浅谈语言模型推理框架 vLLM 0.6.0性能优化
在此前的大模型技术实践中,我们介绍了加速并行框架Accelerate、DeepSpeed及Megatron-LM。得益于这些框架的助力,大模型的分布式训练得以化繁为简。
然而,企业又该如何将训练完成的模型实际应用部署,持续优化服务吞吐性能?我们不仅要考量模型底层的推理效率,还需从请求处理的调度策略上着手,确保每一环节都能发挥出最佳效能。
本期内容,优刻得将为大家带来vLLM[1],一款高性能推理服务框架的相关内容。vLLM于近期推出了0.6.0版本[2]。那么,相比旧版本推出了什么新功能,又做了哪些优化呢?
优刻得模型服务平台UModelVerse现已同步上线vLLM0.6.0。仅需几步,即刻畅享新版vLLM带来的极速推理体验。文末为您带来详细的使用教程。
01
API服务端-推理引擎进程分离
推理服务框架需要考虑服务部署的两个要素:面向客户请求的服务端,以及背后的模型推理端。在vLLM中,分别由API服务端 (API Server)和模型推理引擎 (vLLM Engine)执行相应任务。
1.1 进程共用 vs. 进程分离
根据旧版vLLM设计,负责处理请求的API服务端与负责模型推理的推理引擎,共用同一个python进程;
0.6.0版本将API服务端和推理引擎分离,分别由两个python进程运行。进程之间的信息交互由ZeroMQ socket进行传输 [3]。
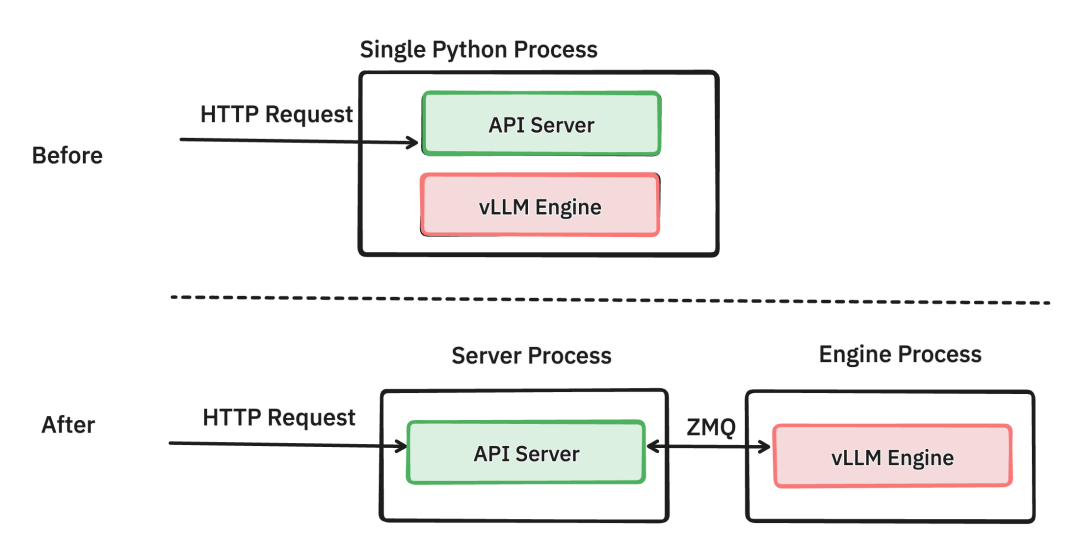
上:API服务端与推理引擎共用同一个python进程;
下:API服务端与推理引擎各自独用python进程。
API服务端需要承担一系列处理HTTP请求等任务。通过对旧版本的性能分析,vLLM团队发现API服务端消耗大量CPU资源。
举个例子,在推理引擎端,轻负载下使用Llama3 8B模型推理生成1个token的耗时约为13ms;而相对应地,API服务端需要能够每秒处理76个token才能跟上推理引擎的速度。由于python GIL的存在,推理引擎还会与服务端争抢CPU资源。CPU端负载巨大无法及时处理计算,则会使得GPU端因等待CPU而产生空闲,无法充分利用性能[3]。
在0.6.0版本中,将API服务端与推理引擎端分离为两个进程后,两个进程可以各自专注于份内职责,而不会受GIL的影响。而在分离后,团队后续可以更好地对两端分别进行更细致的性能优化和打磨。
1.2 TTFT、TPOT和ITL
在进入测试对比前,先了解一下衡量语言模型服务推理效率通常参照的三个指标,即:
首个token响应时长 (Time to first token, TTFT)
每个token输出时长 (Time per output token, TPOT)
跨token延迟 (Inter-token latency, ITL)
TTFT顾名思义,就是从客户端发出请求后开始计时,直到服务端返回第一个输出token的耗时。过程中,由服务端收到请求后着手处理,交由调度器准备推理。推理引擎需要完成prefill任务。基于prefill得到的kv值,decode得到第一个输出token后返回。
而TPOT和ITL概念相对接近,表达的都是后续一连串decode的耗时。根据vLLM测试代码 [4],我们定义如下:
TPOT是在一个请求从发出后,不纳入TTFT的耗时 (主要是为了排除prefill耗时),到所有token全部decode完成并返回的整体耗时除以一共返回的token数量,即每个token输出的平均时长;
而ITL是在计算每次请求返回部分token时所需的时长,即服务端每次decode后返回一个或一批token所需的时长。
举个例子,如果每次服务端返回1个token,则ITL耗时应与TPOT接近;而当每次服务端返回5个token,则ITL耗时应接近于5倍的TPOT耗时 (因为ITL计算单次的时长,而TPOT计算单token的时长)。
1.3 测试&对比
在优刻得云主机上开展对比测试。
利用vLLM官方提供的benchmark_serving基准测试,我们可以模拟真实的客户端请求,从而对比vLLM 0.6.0与旧版vLLM (0.5.5)在进程分离上的优化导致的性能差异。关闭其他优化方法后,在保持其他参数不变的情况下,在opt-125m模型上开展测试。
在服务端,我们分别在0.6.0和旧版本上使用以下的参数:
#vLLM 0.5.5(共用进程)
vllm serve facebook/opt-125m \
--max-model-len 2048 \
--use-v2-block-manager
#vLLM 0.6.0(分离进程)
vllm serve facebook/opt-125m \
--max-model-len 2048 \
--use-v2-block-manager \
--disable-async-output-proc #关闭0.6.0的新优化方法:异步输出处理。下文有详解~
而在客户端,我们统一采用以下脚本。我们模拟100个请求同时发出,请求数据随机取自ShareGPT v3数据集。
python vllm/benchmarks/benchmark_serving.py \
--backend vllm \
--model facebook/opt-125m \
--tokenizer facebook/opt-125m \
--request-rate inf \ #所有请求无间隔同时发送
--num-prompts 100 \ #共100条请求发出
--dataset-name sharegpt \
--dataset-path dataset/ShareGPT_V3_unfiltered_cleaned_split.json \
--sharegpt-output-len 1024 \
--seed 42 #固定种子控制变量
经过测试,结果如下 (左旧版本0.5.5;右新版本0.6.0):
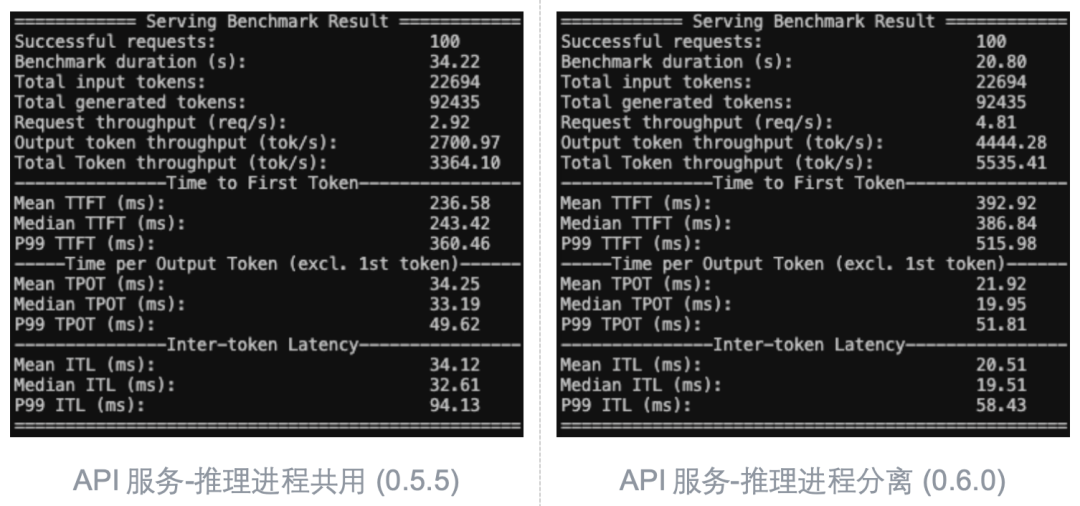
进程分离以牺牲TTFT指标为代价 (笔者推测进程间ZeroMQ通信带来开销),测试整体时长(Benchmark duration)比进程共用快近14秒,提速约40%。该模型参数量较小,GPU压力较小,瓶颈主要在于CPU。进程分离消除了CPU争抢造成的开销。
02
多步调度(Multi-step scheduling)
在请求调度层面,vLLM 0.6.0的更新中引入了多步调度 (Multi-step scheduling)的方法 [2],使得请求处理的调度更高效。为了更好地理解多步调度的意义,我们简单了解一下vLLM调度器。
2.1 调度器 (Scheduler)
vLLM推理引擎LLMEngine中存在调度器 (Scheduler)的概念。调度器控制来自服务端的输入请求会以什么顺序送入模型执行推理。
对于一个输入请求,我们需要首先对输入的句子执行prefill计算,并基于prefill得到的kv值开展decode计算,即预测下一个token。而调度器的职责就是以合理的调度策略,安排模型执行prefill或是decode的顺序 (篇幅限制,具体调度细节这里不展开)。
2.2 单步调度 vs. 多步调度
在旧版vLLM中,每次调度器只会为下一次的模型推理安排优先顺序,即每次调度对应一次模型推理。该方法被称为单步推理;
0.6.0引入多步推理,每次调度器调度会安排接下来的多次模型推理,即每次调度对应n次推理。多步推理可以减少调度次数,降低CPU开销,从而让模型推理充分利用GPU资源,尽量保持运行。
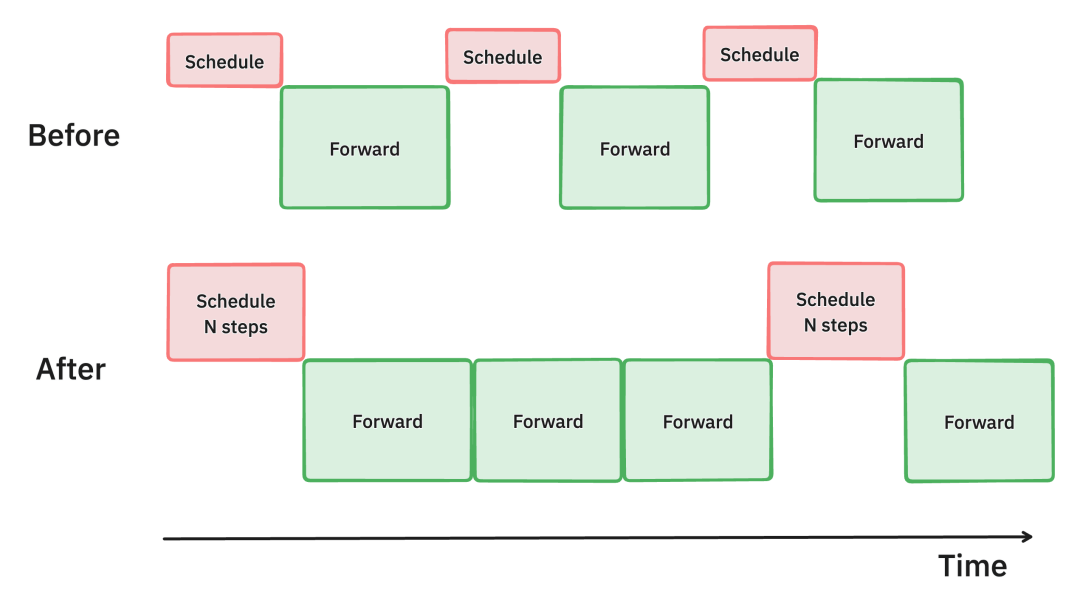
上:一次调度后执行1步推理;
下:一次调度后执行3步推理。
据vLLM团队测试,4张H100环境下运行Llama 70B,多步推理的吞吐量比单步推理提升了28%[3]。
2.3 测试&对比
利用上述基准测试,对比单步调度与多步调度的性能差异。这次我们统一使用0.6.0版本。在保持其他设置相同的情况下,设置服务端启动参数分别如下。而客户端方面设置与上文相同,在此不再赘述。
#单步/多步调度
vllm serve facebook/opt-125m \
--max-model-len 2048 \
--use-v2-block-manager \
--disable-async-output-proc \ #关闭异步输出处理
--num-scheduler-steps 1/10 #每次调度1步/10步
以下为测试结果 (左单步调度,右多步调度step=10):
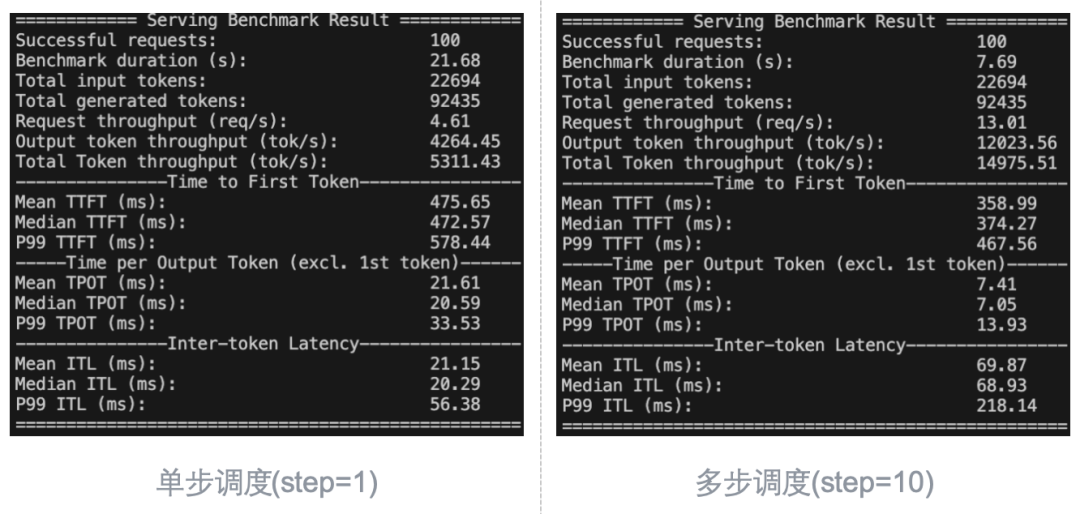
多步调度(step=10)的情况下,基准测试仅耗时7.69秒;而单步调度耗时21.68秒,整体速度上快近3倍。(由于opt-125m模型的参数量较小,计算瓶颈主要位于CPU端,因此对CPU端的优化效果极其显著;对于更大规模的模型,瓶颈位于GPU端,加速效果相对没有这么明显。)
使用NVIDIA Nsight systems [5]进一步分析profile (NVTX中绿色块表明执行调度)。多步调度中每个绿色块之间有10组CPU epoll_pwait和read,即执行10次GPU上的模型推理,并读取结果;而单步推理中每个绿色块之间仅有1组epoll_pwait和read,即1次模型推理。

多步调度(step=10)

单步调度(step=1)
细心的同学可能发现了,上述测试中,尽管多步调度的整体耗时降低了很多,但是ITL远大于单步调度。这是因为多步调度(step=10)将10步推理整合到了一起。
因此,ITL(69.87秒)正好约为10倍TPOT(7.41秒)。增加一场多步调度(step=5)的测试进行验证,可以看到ITL约为41.76秒,约5倍于TPOT的8.79秒。
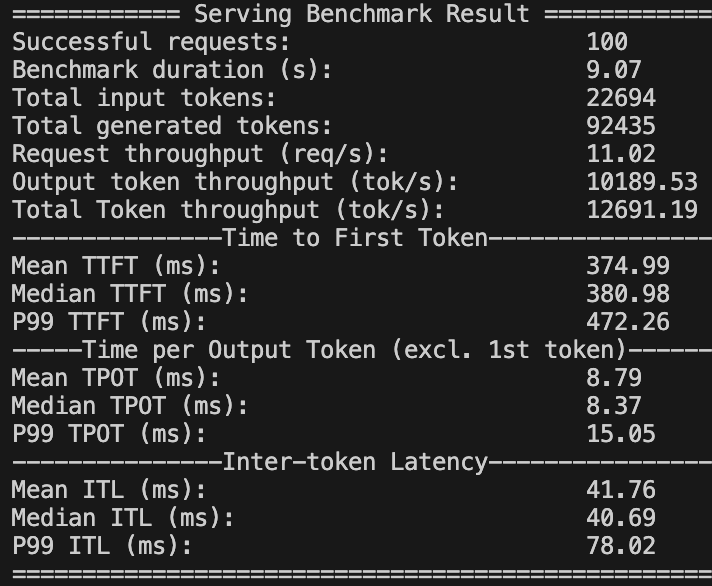
多步调度(step=5)
03
异步输出处理(ASync output processing)
在旧版vLLM中,GPU端模型推理输出token后,必须在CPU端对输出token进行处理并判断是否符合停止条件 (stopping criteria),从而决定是否继续推理,这个操作会产生时间开销;
新版vLLM引入了异步输出处理,使得模型推理和输出处理异步进行,从而重叠计算的时间[3]。
3.1 异步输出处理
在异步输出处理中,我们把模型输出从GPU端取到CPU端进行停止条件判定时,并不会让模型停止推理,等待判定结果从而导致空闲。在CPU端对第n个输出进行处理并判定是否停止的同时,我们在GPU端假设第n个输出尚不符合停止条件,并继续推理预测第n+1个输出。
这样的设计可能会使得每条请求都多了一次推理,造成些许耗时,但与GPU空闲等待所浪费的时间相比就显得很划算了。
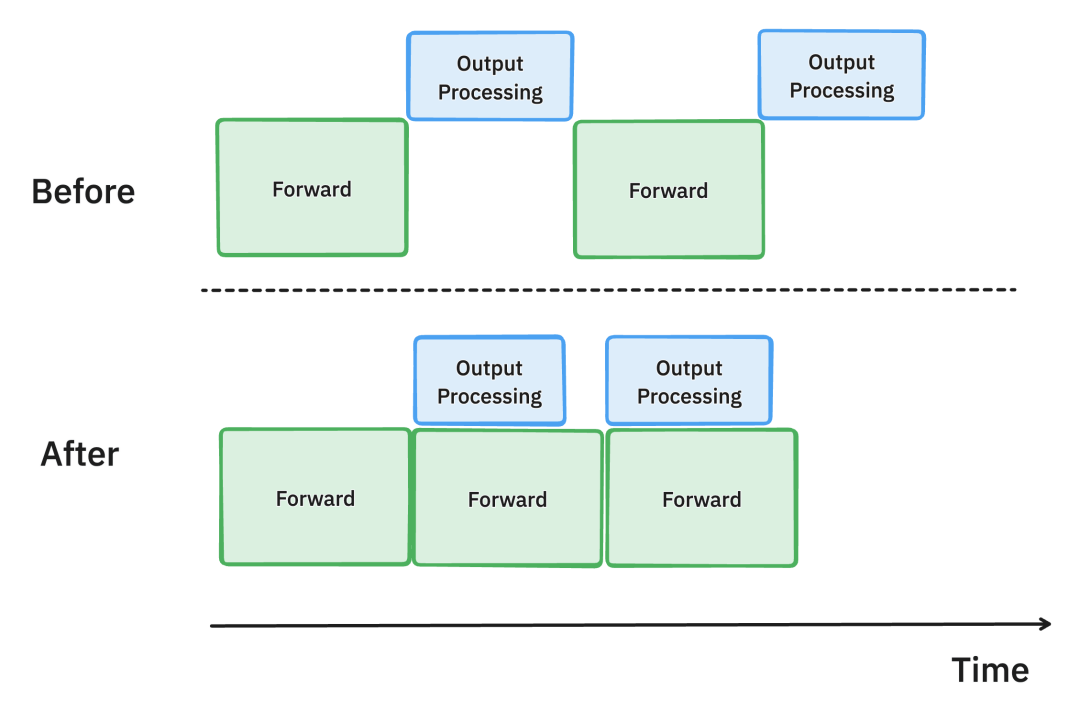
上:不启用异步输出处理;下:启用异步输出处理。
据vLLM团队测试,4张H100环境下运行Llama 70B,异步输出处理的TPOT指标比禁用快了8.7%[3]。
3.2 测试&对比
我们对比启用和禁用异步输出处理的性能差异。在保持其他设置相同的情况下,设置服务端启动参数分别如下。vLLM 0.6.0中默认启用该功能,可以通过设置参数--disable-async-output-proc来手动关闭。
#禁用/启用异步输出处理
vllm serve facebook/opt-125m \
--max-model-len 2048 \
--use-v2-block-manager \
--disable-async-output-proc #移除该参数则默认启用
以下为测试结果 (左禁用异步输出处理,右启用异步输出处理):
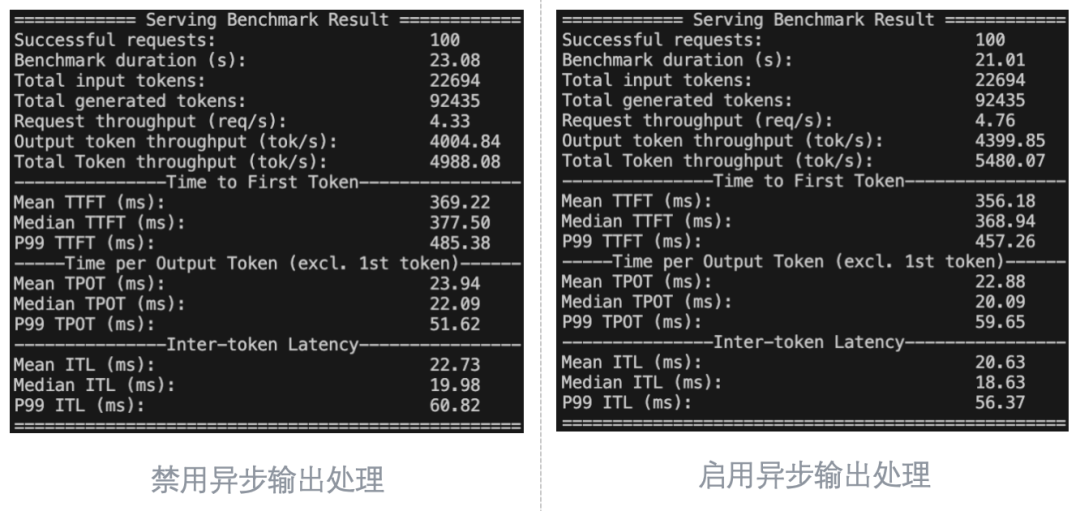
异步输出处理可以获得一些细微的性能提升,主要体现在TPOT和ITL上,约5%左右,基本符合预期。
04
在优刻得UModelVerse体验新版vLLM
4.1 创建并启动服务
打开UCloud控制台 (https://console.ucloud.cn/),登录账号。点击左上角的“全部产品”,从中找到“模型服务平台 UModelVerse”。
点击进入后,点击左侧栏目中的“服务部署”,并点击“创建服务”。
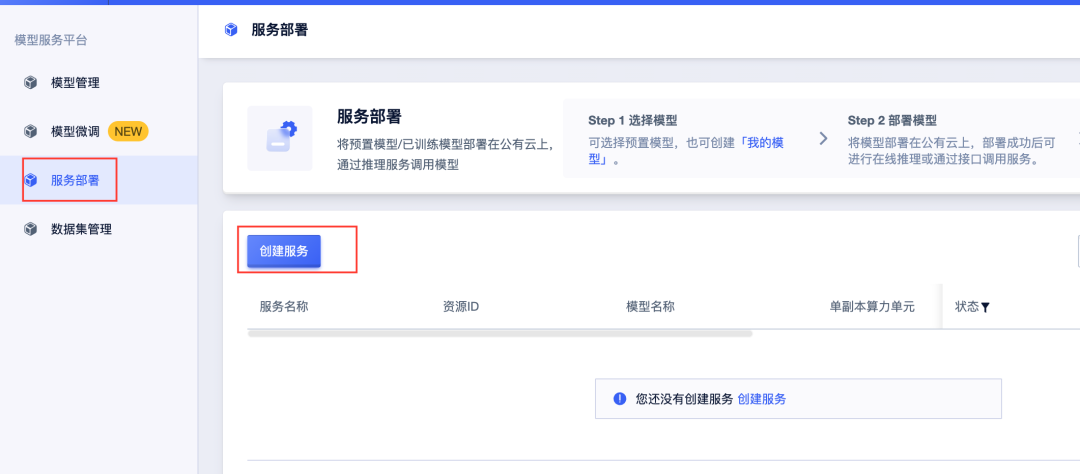
进入界面后,设置想要使用的模型并添加服务名称后,在右侧选择合适的支付方式,并点击“立即购买”,系统自动跳转到支付页面。
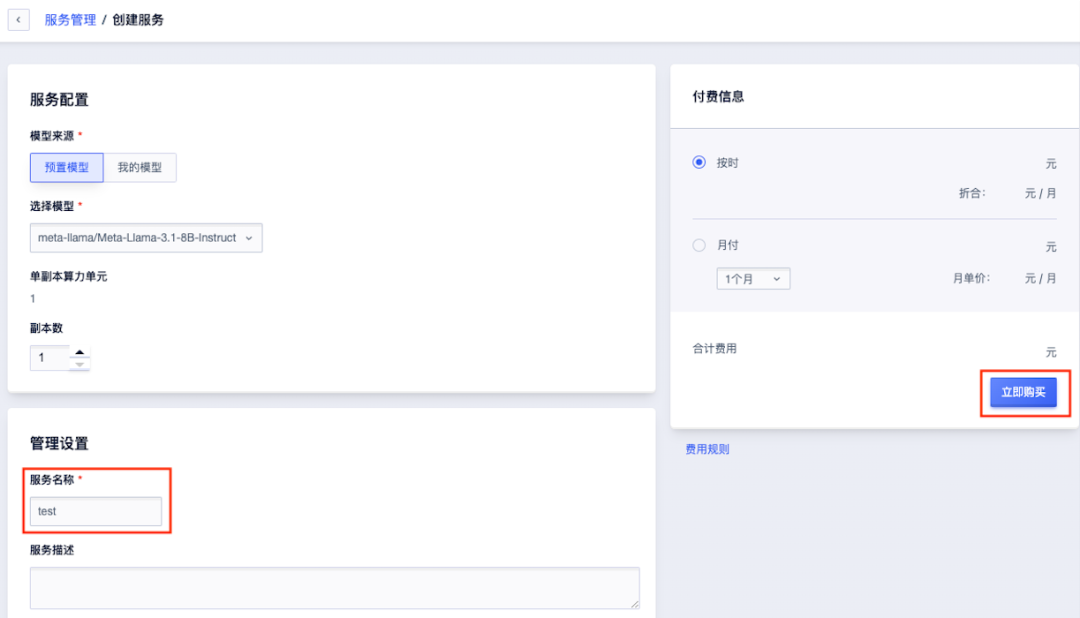
完成支付后,页面回到“服务部署”。可以看到我们购买的服务正处于“部署中”的状态,稍作等待......
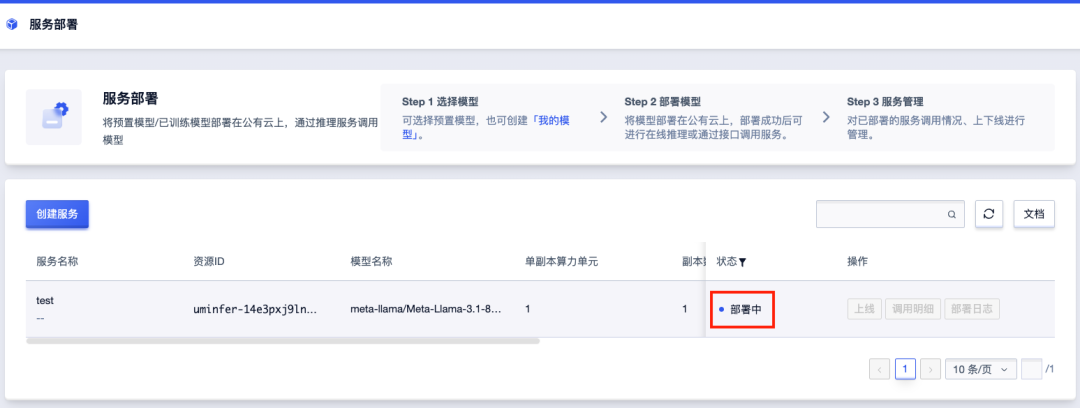
待状态转为“已上线”后,即可点击“访问”打开网页图形界面,或通过API调用。
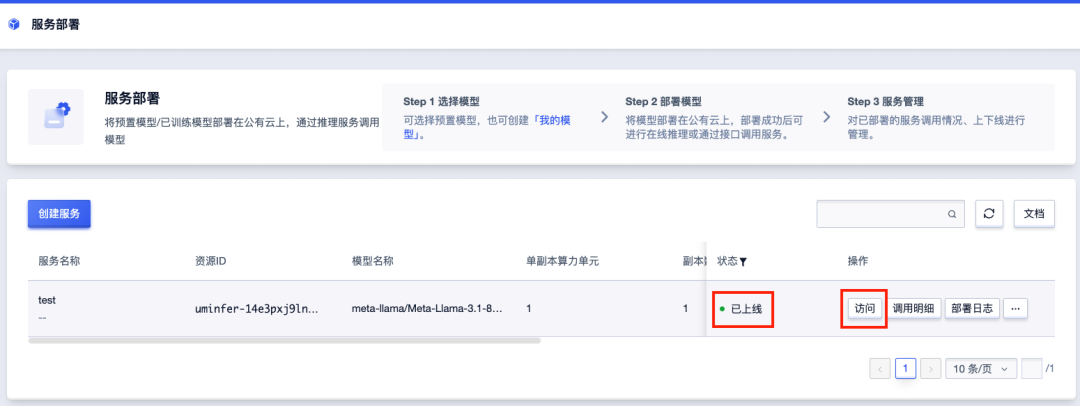
4.2 使用服务
4.2.1 通过网页图形界面
点击“访问”即可进入与chatbot的图形对话页面:
4.2.2 通过API接口
当然,我们也可以通过API接口进行对话。以下是调用代码样例。调用的API参数可以在服务列表中找到。其中:
• API_KEY:即API Key
• BASE_URL:为API地址
• MODEL:为模型的名称


Python
from openai import OpenAI
API_KEY = 'aDZ39J204akIPPhmqQtLuf64CBA7ZbyQ0Ov88VzlPuBRjdvP' # API Key
BASE_URL = 'https://ai.modelverse.cn/uminfer-14e3pxj9lnfc/v1' # 模型URL
MODEL = "meta-llama/Meta-Llama-3.1-8B-Instruct" # 模型名
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
# 调用模型生成文本
response = client.chat.completions.create(
model=MODEL, # 选择模型
temperature=0.5, # 温度,模型输出结果的随机性
max_tokens=512, # 最大tokens长度
messages=[
{"role": "user", "content": "你好呀,可以给我讲个笑话嘛?"},
]
)
# 获取并打印 AI 生成的回复
print(response.choices[0].message.content)
【相关资料】
[1] vLLM: https://github.com/vllm-project/vllm
[2] vLLM Highlights: https://github.com/vllm-project/vllm/releases/v0.6.0
[3] vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction: https://blog.vllm.ai/2024/09/05/perf-update.html
[4] vLLM benchmark source code: https://github.com/vllm-project/vllm/blob/b67feb12749ef8c01ef77142c3cd534bb3d87eda/benchmarks/backend_request_func.py#L283
[5] NVIDIA Nsight Systems: https://developer.nvidia.com/nsight-systems
相关文章:
浅谈语言模型推理框架 vLLM 0.6.0性能优化
在此前的大模型技术实践中,我们介绍了加速并行框架Accelerate、DeepSpeed及Megatron-LM。得益于这些框架的助力,大模型的分布式训练得以化繁为简。 然而,企业又该如何将训练完成的模型实际应用部署,持续优化服务吞吐性能…...

【大数据学习 | kafka高级部分】kafka中的选举机制
controller的选举 首先第一个选举就是借助于zookeeper的controller的选举 第一个就是controller的选举,这个选举是借助于zookeeper的独享锁实现的,先启动的broker会在zookeeper的/contoller节点上面增加一个broker信息,谁创建成功了谁就是主…...
MySQL limit offset分页查询可能存在的问题
MySQL limit offset分页查询语句 有 3 种形式: limit 10:不指定 offset,即 offset 0 ,表示读取第 1 ~ 10 条记录。limit 20, 10:offset 20,因为 offset 从 0 开始,20 表示从第 21 条记录开始…...

CODESYS可视化桌面屏保-动态气泡制作详细案例
#一个用于可视化(HMI)界面的动态屏保的详细制作案例程序# 前言: 在工控自动化设备上,为了防止由于人为误触发或操作引起的故障,通常在触摸屏(HMI)增加屏幕保护界面,然而随着PLC偏IT化的发展,在控制界面上的美观程度也逐渐向上位机或网页前端方面发展,本篇模仿Windows…...

华为 Atlas500 Euler 欧拉系统操作指南
华为 Atlas500 Euler 欧拉系统操作指南 ssh root连接 找到Atlas500的IP地址,如:192.168.1.166 账号/密码:admin/Huawei123 root/密码:Huawei123456 #直接使用root ssh连接 这里受限不让直接用root连接 ssh root192.168.1.116 #…...
Chromium127编译指南 Mac篇(六)- 编译优化技巧
1. 前言 在Chromium127的开发过程中,优化编译速度是提升开发效率的关键因素。本文将重点介绍如何使用ccache工具来加速C/C代码的编译过程,特别是在频繁切换分支和修改代码时。通过合理配置和使用这些工具,您将能够显著减少编译时间ÿ…...

《TCP/IP网络编程》学习笔记 | Chapter 3:地址族与数据序列
《TCP/IP网络编程》学习笔记 | Chapter 3:地址族与数据序列 《TCP/IP网络编程》学习笔记 | Chapter 3:地址族与数据序列分配给套接字的IP地址和端口号网络地址网络地址分类和主机地址边界用于区分套接字的端口号数据传输过程示例 地址信息的表示表示IPv4…...

C++ | Leetcode C++题解之第546题移除盒子
题目: 题解: class Solution { public:int dp[100][100][100];int removeBoxes(vector<int>& boxes) {memset(dp, 0, sizeof dp);return calculatePoints(boxes, 0, boxes.size() - 1, 0);}int calculatePoints(vector<int>& boxes…...

day05(单片机)SPI+数码管
目录 SPI数码管 SPI通信 SPI总线介绍 字节交换原理 时序单元 SPI模式 模式0 模式1 模式2 模式3 数码管 介绍 74HC595芯片分析 原理图分析 cubeMX配置 程序编写 硬件SPI 软件SPI 作业: SPI数…...

Android Framework AMS(13)广播组件分析-4(LocalBroadcastManager注册/注销/广播发送处理流程解读)
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要解读广播组件的广播发送过程。关注思维导图中左上侧部分即可。 有了前面普通广播组件 注册/注销程/广播组件的发送广播流程分析的基础&…...

模糊理论与模糊集概述
1. 模糊集 1️⃣ μ A : U → [ 0 , 1 ] \mu_A:U\to{[0,1]} μA:U→[0,1],将任意 u ∈ U u\in{}U u∈U映射到 [ 0 , 1 ] [0,1] [0,1]上的某个函数 模糊集: A { μ A ( u ) , u ∈ U } A\{\mu_A(u),u\in{}U\} A{μA(u),u∈U}称为 U U U上的一个模糊集…...

基于STM32的实时时钟(RTC)教学
引言 实时时钟(RTC)是微控制器中的一种重要功能,能够持续跟踪当前时间和日期。在许多应用中,RTC用于记录时间戳、定时操作等。本文将指导您如何使用STM32开发板实现RTC功能,通过示例代码实现当前时间的读取和显示。 环…...

Caffeine Cache解析(三):BoundedBuffer 与 MpscGrowableArrayQueue 源码浅析
接续 Caffeine Cache解析(一):接口设计与TinyLFU 接续 Caffeine Cache解析(二):drainStatus多线程状态流转 BoundedBuffer 与 MpscGrowableArrayQueue multiple-producer / single-consumer 这里multiple和single指的是并发数量 BoundedBuffer: Caf…...

全双工通信协议WebSocket——使用WebSocket实现智能学习助手/聊天室功能
一.什么是WebSocket? WebSocket是基于TCP的一种新的网络协议。它实现了浏览器与服务器的全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接,并进行双向数据传输 HTTP 协议是一种无状态的、无连接的、单向的应用…...

Rust-Trait 特征编程
昨夜江边春水生,艨艟巨舰一毛轻。 向来枉费推移力,此日中流自在行。 ——《活水亭观书有感二首其二》宋朱熹 【哲理】往日舟大水浅,众人使劲推船,也是白费力气,而此时春水猛涨,巨舰却自由自在地飘行在水流中…...

彻底理解哈希表(HashTable)结构
目录 介绍优缺点概念哈希函数快速的计算键类型键转索引霍纳法则 均匀的分布 哈希冲突链地址法开放地址法线性探测二次探测再哈希法 扩容/缩容实现哈希创建哈希表质数判断哈希函数插入&修改获取数据删除数据扩容/缩容函数全部代码 哈希表(Hash Table)…...

微信小程序的汽车维修预约管理系统
文章目录 项目介绍具体实现截图技术介绍mvc设计模式小程序框架以及目录结构介绍错误处理和异常处理java类核心代码部分展示详细视频演示源码获取 项目介绍 系统功能简述 前台用于实现用户在页面上的各种操作,同时在个人中心显示各种操作所产生的记录:后…...
)
LeetCode:3255. 长度为 K 的子数组的能量值 II(模拟 Java)
目录 3255. 长度为 K 的子数组的能量值 II 题目描述: 实现代码与解析: 模拟 原理思路: 3255. 长度为 K 的子数组的能量值 II 题目描述: 给你一个长度为 n 的整数数组 nums 和一个正整数 k 。 一个数组的 能量值 定义为&am…...

深入了解逻辑回归:机器学习中的经典算法
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
)
软件测试基础十三(python 函数)
函数 1. 函数的意义 代码复用 提高效率:Python中的函数允许将一段可重复使用的代码封装起来。例如,在一个数据分析项目中,可能需要多次计算一组数据的平均值。可以将计算平均值的代码定义为一个函数: def calculate_average(nu…...

10分钟快速入门:免费开源AI语音转换与音频分离完整指南
10分钟快速入门:免费开源AI语音转换与音频分离完整指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conver…...

企业级应用如何借助Taotoken实现大模型API的容灾与负载均衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何借助Taotoken实现大模型API的容灾与负载均衡 在构建依赖大模型能力的企业级应用时,服务的连续性与稳定性…...

3步打造专业网络视频系统:DistroAV NDI插件完全指南
3步打造专业网络视频系统:DistroAV NDI插件完全指南 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否还在为复杂的视频线缆而烦恼?或者为多设…...

Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件
Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款…...

用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南
用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南 医学影像分析领域,息肉分割一直是内窥镜诊断的关键技术。传统方法依赖医生手动标注,效率低下且易受主观因素影响。近年来,深度学习在医学图像分割领域展现出强大潜…...

【RK3588-AI-003】RK3588串口+SSH远程连接配置+文件互传实操
一、前言 很多刚入手RK3588开发板做AI部署、嵌入式开发的同学,都会遇到三大难题: ❌ 不知道怎么接线、看不懂串口打印日志,调试报错无从下手; ❌ 每次重启开发板IP都会变,频繁修改连接地址,开发极其麻烦&…...

AMD Ryzen嵌入式COM Express模块:工业边缘计算的高性能解决方案
1. 项目概述:当工业计算遇上“锐龙”芯在工业自动化、边缘计算和高端嵌入式领域,COM Express(Computer-On-Module Express)模块一直是构建紧凑、高性能、高可靠性系统的基石。它就像一台浓缩的、标准化的“电脑主板核心”…...

告别Unity WebGL的模糊UI:用Vue3重构前端界面,手把手教你实现双向通信
Unity WebGL与Vue3的完美联姻:打造高清交互界面的实战指南 1. 为什么需要重构Unity WebGL的UI系统? 许多Unity开发者都曾经历过这样的困境:当我们将精心制作的3D项目发布为WebGL版本时,原生UGUI在浏览器中的表现往往不尽如人意。模…...

3分钟快速激活Windows和Office:KMS智能激活工具终极指南
3分钟快速激活Windows和Office:KMS智能激活工具终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成…...

思源宋体TTF实战秘籍:三步搞定专业中文字体配置
思源宋体TTF实战秘籍:三步搞定专业中文字体配置 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找合适的中文字体而烦恼吗?Source Han Serif C…...