遗传算法与深度学习实战——利用进化计算优化深度学习模型
遗传算法与深度学习实战——利用进化计算优化深度学习模型
- 0. 前言
- 1. 利用进化计算优化深度学习模型
- 2. 利用进化策略优化深度学习模型
- 3. 利用差分计算优化深度学习模型
- 相关链接
0. 前言
我们已经学习了使用进化策略 (Evolutionary Strategies, ES) 和差分进化 (Differential Evolution, DE) 调整超参数,并取得了不错的结果。在本节中,我们将应用 ES 和 DE 作为神经进化优化器,并且继续使用圆圈或月亮数据集。
1. 利用进化计算优化深度学习模型
我们已经通过遗传算法优化简单深度学习 ( Deep learning, DL) 网络的权重/参数,除了遗传算法之外,我们还有更强大的进化方法,比如进化策略 (Evolutionary Strategies, ES) 和差分进化 (Differential Evolution, DE),它们可能表现更好。接下来,我们将研究这两种更高级的进化方法。
下图显示了使用 ES 和 DE 算法的运行结果,并观察 DE 和 ES 如何演化在每个数据集的权重。可以看到,ES不仅在解决困难数据集方面表现出色,而且还有解决更复杂问题的潜力。
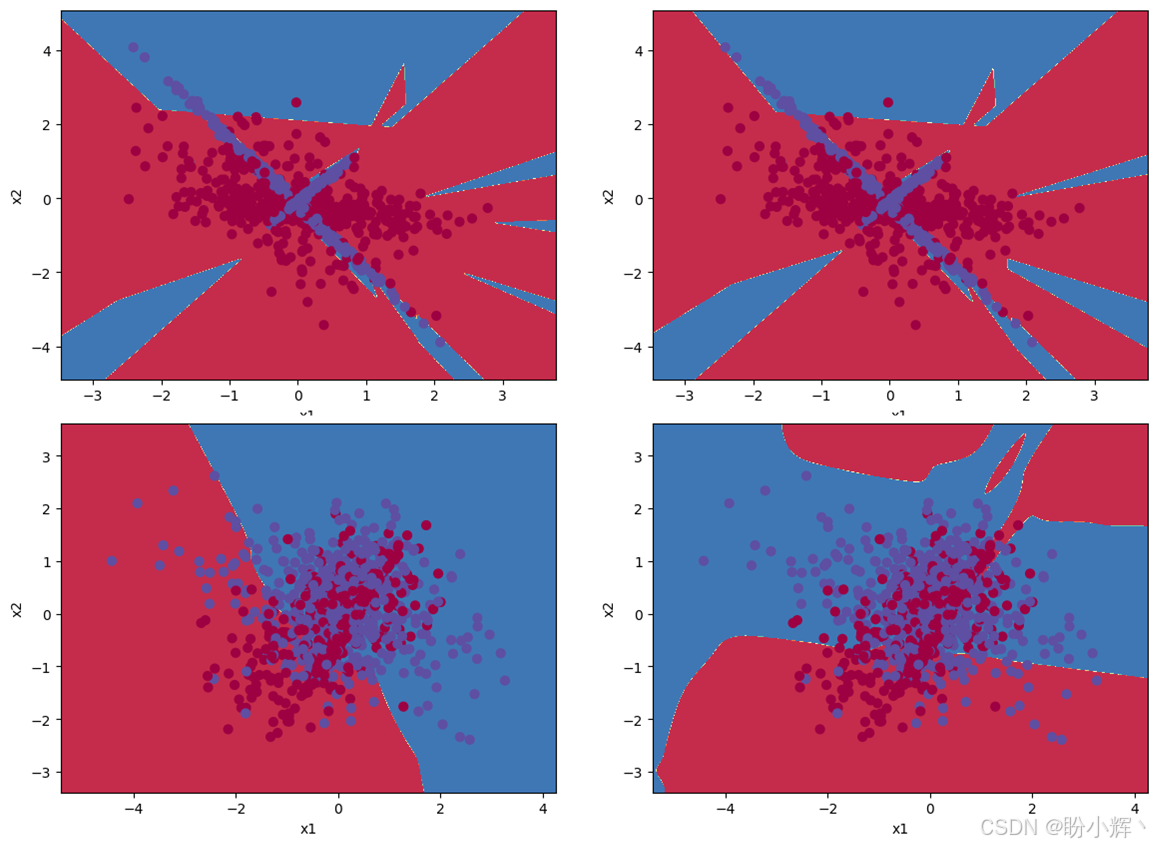
2. 利用进化策略优化深度学习模型
在代码中,将遗传算法转换为进化策略 (Evolutionary Strategies, ES) 和差分进化 (Differential Evolution, DE) 算法。首先使用 ES 算法:
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlib.pyplot as plt
from IPython.display import clear_outputfrom deap import algorithms
from deap import base
from deap import benchmarks
from deap import creator
from deap import toolsimport randomnumber_samples = 1000 #@param {type:"slider", min:100, max:1000, step:25}
difficulty = 5 #@param {type:"slider", min:1, max:5, step:1}
problem = "classification" #@param ["classification", "blobs", "gaussian quantiles", "moons", "circles"]
number_features = 2
number_classes = 2
middle_layer = 25 #@param {type:"slider", min:5, max:25, step:1}def load_data(problem): if problem == "classification":clusters = 1 if difficulty < 3 else 2informs = 1 if difficulty < 4 else 2data = sklearn.datasets.make_classification(n_samples = number_samples,n_features=number_features, n_redundant=0, class_sep=1/difficulty,n_informative=informs, n_clusters_per_class=clusters)if problem == "blobs":data = sklearn.datasets.make_blobs(n_samples = number_samples,n_features=number_features, centers=number_classes,cluster_std = difficulty)if problem == "gaussian quantiles":data = sklearn.datasets.make_gaussian_quantiles(mean=None, cov=difficulty,n_samples=number_samples,n_features=number_features,n_classes=number_classes,shuffle=True,random_state=None)if problem == "moons":data = sklearn.datasets.make_moons(n_samples = number_samples)if problem == "circles":data = sklearn.datasets.make_circles(n_samples = number_samples)return datadata = load_data(problem)
X, Y = data# Input Data
plt.figure("Input Data")
plt.scatter(X[:, 0], X[:, 1], c=Y, s=40, cmap=plt.cm.Spectral)def show_predictions(model, X, Y, name=""):""" display the labeled data X and a surface of prediction of model """x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))X_temp = np.c_[xx.flatten(), yy.flatten()]Z = model.predict(X_temp)plt.figure("Predictions " + name)plt.contourf(xx, yy, Z.reshape(xx.shape), cmap=plt.cm.Spectral)plt.ylabel('x2')plt.xlabel('x1')
plt.scatter(X[:, 0], X[:, 1],c=Y, s=40, cmap=plt.cm.Spectral)clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, Y)show_predictions(clf, X, Y, "Logistic regression")LR_predictions = clf.predict(X)
print("Logistic Regression accuracy : ", np.sum(LR_predictions == Y) / Y.shape[0])def sigmoid(x):return 1.0 / (1.0 + np.exp(-x)) ## Neural Network
class Neural_Network:def __init__(self, n_in, n_hidden, n_out):# Network dimensionsself.n_x = n_inself.n_h = n_hiddenself.n_y = n_out# Parameters initializationself.W1 = np.random.randn(self.n_h, self.n_x) * 0.01self.b1 = np.zeros((self.n_h, 1))self.W2 = np.random.randn(self.n_y, self.n_h) * 0.01self.b2 = np.zeros((self.n_y, 1))self.parameters = [self.W1, self.b1, self.W2, self.b2]def forward(self, X):""" Forward computation """self.Z1 = self.W1.dot(X.T) + self.b1self.A1 = np.tanh(self.Z1)self.Z2 = self.W2.dot(self.A1) + self.b2self.A2 = sigmoid(self.Z2)def set_parameters(self, individual):"""Sets model parameters """idx = 0for p in self.parameters: size = p.sizesh = p.shapet = individual[idx:idx+size]t = np.array(t)t = np.reshape(t, sh)p -= pp += tidx += sizedef predict(self, X):""" Compute predictions with just a forward pass """self.forward(X)return np.round(self.A2).astype(np.int)nn = Neural_Network(2, middle_layer, 1)
number_of_genes = sum([p.size for p in nn.parameters])
print(number_of_genes)individual = np.ones(number_of_genes)
nn.set_parameters(individual)
print(nn.parameters)IND_SIZE = number_of_genes
MIN_VALUE = -1000
MAX_VALUE = 1000
MIN_STRATEGY = 0.5
MAX_STRATEGY = 5CXPB = .6
MUTPB = .3creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, typecode="d", fitness=creator.FitnessMin, strategy=None)
creator.create("Strategy", list, typecode="d")def generateES(icls, scls, size, imin, imax, smin, smax): ind = icls(random.uniform(imin, imax) for _ in range(size)) ind.strategy = scls(random.uniform(smin, smax) for _ in range(size)) return inddef checkStrategy(minstrategy):def decorator(func):def wrappper(*args, **kargs):children = func(*args, **kargs)for child in children:for i, s in enumerate(child.strategy):if s < minstrategy:child.strategy[i] = minstrategyreturn childrenreturn wrappper
return decoratordef custom_blend(ind1, ind2, alpha): for i, (x1, s1, x2, s2) in enumerate(zip(ind1, ind1.strategy,ind2, ind2.strategy)):# Blend the valuesgamma = (1. + 2. * alpha) * random.random() - alphaind1[i] = (1. - gamma) * x1 + gamma * x2ind2[i] = gamma * x1 + (1. - gamma) * x2# Blend the strategiesgamma = (1. + 2. * alpha) * random.random() - alphaind1.strategy[i] = (1. - gamma) * s1 + gamma * s2ind2.strategy[i] = gamma * s1 + (1. - gamma) * s2
return ind1, ind2toolbox = base.Toolbox()
toolbox.register("individual", generateES, creator.Individual, creator.Strategy,IND_SIZE, MIN_VALUE, MAX_VALUE, MIN_STRATEGY, MAX_STRATEGY)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("mate", custom_blend, alpha=0.5)
toolbox.register("mutate", tools.mutESLogNormal, c=1.0, indpb=0.06)
toolbox.register("select", tools.selTournament, tournsize=5)toolbox.decorate("mate", checkStrategy(MIN_STRATEGY))
toolbox.decorate("mutate", checkStrategy(MIN_STRATEGY))nn = Neural_Network(2, middle_layer, 1)
nn.set_parameters(individual)
print(nn.parameters)show_predictions(nn, X, Y, "Neural Network")nn_predictions = nn.predict(X)
print("Neural Network accuracy : ", np.sum(nn_predictions == Y) / Y.shape[0])def evaluate(individual): nn.set_parameters(individual)nn_predictions = nn.predict(X)return 1/np.sum(nn_predictions == Y) / Y.shape[0], toolbox.register("evaluate", evaluate)MU = 340 #@param {type:"slider", min:5, max:1000, step:5}
LAMBDA = 1000 #@param {type:"slider", min:5, max:1000, step:5}
NGEN = 100 #@param {type:"slider", min:100, max:1000, step:10}
RGEN = 10 #@param {type:"slider", min:1, max:100, step:1}
CXPB = .6
MUTPB = .3random.seed(64)pop = toolbox.population(n=MU)
hof = tools.HallOfFame(1)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", np.mean)
stats.register("std", np.std)
stats.register("min", np.min)
stats.register("max", np.max)best = None
history = []for g in range(NGEN):pop, logbook = algorithms.eaMuCommaLambda(pop, toolbox, mu=MU, lambda_=LAMBDA, cxpb=CXPB, mutpb=MUTPB, ngen=RGEN, stats=stats, halloffame=hof, verbose=False)best = hof[0] clear_output()print(f"Gen ({(g+1)*RGEN})")show_predictions(nn, X, Y, "Neural Network") nn_predictions = nn.predict(X)print("Current Neural Network accuracy : ", np.sum(nn_predictions == Y) / Y.shape[0])plt.show()nn.set_parameters(best)show_predictions(nn, X, Y, "Best Neural Network")plt.show()nn_predictions = nn.predict(X)fitness = np.sum(nn_predictions == Y) / Y.shape[0]print("Best Neural Network accuracy : ", fitness)if fitness > .99: #stop conditionbreak
3. 利用差分计算优化深度学习模型
接下来,应用 DE 作为神经进化优化器:
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlib.pyplot as plt
from IPython.display import clear_outputfrom deap import algorithms
from deap import base
from deap import benchmarks
from deap import creator
from deap import toolsimport random
import array
import timenumber_samples = 1000 #@param {type:"slider", min:100, max:1000, step:25}
difficulty = 5 #@param {type:"slider", min:1, max:5, step:1}
problem = "classification" #@param ["classification", "blobs", "gaussian quantiles", "moons", "circles"]
number_features = 2
number_classes = 2
middle_layer = 25 #@param {type:"slider", min:5, max:25, step:1}def load_data(problem): if problem == "classification":clusters = 1 if difficulty < 3 else 2informs = 1 if difficulty < 4 else 2data = sklearn.datasets.make_classification(n_samples = number_samples,n_features=number_features, n_redundant=0, class_sep=1/difficulty,n_informative=informs, n_clusters_per_class=clusters)if problem == "blobs":data = sklearn.datasets.make_blobs(n_samples = number_samples,n_features=number_features, centers=number_classes,cluster_std = difficulty)if problem == "gaussian quantiles":data = sklearn.datasets.make_gaussian_quantiles(mean=None, cov=difficulty,n_samples=number_samples,n_features=number_features,n_classes=number_classes,shuffle=True,random_state=None)if problem == "moons":data = sklearn.datasets.make_moons(n_samples = number_samples)if problem == "circles":data = sklearn.datasets.make_circles(n_samples = number_samples)return datadata = load_data(problem)
X, Y = data# Input Data
plt.figure("Input Data")
plt.scatter(X[:, 0], X[:, 1], c=Y, s=40, cmap=plt.cm.Spectral)def show_predictions(model, X, Y, name=""):""" display the labeled data X and a surface of prediction of model """x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))X_temp = np.c_[xx.flatten(), yy.flatten()]Z = model.predict(X_temp)plt.figure("Predictions " + name)plt.contourf(xx, yy, Z.reshape(xx.shape), cmap=plt.cm.Spectral)plt.ylabel('x2')plt.xlabel('x1')
plt.scatter(X[:, 0], X[:, 1],c=Y, s=40, cmap=plt.cm.Spectral)clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, Y)show_predictions(clf, X, Y, "Logistic regression")LR_predictions = clf.predict(X)
print("Logistic Regression accuracy : ", np.sum(LR_predictions == Y) / Y.shape[0])def sigmoid(x):return 1.0 / (1.0 + np.exp(-x)) ## Neural Network
class Neural_Network:def __init__(self, n_in, n_hidden, n_out):# Network dimensionsself.n_x = n_inself.n_h = n_hiddenself.n_y = n_out# Parameters initializationself.W1 = np.random.randn(self.n_h, self.n_x) * 0.01self.b1 = np.zeros((self.n_h, 1))self.W2 = np.random.randn(self.n_y, self.n_h) * 0.01self.b2 = np.zeros((self.n_y, 1))self.parameters = [self.W1, self.b1, self.W2, self.b2]def forward(self, X):""" Forward computation """self.Z1 = self.W1.dot(X.T) + self.b1self.A1 = np.tanh(self.Z1)self.Z2 = self.W2.dot(self.A1) + self.b2self.A2 = sigmoid(self.Z2)def set_parameters(self, individual):"""Sets model parameters """idx = 0for p in self.parameters: size = p.sizesh = p.shapet = individual[idx:idx+size]t = np.array(t)t = np.reshape(t, sh)p -= pp += tidx += sizedef predict(self, X):""" Compute predictions with just a forward pass """self.forward(X)return np.round(self.A2).astype(np.int)nn = Neural_Network(2, middle_layer, 1)
number_of_genes = sum([p.size for p in nn.parameters])
print(number_of_genes)individual = np.ones(number_of_genes)
nn.set_parameters(individual)
print(nn.parameters)NDIM = number_of_genes
CR = 0.25
F_ = 1creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", array.array, typecode='d', fitness=creator.FitnessMin)toolbox = base.Toolbox()
toolbox.register("attr_float", random.uniform, -1, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, NDIM)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("select", tools.selRandom, k=3)nn = Neural_Network(2, middle_layer, 1)
nn.set_parameters(individual)
print(nn.parameters)show_predictions(nn, X, Y, "Neural Network")nn_predictions = nn.predict(X)
print("Neural Network accuracy : ", np.sum(nn_predictions == Y) / Y.shape[0])def evaluate(individual): nn.set_parameters(individual)nn_predictions = nn.predict(X)return 1/np.sum(nn_predictions == Y) / Y.shape[0], toolbox.register("evaluate", evaluate)MU = 340 #@param {type:"slider", min:5, max:1000, step:5}
NGEN = 1000 #@param {type:"slider", min:100, max:1000, step:10}
RGEN = 10 #@param {type:"slider", min:1, max:10, step:1}random.seed(64)pop = toolbox.population(n=MU)
hof = tools.HallOfFame(1)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", np.mean)
stats.register("std", np.std)
stats.register("min", np.min)
stats.register("max", np.max)logbook = tools.Logbook()
logbook.header = "gen", "evals", "std", "min", "avg", "max"best = None
history = []# Evaluate the individuals
fitnesses = toolbox.map(toolbox.evaluate, pop)
for ind, fit in zip(pop, fitnesses):ind.fitness.values = fitrecord = stats.compile(pop)
logbook.record(gen=0, evals=len(pop), **record)
print(logbook.stream)
for g in range(1, NGEN):for k, agent in enumerate(pop):a,b,c = toolbox.select(pop)y = toolbox.clone(agent)index = random.randrange(NDIM)for i, value in enumerate(agent):if i == index or random.random() < CR:y[i] = a[i] + F_*(b[i]-c[i])y.fitness.values = toolbox.evaluate(y)if y.fitness > agent.fitness:pop[k] = yhof.update(pop) record = stats.compile(pop) best = hof[0]if ((g+1) % RGEN) == 0:clear_output()print(f"Gen ({(g+1)})")show_predictions(nn, X, Y, "Neural Network") nn_predictions = nn.predict(X)print("Current Neural Network accuracy : ", np.sum(nn_predictions == Y) / Y.shape[0])plt.show()nn.set_parameters(best)show_predictions(nn, X, Y, "Best Neural Network")plt.show()nn_predictions = nn.predict(X)fitness = np.sum(nn_predictions == Y) / Y.shape[0]print("Best Neural Network accuracy : ", fitness)if fitness > .99: #stop conditionbreaktime.sleep(1)
对于本节所用的样本数据集,简单的遗传算法方法通常表现最佳,DE 明显是不太理想的选择,而 ES 具有一定的潜力。可以通过完成以下问题进一步了解不同神经优化算法的应用场景:
- 调整超参数,观察它们对
DE或ES的影响。 - 调整特定的进化方法超参数——
ES的最小和最大策略,或DE的pmin/pmax和smin/smax
相关链接
遗传算法与深度学习实战(1)——进化深度学习
遗传算法与深度学习实战(4)——遗传算法(Genetic Algorithm)详解与实现
遗传算法与深度学习实战(14)——进化策略详解与实现
遗传算法与深度学习实战(15)——差分进化详解与实现
遗传算法与深度学习实战(16)——神经网络超参数优化
遗传算法与深度学习实战(19)——使用粒子群优化自动超参数优化
遗传算法与深度学习实战(20)——使用进化策略自动超参数优化
遗传算法与深度学习实战(21)——使用差分搜索自动超参数优化
遗传算法与深度学习实战(22)——使用Numpy构建神经网络
遗传算法与深度学习实战(23)——利用遗传算法优化深度学习模型
相关文章:
遗传算法与深度学习实战——利用进化计算优化深度学习模型
遗传算法与深度学习实战——利用进化计算优化深度学习模型 0. 前言1. 利用进化计算优化深度学习模型2. 利用进化策略优化深度学习模型3. 利用差分计算优化深度学习模型相关链接 0. 前言 我们已经学习了使用进化策略 (Evolutionary Strategies, ES) 和差分进化 (Differential E…...
计算机视觉 ---图像读取与显示(OpenCV与Matplotlib)
前言 本文分别介绍了使用 OpenCV 和 Matplotlib 进行图像读取与显示的方法,如 cv2.imread ()、cv2.imshow ()、plt.imread ()、plt.imshow () 等,并提及了使用 OpenCV 时的注意事项。 OpenCV与Matplotlib图像读取与显示的差异 图像读取: Op…...

XML Schema 字符串数据类型
XML Schema 字符串数据类型 1. 概述 XML Schema 是一种用于定义 XML 文档结构和内容的语言。它提供了一种强大的机制来描述 XML 数据的类型、结构和约束。在 XML Schema 中,字符串数据类型是一种基本数据类型,用于表示文本数据。 2. 字符串数据类型 …...

Spring Boot 读取 yml 并映射至实体
application-base.yml app:# 附件存储路径upload-attachments: /data/attachments/# 报告导出详情 url - 前端score-detail-url: ${app.host.web}/#/process/start?processNo{}# api 文件下载 urlfile-download-url: ${app.host.web}/prod-api/sys_file_info/download/{}?fu…...

/// ts中的三斜线指令 | 前端
第一次看到注意到这行代码,不知道的还以为是注释呢,查了资料才知道这是typescript中的三斜线指令,那有什么作用呢? 1. 这行代码是TypeScript中的一个三斜线指令(Triple-Slash Directive),用于…...
什么岗位需要学习 OpenGL ES ?说说 3.X 的新特性
什么是 OpenGL ES OpenGL ES 是一种为嵌入式系统和移动设备设计的3D图形API(应用程序编程接口)。它是标准 OpenGL 3D 图形库的一个子集,专门为资源受限的环境(如手机、平板电脑、游戏机和其他便携式设备)进行了优化。 由于其在移动设备上的广泛适用性,OpenGL ES是学习移…...

【插件】多断言 插件pytest-assume
背景 assert 断言一旦失败,后续的断言不能被执行 有个插件,pytest-assume的插件,可以提供多断言的方式 安装 pip3 install pytest-assume用法 pytest.assume(表达式,f’提示message’) pytest.assume(表达式,f‘提示message’) pytest.ass…...

ctfshow DSBCTF web部分wp
ctfshow 单身杯 web部分wp web 签到好玩的PHP 源码: <?php error_reporting(0); highlight_file(__FILE__);class ctfshow {private $d ;private $s ;private $b ;private $ctf ;public function __destruct() {$this->d (string)$this->d;$this…...
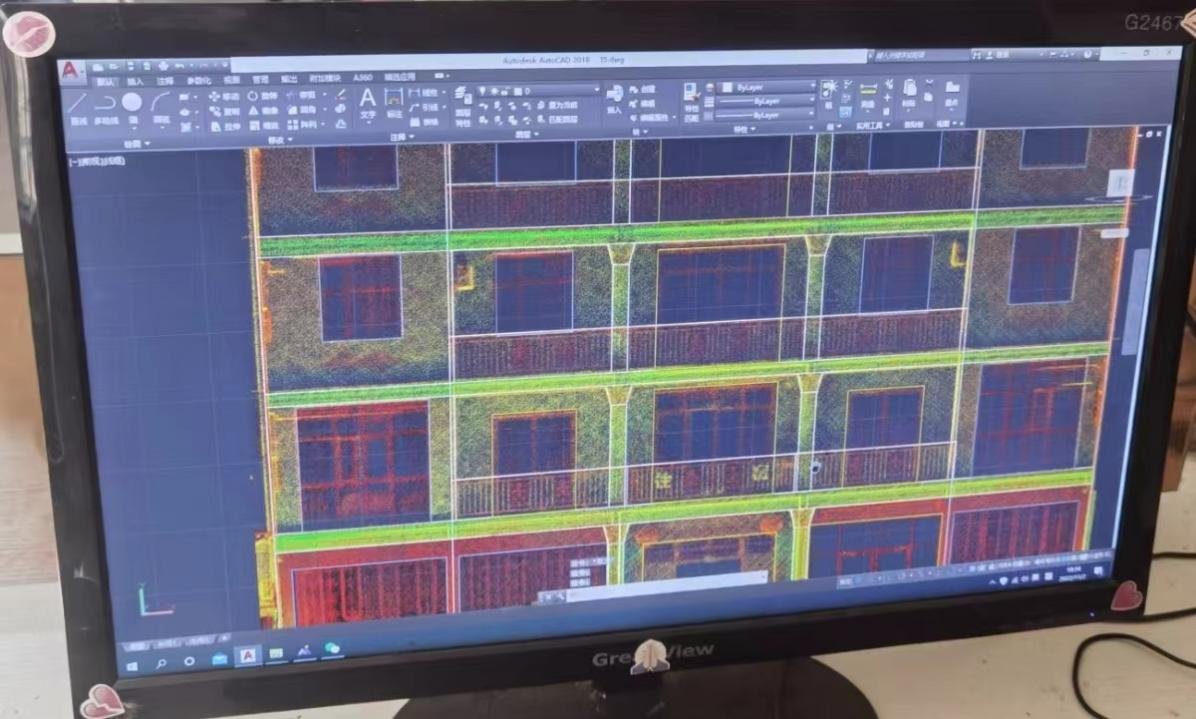
三维点云 和模型转换的问题
随着科技的发展,三维激光扫描采集的点云数据作为一种新型的数据形式,在多个领域中都展现出了其强大的应用价值。那么,什么是点云数据?它是如何生成的?又能为我们的生活和工作带来哪些便利呢? 1.…...
黑马智数Day7
获取行车管理计费规则列表 封装接口 export function getRuleListAPI(params) {return request({url: parking/rule/list,params}) } 获取并渲染数据 import { getRuleListAPI } from /apis/carmounted() {this.getRuleList() }methods: {// 获取规则列表async getRuleList(…...

虚拟机安装Ubuntu 24.04服务器版(命令行版)
这个是专门用于服务器使用的,没有GUI,常用软件安装,见 虚拟机安装Ubuntu 24.04及其常用软件(2024.7)_ubuntu24.04-CSDN博客https://blog.csdn.net/weixin_42173947/article/details/140335522这里只记录独特的安装步骤 1 下载Ubuntu 24.04安…...
.net core开发windows程序在国产麒麟操作系统中运行
.net core自从3.1版本号后,完全是一个独立的开源的多平台开发组件,目前国产化是趋势,不少项目需要开发国产如Kylin操作系统中运行的程序,无论是Web程序还是桌面程序,都有这样的需求。 首先,可明确的的.net…...
【LinuxC编程】06 - 守护进程,线程
进程组和会话 概念和特性 进程组,也称之为作业。BSD于1980年前后向Unix中增加的一个新特性。代表一个或多个进程的集合。每个进程都属于一个进程组。在waitpid函数和kill函数的参数中都曾使用到。操作系统设计的进程组的概念,是为了简化对多个进程的管…...

<websocket><PLC>使用js和html实现webscoket,与PLC进行socket通讯的实例
前言 本文是为了实现从网页端通过websocket与PLC端的socket进行数据通讯。 环境配置 系统:windows 平台:visual studio code 语言:javascript、html、PLC 库:node.js 概述 本文的目的是通过网页端与PLC进行socket通讯,但web端一般并不是直接使用socket,而是websocket,…...
nginx部署H5端程序与PC端进行区分及代理多个项目及H5内页面刷新出现404问题。
在项目中会碰见需要在nginx代理多个项目,如果在加上uniapp开发的H5端的项目,你还要在nginx中区分PC端和手机H5端,这就会让人很头大!网上大部分的资料都是采用在nginx的conf配置文件中添加区分pc和手机端的变量例如:set…...

blenderFds代码解读
文章目录 一. 介绍1. FDS(Fire Dynamics Simulator)2. BlenderFDS 二. 下载代码三. 开发环境配置四. 代码解读1. blender python特有语法2. 代码结构2.1 变量名解释2.2 bl文件夹operators文件夹ui其他文件 2.2 lang文件夹bf_sceneON_GEOMON_MESHON_MOVEO…...
亚马逊评论爬虫+数据分析
爬取评论 做分析首先得有数据,数据是核心,而且要准确! 1、爬虫必要步骤,选好框架 2、开发所需数据 3、最后测试流程 这里我所选框架是seleniumrequest,很多人觉得selenium慢,确实不快,仅针对此…...

新手小白学习docker第六弹------Docker常规安装(安装tomcat、mysql、redis)
目录 1 总体步骤2 安装tomcat2.1 搜索镜像2.2 拉取镜像2.3 查看镜像2.4 启动镜像2.5 访问猫首页 3 安装mysql3.1 搜索镜像3.2 拉取镜像3.3 启动镜像 4 安装redis4.1 拉取镜像4.2 启动镜像(法1基础版)4.3 配置文件4.3.1 在宿主机下新建目录 /app/redis4.3…...
ReactPress与WordPress:两大开源发布平台的对比与选择
ReactPress与WordPress:两大开源发布平台的对比与选择 在当今数字化时代,内容管理系统(CMS)已成为各类网站和应用的核心组成部分。两款备受欢迎的开源发布平台——ReactPress和WordPress,各自拥有独特的优势和特点&am…...

机器情绪及抑郁症算法
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年11月12日17点02分 点击开启你的论文编程之旅https://www.aspiringcode.com/content?id17230869054974 计算机来理解你的情绪&a…...

09_AI审计平台设计:从风险识别出发而非从底稿编号出发
09 AI审计平台设计:从风险识别出发而非从底稿编号出发摘要:如果你打开一个审计系统,首页显示的是E1000、E2000、E3000这些底稿编号,那这个系统的设计者一定没搞明白审计师每天到底在想什么。我做了八年审计系统UX设计,…...

视频字幕提取难题?这个本地OCR工具让你轻松搞定SRT字幕
视频字幕提取难题?这个本地OCR工具让你轻松搞定SRT字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字幕内…...

3个关键问题揭示:为什么你需要DLSS版本管理器提升游戏体验
3个关键问题揭示:为什么你需要DLSS版本管理器提升游戏体验 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾因游戏卡顿而烦恼?是否想知道为什么别人的游戏画面更流畅?DLSS Sw…...

HarmonyOS 6 Chip 组件:设置默认后缀图标使用文档
文章目录代码默认后缀图标核心配置1. 启用默认关闭图标2. 显示优先级规则3. 关联配置项代码解析1. 启用默认后缀图标2. 不冲突条件3. 整体结构总结默认后缀图标即 Chip 内置关闭图标,由系统提供样式、尺寸、交互逻辑,无需配置图片资源,只需开…...

CANN-opbase-昇腾NPU算子开发的基础设施为什么这么重要
CANN-opbase-昇腾NPU算子开发的基础设施为什么这么重要 所有 CANN AOL 算子仓库的底层都依赖 opbase。它不提供任何算子实现,提供的是算子注册、编译、调度的基础设施。如果你要写自定义 Ascend C 算子,opbase 是绕不过去的第一步。 opbase 提供了什么组…...

蚂蚁面试实录:手撕多头注意力到LoRA配置的九个坑
面试开场:写代码,别背公式蚂蚁AI应用开发岗面试一开始,面试官没有让我复述Transformer定义,而是直接说:“用PyTorch手写一个Multi-Head Attention,讲清楚Q、K、V的维度变化。”这种考察方式在蚂蚁很常见&am…...

GEO优化的时间窗口期:从流量分发到语义占位的技术范式转移
过去几十年,互联网的信息检索逻辑建立在倒排索引与超链接分析的基础之上:用户输入关键词,搜索引擎通过爬虫抓取并返回链接列表,网站则通过SEO(搜索引擎优化)争夺SERP(搜索结果页)的排…...

你的仿真传感器数据准吗?Gazebo中激光雷达与深度相机的噪声模型配置与Rviz可视化调参实战
高保真机器人仿真:Gazebo传感器噪声模型与Rviz可视化调参全指南 在机器人算法开发中,仿真环境的真实性直接决定了算法测试的有效性。许多SLAM和导航算法在仿真环境中表现优异,一旦部署到真实机器人上却出现各种问题,这往往源于仿真…...

CANN/cannbot-skills Skill测试框架
Skill 测试框架 【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills 基于变更文件识别受影响的 skills,执行对应…...

2025-2026年护眼灯品牌推荐:十大排行产品专业评测熬夜加班防眼干疲劳性价比高注意事项
摘要 当家庭与办公场景对光环境的要求从“照亮”升级为“护眼”,决策者面临的核心挑战已转变为如何在纷繁的技术参数与品牌承诺中,识别出真正能长期守护视觉健康、并适配多元场景的专业解决方案。根据全球市场研究机构Grand View Research的报告…...