多线程和线程同步复习
多线程和线程同步复习
- 进程线程区别
- 创建线程
- 线程退出
- 线程回收
- 全局写法
- 传参写法
- 线程分离
- 线程同步
- 同步方式
- 互斥锁
- 互斥锁进行线程同步
- 死锁
- 读写锁
- api细说
- 读写锁进行线程同步
- 条件变量
- 生产者消费者案例
- 问题解答
- 加强版生产者消费者
- 总结
- 信号量
- 信号量实现生产者消费者同步-->一个资源
- 信号量实现生产者消费者同步-->多个资源
进程线程区别
- 进程是资源分配的最小单位,线程是操作系统调度执行的最小单位。
- 进程有自己独立的地址空间, 多个线程共用同一个地址空间
- 线程更加节省系统资源, 效率不仅可以保持的, 而且能够更高
在一个地址空间中多个线程独享: 每个线程都有属于自己的栈区, 寄存器(内核中管理的)
在一个地址空间中多个线程共享: 代码段, 堆区, 全局数据区, 打开的文件(文件描述符表)都是线程共享的- 线程是程序的最小执行单位, 进程是操作系统中最小的资源分配单位
每个进程对应一个虚拟地址空间,一个进程只能抢一个CPU时间片
一个地址空间中可以划分出多个线程, 在有效的资源基础上, 能够抢更多的CPU时间片- CPU的调度和切换: 线程的上下文切换比进程要快的多
- 线程更加廉价, 启动速度更快, 退出也快, 对系统资源的冲击小。
创建线程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 子线程的处理代码
void* working(void* arg)
{printf("我是子线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<9; ++i){printf("child == i: = %d\n", i);}return NULL;
}int main()
{// 1. 创建一个子线程pthread_t tid;pthread_create(&tid, NULL, working, NULL);printf("子线程创建成功, 线程ID: %ld\n", tid);// 2. 子线程不会执行下边的代码, 主线程执行printf("我是主线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<3; ++i){printf("i = %d\n", i);}// 休息, 休息一会儿...sleep(1);// >>>>>>>>>>>>>>>>>>>> 让主线程休息一会给子线程运行return 0;
}
子线程被创建出来之后需要抢cpu时间片, 抢不到就不能运行,如果主线程退出了, 虚拟地址空间就被释放了, 子线程就一并被销毁了。
这里的解决方案,让子线程执行完毕, 主线程再退出, 可以在主线程中添加挂起函数 sleep();

线程退出
子线程退出这个地址空间是存在的不影响主线程,这个线程退出函数实际上是服务于主线程的。这个函数作用是让主线程退出后子线程继续执行,而不回收这块虚拟地址空间,当子线程退出后这块虚拟地址空间就会被操作系统回收。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 子线程的处理代码
void* working(void* arg)
{printf("我是子线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<9; ++i){printf("child == i: = %d\n", i);}return NULL;
}int main()
{// 1. 创建一个子线程pthread_t tid;pthread_create(&tid, NULL, working, NULL);printf("子线程创建成功, 线程ID: %ld\n", tid);pthread_exit(NULL);return 0;
}

可以看出来主线程退出后是不影响子线程的执行
线程回收
#include <pthread.h>
// 这是一个阻塞函数, 子线程在运行这个函数就阻塞
// 子线程退出, 函数解除阻塞, 回收对应的子线程资源, 类似于回收进程使用的函数 wait()
int pthread_join(pthread_t thread, void **retval);
全局写法
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>struct Test
{int num;int age;
};
struct Test t;
// 子线程的处理代码
void* working(void* arg)
{for(int i=0; i<5; ++i){printf("子线程:i = %d\n", i);}printf("子线程ID: %ld\n", pthread_self());// struct Test t; >>>>>>>>>>> errt.num=100;t.age=66;pthread_exit(&t);return NULL;
}
int main()
{pthread_t tid;pthread_create(&tid, NULL, working, NULL);printf("主线程:%ld\n",pthread_self());void* ptr;pthread_join(tid,&ptr);struct Test* pt=(struct Test*)ptr;printf("num: %d,age = %d\n",pt->num,pt->age);return 0;
}

pthread_join(tid, &ptr); 的作用是等待子线程 tid 执行完毕,并将子线程通过 pthread_exit 返回的指针值保存到 ptr 中。

传参写法
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>struct Test
{int num;int age;
};// 子线程的处理代码
void* working(void* arg)
{for(int i=0; i<5; ++i){printf("子线程:i = %d\n", i);}printf("子线程ID: %ld\n", pthread_self());struct Test *t=(struct Test*)arg;t->num=100;t->age=66;pthread_exit(&t);return NULL;
}int main()
{pthread_t tid;struct Test t;pthread_create(&tid, NULL, working, &t);// >>>> 把主线程的栈空间给了子线程printf("主线程:%ld\n",pthread_self());void* ptr;pthread_join(tid,&ptr);printf("num: %d,age = %d\n",t.num,t.age);// >>>>>直接打印即可return 0;
}
pthread_join 只是等待线程 tid 执行完成,并获取线程 tid 的返回值。此时并没有释放或销毁传递给线程的参数 t
线程分离
在某些情况下,程序中的主线程有属于自己的业务处理流程,如果让主线程负责子线程的资源回收,调用pthread_join()只要子线程不退出主线程就会一直被阻塞,主要线程的任务也就不能被执行了。
调用这个函数之后指定的子线程就可以和主线程分离,当子线程退出的时候,其占用的内核资源就被系统的其他进程接管并回收了
当主线程退出的时候如果子线程还在工作直接就没了,因为虚拟地址空间被释放了
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 子线程的处理代码
void* working(void* arg)
{printf("我是子线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<9; ++i){printf("child == i: = %d\n", i);}return NULL;
}int main()
{// 1. 创建一个子线程pthread_t tid;pthread_create(&tid, NULL, working, NULL);printf("子线程创建成功, 线程ID: %ld\n", tid);// 2. 子线程不会执行下边的代码, 主线程执行printf("我是主线程, 线程ID: %ld\n", pthread_self());for(int i=0; i<3; ++i){printf("i = %d\n", i);}// 设置子线程和主线程分离pthread_detach(tid);// 让主线程自己退出即可pthread_exit(NULL);return 0;
}
子线程实际上被操作系统回收了
线程同步
线程同步并不是多个线程同时对内存进行访问,而是按照先后顺序依次进行的。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>#define MAX 50
// 全局变量
int number;// 线程处理函数
void* funcA_num(void* arg)
{for(int i=0; i<MAX; ++i){int cur = number;cur++;usleep(10);// >>>>>>>>>> 微秒number = cur;printf("Thread A, id = %lu, number = %d\n", pthread_self(), number);}return NULL;
}void* funcB_num(void* arg)
{for(int i=0; i<MAX; ++i){int cur = number;cur++;number = cur;printf("Thread B, id = %lu, number = %d\n", pthread_self(), number);usleep(5);}return NULL;
}int main(int argc, const char* argv[])
{pthread_t p1, p2;// 创建两个子线程pthread_create(&p1, NULL, funcA_num, NULL);pthread_create(&p2, NULL, funcB_num, NULL);// 阻塞,资源回收pthread_join(p1, NULL);pthread_join(p2, NULL);return 0;
}
这里创建了两个线程 funcA_num 和 funcB_num,它们分别对共享全局变量 number 进行加一操作并输出结果。然而,由于缺少对 number 的同步处理,会导致线程竞争,从而出现不一致的结果。这是因为在多线程环境中,number 的读写操作并不是原子性的,所以多个线程可能会对 number 进行相互覆盖的操作,导致不正确的输出结果。
具体解释:如果线程A执行这个过程期间就失去了CPU时间片,线程A被挂起了最新的数据没能更新到物理内存。线程B变成运行态之后从物理内存读数据,很显然它没有拿到最新数据,只能基于旧的数据往后数,然后失去CPU时间片挂起。线程A得到CPU时间片变成运行态,第一件事儿就是将上次没更新到内存的数据更新到内存,但是这样会导致线程B已经更新到内存的数据被覆盖,活儿白干了,最终导致有些数据会被重复数很多次。
同步方式
对于多个线程访问共享资源出现数据混乱的问题,需要进行线程同步。常用的线程同步方式有四种:互斥锁、读写锁、条件变量、信号量。所谓的共享资源就是多个线程共同访问的变量,这些变量通常为全局数据区变量或者堆区变量,这些变量对应的共享资源也被称之为临界资源。
通过锁机制能保证临界区代码最多只能同时有一个线程访问,这样并行访问就变为串行访问了。
互斥锁
一般情况下,每一个共享资源对应一个把互斥锁,锁的个数和线程的个数无关。
// 初始化互斥锁
// *******restrict: 是一个关键字, 用来修饰指针, 只有这个关键字修饰的指针可以访问指向的内存地址, 其他指针是不行的********
int pthread_mutex_init(pthread_mutex_t *restrict mutex,const pthread_mutexattr_t *restrict attr);
// 释放互斥锁资源
int pthread_mutex_destroy(pthread_mutex_t *mutex);
// 尝试加锁
int pthread_mutex_trylock(pthread_mutex_t *mutex);
互斥锁进行线程同步
加锁和解锁之间放的是临界区,加锁的是临界区的资源
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>#define MAX 50
// 全局变量
int number=0;
pthread_mutex_t mutex;// 线程处理函数
void* funcA_num(void* arg)
{for(int i=0; i<MAX; ++i){pthread_mutex_lock(&mutex);int cur = number;cur++;usleep(10);number = cur;pthread_mutex_unlock(&mutex);printf("Thread A, id = %lu, number = %d\n", pthread_self(), number);}return NULL;
}void* funcB_num(void* arg)
{for(int i=0; i<MAX; ++i){pthread_mutex_lock(&mutex);int cur = number;cur++;number = cur;pthread_mutex_unlock(&mutex);printf("Thread B, id = %lu, number = %d\n", pthread_self(), number);usleep(5);}return NULL;
}int main(int argc, const char* argv[])
{pthread_t p1, p2;pthread_mutex_init(&mutex,NULL);// 创建两个子线程pthread_create(&p1, NULL, funcA_num, NULL);pthread_create(&p2, NULL, funcB_num, NULL);// 阻塞,资源回收pthread_join(p1, NULL);pthread_join(p2, NULL);pthread_mutex_destroy(&mutex);return 0;
}死锁
加锁之后忘记解锁
重复加锁, 造成死锁
在程序中有多个共享资源, 因此有很多把锁,随意加锁,导致相互被阻塞
读写锁
之所以称其为读写锁,是因为这把锁既可以锁定读操作,也可以锁定写操作
使用读写锁锁定了读操作,需要先解锁才能去锁定写操作,反之亦然
特性:
使用读写锁的读锁锁定了临界区,线程对临界区的访问是并行的,读锁是共享的。
使用读写锁的写锁锁定了临界区,线程对临界区的访问是串行的,写锁是独占的。
使用读写锁分别对两个临界区加了读锁和写锁,两个线程要同时访问者两个临界区,访问写锁临界区的线程继续运行,访问读锁临界区的线程阻塞,因为写锁比读锁的优先级高。 >>>>>>>>>>>>>>>> 场景:读进程大于写进程数的时候
api细说
// 在程序中对读写锁加读锁, 锁定的是读操作
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);//调用这个函数,如果读写锁是打开的,那么加锁成功;**如果读写锁已经锁定了读操作**,**调用这个函数依然可以加锁成功,因为读锁是共享的**;如果读写锁已经锁定了写操作,调用这个函数的线程会被阻塞。// 在程序中对读写锁加写锁, 锁定的是写操作
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
//调用这个函数,如果读写锁是打开的,那么加锁成功;**如果读写锁已经锁定了读操作或者锁定了写操作,调用这个函数的线程会被阻塞。**
读写锁进行线程同步
8个线程操作同一个全局变量,3个线程不定时写同一全局资源,5个线程不定时读同一全局资源。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 全局变量
int number = 0;// 定义读写锁
pthread_rwlock_t rwlock;// 写的线程的处理函数
void* writeNum(void* arg)
{while(1){pthread_rwlock_wrlock(&rwlock);int cur = number;cur ++;number = cur;printf("++写操作完毕, number : %d, tid = %ld\n", number, pthread_self());pthread_rwlock_unlock(&rwlock);// 添加sleep目的是要看到多个线程交替工作sleep(rand() % 10);}return NULL;
}// 读线程的处理函数
// 多个线程可以如果处理动作相同, 可以使用相同的处理函数
// 每个线程中的栈资源是独享
void* readNum(void* arg)
{while(1){pthread_rwlock_rdlock(&rwlock);printf("--全局变量number = %d, tid = %ld\n", number, pthread_self());pthread_rwlock_unlock(&rwlock);sleep(rand() % 10);}return NULL;
}int main()
{// 初始化读写锁pthread_rwlock_init(&rwlock, NULL);// 3个写线程, 5个读的线程pthread_t wtid[3];pthread_t rtid[5];for(int i=0; i<3; ++i){pthread_create(&wtid[i], NULL, writeNum, NULL);}for(int i=0; i<5; ++i){pthread_create(&rtid[i], NULL, readNum, NULL);}// 释放资源for(int i=0; i<3; ++i){pthread_join(wtid[i], NULL);}for(int i=0; i<5; ++i){pthread_join(rtid[i], NULL);}// 销毁读写锁pthread_rwlock_destroy(&rwlock);return 0;
}

条件变量
严格意义上来说,条件变量的主要作用不是处理线程同步, 而是进行线程的阻塞。如果在多线程程序中只使用条件变量无法实现线程的同步, 必须要配合互斥锁来使用。虽然条件变量和互斥锁都能阻塞线程,但是二者的效果是不一样的,二者的区别如下:
条件变量只有在满足指定条件下才会阻塞线程,如果条件不满足,多个线程可以同时进入临界区,同时读写临界资源,这种情况下还是会出现共享资源中数据的混乱。
生产者消费者案例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 链表的节点
struct Node
{int number;struct Node* next;
};// 定义条件变量, 控制消费者线程
pthread_cond_t cond;
// 互斥锁变量
pthread_mutex_t mutex;
// 指向头结点的指针
struct Node * head = NULL;// 生产者的回调函数
void* producer(void* arg)
{// 一直生产while(1){pthread_mutex_lock(&mutex);// 创建一个链表的新节点struct Node* pnew = (struct Node*)malloc(sizeof(struct Node));// 节点初始化pnew->number = rand() % 1000;// 节点的连接, 添加到链表的头部, 新节点就新的头结点pnew->next = head;// head指针前移head = pnew;printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self());pthread_mutex_unlock(&mutex);// 生产了任务, 通知消费者消费pthread_cond_broadcast(&cond);// 生产慢一点sleep(rand() % 3);}return NULL;
}
// 消费者的回调函数
void* consumer(void* arg)
{while(1){pthread_mutex_lock(&mutex);// 一直消费, 删除链表中的一个节点while(head == NULL) // 这样写有bug// while(head == NULL){// 任务队列, 也就是链表中已经没有节点可以消费了// 消费者线程需要阻塞// 线程加互斥锁成功, 但是线程阻塞在这行代码上, 锁还没解开// 其他线程在访问这把锁的时候也会阻塞, 生产者也会阻塞 ==> 死锁// 这函数会自动将线程拥有的锁解开 >>>>>>>>>>>>>>>>> pthread_cond_wait(&cond, &mutex);// 当消费者线程解除阻塞之后, 会自动将这把锁锁上// 这时候当前这个线程又重新拥有了这把互斥锁}// 取出链表的头结点, 将其删除struct Node* pnode = head;printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self());head = pnode->next;free(pnode);pthread_mutex_unlock(&mutex);sleep(rand() % 3);}return NULL;
}int main()
{// 初始化条件变量pthread_cond_init(&cond, NULL);pthread_mutex_init(&mutex, NULL);// 创建5个生产者, 5个消费者pthread_t ptid[5];pthread_t ctid[5];for(int i=0; i<5; ++i){pthread_create(&ptid[i], NULL, producer, NULL);}for(int i=0; i<5; ++i){pthread_create(&ctid[i], NULL, consumer, NULL);}// 释放资源for(int i=0; i<5; ++i){// 阻塞等待子线程退出pthread_join(ptid[i], NULL);}for(int i=0; i<5; ++i){pthread_join(ctid[i], NULL);}// 销毁条件变量pthread_cond_destroy(&cond);pthread_mutex_destroy(&mutex);return 0;
}
问题解答
pthread_cond_wait(&cond, &mutex) 会在执行时释放锁,这是关键所在。
其它被这个消费者互斥锁阻塞的线程再这之后就会开始抢锁
消费者抢锁的操作是再pthread_cond_wait函数内部实现的
案例分析:前一个消费者消费完了链表为空,假设后面还有一个消费者被这个消费者阻塞后,此时生产者生产数据并调用 pthread_cond_broadcast(&cond) 唤醒所有等待的线程,由于前面一个消费者又一次消费完了,那个阻塞的消费者没有进行循环判断就接着消费就会发生段错误。
加强版生产者消费者
生产者设置上限,消费者设置下限,并且用两个条件变量
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>// 链表的节点
struct Node {int number;struct Node* next;
};// 定义两个条件变量, 分别控制生产者和消费者
pthread_cond_t cond_producer; // 生产者的条件变量
pthread_cond_t cond_consumer; // 消费者的条件变量
// 互斥锁变量
pthread_mutex_t mutex;
// 指向头结点的指针
struct Node * head = NULL;
// 生产者生产的上限
#define MAX_PRODUCE 5
// 生产者生产的计数器
int produced_count = 0;// 生产者的回调函数
void* producer(void* arg)
{while (1) {pthread_mutex_lock(&mutex);// 如果已经生产了 5 个任务,则停止生产if (produced_count >= MAX_PRODUCE) {pthread_mutex_unlock(&mutex);break; // 达到生产上限,退出生产}// 创建一个链表的新节点struct Node* pnew = (struct Node*)malloc(sizeof(struct Node));// 节点初始化pnew->number = rand() % 1000;// 节点的连接, 添加到链表的头部, 新节点就新的头结点pnew->next = head;// head指针前移head = pnew;produced_count++; // 更新生产计数器printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self());// 生产了任务, 通知消费者消费pthread_cond_signal(&cond_consumer);pthread_mutex_unlock(&mutex);// 生产慢一点sleep(rand() % 3);}return NULL;
}// 消费者的回调函数
void* consumer(void* arg)
{while (1) {pthread_mutex_lock(&mutex);// 一直消费, 删除链表中的一个节点while (head == NULL) {// 如果链表为空, 消费者线程等待生产者的通知pthread_cond_wait(&cond_consumer, &mutex);}// 取出链表的头结点, 将其删除struct Node* pnode = head;printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self());head = pnode->next;free(pnode);pthread_mutex_unlock(&mutex);sleep(rand() % 3);}return NULL;
}int main()
{// 初始化条件变量pthread_cond_init(&cond_producer, NULL);pthread_cond_init(&cond_consumer, NULL);pthread_mutex_init(&mutex, NULL);// 创建5个生产者, 5个消费者pthread_t ptid[5];pthread_t ctid[5];for (int i = 0; i < 5; ++i) {pthread_create(&ptid[i], NULL, producer, NULL);}for (int i = 0; i < 5; ++i) {pthread_create(&ctid[i], NULL, consumer, NULL);}// 阻塞等待线程退出for (int i = 0; i < 5; ++i) {pthread_join(ptid[i], NULL);}for (int i = 0; i < 5; ++i) {pthread_join(ctid[i], NULL);}// 销毁条件变量pthread_cond_destroy(&cond_producer);pthread_cond_destroy(&cond_consumer);pthread_mutex_destroy(&mutex);return 0;
}总结
不使用条件变量的生产者-消费者模型和使用条件变量的生产者-消费者模型
资源占用:使用条件变量的模型更高效,避免了不必要的 CPU 占用。
延迟:条件变量能更快地响应条件变化,不会因轮询间隔导致延迟。
代码复杂度:使用条件变量需要额外的代码来管理条件的等待和唤醒,但能提高性能。
信号量
信号量用在多线程多任务同步的,一个线程完成了某一个动作就通过信号量告诉别的线程,别的线程再进行某些动作。
信号量实现生产者消费者同步–>一个资源

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
#include <semaphore.h>
// 链表的节点
struct Node
{int number;struct Node* next;
};
//信号量
sem_t semp;
sem_t semc;struct Node * head = NULL;void* producer(void* arg)
{while(1){sem_wait(&semp);struct Node* pnew = (struct Node*)malloc(sizeof(struct Node));pnew->number = rand() % 1000;pnew->next = head;head = pnew;printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self());sem_post(&semc);sleep(rand() % 3);}return NULL;
}void* consumer(void* arg)
{while(1){sem_wait(&semc);struct Node* pnode = head;printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self());head = pnode->next;free(pnode);sem_post(&semp);sleep(rand() %3);}return NULL;
}
int main()
{//生产者sem_init(&semp,0,1);//资源只有一个,虽然线程很多但是都是被阻塞的//消费者 --> 资源初始化为0 sem_init(&semc,0,0);pthread_t ptid[5];pthread_t ctid[5];for(int i=0; i<5; ++i){pthread_create(&ptid[i], NULL, producer, NULL);}for(int i=0; i<5; ++i){pthread_create(&ctid[i], NULL, consumer, NULL);}// 释放资源for(int i=0; i<5; ++i){// 阻塞等待子线程退出pthread_join(ptid[i], NULL);}for(int i=0; i<5; ++i){pthread_join(ctid[i], NULL);}sem_destroy(&semp);sem_destroy(&semc);return 0;
}
信号量实现生产者消费者同步–>多个资源
假设资源数是>1的,此时如果多个生产者同时对链表进行添加数据这样是有问题的!
因此要通过锁来让这些线程线性执行
上面这种情况消费者是不能够通知消费者去生产的,此时生产者由于消费者都没通知所有生产者也阻塞了,这样的话就没有任何一个线程在工作–>问题大了!

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
#include <semaphore.h>
// 链表的节点
struct Node
{int number;struct Node* next;
};
//信号量
sem_t semp;
sem_t semc;
pthread_mutex_t mutex;struct Node * head = NULL;void* producer(void* arg)
{while(1){sem_wait(&semp);pthread_mutex_lock(&mutex);struct Node* pnew = (struct Node*)malloc(sizeof(struct Node));pnew->number = rand() % 1000;pnew->next = head;head = pnew;printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self());pthread_mutex_lock(&mutex);sem_post(&semc);sleep(rand() % 3);}return NULL;
}void* consumer(void* arg)
{while(1){sem_wait(&semc);pthread_mutex_lock(&mutex);struct Node* pnode = head;printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self());head = pnode->next;free(pnode);pthread_mutex_lock(&mutex);sem_post(&semp);sleep(rand() %3);}return NULL;
}int main()
{//生产者sem_init(&semp,0,5);//资源只有一个,虽然线程很多但是都是被阻塞的//消费者 --> 资源初始化为0 sem_init(&semc,0,0);pthread_mutex_init(&mutex, NULL);pthread_t ptid[5];pthread_t ctid[5];for(int i=0; i<5; ++i){pthread_create(&ptid[i], NULL, producer, NULL);}for(int i=0; i<5; ++i){pthread_create(&ctid[i], NULL, consumer, NULL);}// 释放资源for(int i=0; i<5; ++i){// 阻塞等待子线程退出pthread_join(ptid[i], NULL);}for(int i=0; i<5; ++i){pthread_join(ctid[i], NULL);}sem_destroy(&semp);sem_destroy(&semc);pthread_mutex_destroy(&mutex);return 0;
}

在生产者-消费者模型中会出现“解锁和通知消费者之间有生产者加锁”的情况
相关文章:
多线程和线程同步复习
多线程和线程同步复习 进程线程区别创建线程线程退出线程回收全局写法传参写法 线程分离线程同步同步方式 互斥锁互斥锁进行线程同步 死锁读写锁api细说读写锁进行线程同步 条件变量生产者消费者案例问题解答加强版生产者消费者 总结信号量信号量实现生产者消费者同步-->一个…...

贝式计算的 AI4S 观察:使用机器学习对世界进行感知与推演,最大魅力在于横向扩展的有效性
「传统研究方法高度依赖于科研人员自身的特征和问题定义能力,通常采用小数据,在泛化能力和拓展能力上存疑。而 AI 研究方法则需要引入大规模、高质量数据,并采用机器学习进行特征抽取,这使得产生的科研结果在真实世界的问题中非常…...
容器化技术入门:Docker详解
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 容器化技术入门:Docker详解 容器化技术入门:Docker详解 容器化技术入门:Docker详解 引言 Doc…...
框架的药房管理系统)
基于SSM(Spring + Spring MVC + MyBatis)框架的药房管理系统
基于SSM(Spring Spring MVC MyBatis)框架的药房管理系统 项目概述 功能需求 用户管理:管理员可以添加、删除、修改和查询用户信息。药品管理:支持对药品信息的增删改查操作,包括药品名称、价格、库存量等。供应商…...

在服务器里安装2个conda
1、安装新的conda 下载地址:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 本文选择:Anaconda3-2023.03-1-Linux-x86_64.sh 安装:Ubuntu安装Anaconda详细步骤(Ubuntu22.04.1ÿ…...

web安全漏洞之ssrf入门
web安全漏洞之ssrf入门 1.什么是ssrf SSRF(Server Side Request Forgery,服务端请求伪造)是一种通过构造数据进而伪造成服务端发起请求的漏洞。因为请求是由服务器内部发起,所以一般情况下SSRF漏洞的目标往往是无法从外网访问的内系统。 SSRF漏洞形成的原理多是服务…...

《NoSQL 基础知识总结》
在当今的数据存储和管理领域,NoSQL 数据库正逐渐崭露头角,成为许多应用场景下的有力选择。今天,我们就来一起深入了解一下 NoSQL 的基础知识吧。 一、什么是 NoSQL? NoSQL,即 “Not Only SQL”,它是一种不…...

高校宿舍信息管理系统小程序
作者主页:编程千纸鹤 作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参…...

2.索引:MySQL 索引分类
MySQL中的索引是提高数据查询速度的重要工具,就像一本书的目录,可以帮助我们快速定位到所需的内容。选择适合的索引类型对数据库设计和性能优化至关重要。本文将详细介绍MySQL中常见的索引类型,并重点讲解聚集索引和二级索引的概念及应用。 1…...

sklearn红酒数据集分类器的构建和评估
实验目的: 1. 掌握sklearn科学数据包中决策树和神经网络分类器的构建 2. 掌握对不同分类器进行综合评估 实验数据: 红酒数据集 红酒数据集利用红酒的化学特征来描述三种不同类型的葡萄酒。 实验内容与要求: 解压文件得到wine数据。利用pa…...

【IC验证面试常问-4】
IC验证面试常问-4 1.11 struct和union的异同1.13 rose 和posedge 的区别?1.14 semaphore的用处是什么?1.15 类中的静态方法使用注意事项有哪些?1.16 initial和final的区别? s t o p , stop, stop,finish的区别1.17 logic,wire和re…...

【数据集】【YOLO】【目标检测】交通事故识别数据集 8939 张,YOLO道路事故目标检测实战训练教程!
数据集介绍 【数据集】道路事故识别数据集 8939 张,目标检测,包含YOLO/VOC格式标注。数据集中包含2种分类:{0: accident, 1: non-accident}。数据集来自国内外图片网站和视频截图。检测范围道路事故检测、监控视角检测、无人机视角检测、等&…...
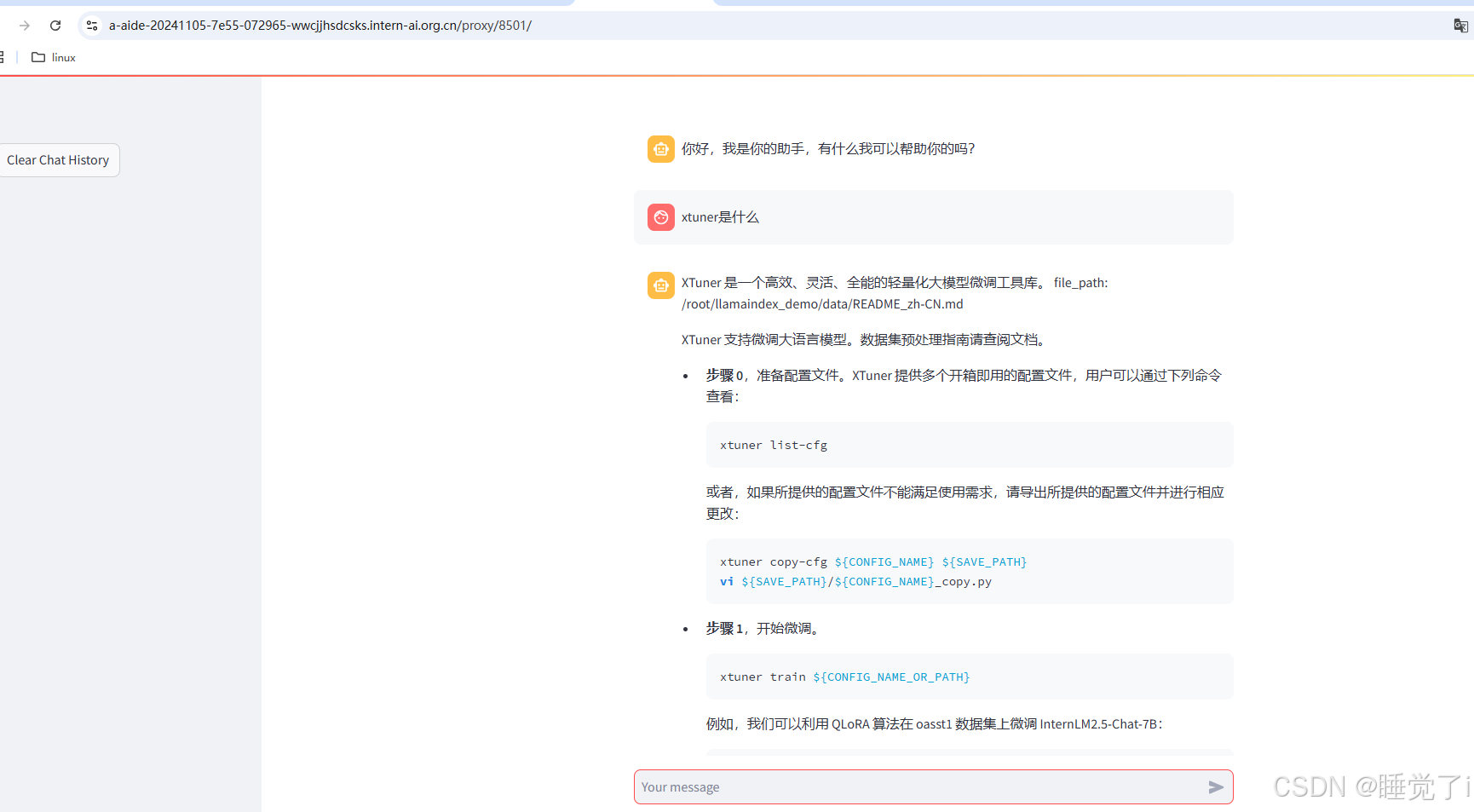
书生浦语第四期基础岛L1G4000-InternLM + LlamaIndex RAG 实践
文章目录 一、任务要求11.首先创建虚拟环境2. 安装依赖3. 下载 Sentence Transformer 模型4.下载 NLTK 相关资源5. 是否使用 LlamaIndex 前后对比6. LlamaIndex web7. LlamaIndex本地部署InternLM实践 一、任务要求1 任务要求1(必做,参考readme_api.md&…...

基于ViT的无监督工业异常检测模型汇总
基于ViT的无监督工业异常检测模型汇总 论文1:VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization(2021)1.1 主要思想1.2 系统框架 论文2:Inpainting Transformer for Anomaly Detection…...

数据库管理-第258期 23ai:Oracle Data Redaction(20241104)
数据库管理258期 2024-11-04 数据库管理-第258期 23ai:Oracle Data Redaction(20241104)1 简介2 应用场景与有点3 多租户环境4 特性与能力4.1 全数据编校4.2 部分编校4.3 正则表达式编校4.4 随机编校4.5 空值编校4.6 无编校4.7 不同数据类型上…...

运放进阶篇-多种波形可调信号发生器-产生方波-三角波-正弦波
引言:前几节我们已经说到硬件相关基础的电路,以及对于运放也讲到了初步的理解,特别是比较器的部分,但是放大器的部分我们对此并没有阐述,在这里通过实例进行理论结合实践的学习。而运放真正的核心,其实就是…...

CSS中的变量应用——:root,Sass变量,JavaScript中使用Sass变量
:root—— 原生CSS 自定义属性(变量) 在 SCSS 文件中定义 CSS 自定义属性。然后通过 JavaScript 读取这些属性。 // variables.scss :root { --login-bg-color: #293146;--left-menu-max-width: 200px;--left-menu-min-width: 64px;--left-menu-bg-…...

WPF+MVVM案例实战与特效(二十八)- 自定义WPF ComboBox样式:打造个性化下拉菜单
文章目录 1. 引言案例效果3. ComboBox 基础4. 自定义 ComboBox 样式4.1 定义 ComboBox 样式4.2 定义 ComboBoxItem 样式4.3 定义 ToggleButton 样式4.4 定义 Popup 样式5. 示例代码6. 结论1. 引言 在WPF应用程序中,ComboBox控件是一个常用的输入控件,用于从多个选项中选择一…...

速盾:怎么使用cdn加速?
CDN(Content Delivery Network)即内容分发网络,是一种通过在网络各处部署节点来缓存和传输网络内容的技术。通过使用CDN加速,可以提高网站的访问速度、减轻服务器负载、提供更好的用户体验。 使用CDN加速的步骤如下: …...

C++ 优先算法 —— 三数之和(双指针)
目录 题目:三数之和 1. 题目解析 2. 算法原理 ①. 暴力枚举 ②. 双指针算法 不漏的处理: 去重处理: 固定一个数 a 的优化: 3. 代码实现 Ⅰ. 暴力枚举(会超时 O(N)) Ⅱ.…...

晶晨T972嵌入式主板开发指南:从硬件选型到量产部署
1. 项目概述:一颗“芯”引发的性价比革命 最近在嵌入式开发圈和智能硬件圈里,一个消息传得挺火:亮钻推出了一款基于晶晨T972平台的高性价比主板。对于很多正在寻找稳定、高性能且成本可控的解决方案的开发者、产品经理和创客来说,…...

WinForm用户控件调试踩坑记:从‘无法试运行’到完美模块测试的完整流程
WinForm用户控件调试实战:从模块移植到精准测试的完整指南 引言:为什么需要独立的控件测试环境? 在WinForm开发中,用户控件(UserControl)的复用与调试一直是让开发者头疼的问题。当你在主项目中直接测试一个复杂控件时,…...
实战:D310T9362V1SPEC触摸屏驱动从零适配与调试(竖屏))
RK3566(泰山派)实战:D310T9362V1SPEC触摸屏驱动从零适配与调试(竖屏)
1. RK3566与D310T9362V1SPEC屏幕简介 RK3566是瑞芯微推出的一款高性能嵌入式处理器,采用四核Cortex-A55架构,主频可达1.8GHz。这款芯片在工业控制、智能家居和物联网设备中广泛应用,特别适合需要图形显示和触摸交互的场景。我最近在一个智能终…...

如何让GBFR-Logs成为你的碧蓝幻想Relink战斗分析利器
如何让GBFR-Logs成为你的碧蓝幻想Relink战斗分析利器 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs 你是否在《碧蓝幻…...

智慧巡检-基于Yolo26的目标检测系统 带登录界面的基于Yolo26的目标检测系统完整源码+原始ui文件+环境配置教程 相关技术文档包含:2万字算法文档+详细操作指南+技术设计文档+流程图+yolo
智慧巡检-基于Yolo26的目标检测系统带登录界面的基于Yolo26的目标检测系统完整源码原始ui文件环境配置教程 相关技术文档包含:2万字算法文档详细操作指南技术设计文档流程图yolo26网络结构图各文件作用说明 可视化界面基于pyside6,数据库为sqlite3&#…...
)
CentOS 7/8下Nginx报`unknown directive “stream“`?可能是你的安装方式不对(附完整修复流程)
CentOS下Nginx报unknown directive "stream"的深度解析与解决方案 当你在CentOS系统上配置Nginx的stream模块时,突然遇到unknown directive "stream"的错误提示,这往往意味着你的Nginx安装并不完整。这个问题看似简单,背…...

Hyper-V DDA图形工具:5分钟完成GPU直通的终极指南
Hyper-V DDA图形工具:5分钟完成GPU直通的终极指南 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 还在为复杂的Hyper-V离散…...

Visual C++运行库终极指南:如何3分钟解决Windows软件启动失败问题
Visual C运行库终极指南:如何3分钟解决Windows软件启动失败问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的场景…...

实战解析:如何通过显卡频率优化解决CUDA/TensorRT推理速度骤降问题
1. 从异常现象到问题定位 最近在部署一个基于YOLOv5的工业检测系统时,遇到了一个让人头疼的问题:当系统从连续检测模式切换到条件触发模式后,原本飞快的CUDA推理速度突然下降了近5倍。更诡异的是,降低相机帧率后,推理…...

第08章 FastAPI 与 SSE 流式 RAG 后端
第08章 FastAPI 与 SSE 流式 RAG 后端 到目前为止,知识库、检索工具、MCP 客户端都已经就绪,但仍缺少一个面向最终用户的入口。本章用 FastAPI 把整条 RAG 链路串起来:接收前端发来的自然语言问题,调用 MCP 工具检索相关工单&…...