sklearn|机器学习:决策树(一)
文章目录
- sklearn|机器学习:决策树(一)
- (一)概述
- (二)实战
- 1. 环境配置
- 2. sklearn 中的决策树
- (1)模块 `sklearn.tree`
- (2)`sklearn` 基本建模流程
- (3)`DecisionTreeClassifier` 与红酒数据集
- a. `criterion`
- - 信息熵 vs 基尼系数
- - 参数选取
- - 决策树基本流程
- - 代码示例
- b. `random_state` & `splitter`
- c. 剪枝参数
- - `max_depth`
- - `min_samples_leaf` & `min_samples_split`
- - `max_features` & `min_impurity_decrease`
- - 最优剪枝参数选择
- d. 目标权重参数
- - `class_weight` & `min_weight_fraction_leaf`
- (4)重要属性和接口
- (5)补充
sklearn|机器学习:决策树(一)
本部分为基于**《菜菜的 sklearn 机器学习》课程的学习笔记,理论部分结合了周志华《机器学习》**来进行补充,scikit-learn 作为一个开源的 python 机器学习工具包,通过 Numpy, SciPy 和 Matploylib 等 python 数值计算的库实现高效的算法应用,涵盖了几乎所有主流机器学习算法。本课程主要介绍了 sklearn 的全面应用,具体包括 sklearn 中对算法的说明,调参,属性,接口,以及实例应用。
官网:https://scikit-learn.org/stable/index.html
(一)概述
决策树(Decision Tree)是一种非参数的有监督学习方法,非参数指不限制数据的结构和类型,有监督学习则指必须具有标签。决策树能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现,可用于解决分类和回归问题,其算法本质是一种图结构。
其他以树模型为核心的集成算法还有随机森林、AdaBoost。
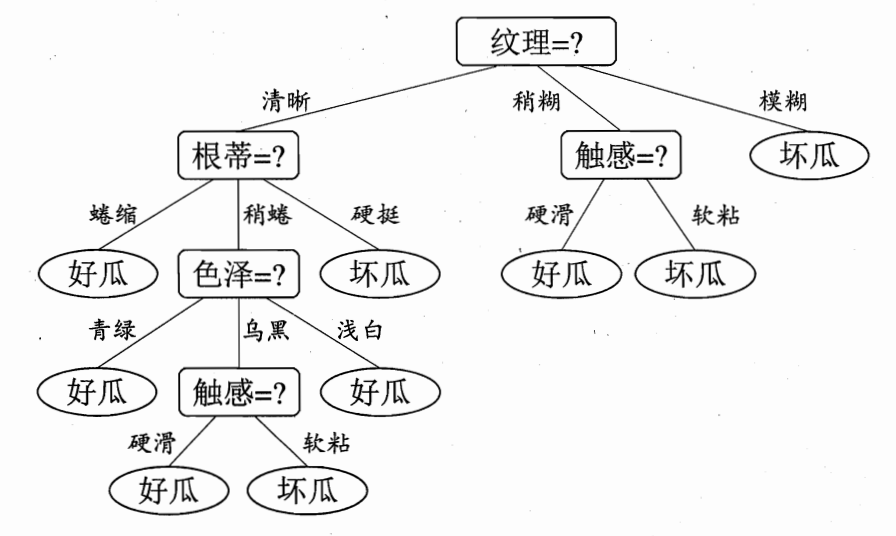
以上为基于西瓜好坏问题构建的决策树,其中最初问题所在地方为根结点(没有进边,有出边,包含最初针对特征的提问),得到结论前的每一个问题为中间节点(既有进边也有出边,进边只有一条,出边可以有多条,均为针对特征的提问),而得到的每一个结论为叶子结点(只有进边,没有出边,每个叶节点都是一个类别标签)。
子节点和父节点:在两个相连的节点中,更接近根节点的是父节点,另一个为子节点。
一般而言,决策树由一个根节点、若干个中间节点和若干个叶节点组成,叶节点对应于决策结果。
决策树算法核心问题:
-
如何从数据表中找出最佳节点和最佳分枝
-
如何让决策树停止生长,防止过拟合
(二)实战
1. 环境配置
本部分环境的安装主要参考了菜菜的开发环境:
此处能够使用 Anaconda,就不推荐使用 pip,因为 pip 安装一部分库的时候可能会出现异常,其默认下载的一部分库的版本可能只适用于 linux 系统,而 Anaconda 的安装一般不会有这个问题。
pip install numpy
pip install pandas
pip install scipy
pip install matplotlib
pip install -U scikit-learn
conda install python-graphviz
注意:Anaconda 的安装和 pip 的安装尽量不要混用,由 Anaconda 安装的库在使用 pip 卸载或是更新的时候,可能出现无法卸载干净,无法正常更新,或更新后一部分库变得无法运行的情况。
2. sklearn 中的决策树
(1)模块 sklearn.tree
sklearn 中决策树的类都在 tree 这个模块下,该模块共包含五类:
| tree.DecisionTreeClassifier | 分类树 |
|---|---|
| tree.DecisionTreeRegressor | 回归树 |
| tree.export_graphviz | 将生成的决策树导出为DOT格式,画图专用 |
| tree.ExtraTreeClassifier | 高随机版本的分类树 |
| tree.ExtraTreeRegressor | 高随机版本的回归树 |
(2)sklearn 基本建模流程
sklearn 具有对所有模型都通用的建模流程,总有以下三步:
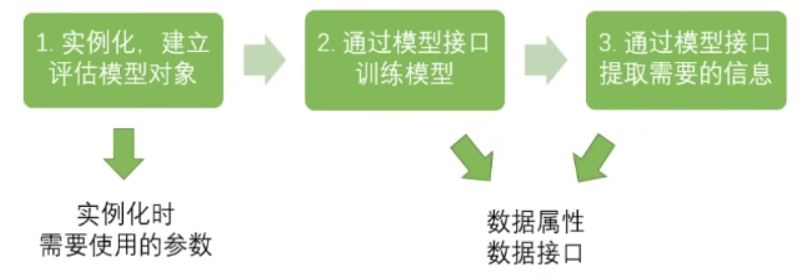
其对应分类树的代码为:
from sklearn import tree # 导入所需要的模块clf = tree.DecisionTreeClassifier() # 实例化模型,需要知道所使用的参数,并将其填充在()内
clf = clf.fit(X_train, y_train) # 用训练集数据训练模型,几乎所有模型均可以用fit来训练
result = clf.score(X_test, y_test) # 导入测试集,从接口中调用需要的信息,如score来获取分类模型的accuracy
(3)DecisionTreeClassifier 与红酒数据集
class DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)
a. criterion
决策树使用“不纯度”来确定最佳节点和最佳分枝方法,通常来说,“不纯度”越低说明决策树对训练集的拟合越好。不纯度基于节点计算,树中每个节点都有一个不纯度,每一层都有一个加权的不纯度。
在同一棵决策树上,子节点的不纯度一定低于父节点,且叶子结点的不纯度一定是最低的。
criterion 则是用来决定不纯度的计算方法的,其中 sklearn 提供了两种选择,默认使用基尼系数 :
-
输入
entropy,使用信息熵(Entropy)
E n t r o p y ( t ) = − ∑ i = 0 c − 1 p ( i ∣ t ) l o g 2 p ( i ∣ t ) Entropy(t)=-\sum_{i=0}^{c-1}p(i|t)log_2p(i|t) Entropy(t)=−i=0∑c−1p(i∣t)log2p(i∣t) -
输入
gini,使用基尼系数(Gini Impurity)
G i n i ( t ) = 1 − ∑ i = 0 c − 1 p ( i ∣ t ) 2 Gini(t)=1-\sum_{i=0}^{c-1}p(i|t)^2 Gini(t)=1−i=0∑c−1p(i∣t)2
其中,t代表给定节点,i代表标签的任意分类,p(i|t) 表示标签分类 i 在节点 t 上所占的比例。
当使用信息熵时,sklearn 实际计算的是基于信息上的信息增益,即父节点的信息熵和子节点的信息熵之差,在实际使用中,两者效果相当。
- 信息熵 vs 基尼系数
- 信息熵对不纯度更加敏感,对不纯度的惩罚最强,决策树的生长更精细,但对于高维数据或噪音较多的数据容易过拟合。
- 基尼系数计算更快,因为不涉及对数。
- 参数选取
- 通常使用基尼系数
- 数据维度较大,噪音较大时使用基尼系数
- 纬度低,数据较清晰时,信息熵与基尼系数没有区别
- 当决策树的拟合程度不够(欠拟合)时,使用信息熵
- 两者尝试选择更佳的
- 决策树基本流程

当没有更多特征可用或整体不纯度指标已达到最优时,决策树停止生长。
- 代码示例
# 导入模块和算法库
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split# 载入数据集
wine = load_wine()
wine # 字典
wine.data # 提取wine中的特征矩阵
wine.data.shape # 查看数据集格式,共有13个特征,178个样本
wine.target # 提取wine中的标签矩阵
# 如果不输入特征名和标签名,会输出对应的列数,不够直观
wine.feature_names # 查看特征名
wine.target_names # 查看标签名# 将字典变为表,前13列为特征,最后一列为标签
import pandas as pd
pd.concat([pd.DataFrame(wine.data), pd.DataFrame(wine.target)], axis=1)# 随机划分训练集和测试集,30%为测试集,70%为训练集,此处需要注意顺序为xxyy
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)
Xtrain # 查看划分后的训练集
Xtrain.shape # 查看划分后的训练集的结构,(124, 13)
Xtest # 查看划分后的测试集
Xtest.shape # 查看划分后的测试集的结构,(54, 13)# Step1:实例化
clf = tree.DecisionTreeClassifier(criterion="entropy")
# Step2:带入训练数据集进行训练
clf.fit(Xtrain, Ytrain)
# Step3:导入测试集计算模型得分
score = clf.score(Xtest, Ytest) # 返回预测的准确度accuracy
score # 0.9814814814814815,每次训练准确度都不一样# 可视化
import graphviz
feature_name = wine.feature_names # 可自定义
dot_data = tree.export_graphviz(clf,feature_names = feature_name,class_names = ["琴酒","雪莉","贝尔摩德"], # 标签名filled = True, # 是否填充颜色,颜色越深不纯度越低rounded = True) # 方框是否圆角
graph = graphviz.Source(dot_data)
graph
节点越往下,不纯度(entropy)越低,当不纯度为0时就可以选出一个标签类别,每个中间节点代表一个特征选择。其中,samples表示样本数,value表示三种label对应的样本数,class表示支持样本数最多的标签,且并非所有特征都会被使用。
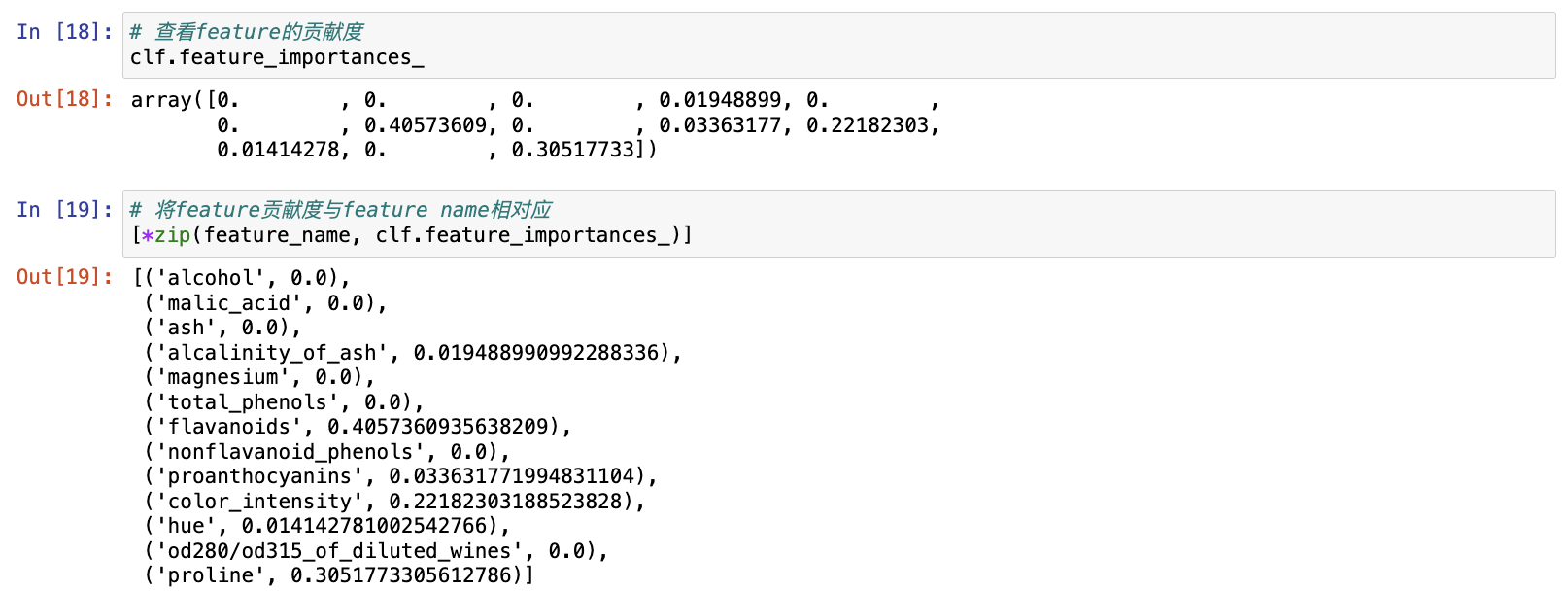
# 查看feature的贡献度,贡献度越高值越大,根节点对于决策树的贡献永远最高
clf.feature_importances_# 将feature贡献度与feature name相对应,形成元组
[*zip(feature_name, clf.feature_importances_)]
b. random_state & splitter
无论决策树模型如何进化,在分枝上的本质都还是追求某个不纯度相关指标的优化,决策树在建树时靠优化节点来追求一颗优化的树,但最优的节点并不能保证最优的树,因此sklearn使用了集成算法来解决该问题,即在每次分枝时,不使用全部特征,而是随机选取一部分特征,再从中选取不纯度相关指标最优的作为分枝用的节点,所以每次生成的树也不同。
random_state 用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会更明显,低维度的数据中随机性几乎不会显现。
# 解决随机性问题,random_state 默认为 None
clf = tree.DecisionTreeClassifier(criterion="entropy", random_state=30)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score
splitter 也可以控制决策树中的随机选项,有两种输入值:
- 输入"best",决策树在分枝时虽然随机,但是会优先选择更重要的特征进行分枝;
- 输入"random",决策树在分枝时更加随机,树会更深,对训练集的拟合将会降低,可以防止过拟合。
clf = tree.DecisionTreeClassifier(criterion="entropy", random_state=30,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score# 可视化
import graphviz
feature_name = wine.feature_names # 可自定义
dot_data = tree.export_graphviz(clf,feature_names = feature_name,class_names = ["琴酒","雪莉","贝尔摩德"], # 标签名filled = True, # 是否填充颜色,颜色越深不纯度越低rounded = True) # 方框是否圆角
graph = graphviz.Source(dot_data)
graph
注意:如果模型特征较多,可以使用以上两个参数来降低过拟合的可能性。
c. 剪枝参数
# 查看模型对训练集的拟合程度
score_train = clf.score(Xtrain, Ytrain)
score_train

如果模型在训练集上的拟合程度比在测试集上要好得多,则认为存在过拟合的问题,为了使决策树具有更好的泛化能力,需要对决策树进行剪枝。
- max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉(使用最广泛),通常在高纬度低样本量时非常有效,决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合,其在集成算法中也非常实用。
实际使用时,建议从=3开始尝试,再根据拟合的效果决定是否增加设定深度。
- min_samples_leaf & min_samples_split
min_samples_leaf 限定一个节点在分枝后的每个子节点都必须包含至少 min_samples leaf 个训练样本,否则分枝就不会发生,分枝会朝着满足每个子节点都包含 min_samples_leaf 个样本的方向去发生;一般搭配max_depth 使用,可以让模型变得更加平滑,且可以保证每个叶子的最小尺寸,能够在回归问题中避免低方差、过拟合的叶子节点出现。
注意:min_samples_leaf 设置过小会引起过拟合,设置过大会阻止模型学习数据。一般来说,建议从=5开始使用;如果叶节点中含有的样本量变化很大,建议输入浮点数作为样本量的百分比来使用。对于类别不多的分类问题,=1通常就是最佳选择。
min_samples_split 限定一个节点必须要包含至少 min_samples_split 个训练样本才允许被分枝,否则分枝就不会发生。
clf = tree.DecisionTreeClassifier(criterion="entropy", random_state=30,splitter="random",max_depth=3,min_samples_leaf=10,min_samples_split=10)
clf = clf.fit(Xtrain, Ytrain)
dot_data = tree.export_graphviz(clf,feature_names = feature_name,class_names = ["琴酒","雪莉","贝尔摩德"], filled = True,rounded = True)
graph = graphviz.Source(dot_data)
graph
- max_features & min_impurity_decrease
max_features 限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃,是用来限制高维度数据的过拟合的剪枝参数,直接限制可以使用的特征数量而强行使决策树停下。在不知道决策树中的各个特征的重要性的情况下,强行设定可能会导致模型学习不足。
如果希望通过降维的方式防止过拟合,建议使用PCA,ICA或者特征选择模块中的降维算法。
min_impurity_decrease 限制信息增益的大小,信息增益小于设定数值的分枝不会发生,信息增益越大代表该层分枝对于决策树的贡献越大。
- 最优剪枝参数选择
超参数的学习曲线是一条以超参数的取值为横坐标,模型的度量指标为纵坐标的曲线,用来衡量不同超参数取值下模型的表现。
import matplotlib.pyplot as plttest = []
for i in range(10):clf = tree.DecisionTreeClassifier(max_depth=i+1,criterion="entropy",random_state=30,splitter="random")clf = clf.fit(Xtrain, Ytrain)score = clf.score(Xtest, Ytest)test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
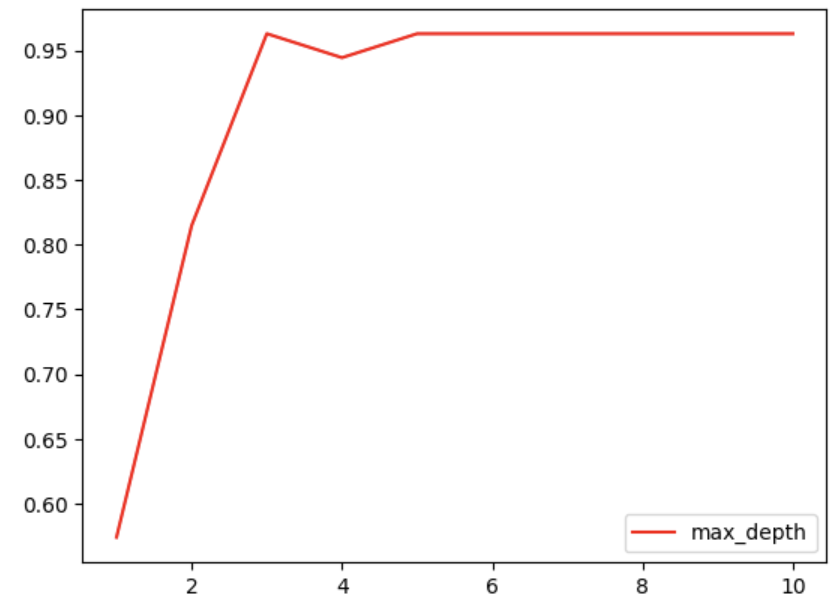
注意:调参并非一定能够提升模型在测试集上的表现,当数据集非常大时,建议提前设定剪枝参数来控制树的复杂性和大小,以免内存消耗过大。
d. 目标权重参数
- class_weight & min_weight_fraction_leaf
当样本存在不平衡,即标签中的某一类天生占有很大的比例,那么构建出的决策树会不可避免地向大比例的部分偏移,如银行在判断”一个办了信用卡的人是否会违约"时是vs否 (1%:99%)的比例,此时即便模型什么也不做,全把结果预测成“否",正确率也能有99%。因此需要使用 class_weight 参数对样本标签进行均衡,给少量的标签更多的权重,该参数默认None,表示自动给与数据集中的所有标签相同的权重。
设定权重后的剪枝将不仅仅只是单纯记录支持样本数,需要搭配 min_weight_fraction_leaf 基于权重来剪枝。
注意:基于权重的剪枝参数(如 min_weightfraction leaf )将比不知道样本权重的标准(如 min_samples leaf)更少偏向主导类;如果样本是加权的,使用基于权重的预修剪标准更容易优化树结构,确保叶节点至少包含样本权重的总和的一小部分。
(4)重要属性和接口
在 sklearn 中,除了 fit 和 score 几乎可以对每个算法使用,还有两个常用的接口:
apply:输入测试集返回每个测试样本所在叶子结点的索引predict:输入测试集返回每个测试样本的标签
所有接口中要求输入 Xtrain 和 Xtest 的部分,其输入的特征矩阵必须至少是一个二维矩阵,即至少有两个特征。
注意:sklearn 不接受任何一维矩阵作为特征矩阵被输入,如果只有一个特征,则需要用reshape(-1,1) 给矩阵增维;如果只有一个特征和一个样本,则需要使用 reshape(1,-1) 来增维。
# apply 返回每个测试样本所在叶子结点的索引
clf.apply(Xtest)# predict 返回每个测试样本的标签
clf.predict(Xtest)

(5)补充
分类树天生不擅长环形数据,每个模型都有自己的决策上限,当一个模型怎么调整都不行的时候,可以选择换其他的模型使用,最擅长月亮型数据的是最近邻算法,RBF支持向量机和高斯过程;最擅长环形数据的是最近邻算法和高斯过程;最擅长对半分的数据的是朴素贝叶斯,神经网络和随机森林。
KNN算法对月亮型和环型数据都具有很好的表现,但可调试范围较小,且计算量较大。
相关文章:
sklearn|机器学习:决策树(一)
文章目录 sklearn|机器学习:决策树(一)(一)概述(二)实战1. 环境配置2. sklearn 中的决策树(1)模块 sklearn.tree(2)sklearn 基本建模流…...

Rust中三种方式使用环境变量
环境变量是存储在操作系统中的一组键值对。它们用于存储系统和其他应用程序所需的配置信息。本文我们将探索如何在Rust中使用标准库以及dotenv crate来处理环境变量。 环境变量 环境变量提供了一种灵活的方式来配置应用程序,而无需直接在源代码中硬编码配置值。这…...

搭建支持国密GmSSL的Nginx环境
准备 1、服务器准备:本文搭建使用的服务器是CentOS 7.6 2、安装包准备:需要GmSSL、国密Nginx,可通过互联网下载或者从 https://download.csdn.net/download/m0_46665077/89936158 下载国密GmSSL安装包和国密Nginx安装包。 服务器安装依赖包…...
Docker部署Portainer CE结合内网穿透实现容器的可视化管理与远程访问
文章目录 前言1. 本地安装Docker2. 本地部署Portainer CE3. 公网远程访问本地Portainer-CE3.1 内网穿透工具安装3.2 创建远程连接公网地址4. 固定Portainer CE公网地址前言 本篇文章介绍如何在Ubuntu中使用docker本地部署Portainer CE可视化管理工具,并结合cpolar实现公网远程…...

不适合的学习方法
文章目录 不适合的学习方法1. 纯粹死记硬背2. 过度依赖单一资料3. 线性学习4. 被动学习5. 一次性学习6. 忽视实践7. 缺乏目标导向8. 过度依赖技术9. 忽视个人学习风格10. 过于频繁的切换 结论 以下是关于不适合的学习方法的更详细描述,包括额外的内容和相关公式&…...

在子类中调用父类的构造函数
在Java中调用父类构造函数 使用super()关键字:在子类的构造函数中,可以使用super()来调用父类的构造函数。如果父类有默认构造函数(即没有参数的构造函数),并且子类的构造函数没有显式调用super(),Java编译…...

【K8S系列】Kubernetes 中 Service 的流量不均匀问题【已解决】
在 Kubernetes 中,Service 是一种抽象,用于定义一组 Pod 的访问策略。当某些 Pod 接收的流量过多,而其他 Pod 的流量较少时,可能会导致负载不均衡。这种情况不仅影响性能,还可能导致某些 Pod 过载,影响应用…...

C-小H学生物
题意:一棵树节点编号为1具有n种不同物种的演化树上。物种i将遗传信息向下传递到物种j会产生dij的遍历。dij是一个长为l的01串。变异程度duv为u到v简单路径上的所有编译信息的异或和。基因多样性定义为 分析:计算Di的遗传信息,用dfs将遗传信息…...

什么是软件设计模式, 它们⽤于解决什么问题, 它们为什么有效
什么是设计模式 软件设计模式是指在软件设计过程中,经过验证的、可复⽤的、对特定 场景下常⻅问题的解决⽅案的⼀种描述或模板。这些模式并不是具体的 代码,⽽是⽤于指导如何组织代码、类和对象,以便更好地解决问题和 满⾜需求。 ⽤于解决的…...
)
LeetCode 3165.不包含相邻元素的子序列的最大和:单点修改的线段树(动态规划)
【LetMeFly】3165.不包含相邻元素的子序列的最大和:单点修改的线段树(动态规划) 力扣题目链接:https://leetcode.cn/problems/maximum-sum-of-subsequence-with-non-adjacent-elements/ 给你一个整数数组 nums 和一个二维数组 q…...

ios 快捷指令扩展(Intents Extension)简单使用 swift语言
本文介绍使用Xcode15 建立快捷指令的Extension,并描述如何修改快捷指令的IntentHandler,带参数跳转主应用;以及展示多个选项的快捷指令弹框(配置intentdefinition文件),点击选项带参数跳到主应用的方法 创建快捷指令 快捷指令是…...

虚拟化环境中的精简版 Android 操作系统 Microdroid
随着移动设备的普及和应用场景的多样化,安全性和隐私保护成为了移动操作系统的重要课题。Google推出的Microdroid,是一个专为虚拟化环境设计的精简版Android操作系统,旨在提供一个安全、隔离的执行环境。本文将详细介绍Microdroid的架构、功能…...

NFTScan Site:以蓝标认证与高级项目管理功能赋能 NFT 项目
自 NFTScan Site 上线以来,它迅速成为 NFT 市场中的一支重要力量,凭借对各类 NFT 集合、市场以及 NFTfi 项目的认证获得了广泛认可。这个平台帮助许多项目提升了曝光度和可见性,为它们在竞争激烈的 NFT 市场中创造了更大的成功机会。 在最新更…...

Vue:模板 MVVM
Vue:模板 & MVVM 模板插值语法指令语法 MVVMdefineProperty数据代理 模板 Vue实例绑定一个容器,想要向容器中填入动态的值,就需要使用模板语法。模板语法分为插值语法和指令语法。 插值语法 插值语法很简单,使用{{}}包含一…...
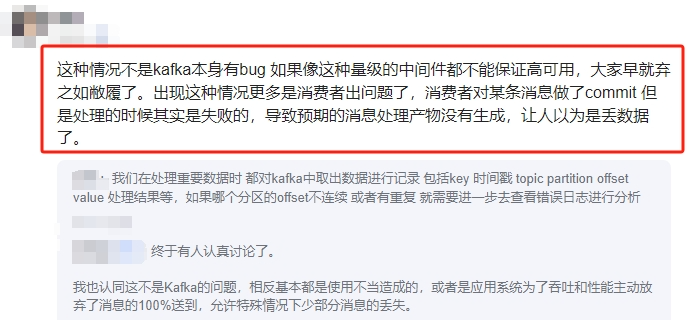
Kafka 消息丢失如何处理?
今天给大家分享一个在面试中经常遇到的问题:Kafka 消息丢失该如何处理? 这个问题啊,看似简单,其实里面藏着很多“套路”。 来,咱们先讲一个面试的“真实”案例。 面试官问:“Kafka 消息丢失如何处理&#x…...

Mysql报错注入之floor报错详解
updatexml extractvalue floor 是mysql的函数 groupbyrandfloorcount 一、简述 利用 select count(),(floor(rand(0)2))x from table group by x,导致数据库报错,通过 concat 函数,连接注入语句与 floor(rand(0)*2)函数,实现将…...
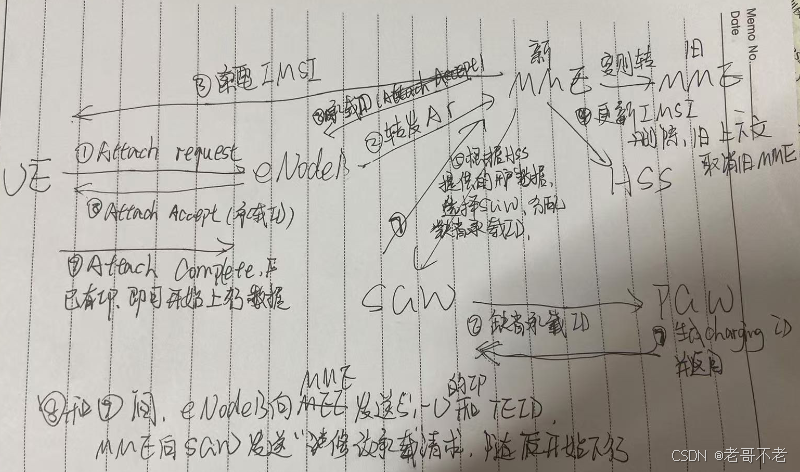
EPS原理笔记
EPS UE(user equipment),移动用户设备 LTE(Long Term Evolution),无线接入网部分,E-UTRAN EPC(system Architecture Evolution、Evoloed Packet Core),核心网部分,主要包括MME、S-GW、P-GW、HSS,连接Intern…...

LeetCode 876. 链表的中间结点
题目描述: 给你单链表的头结点 head ,请你找出并返回链表的中间结点。 如果有两个中间结点,则返回第二个中间结点。 示例 1: 输入:head [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点࿰…...

划界与分类的艺术:支持向量机(SVM)的深度解析
划界与分类的艺术:支持向量机(SVM)的深度解析 1. 引言 支持向量机(Support Vector Machine, SVM)是机器学习中的经典算法,以其强大的分类和回归能力在众多领域得到了广泛应用。SVM通过找到最优超平面来分…...
)
题目:100条经典C语言笔试题目(1-5)
题目: 1、请填写 bool , float, 指针变量 与“零值”比较的if 语句。 提示:这里“零值”可以是 0, 0.0 , FALSE 或者“空指针” 。例如 int 变量 n 与“零值”比较的 if 语句为: (1)请写出bool flag 与“零值”比较…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...
)
从数据到模型:手把手教你预处理MPIIFaceGaze和EyeDiap数据集(Python实战)
从数据到模型:手把手教你预处理MPIIFaceGaze和EyeDiap数据集(Python实战)当你第一次打开MPIIFaceGaze或EyeDiap数据集的压缩包时,那种面对杂乱文件夹和神秘.mat文件的迷茫感,我太熟悉了。作为计算机视觉工程师…...