Python →爬虫实践
爬取研究中心的书目
现在,想要把如下网站中的书目信息爬取出来。
案例一 耶鲁
Publications | Yale Law School
分析网页,如下图所示,需要爬取的页面,标签信息是“<p>”,所以用 items=soup.find_all("p")

代码如下:
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbookurl="https://law.yale.edu/china-center/publications/recent-staff-publications"webfile=requests.get(url)
webfile.encoding="utf-8"
data=webfile.textsoup=bs(data,"html.parser")
soup.prettify()items=soup.find_all("p")
for i in items:print(i.get_text())完善代码如下:
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
import rewb=Workbook()
ws=wb.activewfile=open("bool.txt","w",encoding="utf-8")url="https://law.yale.edu/china-center/publications/recent-staff-publications"webfile=requests.get(url)
webfile.encoding="utf-8"
data=webfile.textsoup=bs(data,"html.parser")
soup.prettify()items=soup.find_all("p")# 正则表达式匹配模式
pattern1 = r'([^,\n“]+), “([^”]+),”\s*([^,\n]+)'
pattern2 = r'([^,]+(?: and [^,]+)*), “([^”]+),”''''
正则表达式匹配模式:([^,]+(?: and [^,]+)*):匹配作者名。这个模式匹配一个或多个名字,由“and”连接。[^,]+匹配一个或多个非逗号字符,(?: and [^,]+)*是一个非捕获组,匹配零个或多个“and”后跟一个或多个非逗号字符的模式。
“([^”]+),”:匹配文章名。这个模式匹配引号内的任何字符,直到遇到闭合的引号和逗号。([^,\n“]+):匹配作者名。这个模式匹配一个或多个非逗号、换行符和左引号的字符序列。[^,\n“]是一个字符集,表示匹配除了逗号、换行符和左引号之外的任何字符。+表示匹配一个或多个这样的字符。
“([^”]+),”:匹配文章名。这个模式匹配以左引号开始,以右引号结束的任何字符序列,并且确保文章名后面跟着一个逗号。
([^,\n]+):匹配期刊名。这个模式匹配一个或多个非逗号和换行符的字符序列。'''for i in items:info=i.get_text()# 查找所有匹配项matches = re.findall(pattern1, info)if len(matches)>0:print(matches)for m in matches:print(m,sep=",",file=wfile)wfile.close()将txt文本导入excel即可。原因在于正则表达式中得到的列表中的信息,有的似乎是tuptle类型,导致openpyxl无法输入xlsx表格中。所以采用了txt文本方式。
基于以上出现的情况,再次优化代码,如下:
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
import rewb=Workbook()
ws=wb.activewfile=open("bool.txt","w",encoding="utf-8")url="https://law.yale.edu/china-center/publications/recent-staff-publications"webfile=requests.get(url)
webfile.encoding="utf-8"
data=webfile.textsoup=bs(data,"html.parser")
soup.prettify()items=soup.find_all("p")# 正则表达式匹配模式
pattern1 = r'([^\n“]+), “([^”]+),”\s*([^,\n]+)' #作者和文章名和期刊名,用括号将三者区分
pattern2 = r'([^\n“]+), “([^”]+),”\s*([^,\n]+[)])'
#parttern1缺少了最后的右括号,在这里补充上。[)]表示可供选择。for i in items:info=i.get_text()# 查找所有匹配项matches = re.findall(pattern2, info)if len(matches)>0:print(matches)for m in matches:mlist=[]#将元组的元素放到列表中,这样可以把列表的字符串输出到xlsx中for k in m:mlist.append(k)print(k,sep=",",end=";",file=wfile)print("\n",file=wfile)
## print(type(k))ws.append(mlist)## print(m,sep=",",file=wfile)#注意,m是元组而不是字符串#print(type(m))wfile.close()
wb.save("book2.xlsx")首先是完善了正则表达式:
'''
正则表达式匹配模式[^,]+匹配一个或多个非逗号字符,
(?: and [^,]+)*是一个非捕获组,匹配零个或多个“and”后跟一个或多个非逗号字符的模式。([^\n“]+):匹配作者名。这个模式匹配一个或多个非换行符和左引号的字符序列。
“([^”]+),”:匹配文章名。这个模式匹配引号内的任何字符,直到遇到闭合的引号和逗号。
[^,\n“]是一个字符集,表示匹配除了逗号、换行符和左引号之外的任何字符。+表示匹配一个或多个这样的字符。
“([^”]+),”:匹配文章名。这个模式匹配以左引号开始,以右引号结束的任何字符序列,并且确保文章名后面跟着一个逗号。
([^,\n]+):匹配期刊名。这个模式匹配一个或多个非逗号和换行符的字符序列。
'''# 正则表达式匹配模式
pattern1 = r'([^\n“]+), “([^”]+),”\s*([^,\n]+)' #作者和文章名和期刊名,用括号将三者区分
pattern2 = r'([^\n“]+), “([^”]+),”\s*([^,\n]+[)])'
#parttern1缺少了最后的右括号,在这里补充上。[)]表示可供选择。
然后循环输出元组中的元素,放到列表中,从而将元组的元素转化为列表中的字符串。
最后,将不必要的信息清除,简洁代码如下:
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
import rewb=Workbook()
ws=wb.activewfile=open("bool.txt","w",encoding="utf-8")url="https://law.yale.edu/china-center/publications/recent-staff-publications"webfile=requests.get(url)
webfile.encoding="utf-8"
data=webfile.textsoup=bs(data,"html.parser")
soup.prettify()items=soup.find_all("p")# 正则表达式匹配模式pattern2 = r'([^\n“]+), “([^”]+),”\s*([^,\n]+[)])'#作者和文章名和期刊名,用括号将三者区分for i in items:info=i.get_text()# 查找所有匹配项matches = re.findall(pattern2, info)if len(matches)>0:print(matches)for m in matches:mlist=[]for k in m:mlist.append(k)print(k,sep=",",end=";",file=wfile) ws.append(mlist)wfile.close()
wb.save("book2.xlsx")即可完成。
案例二 哈佛
爬取哈佛大学费正清中心出版书籍的信息时候,标签信息是class="article-container entry-content clear",所以用:item1=soup.find_all(attrs={"class":"article-container entry-content clear"})

所以,爬取代码如下:
'''
下面这段代码,爬取哈佛大学费正清中心出版书籍的信息
'''
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbookwb=Workbook()
ws=wb.activefor page in range(1,9):url=f'https://fairbank.fas.harvard.edu/research/publications/page/{page}/'webFile=requests.get(url)webFile.eocoding="utf-8"data=webFile.textsoup=bs(data,'html.parser')soup.prettify()##item1=soup.find_all(attrs={"class":"uagb-post__title"})#提取书本标题信息##for i in item1:## print(i.get_text())######item2=soup.find_all(attrs={"class":"ast-excerpt-container ast-blog-single-element"})#提取书目介绍信息##for k in item2:## print(k.get_text())item3=soup.find_all(attrs={"class":"article-container entry-content clear"})#在网络页面中,找到的整个的文本for m in item3:info=m.get_text()row1=info.split("\n")row2=list(filter(lambda x:len(x)>1,row1))#过滤掉空字符串。ws.append(row2)#worksheet中添加的是列表,然后把列表中的元素挨个放到了xlsx表格中。wb.save("bool.xlsx")即可完成。
案例三 普林斯顿大学
观察该网站,标签信息是class="row search-result-wrapper"

其网站如下:
url="https://catalog.princeton.edu/?f%5Bformat%5D%5B%5D=Book&f%5Blocation%5D%5B%5D=East+Asian+Library&page=1&per_page=100"
于是写代码如下:
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
import rewb=Workbook()
ws=wb.activefor pageNum in range(1,100):#提取一百页,共10000条书目的信息url=f"https://catalog.princeton.edu/?f%5Bformat%5D%5B%5D=Book&f%5Blocation%5D%5B%5D=East+Asian+Library&page={pageNum}&per_page=100"webfile=requests.get(url)webfile.encoding="utf-8"data=webfile.textsoup=bs(data,"html.parser")soup.prettify()item=soup.find_all(attrs={"class":"row search-result-wrapper"})for m in item:info=m.get_text()row1=info.split("\n")row2=list(filter(lambda x: len(x)>1,row1))ws.append(row2)print(pageNum,pageNum/100)
wb.save("book3.xlsx")即可完成。
一日一图
代码如下:
"""
使用Python中的turtle模块绘制一个壮观的太阳系图是一个有趣且具有挑战性的任务"""import turtle
import math# 设置屏幕
screen = turtle.Screen()
screen.bgcolor("black")
screen.title("Solar System")# 创建太阳
sun = turtle.Turtle()
sun.hideturtle()
sun.penup()
sun.goto(0, -200)
sun.pendown()
sun.color("yellow")
sun.begin_fill()
sun.circle(50)
sun.end_fill()# 行星数据(名称,距离太阳的距离(单位:像素),大小(单位:像素))
planets = [("Mercury", 35, 5),("Venus", 72, 10),("Earth", 98, 10),("Mars", 152, 7),("Jupiter", 279, 30), # 简化大小,实际应更大("Saturn", 449, 25), # 简化大小,实际应更大# "Uranus" 和 "Neptune" 由于距离太远,在这个比例下可能无法很好地显示
]# 绘制行星和轨道
orbit_color = "gray"
planet_color = ["gray", "yellow", "blue", "red", "orange", "gold", "lightblue"] # 对应行星的颜色,实际应根据行星选择for i, (name, distance, size) in enumerate(planets):# 绘制轨道orbit_turtle = turtle.Turtle()orbit_turtle.hideturtle()orbit_turtle.speed(0)orbit_turtle.penup()orbit_turtle.goto(0, 0)orbit_turtle.pendown()orbit_turtle.color(orbit_color)orbit_turtle.width(2)orbit_turtle.circle(distance)orbit_turtle.hideturtle()# 绘制行星planet_turtle = turtle.Turtle()planet_turtle.hideturtle()planet_turtle.speed(0)planet_turtle.penup()# 计算行星在轨道上的位置angle = 360 * i / len(planets) # 均匀分布行星x = distance * math.cos(math.radians(angle))y = distance * math.sin(math.radians(angle)) - 200 # 减去太阳的高度planet_turtle.goto(x, y)planet_turtle.pendown()planet_turtle.color(planet_color[i % len(planet_color)]) # 循环使用颜色planet_turtle.begin_fill()planet_turtle.circle(size)planet_turtle.end_fill()planet_turtle.write(name, align="center", font=("Arial", 8, "normal"))planet_turtle.hideturtle()# 隐藏turtle光标
turtle.done()
turtle.tracer(False)
图片如下:
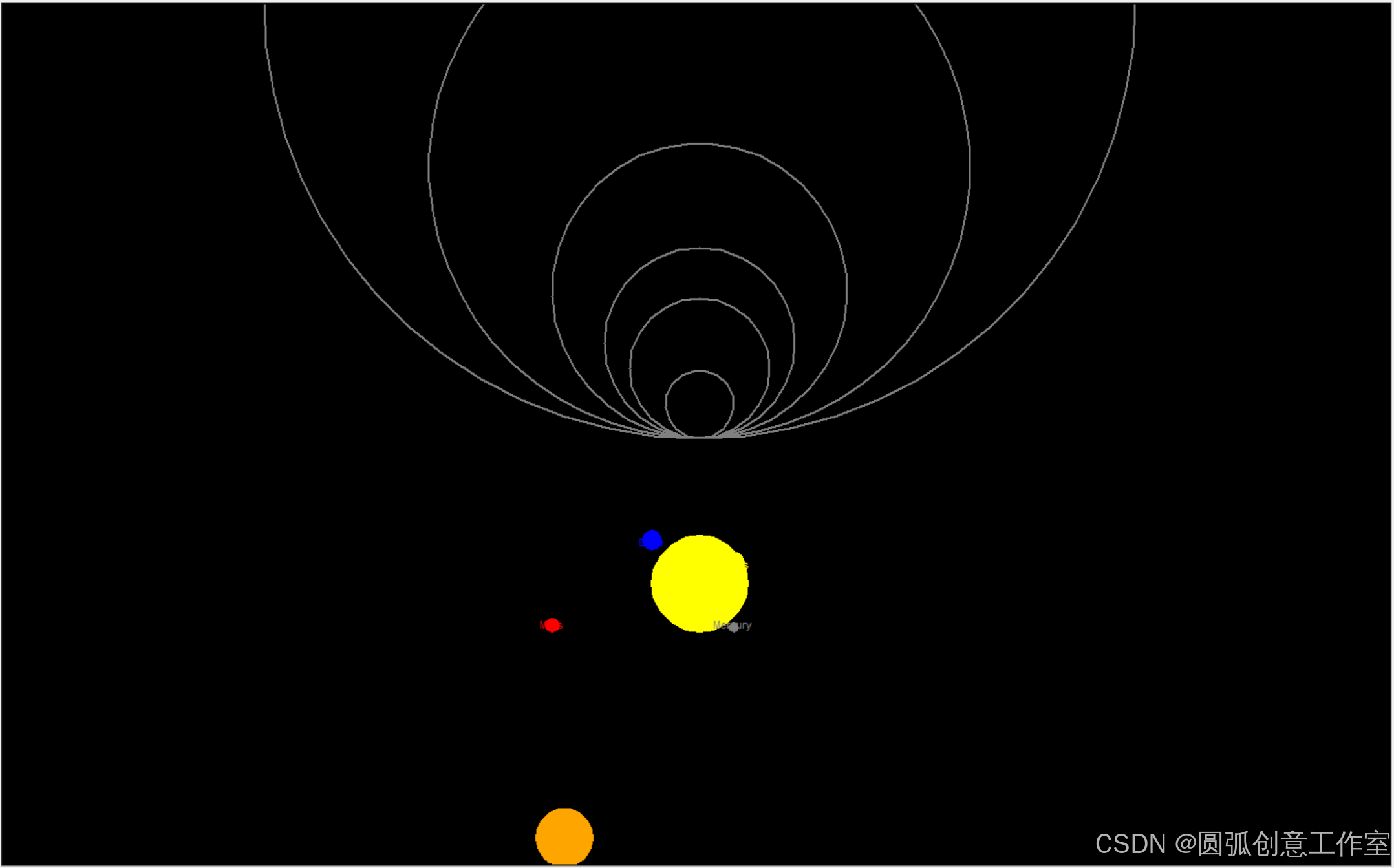
即可完成。
相关文章:
Python →爬虫实践
爬取研究中心的书目 现在,想要把如下网站中的书目信息爬取出来。 案例一 耶鲁 Publications | Yale Law School 分析网页,如下图所示,需要爬取的页面,标签信息是“<p>”,所以用 itemssoup.find_all("p&…...
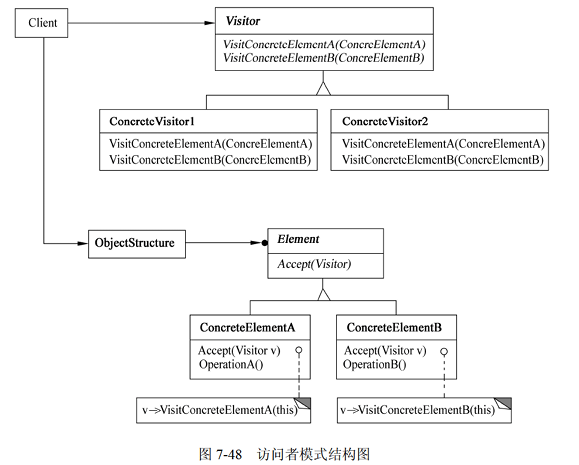
Visitor 访问者模式
1)意图 表示一个作用于某对象结构中的各元素的操作。它允许在不改变各元素的类的前提下定义用于这些元素的新操作。 2)结构 访问者模式的结构图如图 7-48 所示。 其中: Visitor(访问者) 为该对象结构中ConcreteElement 的每一个类声明一个 Vsit 操作。该操作的名字和特征标识…...

Mac解压包安装MongoDB8并设置launchd自启动
记录一下在mac上安装mongodb8过程,本机是M3芯片所以下载m芯片的安装包,intel芯片的类似操作。 首先下载安装程序包。 # M芯片下载地址 https://fastdl.mongodb.org/osx/mongodb-macos-arm64-8.0.3.tgz # intel芯片下载地址 https://fastdl.mongodb.org…...
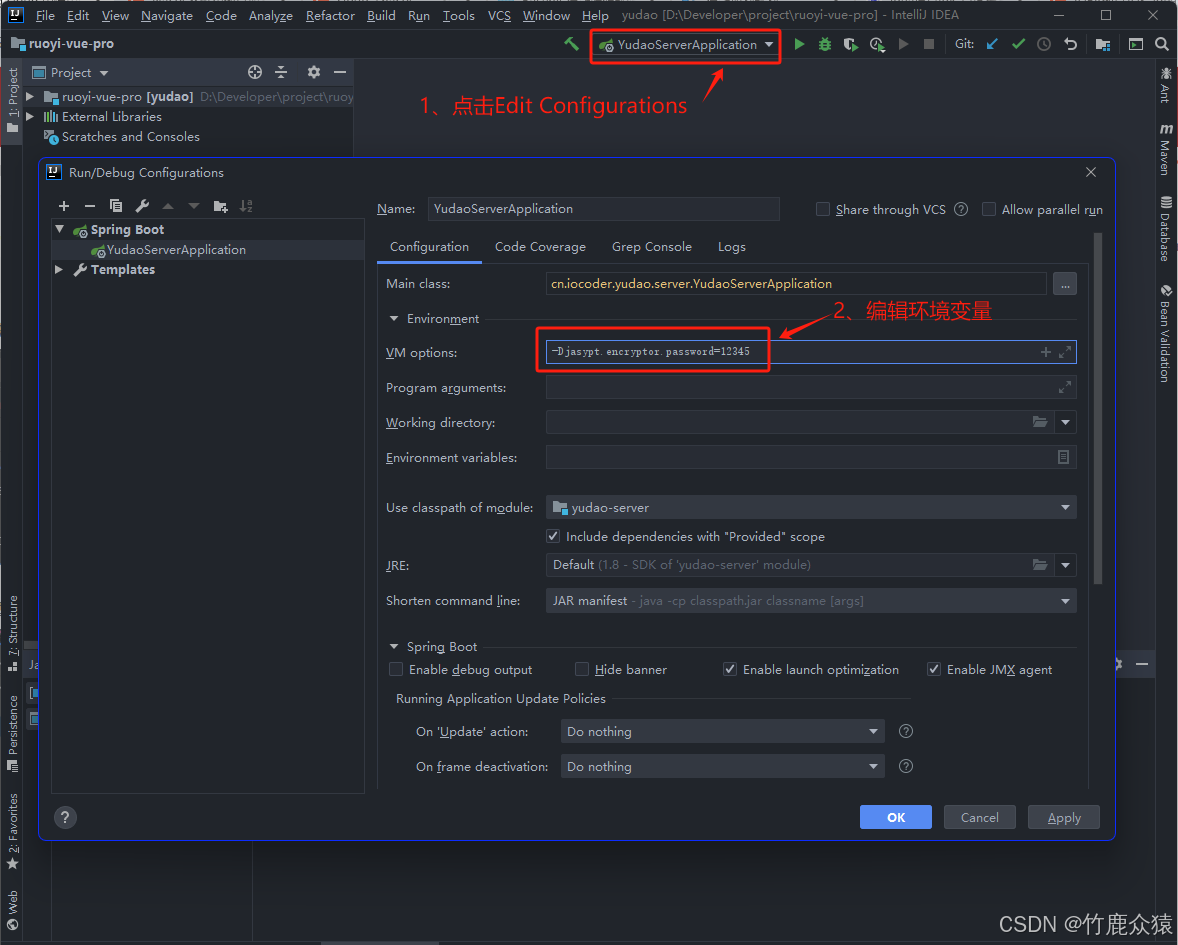
Springboot采用jasypt加密配置
目录 前言 一、Jasypt简介 二、运用场景 三、整合Jasypt 2.1.环境配置 2.2.添加依赖 2.3.添加Jasypt配置 2.4.编写加/解密工具类 2.5.自定义加密属性前缀和后缀 2.6.防止密码泄露措施 2.61.自定义加密器 2.6.2通过环境变量指定加密盐值 总结 前言 在以往的多数项目中࿰…...

加载shellcode
#include <stdio.h>#include <windows.h>DWORD GetHash(const char* fun_name){ DWORD digest 0; while (*fun_name) { digest ((digest << 25) | (digest >> 7)); //循环右移 7 位 digest *fun_name; //累加…...
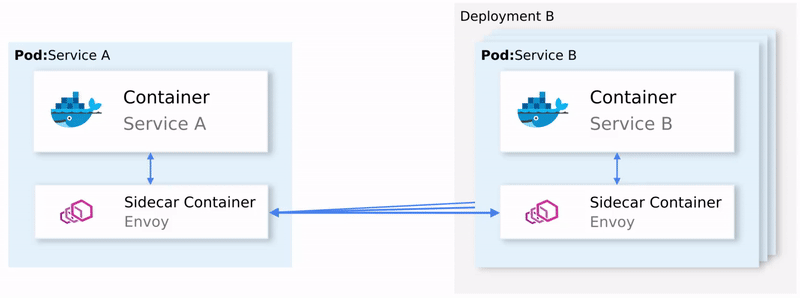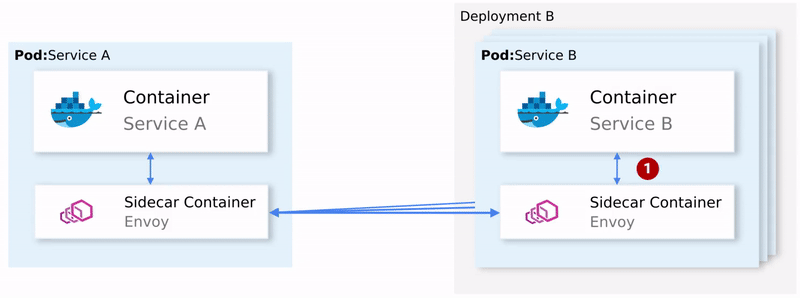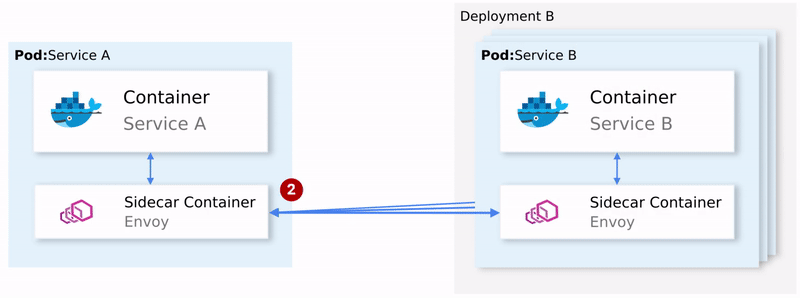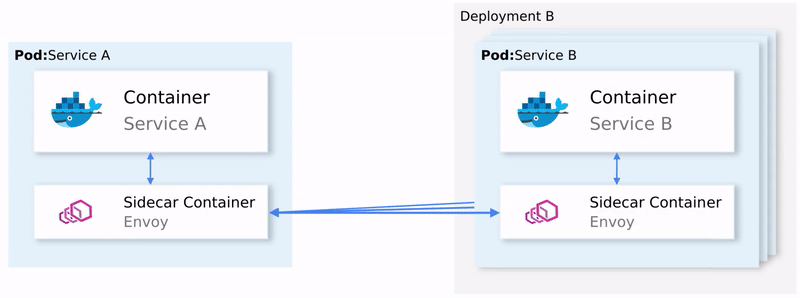
K8S如何基于Istio实现全链路HTTPS
K8S如何基于Istio实现全链路HTTPS Istio 简介Istio 是什么?为什么选择 Istio?Istio 的核心概念Service Mesh(服务网格)Data Plane(数据平面)Sidecar Mode(边车模式)Ambient Mode(环境模式)Control Plane(控制平面)Istio 的架构与组件Envoy ProxyIstiod其他组件Istio 的流量管…...
React Query在现代前端开发中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 React Query在现代前端开发中的应用 React Query在现代前端开发中的应用 React Query在现代前端开发中的应用 引言 React Query …...

【HAProxy09】企业级反向代理HAProxy高级功能之压缩功能与后端服务器健康性监测
HAProxy 高级功能 介绍 HAProxy 高级配置及实用案例 压缩功能 对响应给客户端的报文进行压缩,以节省网络带宽,但是会占用部分CPU性能 建议在后端服务器开启压缩功能,而非在HAProxy上开启压缩 注意:默认Ubuntu的包安装nginx开…...

PostgreSQL中表的数据量很大且索引过大时怎么办
在PostgreSQL中,当表的数据量很大且索引过大时,可能会导致性能问题。以下是一些优化索引和表数据的方法: 1. 评估和删除不必要的索引 识别未使用的索引:使用pg_stat_user_indexes和pg_index系统视图来查找未被使用的索引&#x…...

【QML】QML多线程应用(WorkerScript)
1. 实现功能 QML项目中,点击一个按键后,运行一段比较耗时的程序,此时ui线程会卡住。如何避免ui线程卡住。 2. 单线程(会卡住) 2.1 界面 2.2 现象 点击delay btn后,执行耗时函数(TestJs.func…...

认证鉴权框架SpringSecurity-1--概念和原理篇
1、基本概念 Spring Security 是一个强大且高度可定制的框架,用于构建安全的 Java 应用程序。它是 Spring 生态系统的一部分,提供了全面的安全解决方案,包括认证、授权、CSRF防护、会话管理等功能。 2、认证、授权和鉴权 (1&am…...

计算器上的MC、MR、M+、M—、CE是什么意思?
在计算器中, MC键叫做memory clear,中文 清除存储,是一个清除寄存器中存储数字的指令。 MS键叫做memory save,中文 存入存储。 而MR键,则是一个读取原先存储在寄存器中的数字的指令。 M键指将当前数值存入寄存器以…...

无人机飞手执照处处需要,森林、石油管道、电力巡检等各行业都需要
无人机飞手执照在多个行业中确实具有广泛的应用需求,包括森林、石油管道、电力巡检等领域。以下是对这些领域无人机飞手执照需求的具体分析: 一、森林领域 在森林领域,无人机飞手执照对于进行高效、准确的森林资源管理和监测至关重要。无人机…...

计算机网络——路由选择算法
路由算法 路由的计算都是以子网为单位计算的——找到从原子网到目标子网的路径 链路状态算法...
【前端】技术演进发展简史
一、前端 1、概述 1990 年,第一个web浏览器诞生,Tim 以超文本语言 HTML 为基础在 NeXT 电脑上发明了最原始的 Web 浏览器。 1991 年,WWW诞生,这标志着前端技术的开始。 前端(Front-end)和后端(…...

深入解析贪心算法及其应用实例
标题:深入解析贪心算法及其应用实例 一、引言 贪心算法(Greedy Algorithm)是一类简单、直观的算法设计策略,广泛应用于优化问题中。其基本思想是每一步都选择当前状态下最优的选择,即在每一步做出局部最优的决策&…...

电子工牌独立双通道定向拾音方案(有视频演示)
现在一些行业的客服人员在面对客户都要求使用电子工牌分别记录客服和顾客的声音,我们利用双麦克风阵列双波束拾音的方案设计了一个电子工牌方案.可以有效分别记录客服和顾客的声音. 方案思路: 我们采用了一个双麦阵列波束拾音的模块A-59,此模块可以利用2个麦克风组成阵列进行双…...
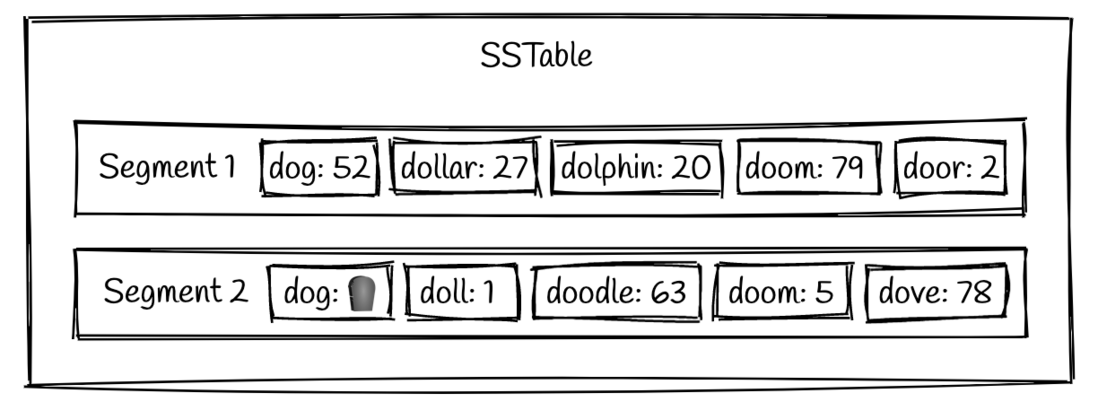
举例理解LSM-Tree,LSM-Tree和B+Tree的比较
写操作 write1:WAL 把操作同步到磁盘中WAL做备份(追加写、性能极高) write2:Memtable 完成WAL后将(k,v)数据写入内存中的Memtable,Memtable的数据结构一般是跳表或者红黑树 内存内采用这种数据结构一方面支持内存…...

React Native 全栈开发实战班 - 核心组件与导航
在 React Native 中,组件是构建用户界面的基本单元。React Native 提供了丰富的内置组件,涵盖了从基础布局到复杂交互的各种需求。本章节将详细介绍常用的内置组件,并重点讲解列表与滚动视图的使用。 1. 常用内置组件详解 React Native 提供…...

Leecode热题100-35.搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: 输入: nums [1,3,5,6], target 5 输出: 2示例 2: 输入:…...

OpenClaw 环境搭建|可视化操作零门槛
📌 OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版) ⭐ 核心优势 全程可视化操作,无需命令行、无需手动配置 Python/Node…...

屹晶微优势代理 600V/0.3A/0.6A 半桥栅极驱动器 SOP8 技术解析
在吹风筒、无线充电、变频水泵、DC-DC电源及无刷电机驱动等应用中,需要一款高耐压、低成本的半桥栅极驱动芯片。EG2304L是一款高性价比的MOS管、IGBT管栅极驱动专用芯片,采用SOP8封装,内置高端悬浮自举电源设计,耐压高达600V&…...

数据库备份与恢复策略
数据库备份与恢复策略 1. 技术分析 1.1 备份概述 备份是数据安全的基石: 备份类型完全备份: 全部数据增量备份: 变化数据差异备份: 上次完全备份后的变化备份策略:定期完全备份增量备份补充实时备份1.2 恢复策略 恢复类型完全恢复: 恢复到最新状态时间点恢复: 恢复到…...

为汉语辩护,彰显中华文字的生命力与优越性
为汉语辩护,彰显中华文字的生命力与优越性上世纪初,一批所谓“新文化人”竟提出废除汉字的主张,他们盲目推崇拉丁文,认为汉语是落后的语言,却不知这是对中华文字深厚底蕴的无知与曲解。如今回望,汉字的独特…...
)
保姆级教程:在Windows上用CMake搞定Qt 6.5与WebRTC M114的集成(附完整代码)
Windows平台Qt 6.5与WebRTC M114深度集成实战指南 环境准备与工具链配置 在Windows平台上进行Qt与WebRTC的集成开发,首先需要搭建完整的工具链环境。不同于简单的库引用,这种深度集成对工具版本和系统配置有着严格要求。 必备组件清单: Visua…...

3分钟掌握京东自动抢购神器:告别“手慢无“的终极指南
3分钟掌握京东自动抢购神器:告别"手慢无"的终极指南 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为京东限时秒杀商品总是抢不到而烦恼吗?面对心仪的热…...

RISC-V系统调用拦截技术解析与优化实践
1. RISC-V系统调用拦截技术概述系统调用拦截(Syscall Interception)是操作系统层面的关键技术,它允许在用户态与内核态的交互过程中插入自定义处理逻辑。这项技术在高性能计算、安全监控、虚拟化等领域有着广泛应用。在x86架构上,…...

告别WMMA API:用PTX的LDMATRIX和MMA指令在Ampere架构上重构你的FP16矩阵乘法内核
从WMMA到PTX:在Ampere架构上重构FP16矩阵乘法的深度实践 当开发者第一次接触Nvidia的Tensor Core编程时,WMMA(Warp Matrix Multiply Accumulate)API往往是首选方案。这套高层抽象接口屏蔽了硬件细节,让开发者能够快速实…...

从Caffeine源码到实战:手把手教你用Checker Framework给Java代码做‘体检’
从Caffeine源码到实战:手把手教你用Checker Framework给Java代码做‘体检’ 在阅读Caffeine这样的高质量开源项目时,细心的开发者常会注意到一些独特的编译注解——比如Nullable、GuardedBy这类标记。这些看似简单的注解背后,其实隐藏着一个强…...
 逃逸/LP模式 传输详解和波形图)
MIPI CSI-2(3) 逃逸/LP模式 传输详解和波形图
专栏目录 MIPI CSI-2(1) D-PHY详细解析 MIPI CSI-2(2) HS模式 传输详解和波形图 MIPI CSI-2(3) 逃逸/LP模式 传输详解和波形图 逃逸模式时序 逃逸模式下lane始终通过LP-TX驱动,不要求有时钟&…...