深度学习-梯度消失/爆炸产生的原因、解决方法
在深度学习模型中,梯度消失和梯度爆炸现象是限制深层神经网络有效训练的主要问题之一,这两个现象从本质上来说是由链式求导过程中梯度的缩小或增大引起的。特别是在深层网络中,若初始梯度在反向传播过程中逐层被放大或缩小,最后导致前几层的权重更新停滞(梯度消失)或异常增大(梯度爆炸),影响模型的有效训练和收敛。接下来,我们从网络深度、激活函数的选择等方面深入分析其成因,并探讨解决这些问题的主流方法。
1. 梯度消失与梯度爆炸的成因
(1)网络深度
在深层神经网络中,每层网络的输出需要通过链式法则依次向前层传递梯度。对于N层网络,梯度会以每层的权重导数值的乘积进行传递。如果网络层数较多,且每层权重的初始值较小,则连乘的结果会逐渐趋于零,导致梯度逐层减小,这即是梯度消失的现象。反之,如果每层权重的初始值较大,则连乘结果会不断增大,出现梯度爆炸。
(2)激活函数的选择 激活函数的选择直接影响到梯度在反向传播中的衰减或放大,尤其是早期的Sigmoid和Tanh激活函数。
- Sigmoid函数:Sigmoid将输入压缩到0到1的范围内,但在0附近的梯度会快速趋近于零,这种“饱和效应”会导致反向传播的梯度迅速衰减,产生梯度消失现象。
- Tanh函数:Tanh虽然比Sigmoid有较大的梯度值区间(-1到1),但在极值区间也会出现梯度趋于零的情况。
- ReLU函数:ReLU(Rectified Linear Unit)虽在正区间表现良好,但在负值区间恒为零,会导致部分神经元的输出始终为零,称为“神经元死亡”,影响梯度传递。
2. 解决梯度消失与爆炸的方法
(1)优化权重初始化策略
- Xavier初始化:适合Sigmoid和Tanh激活函数。它将权重初始化为均值为0、方差为
2/(输入神经元数 + 输出神经元数)的值,确保输出的分布尽量均匀,防止梯度消失或爆炸。 - He初始化:专为ReLU和其变种设计,将权重初始化为均值为0、方差为
2/输入神经元数,使正向和反向传播中梯度保持在合理范围,减轻梯度消失的现象。
(2)激活函数的优化
- ReLU (Rectified Linear Unit):ReLU的导数在正区间为1,能够减轻梯度消失问题。然而,负区间梯度为0会导致“神经元死亡”。为此,引入了多种ReLU的变体:
- Leaky ReLU:在负区间引入一个小的斜率(如0.01)而非直接置零,有效缓解神经元死亡现象。
- Parametric ReLU (PReLU):进一步改进了Leaky ReLU,使负区间的斜率可以学习优化,以适应不同任务的数据分布。
- ELU (Exponential Linear Unit):在负区间以指数形式衰减,而非恒为0,有助于提高网络的收敛速度和稳定性。
- Swish函数:由Google提出,定义为
x * sigmoid(x),允许负数并对输入进行平滑处理,取得了较好的梯度稳定性。
(3)使用正则化技术
- 梯度裁剪(Gradient Clipping):在反向传播中限制梯度的最大值(例如,将超过某阈值的梯度强制设为该阈值)。这种方法通常用于防止梯度爆炸,在RNN和LSTM模型中常用。
- 权重正则化:通过L1和L2正则化对模型参数进行约束。L2正则化通过在损失函数中加入权重平方和作为惩罚项,使得过大的权重更新得以抑制,防止梯度爆炸。
- Layer Normalization:Layer Normalization在每一层对每个神经元的输出进行归一化操作,以确保梯度稳定性,特别适用于循环神经网络(RNN)等任务。
(4)引入新型网络结构
- 残差网络(Residual Networks, ResNet):引入残差连接(skip connections),让信息绕过中间的隐藏层直接传到输出层,确保梯度信息在深层网络中可以顺利传递,极大减轻了梯度消失问题,使得上百层的深层网络得以训练成功。
- 批标准化(Batch Normalization, BN):在每个小批量数据上进行标准化处理,将激活值归一化为均值为0、方差为1的分布。BN不仅稳定了梯度流动,且能提高模型的收敛速度和精度,是现代神经网络中常用的标准技术。
- 长短期记忆网络(LSTM):LSTM(Long Short-Term Memory)结构是为解决循环神经网络中梯度消失问题设计的。LSTM单元通过内部的“遗忘门”、“输入门”和“输出门”机制,控制记忆的更新和遗忘过程。这种机制使得梯度可以有效保留并传播,防止了长期依赖关系中的梯度消失问题,LSTM广泛应用于自然语言处理和时间序列任务。
(5)优化算法的改进
- 自适应优化算法(如Adam和RMSprop):自适应学习率优化算法如Adam、RMSprop等根据梯度的一阶和二阶矩估计动态调整学习率,使得梯度更新在每一层得到较好的适应,能在一定程度上减轻梯度消失与爆炸的问题。
- 学习率调度器(Learning Rate Scheduler):在训练过程中动态调整学习率,初期使用较大学习率快速搜索全局最优,随后逐渐减小学习率以精细化模型参数,避免梯度爆炸或振荡。
(6)其他增强训练的策略
- 早停(Early Stopping):在检测到模型的验证误差持续不变或增大时,提前停止训练,防止梯度爆炸带来的过拟合问题。
- 预训练与微调:通过在相似任务上进行预训练来获得初始参数,再对目标任务进行微调。该策略能为深层网络提供较好的初始点,避免梯度消失或爆炸带来的收敛困难问题。
- 正则化参数搜索:对于不同层次的神经元选择合适的正则化参数,特别是L2正则化和Dropout正则化,有助于保持网络的泛化能力与梯度稳定性。
3. 代码示例
以下是实现梯度剪切和Batch Normalization的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim# 一个简单的全连接神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(784, 512)self.bn1 = nn.BatchNorm1d(512) # 使用Batch Normalizationself.relu = nn.ReLU()self.fc2 = nn.Linear(512, 10)def forward(self, x):x = self.fc1(x)x = self.bn1(x) # 在第一个全连接层后添加BNx = self.relu(x)x = self.fc2(x)return x# 创建模型和优化器
model = SimpleNN()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 模拟训练循环
for data, target in dataloader:optimizer.zero_grad()output = model(data)loss = nn.CrossEntropyLoss()(output, target)loss.backward()# 梯度剪切torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 设定梯度最大阈值为1.0optimizer.step()
/*
模型的第一层全连接后加入Batch Normalization,以减少梯度的偏移,提高梯度在深层网络中传播稳定性。
使用梯度剪切函数clip_grad_norm_防止梯度爆炸,通过设定梯度的最大阈值,更新参数时避免数值不稳定。
*/相关文章:

深度学习-梯度消失/爆炸产生的原因、解决方法
在深度学习模型中,梯度消失和梯度爆炸现象是限制深层神经网络有效训练的主要问题之一,这两个现象从本质上来说是由链式求导过程中梯度的缩小或增大引起的。特别是在深层网络中,若初始梯度在反向传播过程中逐层被放大或缩小,最后导…...
模式概述)
MVC(Model-View-Controller)模式概述
MVC(Model-View-Controller)是一种设计模式,最初由 Trygve Reenskaug 在 1970 年代提出,并在 Smalltalk 编程环境中得到了广泛应用。MVC 模式旨在实现用户界面和业务逻辑的分离,以增强应用程序的可维护性、可扩展性和复…...

数据结构 —— 红黑树
目录 1. 初识红黑树 1.1 红黑树的概念 1.2 红⿊树的规则 1.3 红黑树如何确保最长路径不超过最短路径的2倍 1.4 红黑树的效率:O(logN) 2. 红黑树的实现 2.1 红黑树的基础结构框架 2.2 红黑树的插⼊ 2.2.1 情况1:变色 2.2.2 情况2:单旋变色 2.2…...

《功能高分子学报》
《功能高分子学报》 中国标准连续出版物号:CN 31-1633/O6,国际标准连续出版物号:ISSN 1008-9357,邮发代号:4-629,刊期:双月刊。 《功能高分子学报》主要刊登功能高分子和其他高分子领域具有创新意义的学术…...

Linux特种文件系统--tmpfs文件系统
tmpfs类似于RamDisk(只能使用物理内存),使用虚拟内存(简称VM)子系统的页面存储文件。tmpfs完全依赖VM,遵循子系统的整体调度策略。说白了tmpfs跟普通进程差不多,使用的都是某种形式的虚拟内存&a…...
《基于STMF103的FreeRTOS内核移植》
目录 1.FreeRTOS资料下载与出处 1.1官网下载,网址:www.freertos.org 1.2在正点原子官网,任意STM32F1的开发板资料A盘里, 2.FreeRTOS移植重要文件讲解 2.1 FreeRTOS与FreeRTOS-Plus文件夹 2.2 Demo、Lincence、Source ●Demo文件…...

一七二、Vue3性能优化方式
Vue 3 的性能优化相较于 Vue 2 有了显著提升,利用新特性和改进方法可以更高效地构建和优化应用。以下是 Vue 3 的常见性能优化方法及示例。 1. 使用组合式 API (Composition API) Vue 3 引入的组合式 API,通过逻辑拆分和复用来实现更高效的代码组织和性…...

软件测试--BUG篇
博主主页: 码农派大星. 数据结构专栏:Java数据结构 数据库专栏:MySQL数据库 JavaEE专栏:JavaEE 软件测试专栏:软件测试 关注博主带你了解更多知识 目录 1. 软件测试的⽣命周期 2. BUG 1. BUG 的概念 2. 描述bug的要素 3.bug级别 4.bug的⽣命周期 5 与开发产⽣争执怎…...

Scikit-learn和Keras简介
一,Scikit-learn是一个开源的机器学习库,用于Python编程语言。它建立在NumPy、SciPy和matplotlib这些科学计算库之上,提供了简单有效的数据挖掘和数据分析工具。Scikit-learn库包含了许多用于分类、回归、聚类和降维的算法,包括支…...

python在word的页脚插入页码
1、插入简易页码 import win32com.client as win32 from win32com.client import constants import osdoc_app win32.gencache.EnsureDispatch(Word.Application)#打开word应用程序 doc_app.Visible Truedoc doc_app.Documents.Add() footer doc.Sections(1).Footers(cons…...

Java面试题十四
一、Java中的JNI(Java Native Interface)是什么?它有什么用途? Java中的JNI(Java Native Interface)是Java提供的一种编程框架,它允许Java代码与本地(Native)代码&#x…...

yarn : 无法加载文件,未对文件 进行数字签名。无法在当前系统上运行该脚本。
执行这个命令时报错:yarn --registryhttps://registry.npm.taobao.org yarn : 无法加载文件 C:\Users\Administrator\AppData\Roaming\npm\yarn.ps1。未对文件 C:\Users\Administ rator\AppData\Roaming\npm\yarn.ps1 进行数字签名。无法在当前系统上运行该脚本。有…...

Hadoop——HDFS
什么是HDFS HDFS(Hadoop Distributed File System)是Apache Hadoop的核心组件之一,是一个分布式文件系统,专门设计用于在大规模集群上存储和管理海量数据。它的设计目标是提供高吞吐量的数据访问和容错能力,以支持大数…...

计算机的一些基础知识
文章目录 编程语言 程序 所谓程序,就是 一组指令 以及 这组指令要处理的数据。狭义上来说,程序对我们来说,通常表现为一组文件。 程序 指令 指令要处理的数据。 编程语言发展 机器语言:0、1 二进制构成汇编语言:…...

学习RocketMQ(记录了个人艰难学习RocketMQ的笔记)
一、部署单点RocketMQ Docker 部署 RocketMQ (图文并茂超详细)_docker 部署rocketmq-CSDN博客 这个博主讲的很好,可食用,替大家实践了一遍 二、原理篇 为什么使用RocketMQ: 为什么选择RocketMQ | RocketMQ 关于一些原理,感觉…...

【设计模式】策略模式定义及其实现代码示例
文章目录 一、策略模式1.1 策略模式的定义1.2 策略模式的参与者1.3 策略模式的优点1.4 策略模式的缺点1.5 策略模式的使用场景 二、策略模式简单实现2.1 案例描述2.2 实现代码 三、策略模式的代码优化3.1 优化思路3.2 抽象策略接口3.3 上下文3.4 具体策略实现类3.5 测试 参考资…...
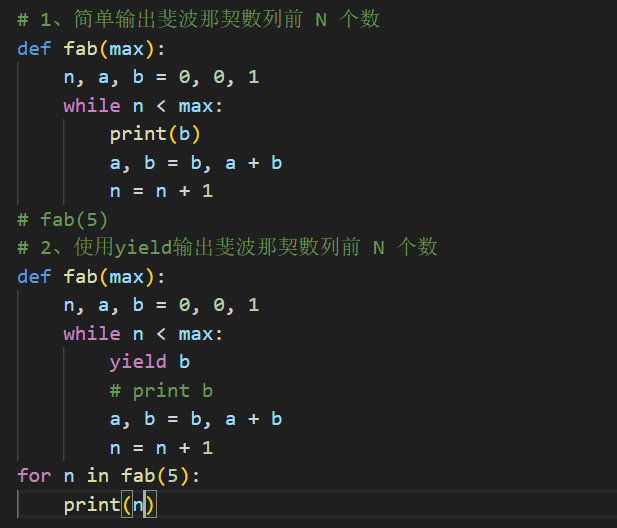
list与iterator的之间的区别,如何用斐波那契数列探索yield
问题 list与iterator的之间的区别是什么?如何用斐波那契数列探索yield? 2 方法 将数据转换成list,通过对list索引和切片操作,以及可以进行添加、删除和修改元素。 iterator是一种对象,用于遍历可迭代对象(如列表、元组…...

抖音店铺数据也就是抖店,如何使用小店数据集来挖掘价值?
抖音商家现在基本达到二百多万家抖店,有一些公司可能会根据开放的数据研究行业分布、GMV等等,就像是也出了专业的一些平台如“蝉妈妈”、“达多多”,对我来说受限制就是难受。 当然也有很多大型合法的数据平台有抖店数据集,但…...

KubeVirt 安装和配置 Windows虚拟机
本文将将介绍如何安装 KubeVirt 和使用 KubeVirt 配置 Windows 虚拟机。 前置条件 准备 Ubuntu 操作系统,一定要安装图形化界面。 安装 Docker(最新版本) 安装 libvirt 和 TigerVNC: apt install libvirt-daemon-system libvir…...

CM API方式设置YARN队列资源
简述 对于CDH版本我们可以参考Fayson的文章,本次是CDP7.1.7 CM7.4.4 ,下面只演示一个设置队列容量百分比的示例,其他请参考cloudera官网。 获取cookies文件 生成cookies.txt文件 curl -i -k -v -c cookies.txt -u admin:admin http://192.168.242.100:7180/api/v44/clusters …...

【YOLO目标检测全栈实战】33 模型部署的终极形态:ONNX Runtime + TensorRT EP 跨平台推理
还记得上周帮一家做边缘计算盒子的客户调优时,他们遇到一个典型问题:同一份ONNX模型,在Windows服务器上用TensorRT跑出了5ms的推理延迟,可部署到客户的ARM工控机上,却只能用CPU硬扛,延迟直接飙到80ms。 客户老板当场拍桌子:“你们这模型是不是分三六九等?”我拆开部署…...

ElevenLabs奥里亚文语音SDK集成终极 checklist:从Unicode 13.0字符兼容性到Odia Conjunct Glyph渲染异常修复
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs奥里亚文语音SDK集成终极 checklist:从Unicode 13.0字符兼容性到Odia Conjunct Glyph渲染异常修复 Unicode 13.0 兼容性验证 ElevenLabs v4.2.1 SDK 默认支持 Unicode 13.0&…...

【M1 Mac实战】MATLAB R2021b 安装与优化全攻略
1. M1 Mac安装MATLAB R2021b前的准备工作 第一次在M1芯片的Mac上安装MATLAB R2021b时,我遇到了不少坑。这里分享下必须做好的几项准备工作,能帮你节省至少2小时的折腾时间。 首先确认你的系统版本。实测在macOS Monterey(12.0)到V…...

MacType终极指南:彻底解决Windows字体模糊问题的免费神器
MacType终极指南:彻底解决Windows字体模糊问题的免费神器 【免费下载链接】mactype Better font rendering for Windows. 项目地址: https://gitcode.com/gh_mirrors/ma/mactype 你是否厌倦了Windows系统上模糊不清的字体显示?长期面对锯齿边缘的…...

基于Puppeteer与GPT的微信AI助手:从自动化到智能回复的完整实现
1. 项目概述:一个能帮你自动回复微信消息的AI助手 如果你也和我一样,每天被淹没在微信的群聊、私聊和各种公众号消息里,但又不想错过重要信息,或者希望有一个“智能分身”能帮你处理一些重复性的咨询,那么这个项目你一…...

MoviePilot批量重命名:5步解决NAS媒体库命名混乱问题
MoviePilot批量重命名:5步解决NAS媒体库命名混乱问题 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot 你是否曾为NAS中杂乱无章的媒体文件名而烦恼?"Avengers.Endgame.2019.1…...

UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法
UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法 如果你正在开发UEFI驱动或应用,事件机制(Event)一定是绕不开的核心功能。但看似简单的WaitForEvent和CreateEvent,在实际编码中却暗藏玄机。本文将…...

Unity实战:利用TriLib插件实现运行时动态加载外部3D模型
1. TriLib插件基础入门 第一次接触TriLib插件时,我也被它强大的功能惊艳到了。这个插件最大的价值在于,它能让我们在Unity运行时动态加载各种主流3D模型格式,比如FBX、OBJ、GLTF等,而不需要提前在编辑器中导入。想象一下ÿ…...
)
LM567锁相环芯片实测:手把手教你搭建10kHz音频信号检测电路(附面包板接线图)
LM567锁相环芯片实战:从零构建10kHz音频检测电路全流程解析 在电子设计领域,频率检测一直是个既基础又关键的课题。无论是红外遥控信号解码、超声波测距,还是电磁导航系统,精准的频率识别都是实现功能的前提。而LM567这款经典的锁…...

2026年5月14隔夜暗盘挂单排行榜
推荐好文:每年节约五六千交易费不香吗如何获取龙虎榜是否有量化参与如何获取股东减持信息大A有5400多只股票, 这里面只有不到10%, 约500只由资金投票, 剩余的都是杂毛, 炒股看龙头找主线. 从隔夜挂单里选择, 再叠加我们之前分享的如何判断是否有大股东减持, 是否有融资融券参与…...