Spark 的Standalone集群环境安装与测试
目录
一、Standalone 集群环境安装
(一)理解 Standalone 集群架构
(二)Standalone 集群部署
二、打开监控界面
(一)master监控界面
(二)日志服务监控界面
三、集群的测试
(一)圆周率测试
(二)测试 wordcount
四、关于 Spark 程序构成与监控界面
(一)4040 端口相关
(二)4040 与 8080 界面区别
五、总结
在大数据处理领域,Spark 是一款极为强大的工具。本文将重点介绍 Spark 的 Standalone 集群环境安装、测试相关内容,帮助大家更好地理解和使用 Spark 的集群模式。
一、Standalone 集群环境安装
(一)理解 Standalone 集群架构

对比图:

- 架构特点
Standalone 集群采用普通分布式主从架构。其中,Master 作为管理节点,其功能丰富,类似于 YARN 中的 ResourceManager,主要负责管理从节点、接收请求、资源管理以及任务调度。Worker 则是计算节点,它会利用自身节点的资源来运行 Master 分配的任务。这个架构为 Spark 提供了分布式资源管理和任务调度功能,和 YARN 的作用基本一致,而且它是 Spark 自带的计算平台。
- Python 环境注意事项
需要注意的是,每一台服务器上都要安装 Anaconda,因为其中包含 python3 环境。若没有安装,就会出现 python3 找不到的错误。
(二)Standalone 集群部署
第一步:将bigdata02和bigdata03安装Annaconda
因为里面有python3环境,假如没有安装的话,就报这个错误:
上传,或者同步
xsync.sh /opt/modules/Anaconda3-2021.05-Linux-x86_64.sh
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
#第一次:【直接回车,然后按q】Please, press ENTER to continue>>>
#第二次:【输入yes】Do you accept the license terms? [yes|no][no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】[/root/anaconda3] >>> /opt/installs/anaconda3#第四次:【输入yes,是否在用户的.bashrc文件中初始化
Anaconda3的相关内容】Do you wish the installer to initialize Anaconda3by running conda init? [yes|no][no] >>> yes
配置环境变量制作软连接
刷新环境变量:
# 刷新环境变量
source /root/.bashrc
# 激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate配置环境变量:
# 编辑环境变量
vi /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin制作软链接:
# 刷新环境变量
source /etc/profile
Spark的客户端bin目录下:提供了多个测试工具客户端
# 创建软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME在bigdata01上安装spark
# 解压安装
cd /opt/modules
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/installs
# 重命名
cd /opt/installs
mv spark-3.1.2-bin-hadoop3.2 spark-standalone
# 重新构建软连接
rm -rf spark
ln -s spark-standalone spark修改 spark-env.sh配置文件
cd /opt/installs/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh# 22行:申明JVM环境路径以及Hadoop的配置文件路径
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
# 60行左右
export SPARK_MASTER_HOST=bigdata01 # 主节点所在的地址
export SPARK_MASTER_PORT=7077 #主节点内部通讯端口,用于接收客户端请求
export SPARK_MASTER_WEBUI_PORT=8080 #主节点用于供外部提供浏览器web访问的端口
export SPARK_WORKER_CORES=1 # 指定这个集群总每一个从节点能够使用多少核CPU
export SPARK_WORKER_MEMORY=1g #指定这个集群总每一个从节点能够使用多少内存
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_DAEMON_MEMORY=1g # 进程自己本身使用的内存
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
# Spark中提供了一个类似于jobHistoryServer的进程,就叫做HistoryServer, 用于查看所有运行过的spark程序在HDFS上创建程序日志存储目录
首先如果没有启动hdfs,需要启动一下
# 第一台机器启动HDFS
start-dfs.sh
# 创建程序运行日志的存储目录
hdfs dfs -mkdir -p /spark/eventLogs/spark-defaults.conf:Spark属性配置文件
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf# 末尾
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata01:9820/spark/eventLogs
spark.eventLog.compress trueworkers:从节点地址配置文件
mv workers.template workers
vim workers# 删掉localhost,添加以下内容
bigdata01
bigdata02
bigdata03log4j.properties:日志配置文件
mv log4j.properties.template log4j.properties
vim log4j.properties# 19行:修改日志级别为WARN
log4j.rootCategory=WARN, consolelog4j的5种 级别 debug --> info --> warn --error -->fatal同步bigdata01中的spark到bigdata02和03上
xsync.sh为自建脚本
大数据集群中实用的三个脚本文件解析与应用-CSDN博客
xsync.sh /opt/installs/spark-standalone/接着在第二台和第三台上,创建软链接
cd /opt/installs/
ln -s spark-standalone spark换个思路,是否可以同步软链接:
xsync.sh /opt/installs/spark集群的启动
启动master:
cd /opt/installs/spark
sbin/start-master.sh
启动所有worker:
sbin/start-workers.sh
如果你想启动某一个worker
sbin/start-worker.sh启动日志服务:
sbin/start-history-server.sh要想关闭某个服务,将start换为stop二、打开监控界面
(一)master监控界面
http://bigdata01:8080/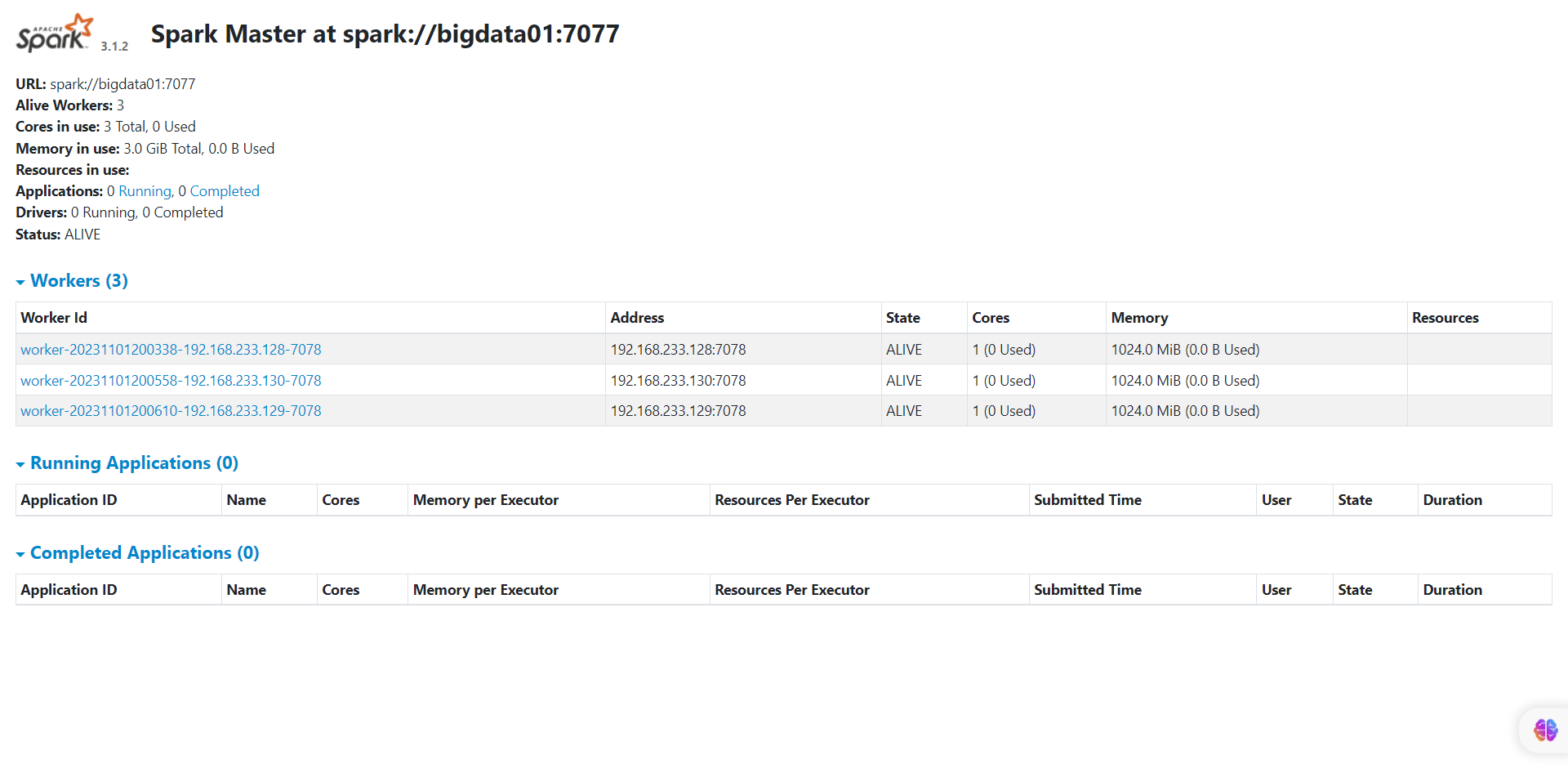
(二)日志服务监控界面
http://bigdata01:18080/假如启动报错,查看日志发现说没有文件夹:
mkdir /tmp/spark-eventshdfs dfs -mkdir -p /spark/eventLogs
再启动即可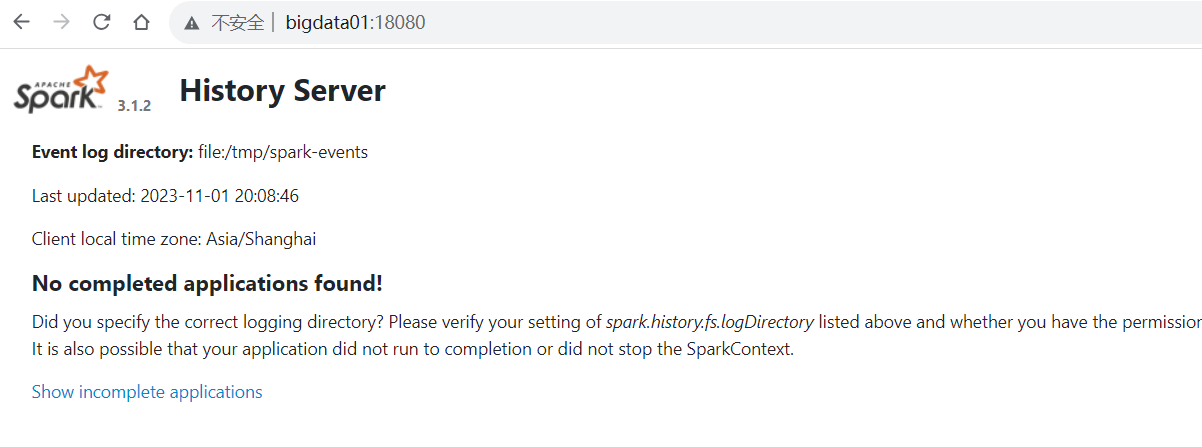
三、集群的测试
(一)圆周率测试
在集群环境下进行圆周率测试,与本地模式运行的区别主要在 --master 后面的参数。
# 提交程序脚本:bin/spark-submit
/opt/installs/spark/bin/spark-submit --master spark://bigdata01:7077 /opt/installs/spark/examples/src/main/python/pi.py 200
(二)测试 wordcount
将本地数据上传至 HDFS
参考:Spark 的介绍与搭建:从理论到实践-CSDN博客
hdfs dfs -mkdir -p /spark/wordcount/input
hdfs dfs -put /home/data.txt /spark/wordcount/input使用集群环境编写测试 wordcount
本地模式:
/opt/installs/spark/bin/pyspark --master local[2]
standalone集群模式:
/opt/installs/spark/bin/pyspark --master spark://bigdata01:7077读取数据 读取是hdfs上的数据
# 读取数据 读取是hdfs上的数据
input_rdd = sc.textFile("/spark/wordcount/input")
# 转换数据
rs_rdd = input_rdd.filter(lambda line : len(line.strip())> 0).flatMap(lambda line :line.strip().split(r" ")).map(lambda word : (word,1)).reduceByKey(lambda tmp,item : tmp+item)
# 保存结果
rs_rdd.saveAsTextFile("/spark/wordcount/output3")以上这些代码跟昨天没区别只是运行环境变了。
本地数据 --> hdfs上的数据
本地资源 --> 集群的资源 这些算子都是在spark自带的standalone集群平台上运行的。解决一个问题:
spark-env.sh
# 22行:申明JVM环境路径以及Hadoop的配置文件路径
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
# 60行左右
export SPARK_MASTER_HOST=bigdata01 # 主节点所在的地址
export SPARK_MASTER_PORT=7077 #主节点内部通讯端口,用于接收客户端请求
export SPARK_MASTER_WEBUI_PORT=8080 #主节点用于供外部提供浏览器web访问的端口
export SPARK_WORKER_CORES=1 # 指定这个集群总每一个从节点能够使用多少核CPU
export SPARK_WORKER_MEMORY=1g #指定这个集群总每一个从节点能够使用多少内存
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_DAEMON_MEMORY=1g # 进程自己本身使用的内存
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
# Spark中提供了一个类似于jobHistoryServer的进程,就叫做HistoryServer, 用于查看所有运行过的spark程序修改完之后,同步给bigdata02和03,重新启动各个服务即可。
四、关于 Spark 程序构成与监控界面
在分布式集群模式下,任何一个 Spark 程序都由 1 个 Driver 和多个 Executor 进程所构成。
任何一个spark程序在集群模式下运行,都有两种进程:
Driver、Executor
Driver: 驱动程序,每一个spark程序都只有一个
Executor: 执行进程,负责计算,可以有多个,运行在不同节点Master和Worker进程,是spark的standalone平台服务启动后的进程,不管是否有任务执行,它都会启动的
Driver、Executor 是只有有任务执行的时候才会有的进程!!
假如一个任务,你看到如下的场景,说明任务没有执行完,需要等......

(一)4040 端口相关
http://bigdata01:4040 查看正在运行的任务
4040这个界面,只要有新任务,就会生成一个新的界面,比如你要是再执行一个任务,端口会变为4041,再来一个任务,端口变4042
默认情况下,当一个Spark Application运行起来后,可以通过访问hostname:4040端口来访问UI界面。hostname是提交任务的Spark客户端ip地址,端口号由参数spark.ui.port(默认值4040,如果被占用则顺序往后探查)来确定。由于启动一个Application就会生成一个对应的UI界面,所以如果启动时默认的4040端口号被占用,则尝试4041端口,如果还是被占用则尝试4042,一直找到一个可用端口号为止
通过这个 界面,可以看到一个任务执行的全部情况。这个界面跟 http://bigdata01:8080界面很像。
(二)4040 与 8080 界面区别
通过案例查看 4040 界面和 8080 界面的区别:
/opt/installs/spark/bin/spark-submit --master spark://bigdata01:7077 /opt/installs/spark/examples/src/main/python/pi.py 1000假如启动了一个任务在集群上运行,4040端口中查看的所有信息都只跟这个任务有关系,
假如又启动一个任务,4040是看不到了,可以使用4041来查看,依次类推。当任务结束后,404x 这些界面都会销毁掉,相当于只能查看正在运行的一个任务。
8080这个界面是一个总指挥,不仅能看到正在运行的任务,还可以看到已经执行完的任务。
五、总结
本文围绕 Spark 的 Standalone 集群环境展开。首先介绍其安装,包括理解架构(主从架构,Master 管理资源和任务调度,Worker 执行任务,类似 YARN,且需安装 Anaconda 保证 python3 环境)和部署(在 bigdata02、03 安装 Anaconda,在 bigdata01 安装 Spark 并修改配置文件、创建日志存储目录、配置 Spark 属性、从节点地址和日志等文件),还讲了集群同步与启动方法。接着是测试,圆周率测试和 wordcount 测试,强调了与本地模式在参数和数据来源上的区别。最后阐述 Spark 程序构成(1 个 Driver 和多个 Executor)和监控界面,如 4040 端口可查看正在运行任务(新任务会使端口递增),8080 端口能查看所有任务情况。
希望本文能帮助大家更好地理解 Spark 的 Standalone 集群环境相关知识,在大数据处理实践中更加得心应手。
相关文章:
Spark 的Standalone集群环境安装与测试
目录 一、Standalone 集群环境安装 (一)理解 Standalone 集群架构 (二)Standalone 集群部署 二、打开监控界面 (一)master监控界面 (二)日志服务监控界面 三、集群的测试 &a…...

在Java中,实现数据库连接通常使用JDBC
学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把手教你开发炫酷的vbs脚本制作(完善中……) 4、牛逼哄哄的 IDEA编程利器技巧(编写中……) 5、面经吐血整理的 面试技…...

Git 测验
Git 测验 引言 Git 是一款强大的分布式版本控制系统,它由Linus Torvalds创建,主要用于帮助多人协作开发项目。Git 的设计目标是速度、数据完整性以及分布式支持。自从2005年发布以来,Git 已经成为全球最流行的版本控制系统之一,被广泛应用于各种规模的软件开发项目中。 …...

L1G3000 提示工程(Prompt Engineering)
什么是Prompt(提示词)? Prompt是一种灵活、多样化的输入方式,可以用于指导大语言模型生成各种类型的内容。什么是提示工程? 提示工程是一种通过设计和调整输入(Prompts)来改善模型性能或控制其输出结果的技术。 六大基本原则: 指令要清晰提供参考内容复杂的任务拆…...

【SQL50】day 1
目录 1.可回收且低脂的产品 2.寻找用户推荐人 3.使用唯一标识码替换员工ID 4.产品销售分析 I 5.有趣的电影 6.平均售价 7.每位教师所教授的科目种类的数量 8.平均售价 1.可回收且低脂的产品 # Write your MySQL query statement below select product_id from Products w…...

jmeter脚本-请求体设置变量and请求体太长的处理
目录 1、查询接口 1.1 准备组织列表的TXT文件,如下: 1.2 添加 CSV数据文件设置 ,如下: 1.3 接口请求体设置变量,如下: 2、创建接口 2.1 见1.1 2.2 见1.2 2.3 准备创建接口的请求体TXT文件ÿ…...

基于java+SpringBoot+Vue的旅游管理系统设计与实现
项目运行 环境配置: Jdk1.8 Tomcat7.0 Mysql HBuilderX(Webstorm也行) Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术: Springboot mybatis Maven mysql5.7或8.0等等组成&#x…...

SD3模型的部署(本地部署)
文章目录 模型权重的下载需要注意的地方推理代码生成的效果图 模型的结构图 模型权重的下载 SD3:huggingface的权重 我们需要把huggingfaceface下的这些文件都下载到一个文件加下,然后在后面的pipe StableDiffusion3Pipeline.from_pretrained(“stabil…...

讲解DFD和ERD
DFD、ERD 1. DFD(数据流图,Data Flow Diagram)DFD的主要元素:DFD的层次结构:举例:1. 上下文图:2. 分解图: DFD的应用: 2. ERD(实体关系图,Entity …...

TVM计算图分割--LayerGroup
文章目录 介绍Layergroup调研TVM中的LayergroupTVM Layergroup进一步优化MergeCompilerRegions处理菱形结构TVM中基于Pattern得到的子图TPUMLIR地平线的Layergroup介绍 Layergroup目前没找到严格、明确的定义,因为不同厂家的框架考虑的因素不同,但是基本逻辑是差不多的。一般…...
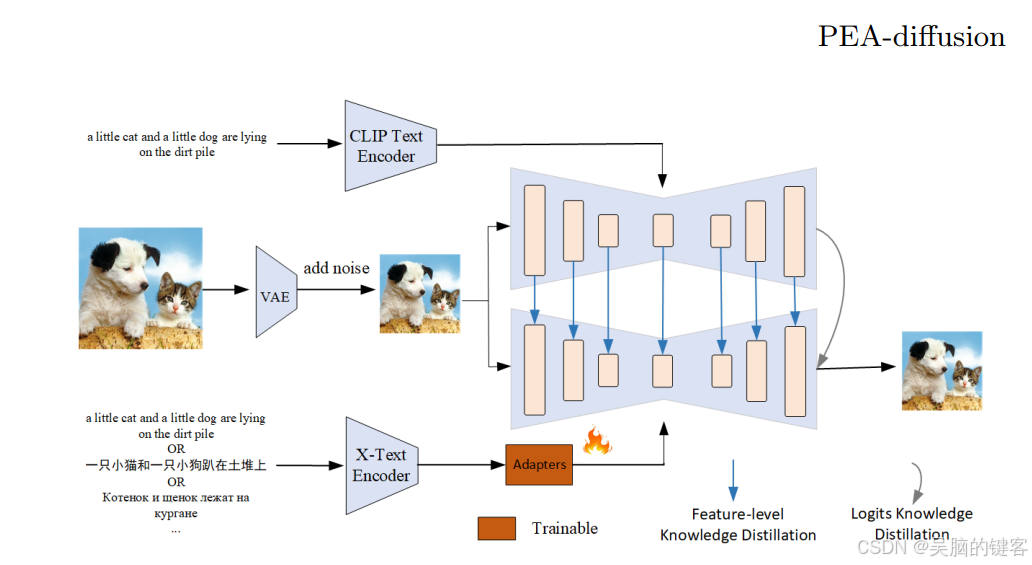
OPPO开源Diffusion多语言适配器—— MultilingualSD3-adapter 和 ChineseFLUX.1-adapter
MultilingualSD3-adapter 是为 SD3 量身定制的多语言适配器。 它源自 ECCV 2024 的一篇题为 PEA-Diffusion 的论文。ChineseFLUX.1-adapter是为Flux.1系列机型量身定制的多语言适配器,理论上继承了ByT5,可支持100多种语言,但在中文方面做了额…...

Spring 设计模式之责任链模式
Spring 设计模式之责任链模式 责任链模式用到的场景java举例 责任链模式 责任链模式(Chain of Responsibility)是一种行为设计模式,它允许你将请求沿着处理者链进行传递。 每个处理者可以对请求进行处理,也可以将请求传递给链中的…...

简单的 docker 部署ELK
简单的 docker 部署ELK 这是我的运维同事部署ELK的文档,我这里记录转载一下 服务规划 架构: Filebeat->kafka->logstash->ES kafka集群部署参照: kafka集群部署 部署服务程序路径/数据目录端口配置文件elasticsearch/data/elasticsearch9200/data/elas…...

四款主流的3D创作和游戏开发软件的核心特点和关系
四款主流的3D创作和游戏开发软件的核心特点和关系 3D建模软件: Blender: 开源免费,功能全面优点: 完全免费持续更新优化社区活跃,学习资源丰富功能全面(建模、动画、渲染等) 缺点: 学习曲线陡峭界面操作…...

聚划算!Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN五模型多变量回归预测
聚划算!Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN五模型多变量回归预测 目录 聚划算!Transformer-LSTM、Transformer、CNN-LSTM、LSTM、CNN五模型多变量回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 聚划算!Tran…...

信息安全工程师(76)网络安全应急响应技术原理与应用
前言 网络安全应急响应(Network Security Incident Response)是针对潜在或已发生的网络安全事件而采取的网络安全措施,旨在降低网络安全事件所造成的损失并迅速恢复受影响的系统和服务。 一、网络安全应急响应概述 定义:网络安全应…...

使用 OpenCV 实现图像的透视变换
概述 在计算机视觉领域,经常需要对图像进行各种几何变换,如旋转、缩放和平移等。其中,透视变换(Perspective Transformation)是一种非常重要的变换方式,它能够模拟三维空间中的视角变化,例如从…...

openGauss数据库-头歌实验1-4 数据库及表的创建
一、创建数据库 (一)任务描述 本关任务:创建指定数据库。 (二)相关知识 数据库其实就是可以存放大量数据的仓库,学习数据库我们就从创建一个数据库开始吧。 为了完成本关任务,你需要掌握&a…...

吉利极氪汽车嵌入式面试题及参考答案
inline 的作用 inline 是 C++ 中的一个关键字。它主要用于函数,目的是建议编译器将函数体插入到调用该函数的地方,而不是像普通函数调用那样进行跳转。 从性能角度来看,当一个函数被标记为 inline 后,在编译阶段,编译器可能会将函数的代码直接复制到调用它的位置。这样做…...

pycharm中的服务是什么?
在PyCharm中,服务是指允许在PyCharm中运行的一种功能或插件。服务可以是内置的,也可以是通过插件安装的。 一些常见的PyCharm服务包括: 调试服务:PyCharm提供了全功能的调试工具,可以帮助开发人员通过设置断点、监视变…...

2026降AI率工具红黑榜:AI智能降重工具怎么选?用数据说话!
红榜优先选千笔AI、ThouPen、豆包,适配国内高校AI率检测规范;黑榜避开低质免费降AI工具、无正规检测对接、改写痕迹生硬的工具,优先按需求匹配三维模型(降AI效果-学术合规性-使用成本)。 一、红榜:10 款高分…...

Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁?
Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁? 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经因为Adobe Crea…...
)
【Gartner认证实践框架】:AI Agent客服上线前必须完成的12项合规性验证清单(含GDPR/等保2.0/金融信创适配)
更多请点击: https://intelliparadigm.com 第一章:AI Agent客服的合规性验证战略定位 在金融、医疗、电信等强监管行业,AI Agent客服系统不仅需满足功能与体验目标,更须将合规性嵌入其设计、开发与运营全生命周期。合规性验证不是…...

Postman登录接口响应为空?HTTP响应体未刷出的三层根因分析
1. 这不是Postman的问题,是接口通信链路上某个环节“失语”了你用Postman调后端登录接口,请求发出去了,状态码也回来了(比如200),但响应体里空空如也——没有JSON数据、没有token字段、甚至Response标签页里…...

如何在现代显示器上完美重温经典游戏?终极宽屏修复工具包指南
如何在现代显示器上完美重温经典游戏?终极宽屏修复工具包指南 【免费下载链接】WidescreenFixesPack Plugins to make or improve widescreen resolutions support in games, add more features and fix bugs. 项目地址: https://gitcode.com/gh_mirrors/wi/Wides…...

机器学习核函数原理与实战选型指南
1. 什么是机器学习中的核函数?它到底在解决什么问题?“Types of Kernels in Machine Learning”这个标题看起来像教科书目录里的一节,但如果你真在项目里调过SVM(kernelrbf)、用过sklearn.metrics.pairwise.rbf_kernel、或者被kernel trick这…...

利用 Taotoken 模型广场为你的智能客服场景选择最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 模型广场为你的智能客服场景选择最合适的大模型 智能客服是当前大模型技术落地最广泛的场景之一。无论是处理售前咨…...

别再用官方互联了!用这款8年前的“神器”HandShaker,安卓14/澎湃OS手机也能和电脑秒传文件
安卓14与澎湃OS用户的跨平台文件传输神器:HandShaker深度体验指南 在智能手机厂商纷纷构建封闭生态的今天,跨品牌设备间的文件传输反而成了令人头疼的问题。小米的妙享中心、华为的多屏协同固然强大,但它们往往要求用户必须使用同品牌笔记本…...

如何为Public Money Public Code网站添加新的支持组织:完整操作指南
如何为Public Money Public Code网站添加新的支持组织:完整操作指南 【免费下载链接】publiccode.asia-legacy Website of https://publiccode.asia 项目地址: https://gitcode.com/gh_mirrors/pu/publiccode.asia-legacy 想要为publiccode.asia这个开源项目…...

为内部ai工具平台选择统一api网关时taotoken的接入与管理价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部AI工具平台选择统一API网关时Taotoken的接入与管理价值 当公司内部需要构建一个集成多种AI能力的工具平台时,技术…...