【MySQL 保姆级教学】 复合查询--超级详细(10)
复合查询
- 1. 复合查询的作用
- 2. 创建将进行操作的表
- 2.1 员工表 emp
- 2.2 部门表 dept
- 2.3 薪资等级表
- 3. 基本查询回顾
- 4. 多表查询
- 4.1 多表查询的定义
- 4.2 笛卡尔积
- 4.3 内连接 inner join
- 4.4 交叉连接 cross join
- 4.5 左外连接 left join
- 4.6 右外连接 right join
- 4.7 自连接
- 5. 子查询
- 5.1 单行子查询
- 5.2 多行子查询
- 5.2.1 in 关键字
- 5.2.2 all 关键字
- 5.2.3 any 关键字
- 5.3 多列子查询
- 5.3.1 多列单行子查询
- 5.3.2 多列多行子查询
- 5.4 from子句中使用子查询
- 6. 临时表
- 7. 合并查询
- 7.1 union 交集
- 7.2 union all 并集
1. 复合查询的作用
复合查询的主要作用包括:
- 数据整合:
通过连接多个表,你可以将分散在不同表中的相关信息整合到一起,形成一个完整的数据集。这对于需要从多个来源获取信息的报告和分析非常有用。 - 提高效率:
相比于多次查询不同的表并将结果手动合并,复合查询可以一次性完成所有操作,减少了与数据库的交互次数,提高了性能。 - 数据关联:
在数据库设计中,通常会使用规范化来减少数据冗余,这意味着相关数据会被存储在不同的表中。复合查询可以帮助你根据表之间的外键关系重新关联这些数据。 - 条件筛选:
复合查询可以让你基于多个表的数据进行复杂的条件筛选。例如,你可以选择满足特定条件的所有记录,即使这些条件涉及多个表中的字段。 - 简化应用逻辑:
在应用程序中,直接使用复合查询可以从数据库层面上处理复杂的逻辑,这样可以简化应用程序代码,并且将业务逻辑更多地放在数据库层面,这有助于维护和优化。
2. 创建将进行操作的表
2.1 员工表 emp
创建表:
CREATE TABLE emp (empno INT PRIMARY KEY,ename VARCHAR(10),job VARCHAR(10),mgr INT,hiredate DATE,sal DECIMAL(7,2),comm DECIMAL(7,2),deptno INT
);
插入数据:
INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, comm, deptno) VALUES
(7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800.00, NULL, 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600.00, 300.00, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250.00, 500.00, 30),
(7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975.00, NULL, 20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250.00, 1400.00, 30),
(7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850.00, NULL, 30),
(7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450.00, NULL, 10),
(7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000.00, NULL, 20),
(7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000.00, NULL, 10),
(7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500.00, 0.00, 30),
(7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100.00, NULL, 20),
(7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950.00, NULL, 30),
(7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000.00, NULL, 20),
(7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300.00, NULL, 10);
2.2 部门表 dept
创建表:
CREATE TABLE dept (deptno INT PRIMARY KEY,dname VARCHAR(255),loc VARCHAR(255)
);
插入数据:
INSERT INTO dept (deptno, dname, loc)
VALUES
(10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON');
2.3 薪资等级表
创建表:
CREATE TABLE salgrade (grade TINYINT PRIMARY KEY,losal SMALLINT,hisal SMALLINT
);
插入数据:
INSERT INTO salgrade (grade, losal, hisal)
VALUES
(1, 700, 1200),
(2, 1201, 1400),
(3, 1401, 2000),
(4, 2001, 3000),
(5, 3001, 9999);
3. 基本查询回顾
-
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
说明:(薪资>500 or job =MANAGR)and 姓名首写为J
命令:select * from emp where (sal>500 or job='MANAGER') and ename like 'J%';
-
按照部门号升序而雇员的工资降序排序
说明:asc–升序;desc–降序
命令:select * from emp order by deptno asc, sal desc;
-
使用年薪进行降序排序
说明:年薪=月薪*12+ifnull(comm,0); comm可能为空值NUll,空值NULL和任何值进行运算都为空置,需要使用ifnull()函数
命令:
错误示例:select ename, sal*12+ifnull(comm,0) as '年薪' from emp order by '年薪' desc;
同学们可以发现,年薪并没有进行排序,这是为什么呢?
答:在这个查询中,'年薪'被当作字符串常量来处理,而不是列别名(此时的列别名是年薪)。因此,这个查询不会按预期的方式工作。正确的写法应该是去掉引号。正确示例:
select ename, sal*12+ifnull(comm,0) as '年薪' from emp order by 年薪 desc;
-
显示工资最高的员工的名字和工作岗位
说明:select max(sal) from emp只能聚合出最高薪,把此最高薪作为条件。
命令:select ename, job from emp where sal=(select max(sal) from emp)
-
显示工资高于平均工资的员工信息
说明:select avg(sal) from emp把该查询的结果作为条件
命令:select * from emp where sal>(select avg(sal) from emp);
-
显示每个部门的平均工资和最高工资
说明:先把部门聚合,然后使用聚合函数;最高工资max(),平均工资avg(),使用format()函数格式平均数
命令:select deptno, max(sal) '最高工资', format(avg(sal),2) '最低工资' from emp group by deptno;
-
显示平均工资低于2000的部门号和它的平均工资
说明:having 平均工资 <2000
命令:
错误示例:select deptno, format(avg(sal),2) '平均工资' from emp group by deptno having 平均工资 < 2000;
同学们可以发现,这里的平均工资<2000并没有起作用,这是为什么呢?
答:因为having子句用于过滤分组后的结果,format(avg(sal),2)处理后的结果不再属于分组后的结果,重命名的 ‘平均工资’ 的列不再是分组后的列名,分组后的列名是avg(sal)。正确示例:
命令:select deptno, format(avg(sal),2) '平均工资' from emp group by deptno having avg(sal) <2000;
命令:
select deptno, avg(sal) '平均工资' from emp group by deptno having 平均工资 <2000;
-
显示每种岗位的雇员总数,平均工资
说明:以 job 聚合
命令:select job,count(*), format(avg(sal),2) from emp group by job;

4. 多表查询
4.1 多表查询的定义
多表查询是指在数据库中从两个或多个表中检索数据的SQL查询。这种查询允许用户基于某些条件将不同表中的数据连接起来,从而获得更复杂和全面的信息。多表查询是关系型数据库管理系统的强大功能之一,它能够帮助用户分析和处理分布在多个表中的数据。
在进行多表查询时,通常会使用到JOIN操作,JOIN可以分为几种类型,包括:
INNER JOIN(内连接):返回两个表中匹配的所有行。只有当两个表中存在匹配的数据时,才会产生结果记录。
LEFT JOIN(左连接):返回左表中的所有记录,以及右表中与之匹配的记录;如果右表没有匹配,则结果中右表的字段为NULL。
RIGHT JOIN(右连接):返回右表中的所有记录,以及左表中与之匹配的记录;如果左表没有匹配,则结果中左表的字段为NULL。
FULL OUTER JOIN(全外连接):返回左表和右表中的所有记录,当某一边没有匹配时,另一边的字段将填充为NULL。
CROSS JOIN(交叉连接):返回左表和右表的笛卡尔积,即左表的每一行与右表的每一行组合。
4.2 笛卡尔积
笛卡尔积(Cartesian Product)是指两个表中所有行的组合。具体来说,如果表 A 有 m 行,表 B 有 n 行,那么它们的笛卡尔积将包含 m×n行,每行是表 A 中的一行与表 B 中的一行的组合。
定义
在数据库中,笛卡尔积是通过 CROSS JOIN 操作实现的。如果没有指定任何连接条件,结果集将包含所有可能的行组合()。CROSS JOIN 可以显式地使用 CROSS JOIN 关键字,也可以通过逗号, 分隔表名并在 WHERE 子句中不指定任何连接条件来实现。
示例:
创建表t1:
create table t1(name char(10));insert into t1 values('李明'), ('李华'), ('李刚');
创建表t2:
create table t2(name char(10));insert into t2 values('高渐离'), ('王昭君'), ('嫦娥');
查询两个表:
命令:select * from t1 cross join t1;

或 命令:select * from t1, t2;

图解:

4.3 内连接 inner join
定义:返回两个表中匹配的所有行。只有当两个表中存在匹配的数据时,才会产生结果记录。
语法:
SELECT *
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
ON 子句的主要作用:
- 指定连接条件:
ON 子句用于指定两个表之间的连接条件,这些条件决定了哪些行应该被组合在一起。 - 过滤结果集:
通过 ON 子句,可以有效地过滤掉不符合条件的行,从而减少结果集的大小,提高查询性能。 - 提高查询的可读性和维护性:
使用 ON 子句可以使查询更加清晰和易于理解,特别是对于复杂的多表查询。
将连接条件放在 ON 子句中,而不是放在 WHERE 子句中,可以使查询结构更加明确,便于维护和调试。
示例:
显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自emp和dept表,因此要联合查询
命令:
# 使用 inner join 时可以省略inner,单独使用joinselect emp.ename, emp.sal, dept.dnamefrom emp inner join depton emp.deptno = dept.deptno;

图解:

一种简单的写法:
select ename, sal, dname
from emp join dept
on emp.deptno = emp.deptno
4.4 交叉连接 cross join
语法:
SELECT t1.id, t1.name, t2.city
FROM t1
CROSS JOIN t2;
CROSS JOIN 生成的是笛卡尔积,但你可以通过 WHERE 子句来过滤结果集,从而实现类似于 INNER JOIN 的效果。
示例:
显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自emp和dept表,因此要联合查询
命令:
select emp.ename, emp.sal, dept.dname
from emp , dept
where emp.deptno = dept.deptno;

图解:

4.5 左外连接 left join
定义:返回左表中的所有记录,以及右表中与之匹配的记录;如果右表没有匹配,则结果中右表的字段为 NULL。
语法:
SELECT *
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
示例:
创建两张表:
-- 建两张表
create table stu (id int, name varchar(30)); -- 学生表
insert into stu values(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');create table exam (id int, grade int); -- 成绩表
insert into exam values(1, 56),(2,76),(11, 8);
查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来
命令:
select * from stu left join exam
on stu.id = exam.id;

由上图图可以看出,左边表的内容去全部显示出来,右边表内进行对左表进行匹配。当左边表和右边表没有匹配时,也会显示左边表的数据,但是,右边表的数据为空。
4.6 右外连接 right join
定义:返回右表中的所有记录,以及左表中与之匹配的记录;如果左表没有匹配,则结果中左表的字段为 NULL。
语法:
SELECT *
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
示例:
创建两张表:
-- 建两张表
create table stu (id int, name varchar(30)); -- 学生表
insert into stu values(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');create table exam (id int, grade int); -- 成绩表
insert into exam values(1, 56),(2,76),(11, 8);
查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来
命令:
select * from exam left join stu
on stu.id = exam.id;

由上图可知,右侧表的内容全部显示出来,左侧的表进行匹配,如果匹配不到数据,则显示空。
4.7 自连接
定义:自连接是指在同一张表连接查询。
语法:
SELECT *
FROM table1 t1 , table1 t2
WHERE t1.column_name = t2.id;
注:自连接的表必须起别名
示例:
显示员工的姓名及上级领导姓名(mgr是员工领导的编号,empno是员工的编号)
领导也是员工,领导和员工都在emp表。
命令:
select t1.ename, t2.ename '领导' from emp t1, emp t2
where t1.mgr = t2.empno;

5. 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
5.1 单行子查询
定义:返回一行记录的子查询
示例:
-
显示SMITH同一部门的员工
命令:select ename from emp where emp.deptno = (select deptno from emp where ename='SMITH');
-
显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号;empno是员工编号)
命令:select empno, ename from emp where empno = (select mgr from emp where ename='FORD');
5.2 多行子查询
定义:返回多行记录的子查询
5.2.1 in 关键字
定义:用于检查某个值是否在一个列表中。它可以用在子查询中,也可以直接列出具体的值。
也可以使用 not in。
示例:
查询和10号部门的工作岗位相同的雇员,打印出他们的名字,岗位,工资,部门号,但是不包含10号自
己的
命令:
select ename, job, sal, deptno
from emp
where job in (select job from emp where deptno = 10) and deptno <> 10;

5.2.2 all 关键字
定义:用于比较一个值与子查询返回的所有值。通常与比较运算符(如 =, >, <, >=, <=, <>)一起使用。
有时可以使用 max() 或 min() 聚合函数代替。
示例:
显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
-
使用 all 关键字
命令:select ename, sal, deptno from emp where sal > all(select sal from emp where deptno =30);
-
使用 max() 聚合函数
命令:select ename, sal, deptno from emp where sal > (select max(sal) from emp group by deptno haivng deptno =30);
5.2.3 any 关键字
定义:用于比较一个值与子查询返回的任意一个值。通常与比较运算符(如 =, >, <, >=, <=, <>)一起使用。
有时可以使用 max() 或 min() 聚合函数代替。
示例:
显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
-
使用 any 关键字
命令:select ename, sal, deptno from emp where sal > any(select sal from emp where deptno = 30);
-
使用 min() 聚合函数
命令:select ename,sal, ddptno from emp where sal > (select min(sal) from emp group by deptno having deptno=30);
5.3 多列子查询
5.3.1 多列单行子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言
的,而多列子查询则是指查询返回多个列数据的子查询语句。
示例:
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
命令:
select * from emp
where (deptno,job) = (select deptno, job from emp where ename= 'SMITH') and ename <> 'SMITH';

5.3.2 多列多行子查询
多列多行子查询和多行子查询类似,也是用 in 关键字进行查询。
示例:
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
命令:
select * from emp
where (deptno,job) = (select deptno, job from emp where ename= 'SMITH') and ename <> 'SMITH';

5.4 from子句中使用子查询
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用(章节6讲解临时表)。
示例:
-
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
命令:select t1.ename, t1.deptno, t1.sal, t2.avgsal from emp t1, (select deptno, avg(sal) avgsal from emp group by deptno) t2 where t1.age > t2.avgsal and t1.deptno=t2.deptno;
-
查找每个部门工资最高的人的姓名、工资、部门、最高工资
命令:select t1.ename, t1.sal, t1.deptno, t2.maxsal from emp t1, (select deptno, max(sal) maxsal from emp group by deptno) t2 where t1.sal = t2.maxsal and t1.deptno= t2.deptno;
-
显示每个部门的信息(部门名,编号,地址)和人员数量
(1)使用多表查询:select t2.dname, t2.deptno,t2.loc, count(*) from emp t1, dept t2 where t1.deptno = t2.deptno group by t2.dname,t2.deptno,t2.loc;
(2)使用子查询
select t1.dname,t1.deptno,t1.loc, t2.count from dept t1, (select deptno, count(*) count from emp group by deptno) t2 where t1.deptno=t2.deptno;
6. 临时表
MySQL一切为表,查询结束、分组结束······后就会生一个临时表。
在某些情况下,MySQL 会使用临时表来存储中间结果。这些情况包括但不限于以下几种:
-
复杂的查询:
当查询涉及多个JOIN、UNION、GROUP BY、ORDER BY 或子查询时,MySQL 可能会创建临时表来存储中间结果。 -
分组和排序:
如果查询包含 GROUP BY 或 ORDER BY 子句,并且结果集较大,MySQL 可能会使用临时表来存储中间结果,以便进行分组或排序操作。 -
子查询:
在某些情况下,特别是当子查询的结果集较大时,MySQL 可能会将子查询的结果存储在临时表中。 -
临时表显式创建:
用户可以显式地创建临时表来存储中间结果,以提高查询性能或简化复杂查询。
MySQL 使用两种类型的临时表:
- 内存临时表(Memory Temporary Table):
- 这种临时表存储在内存中,使用 MEMORY 存储引擎。
- 内存临时表的优点是速度快,但受限于可用内存大小。如果数据量超过内存限制,MySQL 会自动将其转换为磁盘临时表。
- 磁盘临时表(Disk Temporary Table):
- 这种临时表存储在磁盘上,使用 MyISAM 或 InnoDB 存储引擎。
- 磁盘临时表的优点是可以处理更大的数据集,但速度相对较慢。
示例:
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
命令:
select t1.ename, t1.deptno, t1.sal, t2.avgsal
from emp t1, (select deptno, avg(sal) avgsal from emp group by deptno) t2
where t1.age > t2.avgsal and t1.deptno=t2.deptno;

7. 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
7.1 union 交集
该操作符用于取得两个结果集的交集。当使用该操作符时,会自动去掉结果集中的重复行。
示例:
将工资大于2500或职位是MANAGER的人找出来
命令:
select * from emp where sal > 2500 union
select * from emp where job = 'MANAGER';

7.2 union all 并集
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
示例:
工资大于25000或职位是MANAGER的人找出来
命令:
select * from emp where sal >2500 union all
select * from emp where job = 'MANAGER';

相关文章:
【MySQL 保姆级教学】 复合查询--超级详细(10)
复合查询 1. 复合查询的作用2. 创建将进行操作的表2.1 员工表 emp2.2 部门表 dept2.3 薪资等级表 3. 基本查询回顾4. 多表查询4.1 多表查询的定义4.2 笛卡尔积4.3 内连接 inner join4.4 交叉连接 cross join4.5 左外连接 left join4.6 右外连接 right join4.7 自连接 5. 子查询…...
ONLYOFFICE:数字化办公的创新解决方案与高效协作平台
目录 前言—— 关于 ONLYOFFICE 桌面编辑器 1.首页介绍 2.电子表格 功能介绍 适用场景 3.ONLYOFFICE 在线Word功能 4.ONLYOFFICE 在线PPT功能 5.共同办公室 6.探索其他 总结 前言—— 在数字化办公的时代,传统的办公软件常常让人感到束缚与低效。而 ONLY…...

编译Kernel时遇到“error: ‘linux/compiler_types.h‘ file not found“的解决方法
问题描述: 在下载了一份安卓13项目的代码后进行make bootimage编译时遇到了下面编译报错: In file included from /home/bspuser/scode/kernel/msm-4.19/include/uapi/linux/stat.h:5: In file included from /home/bspuser/scode/kernel/msm-4.19/inc…...

开发之翼:划时代的原生鸿蒙应用市场开发者服务
前言 随着"纯血鸿蒙" HarmonyOS NEXT在原生鸿蒙之夜的正式发布,鸿蒙生态正以前所未有的速度蓬勃发展。据知已有超过15000个鸿蒙原生应用和元服务上架,覆盖18个行业,通用办公应用覆盖全国3800万多家企业。原生鸿蒙操作系统降低了接…...

代码随想录一刷——1.两数之和
当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。 C: unordered_map class Solution { public: vector<int> twoSum(vector<int>& nums, int target) { unordered_map<int…...

vue自定义组件实现v-model双向数据绑定
一、Vue2 实现自定义组件双向数据绑定 ① v-model 实现双向数据绑定 在vue2中,子组件上使用v-model的值默认绑定到子组件的props.value属性上,由于子组件不能改变父组件传来的属性,所以需要通过$emit触发事件使得父组件中数据的变化…...

excel指定单元格输入相同的值,比如给D1~D10000输入现在的值
注意,一点不用用WPS,不然运行宏是会报:Droiact-Module1,第1行等Λ列语法错误: Unexpected identifier 步骤 1,altF11打开宏 2,输入脚本 3,点击运行按钮 成功后会看看到...
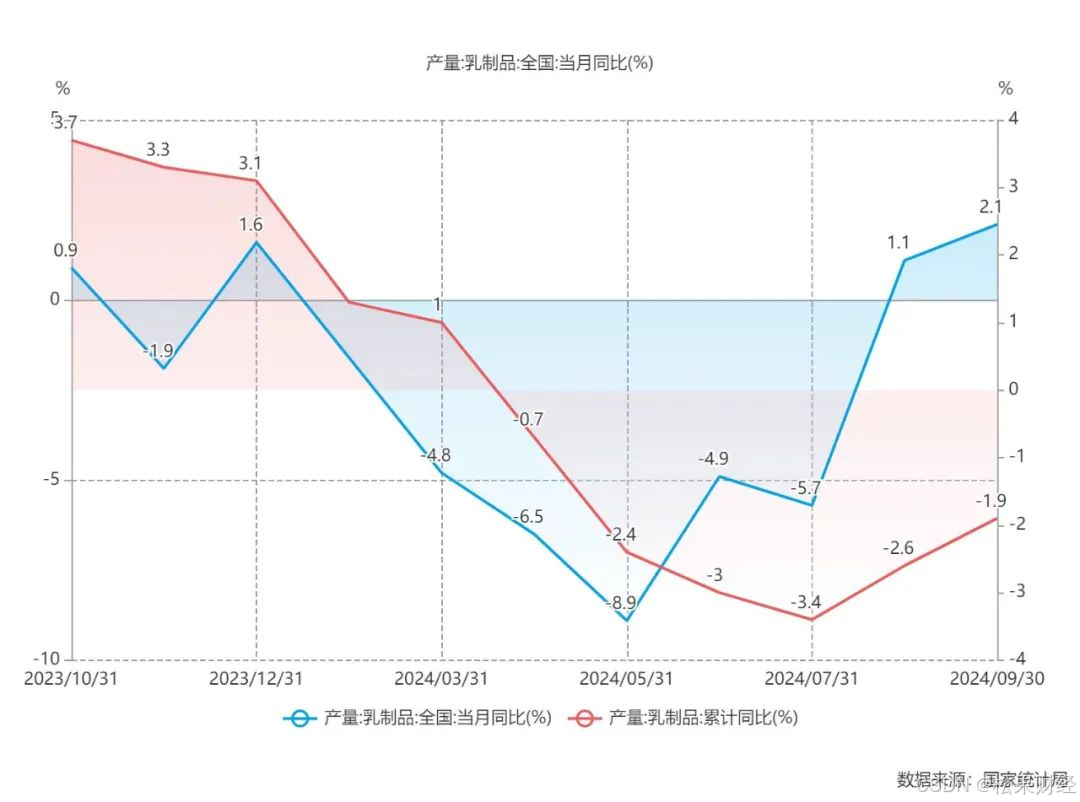
中国最强乳企伊利,三个季度净赚超百亿
伊利三季度的业绩完全超出了市场预期。 在一个飞天茅台都在不断跌价的消费趋势里,伊利三季度扣非净利润的同比增幅达到13.4%。大部分机构和投资者,都没料到伊利这一次的表现如此强悍。这一次,伊利在“大气层”。 并且,伊利前三季…...

SpringBoot源码解析(二):启动流程之引导上下文DefaultBootstrapContext
SpringBoot源码系列文章 SpringBoot源码解析(一):启动流程之SpringApplication构造方法 SpringBoot源码解析(二):启动流程之引导上下文DefaultBootstrapContext 目录 前言一、入口二、DefaultBootstrapContext1、BootstrapRegistry接口2、BootstrapCon…...

配置elk插件安全访问elk前台页面
编辑els配置文件vim elasticsearch.yml,添加以下配置文件 用elk用户,启动els服务 关闭防火墙,查看els启动是否成功,通过是否启动java进程来判断 或者通过查看是否启动9200和9300端口来判断是否启动 交互模式启动密码配置文件interactive表示交…...

[操作系统作业]页面置换算法实现(C++)
💓博主csdn个人主页:小小unicorn ⏩专栏分类:linux 🚚代码仓库:小小unicorn的代码仓库🚚 🌹🌹🌹关注我带你学习编程知识 目录 必做题代码分析(重点以时间统计…...

前端技术月刊-2024.11
本月技术月刊聚焦于前端技术的最新发展和业务实践。业界资讯部分,React Native 0.76 版本发布,带来全新架构;Deno 2.0 和 Node.js 23 版本更新,推动 JavaScript 生态进步;Flutter 团队规模缩减,引发社区关注…...
)
搜索引擎语法大全(Google、bing、baidu)
搜索引擎语法大全 搜索引擎语法通常指的是在搜索引擎中使用特定的运算符和语法来优化搜索结果。 提高搜索精度:使用特定的语法可以帮助用户更精确地找到相关信息,避免无关结果。例如,通过使用引号搜索确切短语,可以确保搜索结果包…...

java设计模式之行为型模式(11种)
行为型模式 行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。 行为型模式分为类行为模式和对象型模式,前者采用继承机制来在类间分派…...

微服务系列一:基础拆分实践
目录 前言 一、认识微服务 1.1 单体架构 VS 微服务架构 1.2 微服务的集大成者:SpringCloud 1.3 微服务拆分原则 1.4 微服务拆分方式 二、微服务拆分入门步骤 :以拆分商品模块为例 三、服务注册订阅与远程调用:以拆分购物车为例 3.1 …...

leetcode 1470.重新排列数组
1.题目要求: 2.题目代码: class Solution { public:vector<int> shuffle(vector<int>& nums, int n) {vector<int> x_array(nums.begin(),nums.begin() n);vector<int> y_array(nums.begin() n,nums.end());int x_index 0;int y_index 0;for…...

windows在两台机器上测试 MySQL 集群实现实时备份
在两台机器上测试 MySQL 集群实现实时备份的基本步骤: 一、环境准备 机器配置 确保两台机器(假设为服务器 A 和服务器 B)能够互相通信,例如它们在同一个局域网内,并且开放了 MySQL 通信所需的端口(默认是 …...

点晴模切ERP系统助力模切企业转型升级之路
随着我国制造业规模不断扩大,中国制造业已经从高速扩张转向深入挖潜的关键阶段。数字化转型不仅有助于提升企业的生产效率和管理水平,还能有效应对市场竞争,实现可持续发展。在数字化转型的过程中,企业资源规划(ERP&am…...

redis修改配置文件配置密码开启远程访问后台运行
编辑 Redis 配置文件 编辑 /etc/redis/redis.conf,设置必要的参数。 sudo vim /etc/redis/redis.conf设置后台运行: 找到以下行,将 no 改为 yes: daemonize yes设置密码: 找到以下行,取消注释并设置密码为…...
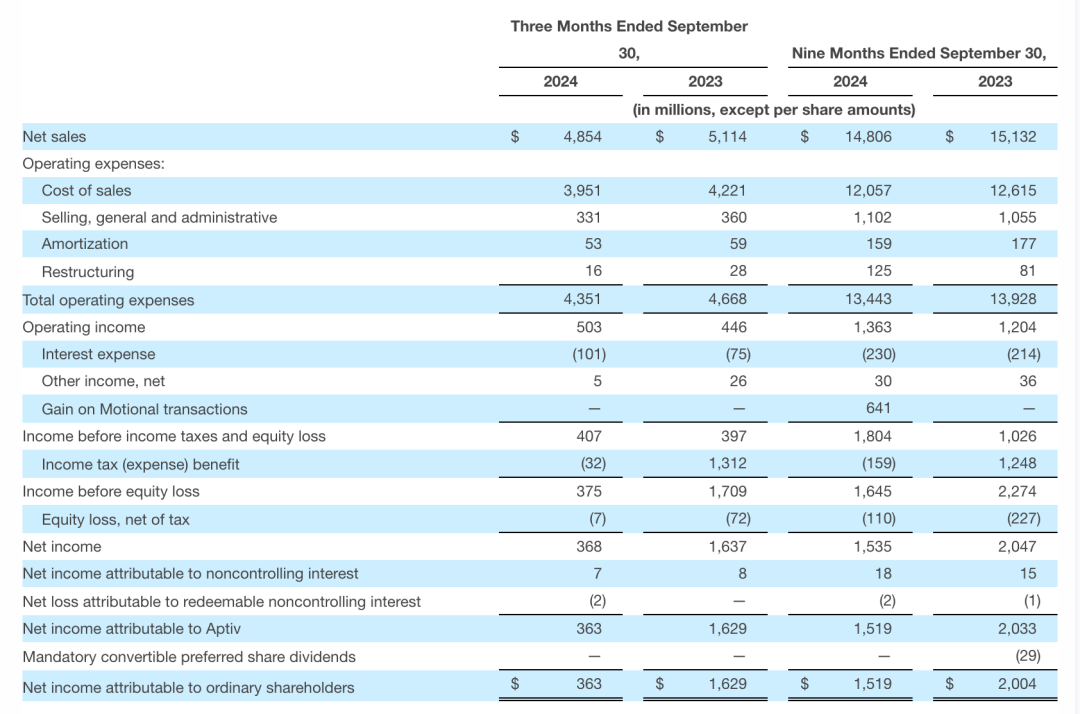
市场分化!汽车零部件「变天」
全球汽车市场的动荡不安,还在持续。 本周,全球TOP20汽车零部件公司—安波福(Aptiv)发布2024年第三季度财报显示,三季度公司经调整后确认收入同比下降6%;按照区域市场来看,也几乎是清一色的下滑景…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...