Spark的Shuffle过程
一、Shuffle 的作用是什么?
Shuffle 操作可以理解为将集群中各个节点上的数据进行重新整理和分类的过程。这一概念源自 Hadoop 的 MapReduce 模型,Shuffle 是连接 Map 阶段和 Reduce 阶段的关键环节。在分布式计算中,每个计算节点通常只处理任务的一部分数据。如果下一个阶段需要依赖前一个阶段的所有计算结果,就需要对这些结果进行重新整合和分类,这就是 Shuffle 的主要任务。在 Spark 中,RDD 之间的依赖关系分为窄依赖和宽依赖,其中宽依赖涉及 Shuffle 操作。因此,在 Spark 程序中,每个 job 的阶段(stage)划分依据就是是否存在 Shuffle 操作,每个 stage 包含一系列的 RDD map 操作。
二、为什么 Shuffle 操作耗时?
Shuffle 操作需要对数据进行重新聚合和划分,并将这些数据分配到集群的各个节点上进行下一步的处理。这一过程中,不同节点之间需要进行大量的数据交换。由于数据传输需要通过网络,并且通常需要先将数据写入磁盘,因此每个节点都会进行大量的文件读写操作。这些读写操作不仅增加了 I/O 开销,还可能导致网络拥塞,从而使 Shuffle 操作变得非常耗时,相比之下,简单的 map 操作则要快得多。
三、Spark 当前的ShuffleManager模式及处理机制
在 Spark 程序中,Shuffle 操作由 ShuffleManager 对象进行管理。目前,Spark 支持两种主要的 ShuffleManager 模式:HashShuffleManager 和 SortShuffleManager。Shuffle 操作包括当前阶段的 Shuffle Write(写入磁盘)和下一阶段的 Shuffle Read(读取),这两种模式的主要区别在于 Shuffle Write 阶段的处理方式。
3.1、HashShuffleManager
HashShuffleManager 是 Spark 最初使用的 ShuffleManager 模式。在这种模式下,每个任务(task)会为每个分区(partition)创建一个临时文件,并将数据直接写入对应的文件中。这种方式简单直观,但在处理大量分区时会产生大量的小文件,导致磁盘 I/O 开销增加。此外,每个任务都需要为每个分区打开和关闭文件,这也会增加文件句柄的开销。
3.2、SortShuffleManager
SortShuffleManager 是目前 Spark 默认使用的 ShuffleManager 模式。在这种模式下,任务会先对数据进行排序,然后将排序后的数据写入一个或几个大文件中。这种方式减少了文件的数量,提高了磁盘 I/O 效率。此外,SortShuffleManager 还支持数据的内存缓存,只有在内存不足时才会将数据溢写到磁盘,从而进一步提高了性能。
四、Spark 程序的 Shuffle 调优
Shuffle 阶段需要将数据写入磁盘,这涉及到大量的读写文件操作和文件传输操作,对节点的系统 I/O 有较大的影响。通过调整一些关键参数,可以减少 Shuffle 阶段的文件数量和 I/O 读写次数,从而提高性能。以下是几个主要的调优参数:
1、spark.shuffle.manager:设置 Spark 任务的 ShuffleManager 模式。对于 Spark 1.2 以上版本,默认值为 sort,即在 Shuffle Write 阶段会对数据进行排序,每个 executor 上生成的文件会合并成两个文件(一个数据文件和一个索引文件)。通常情况下,默认的 sort 模式已经能够提供较好的性能,除非有特殊情况,一般不需要更改此参数。
2、spark.shuffle.sort.bypassMergeThreshold:设置启用 bypass 机制的阈值。如果 Shuffle Read 阶段的 task 数量小于或等于该值,则 Shuffle Write 阶段会启用 bypass 机制。默认值为 200。如果 Shuffle Read 阶段的 task 数量较少,可以适当降低这个阈值,以启用 bypass 机制,减少文件合并操作,提高性能。
3、spark.shuffle.file.buffer:设置 Shuffle Write 阶段写文件时缓冲区的大小。默认值为 32MB。如果内存资源充足,可以将该值调大(例如 64MB),以减少 executor 的 I/O 读写次数,提高写入速度。
4、spark.shuffle.io.maxRetries:设置 Shuffle Read 阶段 fetch 数据时的最大重试次数。默认值为 3 次。如果 Shuffle 阶段的数据量很大,网络环境不稳定,可以适当增加重试次数,以提高数据传输的成功率。
除了上述参数外,还有一些其他常用的 Shuffle 调优参数,可以帮助进一步优化性能:
1、spark.shuffle.compress:是否启用 Shuffle 数据的压缩。默认值为 true。启用压缩可以减少网络传输的数据量,但会增加 CPU 负载。如果网络带宽是瓶颈,建议开启压缩;如果 CPU 是瓶颈,可以考虑关闭压缩。
2、spark.shuffle.spill:是否启用 Shuffle 数据的溢写(spill)。默认值为 true。启用溢写可以防止内存不足导致的任务失败,但会增加磁盘 I/O 开销。如果内存资源充足,可以考虑关闭溢写以提高性能。
3、spark.shuffle.spill.compress:是否启用 Shuffle 溢写数据的压缩。默认值为 true。启用压缩可以减少磁盘 I/O 开销,但会增加 CPU 负载。如果磁盘 I/O 是瓶颈,建议开启压缩;如果 CPU 是瓶颈,可以考虑关闭压缩。
4、spark.shuffle.memoryFraction:分配给 Shuffle 操作的内存比例。默认值为 0.66。根据实际内存情况调整该值,以平衡 Shuffle 操作和其他操作的内存需求。
5、spark.shuffle.manager.numPartitions:设置 Shuffle 操作的分区数。默认值根据数据量自动确定。合理设置分区数,避免过多或过少的分区。过多的分区会导致更多的网络通信,过少的分区可能导致数据倾斜。
通过调整这些参数,可以显著改善 Shuffle 阶段的性能,从而提升整个 Spark 应用的效率。
相关文章:

Spark的Shuffle过程
一、Shuffle 的作用是什么? Shuffle 操作可以理解为将集群中各个节点上的数据进行重新整理和分类的过程。这一概念源自 Hadoop 的 MapReduce 模型,Shuffle 是连接 Map 阶段和 Reduce 阶段的关键环节。在分布式计算中,每个计算节点通常只处理任…...

Java+Swing可视化图像处理软件
JavaSwing可视化图像处理软件 一、系统介绍二、功能展示1.图片裁剪2.图片缩放3.图片旋转4.图像灰度处理5.图像变形6.图像扭曲7.图像移动 三、系统实现1.ImageProcessing.java 四、其它1.其他系统实现2.获取源码 一、系统介绍 该系统实现了图片裁剪、缩放、旋转、图像灰度处理、…...

RDD转换算子:【mapValues、mapPartitions】
文章目录 1、mapValues算子功能语法举例 2、mapPartitions算子功能语法举例 1、mapValues算子 功能 针对二元组KV类型的RDD,对RDD中每个元素的Value进行map处理,结果放入一个新的RDD中 语法 def mapValues(self: RDD[Tuple[K,V]], f: (V) -> U) -…...

数组和指针的复杂关系
C语言中指针和数组的关系似乎很“纠结”,让人爱恨交织。本文试图帮助读者理清它们之间的复杂关系! 数组名的理解 数组元素在内存中是连续存放的,在C语言中,数组名有特殊的含义,它表示数组首元素的地址。因此…...

Linux系统I/O调优实例
文章目录 一 、资源限制二、测试硬盘速度: 一 、资源限制 限制用户资源配置文件:/etc/security/limits.conf [rootxuegod63 ~]# vim /etc/security/limits.conf 每行的格式: 用户名/用户组名 类型(软限制/硬限制) 选项 值 通常我们在服务器…...

记录Ubuntu OS的异常
PS: 参加过408改卷的ZJU ghsongzju.edu.cn 开启嘲讽: 你们知道408有多简单吗,操作系统真实水平自己知道就行~~ dmesg dmesg 是一个用于显示内核环形缓冲区消息的命令,主要用于查看系统启动时的消息、驱动程序加载信息、硬件错误…...

Vue 3 单元测试与E2E测试
在Vue 3应用的开发过程中,测试是一个至关重要的环节。它不仅能够确保代码的正确性,还能在后续的代码重构和升级过程中提供安全保障。本文将深入探讨Vue 3的单元测试(Unit Testing)和端到端测试(End-to-End Testing, E2…...

猫用空气净化器哪个牌子好?求除毛好、噪音小的宠物空气净化器!
换毛季家里孩子不省心,疯狂掉落的猫毛和空气中乱飞的浮毛可把我折磨死了。每天下班都要抽出时间来清理,不然这个家就不能要了。猫毛靠我自己可以打扫,浮毛还得借助宠物空气净化器这种专业工具。所以我最近着手做功课,打算入手一台…...

第十九课 Vue组件中的方法
Vue组件中的方法 组件中的方法拓展与实例对象中的方法拓展类似 <div id"app"><test></test> </div> <script>Vue.component(test, {template: <input type"button" value"这是个按钮组件" click"fun()…...

【JavaScript】V8,Nodejs 与浏览器
V8 V8 是一个 JavaScript engine,负责编译并执行 JavaScript 源代码,处理对象的内存分配,并对不再需要的对象进行垃圾收集。 V8 包含两个主要组件: Memory Heap:负责存储分配。 Call Stack:代码执行时&am…...

内存马浅析
之前在jianshu上写了很多博客,但是安全相关的最近很多都被锁了。所以准备陆陆续续转到csdn来。内存马前几年一直是个很热门的漏洞攻击手段,因为相对于落地的木马,无文件攻击的内存马隐蔽性、持久性更强,适用的漏洞场景也更多。 J…...

聊一聊Elasticsearch的基本原理与形成机制
1、搜索引擎的基本原理 通常搜索引擎包括:数据采集、文本分析、索引存储、搜索等模块,它们之间的协作流程如下图: 数据采集模块负责采集需要搜索的数据源。 文本分析模块是将结构化数据中的长文本切分成有实际意义的词,这样用户…...

应急救援无人车:用科技守护安全!
一、核心功能 快速进入危险区域: 救援无人车能够迅速进入地震、火灾、洪水等自然灾害或重大事故的现场,这些区域往往对人类救援人员构成极大威胁。 通过自主导航和环境感知技术,无人车能够避开危险区域,确保自身安全的同时&…...

详解Java之Spring MVC篇二
目录 获取Cookie/Session 理解Cookie 理解Session Cookie和Session的区别 获取Cookie 获取Session 获取Header 获取User-Agent 获取Cookie/Session 理解Cookie HTTP协议自身是“无状态”协议,但是在实际开发中,我们很多时候是需要知道请求之间的…...

flutter鸿蒙next 使用 InheritedWidget 实现跨 Widget 传递状态
在 Flutter 中,状态管理是开发过程中一个至关重要的部分。Flutter 提供了多种方式来实现组件间的状态传递,其中一种比较底层的方式是使用 InheritedWidget。虽然 InheritedWidget 主要用于将数据传递给其子树中的小部件,但它也是许多更高级状…...
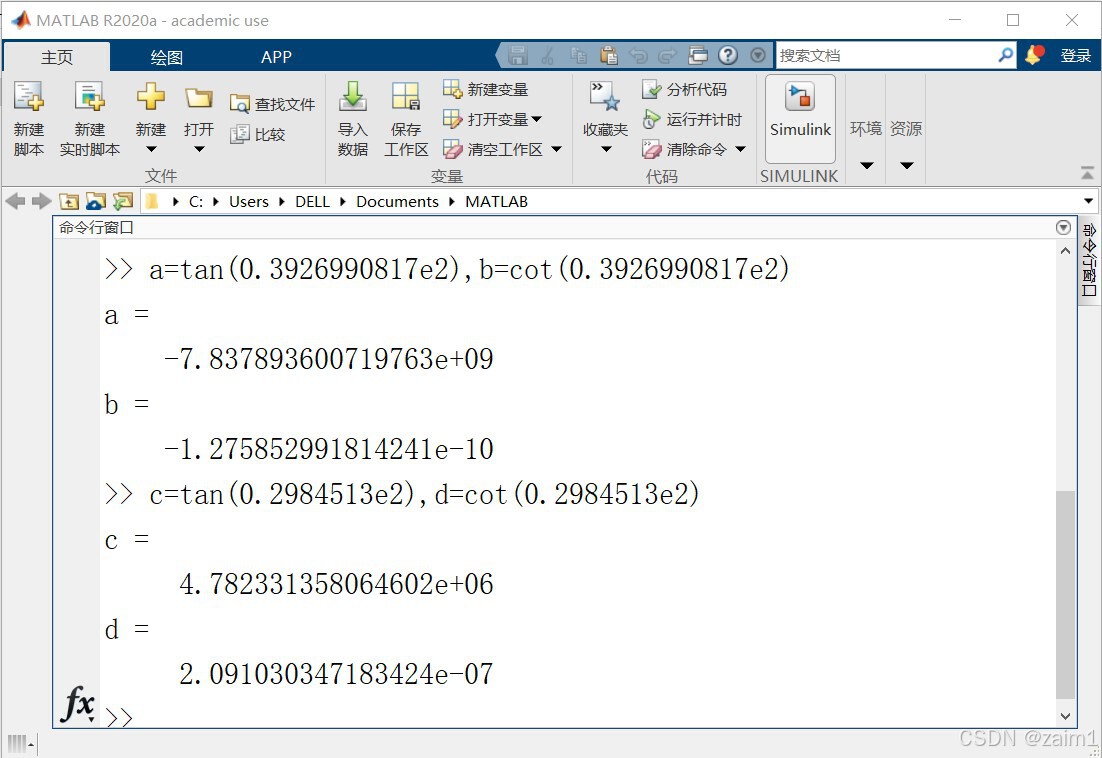
计算机的错误计算(一百四十六)
摘要 探讨 MATLAB 中正切函数 tan(x)、余切函数 cot(x) 关于 附近数的计算精度问题。 例1. 已知 计算 直接贴图吧: 另外,16位的正确值分别为 -0.7837941516239115e10、-0.1275845192169577e-9、0.4782331334117711e7 与 0.2091030357653982e-…...

国标GB28181视频平台EasyCVR私有化视频平台工地防盗视频监控系统方案
一、方案背景 在当代建筑施工领域,安全监管和防盗监控是保障工程顺利进行和资产安全的关键措施。随着科技进步,传统的监控系统已不足以应对现代工地的安全挑战。因此,基于国标GB28181视频平台EasyCVR的工地防盗视频监控系统应运而生…...

CUDA系统学习之一软件堆栈架构
一、CPU与GPU体系架构 计算单元分布 CPU: 少量强大的ALU(算术逻辑单元),通常4-8个核心GPU: 大量小型ALU,成百上千个计算核心特点:GPU更适合并行计算,可以同时处理大量数据控制单元(Control) CPU: 较大的控制单元,复杂的…...

SpringBoot项目中替换指定版本的tomcat
需求:项目使用的SpringBoot框架,因低版本的tomcat的有安全漏洞,根据安全要求需要将项目的tomcat版本升级到9.0.89以上版本。 解决办法: 1、在pom.xml中排除SpringBoot的默认tomcat依赖; <dependency><groupId…...

【5.10】指针算法-快慢指针将有序链表转二叉搜索树
一、题目 给定一个单链表,其中的 元素按升序排序 ,将其转换为 高度平衡的二叉搜索树 。 本题中,一个高度平衡二叉树是指一个二叉树每个节点的左右两个子树的高度差的绝对值不超过 1。 示例: 给定的有序链表: [ -10 , -3 , 0 , …...
)
告别泊车翻车!用Python手把手教你搭建二自由度车辆模型(附代码)
二自由度车辆模型实战:从原理到避坑指南 泊车时方向盘打满,仿真结果却和实际相差十万八千里?很多刚入行自动驾驶仿真的工程师都踩过这个坑。二自由度模型作为车辆动力学的基础工具,在高速巡航等小转角场景表现优异,但遇…...

书匠策AI:你的论文过不了关?http://www.shujiangce.com这套组合拳直接救场!
开篇一句话:2025年写论文,拼的不是文笔,是"过关能力"。 查重40%以上被打回,AIGC检测疑似度超标被标记——这两座大山压在每个毕业生头上。你是不是也经历过这种绝望:明明每个字都是自己敲的,系统…...

WorkshopDL神器秘籍:零门槛解锁Steam创意工坊的终极跨平台方案
WorkshopDL神器秘籍:零门槛解锁Steam创意工坊的终极跨平台方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是不是曾经在Epic商店买了《盖瑞的模组》ÿ…...

HarmonyOS 6 Chip 组件:不显示后缀图标使用文档
文章目录概述源码隐藏后缀图标核心实现原理1. 核心控制字段2. 双重隐藏条件3. 冗余回调说明组件配置解析总结概述 Chip组件后缀图标包含两类:系统默认关闭图标、自定义suffixIcon后缀图标。 通过组件配置项可统一关闭后缀图标展示,实现仅前缀图标文字的…...

ContentBranch+CFBranch混合电影推荐模型|全网独家复现,深度学习实战篇 引入双分支融合架构,兼顾内容特征与协同信号、助力冷启动缓解、数据稀疏性优化、推荐精度有效涨点
目录 一、前言:混合推荐模型的核心价值与行业痛点 二、模型核心原理(全网独家拆解,通俗易懂) 2.1 整体架构逻辑 2.2 ContentBranch(内容分支)原理详解 2.3 CFBranch(协同过滤分支)原理详解 2.4 特征融合与预测层原理 2.5 模型优势总结 三、环境搭建(全平台适配…...

Arty S7 FPGA开发板实战指南:从硬件解析到项目开发
1. 项目概述:为什么是Arty S7?如果你是一名嵌入式开发者、数字电路设计爱好者,或者正在寻找一块能兼顾学习、原型验证和低成本部署的FPGA开发板,那么Digilent的Arty S7系列很可能已经进入了你的视野。我最初接触这块板子ÿ…...
)
告别PS和蓝湖!用PxCook离线搞定前端切图与标注(附学成在线实战)
前端开发者的效率革命:PxCook离线工作流全解析 在快节奏的前端开发领域,效率工具的选择往往决定了项目交付的速度和质量。传统的工作流程中,设计师使用Photoshop完成设计稿后,前端开发者需要反复在PS中测量尺寸、提取颜色值、导出…...
)
Vue3项目里SignalR怎么用?一个聊天室Demo带你从配置到上线(.NET 6 + Vue 3)
Vue3与SignalR实战:构建高互动聊天室的全栈指南 引言 在当今追求实时交互体验的Web应用中,传统的HTTP请求-响应模式已无法满足即时通讯、实时通知等场景需求。SignalR作为ASP.NET Core生态中的实时通信库,通过自动选择最佳传输协议࿰…...

Sunshine游戏串流快速上手:3步搭建你的个人云游戏服务器
Sunshine游戏串流快速上手:3步搭建你的个人云游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上玩转PC游戏大作吗?Sunshine作为一…...
)
别再只会import了!用Python的importlib实现插件化架构(附完整代码)
用Python的importlib构建插件化架构:从理论到实战 在软件开发中,插件化架构是一种强大的设计模式,它允许应用程序在运行时动态加载和卸载功能模块。Python的importlib模块为实现这种架构提供了底层支持,远比简单的import语句强大得…...