八、MapReduce 大规模数据处理深度剖析与实战指南
MapReduce 大规模数据处理深度剖析与实战指南
一、绪论
在当今的大数据时代背景下,海量数据的处理已然成为企业及科研机构所面临的重大挑战。MapReduce 作为一种高效的分布式计算模型,在大规模数据处理领域中发挥着至关重要的作用。本文将深入阐释 MapReduce 的基本原理,并结合实际案例详尽地讲解如何运用该模型进行大规模数据处理的实战操作。
二、MapReduce 原理综述
- Map 阶段
- 原理阐释:Map 函数主要负责将输入数据拆分为一个个键值对(key-value pair),并对每个键值对进行处理,进而生成中间结果键值对。此过程通常是并行执行的,不同的输入数据片段能够在不同的计算节点上同步进行 Map 操作。
- 实例说明:例如在处理文本数据时,Map 函数可将每一行文本作为输入,以单词为键,以 1 为值,表示该单词出现了一次。例如,对于输入文本“Hello World Hello”,Map 函数可能会输出<“Hello”, 1>, <“World”, 1>, <“Hello”, 1>这样的键值对。
- Reduce 阶段
- 原理阐释:Reduce 函数接收 Map 阶段输出的具有相同键的键值对集合,对这些值进行合并、处理等操作,最终生成输出结果。Reduce 阶段通常也是并行执行的,不同键的值集合可以在不同节点上进行处理。
- 实例说明:继续上述例子,对于键“Hello”,Reduce 函数会接收到<“Hello”, 1>, <“Hello”, 1>这样的键值对集合,它可以对值进行求和操作,最终输出<“Hello”, 2>,表示“Hello”这个单词在输入文本中出现了两次。
三、实战案例:网站日志数据剖析
- 数据背景与目标设定
- 我们拥有一个大型网站的日志文件,其中记录了用户的访问行为,涵盖访问时间、IP 地址、访问页面等信息。我们的目标是对每个页面的访问次数进行统计,以便深入了解网站不同页面的热门程度。
- 数据筹备
- 日志文件格式可能如下:
[时间戳] [IP 地址] [访问页面] [其他信息]。我们需要将日志文件存储于分布式文件系统(如 Hadoop HDFS)中,以便 MapReduce 程序能够顺利读取和处理。 - 可运用工具将日志文件上传至 HDFS,例如使用
hadoop fs -put命令。
- 编写 MapReduce 代码
- Map 函数代码(以 Java 为例)
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PageVisitMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private final static LongWritable one = new LongWritable(1);
private Text page = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] parts = line.split(" ");
if (parts.length >= 3) {
// 以访问页面为键,1 为值
page.set(parts[2]);
context.write(page, one);
}
}
}
- Reduce 函数代码(以 Java 为例)
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class PageVisitReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count += value.get();
}
// 输出页面及访问次数
context.write(key, new LongWritable(count));
}
}
- 驱动类代码(以 Java 为例)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageVisitCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Page Visit Count");
job.setJarByClass(PageVisitCount.class);
job.setMapperClass(PageVisitMapper.class);
job.setReducerClass(PageVisitReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}
- 运行 MapReduce 作业
- 将编写好的代码打包成 JAR 文件。
- 在 Hadoop 集群上运行命令,例如:
hadoop jar [JAR 文件名] [输入路径在 HDFS 中的位置] [输出路径在 HDFS 中的位置]。
- 结果分析
- 作业运行完毕后,在指定的输出路径中会获取到结果文件。文件内容每行表示一个页面及其对应的访问次数。
- 可进一步对结果进行分析,比如将结果导入数据库进行可视化展示,或者与历史数据进行对比分析,以了解页面访问趋势的变化等。
四、优化策略与注意事项
- 数据分区
- 可依据数据的特性进行分区,例如按照时间、地域等因素。在处理日志数据时,如果要分析不同时间段的页面访问情况,可以将日志数据按照时间进行分区,如此在 MapReduce 作业中能够更高效地对不同时间段的数据进行处理。
- combiner 的运用
- combiner 是在 Map 阶段之后、Reduce 阶段之前执行的一个本地聚合操作。在我们的例子中,可以在 Map 阶段输出后,在本地对相同页面的访问次数进行初步求和,这样能够减少网络传输的数据量,提升效率。
- 修改 MapReduce 代码,在 Map 函数中添加 combiner 的逻辑(示例代码如下):
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PageVisitMapperWithCombiner extends Mapper<LongWritable, Text, Text, LongWritable> {
private final static LongWritable one = new LongWritable(1);
private Text page = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] parts = line.split(" ");
if (parts.length >= 3) {
page.set(parts[2]);
context.write(page, one);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
// combiner 逻辑,在本地对相同键的值进行求和
Text currentPage = null;
long sum = 0;
for (Map.Entry<Text, LongWritable> entry : context.getMapOutputValueColl().entrySet()) {
if (currentPage == null ||!currentPage.equals(entry.getKey())) {
if (currentPage!= null) {
context.write(currentPage, new LongWritable(sum));
}
currentPage = entry.getKey();
sum = entry.getValue().get();
} else {
sum += entry.getValue().get();
}
}
if (currentPage!= null) {
context.write(currentPage, new LongWritable(sum));
}
}
}
- 内存管理
- MapReduce 作业在运行过程中需要合理地管理内存。若 Map 或 Reduce 任务处理的数据量过大,可能会导致内存溢出。可通过调整 Hadoop 的相关配置参数,如
mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来分配适宜的内存给任务。同时,在代码中要注意避免创建过大的中间数据结构,及时释放不再使用的内存资源。
- 错误处理
- 在大规模数据处理中,可能会遭遇各种错误,如数据格式错误、节点故障等。要在代码中添加恰当的错误处理逻辑,例如对于格式错误的数据可以进行日志记录并跳过,对于节点故障可以利用 Hadoop 的容错机制进行重新调度任务等。
五、结论
MapReduce 为大规模数据处理提供了一种强大且有效的解决方案。通过深入理解其原理并结合实际案例进行实践,我们能够充分发挥它的优势,高效地处理海量数据。在实际应用中,还需不断进行优化并注意各种细节,以提高处理效率并确保作业的稳定性。期望本文的实战讲解能够助力读者更好地掌握 MapReduce 技术,在大数据处理领域取得更为卓越的成果。
相关文章:

八、MapReduce 大规模数据处理深度剖析与实战指南
MapReduce 大规模数据处理深度剖析与实战指南 一、绪论 在当今的大数据时代背景下,海量数据的处理已然成为企业及科研机构所面临的重大挑战。MapReduce 作为一种高效的分布式计算模型,在大规模数据处理领域中发挥着至关重要的作用。本文将深入阐释 MapR…...

开源免费的API网关介绍与选型
api网关的主要作用 API网关在现代微服务架构中扮演着至关重要的角色,它作为内外部系统通信的桥梁,不仅简化了服务调用过程,还增强了系统的安全性与可管理性。例如,当企业希望将内部的服务开放给外部合作伙伴使用时,直…...

OpenCV视觉分析之目标跟踪(5)目标跟踪类TrackerMIL的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 MIL 算法以在线方式训练分类器,以将目标从背景中分离出来。多重实例学习(Multiple Instance Learning)通过在…...

二级列表联动
介绍 本示例主要介绍了List组件实现二级联动(Cascading List)的场景。 该场景多用于商品种类的选择、照片不同类型选择等场景。 效果图 使用说明: 滑动二级列表侧控件(点击没用),一级列表随之滚动。&…...

「C/C++」C++ 标准库 之 #include<sstream> 字符串流库
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...
安全问题原理及解决思路)
深入理解跨域资源共享(CORS)安全问题原理及解决思路
目录 引言 CORS 基础 CORS 安全问题原理 解决思路 结论 引言 跨域资源共享(CORS, Cross-Origin Resource Sharing)是现代Web应用中不可或缺的一部分,特别是在前后端分离的架构中。CORS允许一个域上的Web应用请求另一个域上的资源&#…...
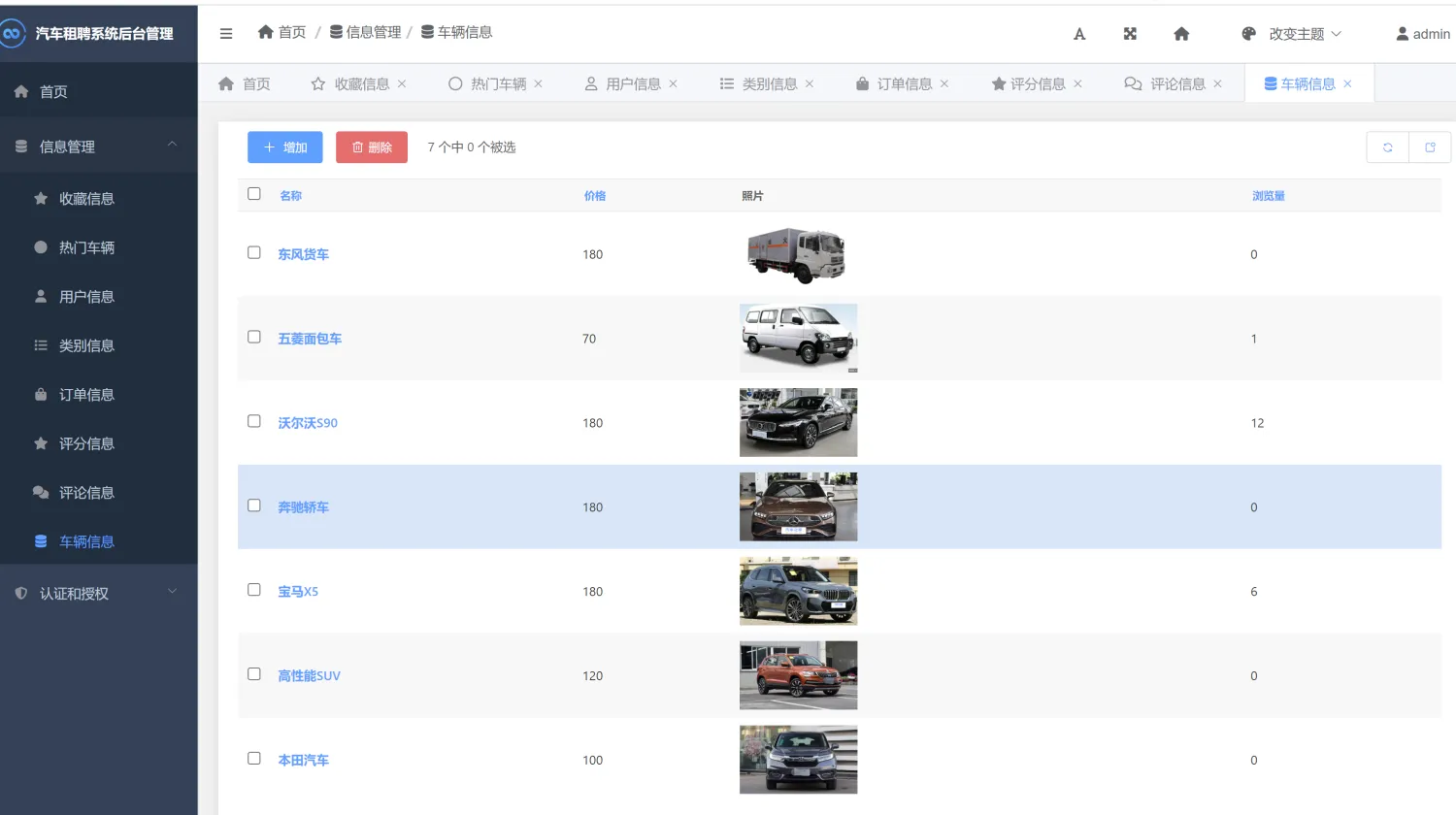
【汽车租聘管理与推荐】Python+Django网页界面+推荐算法+管理系统网站
一、介绍 汽车租聘管理与推荐系统。本系统使用Python作为主要编程语言,前端采用HTML、CSS、BootStrap等技术搭建前端界面,后端采用Django框架处理用户的请求。创新点:使用协同过滤推荐算法实现对当前用户个性化推荐。 其主要功能如下&#…...

Linux常见指令大全(必要+知识点)
目录 ls 指令☑️ 在Windows中会自动显示当前目录当中的所有子目录与文件,但是在Linux中要用到ls指令。 语法: ls [选项][目录或文件] 功能:对于目录,该命令列出该目录下的所有子目录与文件。对于文件,将列出文件名以…...

iOS用rime且导入自制输入方案
iPhone 16 的 cantonese 只能打传统汉字,没有繁简转换,m d sh d。考虑用「仓」输入法 [1] 使用 Rime 打字,且希望导入自制方案 [2]。 仓输入法有几种导入方案的方法,见 [3],此处记录 wifi 上传法。准备工作࿱…...

Linux 进程终止 进程等待
目录 进程终止 退出码 错误码 代码异常终止(信号详解) exit _exit 进程等待 概念 等待的原因 wait 函数原型 参数 返回值 监控脚本 waitpid 概念 函数原型 参数 返回值 WIFEXITED(status) WEXITSTATUS(status) 问题 为什么不用全局变量获得子进程的退出信…...

VBA 64位API声明语句第003讲
跟我学VBA,我这里专注VBA, 授人以渔。我98年开始,从源码接触VBA已经20余年了,随着年龄的增长,越来越觉得有必要把这项技能传递给需要这项技术的职场人员。希望职场和数据打交道的朋友,都来学习VBA,利用VBA,起码可以提高…...

【问题记录】解决VMware虚拟机中鼠标侧键无法使用的问题
前言 有项目需要在Linux系统中开发,因为要测试Linux中相关功能,要用到shell,在Windows中开发太麻烦了,因此我选择使用UbuntuXfce4桌面来开发,这里我用到了Linux版本的IDEA,除了快捷键经常和系统快捷键冲突…...
(鼠标悬停该条数据的时候展示全部内容))
Naive UI 级联选择器 Cascader的:render-lable怎么使用(Vue3 + TS)(鼠标悬停该条数据的时候展示全部内容)
项目场景: 在渲染Cascader级联选择器后,当文字过长的时候,多出来的部分会显示成省略号,这使我们不能很清晰的看到该条数据的完整信息,就需要加一个鼠标悬停展示完整内容。 解决方案: vue: &l…...
)
vue元素里面的 js对象中,:style后面里属性名不支持这种带-的写法(background-color)
首先要知道,在这个:style里面,虽然可以用 {属性: 属性值 , 属性: 属性值} 这种方方式来写很多属性,但也仅限于width这种普通属性,像background-color这种带-的特殊标签是不支持直接写的; <div class"box&quo…...

Git 常用命令与开发流程总结
引言 在我之前面试过程中,经常会问到关于公司使用什么代码版本管理工具。 无非是考察咱们是否用过 Git和SVN。 现在公司选择的工具直接影响到项目的开发流程和协作效率。当前市面上,Git 和 SVN(Subversion)是两种流行的版本控制系…...

链表中插入新的节点
/* 节点结构体定义 */ struct xLIST_ITEM {TickType_t xItemValue; /* 辅助值,用于帮助节点做顺序排列 */ struct xLIST_ITEM * pxNext; /* 指向链表下一个节点 */ struct xLIST_ITEM * pxPrevious; /* 指向链表前一个节点 */ void * pvOw…...
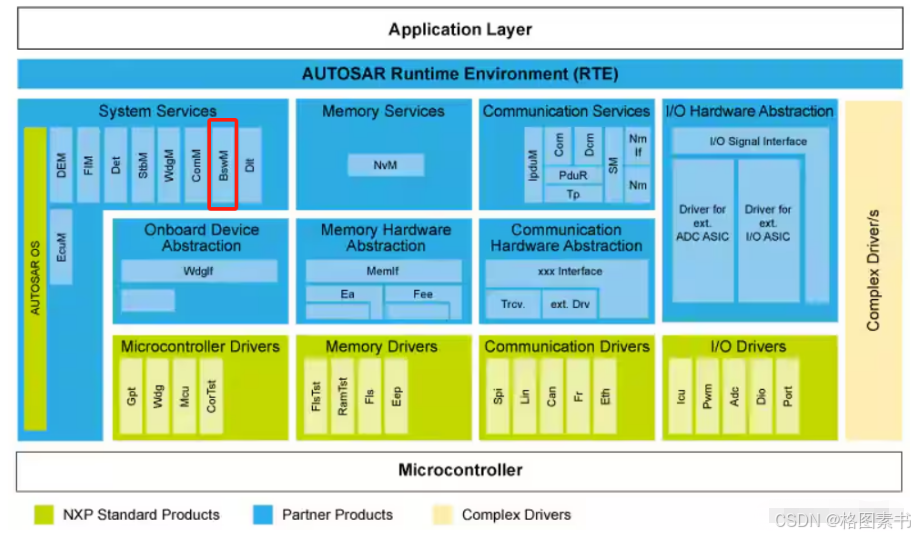
AUTOSAR从入门到精通-BswM模块(二)
目录 前言 算法原理 BswM接口端口 BswM功能描述 模式仲裁 仲裁规则(Arbitration Rules) 模式仲裁来源 模式仲裁过程 模式条件(ModeCondition) 逻辑表达式(LogicExpressions) 模式控制 模式处理 操作执行 模式控制过程 模式控制基本流程 BswM Interfaces and …...
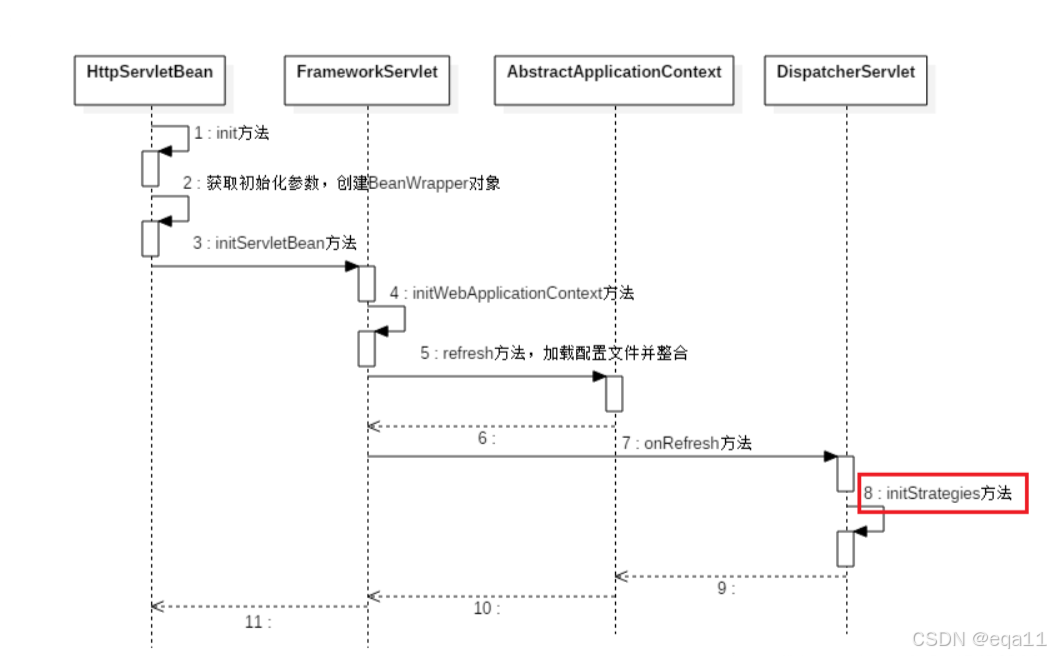
Spring DispatcherServlet详解
文章目录 Spring DispatcherServlet详解一、引言二、DispatcherServlet的初始化与工作流程1、DispatcherServlet的初始化1.1、加载配置和建立WebApplicationContext1.2、初始化策略 2、DispatcherServlet的工作流程2.1、请求分发2.2、代码示例 三、总结 Spring DispatcherServl…...

JS | 软件制作的流程是什么?
目录 一、 需求分析 二、 系统设计 三、 编码实现 四、 测试验证 五、 部署上线 六、 维护更新 软件制作的流程主要包含需求分析、系统设计、编码实现、测试验证、部署上线和维护更新。其中,需求分析是基础,它决定了软件的功能和性能;通…...
简单工厂模式
引言 简单工厂模式并不属于23种设计模式,它是工厂方法模式的“小弟”,由于日常编程中大家会经常用到,只不过没有察觉,因此下文将详解简单工厂模式。 1.概念 简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

别再手动算位宽了!Vivado FIR IP核的位宽计算逻辑与配置避坑指南
Vivado FIR IP核位宽计算实战:从黑盒解析到精准配置 在FPGA数字信号处理领域,FIR滤波器作为基础构建模块,其性能表现直接影响整个系统的信号处理质量。而位宽配置这个看似简单的参数,往往成为项目后期调试阶段的"隐形杀手&qu…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

Nixtla时间序列预测库实战:从统计模型到深度学习的一站式解决方案
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理销售预测、服务器负载监控或者任何与时间相关的数据预测问题,并且厌倦了在复杂的模型库和繁琐的预处理步骤之间反复横跳,那么 Nixtla 这个开源项目很可能就是你一直在找的“瑞士军刀”。…...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...

n8n-claw:在自动化工作流中实现零代码网页抓取
1. 项目概述与核心价值最近在折腾自动化工作流,发现了一个挺有意思的项目,叫freddy-schuetz/n8n-claw。乍一看名字,你可能会有点懵,“n8n”我知道,是那个开源的自动化工具,但这个“claw”是啥?爪…...