11.15 机器学习-集成学习方法-随机森林
# 机器学习中有一种大类叫**集成学习**(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:
# 三个臭皮匠,赛过诸葛亮。集成算法大致可以分为:Bagging,Boosting 和 Stacking 三大类型。
# (1)每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
# (2)利用新的训练集,训练得到M个子模型;
# (3)对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;
# 就是把多个分类器组合起来用 每个分类器都从训练集里面拿一部分(有放回的) 数据进行训练 最后得到了很多个模型组成的一个集成模型 各个模型拿的数据集可能有重合部分
# # 行和列 都会随机选 数据个数和特征个数 关注点不一样
# 然后 传入一个数据拿去预测 集成模型里面的每个子模型都会给一个结果 然后看结果最多的那个当做数据的结果
# **随机森林**就属于集成学习,是通过构建一个包含多个决策树(通常称为基学习器或弱学习器)的森林,每棵树都在不同的数据子集和特征子集上进行训练,
# 最终通过投票或平均预测结果来产生更准确和稳健的预测。这种方法不仅提高了预测精度,也降低了过拟合风险,并且能够处理高维度和大规模数据集
# - 随机: 特征随机,训练集随机
# - 样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择n个样本。用这n个样本来训练一个决策树。
# - 特征:假设训练集的特征个数为d,每次仅选择k(k<d)个来构建决策树。
# - 森林: 多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树
# - 处理具有高维特征的输入样本,而且不需要降维
# - 使用平均或者投票来提高预测精度和控制过拟合
# 不需要降维 因为已经特征选择随机了
# API
# class sklearn.ensemble.RandomForestClassifier
# 参数:
# n_estimators int, default=100
# 森林中树木的数量。(决策树个数)
# criterion {“gini”, “entropy”}, default=”gini” 决策树属性划分算法选择
# 当criterion取值为“gini”时采用 基尼不纯度(Gini impurity)算法构造决策树,
# 当criterion取值为 “entropy” 时采用信息增益( information gain)算法构造决策树.
# max_depth int, default=None 树的最大深度。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_selection import VarianceThreshold
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
def random_forest1():
df1=pd.read_csv("assets/csv/titanic.csv")
df1["age"].fillna(df1["age"].mode()[0],inplace=True)
x=df1.drop(["embarked","home.dest","room","ticket","boat","survived"],axis=1)
y=df1["survived"]
y=y.to_numpy()
# print(x)
# print(y)
x=x.to_dict(orient="records") # df转字典 字典进行字典的那个处理
vector1=DictVectorizer(sparse=False)
x=vector1.fit_transform(x)
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666,train_size=0.8)
scaler1=StandardScaler()
x_train_stand=scaler1.fit_transform(x_train)
x_test_stand=scaler1.transform(x_test)
forest1=RandomForestClassifier(n_estimators=100,criterion="gini",max_depth=3)
model1=forest1.fit(x_train_stand,y_train)
score1=model1.score(x_test_stand,y_test)
print(score1)
pass
if __name__=="__main__":
random_forest1()
pass
相关文章:

11.15 机器学习-集成学习方法-随机森林
# 机器学习中有一种大类叫**集成学习**(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话: # 三个臭皮匠,…...

【SQL】E-R模型(实体-联系模型)
目录 一、介绍 1、实体集 定义和性质 属性 E-R图表示 2. 联系集 定义和性质 属性 E-R图表示 一、介绍 实体-联系数据模型(E-R数据模型)被开发来方便数据库的设计,它是通过允许定义代表数据库全局逻辑结构的企业模式…...

C/C++静态库引用过程中出现符号未定义的处理方式
问题背景: 在接入新库(静态库)时遇到了符号未定义问题,并发现改变静态库的链接顺序可以解决问题。 问题根源: 静态库是由 .o 文件拼接而成的,链接静态库时,链接器以 .o 文件为单位进行处理。链接…...

『VUE』27. 透传属性与inheritAttrs(详细图文注释)
目录 什么是透传属性(Forwarding Attributes)使用条件唯一根节点禁用透传属性继承总结 欢迎关注 『VUE』 专栏,持续更新中 欢迎关注 『VUE』 专栏,持续更新中 什么是透传属性(Forwarding Attributes) 在 V…...

借助Excel实现Word表格快速排序
实例需求:Word中的表格如下图所示,为了强化记忆,希望能够将表格内容随机排序,表格第一列仍然按照顺序编号,即编号不跟随表格行内容调整。 乱序之后的效果如下图所示(每次运行代码的结果都不一定相同&#x…...

数据结构 ——— 层序遍历链式二叉树
目录 链式二叉树示意图编辑 何为层序遍历 手搓一个链式二叉树 实现层序遍历链式二叉树 链式二叉树示意图 何为层序遍历 和前中后序遍历不同,前中后序遍历链式二叉树需要利用递归才能遍历 而层序遍历是非递归的形式,如上图:层序遍历的…...

使用 Prompt API 与您的对象聊天
tl;dr:GET、PUT、PROMPT。现在,可以使用新的 PromptObject API 仅使用自然语言对存储在 MinIO 上的对象进行总结、交谈和提问。在本文中,我们将探讨这个新 API 的一些用例以及代码示例。 赋予动机: 对象存储和 S3 API 的无处不在…...

SpringBoot整合Mybatis-Plus实践汇总
相关依赖 MyBatis-Plus涉及的依赖主要是Mybatis-start、和分页插件的依赖,不考虑使用额外分页插件的前提下,只需要mybatis-plus-boot-starter一个依赖即可与SpringBoot集成: <!--Mybatis-plugs--><dependency><groupId>co…...

基于Spring Boot的在线性格测试系统设计与实现(源码+定制+开发)智能性格测试与用户个性分析平台、在线心理测评系统的开发、性格测试与个性数据管理系统
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

Python实现人脸识别算法并封装为类库
引言 人脸识别技术在现代社会中应用广泛,从安全监控到智能门锁,再到社交媒体中的照片标记功能,都离不开这项技术。本文将详细介绍如何使用Python实现基本的人脸识别算法,并将其封装为一个类库,以便在多个项目中复用。…...

uniapp小程序分享使用canvas自定义绘制 vue3
使用混入结合canvas做小程序的分享 在混入里面定义一个全局共享的分享样式,在遇到特殊页面需要单独处理 utils/share.js import { ref } from vue; export default {onShow() {// 创建时设置统一页面的默认值uni.$mpShare {title: 分享的标题,path: /pages/home/…...

SpringCloud核心组件(四)
文章目录 NacosNacos 配置中心1.起源2.基本概念ProfileData IDGroup 3.基础配置a. bootstrap.ymlb. application.ymlc. nacos 中的配置 DataIDd.测试读取配置中心配置内容 4.配置隔离a.命名空间b.DataIDc.bootstrap.ymld.service 隔离 5.配置拆分a.配置拆分策略b.DataID 配置c.…...

如何把本地docker 镜像下载用到centos系统中呢?
如果需要将镜像下载到本地或在 CentOS 系统上使用该镜像,你可以按照以下步骤操作: 1. 拉取镜像 如果想将镜像从 Docker Hub 或其他镜像仓库下载到本地,可以使用 docker pull 命令。 如果使用的是本地构建的镜像(如 isc:v1.0.0&…...
Godot的开发框架应当是什么样子的?
目录 前言 全局协程还是实例协程? 存档! 全局管理类? UI框架? Godot中的异步(多线程)加载 Godot中的ScriptableObject 游戏流程思考 结语 前言 这是一篇杂谈,主要内容是对我…...

GitHub新手入门 - 从创建仓库到协作管理
GitHub新手入门 - 从创建仓库到协作管理 GitHub 是开发者的社交平台,同时也是代码托管的强大工具。无论是个人项目、开源协作,还是团队开发,GitHub 都能让你轻松管理代码、版本控制和团队协作。今天,我们将从基础开始,…...

作业25 深度搜索3
作业: #include <iostream> using namespace std; bool b[100][100]{0}; char map[100][100]{0}; int dx[4]{0,1,0,-1}; int dy[4]{1,0,-1,0}; int n,m; int sx,sy,ex,ey; int mink2147483647; void dfs(int,int,int); int main(){cin>>n>>m;for(…...

ubuntu20.04 colmap 安装2024.11最新
很多教程都很落后了,需要下载压缩包解压编译的很麻烦 现在就只需要apt install就可以了 apt更新 sudo apt update && sudo apt-get upgrade安装依赖 #安装依赖 sudo apt-get install git cmake ninja-build build-essential libboost-program-options-de…...
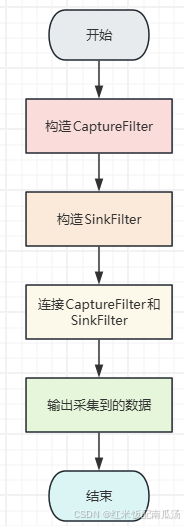
WebRTC视频 03 - 视频采集类 VideoCaptureDS 上篇
WebRTC视频 01 - 视频采集整体架构 WebRTC视频 02 - 视频采集类 VideoCaptureModule [WebRTC视频 03 - 视频采集类 VideoCaptureDS 上篇](本文) WebRTC视频 04 - 视频采集类 VideoCaptureDS 中篇 WebRTC视频 05 - 视频采集类 VideoCaptureDS 下篇 一、前…...
 详解)
python os.path.basename(获取路径中的文件名部分) 详解
os.path.basename 是 Python 的 os 模块中的一个函数,用于获取路径中的文件名部分。它会去掉路径中的目录部分,只返回最后的文件名或目录名。 以下是 os.path.basename 的详细解释和使用示例: 语法 os.path.basename(path) 参数 path&…...
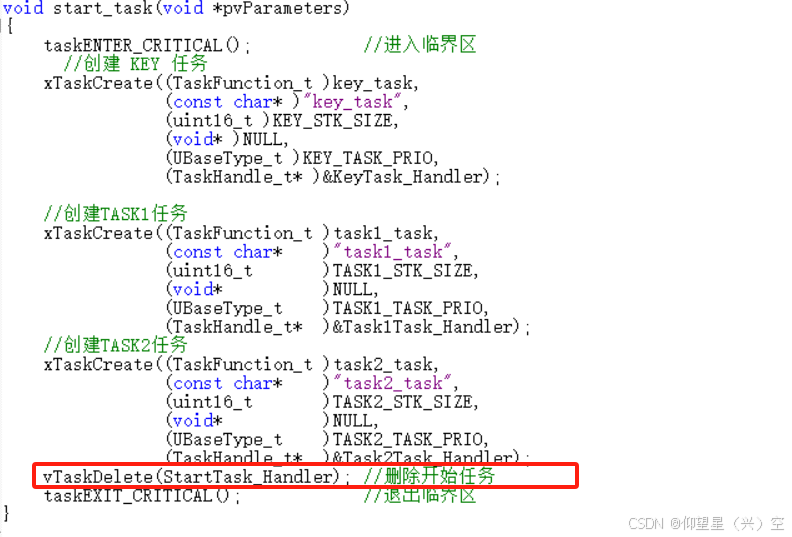
《FreeRTOS任务基础知识以及任务创建相关函数》
目录 1.FreeRTOS多任务系统与传统单片机单任务系统的区别 2.FreeRTOS中的任务(Task)介绍 2.1 任务特性 2.2 FreeRTOS中的任务状态 2.3 FreeRTOS中的任务优先级 2.4 在任务函数中退出 2.5 任务控制块和任务堆栈 2.5.1 任务控制块 2.5.2 任务堆栈…...

CFS调度器:从公平算法到内核实现全景解析
1. CFS调度器的设计哲学与公平性实现 Linux内核的CFS(Completely Fair Scheduler)调度器诞生于2007年,取代了之前的O(1)调度器。它的核心设计理念可以用一个简单的比喻理解:想象CPU时间是一块披萨,CFS要确保每个进程都…...

OpenWebUI智能管道:连接本地AI模型与高性能推理后端
1. 项目概述:一个连接OpenWebUI与本地AI模型的智能管道最近在折腾本地大语言模型(LLM)的朋友,估计都绕不开OpenWebUI(原名Ollama WebUI)这个项目。它提供了一个极其美观、功能强大的Web界面,让我…...

【NotebookLM+IEA/IRENA数据融合实战】:72小时内完成新型储能技术竞争力评估
更多请点击: https://codechina.net 第一章:NotebookLM能源技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的文档进行语义理解与上下文驱动的问答。在能源技术研究领域,NotebookLM 可显…...

告别繁琐组态:用SVG + JavaScript 5分钟为你的工业设备创建可交互HMI组件
工业设备HMI组件开发革命:5分钟用SVGJavaScript打造智能交互界面 在工业自动化领域,人机界面(HMI)是连接设备与操作者的关键纽带。传统HMI开发往往陷入两个极端:要么使用笨重的组态软件进行繁琐配置,要么投入大量时间开发定制化界…...

RK3588/RK1820嵌入式AI模型选型与部署实战:9大模型场景化应用指南
1. 项目概述:嵌入式AI模型部署的十字路口作为一名在嵌入式AI领域摸爬滚打了十多年的老兵,我见过太多项目在模型部署这个环节上栽跟头。大家手里可能都握着RK3588、RK182X这类性能强悍的瑞芯微平台,硬件算力摆在那里,但真要把一个A…...

中小团队如何通过Taotoken统一管理多个AI项目的API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小团队如何通过Taotoken统一管理多个AI项目的API成本 应用场景类,面向同时进行多个AI应用探索或开发的中小团队技术管…...

APK安装器完整指南:在Windows上直接安装安卓应用的专业解决方案
APK安装器完整指南:在Windows上直接安装安卓应用的专业解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓…...

Taotoken Token Plan套餐为高频用户带来的长期成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan套餐为高频用户带来的长期成本优势感知 对于高频使用大模型API的开发者或团队而言,项目开发中的模…...

Kubernetes API Server优化:提升集群管理效率
Kubernetes API Server优化:提升集群管理效率 一、Kubernetes API Server概述 1.1 API Server的角色 Kubernetes API Server是Kubernetes集群的核心组件,负责处理所有的REST API请求,是集群内部和外部通信的枢纽。它负责验证和处理请求&#…...

人群计数老将CSRNet:6年后再看CVPR2018的洞见,它的设计思想对今天还有何启发?
人群计数经典CSRNet:6年后重审其设计哲学与当代启示 2018年CVPR会议上亮相的CSRNet,在当时以简洁优雅的架构刷新了人群计数任务的性能记录。六年过去,当Vision Transformer、扩散模型等新范式不断冲击计算机视觉领域时,回看这个基…...