网络安全法详细介绍——爬虫教程
目录
- @[TOC](目录)
- 一、网络安全法详细介绍
- 1. 网络安全法的主要条款与作用
- 2. 网络安全法与爬虫的关系
- 3. 合法使用爬虫的指南
- 二、爬虫的详细教程
- 1. 准备环境与安装工具
- 2. 使用`requests`库发送请求
- 3. 解析HTML内容
- 4. 使用`robots.txt`规范爬虫行为
- 5. 设置请求间隔
- 6. 数据清洗与存储
- 三、实战示例:爬取一个公开的新闻网站
目录
- @[TOC](目录)
- 一、网络安全法详细介绍
- 1. 网络安全法的主要条款与作用
- 2. 网络安全法与爬虫的关系
- 3. 合法使用爬虫的指南
- 二、爬虫的详细教程
- 1. 准备环境与安装工具
- 2. 使用`requests`库发送请求
- 3. 解析HTML内容
- 4. 使用`robots.txt`规范爬虫行为
- 5. 设置请求间隔
- 6. 数据清洗与存储
- 三、实战示例:爬取一个公开的新闻网站

小知学网络
一、网络安全法详细介绍
1. 网络安全法的主要条款与作用
《中华人民共和国网络安全法》(以下简称“网络安全法”)于2017年6月1日正式施行,旨在保障网络空间的秩序与安全。作为一部专门的网络安全法律,它主要涉及以下几个方面:
-
网络运行安全:企业和个人必须确保网络系统安全运行,采用必要的安全措施防止数据泄露、篡改和破坏。
-
数据保护:网络安全法严格规定了对个人数据和重要数据的采集、传输和储存等处理过程,确保数据在使用中的合法性。未经用户同意,禁止随意收集、贩卖或公开个人隐私数据。
-
法律责任:一旦违反网络安全法的相关规定,企业或个人可能会面临处罚,包括但不限于罚款、业务停顿、责任追究等,严重的可能触犯刑法。
2. 网络安全法与爬虫的关系
对于爬虫行为,网络安全法规定了数据的合法使用和隐私保护。具体来说:
-
未经授权的数据采集:网络安全法要求在采集数据时获得用户或被爬取平台的授权。未经授权的数据爬取可能被视为非法访问,尤其当爬取的数据涉及个人隐私信息(如姓名、身份证号等)时。
-
robots.txt协议:虽然robots.txt协议并不具备法律效力,但它是网站用于告知爬虫访问限制的公开声明。爬虫在采集数据前应先检查网站的robots.txt文件,确定可以爬取的部分。 -
爬虫频率与访问压力:爬虫如果短时间内发起大量请求,可能对网站服务器造成压力,导致服务中断或网站宕机。这种情况可能被网站视为攻击行为,进而触发法律追责。
3. 合法使用爬虫的指南
在实际操作中,如果需要采集公开数据,建议采取以下合法合规的步骤:
-
联系网站管理者,获得许可:有些网站允许开发者申请API或开放数据接口。通过官方渠道获取数据既安全,又符合网站的使用规定。
-
避免采集敏感信息:明确数据用途,排除敏感信息,采集时注意隐私保护。
-
遵守采集频率限制:例如,每秒发起一次请求或设置请求间隔,确保不会影响网站的正常运行。
二、爬虫的详细教程
爬虫技术是网络数据分析和机器学习模型的基础数据源之一。以下是详细的爬虫教程,从工具安装到数据提取再到合法合规使用的全流程。
1. 准备环境与安装工具
爬虫通常使用Python进行编写。以下是需要安装的库:
requests:用于发送HTTP请求。BeautifulSoup:用于解析HTML结构,提取数据。time(内置库):用于控制请求间隔,避免短时间内发送过多请求。
安装命令如下:
pip install requests
pip install beautifulsoup4
2. 使用requests库发送请求
requests库可以帮助我们像浏览器一样访问网页。下面的示例展示了如何获取网页内容:
import requestsurl = "https://example.com"
response = requests.get(url)# 检查请求状态
if response.status_code == 200:html_content = response.text # 获取HTML内容print("请求成功!网页内容如下:")print(html_content[:500]) # 打印前500字符
else:print("请求失败,状态码:", response.status_code)
注意:成功的请求通常返回状态码200,其他状态码(如404)表示资源未找到。爬虫操作时应注意避免频繁请求,以免被网站屏蔽。
3. 解析HTML内容
使用BeautifulSoup解析HTML内容,可以提取特定的数据标签,例如标题、链接或图片等。以下示例展示了如何提取标题标签(<h1>)的内容:
from bs4 import BeautifulSoup# 假设获取到的HTML内容在html_content中
soup = BeautifulSoup(html_content, "html.parser")# 提取所有标题
titles = soup.find_all("h1")
for title in titles:print("标题:", title.get_text())
在实际应用中,我们可以根据网站结构使用多种解析方法,例如按标签、属性或ID提取数据。
4. 使用robots.txt规范爬虫行为
在爬虫启动前,应先检查网站的robots.txt文件,确定允许爬取的范围。以下是查看robots.txt文件的简单代码示例:
robots_url = "https://example.com/robots.txt"
robots_response = requests.get(robots_url)
if robots_response.status_code == 200:print("robots.txt 内容如下:")print(robots_response.text)
else:print("未找到 robots.txt 文件。")
5. 设置请求间隔
为了减少对服务器的影响,可以在每次请求之间设置间隔时间。以下示例展示了如何设置爬虫的访问频率:
import timeurls = ["https://example.com/page1", "https://example.com/page2"]for url in urls:response = requests.get(url)if response.status_code == 200:print("成功获取数据:", url)else:print("请求失败:", url)# 设置延时time.sleep(2) # 延时2秒
6. 数据清洗与存储
爬取的数据可能包含多余信息或需要进一步整理。我们可以使用Python的pandas库对数据进行清洗,并将清洗后的数据存储为CSV文件。
安装pandas库:
pip install pandas
存储示例:
import pandas as pddata = {"Title": ["Example Title 1", "Example Title 2"]}
df = pd.DataFrame(data)
df.to_csv("data.csv", index=False) # 将数据保存为CSV文件
print("数据已保存至 data.csv 文件中。")
三、实战示例:爬取一个公开的新闻网站
下面是一个简单的实例,用于爬取一个公开的新闻网站的标题,最终将数据保存到CSV文件中。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time# 定义目标网址列表
urls = ["https://news.example.com/page1", "https://news.example.com/page2"]titles = [] # 用于存储标题for url in urls:response = requests.get(url)if response.status_code == 200:soup = BeautifulSoup(response.text, "html.parser")page_titles = soup.find_all("h2", class_="news-title")for title in page_titles:titles.append(title.get_text())print(f"{url} 爬取完成。")else:print(f"{url} 请求失败。")# 间隔时间time.sleep(2)# 保存数据至 CSV 文件
df = pd.DataFrame({"Title": titles})
df.to_csv("news_titles.csv", index=False)
print("所有数据已保存至 news_titles.csv 文件。")
这段代码示例展示了完整的爬虫流程,从请求网页、提取数据到保存数据,符合初学者的使用需求。
关于网络安全法和基础爬虫教程的重要内容总结成的表格,以便更直观地查看每个步骤和要点:
| 部分 | 主要内容 | 具体描述 |
|---|---|---|
| 网络安全法 | 主要条款与作用 | 保护网络空间安全,防止数据泄露和篡改;规范个人数据处理,确保隐私;违规可能导致罚款、责任追究等。 |
| 数据保护 | 限制个人数据采集和处理,需获得用户授权;不得未经授权收集、出售或公开个人数据。 | |
| 爬虫与网络安全法的关系 | 未授权爬取可能违反网络安全法;应查看robots.txt协议以确认可爬取范围;未经授权采集隐私信息属违规。 | |
| 爬虫基础教程 | 工具安装 | 安装Python环境,使用requests库发送请求,BeautifulSoup解析HTML,pandas用于数据存储与清洗。 |
| 发送请求 | 使用requests.get(url)获取网页内容,检查状态码确保请求成功(200);若请求失败,需调整访问策略或检查链接。 | |
| 解析HTML | 使用BeautifulSoup解析HTML结构,通过标签或类名提取数据,如标题、图片或链接等信息。 | |
robots.txt协议 | 在请求前先检查网站的robots.txt文件,了解允许爬取的内容,避免违反网站政策。 | |
| 请求频率控制 | 为避免对服务器造成压力,在每次请求间设置延时(例如2秒),防止被网站屏蔽或限制访问。 | |
| 数据清洗与存储 | 使用pandas对爬取的数据进行整理,将清洗后的数据保存为CSV文件,便于后续分析和处理。 | |
| 实战示例 | 爬取新闻网站标题并存储为CSV | 使用循环遍历网址列表,提取标题并存储至列表,利用pandas保存为CSV;每次请求后设置2秒延时。 |
| 合规建议 | 联系数据所有者 | 获得网站官方API或数据接口授权,避免非法访问;确保采集的数据不包含敏感信息,遵循合法性和合理性原则。 |
| 遵守数据隐私 | 确保爬虫仅访问公开数据,严格控制爬虫的访问频率,遵守合法合规要求。 |
相关文章:
网络安全法详细介绍——爬虫教程
目录 [TOC](目录)一、网络安全法详细介绍1. 网络安全法的主要条款与作用2. 网络安全法与爬虫的关系3. 合法使用爬虫的指南 二、爬虫的详细教程1. 准备环境与安装工具2. 使用requests库发送请求3. 解析HTML内容4. 使用robots.txt规范爬虫行为5. 设置请求间隔6. 数据清洗与存储 三…...

PCB什么情况该敷铜,什么情况不该敷铜!
更多电路设计,PCB设计分享及分析,可关注本人微信公众号“核桃设计分享”! 这个是老生常谈的问题了,可私底下还是有很多小伙伴问核桃这个问题,所以今天就好好聊一聊这个话题。 先说结论:PCB不是什么时候都可…...
标准化的企业级信息管理系统信息中心必备PHP低代码平台
谈谈企业级信息管理系统! 1. 标准化的企业级信息管理系统是信息中心必备,这才是集团该用的信息化管理系统。其有个很大特点是便于开发,能服务于企业技术中心,为其提供强大工具能力,在工具能力架构下通过流程、表单、报…...

Rust 力扣 - 1984. 学生分数的最小差值
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 原数组 nums 排序,遍历nums中下标为[0, nums.len() - k]的学生分数 假设当前遍历的下标为i则,以 i 下标为最小值的学生分数的最小差值为nums[i k - 1] - nums[i] 取最小差值的最小值即…...
【098】基于SpringBoot+Vue实现的垃圾分类系统
系统介绍 视频演示 基于SpringBootVue实现的垃圾分类系统 基于SpringBootVue实现的垃圾分类系统设计了三种角色、分别是管理员、垃圾分类管理员、用户,实现了个人中心、用户管理、垃圾分类管理员管理、垃圾分类管理、垃圾类型管理、垃圾图谱管理、系统管理等功能 …...

STM32CUBEIDE FreeRTOS操作教程(八):queues多队列
STM32CUBEIDE FreeRTOS操作教程(八):queues多队列 STM32CUBE开发环境集成了STM32 HAL库进行FreeRTOS配置和开发的组件,不需要用户自己进行FreeRTOS的移植。这里介绍最简化的用户操作类应用教程。以STM32F401RCT6开发板为例&#…...

SIGNAL TAP使用记录
一、首先编译工程 二、打开signal tap,并设置抓取时钟以及采样深度 二、点击set up,然后双击空白处,会弹出右侧窗口,点击filter选择pre_synthesis,这里选择综合前的信号观测,要确保左侧窗口内的信号是黑色…...

基于vue3和elementPlus的el-tree组件,实现树结构穿梭框,支持数据回显和懒加载
一、功能 功能描述 数据双向穿梭:支持从左侧向右侧转移数据,以及从右侧向左侧转移数据。懒加载支持:支持懒加载数据,适用于大数据量的情况。多种展示形式:右侧列表支持以树形结构或列表形式展示。全选与反选…...

彻底理解链表(LinkedList)结构
目录 比较操作结构封装单向链表实现面试题 循环链表实现 双向链表实现 链表(Linked List)是一种线性数据结构,由一组节点(Node)组成,每个节点包含两个部分:数据域(存储数据ÿ…...

TON 区块链开发的深入概述#TON链开发#DAPP开发#交易平台#NFT#Gamefi链游
区块链开发领域发展迅速,各种平台为开发人员提供不同的生态系统。其中一个更有趣且越来越相关的区块链是TON(开放网络)区块链。TON 区块链最初由 Telegram 构思,旨在提供快速、安全且可扩展的去中心化应用程序 (dApp)。凭借其独特…...

Hive专栏概述
Hive专栏概述 Hive“出身名门”,是最初由Facebook公司开发的数据仓库工具。它简单且容易上手,是深入学习Hadoop技术的一个很好的切入点。专栏内容包括:Hive的安装和配置,其核心组件和架构,Hive数据操作语言,…...

鼠标悬停后出现小提示框实现方法
大家在网页上会经常看到某些图标或文字,当鼠标悬停后会在四周某个位置出现一个简短的文字提示,这种提示分为两种,一种是提示固定的文字,例如放在qq图标上,会显示固定的文字“QQ”;第二种是显示鼠标所在标签…...

计算机视觉常用数据集Foggy Cityscapes的介绍、下载、转为YOLO格式进行训练
我在寻找Foggy Cityscapes数据集的时候花了一番功夫,因为官网下载需要用公司或学校邮箱邮箱注册账号,等待审核通过后才能进行下载数据集。并且一开始我也并不了解Foggy Cityscapes的格式和内容是什么样的,现在我弄明白后写下这篇文章…...

css中的样式穿透
1. >>> 操作符 <style scoped> /* 影响子组件的样式 */ .parent >>> .child {color: red; } </style>注意:>>> 操作符在某些预处理器(如Sass)中可能无法识别,因为它不是标准的CSS语法。 …...

MMCA:多模态动态权重更新,视觉定位新SOTA | ACM MM‘24 Oral
来源:晓飞的算法工程笔记 公众号,转载请注明出处 论文: Visual Grounding with Multi-modal Conditional Adaptation 论文地址:https://arxiv.org/abs/2409.04999论文代码:https://github.com/Mr-Bigworth/MMCA 创新点 提出了多模…...
)
linux同步执行命令脚本 (xcall)
linux同步执行命令脚本 (xcall) 1、在/usr/local/bin目录下 创建xcall文件 vim /usr/local/bin/xcall2、输入内容 #!/bin/bash # 获取控制台指令 判断指令是否为空 pcount$# if((pcount0)); thenecho "command can not be null !"exit fifor host in bigdata01 …...

opencv - py_imgproc - py_grabcut GrabCut 算法提取前景
文章目录 使用 GrabCut 算法进行交互式前景提取目标理论演示 使用 GrabCut 算法进行交互式前景提取 目标 在本章中 我们将了解 GrabCut 算法如何提取图像中的前景我们将为此创建一个交互式应用程序。 理论 GrabCut 算法由英国剑桥微软研究院的 Carsten Rother、Vladimir K…...

ChatGPT多模态命名实体识别
ChatGPT多模态命名实体识别 ChatGPT辅助细化知识增强!一、研究背景二、模型结构和代码任务流程第一阶段:辅助精炼知识启发式生成第二阶段:基于…...
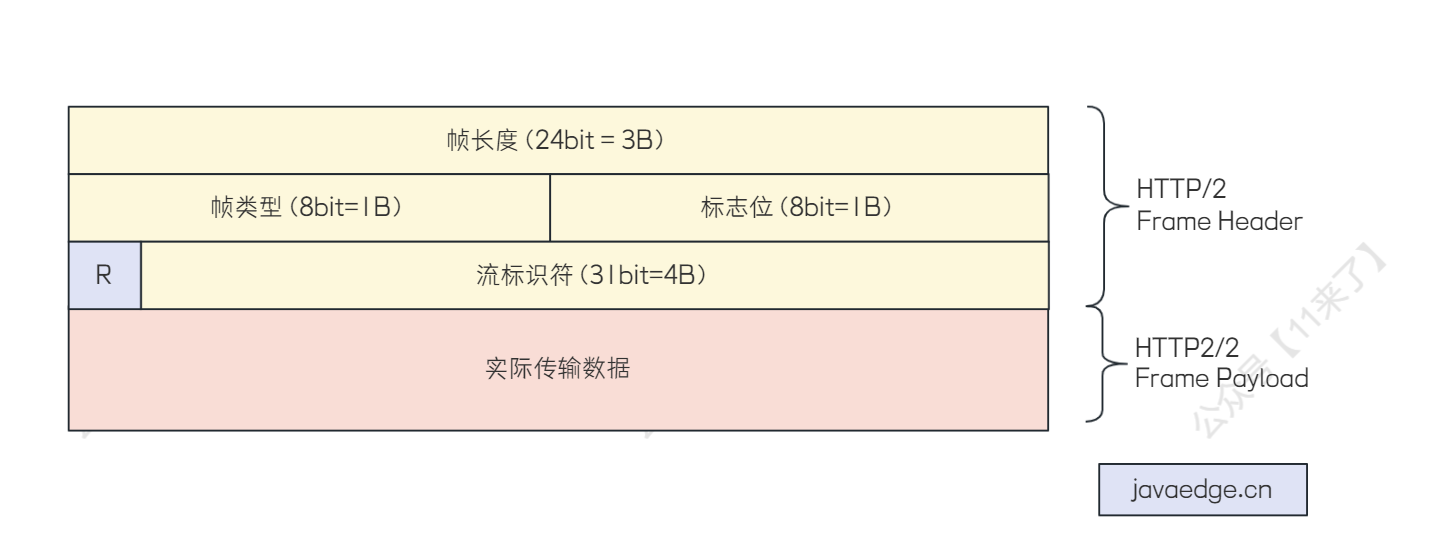
04-Dubbo的通信协议
04-Dubbo的通信协议 Dubbo 支持的通信协议 Dubbo 框架提供了自定义的高性能 RPC 通信协议: 基于 TCP 的 Dubbo2 协议 基于 HTTP/2 的 Triple 协议 Dubbo 框架是不和任何通信协议绑定的,对通信协议的支持非常灵活,支持任意的第三方协议&#x…...

开源数据库 - mysql - innodb源码阅读 - 线程启动
线程启动源码 /** Start up the InnoDB service threads which are independent of DDL recovery.*/void srv_start_threads() {if (!srv_read_only_mode) {/* Before 8.0, it was master thread that was doing periodicalcheckpoints (every 7s). Since 8.0, it is the log …...

别再手动配置时钟树了!用STM32CubeMX 6.10 + Keil MDK 5分钟搞定LED闪烁工程
5分钟极速开发:STM32CubeMX图形化工具颠覆传统嵌入式开发模式 第一次接触STM32开发时,面对密密麻麻的寄存器手册和复杂的时钟树配置,我花了整整三天才让一个LED灯闪烁起来。直到发现STM32CubeMX这个神器——它彻底改变了嵌入式开发的入门门槛…...

基于小安派-Eyes-DU的PWM呼吸灯实现:从环境搭建到代码烧录全解析
1. 项目概述上周,安信可开源硬件社区发布了一款名为“小安派-Eyes-DU”的新板子,我第一时间就入手了。作为一名嵌入式开发爱好者,拿到新板子后的第一件事,自然是想办法“点亮”它,看看它的能耐。官方资料里提到了一个亮…...

STHS34PF80红外存在检测:InfraredPD算法库集成与调试实战
1. 项目概述与核心价值最近在折腾一个智能家居的节能项目,核心需求是让设备能精准判断房间里到底有没有人,而不是简单地检测到有物体移动就触发。市面上很多基于PIR(被动红外)的运动传感器,对于静止不动的人体识别效果…...

GESP学习,如何判断孩子是否适合跳级
判断孩子是否适合跳级,核心是综合评估其学术能力、心理成熟度、社交适应力及政策合规性。以下是基于教育规律与官方政策的系统性判断标准: 一、学术能力:是否真正“学有余力” 1、成绩特别优异: 在当前年级中,各…...

Bash脚本集成AI:实现智能运维自动化与决策增强
1. 项目概述:当Bash脚本遇见AI,自动化运维的“智能大脑”如果你和我一样,是个常年和Linux服务器、运维脚本打交道的“老运维”或开发者,那你肯定对Bash脚本又爱又恨。爱的是它的直接、高效,几行命令就能串联起复杂的系…...

子网掩码实战:从原理到网络规划的深度解析
1. 子网掩码的核心原理 第一次接触子网掩码时,我也被那一串数字搞得晕头转向。直到有次公司网络改造,亲眼看到老工程师用子网划分解决了IP地址不足的问题,才真正明白它的价值。简单来说,子网掩码就像邮局的邮政编码系统 - 它告诉网…...

粒子物理实验中的异构计算与AI技术应用
1. 粒子物理实验的计算挑战与机遇 粒子物理实验正经历前所未有的数据爆炸时代。以大型强子对撞机(HL-LHC)为例,其升级后的数据采集率将达到每秒数PB级别,这相当于每天产生约1亿张高清照片的数据量。传统基于CPU的串行计算架构已无…...

Visual C++运行库终极修复指南:一键解决“缺少DLL文件“的完整解决方案
Visual C运行库终极修复指南:一键解决"缺少DLL文件"的完整解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软…...

NVIDIA Profile Inspector终极指南:解锁700+显卡隐藏设置,提升游戏性能30%
NVIDIA Profile Inspector终极指南:解锁700显卡隐藏设置,提升游戏性能30% 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款强大的开源显卡配置工具…...

Yii2开启URI伪静态的相关配置
Yii2 开启URI伪静态的相关配置 Yii2支持url伪静态链接转换,在配置文件config/web.php中加入 # config/web.php $config [components > [// URI伪静态化配置urlManager > [enablePrettyUrl > true, // 启用美化 URL(隐藏 index.php)…...