【大数据学习 | HBASE高级】rowkey的设计,hbase的预分区和压缩
1. rowkey的设计
RowKey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,字典顺序排序,rowkey的设计至关重要,会影响region分布,如果rowkey设计不合理还会出现region写热点等一系列问题。
rowkey设计原则:
-
保证rowkey的唯一性:性质与主键唯一一致。
-
能满足需求的情况下,长度越短越好:推荐16字节。
- 高位散列:高位散列的目的是使数据均匀分布到不同的region上,散列方式一般采用"反转"、"加盐"、"MD5"的方式对高位进行处理。(防止写热点问题)
需求:hbase存储的是用户的交易信息, 我想查某个用户在某个时间段内的交易记录,如何设计rowkey
用户id(md5), 用户名称, 交易时间, 交易金额, 交易说明
用户id(md5), 交易时间
rowkey设计: 用户id(md5) + _ + 交易时间
create 'hainiu:flow', 'cf'put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210110000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210110000', 'cf:amt', '1000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210110000', 'cf:time', '2021-12-10 11:00:00'put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210120000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210120000', 'cf:amt', '2000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210120000', 'cf:time', '2021-12-10 12:00:00'put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210130000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210130000', 'cf:amt', '3000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210130000', 'cf:time', '2021-12-10 13:00:00'put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210140000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210140000', 'cf:amt', '4000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210140000', 'cf:time', '2021-12-10 14:00:00'# 查询 某个人在 20211210 日 11 点 到 20211211 日 12:30 间的交易记录
scan 'hainiu:flow', {STARTROW => '02f5adff232b37422fc846cc5c1d8328_2021121011' , STOPROW=> '02f5adff232b37422fc846cc5c1d8328_202112101230'}我们可以发现数据已经可以按照范围查询了。
有的时候我们的单点查询比较频繁,那么我们将数据按照散列形式打散然后穿插到不同的region中可以有效的防止读和写热点问题。
有时候我们查询的数据是范围性的扫描,这样时候我们就要知道数据必须要有相似的前缀,这样非常好按照范围查询,防止多region扫描问题的产生,比如人口普查数据,我们最好按照省份开头一样,这样的数据范围性比较好查询。
但是这个时候会出现数据倾斜或者热点问题,所以我们在这个基础上还可以实现预分区的设计,在设定表的时候指定分区的数据范围,保证数据的分布均匀。
2. hbase的预分区
为了解决数据的倾斜问题,或者数据在刚开始插入的数据都在一个region中,使得一个region中的压力太大,我们可以预先设定一个表数据的分区范围,让数据更加均匀的分布在不同的分区中,或者我们在做数据分类的时候可以按照不同的类别将数据放入到不同的region中扫面数据的时候会比较容易,防止跨多个分区进行操作查询。
预分region需要考虑两个因素,即region个数与region大小。
- region个数
官方推荐region个数计算公式:
(RS Xmx * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * column familys)其中:
RS Xmx:regionserver堆栈内存大小,官方推荐每台regionserver内存大小设置20-24G,不推荐设置更大,因为更大的堆栈内存GC效率较低。
hbase.regionserver.global.memstore.size:为整个regionserver中memstore总大小占用总内存的比例,一般默认为0.4
hbase.hregion.memstore.flush.size:为memstoreflush阈值,一般默认128,可以自己设置
column familys:为列族数
例:(20G*0.4)/(128M*2)=32
官方推荐每个regionserver上region个数在20-200之间。
- region大小
单个region官方推荐大小为5-10GB,可以通过hbase.hregion.max.filesize设置,当超过该值后会触发split,与region split策略相关。
# 首先我们需要创建预分区文件
# 比如我们做人口普查,需要将不同省份的数据放入到不同的region中
河北省,山西省,吉林省,辽宁省,黑龙江省,陕西省,甘肃省,青海省,山东省,福建省,浙江省,台湾省,河南省,湖北省,湖南省,江西省,江苏省,安徽省,广东省,海南省,四川省,贵州省,云南省
#首先我们按照这些省份的字典顺序将字母排序
云南省
台湾省
吉林省
四川省
安徽省
山东省
山西省
广东省
江苏省
江西省
河北省
河南省
浙江省
海南省
湖北省
湖南省
甘肃省
福建省
贵州省
辽宁省
陕西省
青海省
黑龙江省
# 然后将这些数据放入到一个文件中 /home/hadoop/split.txt
create 'hainiu:advance_split_region', 'cf', {SPLITS_FILE => '/home/hadoop/split.txt'}
由图,存在24个分区。

3. hbase的压缩
建表时指定压缩格式,开启压缩后可以非常有效的缓解hbase数据膨胀问题。
create 'hainiu:flow',{NAME => 'cf',VERSIONS => 3,COMPRESSION => 'SNAPPY'}, {SPLITS_FILE => '/tmp/advance_split_region_file'}如果建表没指定压缩格式,那需要修改列族支持,步骤如下:
1) disable 'hainiu:flow'
如果表的数据量很大,region很多,disable过程会比较缓慢,需要等待较长时间。过程可以通过查看hbase master log日志监控。
2) alter 'hainiu:flow', NAME => 'cf', COMPRESSION => 'snappy'
NAME即column family,列族。HBase修改压缩格式,需要一个列族一个列族的修改。名字一定要与你自己列族的名字一致,否则就会创建一个新的列族并且压缩格式是snappy的。
3)enable 'hainiu:flow'
重新enable上线flow表
4)major_compact 'hainiu:flow'
enable表后,HBase表的压缩格式并没有生效,还需要执行一个命令,major_compact。
Major compact除了做文件Merge操作,还会将其中的delete项删除。



相关文章:
【大数据学习 | HBASE高级】rowkey的设计,hbase的预分区和压缩
1. rowkey的设计 RowKey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,字典顺序排序,rowkey的设计至关重要,会影响region分布,如果rowkey设计不合理还会出现region写热点等一系列问题。 …...

Dart:字符串
字符串:单双引号 String c hello \c\; // hello c,单引号中使用单引号,需要转义\ String d "hello c"; // hello c,双引号中使用单引号,不需要转义 String e "hello \“c\”"; // hell…...

平衡二叉搜索树之 红黑 树的模拟实现【C++】
文章目录 红黑树的简单介绍定义红黑树的特性红黑树的应用 全部的实现代码放在了文章末尾准备工作包含头文件类的成员变量和红黑树节点的定义 构造函数和拷贝构造swap和赋值运算符重载析构函数findinsert【重要】第一步:按照二叉搜索树的方式插入新节点第二步&#x…...

2:Vue.js 父子组件通信:让你的组件“说话”
上一篇我们聊了如何用 Vue.js 创建一个简单的组件,这次咱们再往前走一步,讲讲 Vue.js 的父子组件通信。组件开发里,最重要的就是让组件之间能够“说话”,数据能流通起来。废话不多说,直接开干! 父组件传数据…...

6. Keepalived配置Nginx自动重启,实现7x24提供服务
一. Keepalived配置Nginx自动重启,实现7x24提供服务 1.编写不停的检查nginx服务器状态,停止并重启,重启失败后则停止keepalived脚本 cd /etc/keepalived/ vim check_nginx_alive_or_not.sh #---内容如下:--------------- #!/bin/bash A=`ps -C nginx --no-header |wc -l...

【PS】蒙版与通道
内容1: 、选择蓝色通道并复制,对复制的蓝色通道ctrli进行反向选择,然后ctrll调整色阶。 、选择载入选区,然后点击rgb。 、点击蒙版 、点击云彩图层调整位置 、点击色相/饱和度,适当调整 、最后使用滤镜等功能添加光圈…...

C++创建型模式之生成器模式
解决的问题 生成器模式(Builder Pattern)主要解决复杂对象的构建问题。当一个对象的创建过程非常复杂,涉及多个步骤和多个部件时,使用生成器模式可以将对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表…...

鸿蒙NEXT应用示例:切换图片动画
【引言】 在鸿蒙NEXT应用开发中,实现图片切换动画是一项常见的需求。本文将介绍如何使用鸿蒙应用框架中的组件和动画功能,实现不同类型的图片切换动画效果。 【环境准备】 电脑系统:windows 10 开发工具:DevEco Studio NEXT B…...
继承特性和分区实现)
postgresql(功能最强大的开源数据库)继承特性和分区实现
PostgreSQL实现了表继承,在多重表继承下,对上亿条不同类别的数据条目进行按型号、按月份双层分区管理,既可在总表查阅所有条目的共有字段,也可在各类型字表查询附加字段,非常高效。 分区是通过继承的方式来实现的&…...
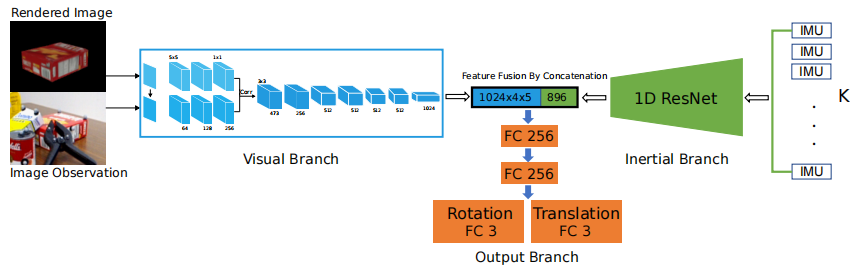
论文笔记(五十六)VIPose: Real-time Visual-Inertial 6D Object Pose Tracking
VIPose: Real-time Visual-Inertial 6D Object Pose Tracking 文章概括摘要I. INTRODACTIONII. 相关工作III. APPROACHA. 姿态跟踪工作流程B. VIPose网络 文章概括 引用: inproceedings{ge2021vipose,title{Vipose: Real-time visual-inertial 6d object pose tra…...

微服务治理详解
文章目录 什么是微服务架构为什么要使用微服务单体架构如何转向微服务架构服务治理服务治理治的是什么服务注册与发现服务熔断降级服务网关服务调用服务负载均衡服务配置中心 微服务解决方案SpringCloud体系EurekaHystrixGatewayOpenFeignRibbonConfig SpringCloud Alibaba体系…...
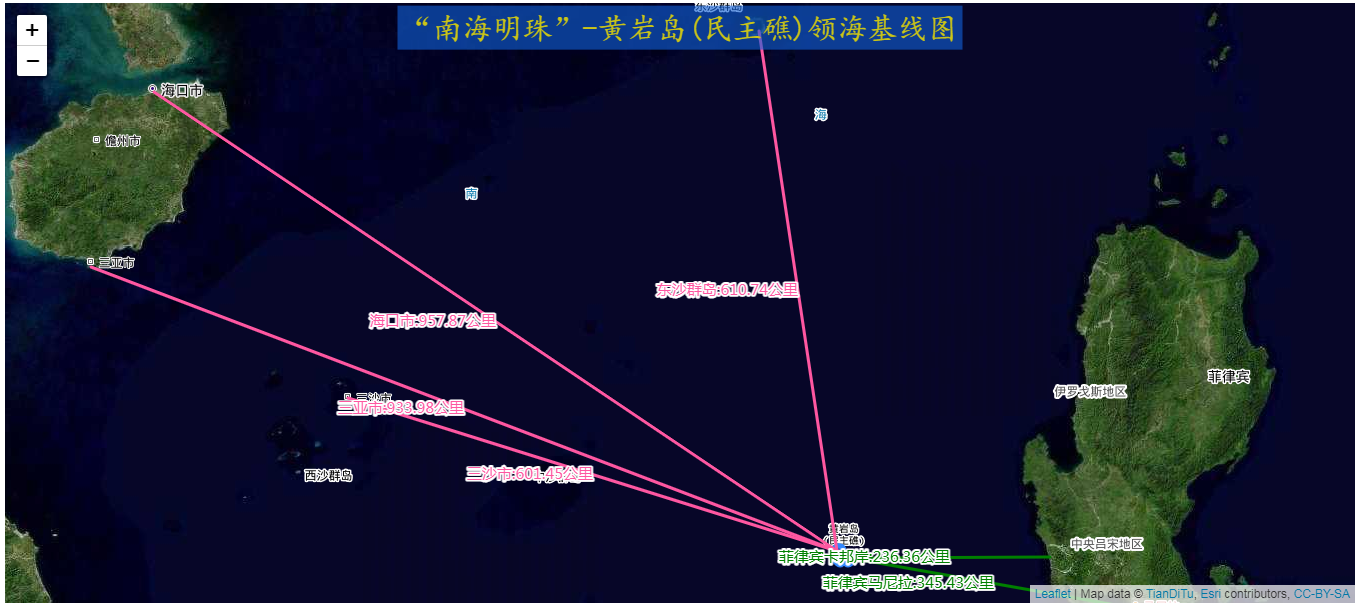
“南海明珠”-黄岩岛(民主礁)领海基线WebGIS绘制实战
目录 前言 一、关于岛屿的基点位置 1、领海基点 二、基点坐标的转换 1、最底层的左边转换 2、单个经纬度坐标点转换 3、完整的转换 三、基于天地图进行WebGIS展示 1、领海基点的可视化 2、重要城市距离计算 四、总结 前言 南海明珠黄岩岛,这座位于南海的…...

Oracle数据库 创建dblink的过程及其用法详解
前言 dblink是Oracle数据库中用于连接不同数据库实例的一种机制。通过dblink,用户可以在一个数据库实例中直接查询或操作另一个数据库实例中的表、视图或存储过程。 dblink的作用主要体现在以下几个方面: 跨数据库操作:允许用户…...

Linux从0——1之shell编程4
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

pycharm快速更换虚拟环境
目录 1. 选择Conda 虚拟环境2. 创建环境3. 直接选择现有虚拟环境 1. 选择Conda 虚拟环境 2. 创建环境 3. 直接选择现有虚拟环境...

MVVM框架
MVVM由以下三个内容构成: Model:数据模型View:界面ViewModel:作为桥梁负责沟通View和Model 在JQuery时期,如果需要刷新UI,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和⻚⾯有强耦合。 在 MVVM 中,UI 是…...

数据仓库在大数据处理中的作用
数据仓库(Data Warehouse,简称DW或DWH)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。以下是对数据仓库及其在大数据处理中作用的详细解释: 一、数据仓库的定义 面向主题&#x…...
)
前端Javascript、Vue、CSS等场景面试题目(二)
前端面试场景题目(一)-CSDN博客 针对您提供的前端场景面试题目,以下是详细的回答: 1. 如何通过 CSS 实现美观的自定义复选框和单选按钮? 方法:使用 CSS 伪元素 ::before 和 ::after,以及隐藏…...
)
鸿蒙学习生态应用开发能力全景图-开发者支持平台(5)
鸿蒙相关平台作用: 开发者社区:开发者技术交流平台,帮助开发者探索开发实践、交流心得经验、获悉业界动态、答疑解惑。 开发者学堂:聚合官方鸿蒙生态课程,课程有慕课、微课、直播课、训练营等多种形式ÿ…...

计算机网络各层设备总结归纳(更新ing)
计算机网络按照OSI(开放式系统互联)模型分为七层,每一层都有其特定的功能和对应的网络设备。以下是各层对应的设备: 1. 物理层(Physical Layer) 设备:中继器(Repeater)、集线器…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

δ - mem:提升大型语言模型内存效率,得分最高可达 1.31 倍!
快速通道可了解 arXiv 成为独立非营利组织的情况,也能直达康奈尔大学官网。同时,还能通过链接进行捐赠,支持 arXiv 的发展。搜索与导航提供了多种搜索途径,可在所有字段(标题、作者、摘要等)进行搜索。还有…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

轻量级爬虫框架slacrawl:基于规则驱动的模块化数据采集实践
1. 项目概述:一个轻量级、模块化的网页爬虫框架最近在做一个需要从多个网站定时抓取结构化数据的小项目,找了一圈现成的工具,要么太重(像Scrapy,学起来成本高),要么太死板(很多脚本只…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

从开源物理拼图游戏学习Unity 2D物理引擎与游戏架构设计
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“openclaw-puzzle-game”。光看名字,你可能会觉得这又是一个普通的开源拼图游戏,但点进去仔细研究后,我发现它的设计思路和实现方式,对于想学习游戏开…...

树莓派机械爪项目实战:从硬件连接到Python控制全解析
1. 项目概述:当树莓派遇上机械爪最近在折腾一个挺有意思的小项目,叫Demwunz/openclaw-pi-installation。光看这个名字,就能猜到个大概:这是一个为树莓派(Raspberry Pi)准备的机械爪(Claw&#x…...