解析传统及深度学习目标检测方法的原理与具体应用之道
深度学习目标检测算法

常用的深度学习的目标检测算法及其原理和具体应用方法:
- R-CNN(Region-based Convolutional Neural Networks)系列1:
- 原理:
- 候选区域生成:R-CNN 首先使用传统的方法(如 Selective Search)生成一系列可能包含物体的候选区域。Selective Search 是一种基于颜色、纹理、大小、形状等多种特征的图像分割方法,通过合并相似的区域来生成候选区域2。
- 特征提取:对于每个候选区域,R-CNN 使用预训练的卷积神经网络(如 AlexNet)提取特征。将每个候选区域缩放到固定大小(如 227x227),然后输入到卷积神经网络中进行前向传播,提取最后一层卷积层的输出作为该候选区域的特征表示2。
- 分类与回归:在特征提取之后,使用支持向量机(SVM)对每个候选区域进行分类,判断其是否属于某个类别。同时,使用边界框回归器对候选区域的位置进行调整,使其更加准确地贴合物体的边界2。
- 具体应用方法:
- 数据准备:收集并标注大量的图像数据,标注信息包括目标物体的类别和位置(通常用矩形框表示)。将数据集划分为训练集、验证集和测试集。
- 模型训练:
- 首先使用在大规模图像分类数据集(如 ImageNet)上预训练的卷积神经网络作为基础模型。
- 利用训练集中的图像及其对应的候选区域进行微调训练,包括特征提取部分的参数调整以及 SVM 分类器和边界框回归器的训练。在训练 SVM 分类器时,将提取的特征和对应的标签输入 SVM 进行训练;对于边界框回归器,使用标注的真实边界框和预测的边界框之间的差异作为损失函数进行训练。
- 预测:对于待检测的图像,使用 Selective Search 算法生成候选区域,然后将这些候选区域输入到训练好的模型中进行特征提取、分类和边界框回归,得到最终的检测结果。最后,使用非极大值抑制(NMS)去除重叠度较高的候选区域,保留置信度较高的区域作为最终的检测结果。
- 应用场景:R-CNN 系列算法在多个领域有广泛应用,如安防监控中对人员、车辆等目标的检测;医疗影像分析中对病变组织、器官等的识别;工业质检中对产品缺陷的检测等2。
- 原理:
- YOLO(You Only Look Once)系列:
- 原理:
- 网格划分:将输入图像分成 SxS 个网格。每个网格负责预测该网格内是否存在目标以及目标的类别和位置信息。
- 边界框预测:每个网格预测多个边界框,每个边界框用五个预测值表示,即 x,y,w,h 和 confidence(置信度)。其中,(x,y) 是边界框的中心坐标,w 和 h 是边界框的宽度和高度,这四个值都被归一化到 (0,1) 区间以便于训练;置信度反映了当前边界框中存在目标的可能性以及预测框与真实框的交并比。
- 类别预测:预测每个网格分别属于每种目标类别的条件概率。在测试时,属于某个网格的多个边界框共享所有类别的条件概率,每个边界框属于某个目标类别的置信度为边界框的置信度与类别条件概率的乘积。
- 具体应用方法:
- 数据准备:与 R-CNN 类似,需要收集和标注大量的图像数据,并且按照要求进行数据集的划分。
- 模型训练:
- 构建 YOLO 网络模型,通常基于深度学习框架(如 PyTorch、TensorFlow 等)进行搭建。
- 使用训练集数据对模型进行训练,通过反向传播算法不断调整网络的权重和偏置,以最小化损失函数。损失函数通常包括边界框的位置误差、置信度误差和类别误差等。
- 预测:将待检测的图像输入到训练好的 YOLO 模型中,模型会一次性输出图像中所有目标的类别和位置信息。可以根据实际需求设置置信度阈值,过滤掉置信度较低的检测结果。
- 应用场景:由于其检测速度快,YOLO 系列算法适用于对实时性要求较高的场景,如自动驾驶中对道路上的车辆、行人、交通标志等的实时检测;智能监控系统中对异常行为的实时监测和预警;无人机对环境的实时监测等415。
- 原理:
- SSD(Single Shot MultiBox Detector)1:
- 原理:
- 多尺度特征图检测:利用卷积神经网络的不同层的特征图进行目标检测。在不同尺度的特征图上,每个像素点都对应着不同大小和比例的默认边界框(prior box)。通过这种方式,可以在不同尺度上检测不同大小的目标,提高了对多尺度目标的检测能力。
- 直接回归:与 YOLO 类似,SSD 也是一种 “端到端” 的检测算法,直接对目标的类别和位置进行回归预测。对于每个默认边界框,预测其是否包含目标以及目标的类别和位置偏移量,以便将默认边界框调整到更准确的位置。
- 具体应用方法:
- 数据准备:同其他目标检测算法,准备好标注好的图像数据集。
- 模型训练:
- 选择合适的主干网络(如 VGG、ResNet 等),并在其基础上构建 SSD 模型。
- 使用训练集数据进行训练,优化模型的参数,使模型能够准确地预测目标的类别和位置。在训练过程中,采用合适的损失函数,如交叉熵损失和位置回归损失的组合,来衡量预测结果与真实值之间的差异。
- 预测:对待检测的图像进行预处理后,输入到训练好的 SSD 模型中,模型会输出每个默认边界框的预测结果,包括是否包含目标、目标的类别以及位置偏移量。根据这些信息,可以得到最终的目标检测结果。
- 应用场景:SSD 算法在速度和精度之间取得了较好的平衡,因此在一些对实时性和准确性都有要求的场景中得到应用,如机器人视觉系统中对周围环境的感知和目标识别;智能交通系统中对车辆、行人等的检测和跟踪等1。
- 原理:
- Faster R-CNN:
- 原理:
- 特征提取:使用卷积神经网络提取输入图像的特征,得到特征图。常用的骨干网络有 VGG、ResNet 等。
- 区域提议网络(RPN):在特征图上引入区域提议网络(RPN),用于生成候选区域。RPN 通过在特征图上滑动窗口,每个窗口位置生成多个不同大小和比例的锚框(anchor),然后对这些锚框进行分类(判断是否包含目标)和回归(调整锚框的位置和大小),得到初步的候选区域。
- RoI Pooling:将 RPN 生成的候选区域映射到特征图上,然后使用 RoI Pooling(Region of Interest Pooling)操作将不同大小的候选区域转换为固定大小的特征向量,以便后续的分类和回归操作。
- 分类与回归:使用全连接层对 RoI Pooling 后的特征向量进行分类和回归,得到最终的目标检测结果,包括目标的类别和精确的位置信息。
- 具体应用方法:
- 数据准备:准备标注好的图像数据集,包括图像和对应的目标标注信息。
- 模型训练:
- 构建 Faster R-CNN 模型,包括特征提取网络、RPN 和后续的分类回归网络。
- 使用训练集数据进行训练,交替训练 RPN 和分类回归网络,使它们能够相互协作,提高目标检测的准确性。在训练过程中,根据损失函数(包括 RPN 的损失和分类回归的损失)进行反向传播,优化模型的参数。
- 预测:对于待检测的图像,经过特征提取、RPN 生成候选区域、RoI Pooling 和分类回归等步骤,得到目标的检测结果。同样,可以使用非极大值抑制去除重叠的检测结果。
- 应用场景:Faster R-CNN 在目标检测的准确性上有较高的表现,适用于对检测精度要求较高的场景,如医学影像诊断中对病灶的检测和分析;卫星图像中对特定目标的识别和定位等5。
- 原理:
- RetinaNet:
- 原理:
- 焦点损失函数(Focal Loss):RetinaNet 的核心创新在于引入了焦点损失函数,用于解决目标检测中类别不平衡的问题。在目标检测中,大量的背景区域远远多于前景目标区域,导致模型在训练过程中容易偏向于背景,而忽略了前景目标。焦点损失函数通过降低易分类样本的权重,增加难分类样本的权重,使得模型更加关注难分类的目标,从而提高了对小目标和不平衡数据的检测性能7。
- 特征金字塔网络(FPN):RetinaNet 通常使用特征金字塔网络来提取多尺度的特征。特征金字塔网络将不同层的特征图进行融合,使得模型能够同时利用低层的高分辨率特征和高层的语义特征,从而更好地检测不同大小的目标。
- 分类与回归:与其他目标检测算法类似,RetinaNet 在特征图上进行目标的分类和回归预测,得到目标的类别和位置信息。
- 具体应用方法:
- 数据准备:准备高质量的图像数据集,确保数据的标注准确无误。
- 模型训练:
- 构建基于 RetinaNet 的目标检测模型,包括特征提取部分、焦点损失函数和分类回归部分。
- 使用训练集数据进行训练,优化模型的参数,使模型能够学习到有效的特征表示和准确的分类回归能力。在训练过程中,焦点损失函数的参数需要根据具体的数据集进行调整,以达到最佳的检测效果。
- 预测:将待检测的图像输入到训练好的 RetinaNet 模型中,得到目标的检测结果。可以根据实际需求对检测结果进行后处理,如非极大值抑制等操作,以提高检测的准确性。
- 应用场景:RetinaNet 在各种场景下都有较好的应用,特别是在对小目标检测要求较高的场景,如航拍图像中的目标检测、智能安防中的行人检测等;以及在数据类别不平衡的情况下,如在某些特定领域中目标数量分布不均匀的场景。
- 原理:
深度学习目标检测方法(基于 YOLOv5 的目标检测)
首先,需要确保已经安装了 YOLOv5 相关的库。如果没有安装,可以通过以下命令在虚拟环境中安装(假设已经安装了pip):
git clone https://github.com/ultralytics/yolo.git
cd yolo
pip install -r requirements.txt
以下是使用 YOLOv5 进行目标检测的 Python 代码示例:
import torch
from PIL import Image
import cv2
import numpy as np# 加载YOLOv5模型
model = torch.hub.load('ultralytics/yolo', 'yolo5s', pretrained=True)# 读取待检测图像
image_path = 'test_image.jpg'
image = Image.open(image_path)# 进行目标检测
results = model(image)# 获取检测结果
for result in results.pred[0]:x1, y1, x2, y2, conf, cls = result.tolist()label = model.names[int(cls)]confidence = conf# 在图像上绘制检测框cv2.rectangle(np.array(image), (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)cv2.putText(np.array(image), f'{label}: {confidence:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HIRAYAMA, 0.5,(0, 255, 0), 2)# 显示检测后的图像
cv2.imshow('Detected Image', np.array(image))
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中:
- 对于传统方法的代码,首先定义了函数来提取 HOG 特征、加载并提取训练数据特征、训练 SVM 模型以及进行行人检测。然后假设已有训练数据,按照流程完成训练并对待检测图像进行检测。
- 对于深度学习方法的代码,先加载了预训练的 YOLOv5 模型,然后读取待检测图像进行目标检测,最后将检测结果绘制在图像上并显示出来。
请注意:
- 传统方法代码中的训练数据准备部分(
train_images和train_labels的获取)在实际应用中需要根据具体情况进行详细的采集、标注等工作。 - 深度学习方法代码中,这里只是简单展示了使用预训练模型进行检测的情况,如果要进行特定场景的精细调整或重新训练等,还需要进一步深入研究 YOLOv5 的相关文档和代码。
传统目标检测方法

传统目标检测方法主要包括三个关键步骤:区域选择、特征提取和分类器分类46。以下是其原理及具体应用方式:
- 区域选择:
- 滑动窗口法:
- 原理:滑动窗口是一种穷举策略,对输入的图像设置不同大小、不同长宽比的窗口,按照一定的步长在图像上进行滑动,遍历整个图像。然后使用一个事先训练好的分类器来判断每个窗口内是否存在目标物体。如果分类器给出的得分较高,则认为该窗口可能包含目标。
- 应用方式:在实际应用中,首先需要确定窗口的大小和步长。窗口大小通常根据目标的大致尺寸范围来选择,比如对于检测行人的任务,窗口大小可能会设置为与行人身高和宽度相适应的尺寸。步长则决定了窗口在图像上移动的间隔,步长越小,检测的精度越高,但计算量也会大大增加。例如,在一些简单的物体检测场景中,可以使用较小的步长和多种尺寸的窗口来确保能够检测到不同大小的目标。不过,这种方法的计算复杂度非常高,因为需要对大量的窗口进行处理,对于实时性要求较高的应用不太适用。
- 选择性搜索法:
- 原理:选择性搜索算法首先对图像进行分割,将图像划分为多个小区域。然后,根据这些区域的颜色、纹理、形状等特征的相似性,对小区域进行合并,形成一系列的候选区域。这些候选区域被认为是可能包含目标的区域,用于后续的特征提取和分类。
- 应用方式:在具体操作时,首先使用图像分割算法将图像分割成初始的小区域。然后,计算每个区域的特征,如颜色直方图、纹理特征等,并根据这些特征的相似性对区域进行合并。合并的过程是一个迭代的过程,直到满足一定的终止条件,比如无法再进行合并或者达到了预设的候选区域数量。选择性搜索算法在一定程度上减少了候选区域的数量,提高了检测的效率,但仍然存在计算量较大的问题。
- 滑动窗口法:
- 特征提取:
- HOG 特征1:
- 原理:HOG(Histogram of Oriented Gradients,方向梯度直方图)特征是通过计算和统计局部区域的梯度方向直方图来构成的。图像中每个像素的梯度包括大小和方向,梯度的方向反映了图像的边缘信息和纹理变化。将图像分成若干个小的细胞单元(cell),对于每个细胞单元,统计其梯度方向的直方图。然后,将多个细胞单元组成一个更大的块(block),对块内的细胞单元的特征进行归一化处理,以减少光照和阴影等因素的影响。最后,将图像中所有块的特征串联起来,就得到了图像的 HOG 特征描述子。
- 应用方式:在行人检测等任务中应用广泛。例如,对于一张输入的行人图像,首先将其灰度化,然后计算每个像素的梯度值。接着,将图像划分为细胞单元和块,统计每个细胞单元的梯度方向直方图,并对块内的特征进行归一化。最后,将得到的 HOG 特征输入到训练好的分类器中进行分类,判断是否是行人。HOG 特征对图像的几何和光学形变具有较好的不变性,适合用于检测具有一定姿态变化的目标,但对于复杂背景和遮挡情况的鲁棒性相对较弱。
- Haar 特征1:
- 原理:Haar 特征是一种基于像素值差异的特征,通俗点讲就是白色像素点与黑色像素点的差分,即特征值 = 白色像素点的像素值总和 - 黑色像素点的像素值总和。通过定义不同的矩形区域组合,可以得到多种不同的 Haar 特征,如两矩形特征、三矩形特征、对角特征等。这些矩形区域在图像上滑动,计算每个位置的 Haar 特征值,形成特征图。
- 应用方式:在 Viola-Jones 目标检测框架中,Haar 特征被用于人脸检测。首先,收集大量的正样本(包含人脸的图像)和负样本(不包含人脸的图像),然后使用这些样本对分类器进行训练。在训练过程中,不断调整分类器的参数,使得分类器能够准确地区分正样本和负样本。对于一张待检测的图像,使用滑动窗口法在图像上遍历不同位置和大小的窗口,计算每个窗口的 Haar 特征,并将这些特征输入到训练好的分类器中,判断窗口内是否存在人脸。
- HOG 特征1:
- 分类器分类:
- SVM(支持向量机):
- 原理:SVM 是一种二分类模型,其基本思想是找到一个能够将不同类别的样本正确划分的超平面,使得样本到超平面的距离最大化。对于线性可分的情况,直接寻找这样的超平面即可;对于线性不可分的情况,通过引入核函数将样本映射到高维空间,使其变得线性可分。在目标检测中,将提取的特征向量输入到 SVM 分类器中,SVM 分类器根据训练好的模型对特征向量进行分类,判断其属于目标还是背景,如果是目标,则进一步确定目标的类别2。
- 应用方式:在使用 SVM 进行目标检测时,首先需要对大量的标注样本进行特征提取,得到特征向量。然后,使用这些特征向量对 SVM 进行训练,调整 SVM 的参数,使得分类器能够准确地对新的样本进行分类。例如,在行人检测中,将提取的 HOG 特征输入到 SVM 分类器中,训练 SVM 分类器区分行人与非行人的特征模式。在训练完成后,对于新的输入图像,提取其 HOG 特征并输入到训练好的 SVM 分类器中,即可得到检测结果。
- Adaboost:
- 原理:Adaboost 是一种集成学习算法,通过将多个弱分类器组合成一个强分类器来提高分类的准确性。首先,初始化样本的权重,每个样本的权重初始值相同且权重之和为 1。然后,训练一系列的弱分类器,每个弱分类器都是基于部分样本进行训练的。在训练过程中,根据样本的分类结果不断调整样本的权重,对于分类错误的样本,增加其权重,对于分类正确的样本,降低其权重。这样,后续的弱分类器会更加关注那些难以分类的样本。最后,将多个弱分类器组合起来,根据每个弱分类器的权重对其分类结果进行加权投票,得到最终的分类结果1。
- 应用方式:在 Viola-Jones 目标检测框架中,Adaboost 算法被用于训练人脸分类器。首先,提取大量的 Haar 特征,然后使用这些特征训练多个弱分类器。在训练过程中,不断调整样本的权重和弱分类器的参数,使得组合后的强分类器能够准确地检测人脸。对于一张待检测的图像,使用滑动窗口法提取多个窗口的 Haar 特征,将这些特征输入到训练好的强分类器中,判断窗口内是否存在人脸。
- SVM(支持向量机):
传统目标检测方法在计算资源有限的情况下曾经发挥了重要作用,但由于其计算复杂度高、对复杂场景的适应性有限等缺点,逐渐被基于深度学习的目标检测方法所取代。不过,传统方法的一些思想和技术仍然对现代目标检测方法的发展具有一定的借鉴意义。
传统目标检测方法(基于 HOG 特征和 SVM 的行人检测):
import cv2
import numpy as np
from sklearn import svm
from skimage.feature import hog# 1. 提取HOG特征
def extract_hog_features(image):gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)features, _ = hog(gray_image, orientations=9, pixels_per_cell=(8, 8), cells_per_block=(2, 2), block_norm='L2-Hys',visualize=False, transform_sqrt=False)return features# 2. 加载训练数据并提取特征
def load_and_extract_features(train_images, train_labels):features = []for image in train_images:hog_features = extract_hog_features(image)features.append(hog_features)return np.array(features), np.array(train_labels)# 3. 训练SVM模型
def train_svm_model(features, labels):clf = svm.SVC(kernel='linear')clf.fit(features, labels)return clf# 4. 进行行人检测
def detect_pedestrians(image, svm_model):hog_features = extract_hog_features(image)prediction = svm_model.predict([hog_features])return prediction# 假设这里有已经准备好的训练图像和标签数据
# 例如,train_images 是一个包含多张训练图像的列表
# train_labels 是对应的训练图像的标签列表(1表示有行人,0表示无行人)# 加载并提取训练数据特征
train_features, train_labels = load_and_extract_features(train_images, train_labels)# 训练SVM模型
svm_model = train_svm_model(train_features, train_labels)# 读取待检测图像
test_image = cv2.imread('test_image.jpg')# 进行行人检测
result = detect_pedestrians(test_image, svm_model)if result == 1:print("检测到行人")
else:print("未检测到行人")
相关文章:
解析传统及深度学习目标检测方法的原理与具体应用之道
深度学习目标检测算法 常用的深度学习的目标检测算法及其原理和具体应用方法: R-CNN(Region-based Convolutional Neural Networks)系列1: 原理: 候选区域生成:R-CNN 首先使用传统的方法(如 Se…...

shell数组
文章目录 🍊自我介绍🍊shell数组概述🍊Shell数组使用方法数组的定义直接定义单元素定义 元素的获取获取单个元素获取全部元素 获取数组长度获取整个数组长度获取单个元素的长度 操作数组增加删除 关联数组 🍊 你的点赞评论就是对博…...

高斯混合模型回归(Gaussian Mixture Model Regression,GMM回归)
高斯混合模型(GMM)是一种概率模型,它假设数据是由多个高斯分布的混合组成的。在高斯混合回归中,聚类与回归被结合成一个联合模型: 聚类部分 — 使用高斯混合模型进行聚类,识别数据的不同簇。回归部分 — 对…...

【3D Slicer】的小白入门使用指南八
3D Slicer DMRI(Diffusion MRI)-扩散磁共振认识和使用 0、简介 大脑解剖 ● 白质约占大脑的 45% ● 有髓神经纤维(大约10微米轴突直径) 白质探索 朱尔斯约瑟夫德杰林(Jules Joseph Dejerine,《神经中心解剖学》(巴黎,1890-1901):基于髓磷脂染色标本的神经解剖图谱)…...

【流量分析】常见webshell流量分析
免责声明:本文仅作分享! 对于常见的webshell工具,就要知攻善防;后门脚本的执行导致webshell的连接,对于默认的脚本要了解,才能更清晰,更方便应对。 (这里仅针对部分后门代码进行流量…...

基于树莓派的边缘端 AI 目标检测、目标跟踪、姿态估计 视频分析推理 加速方案:Hailo with ultralytics YOLOv8 YOLOv11
文件大纲 加速原理硬件安装软件安装基本设置系统升级docker 方案Demo 测试目标检测姿态估计视频分析参考文献前序树莓派文章hailo加速原理 Hailo 发布的 Raspberry Pi AI kit 加速原理,有几篇文章介绍的不错 https://ubuntu.com/blog/hackers-guide-to-the-raspberry-pi-ai-ki…...

Java在算法竞赛中的常用方法
在算法竞赛中,Java以其强大的标准库和高效的性能成为了众多参赛者的首选语言。本文将详细介绍Java在算法竞赛中的常用集合、字符串处理、进制转换、大数处理以及StringBuilder的使用技巧,帮助你在竞赛中更加得心应手。 常用集合 Java的集合框架提供了多…...
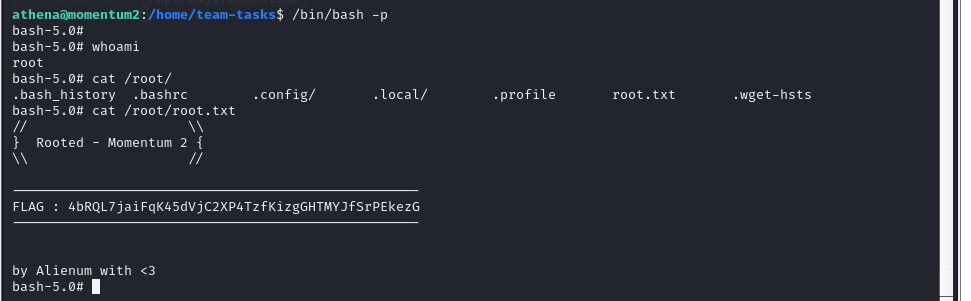
Vulnhub靶场案例渗透[10]- Momentum2
文章目录 一、靶场搭建1. 靶场描述2. 下载靶机环境3. 靶场搭建 二、渗透靶场1. 确定靶机IP2. 探测靶场开放端口及对应服务3. 扫描网络目录结构4. 代码审计5. 反弹shell6. 提权 一、靶场搭建 1. 靶场描述 - Difficulty : medium - Keywords : curl, bash, code reviewThis wor…...

Spark RDD中常用聚合算子源码层面的对比分析
在 Spark RDD 中,groupByKey、reduceByKey、foldByKey 和 aggregateByKey 是常用的聚合算子,适用于按键进行数据分组和聚合。它们的实现方式各不相同,涉及底层调用的函数也有区别。以下是对这些算子在源码层面的分析,以及每个算子…...

计算机网络 (6)物理层的基本概念
前言 计算机网络物理层是OSI模型(开放式系统互联模型)中的第一层,也是七层中的最底层,它涉及到计算机网络中数据的物理传输。 一、物理层的主要任务和功能 物理层的主要任务是处理物理传输介质上的原始比特流,确保数据…...
)
快速上手:Docker 安装详细教程(适用于 Windows、macOS、Linux)
### 快速上手:Docker 安装详细教程(适用于 Windows、macOS、Linux) --- Docker 是一款开源容器化平台,广泛应用于开发、测试和部署。本文将为您提供分步骤的 Docker 安装教程,涵盖 Windows、macOS 和 Linux 系统。 …...

kafka消费者出现频繁Rebalance
kafka消费者在正常使用过程中,突然出现了不消费消息的情况,项目里是使用了多个消费者消费不同数据,按理不会相互影响,看日志,发现消费者出现了频繁的Rebalance。 Rebalance的触发条件 组成员发生变更(新consumer加入组…...
rk3399开发环境使用Android 10初体验蓝牙功能
版本 日期 作者 变更表述 1.0 2024/11/10 于忠军 文档创建 零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等࿰…...

ASP.NET 部署到IIS,访问其它服务器的共享文件 密码设定
asp.net 修改上面的 IIS需要在 配置文件 添加如下内容 》》》web.config <system.web><!--<identity impersonate"true"/>--><identity impersonate"true" userName"您的账号" password"您的密码" /><co…...

将自定义函数添加到MATLAB搜索路径的方法
在MATLAB中,将自定义函数添加到搜索路径可以确保你能够方便地调用这些函数,而不必每次都指定完整路径。本文介绍几种将自定义函数添加到MATLAB搜索路径的方法 文章目录 使用 MATLAB 的路径管理工具使用 addpath 命令在启动时自动添加路径使用 genpath 命…...

云原生之运维监控实践-使用Telegraf、Prometheus与Grafana实现对InfluxDB服务的监测
背景 如果你要为应用程序构建规范或用户故事,那么务必先把应用程序每个组件的监控指标考虑进来,千万不要等到项目结束或部署之前再做这件事情。——《Prometheus监控实战》 去年写了一篇在Docker环境下部署若依微服务ruoyi-cloud项目的文章,当…...

什么是MySQL,有什么特点
什么是 MySQL? MySQL 是一个关系型数据库管理系统(RDBMS),由瑞典公司 MySQL AB 开发,后来被 Sun Microsystems 收购,最终成为 Oracle Corporation 的一部分。MySQL 是最流行的关系型数据库之一,…...

初始化mysql5.7
-- 环境变量 MYSQL_HOME %MYSQL_HOME%\bin -- 新增配置文件 my.ini [mysqld] port 3306 basedir D:/develop/MySQL/mysql-5.7.44-winx64 datadir D:/develop/MySQL/mysql-5.7.44-winx64/data max_connections 200character-set-serverutf8 default-storage-engineINNODB …...

C# 字典应用
using System;using System.Collections.Generic;class Program{static void Main(){// 创建一个字典,键是字符串类型,值是整数类型Dictionary<string, int> studentScores new Dictionary<string, int>();// 向字典中添加键值对// 原理&am…...

CDH安装与配置及相关大数据组件实践
CDH安装与配置及相关大数据组件实践 一、CDH 介绍 CDH(Cloudera’s Distribution Including Apache Hadoop)是一个基于 Web 用户界面的大数据平台版本。它支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoo…...

Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生
Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到无奈&a…...

模拟IC设计避坑指南:用Cadence Virtuoso仿真,揭秘电流镜精度下降的3个元凶
模拟IC设计避坑指南:用Cadence Virtuoso仿真,揭秘电流镜精度下降的3个元凶 在模拟CMOS集成电路设计中,电流镜作为基础模块广泛应用于偏置电路、有源负载等场景。然而许多工程师在Cadence Virtuoso IC617中完成电流镜设计后,常会遇…...

如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案
如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 还在为网站图片加载缓慢而烦恼…...

Java 大厂面试 200 题完整版含答案解析
前言本文整理了近两年从阿里、腾讯、字节、美团、京东、拼多多等大厂面试中高频出现的 200 道 Java 面试题,覆盖 Java 基础、集合、并发、JVM、Spring、MySQL、Redis、消息队列、分布式、场景设计 等核心模块,每题都附有简明扼要的答案解析,助…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

Faderwave合成器设计:从波形塑造到数字滤波的嵌入式音频实践
1. 项目概述:从推子到声音,Faderwave合成器的设计哲学如果你玩过硬件合成器,或者对数字音频合成感兴趣,那你肯定知道,声音设计的起点往往是一个简单的波形。但如何让这个波形“活”起来,变成你脑海中那个独…...

Pro Trinket:Arduino UNO的紧凑型替代方案与双模编程实战
1. Pro Trinket:当Arduino遇上“口袋工程学”如果你和我一样,在创客圈子里摸爬滚打多年,肯定经历过这样的场景:一个基于Arduino UNO的酷炫原型在面包板上运行得风生水起,但当你试图把它塞进一个精致的3D打印外壳&#…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

Cursor编辑器状态快照插件开发:一键保存与恢复工作区
1. 项目概述:一个专为开发者设计的“后悔药”如果你是一名重度使用 Cursor 编辑器的开发者,那么你一定经历过这样的场景:在沉浸式编码时,为了快速定位或修改,你可能会频繁地使用CtrlClick跳转到函数定义,或…...

Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案
Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 还在为传统游戏模组安装的繁琐流程而烦恼吗&…...