain 实战课——安装入门
LangChain安装入门 一、大语言模型简介 大语言模型是利用深度学习技术,尤其是神经网络,来理解和生成人类语言的人工智能模型。这些模型因其庞大的参数数量而得名,能够理解和生成复杂的语言模式。它们通过预测下一个词来训练,基于…...

Python函数中关键字参数、位置参数、默认参数有何不同
在Python中,函数的参数分为三种类型:关键字参数(key arguments)、位置参数(positional arguments)和默认参数(default arguments)。它们的主要区别在于调用时如何传递值,…...
PNG 格式和 JPG 格式都什么时候用
通常我们都知道,如果是针对网络传输或者网站的格式,我们多会使用 PNG 格式。 如果是照片,大部分都是 JPG 格式的。 那么我们网站常用的截图应该保存为什么格式呢? 照片截图 照片截图应该保存为 JPG 格式。 虽然现在我们多存储…...

Qt 练习做一个登录界面
练习做一个登录界面 效果 UI图 UI代码 <?xml version"1.0" encoding"UTF-8"?> <ui version"4.0"><class>Dialog</class><widget class"QDialog" name"Dialog"><property name"ge…...

计算机视觉实验一:图像基础处理
1. 图像的直方图均衡 1.1 实验目的与要求 (1)理解直方图均衡的原理与作用; (2)掌握统计图像直方图的方法; (3)掌握图像直方图均衡的方法。 1.2 实验原理及知识点 直方图均衡化是通过灰度变换将一幅图象转换为另一幅均衡直方图,即在每个灰度级上都具有相同的象素…...

【WebApi】C# webapi 后端接收部分属性
在C#的Web API后端接收部分属性,可以使用[FromBody]特性配合JsonPatchDocument或者Delta来实现。这里提供一个使用JsonPatchDocument的示例。 首先,定义一个模型类:public class User public class User {public int Id {get; set; }...

Java 使用 Redis
Java 使用 Redis 1. 引言 Redis是一个开源的、基于内存的数据结构存储系统,可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串、哈希、列表、集合、有序集合等。由于Redis基于内存,其读写速度非常快,因此被广泛应用于需要高速缓存和实时通讯的场景。…...

SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器
SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为格斗游戏中同时按下W和S导致角色卡顿而烦恼吗?或者在射击游戏急停转…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Docker容器化Emacs:构建可移植、一致的开发环境解决方案
1. 项目概述:为什么要在Docker里运行Emacs?如果你是一个Emacs的重度用户,或者是一个开发者,你很可能遇到过这样的困境:你精心配置的Emacs环境,在换了一台新电脑、升级了操作系统,或者需要在多台…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...

Rulebook-AI:用规则引擎为AI智能体构建可控决策框架
1. 项目概述:一个基于规则的AI智能体框架最近在探索如何让AI智能体(Agent)的行为更可控、更符合业务逻辑时,我遇到了一个挺有意思的开源项目:botingw/rulebook-ai。乍一看这个名字,可能会觉得它又是一个试图…...

AI量化交易实战:从机器学习模型到加密货币对冲基金系统构建
1. 项目概述:一个面向加密货币的AI对冲基金框架最近几年,AI在量化交易领域的应用已经从实验室走向了实战,尤其是在波动性极高的加密货币市场。如果你对量化交易和机器学习感兴趣,并且想找一个能直接上手、结构清晰的实战项目来学习…...