OPPO开源Diffusion多语言适配器—— MultilingualSD3-adapter 和 ChineseFLUX.1-adapter
MultilingualSD3-adapter 是为 SD3 量身定制的多语言适配器。 它源自 ECCV 2024 的一篇题为 PEA-Diffusion 的论文。ChineseFLUX.1-adapter是为Flux.1系列机型量身定制的多语言适配器,理论上继承了ByT5,可支持100多种语言,但在中文方面做了额外优化。 它源于一篇题为 PEA-Diffusion 的 ECCV 2024 论文。

PEA-Diffusion
作者首先提到了一种名为 “知识蒸馏”(Knowledge Distillation,KD)的方法。KD 是一个过程,在这个过程中,一个较小的机器学习模型(称为学生)会学习模仿一个较大、较复杂的模型(称为教师)。在这种情况下,目标是让学生模型尽可能接近教师的输出或预测。这被称为 “强制学生分布与教师分布相匹配”。
然而,作者还希望确保教师模型和学生模型不仅能产生相似的输出结果,而且能以相似的方式处理信息。这就是特征对齐的作用所在。他们希望教师模型和学生模型的中间计算或特征图也能相似。因此,他们引入了一种技术,在这些模型的中间层增强这种特征对齐。这样做的目的是减少所谓的分布偏移,使学生模型更像教师模型。
现在,当模型之间存在维度差异时,OPPOer/ChineseFLUX.1-adapter 就会发挥作用。在这种情况下,他们使用的是名为 CLIP(对比语言图像预训练)的模型,一个用于英语数据,一个用于非英语数据。适配器是添加到模型中的一个小型附加组件,用于对齐或转换特征(中间计算)以匹配维度。该适配器经过训练,可以学习特定语言的信息,而且设计高效,只有 600 万个参数。
因此,总的来说,OPPOer/ChineseFLUX.1-adapter 是一种用于调整不同模型(在本例中为英语和非英语 CLIP 模型)中特征维度的技术,以促进知识提炼并提高学生模型的性能。它是这个复杂系统中一个小而重要的组成部分!
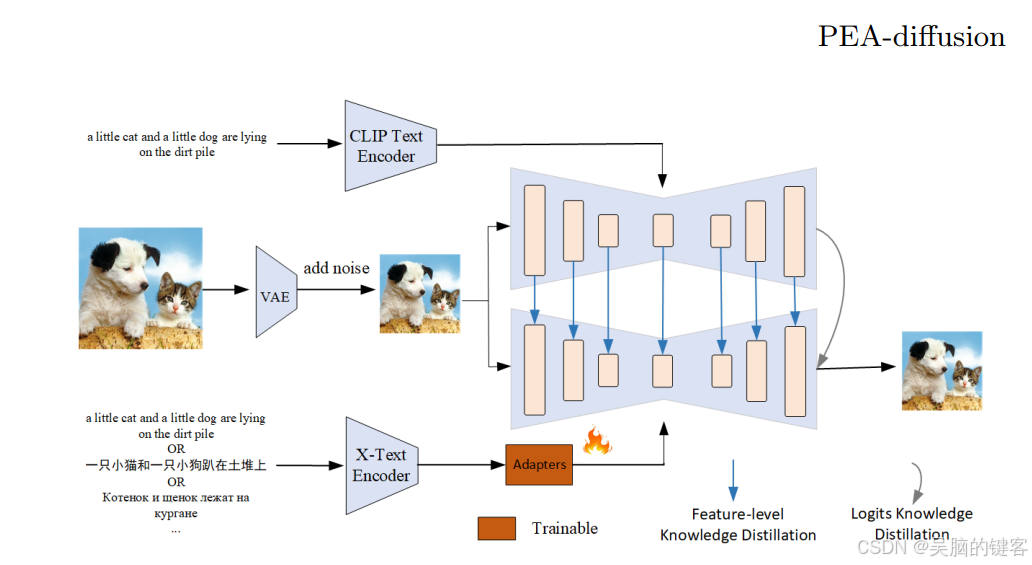
论文:PEA-Diffusion: Parameter-Efficient Adapter with Knowledge Distillation in non-English Text-to-Image Generation
Code: https://github.com/OPPO-Mente-Lab/PEA-Diffusion
MultilingualSD3-adapter
我们使用了多语言编码器 umt5-xxl、Mul-OpenCLIP 和 HunyuanDiT_CLIP。 我们在蒸馏训练中采用了反向去噪处理。
import os
import torch
import torch.nn as nnfrom typing import Any, Callable, Dict, List, Optional, Union
import inspect
from diffusers.models.transformers import SD3Transformer2DModel
from diffusers.image_processor import VaeImageProcessor
from diffusers.schedulers import FlowMatchEulerDiscreteScheduler
from diffusers import AutoencoderKL
from tqdm import tqdm
from PIL import Imagefrom transformers import T5Tokenizer,T5EncoderModel,BertModel, BertTokenizer
import open_clipclass MLP(nn.Module):def __init__(self, in_dim=1024, out_dim=2048, hidden_dim=2048, out_dim1=4096, use_residual=True):super().__init__()if use_residual:assert in_dim == out_dimself.layernorm = nn.LayerNorm(in_dim)self.projector = nn.Sequential(nn.Linear(in_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, out_dim, bias=False),)self.fc = nn.Linear(out_dim, out_dim1)self.use_residual = use_residualdef forward(self, x):residual = xx = self.layernorm(x)x = self.projector(x)x2 = nn.GELU()(x)x2 = self.fc(x2)return x2class Transformer(nn.Module):def __init__(self, d_model, n_heads, out_dim1, out_dim2,num_layers=1) -> None:super().__init__()self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=n_heads, dim_feedforward=2048, batch_first=True)self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)self.linear1 = nn.Linear(d_model, out_dim1)self.linear2 = nn.Linear(d_model, out_dim2)def forward(self, x):x = self.transformer_encoder(x)x1 = self.linear1(x)x1 = torch.mean(x1,1)x2 = self.linear2(x)return x1,x2def image_grid(imgs, rows, cols):assert len(imgs) == rows*colsw, h = imgs[0].sizegrid = Image.new('RGB', size=(cols*w, rows*h))grid_w, grid_h = grid.sizefor i, img in enumerate(imgs):grid.paste(img, box=(i%cols*w, i//cols*h))return grid
def retrieve_timesteps(scheduler,num_inference_steps: Optional[int] = None,device: Optional[Union[str, torch.device]] = None,timesteps: Optional[List[int]] = None,sigmas: Optional[List[float]] = None,**kwargs,
):if timesteps is not None and sigmas is not None:raise ValueError("Only one of `timesteps` or `sigmas` can be passed. Please choose one to set custom values")if timesteps is not None:accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())if not accepts_timesteps:raise ValueError(f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"f" timestep schedules. Please check whether you are using the correct scheduler.")scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)timesteps = scheduler.timestepsnum_inference_steps = len(timesteps)elif sigmas is not None:accept_sigmas = "sigmas" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())if not accept_sigmas:raise ValueError(f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"f" sigmas schedules. Please check whether you are using the correct scheduler.")scheduler.set_timesteps(sigmas=sigmas, device=device, **kwargs)timesteps = scheduler.timestepsnum_inference_steps = len(timesteps)else:scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)timesteps = scheduler.timestepsreturn timesteps, num_inference_stepsclass StableDiffusionTest():def __init__(self,model_path,text_encoder_path,text_encoder_path1,text_encoder_path2,proj_path,proj_t5_path):super().__init__()self.transformer = SD3Transformer2DModel.from_pretrained(model_path, subfolder="transformer",torch_dtype=dtype).to(device)self.vae = AutoencoderKL.from_pretrained(model_path, subfolder="vae").to(device,dtype=dtype)self.scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(model_path, subfolder="scheduler")self.vae_scale_factor = (2 ** (len(self.vae.config.block_out_channels) - 1) if hasattr(self, "vae") and self.vae is not None else 8)self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)self.default_sample_size = (self.transformer.config.sample_sizeif hasattr(self, "transformer") and self.transformer is not Noneelse 128)self.text_encoder_t5 = T5EncoderModel.from_pretrained(text_encoder_path).to(device,dtype=dtype)self.tokenizer_t5 = T5Tokenizer.from_pretrained(text_encoder_path)self.text_encoder = BertModel.from_pretrained(f"{text_encoder_path1}/clip_text_encoder", False, revision=None).to(device,dtype=dtype)self.tokenizer = BertTokenizer.from_pretrained(f"{text_encoder_path1}/tokenizer")self.text_encoder2, _, _ = open_clip.create_model_and_transforms('xlm-roberta-large-ViT-H-14', pretrained=text_encoder_path2)self.tokenizer2 = open_clip.get_tokenizer('xlm-roberta-large-ViT-H-14')self.text_encoder2.text.output_tokens = Trueself.text_encoder2 = self.text_encoder2.to(device,dtype=dtype)self.proj = MLP(2048, 2048, 2048, 4096, use_residual=False).to(device,dtype=dtype)self.proj.load_state_dict(torch.load(proj_path, map_location="cpu"))self.proj_t5 = Transformer(d_model=4096, n_heads=8, out_dim1=2048, out_dim2=4096).to(device,dtype=dtype)self.proj_t5.load_state_dict(torch.load(proj_t5_path, map_location="cpu"))def encode_prompt(self, prompt, device, do_classifier_free_guidance=True, negative_prompt=None):batch_size = len(prompt) if isinstance(prompt, list) else 1text_input_ids_t5 = self.tokenizer_t5(prompt,padding="max_length",max_length=77,truncation=True,add_special_tokens=False,return_tensors="pt",).input_ids.to(device)text_embeddings = self.text_encoder_t5(text_input_ids_t5)text_inputs = self.tokenizer(prompt,padding="max_length",max_length=77,truncation=True,return_tensors="pt",)input_ids = text_inputs.input_ids.to(device)attention_mask = text_inputs.attention_mask.to(device)encoder_hidden_states = self.text_encoder(input_ids,attention_mask=attention_mask)[0]text_input_ids = self.tokenizer2(prompt).to(device)_,encoder_hidden_states2 = self.text_encoder2.encode_text(text_input_ids)encoder_hidden_states = torch.cat([encoder_hidden_states, encoder_hidden_states2], dim=-1)encoder_hidden_states_t5 = text_embeddings[0]encoder_hidden_states = self.proj(encoder_hidden_states)add_text_embeds,encoder_hidden_states_t5 = self.proj_t5(encoder_hidden_states_t5.half())prompt_embeds = torch.cat([encoder_hidden_states, encoder_hidden_states_t5], dim=-2) # get unconditional embeddings for classifier free guidanceif do_classifier_free_guidance:if negative_prompt is None:uncond_tokens = [""] * batch_sizeelse:uncond_tokens = negative_prompttext_input_ids_t5 = self.tokenizer_t5(uncond_tokens,padding="max_length",max_length=77,truncation=True,add_special_tokens=False,return_tensors="pt",).input_ids.to(device)text_embeddings = self.text_encoder_t5(text_input_ids_t5)text_inputs = self.tokenizer(uncond_tokens,padding="max_length",max_length=77,truncation=True,return_tensors="pt",)input_ids = text_inputs.input_ids.to(device)attention_mask = text_inputs.attention_mask.to(device)encoder_hidden_states = self.text_encoder(input_ids,attention_mask=attention_mask)[0]text_input_ids = self.tokenizer2(uncond_tokens).to(device)_,encoder_hidden_states2 = self.text_encoder2.encode_text(text_input_ids)encoder_hidden_states = torch.cat([encoder_hidden_states, encoder_hidden_states2], dim=-1)encoder_hidden_states_t5 = text_embeddings[0]encoder_hidden_states_uncond = self.proj(encoder_hidden_states)add_text_embeds_uncond,encoder_hidden_states_t5_uncond = self.proj_t5(encoder_hidden_states_t5.half())prompt_embeds_uncond = torch.cat([encoder_hidden_states_uncond, encoder_hidden_states_t5_uncond], dim=-2)prompt_embeds = torch.cat([prompt_embeds_uncond, prompt_embeds], dim=0)pooled_prompt_embeds = torch.cat([add_text_embeds_uncond, add_text_embeds], dim=0)return prompt_embeds,pooled_prompt_embedsdef prepare_latents(self,batch_size,num_channels_latents,height,width,dtype,device,generator,latents=None,):if latents is not None:return latents.to(device=device, dtype=dtype)shape = (batch_size,num_channels_latents,int(height) // self.vae_scale_factor,int(width) // self.vae_scale_factor,)if isinstance(generator, list) and len(generator) != batch_size:raise ValueError(f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"f" size of {batch_size}. Make sure the batch size matches the length of the generators.")latents = torch.randn(shape, generator=generator, dtype=dtype).to(device)return latents@propertydef guidance_scale(self):return self._guidance_scale@propertydef clip_skip(self):return self._clip_skip# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`# corresponds to doing no classifier free guidance.@propertydef do_classifier_free_guidance(self):return self._guidance_scale > 1@propertydef joint_attention_kwargs(self):return self._joint_attention_kwargs@propertydef num_timesteps(self):return self._num_timesteps@propertydef interrupt(self):return self._interrupt@torch.no_grad()def __call__(self,prompt: Union[str, List[str]] = None,prompt_2: Optional[Union[str, List[str]]] = None,prompt_3: Optional[Union[str, List[str]]] = None,height: Optional[int] = None,width: Optional[int] = None,num_inference_steps: int = 28,timesteps: List[int] = None,guidance_scale: float = 7.0,negative_prompt: Optional[Union[str, List[str]]] = None,negative_prompt_2: Optional[Union[str, List[str]]] = None,negative_prompt_3: Optional[Union[str, List[str]]] = None,num_images_per_prompt: Optional[int] = 1,generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,latents: Optional[torch.FloatTensor] = None,prompt_embeds: Optional[torch.FloatTensor] = None,negative_prompt_embeds: Optional[torch.FloatTensor] = None,pooled_prompt_embeds: Optional[torch.FloatTensor] = None,negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,output_type: Optional[str] = "pil",return_dict: bool = True,joint_attention_kwargs: Optional[Dict[str, Any]] = None,clip_skip: Optional[int] = None,callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,callback_on_step_end_tensor_inputs: List[str] = ["latents"],):height = height or self.default_sample_size * self.vae_scale_factorwidth = width or self.default_sample_size * self.vae_scale_factorself._guidance_scale = guidance_scaleself._clip_skip = clip_skipself._joint_attention_kwargs = joint_attention_kwargsself._interrupt = Falseif prompt is not None and isinstance(prompt, str):batch_size = 1elif prompt is not None and isinstance(prompt, list):batch_size = len(prompt)else:batch_size = prompt_embeds.shape[0]prompt_embeds,pooled_prompt_embeds = self.encode_prompt(prompt, device)timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)self._num_timesteps = len(timesteps)num_channels_latents = self.transformer.config.in_channelslatents = self.prepare_latents(batch_size * num_images_per_prompt,num_channels_latents,height,width,prompt_embeds.dtype,device,generator,latents,)for i, t in tqdm(enumerate(timesteps)):if self.interrupt:continuelatent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latentstimestep = t.expand(latent_model_input.shape[0]).to(dtype=dtype)noise_pred = self.transformer(hidden_states=latent_model_input,timestep=timestep,encoder_hidden_states=prompt_embeds.to(dtype=self.transformer.dtype),pooled_projections=pooled_prompt_embeds.to(dtype=self.transformer.dtype),joint_attention_kwargs=self.joint_attention_kwargs,return_dict=False,)[0]if self.do_classifier_free_guidance:noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)latents_dtype = latents.dtypelatents = self.scheduler.step(noise_pred, t, latents, return_dict=False)[0]if latents.dtype != latents_dtype:if torch.backends.mps.is_available():latents = latents.to(latents_dtype)if callback_on_step_end is not None:callback_kwargs = {}for k in callback_on_step_end_tensor_inputs:callback_kwargs[k] = locals()[k]callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)latents = callback_outputs.pop("latents", latents)prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)negative_pooled_prompt_embeds = callback_outputs.pop("negative_pooled_prompt_embeds", negative_pooled_prompt_embeds)if output_type == "latent":image = latentselse:latents = (latents / self.vae.config.scaling_factor) + self.vae.config.shift_factorimage = self.vae.decode(latents, return_dict=False)[0]image = self.image_processor.postprocess(image, output_type=output_type)return imageif __name__ == '__main__':device = "cuda" dtype = torch.float16text_encoder_path = 'google/umt5-xxl'text_encoder_path1 = "Tencent-Hunyuan/HunyuanDiT/t2i"text_encoder_path2 = 'laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k/open_clip_pytorch_model.bin'model_path = "stabilityai/stable-diffusion-3-medium-diffusers"proj_path = "OPPOer/MultilingualSD3-adapter/pytorch_model.bin"proj_t5_path = "OPPOer/MultilingualSD3-adapter/pytorch_model_t5.bin"sdt = StableDiffusionTest(model_path,text_encoder_path,text_encoder_path1,text_encoder_path2,proj_path,proj_t5_path)batch=2height = 1024width = 1024 while True:raw_text = input("\nPlease Input Query (stop to exit) >>> ")if not raw_text:print('Query should not be empty!')continueif raw_text == "stop":breakimages = sdt([raw_text]*batch,height=height,width=width)grid = image_grid(images, rows=1, cols=batch)grid.save("MultilingualSD3.png")ChineseFLUX.1-adapter
使用了多语言编码器 byt5-xxl,在适应过程中使用的教师模型是 FLUX.1-schnell。 我们采用了反向去噪过程进行蒸馏训练。 理论上,该适配器可应用于任何 FLUX.1 系列模型。 我们在此提供以下应用示例。
from diffusers import FluxPipeline, AutoencoderKL
from diffusers.image_processor import VaeImageProcessor
from transformers import T5ForConditionalGeneration,AutoTokenizer
import torch
import torch.nn as nnclass MLP(nn.Module):def __init__(self, in_dim=4096, out_dim=4096, hidden_dim=4096, out_dim1=768, use_residual=True):super().__init__()self.layernorm = nn.LayerNorm(in_dim)self.projector = nn.Sequential(nn.Linear(in_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, out_dim, bias=False),)self.fc = nn.Linear(out_dim, out_dim1)def forward(self, x):x = self.layernorm(x)x = self.projector(x)x2 = nn.GELU()(x)x1 = self.fc(x2)x1 = torch.mean(x1,1)return x1,x2dtype = torch.bfloat16
device = "cuda"
ckpt_id = "black-forest-labs/FLUX.1-schnell"
text_encoder_ckpt_id = 'google/byt5-xxl'
proj_t5 = MLP(in_dim=4672, out_dim=4096, hidden_dim=4096, out_dim1=768).to(device=device,dtype=dtype)
text_encoder_t5 = T5ForConditionalGeneration.from_pretrained(text_encoder_ckpt_id).get_encoder().to(device=device,dtype=dtype)
tokenizer_t5 = AutoTokenizer.from_pretrained(text_encoder_ckpt_id)proj_t5_save_path = f"diffusion_pytorch_model.bin"
state_dict = torch.load(proj_t5_save_path, map_location="cpu")
state_dict_new = {}
for k,v in state_dict.items():k_new = k.replace("module.","")state_dict_new[k_new] = vproj_t5.load_state_dict(state_dict_new)pipeline = FluxPipeline.from_pretrained(ckpt_id, text_encoder=None, text_encoder_2=None,tokenizer=None, tokenizer_2=None, vae=None,torch_dtype=torch.bfloat16
).to(device)vae = AutoencoderKL.from_pretrained(ckpt_id, subfolder="vae",torch_dtype=torch.bfloat16
).to(device)
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)while True:raw_text = input("\nPlease Input Query (stop to exit) >>> ")if not raw_text:print('Query should not be empty!')continueif raw_text == "stop":breakwith torch.no_grad():text_inputs = tokenizer_t5(raw_text,padding="max_length",max_length=256,truncation=True,add_special_tokens=True,return_tensors="pt",).input_ids.to(device)text_embeddings = text_encoder_t5(text_inputs)[0]pooled_prompt_embeds,prompt_embeds = proj_t5(text_embeddings)height, width = 1024, 1024latents = pipeline(prompt_embeds=prompt_embeds, pooled_prompt_embeds=pooled_prompt_embeds,num_inference_steps=4, guidance_scale=0, height=height, width=width,output_type="latent",).imageslatents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)latents = (latents / vae.config.scaling_factor) + vae.config.shift_factorimage = vae.decode(latents, return_dict=False)[0]image = image_processor.postprocess(image, output_type="pil")image[0].save("ChineseFLUX.jpg")MultilingualOpenFLUX.1
OpenFLUX.1
是对 FLUX.1-schnell 模型的微调,已对其进行了蒸馏训练。 请务必更新以下代码中下载的 fast-lora.safetensors 的路径。
from diffusers import FluxPipeline, AutoencoderKL
from diffusers.image_processor import VaeImageProcessor
from transformers import T5ForConditionalGeneration,AutoTokenizer
import torch
import torch.nn as nnclass MLP(nn.Module):def __init__(self, in_dim=4096, out_dim=4096, hidden_dim=4096, out_dim1=768, use_residual=True):super().__init__()self.layernorm = nn.LayerNorm(in_dim)self.projector = nn.Sequential(nn.Linear(in_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, hidden_dim, bias=False),nn.GELU(),nn.Linear(hidden_dim, out_dim, bias=False),)self.fc = nn.Linear(out_dim, out_dim1)def forward(self, x):x = self.layernorm(x)x = self.projector(x)x2 = nn.GELU()(x)x1 = self.fc(x2)x1 = torch.mean(x1,1)return x1,x2dtype = torch.bfloat16
device = "cuda"
ckpt_id = "ostris/OpenFLUX.1"
text_encoder_ckpt_id = 'google/byt5-xxl'
proj_t5 = MLP(in_dim=4672, out_dim=4096, hidden_dim=4096, out_dim1=768).to(device=device,dtype=dtype)
text_encoder_t5 = T5ForConditionalGeneration.from_pretrained(text_encoder_ckpt_id).get_encoder().to(device=device,dtype=dtype)
tokenizer_t5 = AutoTokenizer.from_pretrained(text_encoder_ckpt_id)proj_t5_save_path = f"diffusion_pytorch_model.bin"
state_dict = torch.load(proj_t5_save_path, map_location="cpu")
state_dict_new = {}
for k,v in state_dict.items():k_new = k.replace("module.","")state_dict_new[k_new] = vproj_t5.load_state_dict(state_dict_new)pipeline = FluxPipeline.from_pretrained(ckpt_id, text_encoder=None, text_encoder_2=None,tokenizer=None, tokenizer_2=None, vae=None,torch_dtype=torch.bfloat16
).to(device)
pipeline.load_lora_weights("ostris/OpenFLUX.1/openflux1-v0.1.0-fast-lora.safetensors")vae = AutoencoderKL.from_pretrained(ckpt_id, subfolder="vae",torch_dtype=torch.bfloat16
).to(device)
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)while True:raw_text = input("\nPlease Input Query (stop to exit) >>> ")if not raw_text:print('Query should not be empty!')continueif raw_text == "stop":breakwith torch.no_grad():text_inputs = tokenizer_t5(raw_text,padding="max_length",max_length=256,truncation=True,add_special_tokens=True,return_tensors="pt",).input_ids.to(device)text_embeddings = text_encoder_t5(text_inputs)[0]pooled_prompt_embeds,prompt_embeds = proj_t5(text_embeddings)height, width = 1024, 1024latents = pipeline(prompt_embeds=prompt_embeds, pooled_prompt_embeds=pooled_prompt_embeds,num_inference_steps=4, guidance_scale=0, height=height, width=width,output_type="latent",).imageslatents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)latents = (latents / vae.config.scaling_factor) + vae.config.shift_factorimage = vae.decode(latents, return_dict=False)[0]image = image_processor.postprocess(image, output_type="pil")image[0].save("ChineseOpenFLUX.jpg")相关文章:
OPPO开源Diffusion多语言适配器—— MultilingualSD3-adapter 和 ChineseFLUX.1-adapter
MultilingualSD3-adapter 是为 SD3 量身定制的多语言适配器。 它源自 ECCV 2024 的一篇题为 PEA-Diffusion 的论文。ChineseFLUX.1-adapter是为Flux.1系列机型量身定制的多语言适配器,理论上继承了ByT5,可支持100多种语言,但在中文方面做了额…...

Spring 设计模式之责任链模式
Spring 设计模式之责任链模式 责任链模式用到的场景java举例 责任链模式 责任链模式(Chain of Responsibility)是一种行为设计模式,它允许你将请求沿着处理者链进行传递。 每个处理者可以对请求进行处理,也可以将请求传递给链中的…...

简单的 docker 部署ELK
简单的 docker 部署ELK 这是我的运维同事部署ELK的文档,我这里记录转载一下 服务规划 架构: Filebeat->kafka->logstash->ES kafka集群部署参照: kafka集群部署 部署服务程序路径/数据目录端口配置文件elasticsearch/data/elasticsearch9200/data/elas…...

四款主流的3D创作和游戏开发软件的核心特点和关系
四款主流的3D创作和游戏开发软件的核心特点和关系 3D建模软件: Blender: 开源免费,功能全面优点: 完全免费持续更新优化社区活跃,学习资源丰富功能全面(建模、动画、渲染等) 缺点: 学习曲线陡峭界面操作…...

聚划算!Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN五模型多变量回归预测
聚划算!Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN五模型多变量回归预测 目录 聚划算!Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN五模型多变量回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 聚划算!Tran…...

信息安全工程师(76)网络安全应急响应技术原理与应用
前言 网络安全应急响应(Network Security Incident Response)是针对潜在或已发生的网络安全事件而采取的网络安全措施,旨在降低网络安全事件所造成的损失并迅速恢复受影响的系统和服务。 一、网络安全应急响应概述 定义:网络安全应…...

使用 OpenCV 实现图像的透视变换
概述 在计算机视觉领域,经常需要对图像进行各种几何变换,如旋转、缩放和平移等。其中,透视变换(Perspective Transformation)是一种非常重要的变换方式,它能够模拟三维空间中的视角变化,例如从…...

openGauss数据库-头歌实验1-4 数据库及表的创建
一、创建数据库 (一)任务描述 本关任务:创建指定数据库。 (二)相关知识 数据库其实就是可以存放大量数据的仓库,学习数据库我们就从创建一个数据库开始吧。 为了完成本关任务,你需要掌握&a…...

吉利极氪汽车嵌入式面试题及参考答案
inline 的作用 inline 是 C++ 中的一个关键字。它主要用于函数,目的是建议编译器将函数体插入到调用该函数的地方,而不是像普通函数调用那样进行跳转。 从性能角度来看,当一个函数被标记为 inline 后,在编译阶段,编译器可能会将函数的代码直接复制到调用它的位置。这样做…...

pycharm中的服务是什么?
在PyCharm中,服务是指允许在PyCharm中运行的一种功能或插件。服务可以是内置的,也可以是通过插件安装的。 一些常见的PyCharm服务包括: 调试服务:PyCharm提供了全功能的调试工具,可以帮助开发人员通过设置断点、监视变…...

[Unity Demo]从零开始制作空洞骑士Hollow Knight第十七集:制作第二个BOSS燥郁的毛里克
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、制作游戏第二个BOSS燥郁的毛里克 1.导入素材和制作相关动画1.5处理玩家受到战吼相关行为逻辑处理2.制作相应的行为控制和生命系统管理3.制作战斗场景和战斗…...

深度解析阿里的Sentinel
1、前言 这是《Spring Cloud 进阶》专栏的第五篇文章,这篇文章介绍一下阿里开源的流量防卫兵Sentinel,一款非常优秀的开源项目,经过近10年的双十一的考验,非常成熟的一款产品。 文章目录如下: 2、什么是sentinel&…...

Linux系统-日志轮询(logrotate)
作者介绍:简历上没有一个精通的运维工程师。希望大家多多关注作者,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。 这是Linux进阶部分的最后一大章。讲完这一章以后,我们Linux进阶部分讲完以后,我们的Linux操作部分就…...

机器学习在时间序列预测中的应用与实现——以电力负荷预测为例(附代码)
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 随着数据采集技术的发展,时间序列数据在各个领域中的应用越来越广泛。时间序列预测旨在基于过去的时间数据来…...

白杨SEO:百度在降低个人备案类网站搜索关键词排名和流量?怎样应对?【参考】
很久没有写百度或者网站这块内容了,一是因为做百度网站朋友越来越少,不管是个人还是企业;二是百度上用户搜索与百度给到网站的流量都越来越少。 为什么想到今天又来写这个呢?因为上个月有个朋友来咨询我说网站百度排名全没了&…...

前端实现json动画(附带示例)
前端实现json动画(附带示例) 使用lottie制作动画。1.json动画2.实现效果3.git仓库4.运行5.json动画天堂6.代码7. 经常使用的方法 使用lottie制作动画。 1.json动画 废话不多说,直接看效果图2.实现效果 3.git仓库 https://gitee.com/chaiach…...

AI 写作(一):开启创作新纪元(1/10)
一、AI 写作:重塑创作格局 在当今数字化高速发展的时代,AI 写作正以惊人的速度重塑着创作格局。AI 写作在现代社会中占据着举足轻重的地位,发挥着不可替代的作用。 随着信息的爆炸式增长,人们对于内容的需求日益旺盛。AI 写作能够…...

C#-类:索引器
索引器作用:可以让我们以中括号的形式访问自定义类中的元素。 规则自己定,访问时和数组一样 适用于,在类中有数组变量时使用,可以方便的访问、进行逻辑处理 可以重载,结构体也支持索引器 一:索引器的语法…...

Neo4j Cypher WHERE子句详解 - 初学者指南
Neo4j Cypher WHERE子句详解 - 初学者指南 前言1. WHERE子句基础1.1 WHERE子句的本质1.2 示例数据 2. 基本用法2.1 节点属性过滤2.2 关系属性过滤 3. 高级过滤技巧3.1 字符串匹配3.2 正则表达式3.3 属性存在性检查 4. 列表和范围操作4.1 IN操作符4.2 范围查询 5. 空值处理5.1 默…...

【CSS】标准怪异盒模型
概念 CSS 盒模型本质上是一个盒子,盒子包裹着HTML 元素,盒子由四个属性组成,从内到外分别是:content 内容、padding 内填充、border 边框、外边距 margin 盒模型的分类 W3C 盒子模型(标准盒模型) IE 盒子模型(怪异盒模型) 两种…...

不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变
不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变 💡 每次做 PPT 都在 Powerpoint 里拖来拖去,最后做出来还是那个味儿?Frontend Slides 让…...

迷拟极速飞车——极致竞速新体验,重塑线下轻娱新标杆
随着国内文旅休闲、商业游乐行业的快速发展,消费者的线下娱乐审美与体验标准持续升级。传统游乐项目模式固化、玩法单一,同质化问题愈发突出,千篇一律的休闲设施早已无法满足全年龄段游客的多元化游玩需求。无论是城市商业综合体、城郊文旅景…...

NoFences:Windows桌面整理终极指南,5分钟打造高效工作空间
NoFences:Windows桌面整理终极指南,5分钟打造高效工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要在混乱的Windows桌面上花费大…...

Unity热更新原理与方案选型:从AOT限制到HybridCLR实践
1. 热更新不是“打补丁”,而是游戏生命周期的呼吸系统很多人第一次听说Unity热更新,脑子里浮现的是“改个UI文字不用重发包”“修个崩溃不用上架审核”——这没错,但太浅了。我带过三支手游团队,从2017年用AssetBundle硬啃&#x…...

5个步骤在Windows Hyper-V上完美运行macOS虚拟机
5个步骤在Windows Hyper-V上完美运行macOS虚拟机 【免费下载链接】OSX-Hyper-V OpenCore configuration for running macOS on Windows Hyper-V. 项目地址: https://gitcode.com/gh_mirrors/os/OSX-Hyper-V 你是否想在Windows电脑上体验macOS的流畅操作?OSX-…...

终极Ghidra逆向工程指南:30分钟从零掌握二进制分析
终极Ghidra逆向工程指南:30分钟从零掌握二进制分析 【免费下载链接】ghidra Ghidra is a software reverse engineering (SRE) framework 项目地址: https://gitcode.com/GitHub_Trending/gh/ghidra Ghidra作为一款由美国国家安全局(NSAÿ…...

如何解决跨平台资源下载难题:res-downloader的完整使用指南
如何解决跨平台资源下载难题:res-downloader的完整使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

5种方法高效解决DWG文件格式兼容性问题:LibreDWG开源CAD库完整指南
5种方法高效解决DWG文件格式兼容性问题:LibreDWG开源CAD库完整指南 【免费下载链接】libredwg Official mirror of libredwg. With CI hooks and nightly releases. PRs ok 项目地址: https://gitcode.com/gh_mirrors/li/libredwg LibreDWG是一个免费开源的C…...

【AI时代】一句指令复刻所有网页 WEB原型不用愁
【AI时代】一句指令复刻所有网页 WEB原型不用愁“连接 CDP,参考 baidu.com,开发功能原型,1:1 复刻现有页面。”就这么一句话,AI 帮你把原型做出来了。📸 效果对比 原始参考页面生成效果💡 这是 原型开发方式…...

金仓数据库KingbaseES自动创建表空间目录:简化运维,适配国产生态
目录 一、前言:传统表空间创建的运维痛点 二、自动创建表空间目录核心方案 2.1 核心控制参数 2.2 功能强制约束条件 2.3 多场景实操测试(含大小写混合路径) 场景1:目标目录已存在 场景2:目标目录部分存在 场景…...