机器学习在时间序列预测中的应用与实现——以电力负荷预测为例(附代码)
📝个人主页🌹:一ge科研小菜鸡-CSDN博客
🌹🌹期待您的关注 🌹🌹

1. 引言
随着数据采集技术的发展,时间序列数据在各个领域中的应用越来越广泛。时间序列预测旨在基于过去的时间数据来预测未来的值。典型的应用包括股票市场预测、天气预报、流量预测以及电力负荷预测。在电力行业,准确的负荷预测可以帮助优化电力供应、提高能源利用效率、减少运营成本。
机器学习在时间序列预测中的应用逐渐超越传统的统计方法,例如ARIMA和指数平滑等。特别是近年来,基于深度学习的模型(如LSTM、GRU和Transformer)在复杂时间序列预测中表现出显著的优越性。本文将以电力负荷预测为例,探讨时间序列预测的基本步骤、常用模型及实际实现。
2. 时间序列数据特征分析
电力负荷数据通常包含以下特征:
- 趋势:即数据随时间的上升或下降趋势,例如电力负荷随着城市的发展可能逐年增加。
- 季节性:电力负荷通常表现出明显的周期性。例如,冬季和夏季的电力负荷会高于春秋季。
- 周期性:每日、每周、甚至每月的周期性,例如每天的用电高峰时段。
这些特征是电力负荷预测的基础,且决定了所需模型的复杂程度。
3. 数据预处理
在进行时间序列预测之前,数据预处理至关重要,具体包括以下步骤:
- 缺失值处理:时间序列数据中的缺失值可能会导致模型不稳定,需要合理填补。
- 异常值检测:电力负荷数据中可能存在异常峰值,这些峰值可能由人为原因或数据采集问题造成。
- 特征工程:生成可能的相关特征,例如“小时”、“星期几”、“假期”等,可能有助于提升预测精度。
4. 模型选择
在本案例中,我们将使用以下三种机器学习模型来对电力负荷进行预测:
- 线性回归模型:简单且易于解释,适合具有线性趋势的时间序列。
- 随机森林模型:一种集成学习方法,适合处理非线性特征,能够挖掘时间序列中的复杂关系。
- LSTM模型:长短期记忆网络(LSTM)适合处理序列性较强的数据,尤其在长时间序列预测中具有优越性。
5. 实际案例操作代码
5.1 数据加载和预处理
以下代码加载并预处理电力负荷数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 加载数据
data = pd.read_csv("electricity_load.csv", parse_dates=["date"], index_col="date")# 查看数据
print(data.head())# 缺失值填补
data.fillna(method="ffill", inplace=True)# 提取时间特征
data["hour"] = data.index.hour
data["day_of_week"] = data.index.dayofweek
data["month"] = data.index.month
5.2 特征工程
在这里,我们可以通过周期性特征生成更加丰富的数据特征。
data["hour_sin"] = np.sin(2 * np.pi * data["hour"] / 24)
data["hour_cos"] = np.cos(2 * np.pi * data["hour"] / 24)
data["day_of_week_sin"] = np.sin(2 * np.pi * data["day_of_week"] / 7)
data["day_of_week_cos"] = np.cos(2 * np.pi * data["day_of_week"] / 7)
5.3 数据分割和归一化
我们将数据划分为训练集和测试集,并对特征进行标准化。
# 数据分割
train_data, test_data = train_test_split(data, test_size=0.2, shuffle=False)# 特征和目标
X_train = train_data.drop("load", axis=1)
y_train = train_data["load"]
X_test = test_data.drop("load", axis=1)
y_test = test_data["load"]# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
5.4 线性回归模型
首先使用线性回归模型进行预测。
from sklearn.linear_model import LinearRegression# 定义模型
lr_model = LinearRegression()# 训练模型
lr_model.fit(X_train, y_train)# 预测
y_pred_lr = lr_model.predict(X_test)# 评估
from sklearn.metrics import mean_squared_error
print("Linear Regression MSE:", mean_squared_error(y_test, y_pred_lr))
5.5 随机森林模型
接下来使用随机森林模型来进一步捕捉数据中的非线性关系。
from sklearn.ensemble import RandomForestRegressor# 定义模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)# 训练模型
rf_model.fit(X_train, y_train)# 预测
y_pred_rf = rf_model.predict(X_test)# 评估
print("Random Forest MSE:", mean_squared_error(y_test, y_pred_rf))
5.6 LSTM模型
由于LSTM模型对长时间序列数据具有较好的记忆能力,因此我们采用LSTM来进行预测。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset# 将数据转换为张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32)# 构建数据集和数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):h_0 = torch.zeros(1, x.size(0), hidden_size).to(device)c_0 = torch.zeros(1, x.size(0), hidden_size).to(device)out, _ = self.lstm(x, (h_0, c_0))out = self.fc(out[:, -1, :])return out# 模型参数
input_size = X_train.shape[1]
hidden_size = 64
num_layers = 1
output_size = 1# 初始化模型
lstm_model = LSTMModel(input_size, hidden_size, num_layers, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.001)# 训练模型
num_epochs = 20
for epoch in range(num_epochs):for X_batch, y_batch in train_loader:outputs = lstm_model(X_batch)loss = criterion(outputs, y_batch.view(-1, 1))optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 预测
y_pred_lstm = lstm_model(X_test_tensor).detach().numpy()
print("LSTM MSE:", mean_squared_error(y_test, y_pred_lstm))
6. 模型评估与对比
在完成线性回归、随机森林和LSTM模型的训练与预测后,我们使用均方误差(Mean Squared Error,MSE)作为主要评估指标,对各模型在测试集上的表现进行分析和对比。每种模型在不同类型的时间序列数据上具有不同的优势和劣势,因此合理的模型选择和调优对于提升预测效果至关重要。
6.1 线性回归模型的评估
线性回归模型简单且易于解释,其性能在拥有稳定线性趋势的数据中往往较为优异。通过测试集上的MSE得分可以看出,线性回归在捕捉基础的电力负荷趋势上表现较好。然而,线性回归模型在应对电力负荷数据的复杂周期性和非线性变化时有一定局限。这种模型容易受到极端值影响,且难以灵活适应负荷数据中的非线性波动。因此,线性回归更适合作为基线模型,对整体数据趋势进行初步的预测和估计。
6.2 随机森林模型的评估
随机森林是一种基于决策树的集成学习算法,能够在处理数据中的非线性关系方面表现出色。在电力负荷预测中,随机森林通过其多层的树结构对不同特征组合进行学习,从而更好地捕捉电力负荷数据中的复杂周期性和非线性变化。相较于线性回归模型,随机森林在测试集上的MSE通常更低,说明它在该数据集上的拟合能力较强。然而,随机森林模型的计算复杂度较高,且对长时间序列的全局趋势并不敏感。因此,虽然它可以有效识别较短周期内的负荷波动,但在面临较长时间跨度的趋势变化时,效果可能不如一些深度学习模型。
6.3 LSTM模型的评估
长短期记忆网络(LSTM)是一种专为时间序列和序列数据设计的递归神经网络(RNN),擅长处理长时间依赖的特征。LSTM在电力负荷预测中的表现尤为出色,因为它通过“记忆门”机制可以保存和利用长时间的负荷信息,从而更好地捕捉数据中的长期趋势和季节性周期。LSTM在测试集上往往能够获得最低的MSE,这表明它在这类数据上的表现优越。然而,LSTM的训练过程较为耗时,且对于超参数的选择和调优要求较高。在实际应用中,LSTM的预测效果也会受到输入序列长度和模型复杂度的影响。因此,在电力负荷预测中,LSTM适合作为长时间跨度的主要预测模型。
6.4 模型对比
通过对比线性回归、随机森林和LSTM模型在电力负荷预测上的表现,可以得出以下结论:
- 线性回归适合基础的趋势预测,适合作为初步的基线模型,易于实现且对模型解释性要求高。
- 随机森林在捕捉复杂的短周期非线性波动方面表现较佳,但在长时间跨度上的表现略显不足。
- LSTM在应对长时间序列依赖和复杂周期性变化时表现优越,能够更准确地预测未来负荷数据。
综合来看,选择合适的模型需要考虑数据特征和预测任务的时间跨度。如果以短期预测为主,可以选用随机森林,若需要长期趋势预测,LSTM则是更为合适的选择。多模型集成在实际应用中也逐渐被采用,将多个模型的预测结果加权平均往往可以提升总体精度。
7. 总结与未来展望
7.1 总结
本项目通过电力负荷预测的实际案例,系统地展示了机器学习在时间序列预测中的应用。我们从数据预处理、特征工程到模型训练与评估,介绍了从传统线性回归、集成方法(随机森林)到深度学习(LSTM)等多种预测方法的实现和对比。各模型在电力负荷数据上的表现证明了其在特定任务中的适用性,同时也揭示了它们的局限性。
在实际应用中,电力负荷预测是一个复杂的任务,不仅需要捕捉基础的时间趋势,还需要识别数据中的季节性和周期性波动。本文中提到的线性回归、随机森林和LSTM模型均在各自的优势领域展现了较强的性能,但同时也指出了它们在应对长时间依赖和非线性特征方面的差异。特别是LSTM网络,在长时间依赖和复杂非线性关系的预测中展现了显著的优越性,这为电力负荷预测提供了强有力的支持。
7.2 未来展望
在未来,随着电力负荷数据的多维度和复杂性增加,如何构建更加鲁棒的预测模型是一个重要研究方向。以下是几个未来可行的方向:
-
多模型集成:结合不同模型的优势,通过集成学习的方法对电力负荷进行预测,可能进一步提高模型的精度和稳定性。例如,将线性回归作为基线模型,随机森林用于非线性调整,LSTM用于长时间序列的依赖预测。
-
深度学习中的Transformer模型:近年来,Transformer模型在自然语言处理和计算机视觉中的表现引人注目。由于其优异的并行计算能力和处理长距离依赖关系的能力,将Transformer应用于时间序列预测可能会带来新的突破。
-
自适应特征选择:通过自动化特征选择或特征生成来优化模型输入特征,可能在数据量不断增大的情况下保持高效的计算性能。例如,使用自动特征工程工具或生成对电力负荷高度相关的时间周期特征,可以进一步提高模型的精确性。
-
外部因素引入:电力负荷预测不仅受历史负荷数据影响,还受到天气、经济活动等外部因素的影响。未来可以通过整合天气预报数据、社会经济因素等外部数据,以提高负荷预测的准确度。
-
迁移学习:在不同地区或不同季节的电力负荷数据上训练的模型可能具备某些共性。通过迁移学习,将在某一地区训练的负荷预测模型迁移到另一地区,可能减少在新地区上训练的时间和数据需求。
综上所述,机器学习在时间序列预测中的应用潜力巨大。结合实际的业务需求和数据特征,合理地选择和改进预测模型将大幅提升预测精度,为电力、金融等领域的决策提供强有力的支持。随着数据获取能力的提升和模型算法的进步,机器学习必将在时间序列预测领域产生更广泛的应用和影响。
相关文章:
机器学习在时间序列预测中的应用与实现——以电力负荷预测为例(附代码)
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 随着数据采集技术的发展,时间序列数据在各个领域中的应用越来越广泛。时间序列预测旨在基于过去的时间数据来…...

白杨SEO:百度在降低个人备案类网站搜索关键词排名和流量?怎样应对?【参考】
很久没有写百度或者网站这块内容了,一是因为做百度网站朋友越来越少,不管是个人还是企业;二是百度上用户搜索与百度给到网站的流量都越来越少。 为什么想到今天又来写这个呢?因为上个月有个朋友来咨询我说网站百度排名全没了&…...

前端实现json动画(附带示例)
前端实现json动画(附带示例) 使用lottie制作动画。1.json动画2.实现效果3.git仓库4.运行5.json动画天堂6.代码7. 经常使用的方法 使用lottie制作动画。 1.json动画 废话不多说,直接看效果图2.实现效果 3.git仓库 https://gitee.com/chaiach…...

AI 写作(一):开启创作新纪元(1/10)
一、AI 写作:重塑创作格局 在当今数字化高速发展的时代,AI 写作正以惊人的速度重塑着创作格局。AI 写作在现代社会中占据着举足轻重的地位,发挥着不可替代的作用。 随着信息的爆炸式增长,人们对于内容的需求日益旺盛。AI 写作能够…...

C#-类:索引器
索引器作用:可以让我们以中括号的形式访问自定义类中的元素。 规则自己定,访问时和数组一样 适用于,在类中有数组变量时使用,可以方便的访问、进行逻辑处理 可以重载,结构体也支持索引器 一:索引器的语法…...

Neo4j Cypher WHERE子句详解 - 初学者指南
Neo4j Cypher WHERE子句详解 - 初学者指南 前言1. WHERE子句基础1.1 WHERE子句的本质1.2 示例数据 2. 基本用法2.1 节点属性过滤2.2 关系属性过滤 3. 高级过滤技巧3.1 字符串匹配3.2 正则表达式3.3 属性存在性检查 4. 列表和范围操作4.1 IN操作符4.2 范围查询 5. 空值处理5.1 默…...

【CSS】标准怪异盒模型
概念 CSS 盒模型本质上是一个盒子,盒子包裹着HTML 元素,盒子由四个属性组成,从内到外分别是:content 内容、padding 内填充、border 边框、外边距 margin 盒模型的分类 W3C 盒子模型(标准盒模型) IE 盒子模型(怪异盒模型) 两种…...

栈详解
目录 栈栈的概念及结构栈的实现数组栈的实现数组栈功能的实现栈的初始化void STInit(ST* pst)初始化情况一初始化情况二 代码栈的插入void STPush(ST* pst, STDataType x)代码 栈的删除void STPop(ST* pst)代码 栈获取数据STDataType STTop(ST* pst)代码 判断栈是否为空bool ST…...

硬盘 <-> CPU, CPU <-> GPU 数据传输速度
1. 硬盘 <-> CPU 数据传输速度 import time import os# 定义文件大小和测试文件路径 file_size 1 * 1024 * 1024 * 100 # 100 MB 的文件大小 file_path "test_file.bin"# 创建一个测试文件并测量写入速度 def test_write_speed():data os.urandom(file_si…...

数据编排与ETL有什么关系?
数据编排作为近期比较有热度的一个话题,讨论度比较高,同时数据编排的出现也暗示着数字化进程的自动化发展。在谈及数据编排时,通常也会谈到ETL,这两个东西有相似点也有不同点。 数据编排和ETL(提取、转换、加载&#x…...

来了解一下!!!——React
React 是一个用于构建用户界面的 JavaScript 库,特别适合用于创建单页面应用程序(SPA)。它由 Facebook 维护,并且拥有一个活跃的社区,这使得 React 成为了目前最流行的前端框架之一。以下是关于 React 的一些重要信息和…...

用vite创建项目
一. vite vue2 1. 全局安装 create-vite npm install -g create-vite 2. 创建项目 进入你想要创建项目的文件夹下 打开 CMD 用 JavaScript create-vite my-vue2-project --template vue 若用 TypeScript 则 create-vite my-vue2-project --template vue-ts 这里的 …...

json-server的使用(根据json数据一键生成接口)
一.使用目的 在前端开发初期,后端 API 可能还未完成,json-server 可以快速创建模拟的 RESTful API,帮助前端开发者进行开发和测试。 二.安装 npm install json-server //局部安装npm i json-server -g //全局安装 三.使用教程 1.准备一…...

半波正弦信号的FFT变换
目录 Hello, 大家好,这一期我们谈谈半波正弦信号的FFT变化长什么样子。本文硬件使用GFARM02硬件模块[1],文章最后有其淘宝链接。核心器件为STM32F103RCT6,为Cortex-M3核,采用的CMSIS版本为CMSIS_5-5.6.0。 如图1所示&…...
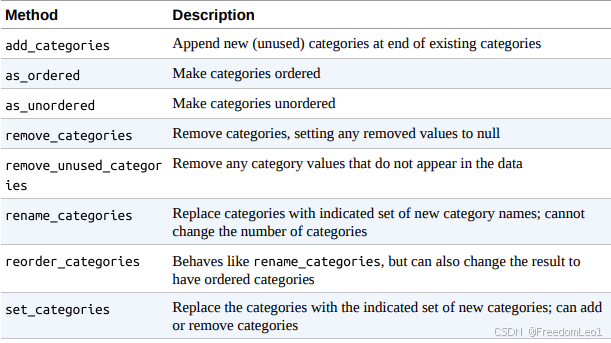
Python数据分析NumPy和pandas(二十三、数据清洗与预处理之五:pandas的分类类型数据)
pandas的分类类型数据(Categorical Data) 这次学习使用Categorical Data,在某些 pandas 操作中使用分类类型能实现更好的性能和减少内存使用。另外还学习一些工具,这些工具有助于在统计和机器学习应用程序中使用分类数据。 一.背…...
--multi/exec/eval命令执行流程)
redis源码系列--(二)--multi/exec/eval命令执行流程
本文主要记录multi/exec、eval、redis执行lua脚本的源码流程 redis在exec之前,所有queued的命令是没有执行的,!!!在执行时会通过检测client是否被打上CLIENT_DIRTY_CAS标记来判断[watch后,exec时]时间段内是否有key被…...

【力扣打卡系列】移动零(双指针)
坚持按题型打卡&刷&梳理力扣算法题系列,语言为go,Day19 移动零(双指针) 题目描述 解题思路 p和q同时从起点移动,p每次都,q仅在交换时,p遇到非零数时与p值交换!!…...

无源元器件-电容选型参数总结
🏡《总目录》 目录 1,概述2,电容选型参数2.1,电容值(Capacitance)2.2,额定电压(Rated Voltage )2.3,外观(Appearance)2.4,尺寸(Dimension)2.5,耐压(Voltage Proof)2.6,绝缘电阻(Insulation Resistance)2.7,耗散因子或耗散系数(IQ or Dissipation Facto…...

Linux下的socket编程
概述 下面是一个通用的server端程序源码,用于实现两个client之间的通信。 功能 1、接收user的命令cmd消息,并将cmd消息发送到dev; 2、接收dev的应答ack消息,并将ack消息发送到user; 架构实现 通过6个线程实现。 …...

【算法】Floyd多源最短路径算法
目录 一、概念 二、思路 三、代码 一、概念 在前面的学习中,我们已经接触了Dijkstra、Bellman-Ford等单源最短路径算法。但首先我们要知道何为单源最短路径,何为多源最短路径 单源最短路径:从图中选取一点,求这个点到图中其他…...

C++中多才多艺的 const
1. 定义一个常全局变量1const int global 100; // 初始化之后不可再赋值这样的global实际上是一个常量,这是C用来取代宏定义的其中一种措施,const常量有类型检测,提高编译器的效率。2. 定义常指针这有两个版本,分别是:…...

Microsoft Defender双零日在野利用全解析:从BlueHammer到RedSun的终端沦陷之路
前言 2026年5月20日,微软安全响应中心(MSRC)发布紧急安全公告,承认旗下Microsoft Defender存在两个已被野外利用超过一个月的零日漏洞——CVE-2026-41091与CVE-2026-45498。同日,美国国土安全部下属的网络安全与基础设施安全局(CISA)将这两个…...
)
从‘相框’与‘相片’说起:彻底搞懂MFC文档/视图架构与消息路由(含实战避坑)
从相框到相片:深入解析MFC文档/视图架构的设计哲学与实战应用 在Windows桌面应用开发的历史长河中,MFC(Microsoft Foundation Classes)作为经典的C框架,其独特的文档/视图架构一直是开发者又爱又恨的设计。想象一下相框…...

如何免费获得你的AI桌面助手:UI-TARS桌面版完整使用指南
如何免费获得你的AI桌面助手:UI-TARS桌面版完整使用指南 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop …...

为开源Agent框架OpenClaw快速接入Taotoken的多模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源Agent框架OpenClaw快速接入Taotoken的多模型能力 应用场景类,针对使用OpenClaw等开源Agent框架的开发者…...

Hotkey Detective:3分钟找出Windows热键冲突的终极指南
Hotkey Detective:3分钟找出Windows热键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否遇…...

ESP-IDF+vscode开发ESP32第十三讲——NVS
目录 一、NVS梳理 1.1 分区 (Partition):NVS 的专属“仓库” 1.2 页面 (Page):仓库里的“货架” 1.3 条目 (Entry):货架上的“最小存储格” 1.4 键值对 (Key-Value Pair):实际存放的“货物” 1.5 命名空间 (Namespace)&…...

Wireshark深度解析TLS 1.3与HTTP/2隐性故障pcap样本
1. 这不是一份普通pcap,而是一份“网络故障诊断教科书级样本”你有没有遇到过这样的情况:客户发来一个几十MB的pcap文件,标题叫“系统登录超时”,你打开Wireshark,密密麻麻全是TCP重传、RST包、DNS超时,但翻…...

Unity 2D基础:2D相机Orthographic的参数调节
Unity 2D基础:2D相机Orthographic的参数调节📚 本章学习目标:深入理解2D相机Orthographic的参数调节的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2…...

Focus-DETR:基于前景特征选择的高效目标检测模型解析
1. 项目概述与核心痛点目标检测,这个计算机视觉领域的经典任务,如今正站在一个十字路口。一方面,以DETR(Detection Transformer)为代表的端到端检测范式,凭借其简洁优雅的架构和强大的性能,正迅…...