从视频帧生成点云数据、使用PointNet++模型提取特征,并将特征保存下来的完整实现。
文件地址
https://github.com/yanx27/Pointnet_Pointnet2_pytorch?spm=5176.28103460.0.0.21a95d27ollfze
Pointnet_Pointnet2_pytorch\log\classification\pointnet2_ssg_wo_normals文件夹改名为Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg
"E:\Pointnet_Pointnet2_pytorch\provider.py" 在provider.py文件头添加
def pc_normalize(pc):l = pc.shape[0]centroid = np.mean(pc, axis=0)pc = pc - centroidm = np.max(np.sqrt(np.sum(pc**2, axis=1)))pc = pc / mreturn pc详细介绍了如何从视频帧中生成点云数据并使用PointNet++模型提取特征,最后将特征保存下来。
从视频帧中生成点云数据并提取特征
1. 引言
在计算机视觉领域,点云数据是一种重要的三维数据形式,广泛应用于自动驾驶、机器人导航、物体识别等场景。本文将详细介绍如何从视频帧中生成点云数据,并使用PointNet++模型提取特征,最后将特征保存下来以供后续分析或使用。
2. 环境准备
在开始之前,确保你的环境中安装了以下依赖项:
Python 3.6+
PyTorch 1.7+
Open3D
OpenCV
NumPy
你可以使用以下命令安装这些依赖项:
pip install torch torchvision
pip install open3d opencv-python numpy
3. 代码实现
import os
import sys
# 获取当前脚本所在的目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将 models 目录添加到 sys.path
sys.path.insert(0, os.path.join(current_dir, 'models'))
import numpy as np
import torch
import cv2
import open3d as o3d
from models.pointnet2_cls_ssg import get_model
from provider import pc_normalize
import time
import hashlib# 打印 sys.path 以确认路径是否正确
print(sys.path)# 设置设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"设备设置为: {device}")# 加载预训练模型
#"E:\Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg\checkpoints\best_model.pth"
model_path = os.path.join('log', 'classification', 'pointnet2_cls_ssg', 'checkpoints', 'best_model.pth') # 替换为实际路径
print(f"加载预训练模型: {model_path}")
model = get_model(num_class=40, normal_channel=False).to(device)# 只加载模型参数
checkpoint = torch.load(model_path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
print("模型加载完成")# 从视频帧生成点云数据
def frame_to_point_cloud(frame, depth_frame=None):if depth_frame is None:# 如果没有深度图,使用随机生成的点云数据作为示例points = np.random.rand(1024, 3) # 生成 1024 个点,每个点有 3 个坐标else:# 使用深度图生成点云h, w = depth_frame.shapey, x = np.indices((h, w))z = depth_framepoints = np.stack([x, y, z], axis=-1).reshape(-1, 3)points = points[~np.isnan(points).any(axis=1)] # 去除无效点if points.shape[0] > 1024:points = points[np.random.choice(points.shape[0], 1024, replace=False)]elif points.shape[0] < 1024:points = np.pad(points, ((0, 1024 - points.shape[0]), (0, 0)), mode='constant')print(f"生成点云数据: {points.shape}")return points# 提取特征
def extract_features(model, point_cloud):point_cloud = pc_normalize(point_cloud) # 归一化点云point_cloud = torch.from_numpy(point_cloud).float().unsqueeze(0).transpose(2, 1).to(device)with torch.no_grad():pred, trans_feat = model(point_cloud) # 只接收两个返回值print(f"提取特征完成: {pred.shape}")return pred.cpu().numpy()# 处理单个视频文件
def process_video(video_path, output_folder):cap = cv2.VideoCapture(video_path)frame_count = 0video_name = os.path.basename(video_path).split('.')[0]print(f"开始处理视频: {video_path}")all_features = []while cap.isOpened():ret, frame = cap.read()if not ret:break# 生成点云数据point_cloud = frame_to_point_cloud(frame)if point_cloud.shape[0] < 1024: # 确保至少有 1024 个点print(f"帧 {frame_count} 点云数据不足,跳过")continue # 如果点不够,跳过此帧# 提取特征features = extract_features(model, point_cloud)print(f"处理帧 {frame_count} 特征: {features}")# 保存特征到 all_features 列表中all_features.append(features)frame_count += 1cap.release()print(f"视频处理完成: {video_path}")# 生成唯一的文件名output_file = os.path.join(output_folder, f'{video_name}_features.npy')# 将所有特征保存到一个文件中np.save(output_file, np.vstack(all_features))print(f"特征已保存到: {output_file}")# 检查视频文件是否已处理
def is_video_processed(video_path, processed_videos):video_hash = hashlib.md5(video_path.encode()).hexdigest()return video_hash in processed_videos# 获取已处理的视频文件列表
def get_processed_videos(output_file):if not os.path.exists(output_file):return set()processed_videos = set()with open(output_file, 'r') as f:for line in f:processed_videos.add(line.strip())return processed_videos# 记录已处理的视频文件
def record_processed_video(video_path, output_file):video_hash = hashlib.md5(video_path.encode()).hexdigest()with open(output_file, 'a') as f:f.write(video_hash + '\n')# 处理视频文件夹
def process_video_folder(folder_path, output_folder):processed_videos_file = os.path.join(output_folder, 'processed_videos.txt')processed_videos = get_processed_videos(processed_videos_file)print(f"开始处理视频文件夹: {folder_path}")for root, dirs, files in os.walk(folder_path):for file in files:if file.endswith('.mp4') or file.endswith('.avi'):video_path = os.path.join(root, file)if is_video_processed(video_path, processed_videos):print(f"视频已处理,跳过: {video_path}")continueprocess_video(video_path, output_folder)record_processed_video(video_path, processed_videos_file)print("所有视频处理完成")# 主程序
if __name__ == "__main__":# 视频文件夹路径input_folder = r'E:\Pointnet_Pointnet2_pytorch\data\voide'output_folder = r'E:\Pointnet_Pointnet2_pytorch\data\voide_features' # 特征保存路径# 确保输出文件夹存在os.makedirs(output_folder, exist_ok=True)# 处理视频文件夹process_video_folder(input_folder, output_folder)
3.1 导入必要的库
首先,我们需要导入一些必要的库,包括文件操作、数值计算、深度学习框架、图像处理和点云处理相关的库。
3.2 设置设备
检查是否有可用的GPU,并设置设备。如果存在GPU,将使用GPU进行计算;否则,使用CPU。
3.3 加载预训练模型
我们使用PointNet++模型来提取点云特征。首先,加载预训练模型。这通常涉及以下几个步骤:
指定模型路径:提供预训练模型的路径。
加载模型:使用 get_model 函数创建模型实例,并将其移动到指定的设备(CPU或GPU)。
加载模型参数:从预训练模型文件中加载模型参数,并设置模型为评估模式。
3.4 从视频帧生成点云数据
定义一个函数 frame_to_point_cloud,该函数从视频帧中生成点云数据。如果没有深度图,可以生成随机点云数据作为示例。具体步骤如下:
生成随机点云:如果没有深度图,生成1024个随机点,每个点有3个坐标。
使用深度图生成点云:如果有深度图,从深度图中提取点云数据。具体做法是将深度图的每个像素位置(x, y)和对应的深度值z组合成一个三维点(x, y, z)。然后,去除无效点,并确保点云数据的形状为 (1024, 3)。
3.5 提取特征
定义一个函数 extract_features,该函数使用预训练模型提取点云数据的特征。具体步骤如下:
归一化点云:对点云数据进行归一化处理,使其适合输入到模型中。
转换为张量:将点云数据转换为PyTorch张量,并移动到指定的设备。
提取特征:使用预训练模型提取特征,并返回特征向量。
3.6 处理单个视频文件
定义一个函数 process_video,该函数处理单个视频文件,逐帧生成点云数据并提取特征。具体步骤如下:
打开视频文件:使用OpenCV的 cv2.VideoCapture 打开视频文件。
读取帧:逐帧读取视频。
生成点云数据:调用 frame_to_point_cloud 函数生成点云数据。
提取特征:调用 extract_features 函数提取特征。
保存特征:将提取的特征保存为 .npy 文件。
3.7 处理视频文件夹
定义一个函数 process_video_folder,该函数处理指定文件夹中的所有视频文件。具体步骤如下:
遍历文件夹:使用 os.walk 遍历指定文件夹中的所有视频文件。
处理每个视频:调用 process_video 函数处理每个视频文件。
3.8 主程序
在主程序中,指定输入视频文件夹和输出特征文件夹的路径,并调用 process_video_folder 函数处理所有视频文件。
4. 总结
本文详细介绍了如何从视频帧中生成点云数据,并使用PointNet++模型提取特征,最后将特征保存下来。通过这些步骤,你可以将视频数据转换为点云数据,并提取有用的特征,为后续的分析和应用提供支持。

相关文章:
从视频帧生成点云数据、使用PointNet++模型提取特征,并将特征保存下来的完整实现。
文件地址 https://github.com/yanx27/Pointnet_Pointnet2_pytorch?spm5176.28103460.0.0.21a95d27ollfze Pointnet_Pointnet2_pytorch\log\classification\pointnet2_ssg_wo_normals文件夹改名为Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg "E:…...

工化企业内部能源能耗过大 落实能源管理
一、精准监测与数据分析 实时准确的数据采集 企业能耗管理系统能够对企业内各种能源(如电、水、气、热等)的使用情况进行实时监测。通过安装在能源供应线路和设备上的智能传感器,可以精确地采集能源消耗的各项数据,包括瞬时流量、…...

LSTM 和 LSTMCell
1. LSTM 和 LSTMCell 的简介 LSTM (Long Short-Term Memory): 一种特殊的 RNN(循环神经网络),用于解决普通 RNN 中 梯度消失 或 梯度爆炸 的问题。能够捕获 长期依赖关系,适合处理序列数据(如自然语言、时间序列等&…...

python成长技能之正则表达式
文章目录 一、认识正则表达式二、使用正则表达式匹配单一字符三、正则表达式之重复出现数量匹配四、使用正则表达式匹配字符集五、正则表达式之边界匹配六、正则表达式之组七、正则表达式之贪婪与非贪婪 一、认识正则表达式 什么是正则表达式 正则表达式(英语&…...

解决docker报Error response from daemon Get httpsregistry-1.docker.iov2错误
解决docker报Error response from daemon: Get "https://registry-1.docker.io/v2/"错误 报错详情 首先先看一下问题报错效果,我想要拉去nacos-serve:1.1.4的镜像,报如下错误,从报错信息可以看到,用于网络的愿意&…...

【论文分享】利用多源大数据衡量街道步行环境的老年友好性:以中国上海为例
本次给大家带来一篇SCI论文的全文翻译!该论文考虑了绿化程度、可步行性、安全性、形象性、封闭性和复杂性这六个指标,提出了一种基于多源地理空间大数据的新型定量评价模型,用于从老年人和专家的角度评估街道步行环境的老年友好程度ÿ…...

说说软件工程中的“协程”
在软件工程中,协程(coroutine)是一种程序运行的方式,可以理解成“协作的线程”或“协作的函数”。以下是对协程的详细解释: 一、协程的基本概念 定义:协程是一组序列化的子过程,用户能像指挥家…...

使用IDE实现java端远程调试功能
使用IDE实现java端远程调试功能 1. 整体描述2. 前期准备3. 具体操作3.1 修改启动命令3.2 IDE配置3.3 打断点3.4 运行Debug 4. 总结 1. 整体描述 在做项目时,有些时候,需要和第三方进行调式,但是第三方不在一起,需要进行远程调试&…...

javaScript交互案例2
1、京东侧边导航条 需求: 原先侧边栏是绝对定位当页面滚动到一定位置,侧边栏改为固定定位页面继续滚动,会让返回顶部显示出来 思路: 需要用到页面滚动事件scroll,因为是页面滚动,所以事件源是document滚动…...

JavaScript 浏览器对象模型 BOM
浏览器对象模型(Browser Object Model,BOM)是指一组与浏览器进行交互的 JavaScript 对象。它允许 JavaScript 与浏览器的组件进行交互,比如窗口、文档、历史记录等。BOM 不同于 DOM(文档对象模型)ÿ…...

基于MATLAB的激光雷达与相机联合标定原理及实现方法——以标定板为例
1.为什么要进行激光雷达和相机的联合标定? 激光雷达和相机的联合标定是为了将两种传感器的数据统一到同一坐标系中,从而实现更准确的环境感知。激光雷达提供精准的三维距离信息,而相机捕捉丰富的纹理和颜色,通过联合标定可以结合两…...

React(一)
文章目录 项目地址一、创建第一个react项目二、JSX语法2.1 生成列表2.2 大括号识别JS的表达式2.3 列表循环array2.4 条件判断以及假值显示2.5 复杂条件渲染2.6 事件处理2.7 添加CSS样式2.8 添加图片2.9 使用Fregments返回多个根标签2.10多条件渲染2.11 导出子组件2.12 给子组件…...

Liunx-Ubuntu22.04.1系统下配置Anaconda+pycharm+pytorch-gpu环境配置
这里写自定义目录标题 Liunx-Ubuntu22.04.1系统下配置Anacondapycharmpytorch-gpu环境配置一、Anaconda3配置1.Anaconda安装2.Anaconda更新3.Anaconda删除 二、pycharm配置1.pycharm安装 三、pytorch配置 Liunx-Ubuntu22.04.1系统下配置Anacondapycharmpytorch-gpu环境配置 一…...

Postman之数据提取
Postman之数据提取 1. 提取请求头\request中的数据2. 提取响应消息\response中的数据3. 通过正在表达式提取4. 提取cookies数据 本文主要讲解利用pm对象对数据进行提取操作,虽然postman工具的页面上也提供了一部分的例子,但是实际使用时不是很全面&#…...

selenium元素定位校验以及遇到的元素操作问题记录
页面元素定位方法及校验 使用比较多的是通过id、class和xpath来对元素进行定位。在定位前可以现在浏览器验证是否可以找到指定的元素。这样就不用每添加一个元素定位都运行代码来检查定位方式表达式是否正确。 使用XPATH定位 在浏览器F12,找到元素,在元…...

在AndroidStudio中新建项目时遇到的Gradle下载慢问题,配置错的按我的来,镜像地址不知道哪个网页找的,最主要下载要快
android-studio-2024.2.1.11-windows Android 移动应用开发者工具 – Android 开发者 | Android Developers https://r4---sn-j5o76n7z.gvt1-cn.com/edgedl/android/studio/install/2024.2.1.11/android-studio-2024.2.1.11-windows.exe?cms_redirectyes&met1731775…...

用mv命令替换rm命令
# 用mv命令替换rm命令 主要内容来源自以上博文 rm命令穷凶极恶,以下为替换命令的方式,必做 步骤 修改vim ~/.bashrc加入以下代码 mkdir -p ~/.trash #在家目录下创建一个.trash文件夹(隐藏文件,ls -a 查看) alias rmdel #使用别名…...

电解车间铜业机器人剥片技术是现代铜冶炼过程中自动化和智能化的重要体现
电解车间铜业机器人剥片技术是现代铜冶炼过程中自动化和智能化的重要体现 电解车间铜业机器人剥片技术是现代铜冶炼过程中自动化和智能化的重要体现,它主要应用于铜电解精炼的最后阶段,即从阴极板上剥离出纯铜的过程。以下是该技术的几个关键点ÿ…...
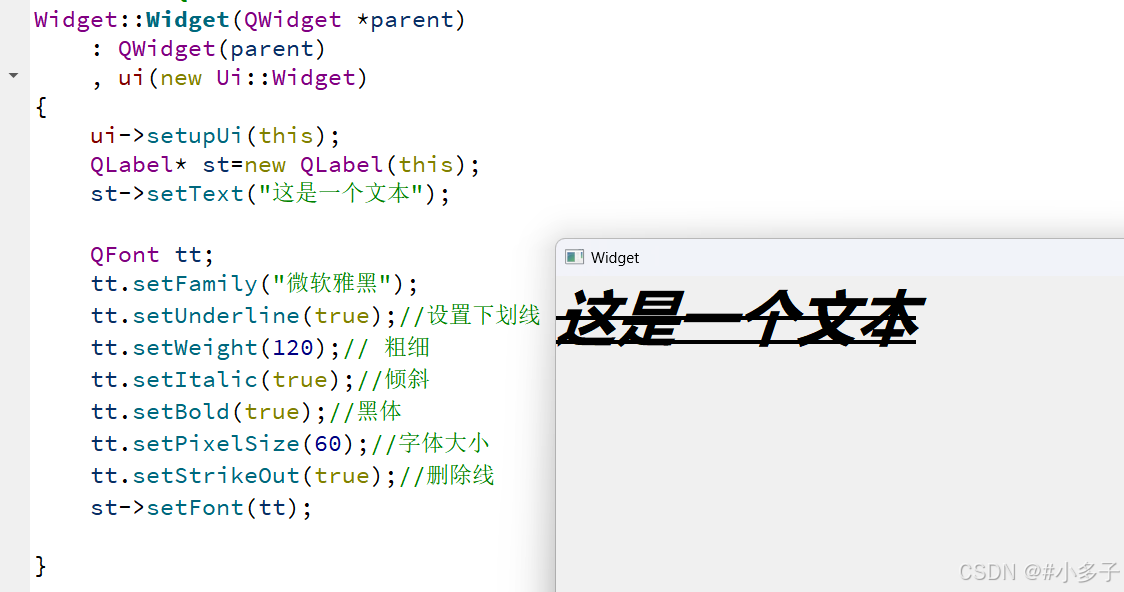
【qt】控件2
1.frameGeometry和Geometry区别 frameGeometry是开始从红圈开始算,Geometry从黑圈算 程序证明:使用一个按键,当按键按下,qdebug打印各自左上角的坐标(相当于屏幕左上角),以及窗口大小 Widget::Widget(QWid…...

Frida反调试对抗系列(四)百度加固
本文只是交流技术,如有侵权请联系我删除。 知识星球:https://t.zsxq.com/kNlj4 前言: 上一篇文章我们提到 我们使用github开源魔改好的frida server 但是仍然有一些厂商的server不能通过,那么这篇文章针对百度加固 进行快速通…...

Windows下用Python调用CDS API下载ERA5数据,报错Missing/incomplete configuration?手把手教你创建.cdsapirc配置文件
Windows下Python调用CDS API下载ERA5数据报错排查指南:从配置文件创建到隐藏文件陷阱全解析 当你在Windows系统上首次尝试使用Python调用CDS API下载ERA5气象数据时,可能会遇到一个令人困惑的报错:"Missing/incomplete configuration f…...

UE5视频插件深度解析:如何实现高效的实时流媒体处理与录制
UE5视频插件深度解析:如何实现高效的实时流媒体处理与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一款基于Unreal Engine 5开发的专业级实时视频处理插件,专为…...

中文文本人性化:从NLP原理到cn-humanizer工程实践
1. 项目概述:为什么我们需要一个中文“人性化”工具?在数字时代,我们与机器生成的文本打交道的机会越来越多。无论是AI助手生成的回复、自动化脚本输出的日志,还是数据清洗后得到的报告,这些文本常常带着一种难以言喻的…...

官宣!网络安全法正式实施,人才缺口 327 万,这 5 类人直接站上风口,年薪百万不是梦
【必看收藏】网络安全人才抢夺战打响!新法实施后5类专业薪资翻倍,附学习路线 新《网络安全法》实施引爆网络安全人才市场,全球缺口480万,中国缺口327万以上。网络空间安全、信息安全、保密技术、网络安全科学与技术、信息对抗技术…...

KMS_VL_ALL_AIO智能激活脚本:5分钟搞定Windows和Office永久激活的终极方案
KMS_VL_ALL_AIO智能激活脚本:5分钟搞定Windows和Office永久激活的终极方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office办公软件授权而烦恼吗&…...

LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南
LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

如何快速完成Windows系统部署:高效自动化工具完整指南
如何快速完成Windows系统部署:高效自动化工具完整指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat Wind…...

工业AI相机的散热困局:为什么你的视觉检测总在夏天失效?
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 211、985硕士,从业16年 从事结构设计、热设计、售前、产品设计、项目管理等工作,涉足消费电子、新能源、医疗设备、制药信息化、核工业等…...

2026 云手机横评:傲晨云、红手指、川川云、雷电云实测,全能首选一目了然
一、测评背景与说明随着手游挂机、账号多开、云端办公等需求爆发,云手机已成为个人玩家与工作室的必备工具。当前市场品牌繁杂,傲晨云、红手指、川川云、雷电云是关注度较高的四款产品,它们在性能、稳定性、功能及价格上差异显著。本次测评基…...

零门槛云端实时物体识别:基于Google Colab与MobileNet V2的实践指南
1. 项目概述:零门槛体验云端实时物体识别想亲手体验一下人工智能的“眼睛”是如何看世界的吗?物体识别,这个听起来高深莫测的技术,其实离我们并不遥远。它就像是给计算机装上了一套视觉系统,让它能像我们一样ÿ…...