【数据结构】哈希/散列表
目录
- 一、哈希表的概念
- 二、哈希冲突
- 2.1 冲突概念
- 2.2 冲突避免
- 2.2.1 方式一哈希函数设计
- 2.2.2 方式二负载因子调节
- 2.3 冲突解决
- 2.3.1 闭散列
- 2.3.2 开散列(哈希桶)
- 2.4 性能分析
- 三、实现简单hash桶
- 3.1 内部类与成员变量
- 3.2 插入
- 3.3 获取value值
- 3.4 总代码
- 四、与Java集合类的关系
- 五、练习

一、哈希表的概念
不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
哈希方法:
- 插入元素:
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。 - 搜索元素:
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若
关键码相等,则搜索成功。
哈希函数:哈希方法中使用的转换函数。
哈希表(HashTable):构造出来的结构。
举个栗子:
存储数据关键字为{1,4,5,6,7,9}的数据使用哈希表,我们设置哈希函数为:关键字%容量。因此在得到每个关键字时对容量取余,得到存储下标,放入哈希表得到以下结构。
这样下次搜素时也只需要对关键字取余找到对应下标就搜到了。

二、哈希冲突
2.1 冲突概念
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
例如:在上面的例子中如果在插入关键字为44的值就与4在一个下标,就发生了哈希冲突。
同义词:把具有不同关键码而具有相同哈希地址的数据元素。
2.2 冲突避免
我们哈希表底层数组的容量往往是小于实际要存储的关键字的数量的,这就导致冲突的发生是必然的,但我们能做到尽量的降低冲突发生率。
2.2.1 方式一哈希函数设计
这种方法一般用不到,因为哈希函数一般不由小卡拉米来定制。
满足以下三个条件来设计:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1
之间; - 哈希函数计算出来的地址能均匀分布在整个空间中;
- 哈希函数应该比较简单;
常见哈希函数:
- 直接定制法:
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀;
缺点:需要事先知道关键字的分布情况 ;
使用场景:适合查找比较小且连续的情况。 - 除留余数法:
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。 - 平方取中法:
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址。
使用场景:不知道关键字的分布,而位数又不是很大的情况。 - 折叠法:
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
使用场景:事先不需要知道关键字的分布,适合关键字位数比较多的情况。 - 随机数法:
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
使用场景:应用于关键字长度不等时采用此法。 - 数学分析法:
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某
些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据
散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。
使用场景:处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均
匀的情况。
2.2.2 方式二负载因子调节
负载因子:就是 哈希表中的元素个数 与 哈希表的长度 的比值。
负载因子与冲突发生率的关系图:

由图可知,负载因子大小与与冲突率呈正相关。
所以我们可以通过降低负载因子来降低冲突率。Java中的负载因子设置的是0.75。
2.3 冲突解决
2.3.1 闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
找下一个位置的两种方法:
- 线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。使用这种方式缺点就是产生冲突的数据容易堆积在一块。
而且采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。线性探测采用标记的伪删除法来删除一个元素。 - 二次探测:在设计一个函数来表示下一个位置,找下一个空位置的方法为:Hi = (H0 + i^2 )% m, 或者:Hi = ( H0 - i^2 )% m。其中:i = 1,2,3…, 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
2.3.2 开散列(哈希桶)
开散列法:又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。就相当于使用数组+链表的形式。

冲突严重时的解决方式:
- 每个桶的背后是另一个哈希表;
- 每个桶的背后是一棵搜索树(Java中的HashMap集合类就是每个桶后面是一颗红黑树)。
2.4 性能分析
虽然哈希表一直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数 ,所以,通常意义下,我们认为哈希表的插入/删除/查找时间复杂度是O(1) 。
三、实现简单hash桶
我们自己实现一个简单的hash桶即HashBuck。
先写key与value都是int 类型,再类比写出泛型参数类型。
3.1 内部类与成员变量
hash桶的结构是数组加链表的形式,
- 所以我们内部类要构造一个链表,
- 成员要用实现链表数组,我们在这初始化长度为10。
- 在使用一个usedSize变量记录一下节点的个数,以便调控负载因子。
- 使用一个常量来表示负载因子最大值
//内部类,链表static class Node {public int key;public int value;public Node next;public Node(int key, int value) {this.key = key;this.value = value;}}//初始数组public Node[] array = new Node[10];//使用长度public int usedSize;//负载因子最大值private static final double DEFAULT_LOAD_FACTOR = 0.75f;
泛型参数版本:
static class Node <K,V>{public K key;public V value;Node<K,V> next;public Node(K key, V value) {this.key = key;this.value = value;}}//初始数组public Node<K,V>[] array = (Node<K,V>[])new Node[10];//使用长度public int usedSize;//负载因子最大值private static final double DEFAULT_LOAD_FACTOR = 0.75f;
3.2 插入
实现put方法,我们插入节点的时候,
- 先使用hash函数(key % array.length)找到当前节点该插入的下标。
- 然后再遍历这里面的节点,如果其中关键字key已经存在,我们就更新一下value即可;
- 没有key关键字的节点,我们就尾插进当前节点,
- 要判断当前是否是空,所以我们使用prev,来指向cur的前一个节点,如果prev为空,就说明当前的下标中没有节点。
- 然后节点数量usedSize加1。
- 我们节点个数加一之后,我们就要考虑负载因子是否超了,如果负载因子超了,就扩容。
//插入元素public void put(int key, int value) {int index = key % array.length;Node cur = array[index];Node prev = cur;while(cur != null) {//关键字key已经存在if(cur.key == key) {cur.value = value;return;}prev = cur;cur = cur.next;}//关键字key不存在if(prev == null) {array[index] = new Node(key,value);}else {prev.next = new Node(key,value);}this.usedSize++;//判断负载因子,是否扩容if( loadFactor() >= DEFAULT_LOAD_FACTOR) {resize();}}//计算负载因子private double loadFactor() {return 1.0*usedSize / array.length;}
泛型参数版本:
//插入元素public void put(K key, V value) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];Node<K,V> pre = cur;while(cur != null) {//关键字key已经存在if(cur.key.equals(key)) {cur.value = value;}pre = cur;cur = cur.next;}//关键字key不存在if(pre == null) {array[index] = new Node<>(key,value);} else {pre.next = new Node<>(key,value);}this.usedSize++;//判断负载因子,是否扩容if(loadFactor() >= DEFAULT_LOAD_FACTOR) {resize();}}//计算负载因子private double loadFactor() {return 1.0*usedSize / array.length;}
扩容:
- 在扩容中由于hash函数的存在,我们不能直接使用copyOf直接扩容。
- 由于数组长度变了,所以每个节点该插入的位置也要变化。例如:在数组长度为10时,关键字14和4的节点都要在4下标,而当数组长度变为20的时候,关键字14和4的节点分别在14和4下标。
- 所以我们要遍历原数组中的每一个节点,将其插入新数组中。
//扩容private void resize() {Node[] newArray = new Node[array.length * 2];//遍历每一个节点for(int i = 0; i < array.length; i++) {Node cur = array[i];//插入while (cur != null) {int index = cur.key % newArray.length;//保存下一个节点Node newCur = cur.next;//插入新数组cur.next = newArray[index];newArray[index] = cur;//下一个节点cur = newCur;}}this.array = newArray;}
泛型参数版本:
//扩容private void resize() {Node<K,V>[] newArray = (Node<K, V>[]) new Node[array.length * 2];//遍历每一个节点for(int i = 0; i < array.length; i++) {Node<K,V> cur = array[i];//插入while (cur != null) {int index = cur.key.hashCode() % newArray.length;//保存下一个节点Node<K,V> newCur = cur.next;//插入新数组cur.next = newArray[index];newArray[index] = cur;//下一个节点cur = newCur;}}this.array = newArray;}
3.3 获取value值
获取关键字key的value值:
- 直接使用hash函数,拿到key所在的下标位置,
- 直接遍历下标中的所有节点,找到返回该节点value值,
- 没有返回-1。
//获取关键字key的val值public int getVal(int key) {int index = key % array.length;Node cur = array[index];//遍历while(cur != null) {if(cur.key == key) {return cur.value;}cur = cur.next;}return -1;}
泛型参数版本:
//获取关键字key的val值public V getVal(K key) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];//遍历while(cur != null) {if(cur.key == key) {return cur.value;}cur = cur.next;}return null;}
3.4 总代码
int参数版本:
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;public class HashBuck {//内部类,链表static class Node {public int key;public int value;public Node next;public Node(int key, int value) {this.key = key;this.value = value;}}//初始数组public Node[] array = new Node[10];//使用长度public int usedSize;//负载因子最大值private static final double DEFAULT_LOAD_FACTOR = 0.75f;//插入元素public void put(int key, int value) {int index = key % array.length;Node cur = array[index];Node prev = cur;while(cur != null) {//关键字key已经存在if(cur.key == key) {cur.value = value;return;}prev = cur;cur = cur.next;}//关键字key不存在if(prev == null) {array[index] = new Node(key,value);}else {prev.next = new Node(key,value);}this.usedSize++;//判断负载因子,是否扩容if( loadFactor() >= DEFAULT_LOAD_FACTOR) {resize();}}//扩容private void resize() {Node[] newArray = new Node[array.length * 2];//遍历每一个节点for(int i = 0; i < array.length; i++) {Node cur = array[i];//插入while (cur != null) {int index = cur.key % newArray.length;//保存下一个节点Node newCur = cur.next;//插入新数组cur.next = newArray[index];newArray[index] = cur;//下一个节点cur = newCur;}}this.array = newArray;}//计算负载因子private double loadFactor() {return 1.0*usedSize / array.length;}//获取关键字key的val值public int getVal(int key) {int index = key % array.length;Node cur = array[index];//遍历while(cur != null) {if(cur.key == key) {return cur.value;}cur = cur.next;}return -1;}
}泛型参数版本:
public class HashBuck <K,V>{static class Node <K,V>{public K key;public V value;Node<K,V> next;public Node(K key, V value) {this.key = key;this.value = value;}}//初始数组public Node<K,V>[] array = (Node<K,V>[])new Node[10];//使用长度public int usedSize;//负载因子最大值private static final double DEFAULT_LOAD_FACTOR = 0.75f;//插入元素public void put(K key, V value) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];Node<K,V> pre = cur;while(cur != null) {//关键字key已经存在if(cur.key.equals(key)) {cur.value = value;}pre = cur;cur = cur.next;}//关键字key不存在if(pre == null) {array[index] = new Node<>(key,value);} else {pre.next = new Node<>(key,value);}this.usedSize++;//判断负载因子,是否扩容if(loadFactor() >= DEFAULT_LOAD_FACTOR) {resize();}}//计算负载因子private double loadFactor() {return 1.0*usedSize / array.length;}//扩容private void resize() {Node<K,V>[] newArray = (Node<K, V>[]) new Node[array.length * 2];//遍历每一个节点for(int i = 0; i < array.length; i++) {Node<K,V> cur = array[i];//插入while (cur != null) {int index = cur.key.hashCode() % newArray.length;//保存下一个节点Node<K,V> newCur = cur.next;//插入新数组cur.next = newArray[index];newArray[index] = cur;//下一个节点cur = newCur;}}this.array = newArray;}//获取关键字key的val值public V getVal(K key) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];//遍历while(cur != null) {if(cur.key == key) {return cur.value;}cur = cur.next;}return null;}
}四、与Java集合类的关系
- HashMap 和 HashSet 即 java 中利用哈希表实现的 Map 和 Set;
- java 中使用的是哈希桶方式解决冲突的;
- java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树);
- java 中计算哈希值实际上是调用的类的 hashCode 方法,进行 key 的相等性比较是调用 key 的 equals 方法。所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须覆写 hashCode 和 equals 方法,而且要做到 equals 相等的对象,hashCode 一定是一致的。
五、练习
1. 只出现一次的数字
2.复制带随机指针的链表
3.宝石与石头
4.坏键盘打字
5.前K个高频单词
相关文章:
【数据结构】哈希/散列表
目录 一、哈希表的概念二、哈希冲突2.1 冲突概念2.2 冲突避免2.2.1 方式一哈希函数设计2.2.2 方式二负载因子调节 2.3 冲突解决2.3.1 闭散列2.3.2 开散列(哈希桶) 2.4 性能分析 三、实现简单hash桶3.1 内部类与成员变量3.2 插入3.3 获取value值3.4 总代码…...
flutter 项目初建碰到的控制台报错无法启动问题
在第一次运行flutter时,会碰见一直卡在Runing Gradle task assembleDebug的问题。其实出现这个问题的原因有两个。 一:如果你flutter -doctor 检测都很ok,而且环境配置都很正确,那么大概率就是需要多等一会,少则几十分…...

Java字符串深度解析:String的实现、常量池与性能优化
引言 在Java编程中,字符串操作是最常见的任务之一。String 类在 Java 中有着独特的实现和特性,理解其背后的原理对于编写高效、安全的代码至关重要。本文将深入探讨 String 的实现机制、字符串常量池、不可变性的优点,以及 String、StringBu…...

leetcode 2043.简易银行系统
1.题目要求: 示例: 输入: ["Bank", "withdraw", "transfer", "deposit", "transfer", "withdraw"] [[[10, 100, 20, 50, 30]], [3, 10], [5, 1, 20], [5, 20], [3, 4, 15], [10, 50]] 输出ÿ…...
框架的文物管理系统)
基于SSM(Spring + Spring MVC + MyBatis)框架的文物管理系统
基于SSM(Spring Spring MVC MyBatis)框架的文物管理系统是一个综合性的Web应用程序,用于管理和保护文物资源。下面我将提供一个详细的案例程序概述,包括主要的功能模块和技术栈介绍。 项目概述 功能需求 用户管理:…...

yakit中的规则详细解释
官方文档 序列前置知识之高级配置 | Yak Program Language 本文章多以编写yaml模版的视角来解释 规则一览 匹配器 在编写yaml中会使用到这里两个东西 点击添加会在返回包的右下角出现匹配器 上面有三个过滤器模式,官方解释 丢弃:丢弃模式会在符合匹配…...
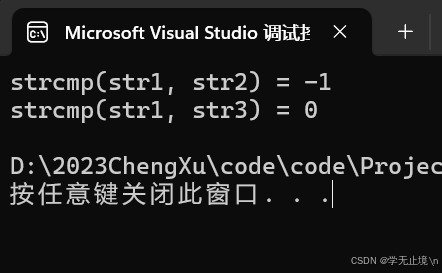
[c语言]strcmp函数的使用和模拟实现
1.strcmp函数的使用 int strcmp ( const char * str1, const char * str2 ); 如果 str1 小于 str2,返回一个负值。如果 str1 等于 str2,返回 0。如果 str1 大于 str2,返回一个正值。 实例: #include <stdio.h> #include &…...

如何把子组件的v-model修改数据,进行接收然后定义数据格式,子传父的实现
在 Vue 中,实现子组件通过 v-model 向父组件传递数据并接收后进行格式化,可以按照以下步骤来封装和实现: 步骤 1: 子组件实现 v-model 子组件需要定义一个 props 来接收 v-model 的值,并通过 emit 方法发出更新事件。 <!-- …...

linux dpkg 查看 安装 卸载 .deb
1、安装 sudo dpkg -i google-chrome-stable.deb # 如果您在安装过程中或安装和启动程序后遇到任何依赖项错误, # 您可以使用以下apt 命令使用-f标志解析和安装依赖项,该标志告诉程序修复损坏的依赖项。 # -y 表示自动回答“yes”,在安装…...

【算法】递归+深搜:105.从前序与中序遍历序列构造二叉树
目录 1、题目链接 2、题目介绍 3、解法 函数头-----找出重复子问题 函数体---解决子问题 4、代码 1、题目链接 105.从前序与中序遍历序列构造二叉树. - 力扣(LeetCode) 2、题目介绍 3、解法 前序遍历性质: 节点按照 [ 根节点 …...

ESP32 gptimer通用定时器初始化报错:assert failed: timer_ll_set_clock_prescale
背景:IDF版本V5.1.2 ,配置ESP32 通用定时器,实现100HZ,占空比50% 的PWM波形。 根据乐鑫官方的IDF指导文档设置内部计数器的分辨率,计数器每滴答一次相当于 1 / resolution_hz 秒。 (ESP-IDF编程指导文档&a…...

基于Python的旅游景点推荐系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

【开源社区】ELK 磁盘异常占用解决及优化实践
1、问题及场景描述 本文主要讨论在 CentOS环境下基于 rpm 包部署 ELK 系统磁盘异常占用的问题解析和解决方案。 生产问题描述:以下问题现实场景基于ELK体系下,ES服务的磁盘占用问题解析。默认情况下,基于 RPM 安装的 Elasticsearch 服务的安…...

达梦数据守护集群_动态增加实时备库
目录 1、概述 2、实验环境 2.1环境信息 2.2配置信息 2.3 查看初始化参数 3、动态增加实时备库 3.1数据准备 3.2配置新备库 3.3动态增加MAL配置 3.4 关闭守护进程及监视器 3.5修改归档(方法1:动态添加归档配置) 3.6 修改归档&…...

计算机基础:Ping、Telnet和SSH
文章目录 PingTelnetSSLSSH隧道 Ping Ping和Telnet是两种常见的网络工具,它们分别用于测试网络连接和检查服务端口的连通性。 Ping是一种网络工具,用于测试主机之间的连通性。它通过发送ICMP(Internet Control Message Protocol)…...

Java教学新动力:SpringBoot辅助平台
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理教学辅助平台的相关信息成为必然。开发合适…...

24/11/3 算法笔记 Adam优化器拆解
Adam 优化器是一种用于深度学习中的自适应学习率优化算法,它结合了两种其他流行的优化方法的优点:RMSprop 和 Momentum。简单来说,Adam 优化器使用了以下方法: 1. **指数加权移动平均(Exponentially Weighted Moving …...

浅谈语言模型推理框架 vLLM 0.6.0性能优化
在此前的大模型技术实践中,我们介绍了加速并行框架Accelerate、DeepSpeed及Megatron-LM。得益于这些框架的助力,大模型的分布式训练得以化繁为简。 然而,企业又该如何将训练完成的模型实际应用部署,持续优化服务吞吐性能…...

【大数据学习 | kafka高级部分】kafka中的选举机制
controller的选举 首先第一个选举就是借助于zookeeper的controller的选举 第一个就是controller的选举,这个选举是借助于zookeeper的独享锁实现的,先启动的broker会在zookeeper的/contoller节点上面增加一个broker信息,谁创建成功了谁就是主…...
MySQL limit offset分页查询可能存在的问题
MySQL limit offset分页查询语句 有 3 种形式: limit 10:不指定 offset,即 offset 0 ,表示读取第 1 ~ 10 条记录。limit 20, 10:offset 20,因为 offset 从 0 开始,20 表示从第 21 条记录开始…...

3个架构策略:构建企业级前端应用的完整解决方案
3个架构策略:构建企业级前端应用的完整解决方案 【免费下载链接】arco-design-pro An out-of-the-box solution to quickly build enterprise-level applications based on Arco Design. 项目地址: https://gitcode.com/gh_mirrors/ar/arco-design-pro 在快速…...
)
告别卡顿!手把手教你用UltraISO给老旧笔记本装上OpenEuler 22.03 LTS(保姆级BIOS设置指南)
告别卡顿!手把手教你用UltraISO给老旧笔记本装上OpenEuler 22.03 LTS(保姆级BIOS设置指南) 老旧笔记本性能跟不上现代操作系统?别急着淘汰它们!OpenEuler作为一款轻量级Linux发行版,特别适合为老设备注入新…...
到底怎么选?)
IPv6网络规划必看:华为设备上DHCPv6与SLAAC(无状态地址分配)到底怎么选?
IPv6网络规划实战:华为设备地址分配方案深度解析 在IPv6网络部署的浪潮中,地址分配策略的选择往往成为困扰网络架构师的首要难题。当传统IPv4的DHCP方式遇上IPv6全新的SLAAC(无状态地址自动配置)机制,技术决策的复杂性…...

为什么你的扑克策略总在关键牌局失效?Desktop Postflop给你答案
为什么你的扑克策略总在关键牌局失效?Desktop Postflop给你答案 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-po…...

极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍
极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在机房上课时,面对老师全屏广…...

手把手教你打造个人语音锁:基于PyTorch声纹识别项目,从环境搭建到GUI应用部署全流程
从零构建智能声纹锁:PyTorch工程化实战指南 当生物识别技术逐渐渗透日常生活,声纹识别正以其非接触、高便捷的特性成为身份认证的新宠。不同于指纹或人脸识别需要专用硬件支持,声纹识别仅需普通麦克风即可实现高精度身份验证。本文将带您完整…...

从源码到实战:手把手教你自定义一个比StringUtils更强大的Java数字校验工具类
从源码到实战:构建超越StringUtils的Java数字校验工具类 在Java开发中,数字校验是每个开发者都会遇到的常见需求。虽然Apache Commons Lang的StringUtils提供了基础的isNumeric方法,但在实际业务场景中,我们经常需要处理更复杂的…...

DLSS Swapper:免费开源的游戏性能优化终极解决方案
DLSS Swapper:免费开源的游戏性能优化终极解决方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为PC游戏玩家设计的免费开源工具,它能够智能管理、下载和替换游戏中的DL…...

Codex+Coze自动化工作流实战
Codex(特指OpenAI的编程特化AI Agent)与Coze(扣子)平台的结合,能够实现从自然语言描述到可运行自动化流程的端到端生成。其核心在于利用Codex强大的代码理解和生成能力,来编写、调试并封装符合Coze平台规范…...

大语言模型推理引擎优化:架构挑战与关键技术解析
1. 大语言模型推理引擎的架构挑战与优化方向1.1 Transformer架构的固有瓶颈Transformer架构的自注意力机制存在两大核心瓶颈:计算复杂度和内存占用。对于序列长度N,自注意力层的计算复杂度为O(N),这使得长文本处理成为性能黑洞。以2048 token…...