python NLTK快速入门
目录
- NLTK简介
- 安装NLTK
- 主要模块及用法
- 词汇与语料库
- 分词与词性标注
- 句法分析
- 情感分析
- 文本分类
- 综合实例:简单的文本分析项目
- 总结
1. NLTK简介
NLTK(Natural Language Toolkit)是一个强大的Python库,专门用于自然语言处理(NLP)任务,常用于文本分析、语言数据处理和机器学习。NLTK包含丰富的语料库和词汇资源,还提供了众多分析工具。
2. 安装NLTK
在Python环境下,您可以用以下命令来安装NLTK:
pip install nltk
之后,运行下面代码来下载NLTK的语料库(语料库包含了大量预训练的文本数据):
import nltk
nltk.download('all')
3. 主要模块及用法
3.1 词汇与语料库
NLTK 提供了许多内置的语料库和词典,可以帮助我们更好地分析文本。
from nltk.corpus import gutenberg # 获取《爱丽丝梦游仙境》前100个字符
text = gutenberg.raw('carroll-alice.txt')
print(text[:100])讲解:这里我们使用 gutenberg 语料库,它包含了很多经典书籍的文本。我们选择了《爱丽丝梦游仙境》并打印了前100个字符。
3.2 分词与词性标注
在自然语言处理中,分词(Tokenization)和词性标注(POS Tagging)是常见的基础操作。
分词示例:
from nltk.tokenize import word_tokenize text = "NLTK makes it easy to work with text data." tokens = word_tokenize(text) print(tokens)讲解:word_tokenize 函数会将一句话分割成一个个词语。这里我们输入了一段文字,输出结果是按词语切分的一个列表。
词性标注示例:
from nltk import pos_tag
tokens = word_tokenize("The quick brown fox jumps over the lazy dog.")
tagged = pos_tag(tokens)
print(tagged)讲解:pos_tag 函数会将分好的词语标注上词性(如名词、动词等),输出的是一个包含词语及其词性标注的元组列表。
3.3 句法分析
NLTK 提供了句法分析工具,可以帮助我们解析句子的语法结构。
示例:
from nltk import CFG
from nltk.parse import RecursiveDescentParser # 定义简单的语法
grammar = CFG.fromstring(""" S -> NP VP NP -> Det N VP -> V NP Det -> 'the' N -> 'cat' | 'dog' V -> 'chases' """) parser = RecursiveDescentParser(grammar)
sentence = "the cat chases the dog".split()
for tree in parser.parse(sentence): print(tree)讲解:这里我们定义了一个简单的上下文无关语法(CFG)来解析句子结构,然后使用 RecursiveDescentParser进行解析。
3.4 情感分析
情感分析是自然语言处理中非常常见的任务,用来分析文本的情感(如积极、消极等)。
示例:
from nltk.sentiment import SentimentIntensityAnalyzer sia = SentimentIntensityAnalyzer()
text = "I love programming!"
sentiment = sia.polarity_scores(text)
print(sentiment)讲解:SentimentIntensityAnalyzer 会给出一个情感分数,输出包含正面、负面、客观及总体评分。
3.5 文本分类
NLTK也提供了文本分类的基本工具,可以帮助我们训练模型进行文本分类。
示例:
import random
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import movie_reviews# 数据处理:随机打乱文档列表
documents = [(list(movie_reviews.words(fileid)), category)for category in movie_reviews.categories()for fileid in movie_reviews.fileids(category)
]
random.shuffle(documents) # 随机打乱顺序,以避免偏差# 特征提取:将单词作为特征
def document_features(words):return {word: True for word in words}# 准备训练集
train_set = [(document_features(d), c) for (d, c) in documents]# 训练分类器:使用前100个文档进行训练
classifier = NaiveBayesClassifier.train(train_set[:100])# 测试分类
test_words = ["love", "wonderful", "amazing"]
print("测试句子:", test_words)
print("分类结果:", classifier.classify(document_features(test_words)))# 显示分类器的性能
print("\n分类器的特征:")
classifier.show_most_informative_features(5)
讲解:这里我们使用了贝叶斯分类器(Naive Bayes),并使用影评数据集对其进行训练,最终用“love”、“wonderful”等词进行分类测试。
4. 综合实例:简单的文本分析项目
结合以上知识点,我们可以进行一个简单的文本分析小项目。
示例:分析电影影评的情感倾向
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import movie_reviews# 数据处理
documents = [(list(movie_reviews.words(fileid)), category)for category in movie_reviews.categories()for fileid in movie_reviews.fileids(category)
]# 特征提取
def document_features(words):return {word: True for word in words}# 训练分类器
train_set = [(document_features(d), c) for (d, c) in documents]
classifier = NaiveBayesClassifier.train(train_set[:100])# 测试分类
print(classifier.classify(document_features(["love", "wonderful", "amazing"])))
讲解:这里我们用影评数据集,并结合情感分析器进行影评倾向判断。通过遍历所有影评,统计正面和负面影评的数量。
5. 总结
通过以上步骤,您已经掌握了 NLTK 的核心用法,包括分词、词性标注、句法分析、情感分析和文本分类等。
相关文章:

python NLTK快速入门
目录 NLTK简介安装NLTK主要模块及用法 词汇与语料库分词与词性标注句法分析情感分析文本分类综合实例:简单的文本分析项目总结 1. NLTK简介 NLTK(Natural Language Toolkit)是一个强大的Python库,专门用于自然语言处理ÿ…...

技术速递|.NET 9 中 System.Text.Json 的新增功能
作者:Eirik Tsarpalis - 首席软件工程师 排版:Alan Wang System.Text.Json 的9.0 版本包含许多功能,主要侧重于 JSON 架构和智能应用程序支持。它还包括一些备受期待的增强功能,例如可空引用类型支持、自定义枚举成员名称、无序元…...

LLM 使用 Elastic 实现可观察性:Azure OpenAI (二)
作者:来自 Elastic Muthukumar Paramasivam•Lalit Satapathy 我们为 Azure OpenAI GA 包添加了更多功能,现在提供提示和响应监控、PTU 部署性能跟踪和计费洞察! 我们最近宣布了 Azure OpenAI 集成的 GA。你可以在我们之前的博客 LLM 可观察性…...

数据库基础(2) . 安装MySQL
0.增加右键菜单选项 添加 管理员cmd 到鼠标右键 运行 reg文件 在注册表中添加信息 这样在右键菜单中就有以管理员身份打开命令行的选项了 1.获取安装程序 网址: https://dev.mysql.com/downloads/mysql/ 到官网下载MySQL8 的zip包, 然后解压 下载后的包为: mysql-8.0.16-…...

高效自动化测试,引领汽车座舱新纪元——实车篇
引言 作为智能网联汽车的核心组成部分,智能座舱不仅是驾驶者与车辆互动的桥梁,更是个性化、智能化体验的源泉。实车测试作为验证智能座舱功能实现、用户体验、行车安全及法规符合性的关键环节,能够最直接地模拟真实驾驶场景,确保…...

GitHub中搜索项目方法
0 Preface/Foreword 1 搜索方法 1.1 项目介绍 如上截图,一个项目包含的基本信息: 项目名项目简介项目介绍Watch数量,接收邮件提醒Star数量,关注,subscribeFork数量,在repo中创建分支 1.2 限定项目名查找…...

浅谈串口服务器的作用
串口服务器是一种网络设备,它允许通过TCP/IP网络远程访问串行设备。它的作用主要包括: 1、远程访问:通过将串行通信转换为以太网通信,串口服务器使得远程访问串行设备成为可能,这对于远程监控和控制非常有用。 2、数据…...

Spark 的Standalone集群环境安装与测试
目录 一、Standalone 集群环境安装 (一)理解 Standalone 集群架构 (二)Standalone 集群部署 二、打开监控界面 (一)master监控界面 (二)日志服务监控界面 三、集群的测试 &a…...

在Java中,实现数据库连接通常使用JDBC
学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把手教你开发炫酷的vbs脚本制作(完善中……) 4、牛逼哄哄的 IDEA编程利器技巧(编写中……) 5、面经吐血整理的 面试技…...

Git 测验
Git 测验 引言 Git 是一款强大的分布式版本控制系统,它由Linus Torvalds创建,主要用于帮助多人协作开发项目。Git 的设计目标是速度、数据完整性以及分布式支持。自从2005年发布以来,Git 已经成为全球最流行的版本控制系统之一,被广泛应用于各种规模的软件开发项目中。 …...

L1G3000 提示工程(Prompt Engineering)
什么是Prompt(提示词)? Prompt是一种灵活、多样化的输入方式,可以用于指导大语言模型生成各种类型的内容。什么是提示工程? 提示工程是一种通过设计和调整输入(Prompts)来改善模型性能或控制其输出结果的技术。 六大基本原则: 指令要清晰提供参考内容复杂的任务拆…...

【SQL50】day 1
目录 1.可回收且低脂的产品 2.寻找用户推荐人 3.使用唯一标识码替换员工ID 4.产品销售分析 I 5.有趣的电影 6.平均售价 7.每位教师所教授的科目种类的数量 8.平均售价 1.可回收且低脂的产品 # Write your MySQL query statement below select product_id from Products w…...

jmeter脚本-请求体设置变量and请求体太长的处理
目录 1、查询接口 1.1 准备组织列表的TXT文件,如下: 1.2 添加 CSV数据文件设置 ,如下: 1.3 接口请求体设置变量,如下: 2、创建接口 2.1 见1.1 2.2 见1.2 2.3 准备创建接口的请求体TXT文件ÿ…...

基于java+SpringBoot+Vue的旅游管理系统设计与实现
项目运行 环境配置: Jdk1.8 Tomcat7.0 Mysql HBuilderX(Webstorm也行) Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术: Springboot mybatis Maven mysql5.7或8.0等等组成&#x…...

SD3模型的部署(本地部署)
文章目录 模型权重的下载需要注意的地方推理代码生成的效果图 模型的结构图 模型权重的下载 SD3:huggingface的权重 我们需要把huggingfaceface下的这些文件都下载到一个文件加下,然后在后面的pipe StableDiffusion3Pipeline.from_pretrained(“stabil…...

讲解DFD和ERD
DFD、ERD 1. DFD(数据流图,Data Flow Diagram)DFD的主要元素:DFD的层次结构:举例:1. 上下文图:2. 分解图: DFD的应用: 2. ERD(实体关系图,Entity …...

TVM计算图分割--LayerGroup
文章目录 介绍Layergroup调研TVM中的LayergroupTVM Layergroup进一步优化MergeCompilerRegions处理菱形结构TVM中基于Pattern得到的子图TPUMLIR地平线的Layergroup介绍 Layergroup目前没找到严格、明确的定义,因为不同厂家的框架考虑的因素不同,但是基本逻辑是差不多的。一般…...
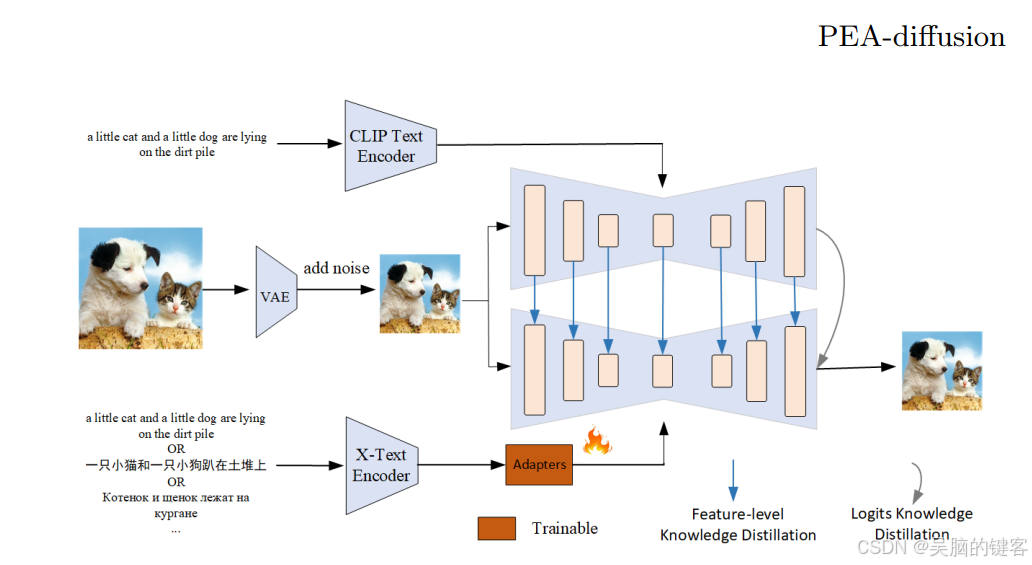
OPPO开源Diffusion多语言适配器—— MultilingualSD3-adapter 和 ChineseFLUX.1-adapter
MultilingualSD3-adapter 是为 SD3 量身定制的多语言适配器。 它源自 ECCV 2024 的一篇题为 PEA-Diffusion 的论文。ChineseFLUX.1-adapter是为Flux.1系列机型量身定制的多语言适配器,理论上继承了ByT5,可支持100多种语言,但在中文方面做了额…...

Spring 设计模式之责任链模式
Spring 设计模式之责任链模式 责任链模式用到的场景java举例 责任链模式 责任链模式(Chain of Responsibility)是一种行为设计模式,它允许你将请求沿着处理者链进行传递。 每个处理者可以对请求进行处理,也可以将请求传递给链中的…...

简单的 docker 部署ELK
简单的 docker 部署ELK 这是我的运维同事部署ELK的文档,我这里记录转载一下 服务规划 架构: Filebeat->kafka->logstash->ES kafka集群部署参照: kafka集群部署 部署服务程序路径/数据目录端口配置文件elasticsearch/data/elasticsearch9200/data/elas…...

UPS电源部分
1.法国最好的ups 施耐德电器 美国最好的ups 伊顿 瑞士最好的ups ABB 日本最好的ups 三菱电器 台湾是 台达电子 对的吗2.施耐德电气 (Schneider Electric):虽然公司总部在法国,但其UPS业务的核心是旗下的APC(美国电力转换公司&…...
)
【Anaconda】使用指南及问题汇总(自用)
安装 1. Anaconda的下载与安装 除了安装路径修改,其他的一路默认就好 2. Anaconda修改环境变量 因为我们这一步才手动添加环境变量,所以第一步安装的时候不要让它自动配置环境变量了。 用户变量或者系统变量都可以。建议系统变量,方便后…...

OAuth 2.0 client_id深度解析:从规范到安全实践
1. 引言:一个字符串背后的身份体系 在 OAuth 2.0 的整个生态里,client_id 是出现频率最高却最容易被忽视的参数之一。它几乎出现在每一个授权请求的 URL 里,开发者往往只是将其视为"配置项",从 IdP 控制台粘贴过来填进…...

AI 调研平台,以智能技术重构全域调研数字化体系
在各行各业的业务研判、市场分析、工作调研场景中,传统调研模式长期依赖人工采集、手动整理、经验分析,存在明显的技术与效率短板。人工调研数据来源零散、数据清洗繁琐、分析维度单一,不仅耗费大量人力时间,还容易出现数据遗漏、…...

如何用knitAYABInterface创建复杂图案:从JSON文件到针织成品的完整流程
如何用knitAYABInterface创建复杂图案:从JSON文件到针织成品的完整流程 【免费下载链接】knitAYABInterface A Python library with the interface to the AYAB shield. 项目地址: https://gitcode.com/gh_mirrors/ay/knitAYABInterface 想要将数字图案转化为…...

为什么我总是想很多,却很难开始做?
为什么我总是想很多,却很难开始做? 有一种人,脑子从来停不下来。 走路在想,洗澡在想,睡前还在想。 想人生方向,想技术路线,想项目结构,想商业模式,想内容选题,…...

AI学习-朴素贝叶斯垃圾邮件识别:从理论到实现
朴素贝叶斯垃圾邮件识别:从理论到实现 摘要 本文从理论推导角度,完整解释朴素贝叶斯模型做垃圾邮件识别的可行性,包括:为什么文字需要向量化、贝叶斯公式如何推导出分类规则、"朴素"假设为什么不严格但仍然好用、训练…...

如何快速构建数学可视化:Manim交互式开发完整教程
如何快速构建数学可视化:Manim交互式开发完整教程 【免费下载链接】manim Animation engine for explanatory math videos 项目地址: https://gitcode.com/GitHub_Trending/ma/manim 想要告别数学动画制作中反复修改代码、重新渲染的烦恼吗?&…...

Taotoken控制台的用量看板与账单追溯功能如何助力团队成本管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台的用量看板与账单追溯功能如何助力团队成本管理 对于团队管理者或项目负责人而言,将大模型能力整合进业…...

免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克技术
免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克技术 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/d…...