【Python爬虫实战】轻量级爬虫利器:DrissionPage之SessionPage与WebPage模块详解
🌈个人主页:易辰君-CSDN博客
🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html

目录
前言
一、SessionPage
(一)SessionPage 模块的基本功能
(二)基本使用
(三)常用方法
(四)页面元素定位和数据提取
(五)Cookie 和会话管理
(六)SessionPage 的优点和局限性
(七)SessionPage 和 DriverPage 的搭配使用
(八)SessionPage总结
二、WebPage
(一)WebPage 的核心功能
(二)WebPage 的基本使用
(三)常用方法
(四)WebPage 的优缺点
(五)WebPage 和 Element 配合使用
(六)适用场景
(七)WebPage总结
三、总结
前言
在信息爆炸的时代,自动化网页爬取和数据获取逐渐成为必备技能。drissionPage 是一个基于 Selenium 和 Requests 的 Python 库,通过 SessionPage 和 WebPage 两大模块,简化了网页的自动化操作与数据抓取。SessionPage 使用 HTTP 请求实现轻量级、高效的静态页面爬取,而 WebPage 则结合了动态页面操作和数据提取的强大功能。本教程将详细讲解 SessionPage 和 WebPage 的使用方法及其核心功能,带您高效掌控网页数据。
一、SessionPage
drissionPage 是一个基于 Selenium 和 Requests 的 Python 库,用于简化网页自动化操作和数据爬取。它的 SessionPage 模块提供了一种无头的 HTTP 方式来操作网页,主要基于 requests 库实现,比起 Selenium 模块下的 DriverPage,SessionPage 更轻量、速度更快,非常适合进行页面数据的快速爬取。
(一)SessionPage 模块的基本功能
SessionPage 的核心是使用 requests.Session 对象来模拟浏览器的请求和会话,因此它可以保留会话(如 cookies、session 变量等),方便对一些需要登录状态的页面进行爬取。它能完成 HTTP 请求、获取页面内容、解析页面数据等操作。
主要功能包括:
-
自动维护会话状态(如 Cookie)
-
设置请求头(User-Agent、Referer 等)
-
执行 GET 和 POST 请求
-
提取页面内容、元素文本、属性等数据
-
操作模拟表单提交、文件上传、下载等
(二)基本使用
要使用 SessionPage,首先需要导入并创建一个 SessionPage 对象。以下是一个简单的使用示例:
from drission.page import SessionPage# 创建一个 SessionPage 对象
session_page = SessionPage()# 访问一个网页
session_page.get('https://example.com')# 获取网页的标题
print(session_page.title)# 获取网页的 HTML 源码
print(session_page.html)# 获取某个元素的文本
print(session_page('.some-class').text)
(三)常用方法
SessionPage 提供了一些常用方法,帮助简化爬虫开发。以下是几个主要方法的介绍:
(1)get(url, **kwargs)
发送 GET 请求访问网页,支持传入请求参数、headers、cookies 等。
session_page.get('https://example.com', params={'key': 'value'}, headers={'User-Agent': 'custom-agent'})
(2)post(url, data=None, **kwargs)
发送 POST 请求,支持传入请求参数、headers、cookies 等。
session_page.post('https://example.com/login', data={'username': 'myusername', 'password': 'mypassword'})
(3)set_headers(headers)
设置默认请求头,后续的请求都会携带这个请求头。
session_page.set_headers({'User-Agent': 'my-custom-agent'})
(4)download(url, path)
session_page.download('https://example.com/image.png', 'path/to/save/image.png')
(四)页面元素定位和数据提取
SessionPage 提供了与 DriverPage 类似的选择器接口,用于提取页面元素信息。使用 session_page('css_selector') 可以快速定位页面元素并提取内容。
# 获取元素的文本
text = session_page('h1.title').text# 获取元素的属性
link = session_page('a.link').attr('href')# 获取页面中所有指定元素
all_links = session_page('a').all_attrs('href')
(五)Cookie 和会话管理
由于 SessionPage 基于 requests.Session,它能够很好地管理 cookies 和会话。可以通过以下方法来操作 cookies:
(1)cookies
直接访问 cookies 属性可以查看当前的 cookies。
print(session_page.cookies)
(2)set_cookies(cookies)
设置 cookies,可以传入字典格式的 cookies。
session_page.set_cookies({'name': 'value'})
(3)get_cookie(name)
获取指定名称的 cookie 值。
cookie_value = session_page.get_cookie('name')
(4)clear_cookies()
清除当前会话中的所有 cookies。
session_page.clear_cookies()
(六)SessionPage 的优点和局限性
优点
-
速度快:基于 HTTP 请求,不需要加载浏览器,速度更快。
-
低资源消耗:不需要启动浏览器进程,内存和 CPU 消耗低。
-
方便爬取纯数据页面:适合用于获取不需要 JavaScript 渲染的静态页面数据。
局限性
-
无法处理动态内容:
SessionPage无法处理依赖 JavaScript 渲染的内容,适合静态页面或数据接口的爬取。 -
功能较少:相较于 Selenium,
SessionPage无法进行复杂的浏览器模拟操作,如点击、输入等。
(七)SessionPage 和 DriverPage 的搭配使用
在一些情况下,页面中存在动态内容,而其他部分是静态内容,可以将 SessionPage 与 DriverPage 配合使用。在动态内容加载完成后,通过 DriverPage 获取 cookies 并传递给 SessionPage,然后继续使用 SessionPage 来爬取其他页面,提升效率。
示例:
from drission import Drission
from drission.page import SessionPage, DriverPage# 创建 Drission 对象
drission = Drission()# 获取 DriverPage 和 SessionPage
driver_page = drission.driver_page
session_page = drission.session_page# 使用 DriverPage 登录并获取 cookies
driver_page.get('https://example.com/login')
driver_page('input[name="username"]').input('myusername')
driver_page('input[name="password"]').input('mypassword')
driver_page('button[type="submit"]').click()# 将登录后的 cookies 复制到 SessionPage
session_page.set_cookies(driver_page.get_cookies())# 使用 SessionPage 访问其他页面
session_page.get('https://example.com/data')
print(session_page.html)
(八)SessionPage总结
SessionPage 是 drissionPage 中用于轻量级爬取的模块,适合在 Windows、MacOS 和 Linux 等环境下进行静态页面爬取。它通过封装 requests.Session 实现对 cookies、headers 等的管理,具备快速、低资源消耗的特点。如果需要操作动态网页,可以结合 DriverPage 使用,或直接使用 DriverPage 进行交互。
二、WebPage
WebPage 是 drissionPage 中用于操作和管理网页的类,它可以基于 DriverPage(使用 Selenium 驱动浏览器)和 SessionPage(使用 requests 进行 HTTP 请求)进行网页访问、数据提取和交互等操作。因此 WebPage 作为 drissionPage 中的核心类,支持丰富的网页操作功能,简化了常见的网页爬取和自动化工作。
(一)WebPage 的核心功能
WebPage 主要提供以下核心功能:
-
统一操作接口:不论是使用浏览器驱动(
DriverPage)还是基于 HTTP 请求(SessionPage),WebPage提供了相同的 API 接口。可以通过统一的方法操作页面元素、获取内容和管理会话。 -
简化的数据提取:提供简洁的选择器和数据提取方法,支持通过 CSS 选择器、XPath 等方式快速获取元素、文本、属性等信息。
-
适用于动态和静态页面:支持 JavaScript 渲染的页面,也可以处理纯静态页面,能够满足多种类型网站的需求。
-
会话管理:
WebPage能自动管理和保存会话信息(如 cookies),适合处理需要保持登录状态的任务。
(二)WebPage 的基本使用
首先创建 Drission 对象,并通过它生成 WebPage 实例。WebPage 会根据 Drission 的初始化配置,自动选择 DriverPage 或 SessionPage,以便进行浏览器自动化或 HTTP 请求。
示例:
from drission import Drission
from drission.page import WebPage# 初始化 Drission 实例
drission = Drission()# 创建 WebPage 对象
page = WebPage(drission)# 访问页面
page.get('https://example.com')# 获取页面标题
print(page.title)# 获取页面 HTML 源码
print(page.html)
(三)常用方法
WebPage 提供了丰富的方法来操作页面和提取内容。以下是一些常用方法的介绍:
(1)get(url, **kwargs)
用于加载指定的 URL 地址。对于 SessionPage,可以传入请求参数和 headers 等。
page.get('https://example.com')
(2)title
获取当前页面的标题。
print(page.title)
(3)html
返回页面的 HTML 源码。对于 SessionPage,它返回的是请求的响应内容,而对于 DriverPage,则是浏览器渲染后的 HTML。
print(page.html)
(4)text
获取页面的纯文本内容。
print(page.text)
(5)元素选择和提取
可以通过 WebPage 的选择器方法来快速获取页面中的元素。支持多种选择器类型,如 CSS、XPath 等。
-
page('css_selector'): 选择单个元素,返回Element对象。 -
page('css_selector').text: 获取元素的文本内容。 -
page('css_selector').attr('href'): 获取元素的某个属性值。 -
page('css_selector').all(): 获取多个匹配的元素。
# 获取元素的文本内容
text = page('h1.title').text# 获取元素的属性
link = page('a.link').attr('href')# 获取页面中所有指定元素
all_links = page('a').all_attrs('href')
(6)操作元素
在 DriverPage 模式下,WebPage 支持点击、输入文本、提交表单等操作。例如:
# 点击一个按钮
page('button.submit').click()# 在输入框中输入文本
page('input#name').input('drission')# 提交表单
page('form#login').submit()
(7)滚动和等待
在 DriverPage 模式下,可以执行滚动、等待等操作,模拟用户的交互。
# 滚动到页面底部
page.scroll_to('bottom')# 等待某个元素出现
page.wait('div.content')
(四)WebPage 的优缺点
优点
-
通用性:
WebPage统一了动态和静态页面的操作接口,能自动选择DriverPage或SessionPage。 -
丰富的页面操作支持:支持各种页面操作,简化了数据提取、页面交互等工作。
-
良好的会话管理:自动保存 cookies,适用于需要登录的页面。
局限性
-
WebPage的一些功能(如点击、输入)仅在DriverPage下有效,在SessionPage下无法处理 JavaScript 动态内容。 -
由于自动化的程度较高,在处理一些复杂页面交互时,可能需要额外的自定义代码。
(五)WebPage 和 Element 配合使用
WebPage 的选择器方法返回的对象是 Element,它表示页面中的一个具体元素。Element 对象允许进一步的操作,例如提取属性、点击、输入等。
示例:
# 获取某个元素
element = page('a.link')# 获取属性
href = element.attr('href')# 点击元素
element.click()# 获取子元素
sub_element = element('span')
(六)适用场景
-
动态网页数据提取:可以使用
DriverPage模式获取 JavaScript 渲染的数据。 -
静态网页爬取:使用
SessionPage模式直接请求页面,速度快、性能高。 -
登录后数据爬取:利用会话管理功能,通过
WebPage可以在需要登录的页面中保持会话,方便多页面数据的批量爬取。
(七)WebPage总结
WebPage 是一个封装强大的网页操作类,整合了 DriverPage 和 SessionPage 的功能,适合不同类型的页面操作。其统一的 API 设计,让开发者可以更方便地进行数据提取和页面交互,适用于动态和静态网页的自动化任务。同时,结合 Element 类的丰富操作接口,WebPage 成为一个非常强大、灵活的网页自动化和爬取工具。
三、总结
drissionPage 的 SessionPage 和 WebPage 模块,通过封装 Requests 和 Selenium,为开发者提供了一个高效灵活的网页操作和数据抓取工具。SessionPage 模块适合快速静态页面爬取,而 WebPage 则在动态交互和数据提取上表现出色。通过二者的合理组合,drissionPage 让数据采集更加简洁高效,无论是快速抓取静态数据,还是在需要保持会话状态的网页中提取信息,都可以游刃有余地应对,是一个理想的爬虫开发工具。
相关文章:
【Python爬虫实战】轻量级爬虫利器:DrissionPage之SessionPage与WebPage模块详解
🌈个人主页:易辰君-CSDN博客 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、SessionPage (一)SessionPage 模块的基本功能 (二)基本使…...

计算机网络-2.1物理层
文章目录 通信的基础概念信源、信宿、信号、信道码元、速率、波特带宽(Hz) 奈奎斯特采样定律和香农采样定律编码&解码,调制&解调常用的编码方法常用的调制方法 传输介质1. 导向型传输介质2. 非导向型传输介质物理层接口的特性 物理层…...
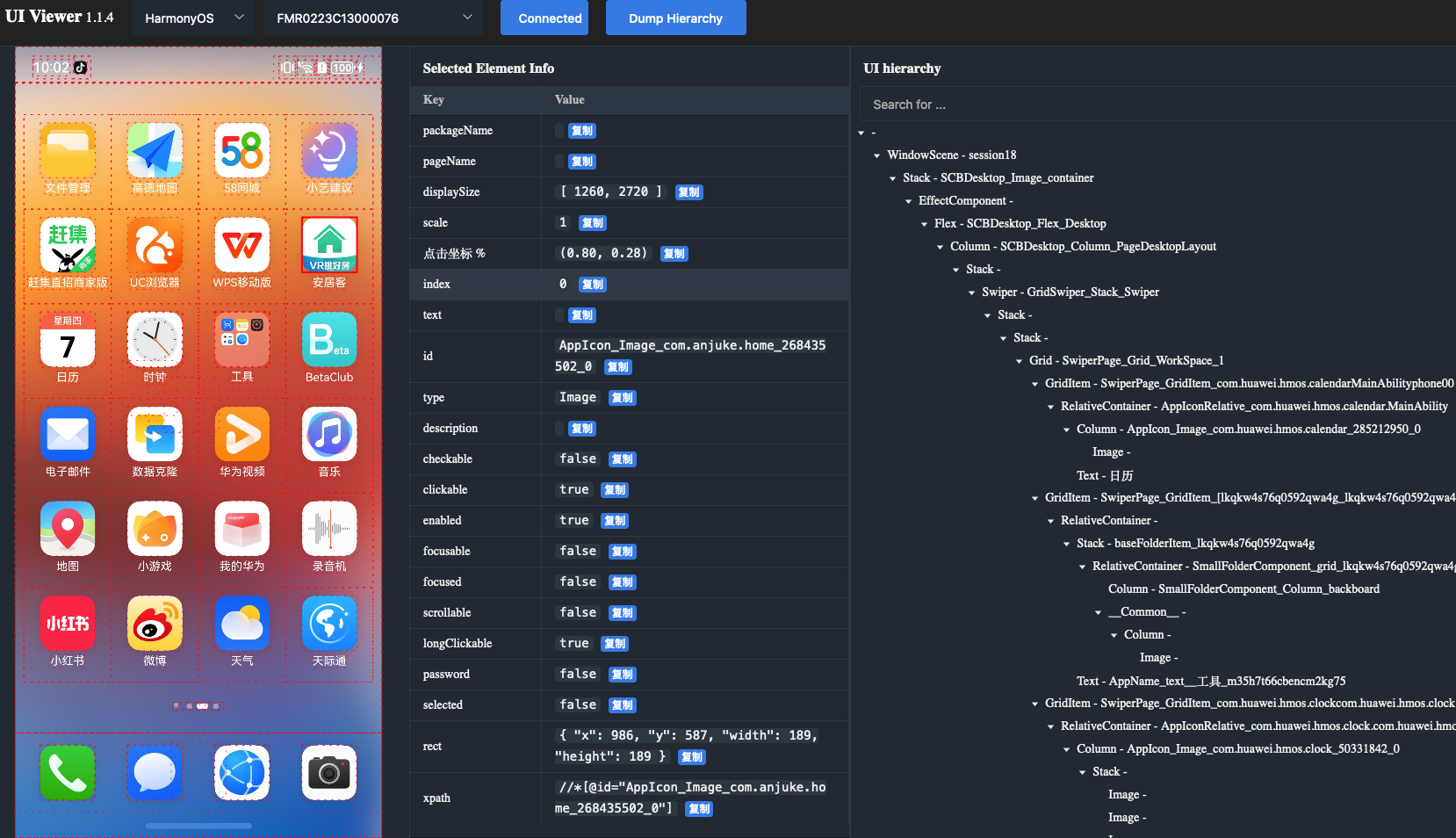
纯血鸿蒙系统 HarmonyOS NEXT自动化测试实践
1、测试框架选择 hdc:类似 android 系统的 adb 命令,提供设备信息查询,包管理,调试相关的命令ohos.UiTest:鸿蒙 sdk 的一部分,类似 android sdk 里的uiautomator,基于 Accessibility 服务&…...

C 语言标准库 - <errno.h>
目录 1.errno 变量 2.宏 1.errno 变量 errno.h 声明了一个 int 类型的 errno 变量,用来存储错误码(正整数)。 如果这个变量有非零值,表示已经执行的程序发生了错误。 #include <errno.h> #include <stdio.h> #in…...

Golang自带的测试库testing的使用
testing是golang自带的测试库。 testting规则: 在待测试功能所在文件的同级目录中创建一个以_test.go结尾的文件。 测试函数名必须是TestXxxx这个形式,而且Xxxx必须以大写字母开头,另外函数带有一个*testing.T类型的参数。 // 单元测试&am…...

29.电影院售票系统(基于springboot和vue的Java项目)
目录 1.系统的受众说明 2 论文背景 2.1 国内研究现状: 2.2 国外研究现状: 2.3 所用技术 3 系统需求分析 3.1 需求分析 3.2 可行性分析 3.2.1技术可行性分析 3.2.2市场可行性分析 3.2.3经济可…...

大学生就业平台微信小程序
随着计算机技术的成熟,互联网的建立,如今,PC平台上有许多关于大学生就业方面的程序,但由于使用时间和地点上的限制,用户在使用上存在着种种不方便,而开发一款大学生就业平台微信小程序,能够有效…...

Redis 缓存击穿
目录 缓存击穿 什么是缓存击穿? 有哪些解决办法? 缓存穿透和缓存击穿有什么区别? 缓存雪崩 什么是缓存雪崩? 有哪些解决办法? 缓存预热如何实现? 缓存雪崩和缓存击穿有什么区别? 如何保…...
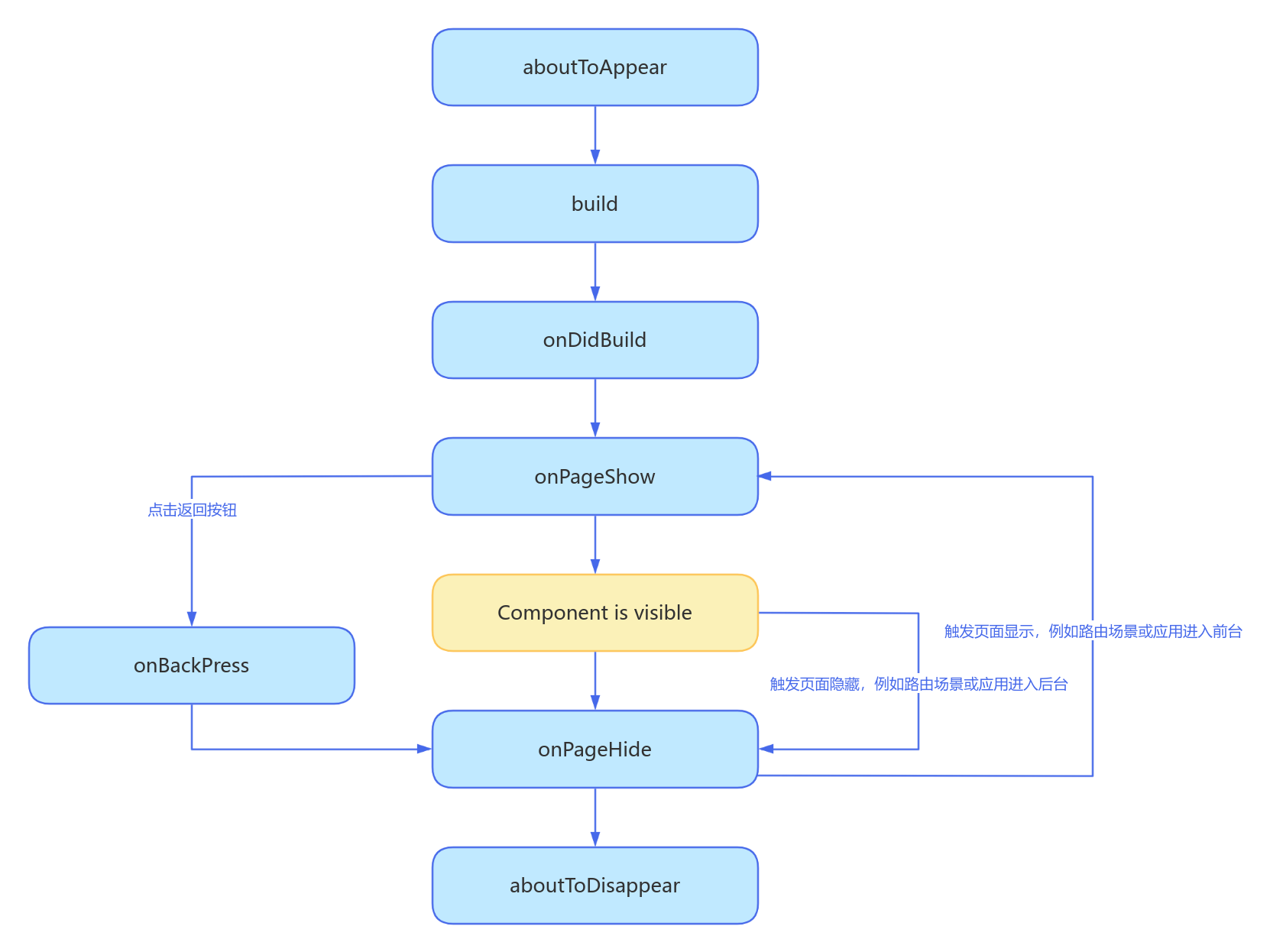
初探鸿蒙:从概念到实践
一、鸿蒙开发的环境准备 开发工具:使用 DevEco Studio,支持 ArkTS 语法。 系统要求:确保计算机符合 DevEco Studio 的最低系统需求。安装步骤:下载 DevEco Studio,安装合适的 SDK 和模拟器 二、鸿蒙应用可以…...

PHP API的路由设计思路
PHP API的路由设计是构建高效、可维护API的关键环节。以下是一套完整的PHP API路由设计思路: 一、明确设计原则 使用统一资源标识符(URI):通过URI来标识资源,确保每个资源都有一个唯一的地址。使用HTTP方法ÿ…...

工程师 - 如何访问Github
Github无法访问,涉及到IP地址、Host文件、DNS等配置。 1,查找github地址 打开https://www.ipaddress.com/网站,这个网站首页是查询自己IP的。 在上方搜索栏输入github.com,查找github的地址。 https://www.ipaddress.com/websit…...

222. 完全二叉树的节点个数 迭代
222. 完全二叉树的节点个数 已解答 简单 相关标签 相关企业 给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。 完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值࿰…...

中心极限定理的三种形式
独立同分布的中心极限定理: 设 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn是独立同分布的随机变量序列,且 E ( X i ) μ E(X_i) \mu E(Xi)μ, D ( X i ) σ 2 > 0 D(X_i) \sigma^2 > 0 D(Xi)σ2>0存在…...

React Native 全栈开发实战班 - 导航栈定制
在 React Native 应用中,导航栈管理是实现页面跳转和状态维护的核心机制。React Navigation 提供了强大的导航栈管理功能,允许开发者灵活地控制页面堆栈、传递参数、处理返回逻辑等。本章节将深入探讨导航栈的管理与定制,包括如何控制导航栈、…...

扬州BGP高防服务器可以给企业带来哪些好处?
扬州BGP服务器是目前江苏较为出名的高防机房,随着网络安全逐渐被企业所重视,扬州机房的也被大家进行选择,但是扬州BGP高防服务器除了可以帮助企业抵御网络攻击,还有着其他的帮助,下面就让我们来了解一下吧!…...

题目讲解15 合并两个排序的链表
原题链接: 合并两个排序的链表_牛客题霸_牛客网 思路分析: 第一步:写一个链表尾插数据的方法。 typedef struct ListNode ListNode;//申请结点 ListNode* BuyNode(int x) {ListNode* node (ListNode*)malloc(sizeof(ListNode));node->…...

leetcode92:反转链表||
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1,4,3,2…...

arkUI:遍历数据数组动态渲染(forEach)
arkUI:遍历数据数组动态渲染(forEach) 1 主要内容说明2 相关内容2.1 ForEach 的基本语法2.2 简单遍历数组2.2 多维数组遍历2.4 使用唯一键2.5 源码1的相关说明2.5.1 源码1 (遍历数据数组动态渲染)2.5.2 源码1运行效果 …...

js中import引入一个export值可以被修改。vue,react
import引入的数据实际就是数据本身。 如果导出的是一个对象,该对象引入后被更改了,则会影响其他文件引入此对象 解释示例: // resources.js const obj {} export {obj} 当在a.js中import引入一个空对象obj,并且新增一个属性ob…...

PDF24:多功能 PDF 工具使用指南
PDF24:多功能 PDF 工具使用指南 在日常工作和学习中,PDF 是一种常见且重要的文档格式。无论是查看、编辑、合并,还是转换 PDF 文件,能够快速高效地处理 PDF 文档对于提高工作效率至关重要。PDF24 是一款免费、功能全面的 PDF 工具…...

指令不生效?模型“装聋作哑”?ChatGPT自定义指令调试全流程,从日志埋点到上下文权重校准
更多请点击: https://codechina.net 第一章:指令不生效?模型“装聋作哑”?ChatGPT自定义指令调试全流程,从日志埋点到上下文权重校准 当用户设置的自定义指令(如“始终用简体中文回复”“拒绝回答政治类问…...

Prompt Cache:别再为同样的 System Prompt 重算一遍
多轮对话里 System Prompt 每次都一样——500 Token 的固定前缀,每轮推理都要重跑一遍 Prefill。等于把同一段文字反复"读"几十上百遍。Prompt Cache 就是来省掉这件重复劳动的。 正常推理流程下,一个新请求进来先跑 Prefill(全 P…...

UnityExplorer自由视角相机终极指南:3种模式带你突破游戏视角限制
UnityExplorer自由视角相机终极指南:3种模式带你突破游戏视角限制 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer 你是否…...

如何轻松转换B站缓存视频:m4s-converter终极实用指南
如何轻松转换B站缓存视频:m4s-converter终极实用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了喜欢的视…...

OpenMemories-Tweak:嵌入式系统配置管理的逆向工程实践
OpenMemories-Tweak:嵌入式系统配置管理的逆向工程实践 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 问题导向:破解封闭式嵌入式系统的配置限制 在…...

毕业论文查重不花一分钱?书匠策AI这个免费功能,90%的同学还不知道!
嗨,同学们好,我是你们的论文写作科普搭子。 今天要跟大家聊一个所有毕业生都绕不开的坎——论文查重。 先问大家一个扎心的问题:你的论文查重花了多少钱? 我见过有同学前前后后查了五六次,光查重费就花了上千块。更…...

百度网盘Mac版SVIP破解插件:从龟速到极速的下载体验优化指南
百度网盘Mac版SVIP破解插件:从龟速到极速的下载体验优化指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾经面对百度网盘那令人…...

Grafana CVE-2021-43798路径遍历漏洞原理与实战复现
1. 这个漏洞不是“找文件”,而是Grafana的API信任机制被彻底绕过你可能在靶场里点开Grafana登录页,输入默认账号密码,进后台点几下就以为复现完成了——但那只是界面,不是漏洞。CVE-2021-43798的本质,是Grafana 8.x版本…...

LangGraph多智能体能力路由:动态专家选择与负载均衡
LangGraph多智能体能力路由:动态专家选择与负载均衡一、引言 钩子 你是否遇到过这种情况: 当你构建了一个由多个大模型或专业Agent组成的“超级团队”——有的精通数学推理、有的擅长代码生成、有的是情感分析小能手、还有的能写长篇技术文档——却发现整…...

Windows Cleaner深度解析:4步彻底解决C盘空间不足的完整技术方案
Windows Cleaner深度解析:4步彻底解决C盘空间不足的完整技术方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...