AI图像相似性搜索对比:VIT, CLIP, DINO-v2, BLIP-2
图像相似性搜索的核心在于一个简单的想法:图像可以表示为高维空间中的向量。当两个图像相似时,它们的向量应该在这个空间中占据相似的位置。我们可以通过测量角度(或余弦相似度)来确定这些向量的相似程度。如果角度小,图像就接近(相似)。如果角度大(不同),图像就会相距很远。这就像在公寓大楼里寻找邻居一样,但方式要抽象得多。使用不同的 AI 模型,例如 ViT、CLIP、BLIP、EfficientNet、DINO-v2 和 VGG16比较图像并查看它们的相似之处。

模型介绍
关于图像相似度计算的几种深度学习方法,以下是对几个模型的介绍,包括它们的优缺点:
1. ViT(Vision Transformer)
ViT是Google在2020年提出的模型,将Transformer架构应用于图像分类任务。ViT通过将图像分割成多个小块(patches),然后将这些小块线性映射到低维空间,并添加位置编码后输入到Transformer Encoder中进行处理。
优点:
- 全局感受野:ViT能够捕获图像的全局特征,这在CNN中较难实现。
- 可扩展性:模型的效果随着模型大小的增加而提升,表现出很好的可扩展性。
- 较少的训练资源:在大规模数据集上预训练后,ViT在多个中小型图像识别基准上的表现优于SOTA的CNN,同时需要的训练资源更少。
缺点:
- 缺乏归纳偏置:ViT不具有CNN的归纳偏置,如平移不变性和局部感受野,这可能需要额外的技术来补偿。
- 对数据量要求高:ViT在小数据集上的表现可能不如CNN,需要大量数据进行预训练才能发挥其优势。
2. CLIP(Contrastive Language-Image Pre-Training)
CLIP是OpenAI在2021年发布的多模态预训练神经网络,通过对比学习的方式,将图像和文本映射到共享的向量空间中,实现图像和文本之间的语义关联。
优点:
- 零样本学习:CLIP在零样本学习任务中表现出色,不需要看到新的图像或文本的训练示例就能进行预测。
- 简洁有效的架构:模型架构简洁,效果好,适用于多种视觉和语言任务。
缺点:
- 对标注数据的依赖:尽管CLIP在预训练阶段不需要大量标注数据,但在某些任务中,如图像分类,可能需要额外的标注数据来微调模型。
3. BLIP(Bootstrapped Language-Image Pretraining)
BLIP是Salesforce提出的多模态Transformer模型,旨在统一视觉理解任务和生成任务。BLIP通过引入Captioner和Filter模块来提高数据质量和数量,从而提升模型性能。
优点:
- 理解和生成能力:BLIP兼具图文多模态的理解和生成能力,适用于多种视觉语言任务。
- 数据质量提升:通过Captioner和Filter模块,BLIP能够去除网络资源中的文本噪声,提高模型性能。
缺点:
- 训练成本:BLIP的训练需要较大的网络架构和数据集,导致较大的训练代价。
4. EfficientNet
EfficientNet是Google提出的模型,通过复合缩放方法(同时考虑网络深度、宽度和图像分辨率)来提高模型的效率和准确性。
优点:
- 高效率:EfficientNet在保持高准确率的同时,模型更小、更快,提高了网络的实用性和工业落地可能。
- 系统性模型缩放:EfficientNet提出了一种系统性的方法来缩放模型,而不是随意增加网络的深度或宽度。
缺点:
- 对资源的需求:尽管EfficientNet在效率上有显著提升,但在某些情况下,可能仍然需要较多的计算资源。
5. DINO-v2
DINO-v2是Meta AI发布的自监督学习模型,能够抽取强大的图像特征,且在下游任务上不需要微调。
优点:
- 无需微调:DINO-v2可以直接用作多种计算机视觉任务的骨干网络,无需微调。
- 自监督学习:DINO-v2使用自监督学习,可以从任何图像集合中学习,不依赖于大量的标记数据。
缺点:
- 对数据集的依赖:虽然DINO-v2可以从任何图像集合中学习,但其性能可能依赖于数据集的质量和多样性。
步骤1:数据准备
从维基百科抓取了国旗图像,将世界各地国家的国旗变成了一个数据集。
图像相似性搜索的核心在于一个简单的想法:图像可以表示为高维空间中的向量。当两个图像相似时,它们的向量应该在这个空间中占据相似的位置。我们可以通过测量角度(或余弦相似度)来确定这些向量的相似程度。如果角度小,图像就接近(相似)。如果角度大(不同),图像就会相距很远。这就像在公寓大楼里寻找邻居一样,但方式要抽象得多。
import pandas as pd
flags_df = pd.read_csv('national_flags.csv')
print(flags_df)

步骤2:特征提取
提取特征,将每个模型获取标志的图像并将其转换为特征向量,并将其特征转换为数字列表。在本实验中,将使用 Huggingface 的特征转换器库来进行特征提取。
- EfficientNet: 通过平均最后一个隐藏层输出的空间维度来提取标志特征,重点关注细粒度模式。
image_processor = AutoImageProcessor.from_pretrained("google/efficientnet-b7")
model = EfficientNetModel.from_pretrained("google/efficientnet-b7")# prepare input image
inputs = image_processor(img, return_tensors='pt')with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)embedding = outputs.hidden_states[-1]
embedding = torch.mean(embedding, dim=[2,3])
- ViT: 使用其转换器架构中第一个标记的最后隐藏状态,捕获局部和全局视觉特征。
image_processor = AutoImageProcessor.from_pretrained("google/vit-large-patch16-224-in21k")
model = ViTModel.from_pretrained("google/vit-large-patch16-224-in21k")# prepare input image
inputs = image_processor(img, return_tensors='pt')with torch.no_grad():outputs = model(**inputs)
embedding = outputs.last_hidden_state
embedding = embedding[:, 0, :].squeeze(1)
- DINO-v2: 通过专注于自我监督学习来生成嵌入,利用第一个标记来捕获以对象为中心的细节。
image_processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model = AutoModel.from_pretrained('facebook/dinov2-base')# prepare input image
inputs = image_processor(img, return_tensors='pt')with torch.no_grad():outputs = model(**inputs)
embedding = outputs.last_hidden_state
embedding = embedding[:, 0, :].squeeze(1)
- CLIP: 结合图像和文本嵌入,使用图像特征来理解视觉概念以及来自配对文本的上下文数据。
image_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")# prepare input image
inputs = image_processor(images=img, return_tensors='pt', padding=True)with torch.no_grad():embedding = model.get_image_features(**inputs)
- BLIP-2: 采用视觉语言模型,通过其以查询为中心的转换器 (Q-Former) 提取特征来捕获图像语义和关系。
image_processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)inputs = image_processor(images=img, return_tensors='pt', padding=True)
print('input shape: ', inputs['pixel_values'].shape)with torch.no_grad():outputs = model.get_qformer_features(**inputs)
embedding = outputs.last_hidden_state
embedding = embedding[:, 0, :].squeeze(1)
- VGG16: 一种 CNN 模型,通过应用一堆卷积层来输出标记嵌入,强调分层图像表示。
model = models.vgg16(pretrained=True)
model.eval() # Set the model to evaluation modebatch_t = torch.unsqueeze(img, 0)with torch.no_grad():embedding = model(batch_t)
接着将每个模型提取的图像特征,转换为DataFrame数据,这将作为相似性分析的基础。
步骤 3:使用FAISS余弦相似度
通过上面的方法将图像通过各个模型进行特征提取,并将特征转换成dataframe的形式。利用余弦相似度来计算图像相似程度。余弦相似度比较两个向量的方向,使其能够有效地根据模式而不是大小来识别关系。这种方法在分析数据相似度上特别有用,其中重点是相对形状和像素元素,而不是特征向量的绝对大小。
-
归一化:每个特征向量都归一化为单位长度,因此余弦相似度可以计算为向量的点积。这确保相似性反映了向量之间的角度。
-
用于相似性搜索的 FAISS:利用 FAISS(一个针对高效相似性搜索而优化的库),根据其标准化特征向量,根据测试的数据查找前 K 个最相似的国家/地区。在大型旗帜图像数据集上进行快速且可扩展的比较。
def clean_feature_string(feature_str):cleaned_str = re.sub(r'[\[\]]', '', feature_str) # Remove bracketscleaned_values = np.fromstring(cleaned_str, sep=' ') # Parse values into numpy arrayreturn cleaned_values# Function to get top K similar countries using FAISS
def get_top_k_similar_countries(input_country, df, k=5):countries = df['Country'].valuesfeatures = np.array([clean_feature_string(f) for f in df['features'].values])# Find the index of the input countrytry:input_idx = list(countries).index(input_country)except ValueError:return f"Country '{input_country}' not found in the dataset."input_embedding = features[input_idx].reshape(1, -1)# Normalize the feature vectors for cosine similarityfeatures_normalized = features / np.linalg.norm(features, axis=1, keepdims=True)# Create a FAISS index for similarity searchdim = features.shape[1]index = faiss.IndexFlatIP(dim) # Add all features to the FAISS indexindex.add(features_normalized)# Search for the top K most similar countriesdistances, top_k_idx = index.search(input_embedding, k+1) # k+1 to exclude the country itself# Return top K countries with their similarity scoresreturn [(countries[i], distances[0][j]) for j, i in enumerate(top_k_idx[0]) if i != input_idx]## Display top 5 similar flags
top_5_countries = get_top_k_similar_countries(country, k=5)for idx, (country, score) in enumerate(top_5_countries):# Load the flag image for each country from the local folderimg = load_local_image(country)display(img)
步骤4: 模型测试
测试 1:乍得和罗马尼亚 所有模型都返回“罗马尼亚”作为最佳匹配。

测试 2:澳大利亚和新西兰 所有模型都正确识别了新西兰。
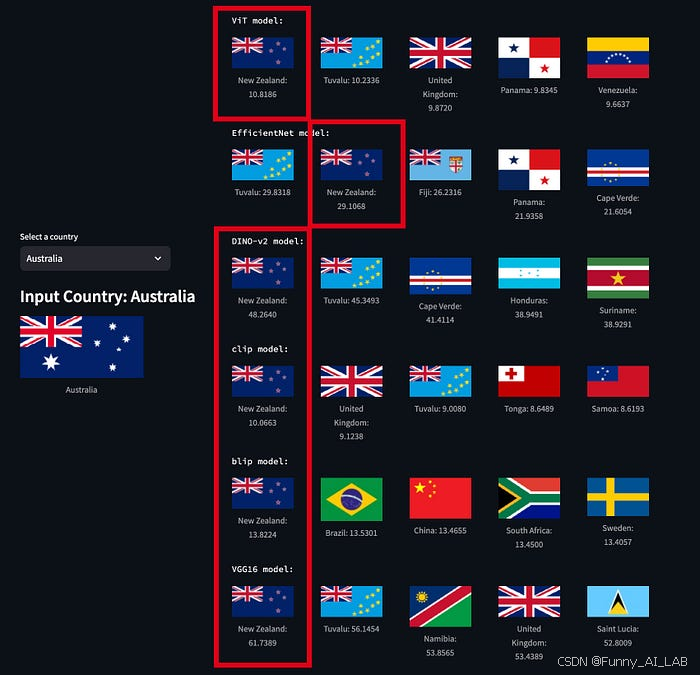
完整版代码如下:
# script to generate embeddings and perform similarity searchesimport pandas as pd
import torch
from transformers import AutoImageProcessor, EfficientNetModel, ViTModel, AutoModel, CLIPProcessor, CLIPModel, Blip2Processor, Blip2Model
from torchvision import models, transforms
import numpy as np
import os
import re
import faiss
flags_df = pd.read_csv('national_flags.csv') # Uncomment if you're loading from a CSV
IMAGE_DIR = "images"
def load_local_image(country_name):# Sanitize the country name to match the local image file naming conventionsanitized_country_name = country_name.replace(" ", "_").replace("[", "").replace("]", "")# Path to the local image fileimage_path = os.path.join(IMAGE_DIR, f"{sanitized_country_name}.png")# Check if the image exists in the folderif os.path.exists(image_path):img = Image.open(image_path)# Convert image to RGB if not already in that modeif img.mode != 'RGB':img = img.convert('RGB')return imgelse:print(f"Image for {country_name} not found.")return None
#ViTdef extract_features_vit(country):image_processor = AutoImageProcessor.from_pretrained("google/vit-large-patch16-224-in21k")model = ViTModel.from_pretrained("google/vit-large-patch16-224-in21k")# prepare input imageimg = load_local_image(country)inputs = image_processor(img, return_tensors='pt')with torch.no_grad():outputs = model(**inputs)embedding = outputs.last_hidden_stateembedding = embedding[:, 0, :].squeeze(1)return embedding.numpy()
#EfficientNetdef extract_features_efficientNet(country):# load pre-trained image processor for efficientnet-b7 and model weightimage_processor = AutoImageProcessor.from_pretrained("google/efficientnet-b7")model = EfficientNetModel.from_pretrained("google/efficientnet-b7")# prepare input imageimg = load_local_image(country)inputs = image_processor(img, return_tensors='pt')with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)embedding = outputs.hidden_states[-1]embedding = torch.mean(embedding, dim=[2,3])return embedding.numpy()#DINO-v2def extract_features_DINO_v2(country):# load pre-trained image processor for efficientnet-b7 and model weightimage_processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')model = AutoModel.from_pretrained('facebook/dinov2-base')# prepare input imageimg = load_local_image(country)inputs = image_processor(img, return_tensors='pt')with torch.no_grad():outputs = model(**inputs)embedding = outputs.last_hidden_stateembedding = embedding[:, 0, :].squeeze(1)return embedding.numpy()#CLIPdef extract_features_clip(country):# load pre-trained image processor for efficientnet-b7 and model weightimage_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")# prepare input imageimg = load_local_image(country)inputs = image_processor(images=img, return_tensors='pt', padding=True)with torch.no_grad():embedding = model.get_image_features(**inputs) return embedding.numpy()#Blip 2def extract_features_blip(country):image_processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)img = load_local_image(country)inputs = image_processor(images=img, return_tensors='pt', padding=True)print('input shape: ', inputs['pixel_values'].shape)with torch.no_grad():outputs = model.get_qformer_features(**inputs)embedding = outputs.last_hidden_stateembedding = embedding[:, 0, :].squeeze(1)return embedding.numpy()#vgg16def extract_features_vgg16(country):model = models.vgg16(pretrained=True) model.eval() # Set the model to evaluation mode# Define the transformation to preprocess the imagepreprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])img = load_local_image(country)img_t = preprocess(img)batch_t = torch.unsqueeze(img_t, 0)with torch.no_grad():embedding = model(batch_t)return embedding.numpy()# Extract features for all flags
flags_df['features'] = flags_df['Country'].apply(extract_features_vit)
#export embeddings to CSV
flags_df.to_csv('national_flag_embeddings_blip.csv', index=False)
#Cosine similarity with FAISSdf = pd.read_csv('embeddings/national_flag_embeddings_vit.csv')
country = "Australia"def clean_feature_string(feature_str):cleaned_str = re.sub(r'[\[\]]', '', feature_str) # Remove bracketscleaned_values = np.fromstring(cleaned_str, sep=' ') # Parse values into numpy arrayreturn cleaned_values# Function to get top K similar countries using FAISS
def get_top_k_similar_countries(input_country, df, k=5):countries = df['Country'].valuesfeatures = np.array([clean_feature_string(f) for f in df['features'].values])# Find the index of the input countrytry:input_idx = list(countries).index(input_country)except ValueError:return f"Country '{input_country}' not found in the dataset."input_embedding = features[input_idx].reshape(1, -1)# Normalize the feature vectors for cosine similarityfeatures_normalized = features / np.linalg.norm(features, axis=1, keepdims=True)# Create a FAISS index for similarity searchdim = features.shape[1]index = faiss.IndexFlatIP(dim) # Add all features to the FAISS indexindex.add(features_normalized)# Search for the top K most similar countriesdistances, top_k_idx = index.search(input_embedding, k+1) # k+1 to exclude the country itself# Return top K countries with their similarity scoresreturn [(countries[i], distances[0][j]) for j, i in enumerate(top_k_idx[0]) if i != input_idx]# Display top 5 similar flags
top_5_countries = get_top_k_similar_countries(country, k=5)for idx, (country, score) in enumerate(top_5_countries):# Load the flag image for each country from the local folderimg = load_local_image(country)display(img)获取数据代码:
script to scrape flag images from Wikipedia and download images
import pandas as pd
import requests
from bs4 import BeautifulSoup
import os
import pandas as pd
import requests
from PIL import Image
from io import BytesIO
# URL of the Wikipedia page
url = "https://en.wikipedia.org/wiki/List_of_national_flags_of_sovereign_states"# Send a GET request to the URL
response = requests.get(url)# Parse the content of the page with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')# Find the table with the flags
table = soup.find('table', class_='wikitable')# Initialize lists to store the names and images
names = []
images = []# Iterate through the rows of the table
for row in table.find_all('tr')[1:]: # Skip the header rowflag_cell = row.find('td')name_cell = row.find('th') # Extract the name cell# Check if both cells are foundif flag_cell and name_cell:# Extract the country namename = name_cell.get_text(strip=True)# Extract the flag image URL (from the <img> tag)img_tag = flag_cell.find('img')if img_tag and img_tag.has_attr('src'):# Construct the full image URLimg_url = "https:" + img_tag['src']else:img_url = None# Append the results to the listsnames.append(name)images.append(img_url)# Create a DataFrame with the results
flags_df = pd.DataFrame({'Country': names,'Flag Image': images
})# Display the DataFrame# Optionally, save the DataFrame to a CSV file
flags_df.to_csv('national_flags.csv', index=False)
相关文章:
AI图像相似性搜索对比:VIT, CLIP, DINO-v2, BLIP-2
图像相似性搜索的核心在于一个简单的想法:图像可以表示为高维空间中的向量。当两个图像相似时,它们的向量应该在这个空间中占据相似的位置。我们可以通过测量角度(或余弦相似度)来确定这些向量的相似程度。如果角度小,…...
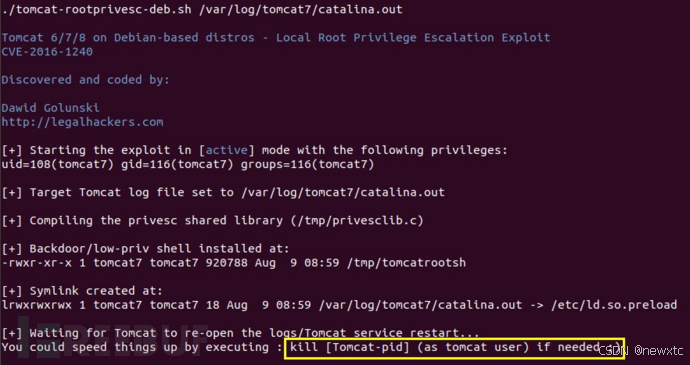
【tomcat系列漏洞利用】
Tomcat 服务器是一个开源的轻量级Web应用服务器,在中小型系统和并发量小的场合下被普遍使用。主要组件:服务器Server,服务Service,连接器Connector、容器Container。连接器Connector和容器Container是Tomcat的核心。一个Container…...
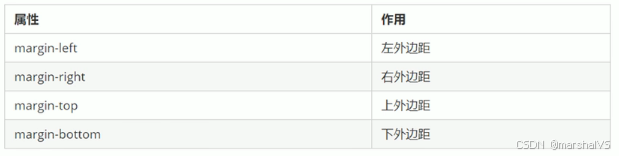
前端学习-盒子模型(十八)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 盒子模型组成 边框 语法 边框简写 代码示例 表格的细线边框 语法 内边距 内边距复合写法 外边距 外边距典型应用 外边距合并 清除内外边距 总结 前…...
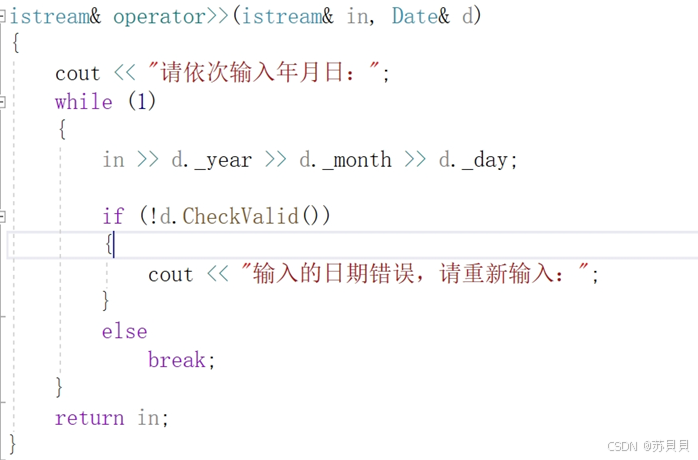
【C++】类和对象(十二):实现日期类
大家好,我是苏貝,本篇博客带大家了解C的实现日期类,如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 1 /!/>/</>/<运算符重载2 /-//-运算符重载(A) 先写,再通过写(B…...
文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《提升系统频率支撑能力的“车-氢”柔性可控负荷协同构网控制》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源…...

异或的性质
交换两个变量的值,不使用第三个变量。 即a3,b5,交换之后a5,b3; 有两种解法, 一种用算术算法, 一种用^(异或) a a b; b a - b; a a - b; or a a^b;// 只能对int,char… b a^b; a a^b; or a ^ b ^ a; 异或交换两个变量值的方法是利用了异或运算的特性。下面是…...

新一代Webshell管理器
工具介绍 游魂是一个开源的Webshell管理器,提供更为方便的界面和更为简单易用的功能,可配合或代替其他webshell管理器,帮助用户在各类渗透场景中控制目标机器。游魂不仅支持常见的一句话webshell以及常见Webshell管理器的功能,还…...

「iOS」——知乎日报一二周总结
知乎日报仿写 前言效果Manager封装网络请求线程冲突问题下拉刷新添加网络请求的图片通过时间戳和日期格式化获取时间 总结 前言 前两周内容的仿写,主要完成了首页的仿写,进度稍慢。 效果 Manager封装网络请求 知乎日报的仿写需要频繁的申请网络请求&am…...

windows C#-匿名类型
匿名类型提供了一种方便的方法,可用来将一组只读属性封装到单个对象中,而无需首先显式定义一个类型。 类型名由编译器生成,并且不能在源代码级使用。 每个属性的类型由编译器推断。 可结合使用 new 运算符和对象初始值设定项创建匿名类型。 …...
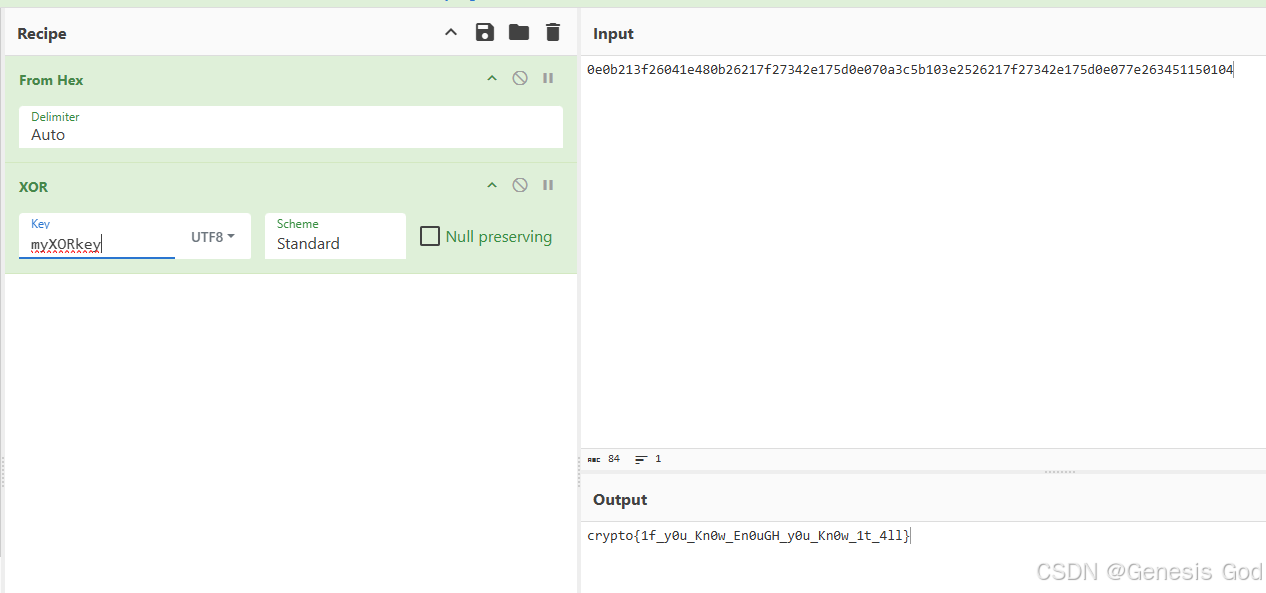
CryptoHack 简介
CryptoHack 简介 文章目录 CryptoHack 简介一、python的安装,运行二、ASCII码三、十六进制四、Base64五、字节和大整数六、XOR1.基本2.xor属性3.xor隐藏字节4.cryptohack——You either know, XOR you dont 一、python的安装,运行 二、ASCII码 chr()函数…...

transformControls THREE.Object3D.add: object not an instance of THREE.Object3D.
把scene.add(transformControls);改为scene.add(transformControls.getHelper());...

游戏开发与游戏运营:哪个更难?
在探讨游戏产业时,游戏开发和游戏运营是两个至关重要的环节。它们各自承担着不同的职责,共同推动着游戏产品的成功与发展。然而,关于哪个环节更难的问题,并没有一个绝对的答案,因为两者都涉及复杂的流程、专业技能和独…...

大模型在自动化渗透测试中的应用
1. 引言 随着人工智能技术的快速发展,特别是大模型(如GPT-3、GPT-4等)的出现,自动化渗透测试领域迎来了新的机遇。大模型具有强大的自然语言处理能力和生成能力,能够在多个环节提升渗透测试的效率和准确性。本文将详细…...

《AI在企业战略中的关键地位:以微软和阿里为例》
内容概要 在当今商业环境中,人工智能(AI)的影响力如滔滔洪水,愈演愈烈。文章将揭示AI在企业战略中的崛起,尤其以微软和阿里巴巴为代表的企业,这两家科技巨头通过不同方式,将智能技术融入其核心…...

C语言 | Leetcode C语言题解之第537题复数乘法
题目: 题解: bool parseComplexNumber(const char * num, int * real, int * image) {char *token strtok(num, "");*real atoi(token);token strtok(NULL, "i");*image atoi(token);return true; };char * complexNumberMulti…...

Vue如何实现数据的双向绑定和局部更新?
1、Vue如何实现数据的双向绑定和局部更新? Vue.js中数据的双向绑定和局部更新可以通过v-model指令来实现。v-model是一个内置的双向数据绑定机制,用于将输入元素(如input、textarea、select等)与Vue实例的数据进行双向绑定。 在…...

java学习1
一、运算符 1.算术运算符 在代码中,如果有小数参与计算,结果有可能不精确 1-1.隐式转换和强制转换 数字进行运算时,数据类型不一样不能运算,需要转成一样的,才能运算 (1)隐式转换:…...

如何缩小PPT演示文稿的大小?
有时候PPT的磁盘空间一不小心就变得意想不到的大,比如上百MB,该如何缩小PPT的大小从而便于上传或者携带呢? 导致PPT大的原因: 媒体文件在插入或者复制到演示文稿里会被直接涵盖在其中(.pptx版本)…...

闯关leetcode——234. Palindrome Linked List
大纲 题目地址内容 解题代码地址 题目 地址 https://leetcode.com/problems/palindrome-linked-list/description/ 内容 Given the head of a singly linked list, return true if it is a palindrome or false otherwise. Example 1: Input: head [1,2,2,1] Output: tru…...

通过源码分析类加载器里面可以加载的类
类列表 每一个ClassLoader里面的类列表,类的数量都是固定的。 对上一节中的dex反编译 使用DexClassLoader类动态加载插件dex 利用jadx对dex进行反编译可以看到有哪些类 源码分析 BaseDexClassLoader 从BaseDexClassLoader类加载器开始分析 在BaseDexClassLoade…...
在 Windows 平台上的官方下载选项列表)
Python 3.13.7(发布于 2025 年 8 月 14 日)在 Windows 平台上的官方下载选项列表
Python 3.13.7(发布于 2025 年 8 月 14 日)在 Windows 平台上的官方下载选项列表,包含多种架构(x64、x86/32-bit、ARM64)和两种分发形式: Windows installer:标准图形化安装程序(含…...
)
从炸管到稳定运行:我的MOSFET应用避坑实录(附热设计、驱动电路实测数据)
从炸管到稳定运行:我的MOSFET应用避坑实录 去年夏天,当我设计的48V转12V DC-DC模块第三次在高温测试中炸毁时,实验室里弥漫的焦糊味终于让我意识到:MOSFET的应用远不是选个低Rds(on)就万事大吉。作为从业十年的电源工程师&#x…...

深度解析DeepMIMO:毫米波大规模MIMO信道建模的5个架构设计决策
深度解析DeepMIMO:毫米波大规模MIMO信道建模的5个架构设计决策 【免费下载链接】DeepMIMO-matlab DeepMIMO dataset and codes for mmWave and massive MIMO applications 项目地址: https://gitcode.com/gh_mirrors/de/DeepMIMO-matlab 在5G/6G通信系统演进…...

暗黑2终极增强:PlugY插件如何彻底改变你的单机游戏体验
暗黑2终极增强:PlugY插件如何彻底改变你的单机游戏体验 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 还在为暗黑破坏神2单机模式的种种限制而烦恼吗&am…...

AI简历被秒拒?项目描述的4个细节,决定你能否拿到面试
AI简历被秒拒?项目描述的4个细节,决定你能否拿到面试金三银四求职季,不少求职者靠着AI工具快速生成简历,却发现投出的简历石沉大海、屡屡秒拒。很多人疑惑,自己的技术栈、项目经验明明符合岗位要求,为什么连…...

行业研究报告怎么选:看清咨询公司的“真本事”
一、为什么大家都在找“靠谱的行业研究报告”这几年,不论是创业公司做战略决策,还是大型企业布局新业务,几乎都有一个共识——决策要有数据、有研究、有趋势支撑。于是,“行业研究报告”成了商业决策的必备工具,但市场…...

腾讯混元OCR实战体验:上传图片秒出文字,支持100多种语言识别
腾讯混元OCR实战体验:上传图片秒出文字,支持100多种语言识别 1. 产品概述与核心优势 1.1 什么是腾讯混元OCR 腾讯混元OCR是基于腾讯混元原生多模态架构开发的轻量化文字识别系统。这个工具最吸引人的地方在于,它只需要1B(10亿&…...

非参数回归实战:从理论到Python实现
1. 非参数回归:当数据拒绝被简单定义时 记得第一次接触回归分析时,老师用"用直线拟合数据点"来解释线性回归。但当我把这个方法用在实际项目中时,发现很多数据根本不像教科书里画的那样规整。那些弯弯曲曲的数据点,像是…...

解决SlowFast环境配置中的‘No module named torch._six’等疑难杂症:从修改压缩包到调整import路径
SlowFast环境配置深度排障指南:从源码修改到路径调整的完整解决方案 在视频理解领域,SlowFast作为Facebook Research开源的优秀框架,凭借其双路径网络设计在动作识别任务中表现出色。然而,许多开发者在环境配置阶段就会遭遇各种&q…...

新一代指控系统依然是:人机环
AI是强大的“赋能器”和“加速器”,但指挥的艺术、责任和最终决断必须由人掌握。基于俄乌、美以伊博弈的案例,构建新一代“人机环境融合”体系化指控系统的具体实践路径已经清晰。AI的定位:从“自动化”到“智能化辅助”美军Maven系统&#x…...