构建基于 DCGM-Exporter, Node exporter,PROMETHEUS 和 GRAFANA 构建算力监控系统
目录
- 引言
- 工具作用
- 概述
- DCGM-Exporter
- Node exporter
- PROMETHEUS
- GRAFANA
- 小结
- 部署
- 单容器
- DCGM-Exporter
- Node exporter
- PROMETHEUS
- GRAFANA
- Node exporter
- DCGM-Exporter
- 多容器
- Node exporter
- DCGM-Exporter
- Docker Compose
- 参考
引言
本文的是适用对象,是希望通过完全基于Docker ,实现对于一个较小的算力群,比如大学课题组的多台服务器,实现CPU和GPU的资源使用监控。
工具作用
概述
目前的大多数教程都倾向于详细讲解DCGM,Node exporter,PROMETHEUS 和 GRAFANA 的概念,设计和作用,使得这一系统的部署问题变得非常复杂。本文倾向于直接部署直接应用,所以不死磕原理,而直接概述其作用,能够基本认识到它们的作用,然后实现部署。
DCGM-Exporter
- GitHub: https://github.com/NVIDIA/dcgm-exporter
- 作用:DCGM-Exporter 主要用于收集主机或者节点上的GPU的数据,并且通过端口暴露数据。
Node exporter
- GitHub: https://github.com/prometheus/node_exporter
- 作用:Node exporter 主要用于收集主机或者节点上的CPU,内存,磁盘等硬件信息,并且通过端口暴露数据。
PROMETHEUS
- GitHub: https://github.com/prometheus/prometheus
- 作用:Prometheus 主要是作为数据库存储各个主机和节点所暴露出的数据。
GRAFANA
-GitHub: https://github.com/grafana/grafana
- 作用:grafana 则是通过面板将监控数据进行可视化或者其他操作。
小结
Node exporter 和 DCGM-Exporter 分别用于收集主机或者节点上的数据;而 PROMETHEUS 则负责存储这些数据;GRAFANA 最后将这些监控数据可视化呈现。
部署
单容器
我们可以通过docker命令在主机或者节点上部署容器实现对应的服务
DCGM-Exporter
对于DCGM-Exporter,参考 https://github.com/NVIDIA/dcgm-exporter,我们可以参考它的官方文档的命令予以部署
docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04
但是其实这个命令可以优化一下,加入自动重启的参数,因为对应的机器偶尔难免需要重启,每次人为的重启容器非常麻烦。同时也需要对应的配置Docker 重启,改进后的命令如下:
docker run -d --restart=always --gpus all -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.6-3.4.2-ubuntu22.04
这样一来,DCGM-Exporter 的数据将通过主机的 9400端口暴露。
Node exporter
对于Node exporter,参考https://github.com/prometheus/node_exporter,文档所推荐的命令为
docker run -d \--net="host" \--pid="host" \-v "/:/host:ro,rslave" \quay.io/prometheus/node-exporter:latest \--path.rootfs=/host同样可以加入自动重启的参数,改进后的命令为
docker run -d --restart=always\
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host
这样一来,Node exporter 的数据将通过主机的 9100端口暴露。
PROMETHEUS
前面已经提到,DCGM-Exporter 和 Node exporter 暴露数据以后,我们需要 PROMETHEUS 将数据保存起来,所以我们需要通过配置文件告诉 PROMETHEUS 暴露数据的exporter 在哪里,
所以我们需要编写配置文件,以Node exporter 为例,我们可以编写 ·prometheus_cpu.yml· 的配置文件:
# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "NAME YOU LIKE"static_configs:- targets: ['1.1.1.1:9100']labels:instance: 'name1'- targets: ['2.2.2.2:9100']labels:instance: 'name2'- targets: ['3.3.3.3:9100']labels:instance: 'name3'- targets: ['4.4.4.4:9100']labels:instance: 'name4'因为 prometheus 是一个数据库容器,所以我们需要对它做数据持久化,把它的数据挂载在本地,所以我们可以运行如下命令进行部署
sudo docker run -d \
--restart=always \
--net="host" \
--pid="host" \
-v "/home/xxx/node_export_data:/host:ro,rslave" \
-v "./prometheus_cpu.yml:/etc/prometheus/prometheus.yml" \
-p 9090:9090
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host
对于 DCGM-Exporter 所对应的GPU的数据同理操作即可。
于是我们可以通过我们所配置的9090端口访问prometheus。
GRAFANA
在数据成功由 prometheus 保存以后,接下来我们需要使用面板将其可视化
此时可以部署GRAFANA 实现,按照官方文档的描述,可以通过运行
docker run -d -p 3000:3000 --name=grafana grafana/grafana-enterprise
来运行 GRAFANA ,然后访问对应的3000即可。
需要注意的是,对于不同的node exporter 需要使用不同的dashboard
- Node exporter:Node Exporter Full
- DCGM-Exporter: NVIDIA DCGM Exporter Dashboard
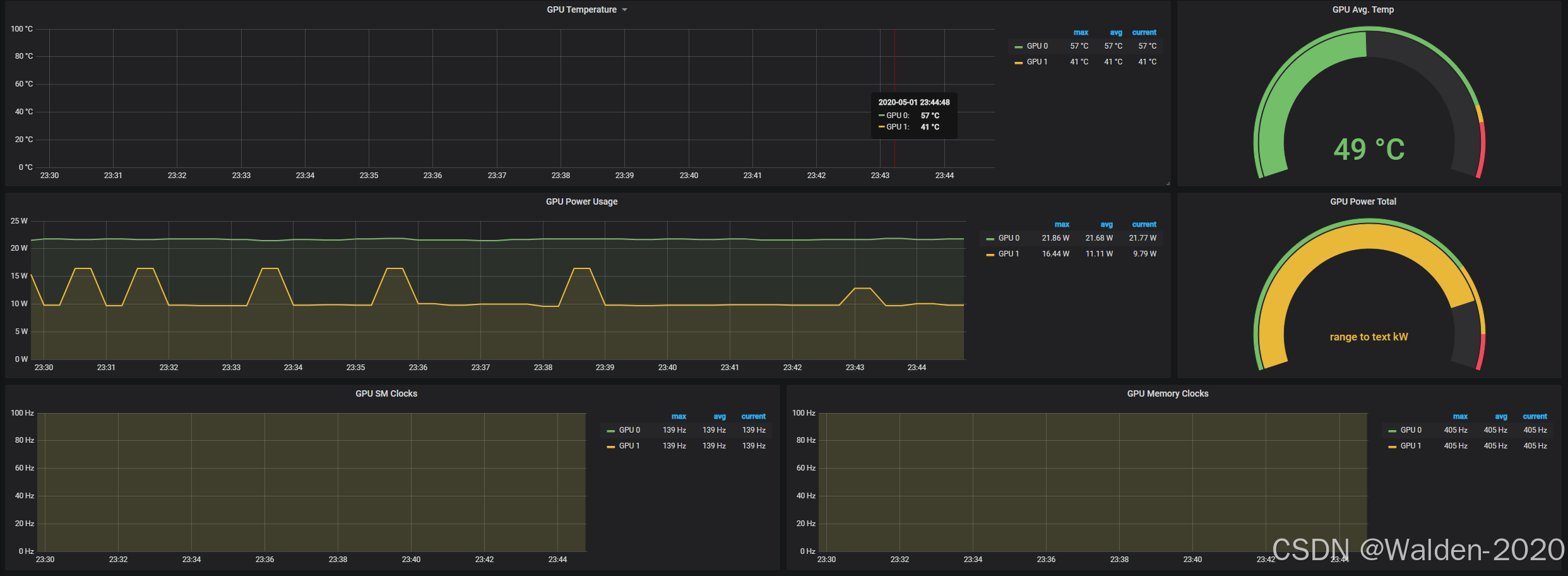
Node exporter

图源:https://grafana.com/api/dashboards/1860/images/7994/image
DCGM-Exporter
图源:https://grafana.com/api/dashboards/12239/images/8088/image
然后我们通过登录 GRAFANA ,配置prometheus数据源,选择不同的dashboard,即可实现监控数据的可视化;
多容器
事实上,当我们面对一个计算机集群部署时候,我们不太可能逐容器部署,我们往往会在需要监控的机器上部署DCGM-Exporter和Node exporter,而选择一台机器作为Server,来同时承担 PROMETHEUS 和 GRAFANA 的角色,并且这台机器本身可能也要部署 DCGM-Exporter和Node exporter,于是,我们需要使用Docker compose 实现多容器同时部署;
Node exporter
对于本机的 Node exporter,我们依然是单独部署,然后在配置prometheus时,使用主机IP地址
- targets: ['1.2.3.6:9100']labels:instance: 'localhost'
DCGM-Exporter
对于本机的DCGM-Exporter,则可以通过Docker compose 一次性部署;
假如我们在docker compose 里为 DCGM-Exporter 取的名字是gpu_exporter
则在编写prometheus_gpu.yml时,我们可以直接配置
- targets: ['gpu_exporter:9400']labels:instance: 'localhost'
Docker Compose
加入我们已经提前写好了 prometheus_cpu.yml 和 prometheus_gpu.yml
那么我们可以同时在一台机器上部署 DCGM-Exporter, PROMETHEUS 和 GRAFANA,docker-compose.yml的内容如下:
version: '3.8'services:prometheus_cpu:image: prom/prometheus:latestcontainer_name: prometheus_cpuuser: rootvolumes:- /path/prometheus_cpu.yml:/etc/prometheus/prometheus.yml- /path/prometheus_cpu_data:/prometheus command:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus/'- '--storage.tsdb.retention.time=45d'ports:- "9200:9090"networks:- monitoringprometheus_gpu:image: prom/prometheus:latestcontainer_name: prometheus_gpuuser: rootvolumes:- /path/prometheus_gpu.yml:/etc/prometheus/prometheus.yml- /path/prometheus_gpu_data:/prometheus command:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus/'- '--storage.tsdb.retention.time=45d'ports:- "9800:9090"networks:- monitoringdepends_on:- gpu_exportergpu_exporter:image: nvidia/dcgm-exporter:3.3.6-3.4.2-ubuntu22.04container_name: gpu_exporterruntime: nvidiaenvironment:- NVIDIA_VISIBLE_DEVICES=allports:- "9400:9400"networks:- monitoringdeploy:resources:reservations:devices:- capabilities: [gpu]networks:monitoring:driver: bridge理论上来说,可以同时部署上 GRAFANA,但是因为我们在部署的时候并没有成功,后面把 GRAFANA 部署到另外一台机器上得以实现;
但是此处想重点表达的是 prometheus_cpu 和 prometheus_gpu 和 gpu_exporter 是可以实现一次性部署的。
此处可以给出一个由GitHub Copilot 协助完成的完整的docker-compose.yml 以供参考
version: '3.8'services:prometheus_cpu:image: prom/prometheus:latestcontainer_name: prometheus_cpuuser: rootvolumes:- /path/prometheus_cpu.yml:/etc/prometheus/prometheus.yml- /path/prometheus_cpu_data:/prometheus command:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus/'- '--storage.tsdb.retention.time=45d'ports:- "9200:9090"networks:- monitoringprometheus_gpu:image: prom/prometheus:latestcontainer_name: prometheus_gpuuser: rootvolumes:- /path/prometheus_gpu.yml:/etc/prometheus/prometheus.yml- /path/prometheus_gpu_data:/prometheus command:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus/'- '--storage.tsdb.retention.time=45d'ports:- "9800:9090"networks:- monitoringdepends_on:- gpu_exportergpu_exporter:image: nvidia/dcgm-exporter:3.3.6-3.4.2-ubuntu22.04container_name: gpu_exporterruntime: nvidiaenvironment:- NVIDIA_VISIBLE_DEVICES=allports:- "9400:9400"networks:- monitoringdeploy:resources:reservations:devices:- capabilities: [gpu]grafana:image: grafana/grafana:latestcontainer_name: grafanaports:- "3000:3000"environment:- GF_SECURITY_ADMIN_PASSWORD=adminvolumes:- grafana_data:/var/lib/grafananetworks:- monitoringdepends_on:- prometheus_cpu- prometheus_gpunetworks:monitoring:driver: bridgevolumes:grafana_data:
在编写完 docker-compose.yml 文件以后,在对应的文件下,执行命令:
docker-compose up
即可运行服务,至此,可完成对一个小的计算机群的算力资源的监控。
参考
- HOW TO MONITOR NVIDIA GPUs USING DCGM, PROMETHEUS AND GRAFANA
相关文章:
构建基于 DCGM-Exporter, Node exporter,PROMETHEUS 和 GRAFANA 构建算力监控系统
目录 引言工具作用概述DCGM-ExporterNode exporterPROMETHEUSGRAFANA小结 部署单容器DCGM-ExporterNode exporterPROMETHEUSGRAFANANode exporterDCGM-Exporter 多容器Node exporterDCGM-ExporterDocker Compose 参考 引言 本文的是适用对象,是希望通过完全基于Doc…...

第13章 聚合函数
一、聚合函数介绍 实际上 SQL 函数还有一类,叫做聚合(或聚集、分组)函数,它是对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。(可以是一个字段的数据,也可以是通…...
)
【计网不挂科】计算机网络期末考试——【选择题&填空题&判断题&简述题】试卷(4)
前言 大家好吖,欢迎来到 YY 滴计算机网络 系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 本博客主要内容,收纳了一部门基本的计算机网络题目,供yy应对期中考试复习。大家可以参考 本章是去答案版本。带答案的版本在下…...

C# 中 LibraryImport 和 DllImport有什么不同
libraryimport 和 dllimport 是两个与动态链接库(DLL)相关的术语,它们在不同的编程语言和上下文中有不同的含义和用途。 在 C# 中,DllImportAttribute 是一个特性,用于指示一个方法声明是作为对非托管 DLL 中函数的 P…...

PDF编辑工具Adobe Acrobat DC 2023安装教程(附安装包)
Adobe Acrobat DC 2023 是 Adobe 公司推出的一款功能强大的 PDF 文档处理软件。它不仅支持创建、编辑和签署 PDF 文件,还提供了丰富的工具来管理和优化这些文件。以下是 Acrobat DC 2023 的一些主要特点: 1.PDF 创建与编辑:用户可以直接从多…...

系动词、表语和主语补足语
系动词、表语和主语补足语 1. The classification of English verbs (英语动词的分类)2. 系动词 (连系动词)2.1. Grammatical function (语法功能) 3. 表语和主语补足语3.1. Predicative expression (表语)3.2. Subject complement (主语补足语) 4. Copula-like words4.1. List…...
【网络安全 | 并发问题】Nginx重试机制与幂等性问题分析
未经许可,不得转载。 文章目录 业务背景Nginx的错误重试机制proxy_next_upstream指令配置重试500状态码非幂等请求的重试问题幂等性和非幂等性请求non_idempotent选项的使用解决方案业务背景 在现代互联网应用中,高可用性(HA)是确保系统稳定性的关键要求之一。为了应对服务…...

Java 详解 接口
文章目录 一、概述1.1、何为接口1.2、接口的定义 二、特点2.1、接口的成员变量2.2、接口的成员方法2.3、接口中不可以含有构造器和代码块2.4、接口不可以实例化对象2.5、接口和类之间使用implements关键字进行连接2.6、当类在重写接口中的方法时,不可以使用默认的访…...

wordpress搬家迁移后怎么修改数据库用户名
在WordPress中修改数据库用户名,你需要更新WordPress的配置文件wp-config.php。以下是步骤和示例代码: 使用FTP客户端或文件管理器登录到你的网站的主机账户。 找到wp-config.php文件,它通常位于WordPress安装的根目录中。 打开wp-config.…...

C# 用于将一个DataTable转换为Users对象的列表
1:第一种例子: /// <summary> /// 用户名循环赋值 /// </summary> /// <param name"dt"></param> /// <returns></returns> public List<Users> FenPeiFillModelUsers(DataTable dt) { …...

Spark中的shuffle
Shuffle的本质基于磁盘划分来解决分布式大数据量的全局分组、全局排序、重新分区【增大】的问题。 1、Spark的Shuffle设计 Spark Shuffle过程也叫作宽依赖过程,Spark不完全依赖于内存计算,面临以上问题时,也需要Shuffle过程。 2、Spark中哪…...
网络安全SQL初步注入2
六.报错注入 mysql函数 updatexml(1,xpath语法,0) xpath语法常用concat拼接 例如: concat(07e,(查询语句),07e) select table_name from information_schema.tables limit 0,1 七.宽字节注入(如果后台数据库的编码为GBK) url编码:为了防止提交的数据和url中的一些有特殊意…...
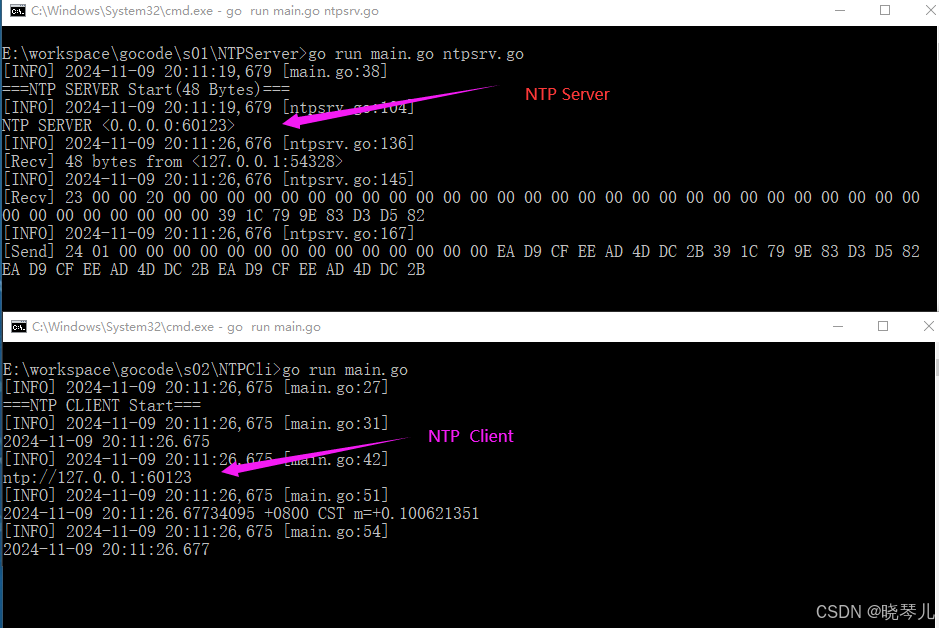
使用Go语言编写一个简单的NTP服务器
NTP服务介绍 NTP服务器【Network Time Protocol(NTP)】是用来使计算机时间同步化的一种协议。 应用场景说明 为了确保封闭局域网内多个服务器的时间同步,我们计划部署一个网络时间同步服务器(NTP服务器)。这一角色将…...

注意力机制篇 | YOLO11改进 | 即插即用的高效多尺度注意力模块EMA
前言:Hello大家好,我是小哥谈。与传统的注意力机制相比,多尺度注意力机制引入了多个尺度的注意力权重,让模型能够更好地理解和处理复杂数据。这种机制通过在不同尺度上捕捉输入数据的特征,让模型同时关注局部细节和全局…...
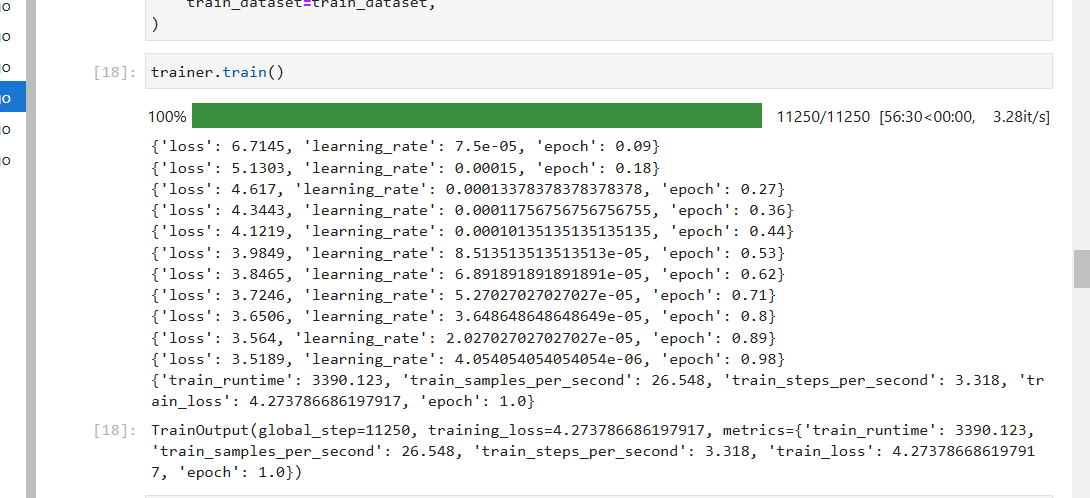
昇思大模型平台打卡体验活动:项目3基于MindSpore的GPT2文本摘要
昇思大模型平台打卡体验活动:项目3基于MindSpore的GPT2文本摘要 1. 环境设置 本项目可以沿用前两个项目的相关环境设置。首先,登陆昇思大模型平台,并进入对应的开发环境: https://xihe.mindspore.cn/my/clouddev 接着࿰…...
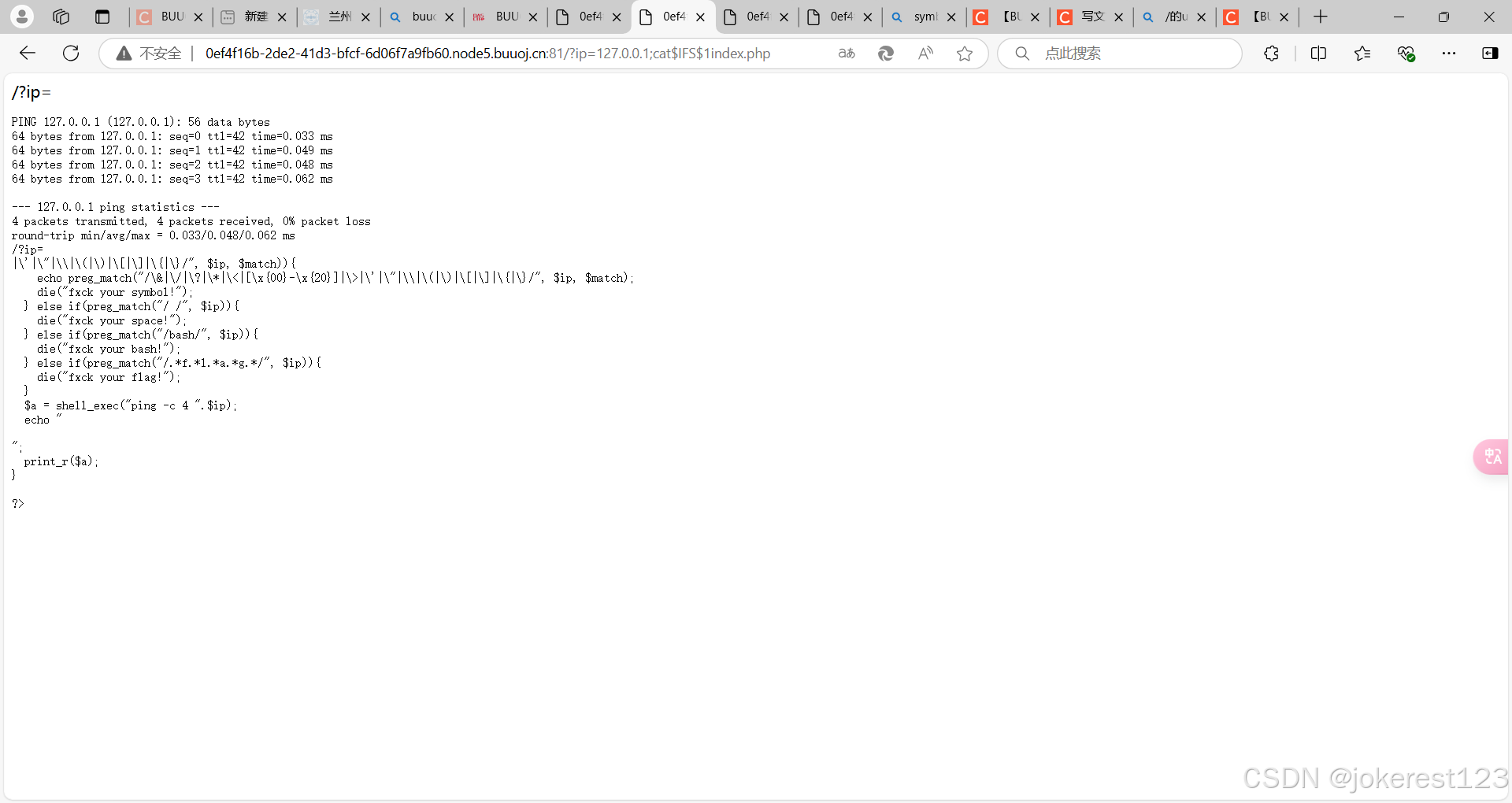
web——[GXYCTF2019]Ping Ping Ping1——过滤和绕过
0x00 考点 0、命令联合执行 ; 前面的执行完执行后面的 | 管道符,上一条命令的输出,作为下一条命令的参数(显示后面的执行结果) || 当前面的执行出错时(为假)执行后面的 & 将任…...

婚礼纪 9.5.57 | 解锁plus权益的全能结婚助手,一键生成结婚请柬
婚礼纪是一款结婚服务全能助手,深受9000万新人信赖的一站式结婚服务平台。解锁plus权益后,用户可以享受部分VIP会员功能。应用提供了丰富的结婚筹备工具和服务,包括一键生成结婚请柬、婚礼策划、婚纱摄影、婚宴预订等。婚礼纪旨在为新人提供全…...

M1M2 MAC安装windows11 虚拟机的全过程
M1/M2 MAC安装windows11 虚拟机的全过程 这两天折腾了一下windows11 arm架构的虚拟机,将途中遇到的坑总结一下。 1、虚拟机软件:vmware fusion 13.6 或者 parallel 19 ? 结论是:用parellel 19。 这两个软件都安装过࿰…...

监控架构-Prometheus-普罗米修斯
目录 1. Prometheus概述 2. Prometheus vs Zabbix 3. Prometheus极速上手指南 3.1 时间同步 3.2 部署Prometheus 3.3 启动Prometheus 3.4 Prometheus监控架构 3.5 补充 配置页面 简单过滤 查看数据 查看图形 http://prometheus.oldboylinux.cn:9090/metrics显示…...

Kylin Server V10 下自动安装并配置Kafka
Kafka是一个分布式的、分区的、多副本的消息发布-订阅系统,它提供了类似于JMS的特性,但在设计上完全不同,它具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费,如常规的消息收集、…...

深入OpenHarmony NAPI引擎:从‘@ohos.hilog’导入到so库加载的底层链路剖析
深入OpenHarmony NAPI引擎:从‘ohos.hilog’导入到so库加载的底层链路剖析 当开发者在OpenHarmony应用中写下import hilog from ohos.hilog时,背后隐藏着一套精密的系统级协作机制。这条看似简单的语句,实际上触发了从JavaScript语法解析到原…...

DamoFD与数据结构优化:提升人脸检测效率50%的实战技巧
DamoFD与数据结构优化:提升人脸检测效率50%的实战技巧 1. 效果惊艳的开场 如果你正在为人脸检测模型的推理速度发愁,那么今天的内容绝对能让你眼前一亮。DamoFD-0.5G作为达摩院推出的轻量级人脸检测模型,本身已经相当高效,但通过…...

告别AI对话失忆症:深入LangChain4j的ChatMemoryProvider与InMemoryChatMemoryStore
深入LangChain4j记忆管理:构建高性能会话隔离系统的实践指南 在构建企业级AI对话系统时,会话记忆管理往往成为决定用户体验的关键因素。想象这样一个场景:当用户询问"我上周提到的项目进展如何?"时,系统能否…...

2026年项目管理工具选型指南:功能对比、适用场景与避坑建议
项目管理工具早已不只是任务看板,而是连接目标、需求、计划、资源、交付、知识与复盘的管理底座。本文选取 ONES、Tower、Jira、Asana、monday.com、ClickUp、Microsoft Planner、Smartsheet、Notion 九款主流项目管理工具展开评估,帮助企业中高层研发负…...

免费EDA工具全解析:从电路仿真到PCB设计
1. 电路设计软件的选择困境与免费方案的价值 作为一名在电子设计行业摸爬滚打多年的工程师,我深知专业工具对项目成败的决定性影响。行业主流EDA工具如Altium Designer、Cadence往往价格不菲,单用户年费动辄数万元,这对独立开发者、学生群体和…...

别再手动测试了!教你用ThinkPHP6+Workerman/MQTT搭建一个本地MQTT消息调试台
基于ThinkPHP6与Workerman/MQTT构建物联网调试平台的完整指南 物联网开发中,MQTT协议因其轻量级和高效性成为设备通信的首选方案。但调试MQTT消息往往依赖命令行工具或第三方平台,效率低下且缺乏灵活性。本文将展示如何利用ThinkPHP6框架配合Workerman/M…...

7个高效步骤:Meshroom开源三维重建工具从入门到精通
7个高效步骤:Meshroom开源三维重建工具从入门到精通 【免费下载链接】Meshroom 3D Reconstruction Software 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 技术原理:三维重建的底层逻辑与技术选型 摄影测量技术的数学基础 三维重建技…...

5G RedCap路由器如何选?关键特性解析与典型应用场景指南
1. 5G RedCap路由器选购的核心指标 第一次接触5G RedCap路由器时,我被参数表里密密麻麻的术语搞得头晕眼花。后来在工业现场实测了7款不同型号后,才发现真正影响使用体验的关键指标其实就这几个: 频段支持就像路由器的"语言能力"。…...

【Echarts】Y轴标签优化:动态调整与智能截断的实战技巧
1. Y轴标签显示问题的根源分析 当使用Echarts绘制图表时,Y轴标签过长导致显示不全是个常见痛点。这个问题通常发生在两种场景:一是数据来自后端接口,标签长度不可控;二是图表容器宽度有限,无法容纳完整标签。 我遇到过…...

基于LSTM与SmolVLA的时序多模态数据分析
基于LSTM与SmolVLA的时序多模态数据分析 想象一下,你面前有一段监控视频,画面里有人正在行走、停留、再行走。如果只看其中一帧,你只能知道“这里有个人”;但如果把连续几帧连起来看,你就能判断出“这个人正在从A点走…...