彻底理解哈希表(HashTable)结构
目录
- 介绍
- 优缺点
- 概念
- 哈希函数
- 快速的计算
- 键类型
- 键转索引
- 霍纳法则
- 均匀的分布
- 哈希冲突
- 链地址法
- 开放地址法
- 线性探测
- 二次探测
- 再哈希法
- 扩容/缩容
- 实现哈希
- 创建哈希表
- 质数判断
- 哈希函数
- 插入&修改
- 获取数据
- 删除数据
- 扩容/缩容函数
- 全部代码
哈希表(Hash Table)又称散列表是一种数据结构,它使用键值对(Key-Value Pair)来存储数据,并通过哈希函数将键映射到数组的特定位置,从而实现高效的查找、插入和删除操作。哈希表通常被用在需要快速查找的场景,例如数据库索引、缓存和符号表等
介绍
哈希表本质上就是一个数组,只不过数组存放的是单一的数据,而哈希表中存放的是键值对(key - value pair)
-
在哈希表中,每个键(
key)与一个值(value)相关联,并且是通过键来查找值的 -
为了实现快速查找,哈希表会通过一个哈希函数将键转换为一个哈希值
-
再将这个哈希值转换成一个索引,用于存储或查找该键对应的值在数组中的位置

优缺点
-
优点:
-
查找速度快:在哈希函数设计合理的情况下,哈希表可以在常数时间内完成查找、插入和删除操作
-
实现简单:通过数组加链表或开放地址法可以轻松实现哈希表
-
-
缺点:
-
空间浪费:为了减少碰撞,哈希表的容量通常要比实际存储的元素数量多,造成了一定的空间浪费
-
不支持有序存储:哈希表中元素的顺序与插入顺序无关,不支持按序查找
-
哈希函数设计复杂:哈希函数的设计对哈希表的性能至关重要,设计不当的哈希函数会导致大量碰撞,影响性能
-
概念
下面是哈希表中的一些概念,后面也会具体学习:
-
存储结构: 哈希表通常由一个数组和一个哈希函数组成。数组的每个元素称为桶(
Bucket),它可以存储一个或多个键-值对 -
哈希化(
Hashing):是将输入数据(通常是任意长度的)通过哈希函数转换为固定长度的输出(数组范围内下标)的过程 -
哈希函数(
Hash Function) : 哈希函数将键转换成一个数组的索引(即一个整数) -
哈希冲突(
Hash Collision) : 当不同的键被哈希函数映射到相同的索引时,就发生了哈希冲突。常用的解决哈希冲突的方式有链地址法和开放地址法 -
装填因子(
Load Factor):哈希表中存储的元素数量与数组大小(总槽位数量)的比率-
哈希表的大小(槽位数)是固定的,但存储的元素项数可以超过槽位数
-
装填因子表示哈希表空间的利用效率。较高的装填因子意味着表中存储的元素较多,空间利用率高
-
当装填因子增加(接近于 1 或更高) 时,哈希表的查找效率可能降低,尤其是在使用开放地址法时,冲突处理需要更多的探测次数
-
使用链地址法时,装填因子的增加会导致链表长度增加,从而提高平均查找时间
-
在动态哈希表中,当装填因子超过某个阈值(如 0.75),通常会触发哈希表的扩容,以减少冲突和提高性能
-
如果装填因子过低,可能会导致缩容,以节省空间
-
理想的装填因子:
开放地址法:理想的装填因子通常低于 1,推荐在 0.5 到 0.75 之间,以平衡空间利用和查找效率
链地址法:装填因子可以超过 1,因为多个元素可以存储在同一个槽中。通常装填因子在 0.7 到 1.0 是较好的选择,但也可以更高,具体取决于链表长度对性能的影响
-
-
扩容(
Rehashing):当哈希表的装载因子超过设定值时,可能需要进行扩容。扩容通常包括创建一个更大的数组,并重新计算所有键的哈希值,以将它们映射到新数组中 -
缩容:缩容是指在数据量减少到一定程度时,减少哈希表的容量,以节省空间并提高内存利用效率
哈希函数
哈希函数将键转换成一个数组的索引(即一个整数)
设计好的哈希函数应该具备哪些优点呢?
-
快速的计算:哈希表的优势就在于效率,所以快速获取到对应的
hashCode非常重要 -
均匀的分布:哈希表中无论是链地址法还是开放地址法,当多个元素映射到同一个位置的时候,都会影响效率,优秀的哈希函数应该尽可能将元素映射到不同的位置,让元素在哈希表中均匀的分布
快速的计算
下面的三个模块知识都是为了理解计算问题,为了快速地获取对应的hashCode
键类型
归根结底哈希函数就是将键key转换为索引值,能作为键key的类型有很多数字、字符串、对象等等,我们这里主要是学习字符串作为键,因为哈希表的键通常被实现为字符串,主要是出于以下几个原因:
-
一致性:使用字符串作为键可以提供一致的方式来处理不同类型的键。即使是数字和其他类型,最终也会转换为字符串进行存储
-
哈希函数:哈希表使用哈希函数将键映射到数组的索引。字符串通常更易于处理,因为它们可以直接进行哈希运算,而其他类型(如对象)可能需要更多的处理步骤
-
易于比较:字符串具有明确的比较规则,这使得查找、插入和删除操作变得更简单和高效
-
空间效率:在许多语言中,字符串作为键的存储方式通常比对象或其他复杂类型更紧凑,减少了内存使用
-
灵活性:字符串可以表示各种信息,能够轻松适应不同的场景,例如数据库索引、字段名称等
键转索引
理解了键的类型,我们能想到就是哈希函数要将字符串转换为数字,那这有什么方法那?
-
方法一:将字符的
ASCII值相加,问题就是很多键最终的值可能都是一样的,比如was/tin/give/tend/moan/tick都是43 -
方法二:使用一个常数乘以键的每个字符的
ASCII值,得到的数字可以基本保证它的唯一性(下面解释),和别的单词重复率大大降低,问题是得到的值太大了,因为这个值是要作为索引的,创建这么大的数组是没有意义的-
其实我们平时使用的大于
10的数字,可以用一种幂的连乘来表示它的唯一性: 比如:7654 = 7*10³ + 6*10² + 5*10 + 4 -
单词也可以使用这种方案来表示:比如
cats = 3*27³ + 1*27² + 20*27 + 17= 60337,27是因为有27个字母
-
-
那么对于获取到的索引太大这个问题又出现了压缩算法,即把幂的连乘方案中得到的巨大整数范围压缩到可接受的数组范围中
-
如何压缩呢? 有一种简单的方法就是使用取余操作符,它的作用是得到一个数被另外一个数整除后的余数
-
举个例子理解:先来看一个小点的数字 范围压缩到一个小点的空间中,假设把从
0~199的数字,压缩为从0~9的数字 -
我们能想到当一个数被
10整除时,余数一定在0~9之间,比如13 % 10 = 3,157 % 10 = 7 -
同理数组的索引是有限的,比如从
0到n-1(其中n是可接受的数组长度),通过对进行取余操作,可以将它们限制在这个范围内 -
设
hash是通过哈希函数得到的键的哈希值,n是数组的长度,索引可以通过index = hash % n计算得出 -
在某些情况下,哈希值可能是负数。为了确保得到的索引是非负的,可以使用以下公式:
index = ((hash % n) + n) % n
-
霍纳法则
上面计算哈希值的时候使用的方式:cats = 3*27³ + 1*27² + 20*27 + 17= 60337,那么这种计算方式会进行几次乘法几次加法呢?
-
我们可以抽象成一个表达式:
a(n)x^n + a(n-1)x^(n-1) +... + a(1)x + a(0)-
乘法次数:
n + (n-1) +... + 1 = n(n + 1)/2 -
加法次数:
n次 -
时间复杂度:
O(N²)
-
-
通过变换可以得到一种快得多的算法,即解决这类求值问题的高效算法霍纳法则,在中国被称为秦九韶算法
-
Pn(x) = a(n)x^n + a(n-1)x^(n-1) + ... + a(1)x + a(0) = (((a(n)x + a(n−1))x + a(n−2))x + ⋯)x + a1)x + a0:

下面我们用具体数字理解一下:

-
乘法次数:
n次 -
加法次数:
n次 -
时间复杂度:从
O(N²)降到了O(N)
-
均匀的分布
-
在设计哈希表时,已经处理映射到相同下标值的情况:链地址法或者开放地址法(文章后面详细讲解)
-
但是无论哪种方案都是为了提高效率,最好的情况还是让数据在哈希表中均匀分布
-
因此需要在使用常量的地方,尽量使用质数
-
比如哈希表的长度和
N次幂的底数(我们之前使用的是27) -
为什么他们使用质数,会让哈希表分布更加均匀呢?
-
质数和其他数相乘的结果相比于其他数字更容易产生唯一性的结果,减少哈希冲突
-
Java中的HashMap的N次幂的底数选择的是31,比较常用的数是31或37,是经过长期观察分布结果得出的 -
举个例子:
如果使用
10作为模数(数组长度)取模,那么所有以0或5结尾的数,都会被映射到同一个槽位但如果使用质数
11,则可以有效地避免这种情况,因为11没有因数是2或5,它能使得键值分布更加均匀
-
哈希冲突
比如经过哈希化后demystify和melioration得到的下标相同,那怎么放入数组中那?就是当不同的键被哈希函数映射到相同的索引时,就发生了哈希冲突。常用的解决哈希冲突的方式有链地址法和开放地址法
链地址法
链地址法是一种比较常见的解决冲突的方案(也称为拉链法),
每个哈希表的槽(bucket)可以存储多个元素。当多个键被哈希到同一个索引时,链地址法会将这些元素存储在一个链表或其他数据结构中

-
链地址法的核心思想是将每个数组元素作为一个桶,桶内存储多个键值对。通常使用链表或数组来实现
-
一旦发现重复,将重复的元素插入到链表的首端或者末端即可
-
当查询时先根据哈希化后的下标值找到对应的位置,再取出链表,依次查询找寻找的数据
-
效率:

-
哈希表中共有
N个数据项,有arraySize个槽位,每个槽位中的链表长度大致相同,怎么计算每个链表的平均长度 -
假设
arraySize = 10(哈希表中有10个槽位),N = 50(哈希表中有50个数据项),平均每个链表中大约有5个数据项(通过将总的数据项数N除以槽位数arraySize来得到,公式就是装填因子loadFactor) -
当用链地址法实现哈希表时,查找一个元素的过程分为两部分:
计算哈希值并定位到槽位:这一步是一个常数时间操作,通常是
1次操作,不依赖链表的长度遍历链表查找元素:如果多个元素在同一个槽位上,哈希表会在这个槽位的链表中查找元素。查找的平均次数是链表长度的一半,通常是
loadFactor / 2因此成功可能只需要查找链表的一半即可:
1 + loadFactor/2,不成功可能需要将整个链表查询完才知道不成功:1 + loadFactor -
链地址法相对来说效率是好于开放地址法的,所以在真实开发中使用链地址法的情况较多
-
它不会因为添加了某元素后性能急剧下降,比如在
Java的HashMap中使用的就是链地址法
-
开放地址法
开放地址法的主要工作方式是当发生哈希冲突时,寻找数组中的下一个空槽来存储冲突的元素,比如下图中插入38时应该在05的位置,但被49占了,那么38应该放在哪个位置,有三种探索空槽的方式:线性探测、二次探测和再哈希法

线性探测
线性探测(Linear Probing)是每次发生冲突时,检查下一个空白的槽index = (hashFunc(key) + i) % tableSize; // i 是冲突次数

-
插入
38时:-
经过哈希化得到的
index = 5,但是在插入的时候,发现该位置已经有了49 -
线性探测就是从
index + 1位置开始一点点查找空的位置来放置38
-
-
查询
38时:-
首先经过哈希化得到
index = 5,看5的位置结果和查询的数值是否相同 -
相同那么就直接返回,不相同就线性查找,从
index + 1位置开始查找和38一样的 -
注意:查询过程有一个约定,就是查询到空位置,就停止
-
-
删除
38时:-
删除操作一个数据项时,不可以将这个位置下标的内容设置为
null,为什么呢? -
因为将它设置为
null可能会影响之后查询其他操作 -
通常删除一个位置的数据项时,可以将它进行特殊处理(比如设置为
-1) -
当看到
-1位置的数据项时,就知道查询时要继续查询,但是插入时这个位置可以放置数据
-
-
效率:公式来自于
Knuth(算法分析领域的专家,现代计算机的先驱人物)
-
问题:
-
线性有一个比较严重的问题就是聚集
-
比如在没有任何数据的时候,插入的是
22-23-24-25-26,那么意味着下标值:0-1-2-3-4的位置都有元素,这种一连串填充单元就叫做聚集 -
聚集会影响哈希表的性能,无论是插入/查询/删除都会影响,比如我们插入一个38,会发现连续的单元都不允许放置数据,并且在这个过程中需要探索多次
-
二次探测
二次探测(Quadratic Probing)根据冲突次数的平方来确定下一个槽的位置 index = (hashFunc(key) + i^2) % tableSize

-
优化线性问题:
-
线性探测可以看成是步长为
1的探测,比如从下标值x开始,那么线性测试就是x+1,x+2,x+3依次探测 -
二次探测对步长做了优化,比如从下标值
x开始x+1²,x+2²,x+3²,这样就可以一次性探测比较长的距离,比避免那些聚集带来的影响
-
-
效率:

-
问题:
-
二次探测依然存在问题,比如连续插入的是
32-112-82-2-192,那么依次累加的时候步长的相同的 -
也就是这种情况下会造成步长不一样的一种聚集,还是会影响效率
-
再哈希法
再哈希(Double Hashing)使用第二个哈希函数计算步长,确定下一个槽的位置 index = (hashFunc1(key) + i * (constant - (hashFunc2(key) % constant))) % tableSize

-
优化二次探测问题:
-
二次探测的算法产生的探测序列步长是固定的:
1-4-9-16依此类推 -
把键用另外一个哈希函数,再做一次哈希化,用这次哈希化的结果作为步长
-
第二次哈希化需要具备如下特点:
和第一个哈希函数不同(不要再使用上一次的哈希函数了, 不然结果还是原来的位置)
不能输出为
0(否则将没有步长,每次探测都是原地踏步,算法就进入了死循环)计算机专家已经设计出一种工作很好的哈希函数:
stepSize = constant - (hanshFunc(key) % constant),constant是质数,且小于数组的容量
-
-
效率:

扩容/缩容
-
为什么扩容/缩容?
-
随着数据量的增多,每一个
index对应的bucket会越来越长,也就造成效率的降低,所以在合适的情况对数组进行扩容,比如扩容两倍 -
当哈希表的装填因子(元素数量与哈希表容量的比值)低于某个阈值时,会考虑缩容以节省空间并提高内存利用效率
-
-
如何进行扩容/缩容?
-
扩容可以简单的将容量增大两倍,但是这种情况下所有的数据项一定要同时进行修改(重新调用哈希函数,来获取到不同的位置)
-
比如
hashCode = 12的数据项,在arraySize = 8的时候放index = 4的位置,在arraySize = 16的时候放index = 12的位置 -
缩容时通常将哈希表容量减小为当前容量的一半,并重新计算并分配所有现有元素的位置
-
这是一个耗时的过程,但是如果数组需要扩容,那么这个过程是必要的
-
-
什么情况下扩容/缩容?
-
比较常见的情况是
loadFactor > 0.75的时候进行扩容,比如Java的哈希表就是在装填因子大于0.75的时候,对哈希表进行扩容 -
通常会设置一个下限装填因子,比如
0.25,低于此值时触发缩容,但也要避免过度缩容:通常会设置一个较小的、合理的最小容量,比如7或8,以保证哈希表即使在元素很少时也保持一定的容量,从而避免频繁地扩容和缩容
-
实现哈希
上面学了那么多的理论和公式,我们要用代码自己实现一个哈希表,在实现之前我们先理清楚实现的方案和结构,这样当我们实现操作方法时才能更清晰的知道要做什么
-
方案使用链地址法处理冲突
-
链地址法的核心思想是将每个数组元素作为一个桶,桶内存储多个键值对
-
通常使用链表或数组来实现,我们使用数组实现,因为数组是
js/ts已经提供给我们的数据结构(想用链表后面自己练习吧,需要自己再实现链表结构,参考文章https://blog.csdn.net/qq_45730399/article/details/143408205
-
-
用上面方案实现的存储结构如下:
[[[key1, value1], [key2, value2]], [[key3, value3]]]
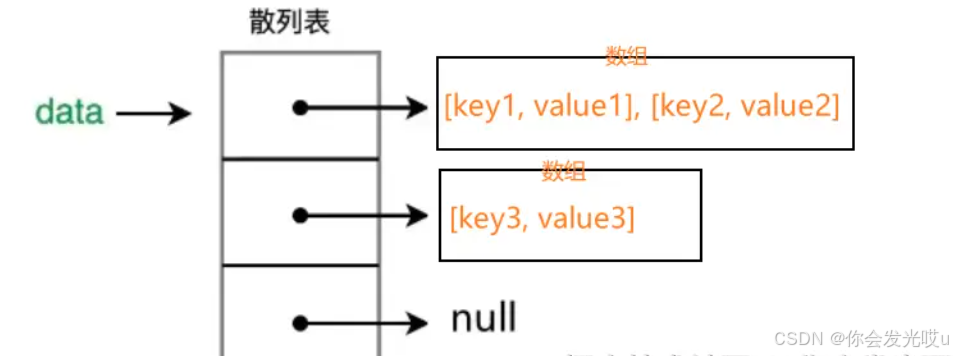
-
哈希表的桶中每个元素还是一个数组桶,这个数组桶中放的是多个键值对元组
[key1, value1],为什么使用数组包裹键值对,而不是对象{key1: value1}?键值对元组数组:
[['key1', 'value1'], ['key2', 'value2']]- 轻松处理多个相同键名对应不同值的情况
- 访问时可以直接通过遍历数组查找特定键的元组,逻辑清晰
- 比如在
get('name')时,只需查找数组中第一项等于'name'的元组,取第二项作为值
对象数组:
[{'key1': 'value1'}, {'key2': 'value2'}]-
对象中每个键只能出现一次,意味着如果需要存储相同键名的不同值
-
查找某个键的值时,需要遍历整个数组并访问对象的属性
-
需要额外的逻辑来查找特定的键,因为每个对象的结构不一致,效率较低
-
创建哈希表
定义三个属性:
storage:作为数组,数组中存放相关的元素count:表示当前已经存在了多少数据length:用于标记数组中一共可以存放多少个元素
class HashTable<T = any> {storage: [string, T][][] = []; // [[[key1, value1], [key2, value2]], [[key3, value3]]]private count: number = 0; // 已经存在了多少数据private length: number = 11; // 数组中一共可以存放多少个元素
}
const hashTable = new HashTable()
质数判断
上面理论知识我们也解析了为什么要用质数,既然要用质数就需要判断一个数是不是质数,质数表示大于1的自然数中,只能被1和自己整除的数
-
简单实现:
isPrime(num: number): boolean {for (let i = 2; i < num; i++) {if (num % i === 0) return false;}return true; } -
高效实现:
- 只需要检查它是否能被小于等于其平方根的数整除,这是因为如果
num能被一个大于其平方根的数整除,那么另一个因数必定小于其平方根

isPrime(num: number): boolean {const sqrt = Math.sqrt(num)for (let i = 2; i <= sqrt; i++) {if (num % i === 0) return false}return true } - 只需要检查它是否能被小于等于其平方根的数整除,这是因为如果
哈希函数
hashFunc(key: string): number {let code = 0;for (let i = 1; i <= key.length; i++) {code = 31 * code + key.charCodeAt(i); // 使用霍纳法则}return code % this.length;
}
插入&修改
put(key: string, value: T): void {// 1.根据key获取数组中对应的索引值const index = this.hashFunc(key);// 2.取出索引值对应位置的数组(桶)let bucket = this.storage[index];// 3.判断bucket是否有值if (!bucket) {bucket = [];this.storage[index] = bucket;}// 4.确定已经有一个数组了, 但是数组中是否已经存在key是不确定的let isUpdate = false;for (let i = 0; i < bucket.length; i++) {if (bucket[i][0] === key) {bucket[i][1] = value;isUpdate = true;break;}}if (!isUpdate) {bucket.push([key, value]);this.count++;}
}
获取数据
get(key: string): T | undefined {// 1.根据key获取索引值indexconst index = this.hashFunc(key);// 2.获取bucket(桶)const bucket = this.storage[index];if (!bucket) return undefined;// 3.对bucket进行遍历for (let i = 0; i < bucket.length; i++) {if (bucket[i][0] === key) return bucket[i][1];}return undefined;
}
删除数据
delete(key: string): T | null {// 1.根据key获取索引值indexconst index = this.hashFunc(key);// 2.获取bucket(桶)const bucket = this.storage[index];if (!bucket) return null;// 2.删除key项for (let i = 0; i < bucket.length; i++) {let tuple = bucket[i];if (tuple[0] === key) {bucket.splice(i, 1);this.count--;return tuple[1];}}return null;
}
扩容/缩容函数
resize(): void {// 装填因子大于0.75时扩容length两倍const isReduce = this.count / this.length > 0.75;const isExpand = this.count / this.length < 0.25;const newLength = isReduce? this.getPrime(this.length * 2) : isExpand? this.getPrime(this.length / 2): this.length;if(newLength === this.length) return// 扩容/缩容后清空数据并再次循环数据重新put进哈希表let oldStorage = this.storage;this.storage = [];this.count = 0;this.length = newLength;oldStorage.forEach((bucket) => {if (!bucket) return;bucket.forEach((f) => {this.put(f[0], f[1]);});});
}
全部代码
class HashTable<T = any> {storage: [string, T][][] = []; // [[[key1, value1], [key2, value2]], [[key3, value3]]]private count: number = 0; // 已经存在了多少数据private length: number = 7; // 数组中一共可以存放多少个元素// 判断质数private isPrime(num: number): boolean {const sqrt = Math.floor(Math.sqrt(num));for (let i = 2; i <= sqrt; i++) {if (num % i === 0) return false;}return true;}// 获取质数private getPrime(num: number): number {let prime = Math.floor(num);while (!this.isPrime(prime)) {prime++;}return prime;}// 哈希函数private hashFunc(key: string): number {let code = 0;for (let i = 0; i < key.length; i++) {code = 31 * code + key.charCodeAt(i); // 使用霍纳法则}return code % this.length;}// 扩容/缩容private resize(newLength: number): void {// 扩容/缩容后清空数据并再次循环数据重新put进哈希表let oldStorage = this.storage;this.storage = [];this.count = 0;this.length = this.getPrime(newLength) < 7 ? 7 : this.getPrime(newLength);oldStorage.forEach((bucket) => {if (!bucket) return;bucket.forEach((f) => {this.put(f[0], f[1]);});});}// 插入/修改数据put(key: string, value: T): void {// 1.根据key获取数组中对应的索引值const index = this.hashFunc(key);// 2.取出索引值对应位置的数组(桶)let bucket = this.storage[index];// 3.判断bucket是否有值if (!bucket) {bucket = [];this.storage[index] = bucket;}// 4.确定已经有一个数组了, 但是数组中是否已经存在key是不确定的let isUpdate = false;for (let i = 0; i < bucket.length; i++) {if (bucket[i][0] === key) {bucket[i][1] = value;isUpdate = true;break;}}if (!isUpdate) {bucket.push([key, value]);this.count++;if (this.count / this.length > 0.75) {this.resize(this.length * 2); // 扩容处理}}}// 获取数据get(key: string): T | null {// 1.根据key获取索引值indexconst index = this.hashFunc(key);// 2.获取bucket(桶)const bucket = this.storage[index];if (!bucket) return null;// 3.对bucket进行遍历for (let i = 0; i < bucket.length; i++) {if (bucket[i][0] === key) return bucket[i][1];}return null;}// 删除数据delete(key: string): T | null {// 1.根据key获取索引值indexconst index = this.hashFunc(key);// 2.获取bucket(桶)const bucket = this.storage[index];if (!bucket) return null;// 2.删除key项for (let i = 0; i < bucket.length; i++) {let tuple = bucket[i];if (tuple[0] === key) {bucket.splice(i, 1);this.count--;if (this.length > 7 && this.count / this.length < 0.25) {this.resize(this.length / 2); // 缩容处理}return tuple[1];}}return null;}
}const hashTable = new HashTable();
hashTable.put("aaa", 100);
hashTable.put("aaa", 200);
hashTable.put("bbb", 300);
hashTable.put("ccc", 400);
hashTable.put("abc", 111);
hashTable.put("cba", 222);
console.log(111, hashTable.storage);
/*
111 [[ [ 'bbb', 300 ] ],[ [ 'aaa', 200 ], [ 'cba', 222 ] ],<4 empty items>,[ [ 'ccc', 400 ], [ 'abc', 111 ] ]]
*/// 如果loadFactor > 0.75进行扩容操作
hashTable.put("nba", 333);
hashTable.put("mba", 444);
console.log(222, hashTable.storage);
/* 222 [<2 empty items>,[ [ 'mba', 444 ] ],<3 empty items>,[ [ 'bbb', 300 ] ],<4 empty items>,[ [ 'nba', 333 ] ],<1 empty item>,[ [ 'ccc', 400 ] ],[ [ 'cba', 222 ] ],[ [ 'abc', 111 ] ],[ [ 'aaa', 200 ] ]]
*/hashTable.delete("nba");
hashTable.delete("mba");
hashTable.delete("abc");
hashTable.delete("cba");
hashTable.delete("aaa");
console.log(333, hashTable.storage); // 333 [ [ [ 'bbb', 300 ] ], <5 empty items>, [ [ 'ccc', 400 ] ] ]
相关文章:
彻底理解哈希表(HashTable)结构
目录 介绍优缺点概念哈希函数快速的计算键类型键转索引霍纳法则 均匀的分布 哈希冲突链地址法开放地址法线性探测二次探测再哈希法 扩容/缩容实现哈希创建哈希表质数判断哈希函数插入&修改获取数据删除数据扩容/缩容函数全部代码 哈希表(Hash Table)…...

微信小程序的汽车维修预约管理系统
文章目录 项目介绍具体实现截图技术介绍mvc设计模式小程序框架以及目录结构介绍错误处理和异常处理java类核心代码部分展示详细视频演示源码获取 项目介绍 系统功能简述 前台用于实现用户在页面上的各种操作,同时在个人中心显示各种操作所产生的记录:后…...
)
LeetCode:3255. 长度为 K 的子数组的能量值 II(模拟 Java)
目录 3255. 长度为 K 的子数组的能量值 II 题目描述: 实现代码与解析: 模拟 原理思路: 3255. 长度为 K 的子数组的能量值 II 题目描述: 给你一个长度为 n 的整数数组 nums 和一个正整数 k 。 一个数组的 能量值 定义为&am…...

深入了解逻辑回归:机器学习中的经典算法
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
)
软件测试基础十三(python 函数)
函数 1. 函数的意义 代码复用 提高效率:Python中的函数允许将一段可重复使用的代码封装起来。例如,在一个数据分析项目中,可能需要多次计算一组数据的平均值。可以将计算平均值的代码定义为一个函数: def calculate_average(nu…...

计算机网络——HTTP篇
基础篇 IOS七层网络模型 TCP/IP四层模型? 应⽤层:位于传输层之上,主要提供两个终端设备上的应⽤程序之间的通信,它定义了信息交换的格式,消息会交给下⼀层传输层来传输。 传输层的主要任务就是负责向两台设备进程之间…...

信息化运维方案,实施方案,开发方案,信息中心安全运维资料(软件资料word)
1 编制目的 2 系统运行维护 2.1 系统运维内容 2.2 日常运行维护方案 2.2.1 日常巡检 2.2.2 状态监控 2.2.3 系统优化 2.2.4 软件系统问题处理及升级 2.2.5 系统数据库管理维护 2.2.6 灾难恢复 2.3 应急运行维护方案 2.3.1 启动应急流程 2.3.2 成立应急小组 2.3.3 应急处理过程 …...
自动化工具 Gulp
自动化工具 gulp 摘要 概念:gulp用于自动化开发流程。 理解:我们只需要编写任务,然后gulp帮我们执行 核心概念: 任务:通过定义不同的任务来组织你的构建流程。 管道:通过管道方式将文件从一个插件传递…...

css实现div被图片撑开
固定好盒子的宽度,高度随传过来的图片大小决定 <div class"tab-con"> <img:src"concertInfo.detail"alt""> </div>.tab-con {margin-bottom: 20px;width: 700px;img {width: 700px;height: auto;object-fit: cont…...
)
Power Pivot、Power BI 和 SQL Server Analysis Services 的公式语言:DAX(数据分析表达式)
DAX(Data Analysis Expressions)是一种用于 Power Pivot、Power BI 和 SQL Server Analysis Services 的公式语言,旨在帮助用户进行数据建模和复杂计算。DAX 的设计初衷是使数据分析变得简单而高效,特别是在处理数据模型中的表关系…...

大模型应用编排工具Dify二开之工具和模型页面改造
1.前言 简要介绍下 dify: 一款可以对接市面上主流大模型的任务编排工具,可以通过拖拽形式进行编排形成解决某些业务场景的大模型应用。 背景信息: 环境:dify-0.8.3、docker-21 最近笔者在做 dify的私有化部署和二次…...

Pytorch用BERT对CoLA、新闻组文本数据集自然语言处理NLP:主题分类建模微调可视化分析...
原文链接:https://tecdat.cn/?p38181 自然语言处理(NLP)领域在近年来发展迅猛,尤其是预训练模型的出现带来了重大变革。其中,BERT 模型凭借其卓越性能备受瞩目。然而,对于许多研究者而言,如何高…...

LightGBM-GPU不能装在WSL,能装在windows上
这是一篇经验总结文章,注重思路,忽略细节。 1.起因 用多个机器学习方法训练模型,比较性能,发现Light GBM方法获得的性能明显更高,但问题是在CPU上训练的速度特别特别慢,需要用GPU训练。 2.开始装LightGB…...

工业相机常用功能之白平衡及C++代码分享
目录 1、白平衡的概念解析 2、相机白平衡参数及操作 2.1 相机白平衡参数 2.2 自动白平衡操作 2.3 手动白平衡操作流程 3、C++ 代码从XML读取参数及设置相机参数 3.1 读取XML 3.2 C++代码,从XML读取参数 3.3 给相机设置参数 1、白平衡的概念解析 白平衡(White Balance)…...

Foundry 单元测试
安装 Foundry 如果你还没有安装 Foundry,请按照此处的说明进行操作:Foundry 安装 Foundry Hello World 只需运行以下命令,它将为你设置环境,创建测试并运行它们。(当然,这假设你已经安装了 Foundry&…...

idea database连接数据库后看不到表解决方法、格式化sql快捷键
最下面那个勾选上就可以了 或 格式化sql快捷键: 先选中, 使用快捷键格式化 SQL: Windows/Linux: Ctrl Alt L macOS: Cmd Alt L...

【数学二】线性代数-向量-向量组的秩、矩阵得秩
考试要求 1、理解 n n n维向量、向量的线性组合与线性表示的概念. 2、理解向量组线性相关、线性无关的概念,掌握向量组线性相关、线性无关的有关性质及判别法. 3、了解向量组的极大线性无关组和向量组的秩的概念,会求向量组的极大线性无关组及秩. 4、了解向量组等价的概念,…...

ABAP开发-内存管理
系列文章目录 文章目录 系列文章目录前言一、概述二、程序间调用三、外部会话和内部会话四、SAP内存与ABAP内存五、实例总结 前言 一、概述 内存是程序之间为了传递数据而使用的共享存储空间,在每个程序里使用的内存有SAP内存和ABAP内存 SAP内存分类 SAP内存 主会…...

【Ajax】跨域
文章目录 1 同源策略1.1 index.html1.2 server.js 2 如何解决跨域2.1 JSONP2.1.1 JSONP 原理2.1.2 JSONP 实践2.1.3 jQuery 中的 JSONP 2.2 CORS2.2.1 CORS实践 3 server.js 1 同源策略 同源策略(Same-Origin Policy)最早由 Netscape 公司提出,是浏览器的一种安全策…...

yii 常用一些调用
yii 常用一些调用 (增加中) 调用YII框架中 jquery:Yii::app()->clientScript->registerCoreScript(‘jquery’); framework/web/js/source的js,其中registerCoreScript key调用的文件在framework/web/js/packages.php列表中可以查看 在view中得到当前contro…...

大数据之安装zookeeper
下载 官方下载地址:https://archive.apache.org/dist/zookeeper/ 解压 tar -zxvf zookeeper-3.4.13.tar.gz 创建目录 日志目录和数据目录 cd zookeeper-3.4.13/ # 数据目录 mkdir data # 数据目录的目录 mkdir data-log # 日志目录 mkdir logs 修改配置 日志…...

SQL-lab通关教程
Less-1单引号型完整注入流程打开靶场第一关你会看到如下图所示界面,由为方便后续靶场的payload输入查看,我这里了将直接利用hackbar进行sql注入测试。第1步:确认闭合方式payload:http://127.0.0.1:8080/Less-1/?id1分析ÿ…...

汽车软件测试实战指南:从MiL到HiL的测试体系与工程实践
1. 汽车软件测试:从术语迷雾到实战地图 干了十几年嵌入式,从消费电子一路干到汽车电子,最深的感触就是: “隔行如隔山” ,这话在汽车软件测试领域体现得淋漓尽致。刚入行那会儿,听到同事讨论MiL、SiL、Hi…...

高炉智变:12期实战带你玩转工业AI落地~系列文章11:可解释AI实践:SHAP+LIME打开高炉模型的“黑箱“
🎯 高炉智变11|可解释AI实践:SHAPLIME打开高炉模型的"黑箱" 📅 本文目录 一、前言:AI可解释性的重要性二、SHAP可解释性框架三、LIME局部解释方法四、高炉模型可解释性实践五、实战代码实现六、总结与预告 一…...
)
告别卡顿!手把手教你用UltraISO给老旧笔记本装上OpenEuler 22.03 LTS(保姆级BIOS设置指南)
告别卡顿!手把手教你用UltraISO给老旧笔记本装上OpenEuler 22.03 LTS(保姆级BIOS设置指南) 老旧笔记本性能跟不上现代操作系统?别急着淘汰它们!OpenEuler作为一款轻量级Linux发行版,特别适合为老设备注入新…...

Linux串口编程进阶:深入termios2结构体,搞定CH340/FTDI各种转接器的非标准波特率
Linux串口编程实战:破解CH340/FTDI非标准波特率适配难题 当你在工业物联网项目中尝试将某个9600bps的设备升级到115200bps时,可能会发现某些USB转串口适配器死活不配合——明明代码正确,波特率却始终无法生效。这不是你的错,而是…...

前端工程化实战:代码规范、兼容性、调试与项目整合
前言学完 HTML 和 CSS 的核心知识后,如何写出规范、可维护、兼容性好的代码,并高效地调试和构建项目,是很多初学者的薄弱环节。本篇整合 代码书写规范、浏览器兼容性处理、Chrome DevTools 调试技巧、项目目录结构 以及 前端学习路径 等实用技…...

AI Agent到底是什么
AI Agent 到底是什么?看完我悟了 今天看了几个产品,跟 AI 聊了聊,突然对 AI Agent 有了个很朴素的理解。AI Agent 不神秘 很多人觉得 AI Agent 是什么高深的东西,只有大厂才能搞。 但我现在的理解就一句话:❝ 「AI Age…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

精准识别胡椒成熟度!YOLO-AVCA-CBAMNet 让智慧农业更高效
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 https://pmc.ncbi.nlm.nih.gov/articles/PMC12830288/ 计算机视觉研究院专栏 Column of Computer Vision Institute 本文提出YOLO-…...