Vert.x,应用监控 - 全链路跟踪,基于Zipkin
关于Zipkin
Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),能够收集服务间调用的时序数据,提供调用链路的追踪。Zipkin每一个调用链路通过一个trace id来串联起来,通过trace id,就能够直接定位到这次调用链路,并且可以根据服务名、标签、响应时间等进行查询,找出哪些耗时比较长的链路节点。
当用户发起一次调用时,Zipkin的客户端(Brave)会在入口处为整条调用链路生成一个全局唯一的trace id, 一个trace id代表一个完整的调用链。一个trace内部包含多个span。
Zipkin为一条链路中的每一次分布式调用生成一个span id。一个trace由一组span组成,一个trace中的所有span是一个树形结构,树的根节点叫做root span。除root span外,其他span都会包含一个parent Id,表示父级span的span Id。
每个span中包含多个Annotation,用来记录关键事件的时间点。
ZipKin 可以分为两部分:
- ZipKin Server :用来作为数据的采集存储、数据分析与展示;
- ZipKin Client :基于不同的语言及框架封装的一些列客户端工具,这些工具完成了追踪数据的生成与上报功能。
ZipKin Server
Zipkin支持的存储类型有inMemory(默认)、MySQL、Cassandra、以及ElasticsSearch几种方式,正式环境推荐使用Cassandra和ElasticSearch。
要使用ZipKin Server非常简单,通过https://repo1.maven.org/maven2/io/zipkin/zipkin-server/下载zipkin-server-x.xx-exec.jar文件,然后执行即可:
# java -jar zipkin-server-3.4.2-exec.jar
...
2024-11-08T11:15:47.484+08:00 INFO [/] 2450 --- [oss-http-*:9411] c.l.a.s.Server : Serving HTTP at /[0:0:0:0:0:0:0:0]:9411 - http://127.0.0.1:9411/说明: 如果不指定参数,zipkin server不存储跟踪数据(inMemory) , 可以通过--STORAGE_TYPE参数指定支持的持久化存储。
ZipKin Client
Brave是ZipKin客户端的库文件,在我们编写的代码中使用,用于将我们的埋点信息上报到Zipkin服务器端,通常框架会整合Brave。
vertx-zipkin
Vert.x通过Zipkin Brave整合了Zipkin,提供了一个开箱即用的组件vertx-zipkin,可以让我们轻松的使用Zipkin跟踪Vertx编写的服务的调用。
首先需要添相关依赖添:
<dependency><groupId>io.vertx</groupId><artifactId>vertx-zipkin</artifactId><version>4.5.10</version>
</dependency>
使用vertx-zipkin非常简单,只要为Vertx实例指定相应的zipkin跟踪配置(ZipkinTracingOptions)即可:
import io.vertx.core.Vertx;
import io.vertx.core.VertxOptions;
import io.vertx.core.http.HttpMethod;
import io.vertx.core.http.HttpServer;
import io.vertx.core.http.HttpServerResponse;
import io.vertx.core.json.JsonArray;
import io.vertx.core.json.JsonObject;
import io.vertx.ext.web.Router;
import io.vertx.mysqlclient.MySQLBuilder;
import io.vertx.mysqlclient.MySQLConnectOptions;
import io.vertx.sqlclient.PoolOptions;
import io.vertx.sqlclient.Row;
import io.vertx.sqlclient.SqlClient;
import io.vertx.sqlclient.Tuple;
import io.vertx.tracing.zipkin.HttpSenderOptions;
import io.vertx.tracing.zipkin.ZipkinTracingOptions;public class API01 {public static void main(String[] args) {String senderEndpoint = "http://172.18.240.73:9411/api/v2/spans"; // zipkin serverVertx vertx = Vertx.vertx(new VertxOptions().setTracingOptions(new ZipkinTracingOptions().setSenderOptions(new HttpSenderOptions().setSenderEndpoint(senderEndpoint)).setServiceName("API01"))); // 必须指定唯一的服务名MySQLConnectOptions connectOptions = new MySQLConnectOptions().setHost("127.0.0.1").setPort(3306).setUser("root").setPassword("Passw0rd").setDatabase("hr").setConnectTimeout(2000).addProperty("autoReconnect", "true").addProperty("useSSL","false").addProperty("rewriteBatchedStatements", "true");PoolOptions poolOptions = new PoolOptions().setMaxSize(5);SqlClient client = MySQLBuilder.client().using(vertx).with(poolOptions).connectingTo(connectOptions).build();HttpServer server = vertx.createHttpServer();Router router = Router.router(vertx);router.route(HttpMethod.GET, "/api/v2/api01/:empNo").handler(routingContext ->{String en = routingContext.pathParam("empNo");int empNo = 0;try {empNo = Integer.parseInt(en);} catch(Exception e) {}String sqlText = "select empno, ename, job from emp where empno = ?";client.preparedQuery(sqlText).execute(Tuple.of(empNo)).onSuccess(rows -> {JsonArray result = new JsonArray();for (Row row : rows) {JsonObject json = row.toJson();result.add(json);}HttpServerResponse response = routingContext.response();response.putHeader("content-type", "application/json");response.end(result.toString());}).onFailure(exception -> {routingContext.fail(exception);});});server.requestHandler(router).listen(8001);}
}
启动并调用我们编写的接口,即可在zipkin服务端跟踪我们的调用信息。
访问zipkin服务器"http://172.18.240.73:9411/zipkin/“,点击"Find a trace” -> 点红色的"+“号图标,指定"serviceName”,然后点击"RUN QUERY"按钮进行查询。

可以看到本次api01调用耗时5.583ms,其中数据库耗时3.407ms。没有其它分布式调用。
设计一个复杂的案例,假设有一个接口api04,在api04中,分别调用api03和api02接口,而在api02中又调用api01接口。调用http://127.0.0.1:8004/api/v2/api04, 来看看zipkin跟踪效果:

是不是很酷,整个调用链都清晰的显示出来,可以非常直观的看到api04的耗时,包括其内部分布式子调用的顺序和耗时,而我们要做的仅仅是添加几行zipkin配置代码。完整案例代码见文章顶部。
相关文章:
Vert.x,应用监控 - 全链路跟踪,基于Zipkin
关于Zipkin Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),能够收集服务间调用的时序数据,提供调用链路的追踪。Zipkin每一个调用链路通过一个trace id来串联起来,通过trace id,就能够直接定位到这次调…...

Rust常用数据结构教程 序列
文章目录 一、Vec1.Vec与堆栈2.什么时候需要Vec3.get()方法4.与枚举的结合 二、VecDeque1.什么情况适合VecDeque2.VecDeque的方法 三、LinkedList1.什么时候用LinkedList 参考 一、Vec 可变数组(vector)数组存储在heap上,在运行时(runtime)可以增加或减少数组 长度 有人把Ve…...
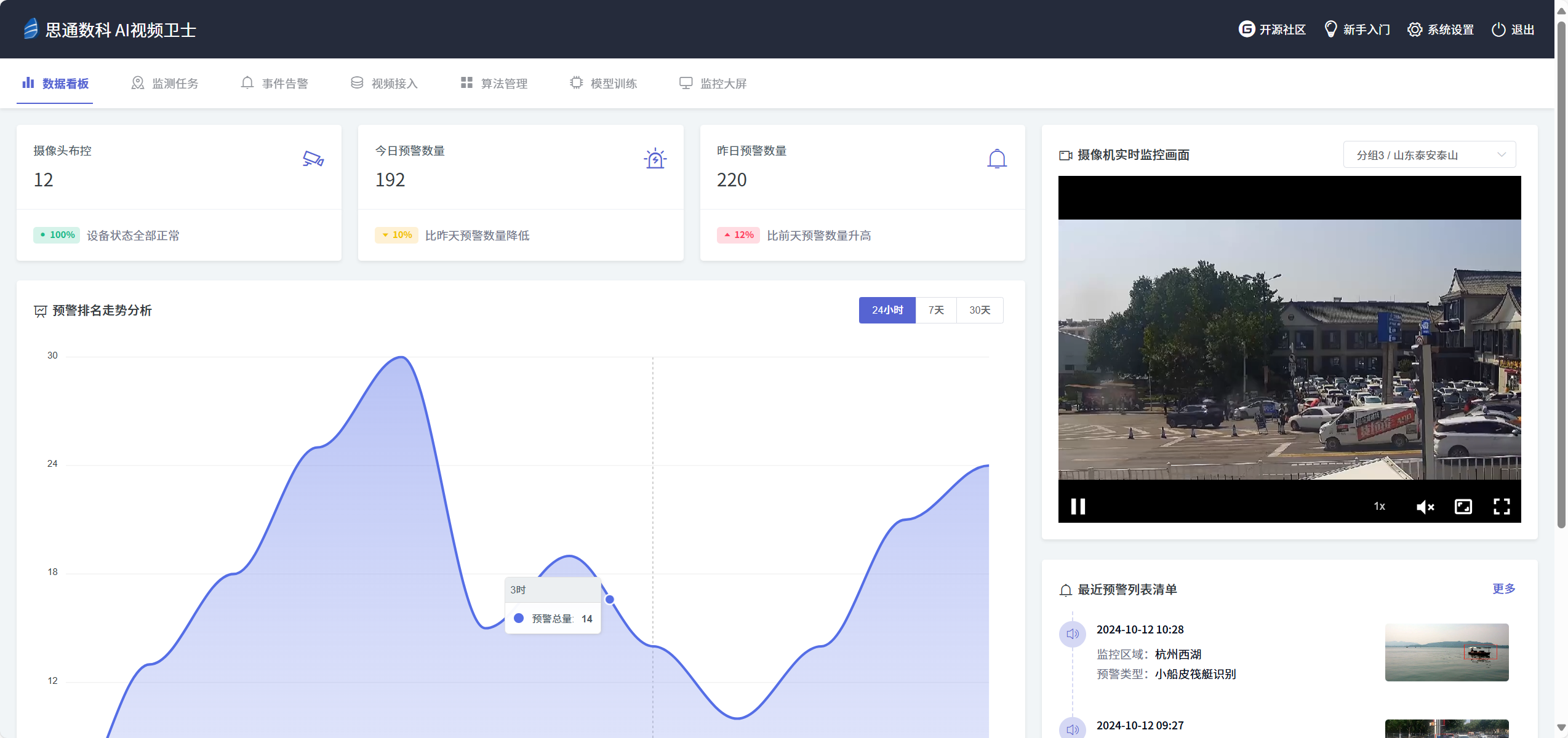
智慧城市路面垃圾识别系统产品介绍方案
方案介绍 智慧城市中的路面垃圾识别算法通常基于深度学习框架,这些算法因其在速度和精度上的优势而被广泛采用。这些模型能够通过训练识别多种类型的垃圾,包括塑料袋、纸屑、玻璃瓶等。系统通过训练深度学习模型,使其能够识别并定位多种类型…...

网络安全:构建坚固的数字堡垒
网络安全:构建坚固的数字堡垒 在当今数字化时代,网络安全已经成为企业和个人不可忽视的重要议题。随着互联网的普及和信息技术的快速发展,网络攻击、数据泄露和隐私侵犯等问题日益严重,给企业和个人带来了巨大的风险和损失。本文…...

LeetCode题练习与总结:打乱数组--384
一、题目描述 给你一个整数数组 nums ,设计算法来打乱一个没有重复元素的数组。打乱后,数组的所有排列应该是 等可能 的。 实现 Solution class: Solution(int[] nums) 使用整数数组 nums 初始化对象int[] reset() 重设数组到它的初始状态并返回int[]…...

科技改变生活:最新智能开关、调光器及插座产品亮相
根据QYResearch调研团队的最新力作《欧洲开关、调光器和插座市场报告2023-2029》显示,预计到2029年,欧洲开关、调光器和插座市场的规模将攀升至57.8亿美元,并且在接下来的几年里,将以4.2%的复合年增长率(CAGRÿ…...

传统RAG流程;密集检索器,稀疏检索器:中文的M3E
目录 传统RAG流程 相似性搜索中:神经网络的密集检索器,稀疏检索器 密集检索器 BGE系列模型 text-embedding-ada-002模型 M3E模型 稀疏检索器 示例一:基于TF-IDF的稀疏检索器 示例二:基于BM25的稀疏检索器 稀疏检索器的特点与优势 传统RAG流程 相似性搜索中:神经…...

基于统计方法的语言模型
基于统计方法的语言模型 基于统计方法的语言模型主要是指利用统计学原理和方法来构建的语言模型,这类模型通过分析和学习大量语料库中的语言数据,来预测词、短语或句子出现的概率。 N-gram模型:这是最基础的统计语言模型之一,它基…...

Flux comfyui 部署笔记,整合包下载
目录 comfyui启动: 1、下载 Flux 模型 2、Flux 库位置 工作流示例: Flux学习资料免费分享 comfyui启动: # 配置下载模型走镜像站 export HF_ENDPOINT="https://hf-mirror.com" python3 main.py --listen 0.0.0.0 --port 8188 vscode 点击 port 映射到本地,…...

高性能分布式缓存Redis-数据管理与性能提升之道
一、持久化原理 Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。除此…...

BO-CNN-LSTM回归预测 | MATLAB实现BO-CNN-LSTM贝叶斯优化卷积神经网络-长短期记忆网络多输入单输出回归预测
BO-CNN-LSTM回归预测 | MATLAB实现BO-CNN-LSTM贝叶斯优化卷积神经网络-长短期记忆网络多输入单输出回归预测 目录 BO-CNN-LSTM回归预测 | MATLAB实现BO-CNN-LSTM贝叶斯优化卷积神经网络-长短期记忆网络多输入单输出回归预测效果一览基本介绍模型搭建程序设计参考资料 效果一览 …...

DataWind将字符串数组拆出多行的方法
摘要: 可视化建模中先将字符串split为array再用explode(array)即可 可视化建模 进入“可视化建模”页面 1.1 新建任务 如果团队内没有可视化建模任务。请点击“新建任务”,输入名称并确定。 1.2 建立数据连接 在左边栏中选择“数据连接”,…...

try...catch 和then...catch的异同点分析
try…catch 和 then…catch 的异同点分析 在现代 JavaScript 编程中,异常处理和 Promise 的处理是非常常见的两种方式。try...catch 语句主要用于同步代码的异常处理,而 .then().catch() 是 Promise 中的异步处理方法。 1. 基础概念 1.1 try…catch …...
Mit6.S081-实验环境搭建
Mit6.S081-实验环境搭建 注:大家每次做一些操作的时候觉得不太保险就先把虚拟机克隆一份 前言 qemu(quick emulator):这是一个模拟硬件环境的软件,利用它可以运行我们编译好的操作系统。 准备一个Linux系统…...

以太网交换安全:MAC地址漂移
一、什么是MAC地址漂移? MAC地址漂移是指设备上一个VLAN内有两个端口学习到同一个MAC地址,后学习到的MAC地址表项覆盖原MAC地址表项的现象。 MAC地址漂移的定义与现象 基本定义:MAC地址漂移发生在一个VLAN内的两个不同端口学习到相同的MAC地…...

STM32实现串口接收不定长数据
原理 STM32实现串口接收不定长数据,主要靠的就是串口空闲(idle)中断,此中断的触发条件与接收的字节数无关,只有当Rx引脚无后续数据进入时(串口空闲时),认为这时候代表一个数据包接收完成了&…...

AAA 数据库事务隔离级别及死锁
目录 一、事务的四大特性(ACID) 1. 原子性(atomicity): 2. 一致性(consistency): 3. 隔离性(isolation): 4. 持久性(durability): 二、死锁的产生及解决方法 三、事务的四种隔离级别 0 .封锁协议 …...

外接数据库给streamlit等web APP带来的变化
之前我采用sreamlit制作了一个调查问卷的APP, 又使用MongoDB作为外部数据存储,隐约觉得外部数据库对于web APP具有多方面的意义,代表了web APP发展的趋势之一,似乎是作为对这种趋势的响应,streamlit官方近期开发了st.c…...

Gitpod: 我们正在离开 Kubernetes
原文:Christian Weichel - 2024.10.31 Kubernetes 似乎是构建远程、标准化和自动化开发环境的显而易见选择。我们也曾这样认为,并且花费了六年时间,致力于打造最受欢迎的云开发环境平台,并达到了互联网级的规模。我们的用户数量达…...

1.每日SQL----2024/11/7
题目: 计算用户次日留存率,即用户第二天继续登录的概率 表: iddevice_iddate121382024-05-03232142024-05-09332142024-06-15465432024-08-13523152024-08-13623152024-08-14723152024-08-15832142024-05-09932142024-08-151065432024-08-131123152024-…...

新手零基础入门:在快马平台用AI生成你的首个龙虾部署项目
新手零基础入门:在快马平台用AI生成你的首个龙虾部署项目 作为一个刚接触容器化开发的新手,第一次听说"龙虾部署"这个概念时,我完全摸不着头脑。后来才知道,这其实就是Docker容器化部署的一种形象说法。今天我想分享一…...
)
Anaconda环境下Spyder升级保姆级教程(附常见问题解决方案)
Anaconda环境下Spyder升级全攻略与疑难排解手册 在Python数据科学领域,Spyder作为专为科学计算设计的集成开发环境(IDE),凭借其变量查看器、交互式控制台和强大的调试功能,已成为众多研究人员的首选工具。而Anaconda作为Python科学计算的瑞士…...

intv_ai_mk11快速上手:浏览器输入URL→发送‘帮我写周报’→获得带数据亮点的Word格式草稿
intv_ai_mk11快速上手:浏览器输入URL→发送帮我写周报→获得带数据亮点的Word格式草稿 1. 什么是intv_ai_mk11 intv_ai_mk11是一款基于Llama架构的AI对话助手,拥有7B参数规模,运行在GPU服务器上。它能像真人助手一样理解你的需求࿰…...

OFA-VE环境部署:Python 3.11+PyTorch+CUDA一站式配置手册
OFA-VE环境部署:Python 3.11PyTorchCUDA一站式配置手册 1. 引言:认识OFA-VE视觉推理系统 OFA-VE是一个基于阿里巴巴达摩院OFA大模型构建的多模态推理平台,专门用于分析图像内容与文本描述之间的逻辑关系。这个系统采用了现代化的赛博朋克视…...

March7thAssistant:崩坏:星穹铁道企业级自动化解决方案
March7thAssistant:崩坏:星穹铁道企业级自动化解决方案 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 【核心价值定位】游戏工作室效率倍增引…...

从零部署到实战标注:SUSTechPOINTS 3D点云标注平台全流程指南
1. 为什么选择SUSTechPOINTS进行3D点云标注 在自动驾驶研发过程中,3D点云标注是个绕不开的苦差事。我最早用过不少商业标注工具,不是价格贵得离谱,就是功能残缺不全。直到去年团队接手一个校企合作项目,才发现南方科技大学开源的这…...

2026年AI Agent将迎来爆发!这五大趋势将重塑企业未来,你准备好了吗?
2026年AI Agent将进入规模化部署阶段,应用渗透率将大幅提升。文章分析了五大核心趋势:多智能体协同、企业级部署规模化、行业垂直化、可信性与透明度提升,以及人机协作模式重构。同时,文章也提醒企业需警惕项目失败风险࿰…...

激发创意:利用快马平台ai模型辅助设计与优化cmhhc算法
激发创意:利用快马平台AI模型辅助设计与优化CMHHC算法 最近在做一个字符串压缩相关的项目,需要实现一个自定义的压缩算法CMHHC。这个算法的核心思想其实很简单:对于连续出现的相同字符,用该字符加上出现次数来表示。比如"aa…...

3分钟上手弹幕盒子:零基础高效制作自定义弹幕的免费工具
3分钟上手弹幕盒子:零基础高效制作自定义弹幕的免费工具 【免费下载链接】danmubox.github.io 弹幕盒子 项目地址: https://gitcode.com/gh_mirrors/da/danmubox.github.io 弹幕盒子是一款专业的在线自定义弹幕生成工具,以轻量化架构设计为核心&a…...

C++的std--allocator_traits分配器特性与自定义内存管理的适配
C标准库中的内存管理一直是个既基础又复杂的主题。std::allocator_traits作为C11引入的分配器特性模板,为自定义内存管理提供了统一的适配接口,让开发者能在不重写整套分配逻辑的情况下,灵活扩展内存管理策略。无论是实现高性能内存池&#x…...