使用python-Spark使用的场景案例具体代码分析
使用场景
1. 数据批处理
• 日志分析:互联网公司每天会产生海量的服务器日志,如访问日志、应用程序日志等。Spark可以高效地读取这些日志文件,对数据进行清洗(例如去除无效记录、解析日志格式)、转换(例如提取关键信息如用户ID、访问时间、访问页面等)和分析(例如统计页面访问量、用户访问路径等)。
• 数据仓库ETL(Extract,Transform,Load):在构建数据仓库时,需要从各种数据源(如关系型数据库、文件系统等)提取数据,进行清洗、转换和加载到数据仓库中。Spark可以处理大规模的数据,并且通过其丰富的转换操作(如对数据进行聚合、关联等),能够很好地完成ETL流程。
2. 机器学习与数据挖掘
• 推荐系统:基于用户的行为数据(如购买记录、浏览历史等)和物品的属性数据,Spark MLlib(机器学习库)可以用于构建推荐模型。例如,使用协同过滤算法来发现用户的兴趣偏好,为用户推荐可能感兴趣的商品、电影、音乐等。
• 聚类分析:对于大规模的数据集,如客户细分场景下的用户特征数据,Spark可以应用聚类算法(如K - Means)将相似的用户或数据点聚集在一起,帮助企业更好地理解客户群体的结构,进行精准营销等活动。
3. 实时数据处理
• 实时监控与预警:在金融领域,Spark Streaming可以实时处理股票交易数据,计算关键指标(如实时股价波动、成交量变化等),当指标超出设定的阈值时,及时发出预警信号。
• 实时交通数据分析:通过接入交通传感器(如摄像头、测速仪等)的实时数据,Spark可以对交通流量、车速、拥堵情况等进行实时分析,为交通管理部门提供决策支持,如动态调整交通信号灯时间。
Spark使用场景的详细代码案例
1. 数据批处理 - 日志分析
from pyspark.sql import SparkSession
from pyspark.sql.functions import split, count, col# 创建SparkSession
spark = SparkSession.builder.appName("LogAnalysis").getOrCreate()# 假设日志数据格式为每行: [IP地址, 时间戳, 请求方法, 请求路径, 协议, 状态码, 用户代理]
# 这里模拟一些日志数据
log_data = [("192.168.1.1", "2024-11-08 10:00:00", "GET", "/index.html", "HTTP/1.1", "200", "Mozilla/5.0"),("192.168.1.2", "2024-11-08 10:05:00", "GET", "/about.html", "HTTP/1.1", "200", "Chrome/100.0"),("192.168.1.1", "2024-11-08 10:10:00", "POST", "/login", "HTTP/1.1", "200", "Mozilla/5.0")
]columns = ["ip", "timestamp", "method", "path", "protocol", "status", "user_agent"]
df = spark.createDataFrame(log_data, columns)# 统计每个页面的访问次数
page_views = df.groupBy("path").agg(count("*").alias("views"))
page_views.show()# 统计每个IP的请求次数
ip_requests = df.groupBy("ip").agg(count("*").alias("requests"))
ip_requests.show()# 找出访问次数最多的前5个页面
top_pages = page_views.orderBy(col("views").desc()).limit(5)
top_pages.show()# 关闭SparkSession
spark.stop()
2. 数据批处理 - 数据仓库 ETL(以从CSV文件提取数据并加载到新表为例)
from pyspark.sql import SparkSession
import os# 创建SparkSession
spark = SparkSession.builder.appName("ETLExample").getOrCreate()# 假设源数据是一个CSV文件,路径为以下(这里可以替换为真实路径)
csv_path = "/path/to/source/csv/file.csv"
if not os.path.exists(csv_path):raise FileNotFoundError(f"CSV file not found at {csv_path}")# 读取CSV文件,假设CSV文件有列名:id, name, age
df = spark.read.csv(csv_path, header=True, inferSchema=True)# 进行一些数据转换,比如将年龄加1(这里只是示例,可以根据实际需求调整)
df = df.withColumn("new_age", df.age + 1)# 假设要将数据加载到一个新的Parquet格式文件中,路径为以下(可替换)
output_path = "/path/to/output/parquet/file.parquet"
df.write.mode("overwrite").parquet(output_path)# 关闭SparkSession
spark.stop()
3. 机器学习与数据挖掘 - 推荐系统(基于用户 - 物品评分的协同过滤)
from pyspark.sql import SparkSession
from pyspark.ml.recommendation import ALS
from pyspark.ml.evaluation import RegressionEvaluator# 创建SparkSession
spark = SparkSession.builder.appName("RecommendationSystem").getOrCreate()# 模拟用户 - 物品评分数据
data = [(1, 1, 5.0),(1, 2, 4.0),(2, 1, 3.0),(2, 2, 2.0),(2, 3, 4.0),(3, 1, 2.0),(3, 3, 5.0),(4, 2, 3.0),(4, 3, 4.0),
]columns = ["user_id", "item_id", "rating"]# 创建DataFrame
df = spark.createDataFrame(data, columns)# 划分训练集和测试集
(train_df, test_df) = df.randomSplit([0.8, 0.2])# 创建ALS模型
als = ALS(userCol="user_id", itemCol="item_id", ratingCol="rating", coldStartStrategy="drop")# 训练模型
model = als.fit(train_df)# 对测试集进行预测
predictions = model.transform(test_df)# 评估模型
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error = {rmse}")# 为用户生成推荐
user_recs = model.recommendForAllUsers(5)
user_recs.show(truncate=False)# 关闭SparkSession
spark.stop()
4. 机器学习与数据挖掘 - 聚类分析(K - Means 聚类)
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans# 创建SparkSession
spark = SparkSession.builder.appName("KMeansClustering").getOrCreate()# 模拟客户特征数据,这里假设每个客户有两个特征:年龄和收入
data = [(25, 50000),(30, 60000),(35, 70000),(40, 80000),(28, 55000),(32, 65000),
]columns = ["age", "income"]
df = spark.createDataFrame(data, columns)# 将特征列组合成一个向量列
assembler = VectorAssembler(inputCols=columns, outputCol="features")
df = assembler.transform(df)# 创建K - Means模型,设置聚类数为3
kmeans = KMeans(k=3, seed=1)
model = kmeans.fit(df)# 预测聚类结果
predictions = model.transform(df)
predictions.show()# 关闭SparkSession
spark.stop()
5. 实时数据处理 - 实时监控与预警(以简单的股票价格监控为例,使用Spark Streaming和Socket模拟实时数据)
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext# 创建SparkSession和StreamingContext,设置批处理间隔为5秒
spark = SparkSession.builder.appName("StockMonitoring").getOrCreate()
ssc = StreamingContext(spark.sparkContext, 5)# 这里使用Socket模拟接收实时股票价格数据,实际中可能是从消息队列等接收
# 假设数据格式为: 股票代码,价格
lines = ssc.socketTextStream("localhost", 9999)# 解析数据
data = lines.map(lambda line: line.split(","))# 将数据转换为DataFrame格式(这里只是简单示例,可能需要更多处理)
from pyspark.sql.types import StructType, StructField, StringType, DoubleType
schema = StructType([StructField("symbol", StringType(), True),StructField("price", DoubleType(), True)
])
df = data.toDF(schema)# 假设要监控某只股票(这里以股票代码为 'AAPL' 为例),当价格超过150时预警
apple_stock = df.filter(df.symbol == "AAPL")
alert = apple_stock.filter(df.price > 150).map(lambda row: f"Alert: {row.symbol} price {row.price} is high!")alert.pprint()# 启动 StreamingContext
ssc.start()
# 等待停止
ssc.awaitTermination()
6. 实时数据处理 - 实时交通数据分析(使用Spark Streaming和Kafka,假设已经有Kafka环境和交通数据主题)
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import json# 创建SparkSession和StreamingContext,设置批处理间隔为10秒
spark = SparkSession.builder.appName("TrafficAnalysis").getOrCreate()
ssc = StreamingContext(spark.sparkContext, 10)# Kafka参数,这里需要替换为真实的Kafka服务器地址和交通数据主题
kafkaParams = {"metadata.broker.list": "localhost:9092"}
topic = "traffic_data"# 从Kafka读取实时交通数据
kafkaStream = KafkaUtils.createDirectStream(ssc, [topic], kafkaParams)# 解析JSON格式的交通数据,假设数据包含车速、车流量等信息
def parse_traffic_data(json_str):try:data = json.loads(json_str)return (data["location"], data["speed"], data["volume"])except Exception as e:print(f"Error parsing data: {e}")return Noneparsed_data = kafkaStream.map(lambda x: parse_traffic_data(x[1]))
valid_data = parsed_data.filter(lambda x: x is not None)# 将数据转换为DataFrame格式(这里只是简单示例,可能需要更多处理)
from pyspark.sql.types import StructType, StructField, StringType, DoubleType
schema = StructType([StructField("location", StringType(), True),StructField("speed", DoubleType(), True),StructField("volume", DoubleType(), True)
])
df = valid_data.toDF(schema)# 计算每个区域的平均车速和车流量
average_speed_volume = df.groupBy("location").agg({"speed": "avg", "volume": "sum"})
average_speed_volume.pprint()# 启动 StreamingContext
ssc.start()
# 等待停止
ssc.awaitTermination()
相关文章:

使用python-Spark使用的场景案例具体代码分析
使用场景 1. 数据批处理 • 日志分析:互联网公司每天会产生海量的服务器日志,如访问日志、应用程序日志等。Spark可以高效地读取这些日志文件,对数据进行清洗(例如去除无效记录、解析日志格式)、转换(例如…...

如何查看本地的个人SSH密钥
1.确保你的电脑上安装了 Git。 你可以通过终端或命令提示符输入以下命令来检查: git --version 如果没有安装,请前往 Git 官网 下载并安装适合你操作系统的版本。 2.查找SSH密钥 默认情况下,SSH密钥存储在你的用户目录下的.ssh文件夹中。…...

本人认为 写程序的三大基本原则
1. 合法性 定义:合法性指的是程序必须遵守法律法规和道德规范,不得用于非法活动。 建议: 了解法律法规:在编写程序之前,了解并遵守所在国家或地区的法律法规,特别是与数据隐私、版权、网络安…...
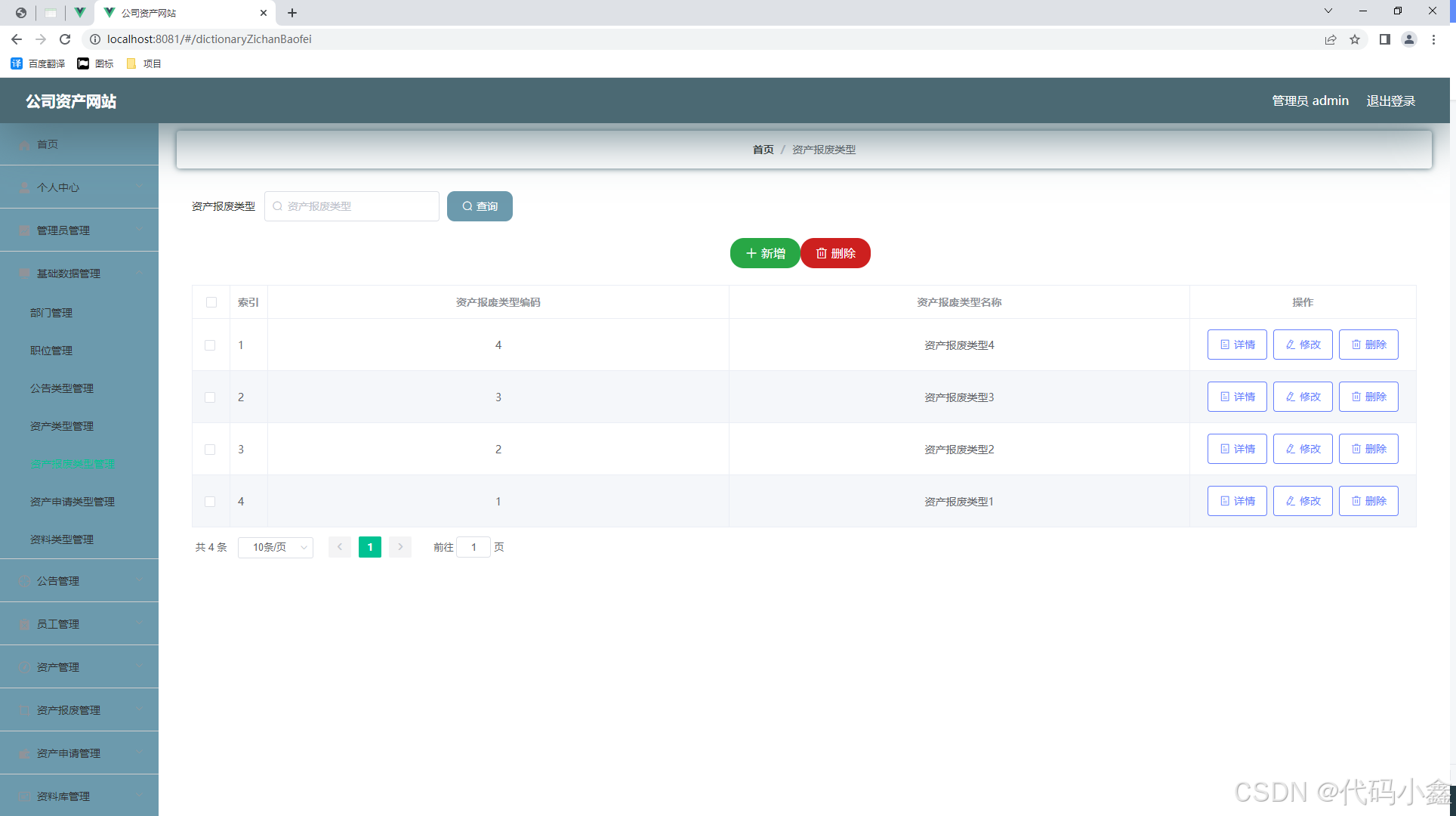
A030-基于Spring boot的公司资产网站设计与实现
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 赠送计算机毕业设计600…...

React Hooks 深度解析与实战
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 React Hooks 深度解析与实战 React Hooks 深度解析与实战 React Hooks 深度解析与实战 引言 什么是 Hooks? 定义 为什么需要 Ho…...

#渗透测试#SRC漏洞挖掘#蓝队基础之网络七层杀伤链04 终章
网络杀伤链模型(Kill Chain Model)是一种用于描述和分析网络攻击各个阶段的框架。这个模型最初由洛克希德马丁公司提出,用于帮助企业和组织识别和防御网络攻击。网络杀伤链模型将网络攻击过程分解为多个阶段,每个阶段都有特定的活…...

计算机毕业设计Python+大模型农产品推荐系统 农产品爬虫 农产品商城 农产品大数据 农产品数据分析可视化 PySpark Hadoop
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

爬虫补环境案例---问财网(rpc,jsdom,代理,selenium)
目录 一.环境检测 1. 什么是环境检测 2.案例讲解 二 .吐环境脚本 1. 简介 2. 基础使用方法 3.数据返回 4. 完整代理使用 5. 代理封装 6. 封装所有使用方法 jsdom补环境 1. 环境安装 2. 基本使用 3. 添加参数形式 Selenium补环境 1. 简介 2.实战案例 1. 逆向目…...

SpringBoot有几种获取Request对象的方法
HttpServletRequest 简称 Request,它是一个 Servlet API 提供的对象,用于获取客户端发起的 HTTP 请求信息。例如:获取请求参数、获取请求头、获取 Session 会话信息、获取请求的 IP 地址等信息。 那么问题来了,在 Spring Boot 中…...

在 Windows 11 中使用 MuMu 模拟器 12 国际版配置代理
**以下是优化后的教学内容,使用 Markdown 格式,便于粘贴到 CSDN 或其他支持 Markdown 格式的编辑器中: 在 Windows 11 中使用 MuMu 模拟器 12 国际版配置代理 MuMu 模拟器内有网络设置功能,可以直接在模拟器中配置代理。但如果你不确定如何操作,可以通过在 Windows 端设…...
ASP.NET Core Webapi 返回数据的三种方式
ASP.NET Core为Web API控制器方法返回类型提供了如下几个选择: Specific type IActionResult ActionResult<T> 1. 返回指定类型(Specific type) 最简单的API会返回原生的或者复杂的数据类型(比如,string 或者…...

SQL面试题——蚂蚁SQL面试题 连续3天减少碳排放量不低于100的用户
连续3天减少碳排放量不低于100的用户 这是一道来自蚂蚁的面试题目,要求我们找出连续3天减少碳排放量低于100的用户,之前我们分析过两道关于连续的问题了 SQL面试题——最大连续登陆问题 SQL面试题——球员连续四次得分 这两个问题都是跟连续有关的,但是球员连续得分的难…...

Python酷库之旅-第三方库Pandas(216)
目录 一、用法精讲 1011、pandas.DatetimeIndex.tz属性 1011-1、语法 1011-2、参数 1011-3、功能 1011-4、返回值 1011-5、说明 1011-6、用法 1011-6-1、数据准备 1011-6-2、代码示例 1011-6-3、结果输出 1012、pandas.DatetimeIndex.freq属性 1012-1、语法 1012…...

论文解析:计算能力资源的可信共享:利益驱动的异构网络服务提供机制
目录 论文解析:计算能力资源的可信共享:利益驱动的异构网络服务提供机制 KM-SMA算法 KM-SMA算法通过不断更新节点的可行顶点标记值(也称为顶标),利用匈牙利方法(Hungarian method)来获取匹配结果。在获取匹配结果后,该算法还会判断该结果是否满足Pareto最优性,即在没…...
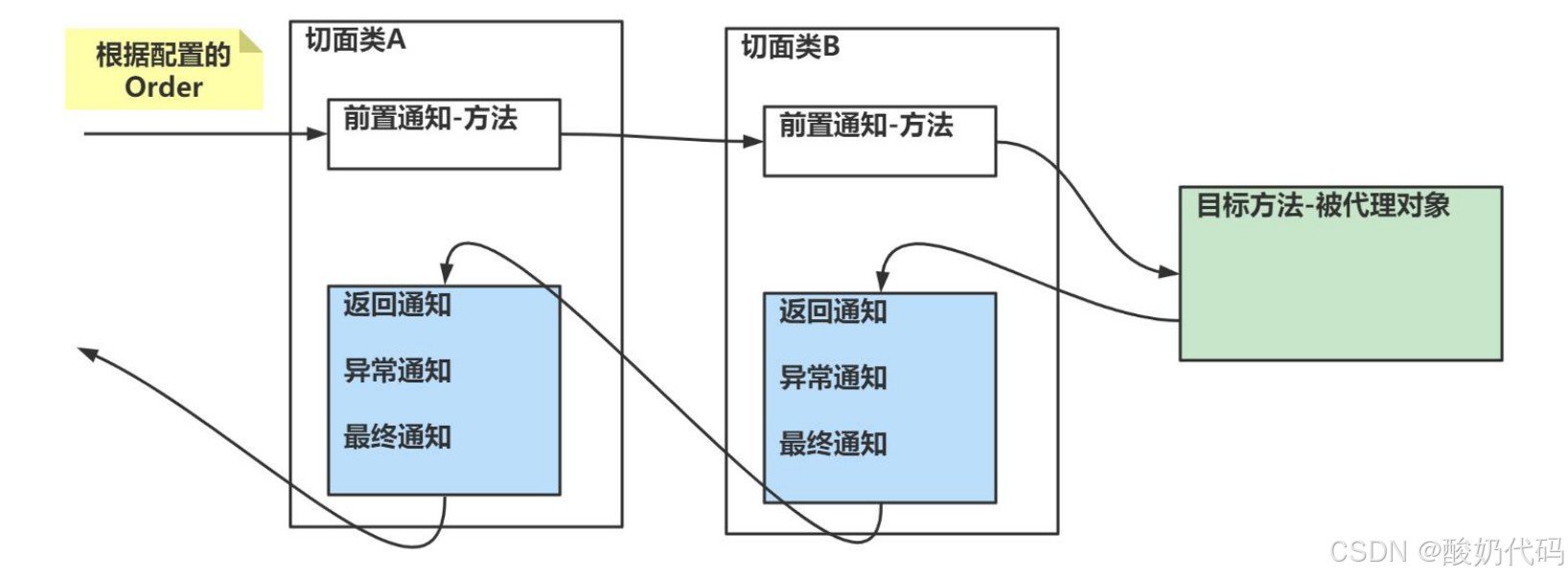
Spring AOP技术
1.AOP基本介绍 AOP 的全称 (aspect oriented programming) ,面向切面编程。 1.和传统的面向对象不同。 面向切面编程是根据自我的需求,将切面类的方法切入到其他的类的方法中。(这么说抽象吧!来张图来解释。) 如图 传…...
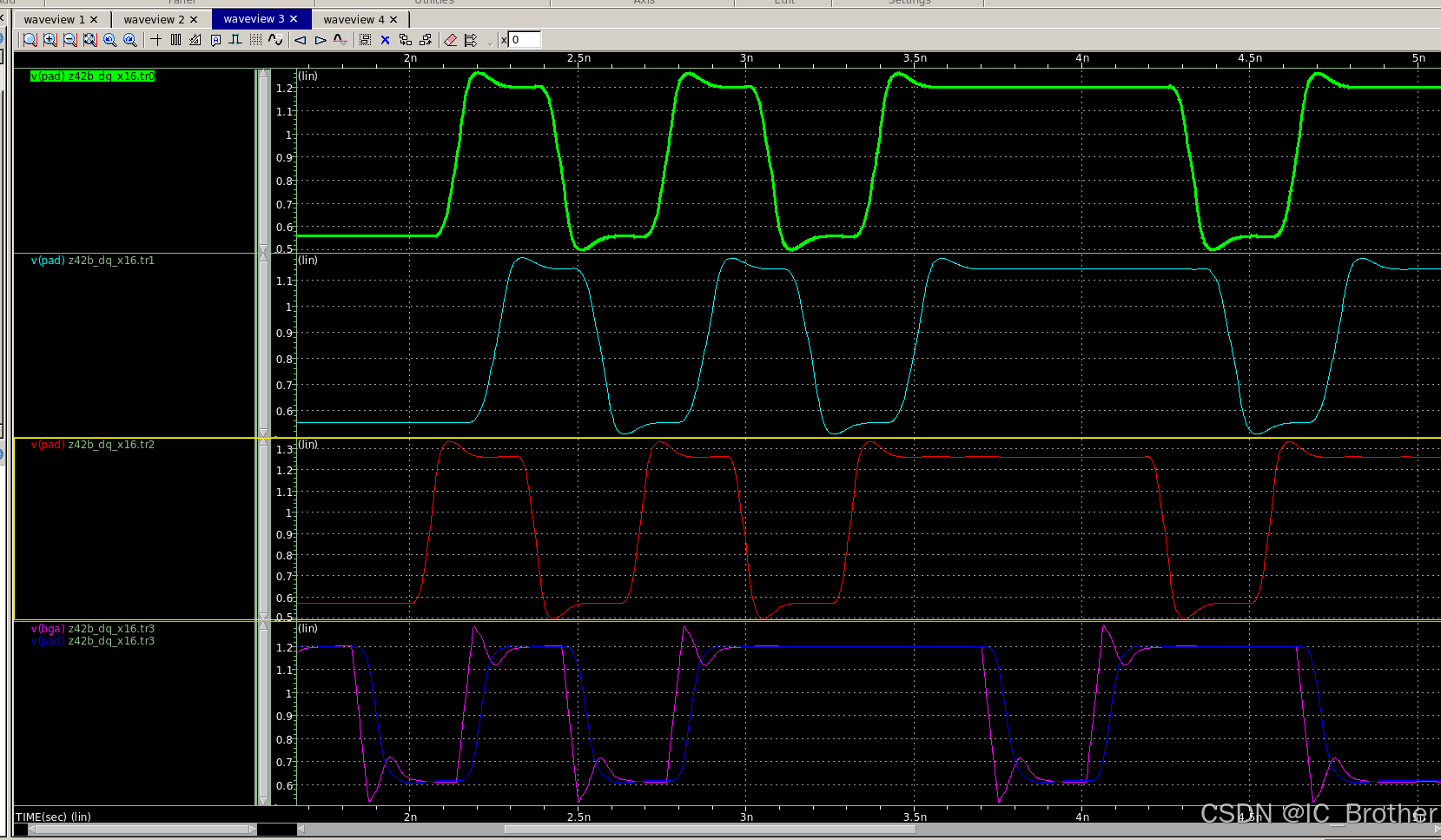
数字IC实践项目(10)—基于System Verilog的DDR4 Model/Tb 及基础Verification IP的设计与验证(付费项目)
数字IC实践项目(10)—基于System Verilog的DDR4 Model/Tb 及基础Verification IP的设计与验证(付费项目) 前言项目框图1)DDR4 Verification IP2)DDR4 JEDEC Model & Tb 项目文件1)DDR4 Veri…...

MATLAB保存多帧图形为视频格式
基本思路 在Matlab中,要将drawnow绘制的多帧数据保存为视频格式,首先需要创建一个视频写入对象。这个对象用于将每一帧图像数据按照视频格式的要求进行组合和编码。然后,在每次drawnow更新绘图后,将当前的图形窗口内容捕获为一帧图…...
 dict字典)
redis7.x源码分析:(3) dict字典
dict字典采用经典hash表数据结构实现,由键值对组成,类似于C中的unordered_map。两者在代码实现层面存在一些差异,比如gnustl的unordered_map分配的桶数组个数是(质数n),而dict分配的桶数组个数是࿰…...

连续九届EI稳定|江苏科技大学主办
【九届EI检索稳定|江苏科技大学主办 | IEEE出版 】 🎈【截稿倒计时】!!! ✨徐秘书:gsra_huang ✨往届均已检索,已上线IEEE官网 🎊第九届清洁能源与发电技术国际学术会议(CEPGT 2…...

HarmonyOS NEXT应用开发实战 ( 应用的签名、打包上架,各种证书详解)
前言 没经历过的童鞋,首次对HarmonyOS的应用签名打包上架可能感觉繁琐。需要各种秘钥证书生成和申请,混在一起也分不清。其实搞清楚后也就那会事,各个文件都有它存在的作用。 HarmonyOS通过数字证书与Profile文件等签名信息来保证鸿蒙应用/…...

昇腾CANN shmem:把多张 NPU 的 HBM 变成一块全局内存
hccl 的通信模型是消息传递——发送方调 send,接收方调 recv,两边同步。hixl 的模型是单边推送——发送方调 put,接收方不用参与。shmem 是第三种模型:PGAS(Partitioned Global Address Space),…...
)
用ESP32和EC11编码器做个无极调光台灯,Arduino代码全解析(附防抖电路)
用ESP32和EC11编码器打造无极调光台灯:从硬件防抖到代码优化的完整指南 在智能家居DIY领域,无极调光台灯一直是创客们热衷的项目之一。传统旋钮调光台灯存在机械磨损、精度有限等问题,而基于ESP32和EC11编码器的数字解决方案不仅寿命更长&…...

从环境变量到Git Bash:给Plink找个‘家’,让你的遗传数据分析命令随处可跑
从环境变量到Git Bash:打造遗传数据分析的高效工作流 在遗传数据分析的日常工作中,Plink作为核心工具几乎出现在每个分析流程中。但许多研究者都会遇到这样的困扰:每次打开新的终端窗口,要么需要反复输入冗长的路径,要…...

统信UOS/麒麟KYLINOS用户看过来:除了Termius,这款开源免费的SSH工具electerm更香!
国产操作系统用户的SSH工具新选择:electerm深度体验报告 对于统信UOS和麒麟KYLINOS用户而言,远程服务器管理是日常工作中的高频需求。Termius作为老牌SSH工具确实表现不俗,但今天我们要探讨的electerm,或许能给你带来意想不到的惊…...
 实战指南:从零搭建 AI Agent 工具生态系统)
MCP (Model Context Protocol) 实战指南:从零搭建 AI Agent 工具生态系统
引言 2025年底 Anthropic 推出的 Model Context Protocol (MCP) 正在彻底改变 AI Agent 与外部工具的交互方式。截至 2026年5月,MCP 生态系统已拥有超过 3000 个开源 Server 实现,成为连接 LLM 与现实世界数据的标准协议。 本文将深入讲解 MCP 的核心原…...

2026最新论文降AI全攻略:亲测5大高质量工具,掌握免费Prompt指令顺利交稿
为了找到真正靠谱的解决方案,我过去测试了市面上大部分号称能降低ai率的方法。从一分钱不花的模型指令,到各种付费的专业降ai率工具,用手头的文本做了几十次实操对比。说心里话,里面套路确实不少,有些方法用完后语句颠…...

如何在Windows 11上快速安装Android应用?终极APK安装器完全指南 [特殊字符]
如何在Windows 11上快速安装Android应用?终极APK安装器完全指南 🚀 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows上安装Android…...

龙芯3A5000开发板PMON升级UEFI固件实战指南
1. 项目概述:从“能用”到“好用”的固件升级之路最近折腾了一块搭载龙芯3A5000处理器的开发板,型号是迅为的LS3A5000。拿到手的时候,板子预装的固件还是传统的PMON。PMON对于玩龙芯的老朋友来说不陌生,它功能稳定,但界…...
)
麒麟系统离线部署OnlyOffice,我踩过的那些坑(附Docker镜像包和完整配置)
麒麟系统离线部署OnlyOffice实战避坑指南 在国产化替代浪潮中,麒麟系统作为主流国产操作系统,正逐步应用于各类关键信息基础设施领域。而办公软件作为日常刚需,如何在麒麟系统上实现高效、安全的文档协作成为许多技术团队面临的挑战。OnlyOff…...

人工智能系统的测试:AI模型的可靠性与鲁棒性测试
在人工智能技术深度渗透各行业的当下,AI模型的可靠性与鲁棒性直接关乎业务安全与用户信任。对于软件测试从业者而言,突破传统测试思维,构建适配AI特性的测试体系,已成为保障AI系统高质量落地的核心任务。 一、AI模型可靠性与鲁棒…...